03 de nov. de 2025·8 min
Padrões de SaaS Multi-tenant: Isolamento, Escala e Design com IA
Aprenda padrões comuns de SaaS multi-tenant, trade-offs de isolamento por tenant e estratégias de escala. Veja como arquiteturas geradas por IA aceleram design e revisões.
O que Multi-tenancy Significa (sem o jargão)
Multi-tenancy significa que um produto de software serve vários clientes (tenants) a partir do mesmo sistema em execução. Cada tenant sente que tem “sua própria app”, mas nos bastidores eles compartilham partes da infraestrutura — como os mesmos servidores web, a mesma base de código e, frequentemente, o mesmo banco de dados.
Um modelo mental útil é um prédio de apartamentos. Cada um tem sua unidade trancada (seus dados e configurações), mas você compartilha o elevador, o encanamento e a equipe de manutenção do prédio (o compute, o armazenamento e as operações da app).
Por que times escolhem multi-tenancy
A maioria dos times não escolhe SaaS multi-tenant porque é tendência — escolhem porque é eficiente:
- Custo menor por cliente: infraestrutura compartilhada costuma ser mais barata do que provisionar uma pilha completa por cliente.
- Operações mais simples: uma plataforma para monitorar, corrigir e proteger (em vez de centenas de pequenas implantações).
- Entrega mais rápida: melhorias vão para todo mundo de uma vez e você evita “deriva de versão” entre clientes.
Onde pode dar errado
Os dois modos clássicos de falha são segurança e desempenho.
Em segurança: se as barreiras entre tenants não são aplicadas em toda parte, um bug pode vazar dados entre clientes. Esses vazamentos raramente são “ataques dramáticos” — muitas vezes são erros comuns como um filtro ausente, uma checagem de permissão mal configurada ou um job em background que roda sem contexto do tenant.
Em desempenho: recursos compartilhados significam que um tenant ocupado pode deixar os outros lentos. Esse efeito de “vizinho barulhento” pode aparecer como consultas lentas, cargas em rajada ou um único cliente consumindo capacidade excessiva de API.
Visão rápida dos padrões abordados
Este artigo percorre os blocos de construção que os times usam para gerenciar esses riscos: isolamento de dados (banco, esquema ou linhas), identidade e permissões orientadas ao tenant, controles contra vizinhos barulhentos e padrões operacionais para escalabilidade e gestão de mudanças.
A Troca Central: Isolamento vs Eficiência
Multi-tenancy é uma escolha sobre onde você se posiciona em um espectro: quanto você compartilha entre tenants vs quanto você dedica por tenant. Cada padrão de arquitetura abaixo é apenas um ponto diferente nessa linha.
Recursos compartilhados vs dedicados: o espectro central
Em uma extremidade, os tenants compartilham quase tudo: as mesmas instâncias da aplicação, os mesmos bancos, as mesmas filas, os mesmos caches — separados logicamente por IDs de tenant e regras de acesso. Isso normalmente é o mais barato e fácil de operar porque você agrega capacidade.
Na outra extremidade, tenants recebem sua “fatia” do sistema: bancos separados, compute separado, às vezes até deploys separados. Isso aumenta segurança e controle, mas também aumenta overhead operacional e custos.
Por que isolamento e custo puxam em direções opostas
Isolamento reduz a chance de um tenant acessar dados de outro, consumir o orçamento de performance alheio ou ser impactado por padrões de uso incomuns. Também facilita certos requisitos de auditoria e conformidade.
Eficiência melhora quando você amortiza capacidade ociosa entre muitos tenants. Infraestrutura compartilhada permite rodar menos servidores, manter pipelines de deploy mais simples e escalar com base na demanda agregada em vez do pior caso por tenant.
Drivers comuns da decisão
Seu ponto “certo” no espectro raramente é filosófico — é impulsionado por restrições:
- SLA e expectativas dos clientes: metas estritas de disponibilidade ou latência empurram para mais isolamento.
- Conformidade e residência de dados: requisitos podem forçar armazenamento ou ambientes dedicados.
- Estágio de crescimento: produtos iniciais costumam começar mais compartilhados para andar mais rápido; depois, podem introduzir opções dedicadas para clientes grandes.
- Maturidade operacional: mais isolamento normalmente significa mais coisas para monitorar, corrigir e migrar.
