O que “Palantir” e “Software Empresarial Tradicional” significam aqui
As pessoas frequentemente usam “Palantir” como atalho para alguns produtos relacionados e uma forma geral de construir operações orientadas a dados. Para manter essa comparação clara, ajuda nomear o que está sendo discutido — e o que não está.
O que “Palantir” refere neste post
Quando alguém diz “Palantir” em um contexto empresarial, normalmente quer dizer um (ou mais) destes:
- Foundry: a plataforma comercial da Palantir, centrada em integrar dados, modelá‑los e permitir tomada de decisão operacional.
- Gotham: frequentemente associada a casos de defesa e setor público, com temas similares, mas história e posicionamento diferentes.
- Apollo: um sistema de entrega e deployment usado para distribuir e gerenciar software em muitos ambientes (incluindo ambientes restritos).
Este post usa “no estilo Palantir” para descrever a combinação de (1) forte integração de dados, (2) uma camada semântica/ontologia que alinha equipes sobre significados e (3) padrões de implantação que podem abranger nuvem, on‑prem e setups desconectados.
O que “software empresarial tradicional” significa aqui
“Software empresarial tradicional” não é um único produto — é a pilha típica que muitas organizações montam ao longo do tempo, como:
- ERP e CRM (sistemas de registro para finanças, cadeia de suprimentos, vendas)
- Um data warehouse ou data lake além de dashboards BI (sistemas para relatórios e análises)
- Middleware de integração (ferramentas ETL/ELT, iPaaS, filas de mensagens, APIs)
Nessa abordagem, integração, análise e operações são frequentemente tratadas por ferramentas e equipes separadas, conectadas através de projetos e processos de governança.
O que esta comparação é (e não é)
Esta é uma comparação de abordagens, não um endosso de fornecedor. Muitas organizações têm sucesso com pilhas convencionais; outras se beneficiam de um modelo de plataforma mais unificada.
A questão prática é: quais trade‑offs você faz em velocidade, controle e em quão diretamente a análise conecta‑se ao trabalho do dia a dia?
Para manter o resto do artigo prático, vamos focar em três áreas:
- Integração de dados: como os dados são conectados, mantidos e de quem são responsabilidade
- Análise operacional: como a análise vai além dos dashboards e entra nas decisões
- Modelos de implantação: nuvem, on‑prem e realidades desconectadas/air‑gapped
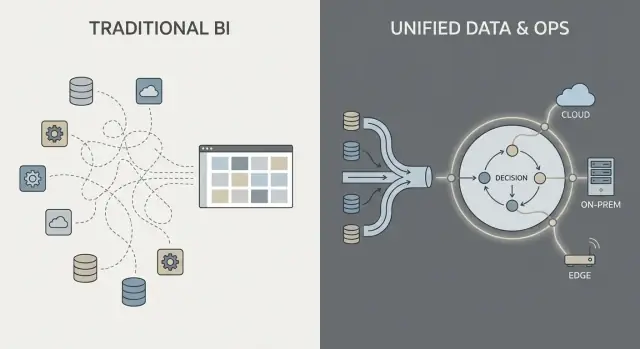
Integração de Dados: Pipelines e Responsabilidades
A maior parte do trabalho de dados em pilhas “tradicionais” segue uma cadeia familiar: puxar dados dos sistemas (ERP, CRM, logs), transformá‑los, carregá‑los em um warehouse ou lake e então construir dashboards BI mais alguns apps downstream.
Esse padrão pode funcionar bem, mas muitas vezes transforma a integração numa série de entregas frágeis: uma equipe é dona dos scripts de extração, outra dos modelos do warehouse, uma terceira das definições de dashboard, enquanto equipes de negócios mantêm planilhas que redefinem silenciosamente “o número real”.
O padrão tradicional: ETL/ELT como uma corrida de revezamento
Com ETL/ELT, mudanças tendem a se propagar. Um novo campo no sistema fonte pode quebrar um pipeline. Um “conserto rápido” cria um segundo pipeline. Logo você tem métricas duplicadas (“receita” em três lugares) e fica pouco claro quem é responsável quando os números não batem.
Processamento em batch é comum aqui: os dados chegam à noite, os dashboards atualizam pela manhã. Near‑real‑time é possível, mas muitas vezes vira uma stack de streaming separada com suas próprias ferramentas e donos.
