Por que você precisa de jobs em segundo plano (e por que isso vira bagunça rápido)
Qualquer trabalho que possa levar mais de um ou dois segundos não deve rodar dentro de uma requisição do usuário. Enviar emails, gerar relatórios e entregar webhooks dependem de redes, serviços de terceiros ou queries lentas. Às vezes eles pausam, falham ou simplesmente demoram mais do que você espera.
Se você fizer esse trabalho enquanto o usuário espera, as pessoas percebem na hora. Páginas travam, botões "Salvar" ficam girando e requisições estouram timeout. Retries também podem acontecer no lugar errado. O usuário atualiza a página, seu load balancer tenta de novo, ou o frontend reenvia, e você acaba com emails duplicados, chamadas duplicadas de webhook ou duas execuções de relatório competindo entre si.
Jobs em segundo plano resolvem isso mantendo as requisições pequenas e previsíveis: aceite a ação, registre um job para executar depois e responda rápido. O job roda fora da requisição, com regras que você controla.
A parte difícil é a confiabilidade. Depois que o trabalho sai do caminho da requisição, você ainda precisa responder perguntas como:
- E se o provedor de email estiver fora por 3 minutos?
- E se um endpoint de webhook retornar 500 ou der timeout?
- E se o job rodar duas vezes?
- Como você percebe jobs travados antes dos usuários reclamarem?
Muitas equipes respondem adicionando "infraestrutura pesada": um message broker, frotas separadas de workers, dashboards, alertas e playbooks. Essas ferramentas são úteis quando você realmente precisa delas, mas também adicionam novas peças móveis e novos modos de falha.
Um objetivo inicial melhor é mais simples: jobs confiáveis usando partes que você já tem. Para a maioria dos produtos isso significa uma fila baseada em banco de dados mais um pequeno processo worker. Adicione uma estratégia clara de retry e backoff, e um padrão de dead-letter para jobs que continuam falhando. Você obtém comportamento previsível sem se comprometer com uma plataforma complexa no dia um.
Mesmo se você estiver construindo rapidamente com uma ferramenta guiada por chat como Koder.ai, essa separação ainda importa. Usuários devem receber uma resposta rápida agora, e seu sistema deve terminar trabalho lento e sujeito a falhas em segurança no segundo plano.
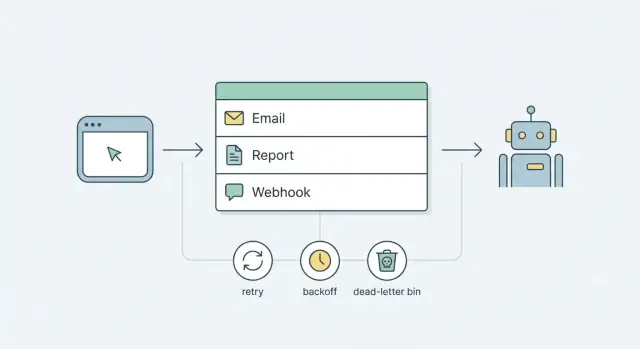
O que é uma fila em termos simples
Uma fila é uma linha de espera para trabalho. Em vez de fazer tarefas lentas ou não confiáveis durante uma requisição do usuário (enviar um email, gerar um relatório, chamar um webhook), você coloca um pequeno registro na fila e retorna rápido. Depois, um processo separado pega esse registro e executa o trabalho.
Algumas palavras que você verá com frequência:
- Job: uma unidade de trabalho, como "enviar email de boas-vindas ao usuário 123".
- Worker: o código que puxa jobs e os executa.
- Attempt: uma tentativa de rodar um job.
- Schedule: quando o job deve rodar (agora ou depois).
- Queue: onde os jobs esperam até que um worker os pegue.
O fluxo mais simples se parece com isto:
-
Enqueue: seu app grava um registro de job (tipo, payload, horário de execução).
-
Claim: um worker encontra o próximo job disponível e o "trava" para que somente um worker o execute.
-
Run: o worker realiza a tarefa (enviar, gerar, entregar).
-
Finish: marque como concluído ou registre uma falha e defina o próximo horário de execução.
Se o volume de jobs for modesto e você já tiver um banco de dados, uma fila respaldada por banco de dados costuma ser suficiente. É fácil de entender, fácil de depurar e atende necessidades comuns como processamento de emails e confiabilidade na entrega de webhooks.