Um modelo mental simples para escolher padrões
Faça duas perguntas:
-
Qual é o raio de impacto se um tenant se comportar mal ou for comprometido?
-
Qual é o custo de negócio de reduzir esse raio de impacto?
Se o raio de impacto precisa ser minúsculo, escolha componentes mais dedicados. Se custo e velocidade são mais importantes, compartilhe mais — e invista em controles de acesso fortes, limites de taxa e monitoramento por tenant para manter o compartilhamento seguro.
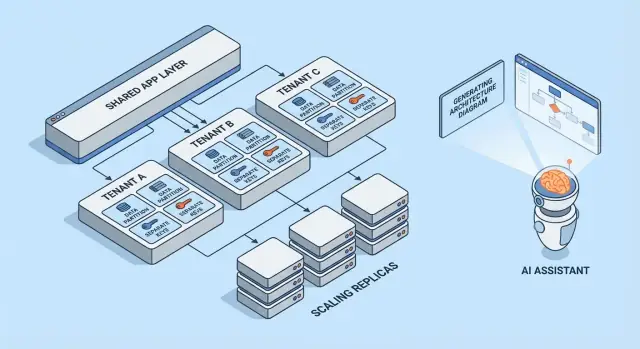
Modelos Multi-tenant em Resumo
Multi-tenancy não é uma arquitetura única — é um conjunto de maneiras de compartilhar (ou não) infraestrutura entre clientes. O melhor modelo depende de quanto isolamento você precisa, quantos tenants espera e quanto overhead operacional seu time consegue suportar.
1) Single-tenant (dedicado) — o baseline
Cada cliente recebe sua própria pilha de app (ou pelo menos runtime e banco isolados). É o mais simples de raciocinar em termos de segurança e desempenho, mas costuma ser o mais caro por tenant e pode desacelerar a escalabilidade das operações.
2) App compartilhado + BD compartilhado — custo mais baixo, exige cuidado máximo
Todos os tenants rodam na mesma aplicação e banco de dados. Os custos são normalmente os mais baixos porque você maximiza reuso, mas é preciso ser meticuloso sobre o contexto do tenant em toda parte (queries, cache, jobs em background, exportações para analytics). Um único erro pode virar um vazamento de dados entre tenants.
3) App compartilhado + BD separado — isolamento mais forte, mais operações
A aplicação é compartilhada, mas cada tenant tem seu próprio banco de dados (ou instância de banco). Isso melhora o controle do raio de impacto em incidentes, facilita backups/restores por tenant e pode simplificar conversas de conformidade. O trade-off é operacional: mais bancos para provisionar, monitorar, migrar e proteger.
4) Modelos híbridos para “tenants grandes”
Muitos produtos SaaS misturam abordagens: a maioria dos clientes vive em infraestrutura compartilhada, enquanto tenants grandes ou regulamentados recebem bancos ou compute dedicados. Híbrido costuma ser o estado prático, mas precisa de regras claras: quem se qualifica, quanto custa e como as atualizações são aplicadas.
Se quiser um mergulho mais profundo nas técnicas de isolamento dentro de cada modelo, veja /blog/data-isolation-patterns.
Padrões de Isolamento de Dados (BD, Esquema, Linha)
Isolamento de dados responde a uma pergunta simples: “Um cliente pode alguma vez ver ou afetar os dados de outro cliente?” Há três padrões comuns, cada um com implicações diferentes de segurança e operação.
Isolamento por linha (tabelas compartilhadas + tenant_id)
Todos os tenants compartilham as mesmas tabelas, e cada linha inclui uma coluna tenant_id. Esse é o modelo mais eficiente para tenants pequenos a médios porque minimiza infraestrutura e mantém reporting/analytics simples.
O risco é direto: se qualquer query esquecer de filtrar por tenant_id, você pode vazar dados. Mesmo um endpoint “admin” ou um job em background pode virar ponto fraco. Mitigações incluem:
- Fazer filtragem por tenant num layer de acesso a dados compartilhado (para que desenvolvedores não criem filtros manualmente)
- Usar recursos do banco de dados como segurança por nível de linha (RLS) onde disponível
- Adicionar testes automatizados que tentem acesso cruzado entre tenants de propósito
- Indexar caminhos de acesso comuns (frequentemente
(tenant_id, created_at)ou(tenant_id, id)) para que consultas com escopo por tenant permaneçam rápidas
Esquema por tenant (mesmo banco, esquemas separados)
Cada tenant recebe seu próprio esquema (namespaces como tenant_123.users, tenant_456.users). Isso melhora o isolamento comparado ao compartilhamento por linha e pode facilitar exportação por tenant ou tuning específico.