O padrão no estilo Palantir: integrar, padronizar o significado e reutilizar em todo lugar
Uma abordagem no estilo Palantir visa unificar fontes e aplicar semântica consistente (definições, relacionamentos e regras) mais cedo, para então expor os mesmos dados curados para análises e fluxos operacionais.
Em termos simples: em vez de cada dashboard ou app “descobrir” o que significa um cliente, ativo, caso ou remessa, esse significado é definido uma vez e reaproveitado. Isso pode reduzir lógica duplicada e tornar a propriedade mais clara — porque quando uma definição muda, você sabe onde ela vive e quem a aprova.
Pontos de dor comuns a observar
A integração geralmente falha por responsabilidades, não por conectores:
- Pipelines frágeis que quebram com pequenas mudanças nas fontes
- Métricas duplicadas definidas de formas diferentes entre equipes
- Propriedade pouco clara sobre qualidade de dados, definições e correções
A pergunta chave não é só “conseguimos conectar ao sistema X?” e sim “quem é dono do pipeline, das definições de métrica e do significado de negócio ao longo do tempo?”
Camada Semântica e Ontologia: Um Centro de Gravidade Diferente
O software empresarial tradicional frequentemente trata o “significado” como um detalhe tardio: dados são armazenados em vários esquemas específicos de app, definições de métricas ficam dentro de dashboards individuais, e equipes mantêm suas próprias versões de “o que é um pedido” ou “quando um caso é resolvido”. O resultado é familiar — números diferentes em lugares diferentes, reuniões lentas de reconciliação e propriedade obscura quando algo dá errado.
Numa abordagem semelhante ao Palantir, a camada semântica não é apenas uma conveniência de relatório. Uma ontologia atua como um modelo de negócio compartilhado que define:
- Entidades (coisas que interessam ao negócio): Pedido, Cliente, Ativo, Remessa, Caso
- Relacionamentos (como essas coisas se conectam): um Pedido pertence a um Cliente; uma Remessa cumpre um Pedido; um Ativo está instalado em um Local
- Ações (o que as pessoas fazem com elas): aprovar, despachar, escalar, aposentar, reembolsar
Isso se torna o “centro de gravidade” para análises e operações: múltiplas fontes de dados ainda podem existir, mas elas se mapeiam para um conjunto comum de objetos de negócio com definições consistentes.
Por que semântica importa mais do que esperam
Um modelo compartilhado reduz números desencontrados porque as equipes não reinventam definições em cada relatório ou app. Também melhora responsabilização: se “Entrega no prazo” é definida contra eventos de Remessa na ontologia, fica mais claro quem é dono dos dados subjacentes e da lógica de negócio.
Exemplos práticos para visualizar
- Pedidos: Vendas, finanças e suporte visualizam o mesmo objeto Pedido, incluindo status, valor, aprovações e exceções — sem “tabelas de pedido” separadas por departamento.
- Ativos: Manutenção, operações e conformidade compartilham um único registro de Ativo com localização, histórico de inspeção e flags de risco.
- Casos: Casos de suporte se conectam a clientes, pedidos e remessas, de modo que regras de escalonamento e métricas de serviço não desviem por equipe.
Feita corretamente, uma ontologia não só deixa dashboards mais consistentes — torna decisões do dia a dia mais rápidas e menos contenciosas.
Análise Operacional vs Dashboards de BI
Dashboards de BI e relatórios tradicionais são primariamente sobre retrospectiva e monitoramento. Eles respondem perguntas como “O que aconteceu na semana passada?” ou “Estamos no caminho certo frente aos KPIs?” Um dashboard de vendas, um relatório de fechamento financeiro ou um scorecard executivo é valioso — mas muitas vezes para por aí.
Análise operacional é diferente: é análise embutida nas decisões e na execução do dia a dia. Em vez de um “destino de analytics” separado, a análise aparece dentro do fluxo de trabalho onde o trabalho é realizado e direciona o próximo passo específico.
