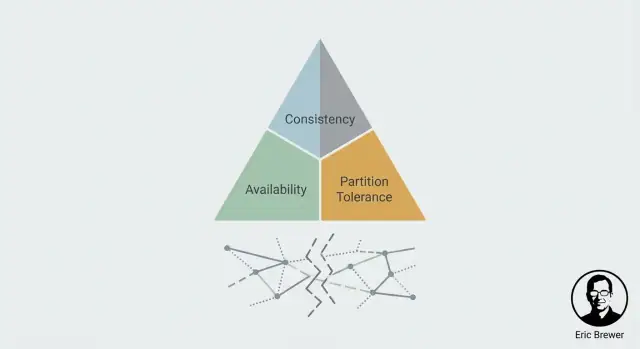
Por que o CAP virou o modelo mental padrão
Quando você armazena os mesmos dados em mais de uma máquina, ganha velocidade e tolerância a falhas — mas também herda um novo problema: desacordo. Dois servidores podem receber atualizações diferentes, mensagens podem chegar atrasadas ou não chegar, e usuários podem ler respostas diferentes dependendo de qual réplica acessam. O CAP ficou popular porque dá aos engenheiros uma maneira clara de falar sobre essa realidade bagunçada sem rodeios.
Eric Brewer, cientista da computação e cofundador da Inktomi, introduziu a ideia central em 2000 como uma afirmação prática sobre sistemas replicados sob falha. Espalhou-se rapidamente porque correspondia ao que equipes já viviam em produção: sistemas distribuídos não apenas falham ao cair; eles falham ao se dividir.
CAP é uma lente de falhas, não uma lista de recursos
CAP é mais útil quando algo dá errado — especialmente quando a rede não se comporta. Em um dia saudável, muitos sistemas podem parecer suficientemente consistentes e disponíveis. O teste de pressão é quando máquinas não conseguem se comunicar de forma confiável e você precisa decidir o que fazer com leituras e gravações enquanto o sistema está dividido.
Esse enquadramento é o motivo pelo qual o CAP virou um modelo mental de referência: ele não debate melhores práticas; força uma pergunta concreta — o que sacrificaremos durante uma divisão?
O que você poderá decidir ao final
Ao final deste artigo, você deverá ser capaz de:
- Reconhecer quando está lidando com um cenário verdadeiro de CAP (replicação + possíveis quebras de comunicação).
- Escolher, de forma intencional, se seu sistema deve priorizar consistência (todos veem a mesma verdade) ou disponibilidade (o sistema continua respondendo) quando réplicas não conseguem concordar.
- Conectar essa escolha ao impacto no produto: o que os usuários experimentam, quais erros aparecem e que correções serão necessárias depois que a partição for resolvida.
O CAP perdura porque transforma o vago "distribuído é difícil" em uma decisão que você pode tomar — e defender.
O cenário: replicação e o problema do desacordo
Um sistema distribuído é, em termos simples, muitos computadores tentando agir como um só. Você pode ter vários servidores em diferentes racks, regiões ou zonas de nuvem, mas para o usuário é “o app” ou “o banco de dados”.
Por que replicamos dados
Para fazer esse sistema compartilhado funcionar em escala do mundo real, normalmente replicamos: mantemos várias cópias dos mesmos dados em máquinas diferentes.
A replicação é popular por três razões práticas:
- Escala: mais máquinas conseguem lidar com mais tráfego.
- Desempenho: usuários podem ser atendidos por uma cópia próxima, reduzindo latência.
- Confiabilidade: se uma máquina morrer, outra cópia pode manter o serviço funcionando.
Até aqui, replicação parece uma vitória óbvia. O porém é que replicação cria um novo trabalho: manter todas as cópias em acordo.
A tensão central: cópias podem discordar
Se cada réplica pudesse sempre falar com todas as outras instantaneamente, poderiam coordenar atualizações e permanecer alinhadas. Mas redes reais não são perfeitas. Mensagens podem ser atrasadas, descartadas ou roteadas contornando falhas.