Plataformas de streaming começam a fazer sentido quando você precisa de throughput muito alto, muitos consumidores independentes ou a capacidade de reproduzir enormes históricos de eventos em muitos sistemas. Se você roda dezenas de serviços com milhões de eventos por hora, ferramentas como Kafka ajudam. Até lá, uma tabela no banco mais um loop de worker cobre muitos casos reais.
Os dados mínimos que você deve rastrear por job
Uma fila em banco só se mantém saudável se cada registro de job responder rapidamente a três perguntas: o que fazer, quando tentar de novo e o que aconteceu da última vez. Acerte isso e as operações ficam monótonas (o que é o objetivo).
O que armazenar no payload (e o que não armazenar)
Armazene o menor input necessário para fazer o trabalho, não o output renderizado inteiro. Payloads bons são IDs e alguns parâmetros, como { "user_id": 42, "template": "welcome" }.
Evite armazenar blobs grandes (HTML completo de emails, grandes dados de relatório, corpos enormes de webhook). Isso faz seu banco crescer mais rápido e dificulta a depuração. Se o job precisa de um documento grande, armazene uma referência: report_id, export_id ou uma chave de arquivo. O worker pode buscar os dados completos quando rodar.
Os campos que valem a pena
No mínimo, deixe espaço para:
- job_type + payload:
job_type seleciona o handler (send_email, generate_report, deliver_webhook). payload guarda inputs pequenos como IDs e opções.
- status: mantenha explícito (por exemplo:
queued, running, succeeded, failed, dead).
- rastreio de tentativas:
attempt_count e max_attempts para parar de tentar quando claramente não vai funcionar.
- campos de tempo:
created_at e next_run_at (quando fica elegível). Adicione started_at e finished_at se quiser melhor visibilidade de jobs lentos.
- idempotência + último erro: um
idempotency_key para prevenir efeitos duplos, e last_error para ver por que falhou sem cavar logs.
Idempotência soa chique, mas a ideia é simples: se o mesmo job rodar duas vezes, a segunda execução deve detectar isso e não fazer nada perigoso. Por exemplo, um job de entrega de webhook pode usar uma chave de idempotência como webhook:order:123:event:paid para não entregar o mesmo evento duas vezes se um retry coincidir com um timeout.
Também capture alguns números básicos desde cedo. Você não precisa de um grande dashboard para começar, só consultas que digam: quantos jobs estão enfileirados, quantos estão falhando e a idade do job enfileirado mais antigo.
Passo a passo: uma fila simples em banco que você pode construir hoje
Se já tem um banco de dados, pode começar uma fila em background sem adicionar nova infraestrutura. Jobs são linhas, e um worker é um processo que fica pegando linhas vencidas e executando o trabalho.
1) Crie uma tabela de jobs
Mantenha a tabela pequena e sem frescura. Você quer campos suficientes para rodar, retryar e depurar jobs depois.
CREATE TABLE jobs (
id bigserial PRIMARY KEY,
job_type text NOT NULL,
payload jsonb NOT NULL,
status text NOT NULL DEFAULT 'queued',
attempts int NOT NULL DEFAULT 0,
next_run_at timestamptz NOT NULL DEFAULT now(),
locked_at timestamptz,
locked_by text,
last_error text,
created_at timestamptz NOT NULL DEFAULT now(),
updated_at timestamptz NOT NULL DEFAULT now()
);
CREATE INDEX jobs_due_idx ON jobs (status, next_run_at);
Se você estiver no Postgres (comum em backends Go), jsonb é prático para guardar dados de job como { "user_id":123,"template":"welcome" }.
Quando uma ação do usuário deve disparar um job (enviar email, acionar webhook), grave a linha do job na mesma transação do banco da mudança principal quando possível. Isso evita "usuário criado mas job faltando" se um crash acontecer logo depois da escrita principal.
Exemplo: quando um usuário se inscreve, insira a linha do usuário e um job send_welcome_email em uma transação.
3) Rode um loop de worker que possa escalar
Um worker repete o mesmo ciclo: encontre um job vencido, reque-o para que ninguém mais pegue, processe-o e depois marque como concluído ou agende um retry.
Na prática, isso significa:
- Pegue um job onde
status='queued' e next_run_at <= now().
- Reque-o de forma atômica (no Postgres,
SELECT ... FOR UPDATE SKIP LOCKED é comum).
- Defina
status='running', locked_at=now(), locked_by='worker-1'.
- Processe o job.
- Marque como finalizado (por exemplo
done/succeeded), ou registre last_error e agende a próxima tentativa.
Múltiplos workers podem rodar ao mesmo tempo. O passo de claim é o que evita dupla seleção.