O trade-off é overhead operacional. Migrations precisam rodar em muitos esquemas e falhas ficam mais complicadas: você pode migrar com sucesso 9.900 tenants e travar em 100. Monitoramento e tooling importam aqui — seu processo de migração precisa de comportamento claro de retry e relatórios.
Banco por tenant (bancos separados)
Cada tenant recebe um banco separado. O isolamento é forte: limites de acesso ficam mais claros, queries ruidosas de um tenant têm menos chance de impactar outro, e restaurar um único tenant de backup é muito mais limpo.
Custos e escalabilidade são as principais desvantagens: mais bancos para gerenciar, mais pools de conexão e potencialmente mais trabalho de upgrade/migração. Muitas equipes reservam esse modelo para tenants de alto valor ou regulamentados, enquanto tenants menores ficam em infraestrutura compartilhada.
Sharding e estratégias de colocação conforme os tenants crescem
Sistemas reais costumam misturar esses padrões. Um caminho comum é isolamento por linha no crescimento inicial e depois “graduar” tenants maiores para esquemas ou bancos separados.
Sharding adiciona uma camada de posicionamento: decidir em qual cluster de banco um tenant mora (por região, faixa de tamanho ou hashing). O essencial é tornar a colocação do tenant explícita e mutável — para que você possa mover um tenant sem reescrever a app e escalar adicionando shards em vez de redesenhar tudo.
Identidade, Acesso e Contexto de Tenant
Multi-tenancy falha de maneiras surpreendentemente ordinárias: um filtro ausente, um objeto em cache compartilhado entre tenants ou uma funcionalidade de admin que “esquece” para quem a requisição pertence. A correção não é um grande recurso de segurança — é um contexto de tenant consistente do primeiro byte da requisição até a última query no banco.
Identificação do tenant (como você sabe “quem”)
A maioria dos produtos SaaS adota um identificador principal e trata o resto como conveniência:
- Subdomínio:
acme.yourapp.comé fácil para usuários e funciona bem com experiências customizadas por tenant. - Header: útil para clientes de API e serviços internos (mas deve ser autenticado).
- Claim no token: um JWT assinado (ou sessão) que inclui
tenant_id, tornando difícil adulterar.
Escolha uma fonte de verdade e registre-a em todos os logs. Se suportar múltiplos sinais (subdomínio + token), defina precedência e rejeite requisições ambíguas.
Escopo da requisição (como toda query permanece no tenant)
Uma boa regra: uma vez que você resolve tenant_id, tudo a jusante deve lê-lo de um único lugar (contexto da requisição), não rederivá-lo.
Guardrails comuns incluem:
- Middleware que anexa
tenant_idao contexto da requisição - Helpers de acesso a dados que exigem
tenant_idcomo parâmetro - Aplicação de enforce no banco (como políticas por linha) para que erros falhem fechados
handleRequest(req):
tenantId = resolveTenant(req) // subdomain/header/token
req.context.tenantId = tenantId
return next(req)
Noções básicas de autorização (papéis dentro de um tenant)
Separe autenticação (quem é o usuário) de autorização (o que ele pode fazer).
Papéis típicos em SaaS são Owner / Admin / Member / Somente leitura, mas o essencial é escopo: um usuário pode ser Admin no Tenant A e Member no Tenant B. Armazene permissões por tenant, não globalmente.
Prevenindo vazamentos entre tenants (testes e guardrails)
Trate acesso cruzado entre tenants como um incidente de alto nível e previna-o proativamente:
- Adicione testes automatizados que tentem ler dados do Tenant B enquanto autenticados como Tenant A
- Torne bugs de filtro ausente mais difíceis de serem enviados (linters, query builders, parâmetros de tenant obrigatórios)
- Registre e alerte padrões suspeitos (ex.: mismatch entre token e subdomínio)
Se quiser um checklist operacional mais profundo, faça link dessas regras nos seus runbooks de engenharia em /security e mantenha-os versionados junto com seu código.