Quando a comunicação está saudável, réplicas geralmente trocam atualizações e convergem para o mesmo estado. Mas quando a comunicação quebra (mesmo temporariamente), você pode acabar com duas versões válidas da “verdade”.
Por exemplo, um usuário altera seu endereço de entrega. A réplica A recebe a atualização, a réplica B não. Agora o sistema precisa responder uma pergunta aparentemente simples: qual é o endereço atual?
Operação normal vs. operação em falha
Esta é a diferença entre:
- Operação normal: réplicas conseguem coordenar; desacordo é em grande parte uma questão de tempo.
- Operação em falha: algumas réplicas não conseguem se comunicar; o desacordo torna-se inevitável.
O pensamento CAP começa exatamente aqui: uma vez que existe replicação, o desacordo sob falha de comunicação não é um caso extremo — é o problema central de projeto.
CAP em linguagem simples: C, A e P
CAP é um modelo mental para o que os usuários realmente sentem quando um sistema está espalhado por várias máquinas (frequentemente em vários locais). Não descreve sistemas “bons” ou “ruins” — apenas a tensão que você precisa gerenciar.
Consistência (C): eu vejo a escrita mais recente?
Consistência é sobre acordo. Se você atualiza algo, a próxima leitura (de qualquer lugar) refletirá aquela atualização?
Do ponto de vista do usuário, é a diferença entre “acabei de mudar e todo mundo vê o novo valor” versus “algumas pessoas ainda veem o valor antigo por um tempo”.
Disponibilidade (A): eu consigo uma resposta?
Disponibilidade significa que o sistema responde a requisições — leituras e gravações — com um resultado de sucesso. Não é “o mais rápido possível”, mas “não se recusa a te servir”.
Durante problemas (um servidor fora, um pico de rede), um sistema disponível continua aceitando requisições, mesmo que tenha que responder com dados que podem estar um pouco desatualizados.
Tolerância a partições (P): o que acontece quando nós não conseguem falar?
Uma partição é quando a rede se divide: máquinas estão em execução, mas mensagens entre algumas delas não conseguem passar (ou chegam tarde demais para serem úteis). Em sistemas distribuídos, você não pode tratar isso como impossível — deve definir comportamento quando isso ocorrer.
Uma história simples: duas lojas, um inventário
Imagine duas lojas que vendem o mesmo produto e compartilham “1 contagem de inventário”. Um cliente compra o último item na Loja A, então a Loja A grava estoque = 0. Ao mesmo tempo, uma partição de rede impede que a Loja B saiba disso.
Se a Loja B permanecer disponível, pode vender um item que não tem mais (aceitando a venda enquanto particionada). Se a Loja B impor consistência, pode recusar a venda até confirmar o inventário mais recente (negando serviço durante a divisão).
O que realmente são partições (e por que você não pode ignorá-las)
Uma “partição” não é apenas “a internet caiu”. É qualquer situação em que partes do seu sistema não conseguem se comunicar de forma confiável — mesmo que cada parte continue rodando normalmente.
Em um sistema replicado, nós trocam mensagens constantemente: gravações, confirmações, heartbeats, eleições de líder, requisições de leitura. Uma partição é o que acontece quando essas mensagens param de chegar (ou chegam tarde demais), criando desacordo sobre a realidade: “A gravação aconteceu?” “Quem é o líder?” “O nó B está vivo?”
Partições são falhas de comunicação
A comunicação pode falhar de formas confusas e parciais:
- Perda de pacotes que dispara retries e timeouts
- Problemas de roteamento onde o tráfego dá uma volta grande ou some
- Links sobrecarregados (ou NICs saturadas) causando grandes atrasos
- Firewalls / security groups mal configurados bloqueando apenas certas portas ou direções
- Problemas de DNS ou discovery que impedem nós de se encontrarem
O ponto importante: partições costumam ser degradação, não uma queda limpa. Do ponto de vista da aplicação, “lento o suficiente” pode ser indistinguível de “fora do ar”.