BI: observar e explicar
BI/reporting normalmente foca em:
- Métricas e definições de KPI padronizadas
- Atualizações agendadas e revisões semanais/mensais
- Visões agregadas (equipes, regiões, períodos)
- Exploração de causa‑raiz após os resultados serem conhecidos
Isso é excelente para governança, gestão de desempenho e responsabilidade.
Análise operacional: decidir e atuar
Análise operacional foca em:
- Sinais em tempo real ou quase em tempo real
- Suporte à decisão no momento da ação
- Recomendações, priorizações e tratamento de exceções
- Ciclos de feedback (a ação funcionou e o que mudou?)
Exemplos concretos são menos “um gráfico” e mais uma fila de trabalho com contexto:
- Despacho: escolher qual equipe enviar para qual serviço dado localização, habilidade, SLA e disponibilidade de peças
- Alocação de inventário: decidir para onde ir com estoque limitado para reduzir backorders e entregas perdidas
- Triagem de fraude: ranqueamento de casos por risco e roteamento para investigadores com evidências anexas
- Agendamento de manutenção: prever falhas e agendar downtime respeitando restrições de produção
A mudança chave: de “ver” para “agir”
A mudança mais importante é que a análise é ligada a um passo específico do fluxo de trabalho. Um dashboard de BI pode mostrar “entregas atrasadas aumentaram.” A análise operacional transforma isso em “aqui estão as 37 remessas em risco hoje, as causas prováveis e as intervenções recomendadas”, com a possibilidade de executar ou atribuir a próxima ação imediatamente.
De Insights para Ações: Design Centrado em Workflows
A análise empresarial tradicional muitas vezes termina em uma visualização: alguém percebe um problema, exporta para CSV, manda por e‑mail e uma equipe separada “faz algo” depois. Uma abordagem no estilo Palantir é desenhada para reduzir essa distância, incorporando a análise diretamente no fluxo de trabalho onde as decisões são tomadas.
Sistemas centrados em workflow tipicamente geram recomendações (ex.: “priorize essas 12 remessas”, “marque esses 3 fornecedores”, “agende manutenção em até 72 horas”) mas ainda requerem aprovações explícitas. Esse passo de aprovação importa porque cria:
- Responsabilidade pela decisão: quem aprovou, quando e com base em quais dados
- Trilhas de auditoria: um registro desde dados de entrada → lógica/modelo → recomendação → ação
- Exceções controladas: operadores podem sobrescrever com uma justificativa, em vez de contornar a ferramenta
Isso é especialmente útil em operações reguladas ou de alto risco onde “o modelo disse” não é justificativa aceitável.
Workflows substituem o “repasse de relatório”
Em vez de tratar a análise como um destino separado, a interface pode encaminhar insights para tarefas: atribuir a uma fila, solicitar assinatura, disparar uma notificação, abrir um caso ou criar uma ordem de serviço. A mudança importante é que os resultados são rastreados dentro do mesmo sistema — assim você pode medir se as ações reduziram risco, custo ou atrasos.
Experiências por função e direitos de decisão
Design centrado em workflow costuma separar experiências por função:
- Operadores de linha de frente: filas rápidas, próxima melhor ação clara, contexto mínimo necessário
- Analistas: drill‑down mais profundo, testes de cenário e monitoramento da qualidade de dados/modelos
- Executivos: KPIs ligados ao throughput operacional e gargalos, não apenas gráficos
O fator comum de sucesso é alinhar o produto com direitos de decisão e procedimentos operacionais: quem pode agir, que aprovações são necessárias e o que significa “concluído” operacionalmente.
Governança, Segurança e Confiança nos Dados
Prototipe um piloto de fluxo de trabalho
Transforme um fluxo operacional em um app funcional a partir de uma conversa por chat.
Governança é onde muitos programas de analytics têm sucesso ou travam. Não é só “configurações de segurança” — é o conjunto prático de regras e evidências que permite às pessoas confiar nos números, compartilhar com segurança e usá‑los para tomar decisões reais.
O que a governança precisa cobrir (além do login)
A maioria das empresas precisa dos mesmos controles centrais, independentemente do fornecedor:
- Controles de acesso: quem pode ver, editar ou aprovar dados, modelos e saídas operacionais
- Linhagem de dados: de onde uma métrica veio, quais fontes a alimentaram e que transformações ocorreram
- Logs de auditoria: um registro defensável de quem mudou o quê e quando
- Aprovações e controle de mudanças: especialmente para métricas “oficiais”, conjuntos de dados compartilhados e workflows de produção
Isso não é burocracia por si só. É como você previne o problema das “duas versões da verdade” e reduz risco quando a análise se aproxima das operações.