Isolamento Além do Banco de Dados
Configure roteamento por tenant
Teste roteamento por subdomínio ou domínio customizado para tenants sem reconstruir sua stack.
Isolamento de banco é só metade da história. Muitos incidentes reais em multi-tenant acontecem na tubulação compartilhada ao redor da sua app: caches, filas e armazenamento. Essas camadas são rápidas, convenientes e fáceis de, acidentalmente, tornar globais.
Caches compartilhados: prevenir colisão de chaves e vazamentos
Se múltiplos tenants compartilham Redis ou Memcached, a regra principal é simples: nunca armazene chaves agnósticas ao tenant.
Um padrão prático é prefixar cada chave com um identificador estável do tenant (não um domínio de e-mail, não um nome de exibição). Por exemplo: t:{tenant_id}:user:{user_id}. Isso faz duas coisas:
- Previene colisões quando dois tenants têm os mesmos IDs internos
- Torna invalidação em massa factível (deletar por prefixo) durante incidentes de suporte ou migrações
Também decida o que é permitido ser compartilhado globalmente (ex.: feature flags públicas, metadata estática) e documente — globais acidentais são fonte comum de exposição entre tenants.
Limites de taxa e cotas orientadas ao tenant
Mesmo com dados isolados, tenants ainda podem impactar outros via compute compartilhado. Adicione limites orientados ao tenant nas bordas:
- Limites de taxa de API por tenant (e muitas vezes por usuário dentro do tenant)
- Cotas para operações caras (exportações, geração de relatórios, chamadas de IA)
Deixe o limite visível (headers, avisos na UI) para que clientes entendam que throttling é política, não instabilidade.
Jobs em background: particione filas por tenant
Uma fila compartilhada pode permitir que um tenant ocupado domine o tempo dos workers.
Correções comuns:
- Filas separadas por tier/plano (ex.:
free,pro,enterprise) - Filas particionadas por bucket de tenant (hash de tenant_id em N filas)
- Agendamento consciente do tenant para dar fatias justas a cada tenant
Sempre propague o contexto do tenant no payload do job e nos logs para evitar efeitos colaterais em tenant errado.
Armazenamento de arquivos/objetos: caminhos, políticas e chaves separadas
Para armazenamento estilo S3/GCS, isolamento costuma ser baseado em caminho e política:
- Bucket por tenant para separação estrita (fronteiras mais fortes, mais overhead)
- Bucket compartilhado com prefixos por tenant (mais simples, exige IAM e URLs assinadas cuidadosas)
Qualquer que seja a escolha, faça validação de propriedade do tenant em cada requisição de upload/download, não apenas na UI.
Lidando com Vizinhos Barulhentos e Uso Justo de Recursos
Sistemas multi-tenant compartilham infraestrutura, o que significa que um tenant pode, acidentalmente (ou intencionalmente), consumir mais que sua cota justa. Esse é o problema do vizinho barulhento: uma única carga alta degrada performance para todos os outros.
Como “vizinho barulhento” aparece
Imagine um recurso de relatório que exporta um ano de dados para CSV. O Tenant A agenda 20 exportações às 9:00. Essas exportações saturam CPU e I/O do banco, então as telas normais do Tenant B começam a time outar — apesar de B não estar fazendo nada fora do comum.
Controles de recurso: limites, cotas e modelagem de workload
Prevenir isso começa com limites explícitos de recurso:
- Rate limits (requisições por segundo) por tenant e por endpoint, para que APIs caras não sejam spammeadas.
- Cotas (totais diários/mensais) para coisas como exportações, emails, chamadas de IA ou jobs em background.
- Workload shaping: coloque tarefas pesadas (exportações, imports, re-indexing) em filas com limites de concorrência por tenant e regras de prioridade.
Um padrão prático é separar tráfego interativo do trabalho batch: mantenha requisições voltadas ao usuário em uma via rápida e mova o resto para filas controladas.
Circuit breakers e bulkheads por tenant
Adicione válvulas de segurança que disparam quando um tenant cruza um limite:
- Circuit breakers: rejeitam temporariamente ou adiam operações caras quando taxas de erro, latência ou profundidade de fila excedem limites para aquele tenant.
- Bulkheads: isolem pools compartilhados (conexões DB, threads de worker, cache) para que um tenant não exausta a capacidade global.