No shutdown, pare de pegar novos jobs, finalize o atual e então saia. Se um processo morrer no meio do job, use uma regra simples: trate jobs em running além de um timeout como elegíveis para re-queue por uma tarefa periódica "reaper".
Se você está construindo no Koder.ai, esse padrão de fila em banco é um padrão sólido para emails, relatórios e webhooks antes de adicionar serviços de fila especializados.
Retries e backoff que não causam caos
Gere um loop de worker em Go
Peça ao Koder.ai para gerar um worker Go com claim seguro de jobs e timeouts.
Retries são como a fila fica calma quando o mundo real está bagunçado. Sem regras claras, retries viram um loop barulhento que spamma usuários, martela APIs e esconde o bug real.
Comece decidindo o que deve retryar e o que deve falhar rápido.
Retry em problemas temporários: timeouts de rede, 502/503, limites de taxa, ou um pico de conexão ao banco.
Falhe rápido quando o job não vai dar certo: um endereço de email faltando, um 400 de webhook porque o payload é inválido, ou um pedido de relatório para uma conta deletada.
Backoff é a pausa entre tentativas. Backoff linear (5s, 10s, 15s) é simples, mas ainda pode criar ondas de tráfego. Backoff exponencial (5s, 10s, 20s, 40s) espalha melhor a carga e costuma ser mais seguro para webhooks e provedores terceiros. Adicione jitter (um pequeno atraso aleatório) para que mil jobs não retryem exatamente no mesmo segundo após uma queda.
Regras que tendem a se comportar bem em produção:
- Retry apenas em erros claramente temporários (timeouts, 429, 5xx).
- Use backoff exponencial com jitter.
- Tople tentativas, então pare e marque o job como falhado.
- Defina timeout por tentativa para que workers não fiquem presos.
- Torne cada job idempotente para que retries não criem duplicados.
Max attempts serve para limitar dano. Para muitas equipes, 5 a 8 tentativas bastam. Depois disso, pare de retryar e estacione o job para revisão (flow dead-letter) em vez de ficar num loop infinito.
Timeouts previnem jobs "zumbis". Emails podem ter timeout de 10 a 20 segundos por tentativa. Webhooks normalmente precisam de limite menor, como 5 a 10 segundos, porque o receptor pode estar fora e você quer seguir em frente. Geração de relatório pode permitir minutos, mas ainda deve ter um corte rígido.
Se estiver construindo isso no Koder.ai, trate should_retry, next_run_at e a chave de idempotência como campos de primeira classe. Esses pequenos detalhes mantêm o sistema silencioso quando algo dá errado.
Dead-letter handling e operações simples
Um estado dead-letter é onde jobs vão quando retries não são mais seguros ou úteis. Transforma falha silenciosa em algo que você pode ver, buscar e agir.
O que salvar em um job dead-letter
Salve o suficiente para entender o que aconteceu e para re-executar o job sem adivinhações, mas tome cuidado com segredos.
Mantenha:
- Os inputs do job (payload) exatamente como usados, mais o tipo e versão do job
- A última mensagem de erro e um stack trace curto (ou um código de erro se não tiver stacks)
- Contagem de tentativas, hora da primeira execução, última execução e próxima execução (se estava agendada)
- Identidade do worker (nome do serviço, host) e um correlation ID para logs
- Um motivo de dead-letter (timeout, erro de validação, 4xx do vendor, etc.)
Se o payload inclui tokens ou dados pessoais, redija ou encripte antes de armazenar.
Um fluxo simples de triagem
Quando um job chega ao dead-letter, tome uma decisão rápida: re-tentar, consertar ou ignorar.
Re-tentar é para outages externos e timeouts. Consertar é para dados ruins (email faltando, URL de webhook errada) ou bug no código. Ignorar deve ser raro, mas pode ser válido quando o job não é mais relevante (por exemplo, o cliente deletou a conta). Se você ignorar, registre um motivo para não parecer que o job sumiu.
Re-enfileirar manualmente é mais seguro quando cria um job novo e mantém o antigo imutável. Marque o job dead-letter com quem re-enfileirou, quando e por quê, então enfileire uma cópia nova com um ID novo.
Para alertas, observe sinais que normalmente significam dor real: contagem de dead-letter subindo rápido, o mesmo erro se repetindo em muitos jobs e jobs antigos enfileirados que não são reivindicados.
Se você usa Koder.ai, snapshots e rollback ajudam quando um release ruim dispara falhas, porque você pode reverter rápido enquanto investiga.