“Segurança no dashboard” vs segurança ao longo de toda a cadeia
Implementações tradicionais de BI muitas vezes colocam segurança principalmente na camada de relatório: usuários veem certos dashboards e administradores gerenciam permissões ali. Isso pode funcionar quando a análise é majoritariamente descritiva.
Uma abordagem no estilo Palantir empurra segurança e governança por toda a cadeia: desde a ingestão bruta, passando pela camada semântica (objetos, relacionamentos, definições), até modelos e mesmo as ações disparadas a partir de insights. O objetivo é que uma decisão operacional (como despachar uma equipe, liberar inventário ou priorizar casos) herde os mesmos controles que os dados subjacentes.
Menor privilégio e segregação de funções (em termos simples)
Dois princípios importam para segurança e responsabilidade:
- Menor privilégio: as pessoas recebem apenas o acesso necessário para fazer seu trabalho
- Segregação de funções: quem constrói ou altera a lógica não é a mesma pessoa que a aprova para uso em produção
Por exemplo, um analista pode propor uma definição de métrica, um data steward a aprova, e operações a utiliza — com trilha de auditoria clara.
Por que governança impulsiona adoção
Boa governança não é só para equipes de compliance. Quando usuários de negócio podem clicar na linhagem, ver definições e confiar em permissões consistentes, eles param de discutir planilhas e começam a agir sobre o insight. Essa confiança é o que transforma analytics de “relatórios interessantes” em comportamento operacional.
Modelos de Implantação: Nuvem, On‑Prem e Ambientes Desconectados
Onde o software empresarial roda deixou de ser um detalhe de TI — isso molda o que você pode fazer com dados, quão rápido pode mudar e quais riscos pode aceitar. Compradores geralmente avaliam quatro padrões de implantação.
Nuvem pública
Nuvem pública (AWS/Azure/GCP) otimiza velocidade: provisionamento rápido, serviços gerenciados reduzem trabalho de infraestrutura e escalar é direto. As principais questões para compradores são residência de dados (qual região, backups, acesso de suporte), integração com sistemas on‑prem e se seu modelo de segurança tolera conectividade de rede na nuvem.
Nuvem privada
Uma nuvem privada (single‑tenant ou Kubernetes/VMs gerenciados pelo cliente) é escolhida quando se deseja automação do tipo nuvem mas com limites de rede e requisitos de auditoria mais apertados. Pode reduzir atrito de conformidade, mas ainda exige disciplina operacional forte em patching, monitoramento e revisões de acesso.
On‑prem
Implantações on‑prem continuam comuns em manufatura, energia e setores altamente regulados onde sistemas e dados não podem sair da instalação. O trade‑off é sobrecarga operacional: ciclo de vida de hardware, planejamento de capacidade e mais esforço para manter ambientes consistentes entre dev/test/prod. Se a organização tem dificuldade em rodar plataformas de forma confiável, on‑prem pode retardar o time‑to‑value.
Desconectado / air‑gapped
Ambientes desconectados (air‑gapped) são um caso especial: defesa, infraestrutura crítica ou locais com conectividade limitada. Aqui, o modelo de implantação deve suportar controles estritos de atualização — artefatos assinados, promoção controlada de releases e instalação repetível em redes isoladas.
Restrições de rede também afetam movimentação de dados: em vez de sync contínuo, pode‑se depender de transferências em estágio e fluxos de trabalho de “exportar/importar”.
Os trade‑offs chave
Na prática, é um triângulo: flexibilidade (nuvem), controle (on‑prem/air‑gapped) e velocidade de mudança (automação + updates). A escolha certa depende de regras de residência, realidades de rede e quanto ops de plataforma sua equipe está disposta a assumir.
Operacionalizando Atualizações: O que a Entrega ao Estilo Apollo Muda
UX operacional em React
Crie uma interface web que vá do insight à ação, não apenas gráficos.