Feito direito, o Tenant A pode prejudicar apenas sua própria velocidade de exportação sem derrubar o Tenant B.
Quando mover um tenant para capacidade dedicada
Mova um tenant para recursos dedicados quando ele consistentemente exceder as suposições do ambiente compartilhado: throughput alto sustentado, picos imprevisíveis ligados a eventos críticos, necessidades de conformidade estrita ou quando o workload exige tuning customizado. Uma regra simples: se proteger outros tenants exigir throttling permanente de um cliente pagante, é hora de capacidade dedicada (ou um nível superior) em vez de firefighting constante.
Padrões de Escala que Funcionam em SaaS Multi-tenant
Construa e ganhe créditos
Compartilhe o que você construiu com a Koder.ai e ganhe créditos pelo programa de conteúdo.
Escalar multi-tenant é menos sobre “mais servidores” e mais sobre evitar que o crescimento de um tenant surpreenda todo mundo. Os melhores padrões tornam a escala previsível, mensurável e reversível.
Escala horizontal para serviços stateless
Comece tornando a camada web/API stateless: armazene sessões em cache compartilhado (ou use auth baseada em token), mantenha uploads em object storage e mova trabalho de longa duração para jobs em background. Quando requisições não dependem de memória ou disco local, você pode adicionar instâncias atrás de um load balancer e escalar rapidamente.
Uma dica prática: mantenha o contexto do tenant na borda (derivado do subdomínio ou headers) e passe-o para cada handler. Stateless não significa desconhecer o tenant — significa estar ciente do tenant sem servidores sticky.
Hotspots por tenant: identificando e suavizando
A maioria dos problemas de escala é “um tenant é diferente”. Fique atento a hotspots como:
- Um tenant gerando tráfego desproporcional
- Alguns tenants com datasets muito grandes
- Uso em rajadas (relatórios de fim de mês, imports noturnos)
Táticas de suavização incluem limites por tenant, ingestão via filas, cache em caminhos de leitura específicos do tenant e shard de tenants pesados em pools de worker separados.
Réplicas de leitura, particionamento e workloads assíncronos
Use réplicas de leitura para workloads pesados de leitura (dashboards, busca, analytics) e mantenha gravações no primário. Particionamento (por tenant, por tempo ou ambos) ajuda a manter índices menores e consultas mais rápidas. Para tarefas caras — exportações, scoring de ML, webhooks — prefira jobs assíncronos com idempotência para que retries não multipliquem carga.
Sinais de planejamento de capacidade e limiares simples
Mantenha sinais simples e orientados ao tenant: latência p95, taxa de erro, profundidade de fila, CPU do DB e taxa de requisições por tenant. Configure limiares fáceis (ex.: “profundidade de fila > N por 10 minutos” ou “p95 > X ms”) que disparem autoscaling ou caps temporários de tenant — antes que outros tenants sintam o impacto.
Observabilidade e Operações por Tenant
Sistemas multi-tenant não falham globalmente primeiro — normalmente falham para um tenant, um nível de plano ou um workload ruidoso. Se seus logs e dashboards não conseguem responder “qual tenant está afetado?” em segundos, o tempo de on-call vira adivinhação.
Logs, métricas e traces com contexto de tenant
Comece com um contexto de tenant consistente em toda a telemetria:
- Logs: inclua
tenant_id,request_ide umactor_idestável (usuário/serviço) em cada requisição e job em background. - Métricas: emita contadores e histogramas de latência segmentados por tier de tenant no mínimo (ex.:
tier=basic|premium) e por endpoint de alto nível (não URLs brutas). - Traces: propague o contexto do tenant como atributo do trace para filtrar um trace lento por tenant e ver onde o tempo é gasto (DB, cache, chamadas a terceiros).
Mantenha a cardinalidade sob controle: métricas por tenant para todos os tenants podem ficar caras. Um compromisso comum é métricas em nível de tier por padrão e drill-down por tenant sob demanda (ex.: sampling de traces para “top 20 tenants por tráfego” ou “tenants atualmente violando SLO”).
Evitar vazamento de dados sensíveis na telemetria
Telemetria é um canal de exportação de dados. Trate-a como dados de produção.