Finalmente, adicione válvulas de segurança para outages de vendors. Limite envios por provedor e use um circuito breaker: se um endpoint de webhook está falhando forte, pause novas tentativas por uma janela curta para não inundar os servidores deles (e os seus).
Padrões para emails, relatórios e webhooks
Adicione visibilidade de dead-letter
Crie um fluxo de dead-letter e uma view administrativa simples para inspecionar e re-enfileirar falhas.
Uma fila funciona melhor quando cada tipo de job tem regras claras: o que conta como sucesso, o que deve retryar e o que nunca deve acontecer duas vezes.
Emails. A maioria das falhas de email é temporária: timeouts do provedor, limites de taxa ou pequenas quedas. Trate essas como retryáveis, com backoff. O risco maior é envios duplicados, então torne jobs de email idempotentes. Guarde uma chave de dedupe estável como user_id + template + event_id e recuse enviar se essa chave já estiver marcada como enviada.
Também vale a pena guardar o nome e versão do template (ou um hash do assunto/corpo renderizado). Se precisar re-executar jobs, você pode escolher reenviar o mesmo conteúdo exato ou regenerar a partir do template mais recente. Se o provedor retornar um message ID, salve-o para que o suporte possa rastrear o que aconteceu.
Relatórios. Relatórios falham de forma diferente. Podem rodar por minutos, bater em limites de paginação ou estourar memória se você processar tudo de uma vez. Divida o trabalho em partes menores. Um padrão comum é: um job "report request" cria muitos jobs de "page" (ou "chunk"), cada um processando uma fatia dos dados.
Armazene resultados para download posterior em vez de manter o usuário esperando. Isso pode ser uma tabela no banco chaveada por report_run_id, ou uma referência de arquivo mais metadados (status, contagem de linhas, created_at). Adicione campos de progresso para que a UI mostre "processando" vs "pronto" sem adivinhar.
Webhooks. Webhooks são sobre confiabilidade de entrega, não velocidade. Assine cada requisição (por exemplo, HMAC com um segredo compartilhado) e inclua um timestamp para impedir replay. Retry apenas quando o receptor pode ter sucesso depois.
Um conjunto simples de regras:
- Retentar em timeouts e respostas 5xx, usando backoff e tentativa máxima.
- Tratar a maioria dos 4xx como falhas permanentes e parar de retryar.
- Registrar o último status code e um corpo de resposta curto para depuração.
- Usar uma chave de idempotência para que receptores possam ignorar duplicados com segurança.
- Limitar tamanho do payload e logar o que você realmente enviou.
Ordenação e prioridade. A maioria dos jobs não precisa de ordenação estrita. Quando a ordem importa, geralmente importa por chave (por usuário, por fatura, por endpoint de webhook). Adicione um group_key e permita apenas um job em voo por chave.
Para prioridade, separe trabalho urgente de trabalho lento. Um backlog de relatórios grande não deve atrasar emails de reset de senha.
Exemplo: após uma compra, você enfileira (1) um email de confirmação do pedido, (2) um webhook para parceiro e (3) um job de atualização de relatório. O email pode retryar rápido, o webhook retrya mais espaçado com backoff e o relatório roda depois em baixa prioridade.
Um exemplo realista: fluxo de cadastro, webhook e relatório noturno
Um usuário se cadastra no seu app. Três coisas devem acontecer, mas nenhuma delas deve atrasar a página de cadastro: enviar um email de boas-vindas, notificar seu CRM com um webhook e incluir o usuário no relatório noturno de atividade.
O que é enfileirado no cadastro
Logo após criar o registro do usuário, grave três linhas de job na sua fila do banco. Cada linha tem um tipo, um payload (como user_id), um status, uma contagem de tentativas e um timestamp next_run_at.
Um ciclo típico de vida se parece com:
queued: criado e aguardando um workerrunning: um worker o reivindicousucceeded: concluído, sem mais trabalhofailed: falhou, agendado para depois ou sem tentativasdead: falhou muitas vezes e precisa de avaliação humana
O job de boas-vindas inclui uma chave de idempotência como welcome_email:user:123. Antes de enviar, o worker verifica uma tabela de chaves de idempotência completadas (ou aplica uma constraint única). Se o job rodar duas vezes por causa de um crash, a segunda execução vê a chave e pula o envio. Sem emails duplicados.
Uma falha e como ela se recupera
Agora o endpoint do CRM está fora. O job de webhook falha com timeout. Seu worker agenda um retry com backoff (por exemplo: 1 minuto, 5 minutos, 30 minutos, 2 horas) mais um pouco de jitter para que muitos jobs não tentem no mesmo segundo.