“Entrega ao estilo Apollo” é basicamente entrega contínua para ambientes de alto risco: você pode enviar melhorias com frequência (semanal, diária, até múltiplas vezes por dia) mantendo operações estáveis.
O objetivo não é “mover rápido e quebrar coisas.” É “mover com frequência e não quebrar nada.”
Entrega contínua em termos simples
Em vez de agrupar mudanças num grande release trimestral, equipes entregam atualizações pequenas e reversíveis. Cada atualização é mais fácil de testar, explicar e reverter se algo der errado.
Para análise operacional, isso importa porque seu “software” não é apenas uma UI — são pipelines de dados, lógica de negócio e workflows que as pessoas usam. Um processo de atualização mais seguro vira parte das operações diárias.
Como isso difere dos ciclos empresariais tradicionais
Upgrades tradicionais frequentemente parecem projetos: janelas longas de planejamento, coordenação de downtime, preocupações de compatibilidade, retreinamento e uma data de corte rígida. Mesmo quando fornecedores oferecem patches, muitas organizações adiam updates porque risco e esforço são imprevisíveis.
Ferramentas ao estilo Apollo buscam tornar o upgrade rotineiro em vez de excepcional — mais parecido com manutenção de infraestrutura do que com migração grande.
Separando “construir” de “entregar”
Ferramentas modernas de deployment deixam equipes desenvolver e testar em ambientes isolados, e então “promover” a mesma build por estágios (dev → test → staging → produção) com controles consistentes. Essa separação ajuda a reduzir surpresas de última hora causadas por diferenças entre ambientes.
Perguntas que você deve fazer aos fornecedores
- Como tratam rollback — um clique, rollback parcial ou recuperação complexa?
- Que versionamento existe para pipelines, modelos e mudanças na ontologia (não só para a UI)?
- Como funciona promoção de ambiente e quem pode aprovar isso?
- É possível rodar canary releases (um subconjunto primeiro) ou flags de recurso?
- Que trilha de auditoria mostra quem entregou o quê, quando e por quê?
- Qual o tempo de inatividade esperado — idealmente nenhum — para atualizações típicas?
Implementação e Time‑to‑Value: O que Realmente Dá Trabalho
Time‑to‑value é menos sobre quão rápido você instala algo e mais sobre quão rápido as equipes conseguem concordar em definições, conectar dados bagunçados e transformar insights em decisões do dia a dia.
Estilos de implementação: configurar, montar ou construir
Software empresarial tradicional costuma enfatizar configuração: você adota um modelo e workflows predefinidos e mapeia seu negócio neles.
Plataformas no estilo Palantir tendem a misturar três modos:
- Configuração para controles de acesso, conexões de dados e componentes padrão
- Blocos reutilizáveis (templates, componentes, padrões) que podem ser montados em novos casos de uso
- Desenvolvimento de aplicações customizadas quando o fluxo é único (ex.: aprovações, tratamento de exceções, repasses operacionais)
A promessa é flexibilidade — mas isso também significa que você precisa clareza sobre o que está construindo versus o que está padronizando.
Uma opção prática na descoberta inicial é prototipar apps de workflow rapidamente — antes de se comprometer com um grande rollout de plataforma. Por exemplo, equipes às vezes usam Koder.ai (uma plataforma de vibe‑coding) para transformar a descrição de um workflow em um app web funcional via chat, então iteram com stakeholders usando planning mode, snapshots e rollback. Como o Koder.ai suporta exportação de código-fonte e stacks de produção típicas (React na web; Go + PostgreSQL no backend; Flutter para mobile), pode ser uma forma de baixo atrito para validar a UX de “insight → tarefa → trilha de auditoria” durante um proof‑of‑value.
Onde as equipes realmente gastam tempo
A maior parte do esforço costuma ir para quatro áreas:
- Onboarding de dados: conseguir que donos de fonte forneçam acesso, documentar campos, lidar com lacunas de qualidade e definir expectativas de refresh
- Modelagem e semântica: concordar em definições de negócio (o que conta como “ativo”, “atrasado”, “disponível”) e mantê‑las consistentes
- Design de workflows: decidir quem age sobre alertas, que decisões são permitidas e o que significa “concluído”
- Treinamento e adoção: transformar uma ferramenta em hábito — especialmente para a linha de frente que não tolera complexidade
Sinais de alerta que atrasam ou matam valor
Fique atento a propriedade pouco clara (sem um dono de dados/produto responsável), muitas definições bespoke (cada equipe inventa métricas) e sem caminho do piloto para escala (uma demo que não pode ser operacionalizada, suportada ou governada).