Por que partições são inevitáveis em escala
À medida que você adiciona mais máquinas, mais redes, mais regiões e mais partes móveis, há simplesmente mais oportunidades para a comunicação quebrar temporariamente. Mesmo que componentes individuais sejam confiáveis, o sistema como um todo experimenta falhas porque tem mais dependências e mais coordenação entre nós.
Você não precisa assumir uma taxa de falha exata para aceitar a realidade: se seu sistema roda tempo suficiente e abrange bastante infraestrutura, partições vão acontecer.
O que "tolerar partições" significa na prática
Tolerância a partições significa que seu sistema é projetado para continuar operando durante uma divisão — mesmo quando nós não conseguem concordar ou confirmar o que o outro lado viu. Isso força uma escolha: continuar atendendo requisições (arriscando inconsistência) ou parar/rejeitar algumas requisições (preservando consistência).
O momento chave: escolher consistência ou disponibilidade durante uma divisão
Uma vez que você tem replicação, uma partição é simplesmente uma quebra de comunicação: duas partes do seu sistema não conseguem falar de forma confiável por um tempo. Réplicas continuam em execução, usuários continuam clicando e seu serviço continua recebendo requisições — mas as réplicas não conseguem concordar sobre a verdade mais recente.
Essa é a tensão do CAP em uma frase: durante uma partição, você deve escolher priorizar Consistência (C) ou Disponibilidade (A). Você não obtém ambos ao mesmo tempo.
Se você escolhe Consistência (C)
Você está dizendo: 'prefiro estar correto a ser responsivo.' Quando o sistema não consegue confirmar que uma requisição manterá todas as réplicas em sincronia, ela deve falhar ou esperar.
Efeito prático: alguns usuários veem erros, timeouts ou mensagens de 'tente novamente' — especialmente para operações que alteram dados. Isso é comum quando você prefere rejeitar um pagamento do que arriscar cobrar duas vezes, ou bloquear uma reserva de assento do que vender em excesso.
Se você escolhe Disponibilidade (A)
Você está dizendo: 'prefiro responder a bloquear.' Cada lado da partição continuará aceitando requisições, mesmo que não possa coordenar.
Efeito prático: usuários recebem respostas de sucesso, mas os dados que leem podem estar desatualizados, e atualizações concorrentes podem conflitar. Você então depende de reconciliação posterior (regras de merge, last-write-wins, revisão manual etc.).
A escolha pode variar por operação
Isso não é sempre uma configuração global. Muitos produtos misturam estratégias:
- Leituras vs gravações: mantenha leituras disponíveis, mas torne gravações mais estritas.
- Ações críticas vs não críticas: imponha consistência para dinheiro, identidade e inventário; permita disponibilidade para feeds, analytics, 'likes' ou perfis em cache.
O momento chave é decidir — por operação — o que é pior: bloquear um usuário agora ou consertar uma verdade conflituosa depois.
Equívocos comuns: além do slogan 'escolha dois'
Crie fluxos tolerantes a falhas
Gere uma API e UI que suportem modo degradado e mensagens claras para o usuário.
O slogan 'escolha dois' é memorável, mas frequentemente engana as pessoas a pensar que CAP é um cardápio de três recursos onde você só pode manter dois para sempre. CAP trata do que acontece quando a rede para de cooperar: durante uma partição (ou qualquer coisa que pareça com uma), um sistema distribuído deve escolher entre retornar respostas consistentes e permanecer disponível para toda requisição.
Equívoco 1: 'Vou escolher C e A e evitar partições'
Em sistemas distribuídos reais, partições não são uma configuração que você pode desativar. Se seu sistema abrange máquinas, racks, zonas ou regiões, mensagens podem ser atrasadas, descartadas, reordenadas ou roteadas de forma estranha. Isso é uma partição do ponto de vista do software: nós não conseguem concordar sobre o que está acontecendo.