Prefira IDs em vez de conteúdo: registre customer_id=123 ao invés de nomes, emails, tokens ou payloads de query. Adicione redaction na camada de logger/SDK e blocklist de segredos comuns (Authorization headers, API keys). Para workflows de suporte, armazene payloads de debug em um sistema separado e com controle de acesso — não em logs compartilhados.
SLOs por tier de tenant (sem prometer demais)
Defina SLOs que correspondam ao que você realmente pode impor. Tenants premium podem ter budgets de latência/erro mais apertados, mas só se você também tiver controles (rate limits, isolamento de workload, filas prioritárias). Publique SLOs de tier como metas e monitore por tier e para um conjunto curado de tenants de alto valor.
Runbooks de on-call: incidentes comuns em SaaS multi-tenant
Seus runbooks devem começar com “identifique tenant(s) afetados” e então a ação de isolamento mais rápida:
- Vizinho barulhento: throttle no tenant, pause jobs pesados ou mova para fila de menor prioridade.
- Hotspots de DB/queries runaway: habilite timeouts de query, inspecione top queries por tenant, aplique um índice ou limite o endpoint.
- Bugs de contexto de tenant (mistura de dados): desabilite imediatamente o feature flag ou endpoint e verifique o escopo do tenant nas checagens de acesso.
- Acúmulo de jobs em background: drene filas por tenant, limite concorrência e reexecute com salvaguardas de idempotência.
Operacionalmente, o objetivo é simples: detectar por tenant, conter por tenant e recuperar sem impactar todo mundo.
Deploys, Migrations e Releases por Tenant
Multi-tenant SaaS muda o ritmo de entrega. Você não está apenas deployando “uma app”; está deployando runtime e caminhos de dados compartilhados que muitos clientes dependem ao mesmo tempo. O objetivo é entregar novas features sem forçar um upgrade sincronizado e em big-bang para todos os tenants.
Deploys rolling e migrations de baixa latência
Prefira padrões de deploy que tolerem versões mistas por uma janela curta (blue/green, canary, rolling). Isso só funciona se suas mudanças de banco também forem staged.
Uma regra prática é expandir → migrar → contrair:
- Expandir: adicionar novas colunas/tabelas/índices sem quebrar o código existente.
- Migrar: backfill de dados em lotes (frequentemente por tenant) e verificar.
- Contrair: remover campos antigos somente depois que todas as instâncias da app não dependam mais deles.
Para tabelas quentes, faça backfills incrementalmente (e com throttle), caso contrário você cria seu próprio evento de vizinho barulhento durante uma migração.
Feature flags por tenant para rollouts mais seguros
Feature flags a nível de tenant permitem que você envie código globalmente enquanto habilita comportamento seletivo.
Isso suporta:
- Programas de early access para alguns tenants
- Rollback rápido desabilitando a feature apenas para tenants afetados
- Experimentos A/B sem fork de deploys
Mantenha o sistema de flags auditável: quem habilitou o quê, para qual tenant e quando.
Versionamento e expectativas de compatibilidade retroativa
Assuma que alguns tenants podem ficar defasados em configuração, integrações ou padrões de uso. Desenhe APIs e eventos com versionamento claro para que novos produtores não quebrem consumidores antigos.
Expectativas comuns a definir internamente:
- Novas releases devem ler tanto as formas antigas quanto as novas durante janelas de migração.
- Deprecações exigem um cronograma publicado (mesmo que sejam notas internas + template de email para clientes).
Gestão de configuração específica por tenant
Trate configuração por tenant como superfície de produto: precisa de validação, defaults e histórico de mudanças.
Armazene configuração separada do código (e idealmente separada de segredos em runtime) e ofereça um modo seguro de fallback quando a configuração for inválida. Uma página interna leve como /settings/tenants pode economizar horas durante resposta a incidentes e rollouts graduais.
Como Arquiteturas Geradas por IA Ajudam (e Seus Limites)
Prototipe multitenancy rápido
Gere um esqueleto com React, Go e PostgreSQL para testar o escopo dos tenants desde cedo.
IA pode acelerar o pensamento arquitetural inicial para um SaaS multi-tenant, mas não substitui julgamento de engenharia, testes ou revisão de segurança. Trate-a como um parceiro de brainstorming de alta qualidade que produz rascunhos — depois verifique cada suposição.