Estruturando um piloto que possa escalar
Um bom piloto é intencionalmente estreito: escolha um workflow, defina usuários específicos e comprometa‑se com um resultado mensurável (ex.: reduzir tempo de turnaround em 15%, cortar backlog de exceções em 30%). Projete o piloto de modo que os mesmos dados, semântica e controles possam se estender para o próximo caso — em vez de recomeçar.
Conversas sobre custo podem confundir porque uma “plataforma” agrega capacidades que normalmente são compradas como ferramentas separadas. O importante é mapear preço aos resultados que você precisa (integração + modelagem + governança + apps operacionais), não apenas a uma linha chamada “software”.
A maior parte dos acordos de plataforma é moldada por poucas variáveis:
- Contagem de usuários e papéis: builders (engenheiros, modeladores) vs consumidores (operadores, analistas)
- Computação e armazenamento: workloads pesados (dados em tempo real, simulação, joins grandes) aumentam custo de infraestrutura
- Número de ambientes: dev/test/prod, além de ambientes regulados ou desconectados, cada um adiciona overhead
- Requisitos de suporte e uptime: suporte 24/7, SLAs de incidente e equipes dedicadas de customer success alteram o preço
- Serviços profissionais: onboarding inicial de dados, design de ontologia e construção de workflows costumam ser o principal custo inicial
O que o custo da “pilha tradicional” esconde
Uma abordagem de soluções pontuais pode parecer mais barata no começo, mas o custo total tende a se espalhar por:
- Múltiplas licenças (ETL/ELT, BI, catálogo, governança, workflow, feature store etc.)
- Trabalho de integração entre ferramentas (conectores, identidade, sincronização de metadados)
- Manutenção contínua (upgrades, pipelines quebrados, definições de métricas duplicadas)
Plataformas frequentemente reduzem o sprawl de ferramentas, mas você troca isso por um contrato maior e mais estratégico.
Com uma plataforma, a aquisição deve tratá‑la como infraestrutura compartilhada: defina escopo empresarial, domínios de dados, requisitos de segurança e marcos de entrega. Peça separação clara entre licença, cloud/infra e serviços, para poder comparar propostas de forma justa.
Checklist simples de orçamento
- Quais equipes vão realmente construir vs apenas visualizar?
- Quais workflows devem rodar em produção (não apenas dashboards)?
- Quantos ambientes e regiões são necessários?
- Há sites air‑gapped ou offline?
- Crescimento esperado em volume de dados/frequência de atualização?
- Serviços necessários para os primeiros 90 dias?
Se quiser uma forma rápida de estruturar suposições, veja /pricing.
Quando abordagens no estilo Palantir se encaixam (e quando não)
Mostre, não explique
Hospede seu protótipo e compartilhe com as partes interessadas para obter feedback real.
Plataformas no estilo Palantir tendem a brilhar quando o problema é operacional (pessoas precisam tomar decisões e agir através de sistemas), não só analítico (pessoas precisam de um relatório). O trade‑off é que você está adotando um estilo mais “de plataforma” — poderoso, mas que exige mais da sua organização do que um rollout simples de BI.
Cenários de bom encaixe
Uma abordagem no estilo Palantir geralmente se encaixa bem quando o trabalho atravessa múltiplos sistemas e equipes e você não pode tolerar entregas frágeis.
Exemplos comuns incluem operações cross‑system como coordenação da cadeia de suprimentos, operações de fraude e risco, planejamento de missão, gestão de casos ou workflows de frota e manutenção — onde os mesmos dados devem ser interpretados de forma consistente por funções diferentes.
Também é adequada quando permissões são complexas (acesso por linha/coluna, dados multi‑tenant, regras need‑to‑know) e quando você precisa de uma trilha de auditoria clara de como os dados foram usados. Finalmente, funciona bem em ambientes regulados ou restritos: requisitos on‑prem, implantações air‑gapped/desconectadas ou acreditações de segurança onde o modelo de implantação é requisito principal, não detalhe.