Mesmo que a rede física esteja bem, falhas em outros lugares criam o mesmo efeito — nós sobrecarregados, pausas de GC, vizinhos barulhentos, hiccups de DNS, load balancers instáveis. O resultado é o mesmo: partes do sistema não conseguem falar entre si o suficiente para coordenar.
Equívoco 2: 'Partições são casos raros'
Aplicações não experimentam 'partição' como um evento binário e limpo. Elas experimentam picos de latência e timeouts. Se uma requisição expira após 200 ms, não importa se o pacote chegou aos 201 ms ou nunca chegou: a aplicação precisa decidir o que fazer a seguir. Do ponto de vista da aplicação, comunicação lenta muitas vezes é indistinguível de comunicação quebrada.
Equívoco 3: 'Sistemas são ou CP ou AP'
Muitos sistemas reais são maioritariamente consistentes ou maioritariamente disponíveis, dependendo da configuração e das condições de operação. Timeouts, políticas de retry, tamanhos de quórum e opções como 'read your writes' podem alterar o comportamento.
Em condições normais, um banco de dados pode parecer fortemente consistente; sob estresse ou problemas entre regiões, ele pode começar a falhar requisições (favorecendo consistência) ou retornar dados antigos (favorecendo disponibilidade).
CAP é menos sobre rotular produtos e mais sobre entender o trade-off que você está fazendo quando o desacordo acontece — especialmente quando esse desacordo é causado por lentidão comum.
Opções de consistência que você realmente pode escolher
Discussões sobre CAP frequentemente fazem a consistência parecer binária: ou 'perfeita' ou 'vale tudo'. Sistemas reais oferecem um cardápio de garantias, cada uma com uma experiência diferente quando réplicas discordam ou um link de rede quebra.
Consistência forte (e seu preço durante falha)
Consistência forte (frequentemente 'linearizável') significa que, uma vez que uma gravação é reconhecida, toda leitura posterior — não importa qual réplica seja atingida — retorna essa gravação.
O custo: durante uma partição ou quando uma minoria de réplicas está inacessível, o sistema pode atrasar ou rejeitar leituras/gravações para evitar mostrar estados conflitantes. Usuários notam isso como timeouts, 'tente novamente' ou comportamento temporariamente somente leitura.
Consistência eventual (e o que os usuários podem notar)
Consistência eventual promete que, se não houver novas atualizações, todas as réplicas convergirão. Não promete que dois usuários lendo agora verão a mesma coisa.
O que os usuários podem notar: uma foto de perfil atualizada que 'reverte', contadores que ficam defasados ou uma mensagem enviada que não aparece em outro dispositivo por alguns instantes.
Garantias úteis de meio-termo
Você frequentemente pode obter uma experiência melhor sem exigir consistência forte completa:
- Read-your-writes: depois de atualizar algo, você não lerá uma versão mais antiga dos seus próprios dados.
- Monotonic reads: uma vez que você viu a versão N, não verá depois a versão N-1.
- Consistência causal: se o evento B depende de A (resposta após ler uma mensagem), todos veem A antes de B.
Essas garantias se alinham bem com como as pessoas pensam ('não me mostre minhas próprias mudanças sumindo') e podem ser mais fáceis de manter durante falhas parciais.
Comece com promessas ao usuário, não com jargão:
- Se leituras incorretas causam dano irreversível (transferência de dinheiro, reserva de inventário, mudanças de permissão), incline-se para consistência mais forte e aceite indisponibilidade temporária.
- Se o recurso tolera desacordo de curta duração (curtidas, contagens de visualizações, rank de feed), consistência eventual ou causal costuma ser adequada.
- Se a dor central é confusão pessoal ('salvei — por que não vejo?'), priorize read-your-writes e monotonic reads.
Consistência é uma escolha de produto: defina o que é 'errado' para o usuário e então escolha a garantia mais fraca que previne esse erro.