Após o máximo de tentativas, o job vira dead. O usuário ainda se cadastrou, recebeu o email de boas-vindas e o job de relatório noturno pode rodar normalmente. Só a notificação para o CRM ficou pendurada, e ela é visível.
Na manhã seguinte, o suporte (ou quem estiver de plantão) pode lidar com isso sem cavar logs por horas:
- Filtrar dead jobs por tipo (por exemplo
webhook.crm).
- Ler a última mensagem de erro e confirmar que o payload parece correto.
- Verificar se o CRM voltou.
- Re-enfileirar o job (dead -> queued, reset de attempts) ou desabilitar esse destino temporariamente.
Se você constrói apps em uma plataforma como Koder.ai, o mesmo padrão se aplica: mantenha o fluxo do usuário rápido, empurre efeitos colaterais para jobs e torne falhas fáceis de inspecionar e re-executar.
Erros comuns que tornam filas não confiáveis
Modele tipos de jobs claramente
Crie tipos de job separados para emails, webhooks e relatórios com regras claras por handler.
A forma mais rápida de quebrar uma fila é tratá-la como opcional. Equipes frequentemente começam com "só enviar o email na requisição desta vez" porque parece mais simples. Então isso se espalha: resets de senha, recibos, webhooks, exportações de relatório. Logo o app fica lento, timeouts sobem e qualquer problema de terceiros vira sua indisponibilidade.
Outra armadilha comum é pular a idempotência. Se um job pode rodar duas vezes, ele não deve criar dois resultados. Sem idempotência, retries viram emails duplicados, eventos de webhook repetidos ou pior.
Um terceiro problema é visibilidade. Se você só fica sabendo de falhas pelos tickets de suporte, a fila já está prejudicando usuários. Mesmo uma visão interna básica que mostre contagens de jobs por status mais last_error pesquisável economiza tempo.
Assassinos de confiabilidade para observar
Alguns problemas aparecem cedo, mesmo em filas simples:
- Retentar imediatamente na falha. Se um provedor está fora, retries rápidos criam seu próprio pico de tráfego.
- Misturar jobs lentos com jobs urgentes. Um relatório de 10 minutos pode bloquear uma mensagem de "verifique seu email".
- Tratar erros como temporários para sempre. Jobs que nunca vão ter sucesso continuam ciclando e escondem problemas reais.
- Nenhuma propriedade de versões de payload. Se você muda o formato do job, jobs antigos podem começar a falhar.
- Ignorar rate limits. Filas podem inundar provedores que te limitam.
Backoff previne auto-ddos. Mesmo um escalonamento básico como 1 minuto, 5 minutos, 30 minutos, 2 horas torna falhas mais seguras. Também defina um limite de tentativas para que um job quebrado pare e fique visível.
Se você constrói no Koder.ai, ajuda entregar esses básicos junto com a feature, não semanas depois como um projeto de limpeza.
Checklist rápido e próximos passos
Antes de adicionar mais ferramentas, garanta que o básico esteja sólido. Uma fila baseada em banco funciona bem quando cada job é fácil de reivindicar, fácil de retryar e fácil de inspecionar.
Um checklist rápido de confiabilidade:
- Todo job tem: id, tipo, payload, status, attempts, max_attempts, run_at/next_run_at e last_error.
- Workers reivindicam jobs com segurança (um worker pega um job) e se recuperam após crashes (timeout do lock + reaper).
- Cada job tem um timeout claro para que trabalho preso vire retry em vez de ficar pendurado.
- Retries são limitados e o atraso entre tentativas cresce (backoff) para evitar ondas de retry.
- Existe um estado dead-letter (ou tabela) e uma forma clara de re-executar ou descartar jobs.
Em seguida, escolha seus três primeiros tipos de job e escreva suas regras. Por exemplo: email de reset de senha (retries rápidos, max curto), relatório noturno (poucos retries, timeouts mais longos), entrega de webhook (mais retries, backoff maior, parar em 4xx permanente).
Se tiver dúvidas sobre quando uma fila de banco deixa de ser suficiente, observe sinais como contenção em nível de linha por muitos workers, necessidade de ordenação estrita entre muitos tipos de jobs, fan-out grande (um evento dispara milhares de jobs) ou consumo entre serviços onde equipes diferentes possuem workers.
Se você quer um protótipo rápido, pode esboçar o fluxo no Koder.ai (koder.ai) usando o planning mode, gerar a tabela de jobs e o loop do worker, e iterar com snapshots e rollback antes de fazer o deploy.