O que arquitetura gerada por IA deve (e não deve) fazer
IA é útil para gerar opções e destacar modos típicos de falha (onde o contexto do tenant pode ser perdido ou onde recursos compartilhados podem criar surpresas). Não deve decidir seu modelo, garantir conformidade ou validar performance. Não consegue ver seu tráfego real, a capacidade do seu time ou casos de borda escondidos em integrações legadas.
Entradas que importam: requisitos, restrições, riscos, crescimento
A qualidade da saída depende do que você fornece. Entradas úteis incluem:
- Contagem de tenants hoje vs. 12–24 meses e volume de dados esperado por tenant
- Requisitos de isolamento (contratuais, regulatórios, expectativas do cliente)
- Orçamento e capacidade operacional (maturidade on-call, suporte SRE, tooling)
- Metas de latência, padrões de pico e rajadas por tenant
- Tolerância a risco: o que acontece se um tenant impacta outro?
Usando IA para propor opções de padrões com trade-offs
Peça 2–4 designs candidatos (por exemplo: banco-por-tenant vs esquema-por-tenant vs isolamento por linha) e solicite uma tabela clara de trade-offs: custo, complexidade operacional, raio de impacto, esforço de migração e limites de escala. IA é boa em listar armadilhas que você pode transformar em perguntas de design para seu time.
Se quiser ir de “arquitetura rascunho” a um protótipo funcionando mais rápido, uma plataforma vibe-coding como Koder.ai pode ajudar a transformar essas escolhas num esqueleto real de app via chat — frequentemente com frontend em React e backend em Go + PostgreSQL — para validar propagação de contexto de tenant, rate limits e fluxos de migração mais cedo. Recursos como modo de planejamento e snapshots/rollback são especialmente úteis ao iterar modelos de dados multi-tenant.
Usando IA para gerar modelos de ameaça e itens de checklist
IA pode rascunhar um modelo de ameaça simples: pontos de entrada, fronteiras de confiança, propagação do contexto do tenant e erros comuns (como checagens de autorização faltando em jobs em background). Use isso para gerar checklists de revisão para PRs e runbooks — mas valide com expertise real de segurança e seu histórico de incidentes.
Um Checklist Prático para Seu Time
Escolher uma abordagem multi-tenant é menos sobre “melhor prática” e mais sobre ajuste: sensibilidade dos seus dados, taxa de crescimento e quanto de complexidade operacional vocês conseguem carregar.
Checklist passo a passo (use em um workshop de 30 minutos)
-
Dados: Que dados são compartilhados entre tenants (se houver)? O que nunca deve co-localizar?
-
Identidade: Onde vive a identidade do tenant (links de convite, domínios, claims de SSO)? Como o contexto do tenant é estabelecido em cada requisição?
-
Isolamento: Decida seu nível padrão de isolamento (linha/esquema/banco) e identifique exceções (ex.: clientes enterprise que precisam de separação mais forte).
-
Escala: Identifique a primeira pressão de escala que espera (armazenamento, leitura, jobs em background, analytics) e escolha o padrão mais simples que a resolva.
Perguntas para validar com engenheiros e revisores de segurança
- Como prevenimos acesso cruzado se um desenvolvedor esquecer um filtro?
- Qual é nossa história de auditoria por tenant (quem fez o quê, quando)?
- Como tratamos exclusão e retenção de dados por tenant?
- Qual é o raio de impacto de uma migração ruim ou query runaway?
- Podemos throttlear, limitar e orçar recursos por tenant?
Sinais de alerta que exigem design mais aprofundado
- “Vamos adicionar checagens de tenant depois.”
- Ferramentas administrativas compartilhadas que conseguem ver tudo sem controles estritos.
- Nenhum plano para backup/restore por tenant ou resposta a incidentes.
- Uma única fila/pool de worker sem justiça per-tenant.
Exemplo de resumo “próxima ação recomendada”
Recomendação: Comece com isolamento por linha + aplicação rigorosa de contexto do tenant, adicione throttles por tenant e defina um caminho de upgrade para esquema/banco por tenant para clientes de alto risco.
Próximas ações (2 semanas): modelar ameaças nas fronteiras do tenant, prototipar aplicação de enforcement em um endpoint e ensaiar uma migração em uma cópia de staging. Para orientação de rollout, veja /blog/tenant-release-strategies.