Disponibilidade como decisão de produto, não apenas número de uptime
Mantenha o código-fonte sob seu controle
Gere, revise e exporte o código-fonte para manter controle total da sua arquitetura.
Disponibilidade no CAP não é um número de exibição ('cinco noves') — é uma promessa que você faz aos usuários sobre o que acontece quando o sistema não pode ter certeza.
Sucesso rápido vs. sucesso preciso
Quando réplicas não conseguem concordar, você frequentemente escolhe entre:
- Sucesso rápido: retornar algo rapidamente (mesmo que possa estar desatualizado).
- Sucesso preciso: retornar apenas quando você pode provar que a resposta está atual.
Os usuários sentem isso como 'o app funciona' versus 'o app está correto'. Nenhum é universalmente melhor; a escolha certa depende do que significa ‘estar errado’ no seu produto. Um feed social levemente desatualizado é irritante. Um saldo bancário desatualizado pode ser danoso.
'Fail closed' vs. 'fail open'
Dois comportamentos comuns aparecem na incerteza:
- Fail closed: rejeitar a requisição (erros, timeouts, modo somente leitura). Você protege a correção, mas usuários podem ficar bloqueados.
- Fail open: servir uma resposta de melhor esforço (cache, réplica local, gravação enfileirada). Você protege o fluxo, mas pode apresentar resultados inconsistentes.
Isso não é puramente técnico; é uma decisão de política. O produto precisa definir o que é aceitável mostrar e o que nunca deve ser chutado.
Disponibilidade parcial ainda é disponibilidade
Disponibilidade raramente é tudo ou nada. Durante uma divisão, você pode ver disponibilidade parcial: algumas regiões, redes ou grupos de usuários têm sucesso enquanto outros falham. Isso pode ser um design deliberado (continuar servindo onde a réplica local está saudável) ou um efeito acidental (desequilíbrios de roteamento, alcance desigual de quóruns).
Modo degradado: manter o essencial, limitar o risco
Um meio-termo prático é o modo degradado: continuar servindo ações seguras enquanto restringe as arriscadas. Por exemplo, permitir navegação e busca, mas desativar temporariamente 'transferir fundos', 'mudar senha' ou outras operações onde correção e unicidade importam.
CAP parece abstrato até você mapear para o que seus usuários experimentam durante uma divisão de rede: prefere que o sistema continue respondendo ou que pare para evitar dados conflitantes?
Inventário e pedidos: risco de oversell vs. quedas no checkout
Imagine dois datacenters aceitando pedidos enquanto não conseguem se comunicar.
Se você mantém o checkout disponível, cada lado pode vender o “último item” e você fará oversell. Isso pode ser aceitável para mercadorias de baixo risco (você faz backorder ou pede desculpas), mas doloroso para lançamentos limitados.
Se optar por consistência primeiro, pode bloquear novos pedidos quando não consegue confirmar o estoque globalmente. Usuários veem 'tente novamente mais tarde', mas você evita vender o que não pode cumprir.
Pagamentos e saldos: padrões de correção (e por quê)
Dinheiro é o domínio clássico onde estar errado é caro. Se duas réplicas aceitarem saques de forma independente durante uma partição, uma conta pode ficar negativa.
Sistemas frequentemente preferem consistência em gravações críticas: recusar ou atrasar ações se não conseguir confirmar o saldo mais recente. Você troca um pouco de disponibilidade (falhas temporárias no pagamento) por correção, auditabilidade e confiança.
Em chat e feeds sociais, usuários geralmente toleram pequenas inconsistências: uma mensagem chega alguns segundos depois, um contador de curtidas está desatualizado, uma métrica aparece mais tarde.
Aqui, projetar para disponibilidade pode ser uma boa escolha de produto, desde que você seja claro sobre quais elementos são 'eventualmente corretos' e consiga mesclar atualizações de forma limpa.