Cenários de menor encaixe
Se o objetivo é principalmente relatórios simples — KPIs semanais, alguns dashboards, rollups financeiros básicos — BI tradicional sobre um warehouse bem gerido pode ser mais rápido e barato.
Também pode ser exagero para conjuntos de dados pequenos, esquemas estáveis ou analytics de departamento único onde uma equipe controla fontes e definições e a principal “ação” ocorre fora da ferramenta.
Critérios de decisão (fit para o problema)
Faça três perguntas práticas:
- Urgência: as equipes precisam de workflows funcionais em semanas, ou isso é um programa longo de modernização?
- Complexidade de dados: decisões-chave estão bloqueadas por definições inconsistentes e sistemas fragmentados?
- Capacidade de mudança: você tem dono de produto, SMEs e banda de governança para adotar uma plataforma e mantê‑la atual?
Os melhores resultados vêm de tratar isso como “encaixe ao problema”, não “uma ferramenta substitui tudo”. Muitas organizações mantêm BI existente para relatórios amplos enquanto usam uma abordagem no estilo Palantir para domínios operacionais de maior risco.
Checklist do Comprador e Próximos Passos
Comprar uma plataforma “no estilo Palantir” vs software empresarial tradicional é menos sobre caixas de recurso e mais sobre onde o trabalho real vai cair: integração, significado compartilhado (semântica) e uso operacional diário. Use o checklist abaixo para forçar clareza cedo, antes de se prender a uma implementação longa ou a uma ferramenta pontual estreita.
Checklist prático de comparação de fornecedores
Peça a cada fornecedor que seja específico sobre quem faz o quê, como isso se mantém consistente e como é usado em operações reais.
- Esforço de integração: quais fontes são típicas (ERP, logs, planilhas, feeds de parceiros)? O que é pré‑construído vs custom? Quem mantém pipelines pós‑go‑live — TI, engenharia de dados ou o fornecedor?
- Consistência semântica: como evitam que cinco equipes definam “cliente”, “ativo” ou “pronto‑para‑missão” de formas diferentes? Eles conseguem mostrar uma camada de negócio governada (ontologia/modelo semântico) e como mudanças propagam?
- Suporte a workflows: equipes de linha de frente conseguem completar uma tarefa (triagem, aprovar, despachar, investigar) dentro do produto, ou é “analisa aqui, age em outro lugar”? Como exceções são tratadas?
- Governança e segurança: controles de acesso granulares, logs de auditoria e gerenciamento de políticas — donos de dados podem controlar quem vê o quê, em que granularidade e por quê?
- Restrições de implantação: roda no ambiente exigido (nuvem, on‑prem, air‑gapped/desconectado)? O que quebra quando a conectividade é limitada? Qual o caminho de upgrade?
Questões de prova para demonstrações (não aceite slides)
- Mostre a linhagem: escolha um KPI crítico e trace‑o da fonte até a métrica final. Onde pode estar errado e como detectariam?
- Demonstre um workflow ponta a ponta: comece em dados brutos, depois alerta → decisão → ação → trilha de auditoria. Inclua aprovações e “quem mudou o quê”.
- Simule uma queda/rollback: o que acontece se um pipeline falha ou um release causa regressão? Consegue reverter limpo e quão rápido?
Quem precisa estar na sala
Inclua stakeholders que vão conviver com os trade‑offs:
- TI e donos de plataforma (propriedade da integração, confiabilidade, custo)
- Segurança e compliance (controles, auditoria, aprovações de implantação)
- Donos de dados/stewards (definições, regras de acesso, responsabilização)
- Líderes de operações (impacto de processo, adoção)
- Usuários de linha de frente (isso realmente os ajuda a trabalhar mais rápido?)
Próximos passos
Execute um proof‑of‑value com tempo limitado centrado em um workflow operacional de alto impacto (não um dashboard genérico). Defina critérios de sucesso antecipadamente: tempo até decisão, redução de erro, auditabilidade e propriedade contínua do trabalho de dados.
Se quiser mais orientação sobre padrões de avaliação, veja /blog. Para ajuda na definição de um proof‑of‑value ou shortlist de fornecedores, entre em contato em /contact.