O ponto: seu trade-off é uma decisão de negócio
A escolha certa do CAP depende do custo de estar errado: reembolsos, exposição legal, perda de confiança do usuário ou caos operacional. Decida onde você pode aceitar desfase temporário — e onde precisa falhar fechado.
Padrões de design que implementam seu trade-off
Depois de decidir o que fará durante uma divisão de rede, você precisa de mecanismos que tornem essa decisão real. Esses padrões aparecem em bancos de dados, sistemas de mensagens e APIs — mesmo que o produto nunca mencione 'CAP'.
Quóruns: acordo da maioria
Um quórum é simplesmente 'a maioria das réplicas concorda'. Se você tem 5 cópias, a maioria é 3.
Ao exigir que leituras e/ou gravações contatem uma maioria, você reduz a chance de retornar dados desatualizados ou conflitantes. Por exemplo, se uma gravação precisa ser reconhecida por 3 réplicas, é mais difícil para dois grupos isolados aceitarem verdades diferentes.
O trade-off é velocidade e alcance: se você não consegue atingir a maioria (por causa de partição ou falhas), o sistema pode recusar a operação — escolhendo consistência sobre disponibilidade.
Timeouts, retries e backoff moldam a disponibilidade percebida
Muitos problemas de 'disponibilidade' não são falhas definitivas, mas respostas lentas. Definir um timeout curto pode fazer o sistema parecer ágil, mas também aumenta a chance de tratar sucessos lentos como falhas.
Retries podem recuperar blips transitórios, mas retries agressivos podem sobrecarregar um serviço já em sofrimento. Backoff (esperar mais entre tentativas) e jitter (aleatoriedade) ajudam a evitar que retries virem um pico de tráfego.
A chave é alinhar essas configurações com sua promessa: 'sempre responder' geralmente significa mais retries e fallbacks; 'nunca mentir' geralmente significa limites mais rígidos e erros claros.
Tratamento de conflitos quando você permite divergência
Se você optar por permanecer disponível durante partições, réplicas podem aceitar atualizações diferentes e você precisa reconciliar depois. Abordagens comuns incluem:
- Last-write-wins (LWW): escolhe a atualização com timestamp mais recente. Simples, mas pode descartar mudanças válidas se relógios divergirem.
- Vetores de versão (em alto nível): anexam um pequeno 'histórico' que ajuda a detectar se atualizações são concorrentes ou uma substitui a outra.
- Regras de merge: definir como combinar mudanças (ex.: união de itens de carrinho; contadores somam; perfis preferem campos não vazios). Funciona melhor quando pensado no modelo de dados.
Idempotência: tornar retries seguros
Retries podem criar duplicações: cobrar um cartão duas vezes ou submeter um pedido duplicado. Idempotência previne isso.
Um padrão comum é a chave de idempotência (request ID) enviada com cada requisição. O servidor armazena o primeiro resultado e retorna o mesmo resultado para repetições — assim retries melhoram disponibilidade sem corromper dados.
Como validar suposições CAP na vida real
Torne reenvios seguros
Adicione chaves de idempotência e handlers seguros contra reenvios para evitar efeitos duplicados sob timeouts.
A maioria das equipes 'escolhe' uma postura CAP em um quadro branco — e descobre em produção que o sistema se comporta diferente sob estresse. Validar significa criar intencionalmente as condições onde os trade-offs do CAP ficam visíveis e checar se seu sistema reage como projetado.
Você não precisa de um corte de cabo real para aprender algo. Use injeção de falhas controlada em staging (e com cuidado em produção) para simular partições:
- Blackhole de tráfego entre serviços ou nós específicos (descartar pacotes sem fechar conexões) para imitar uma divisão silenciosa.
- Egozar links bloqueando portas ou regras de security group entre réplicas/regiões.
- Adicionar latência extrema e perda de pacotes para que timeouts e retries se comportem como em uma partição.
- Forçar isolamento de líder (por exemplo, isolar o primário do quórum) para ver se você falha 'consistente' ou 'disponível'.
O objetivo é responder perguntas concretas: gravações são rejeitadas ou aceitas? leituras retornam dados antigos? o sistema se recupera automaticamente e quanto tempo leva a reconciliação?
Se quiser validar esses comportamentos cedo (antes de investir semanas integrando serviços), pode ajudar montar um protótipo realista rapidamente. Por exemplo, equipes muitas vezes começam gerando um serviço pequeno (comummente um backend em Go com PostgreSQL e uma UI React) e então iteram sobre retries, chaves de idempotência e fluxos de 'modo degradado' em um ambiente sandbox.
Monitorar sinais que revelam dor CAP
Checks tradicionais de uptime não capturam comportamento 'disponível mas errado'. Monitore:
- Taxas de erro por tipo de operação (leitura vs escrita vs atualização condicional)
- Indicadores de leitura desatualizada (violação de read-your-writes, mismatches de versão/ETag, métricas de lag)
- Divergência de réplicas (lag de replicação, contagens de falha ao aplicar, taxas de conflito)
- Timeouts/retries (frequentemente o primeiro sinal de uma partição emergente)
Operadores precisam de ações pré-definidas quando uma partição ocorre: quando congelar gravações, quando fazer failover, quando degradar funcionalidades e como validar a segurança da re-mesclagem.
Também planeje o comportamento exposto ao usuário. Se você escolher consistência, a mensagem pode ser 'Não conseguimos confirmar sua atualização — por favor tente novamente.' Se escolher disponibilidade, seja explícito: 'Sua atualização pode demorar alguns minutos para aparecer em todos os lugares.' Redigir isso claramente reduz carga de suporte e preserva confiança.
Checklist prático CAP para decisões do dia a dia
Quando estiver tomando uma decisão de sistema, o CAP é mais útil como uma auditoria rápida do 'o que quebra durante uma divisão?' — não um debate teórico. Use este checklist antes de escolher um recurso de banco de dados, estratégia de cache ou modo de replicação.
1) Um checklist curto CAP
Pergunte nesta ordem:
- O que deve estar correto? (ex.: 'um saldo bancário nunca pode ficar negativo', 'inventário não pode vender em excesso', 'permissões devem estar corretas')
- O que deve permanecer disponível? (ex.: endpoint de checkout, login, catálogo somente leitura)
- O que pode degradar temporariamente? (ex.: analytics, recomendações, avatares de perfil, 'última vez visto')
Se uma partição ocorrer, você estará decidindo quais desses proteger primeiro.
2) Decida por tipo de dado e por endpoint
Evite uma configuração global única como 'somos um sistema AP'. Em vez disso, decida por:
- Tipo de dado: dinheiro vs curtidas vs logs
- Endpoint: 'fazer pedido' vs 'ver pedido' vs 'rastrear entrega'
Exemplo: durante uma partição, você pode bloquear gravações em payments (prefere consistência) mas manter leituras de product_catalog disponíveis com cache.
3) Defina 'inconsistência aceitável' em termos concretos
Escreva o que você tolera, com exemplos:
- Limite de tempo: 'contagens podem estar 5–10 minutos atrasadas'
- Magnitude: 'inventário pode estar fora por ±1 em itens de baixa demanda'
- Por campo: 'prazo de entrega pode estar desatualizado; total do pedido não pode'
- Texto visível: 'mostrar "pendente" em vez de um status definitivo'
Se você não consegue descrever a inconsistência em exemplos simples, será difícil testar e explicar incidentes.
4) Conclusões + o que ler a seguir
- Partições transformam garantias "agradáveis de ter" em escolhas forçadas.
- Faça essas escolhas explícitas por endpoint e documente a inconsistência aceitável.
Próximos temas que combinam bem com este checklist: consenso (/blog/consensus-vs-cap), modelos de consistência (/blog/consistency-models-explained) e SLOs/orçamentos de erro (/blog/sre-slos-error-budgets).