15 de jun. de 2025·8 min
Permitir que a IA projete esquemas, APIs e modelos de dados de backend
Explore como esquemas e APIs gerados por IA aceleram a entrega, onde falham e um fluxo prático para revisar, testar e governar o design de backend.
Explore como esquemas e APIs gerados por IA aceleram a entrega, onde falham e um fluxo prático para revisar, testar e governar o design de backend.
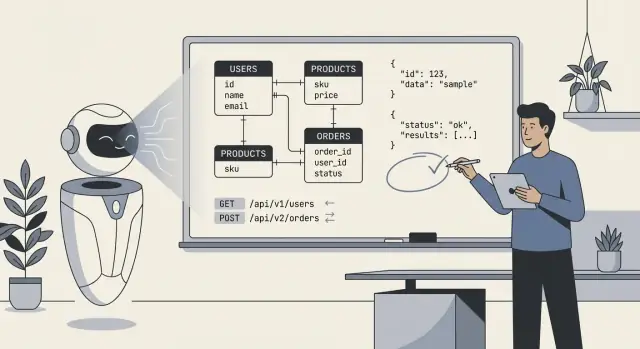
Quando as pessoas dizem “a IA projetou nosso backend”, geralmente querem dizer que o modelo produziu um rascunho inicial do blueprint técnico: tabelas do banco de dados (ou collections), como essas peças se relacionam e as APIs que leem e gravam dados. Na prática, é menos “a IA construiu tudo” e mais “a IA propôs uma estrutura que podemos implementar e refinar”.
No mínimo, a IA pode gerar:
users, orders, subscriptions, além de campos e tipos básicos.A IA pode inferir padrões “típicos”, mas não consegue escolher de forma confiável o modelo correto quando os requisitos são ambíguos ou específicos do domínio. Ela não saberá suas políticas reais sobre:
cancelled vs refunded vs voided).Trate a saída da IA como um ponto de partida rápido e estruturado—útil para explorar opções e detectar omissões—mas não como uma especificação pronta para envio sem revisão. Seu trabalho é fornecer regras claras e casos de borda, então revisar a produção da IA do mesmo jeito que você revisaria o rascunho de um engenheiro júnior: útil, às vezes impressionante, ocasionalmente errado em detalhes sutis.
A IA pode rascunhar um esquema ou API rapidamente, mas não pode inventar os fatos ausentes que fazem um backend “encaixar” ao seu produto. Os melhores resultados acontecem quando você trata a IA como um designer júnior rápido: você fornece restrições claras e ela propõe opções.
Antes de pedir tabelas, endpoints ou modelos, escreva o essencial:
Quando os requisitos são vagos, a IA tende a “adivinhar” padrões: campos opcionais em todo lugar, colunas de status genéricas, propriedade pouco clara e nomes inconsistentes. Isso geralmente leva a esquemas que parecem razoáveis, mas quebram com uso real—especialmente em permissões, relatórios e casos de borda (reembolsos, cancelamentos, envios parciais, aprovações em múltiplas etapas). Você paga por isso depois com migrações, soluções alternativas e APIs confusas.
Use isto como ponto de partida e cole no seu prompt:
Product summary (2–3 sentences):
Entities (name → definition):
-
Workflows (steps + states):
-
Roles & permissions:
- Role:
- Can:
- Cannot:
Reporting questions we must answer:
-
Integrations (system → data we store):
-
Constraints:
- Compliance/retention:
- Expected scale:
- Latency/availability:
Non-goals (what we won’t support yet):
-
A IA é melhor quando você a trata como uma máquina de rascunhos rápida: ela consegue esboçar um modelo de dados de primeira passagem e um conjunto correspondente de endpoints em minutos. Essa velocidade muda sua forma de trabalhar—não porque a saída seja magicamente “correta”, mas porque você pode iterar em algo concreto imediatamente.
O maior ganho é eliminar o ponto de partida vazio. Dê à IA uma descrição curta de entidades, fluxos-chave e restrições, e ela pode propor tabelas/collections, relacionamentos e uma superfície de API base. Isso é especialmente valioso quando você precisa de uma demo rápida ou está explorando requisitos instáveis.
A velocidade compensa mais em:
Humanos cansam e se desviam. A IA não—por isso é ótima em repetir convenções por todo o backend:
createdAt, updatedAt, customerId)/resources, /resources/:id) e payloadsEssa consistência facilita documentação, testes e passagem de projeto.
A IA também é boa em completude. Se você pedir um conjunto CRUD mais operações comuns (search, list, bulk updates), ela frequentemente gera uma superfície inicial mais abrangente do que um rascunho humano apressado.
Um ganho rápido comum é erros padronizados: um envelope uniforme de erro (code, message, details) em todos os endpoints. Mesmo que você refine depois, ter uma forma única desde o início evita uma mistura de respostas ad-hoc.
A mentalidade chave: deixe a IA produzir os primeiros 80% rapidamente e passe seu tempo nos 20% que exigem julgamento—regras de negócio, casos de borda e o “porquê” por trás do modelo.
Esquemas gerados por IA costumam parecer “limpos” à primeira vista: tabelas organizadas, nomes sensatos e relacionamentos que combinam com o caminho feliz. Os problemas aparecem quando dados reais, usuários reais e fluxos reais atingem o sistema.
A IA pode oscilar entre extremos:
Um teste rápido: se suas páginas mais comuns precisam de 6+ joins, você pode estar sobre-normalizado; se atualizações exigem mudar o mesmo valor em muitas linhas, pode estar sub-normalizado.
A IA frequentemente omite requisitos “chatos” que direcionam o design real do backend:
tenant_id nas tabelas, ou não aplicar scoping de tenant em constraints únicas.deleted_at mas não ajustar regras de unicidade ou padrões de consulta para excluir registros deletados.created_by/updated_by, histórico de mudanças ou logs imutáveis de eventos.date e timestamp sem regra clara (armazenar em UTC vs exibir local), levando a bugs de deslocamento de dia.A IA pode supor:
invoice_number),Esses erros geralmente surgem como migrações estranhas e soluções no lado da aplicação.
A maioria dos esquemas gerados não reflete como você vai consultar:
tenant_id + created_at),Se o modelo não descreve as 5 principais consultas do seu app, não pode projetar o esquema corretamente para elas.
A IA costuma ser surpreendentemente boa em produzir uma API que “parece padrão”. Ela replica padrões familiares de frameworks e APIs públicas, o que pode economizar tempo. O risco é que otimize pelo que parece plausível em vez do que é correto para seu produto, dados e mudanças futuras.
Noções básicas de modelagem de recurso. Dado um domínio claro, a IA tende a escolher substantivos e estruturas de URL sensatas (ex.: /customers, /orders/{id}, /orders/{id}/items). Também é boa em repetir convenções de nomeação entre endpoints.
Scaffolding de endpoints comuns. Frequentemente inclui o essencial: list vs detail, create/update/delete e formatos previsíveis de request/response.
Convenções básicas. Se você pedir explicitamente, ela pode padronizar paginação, filtragem e ordenação. Ex.: ?limit=50&cursor=... (cursor pagination) ou ?page=2&pageSize=25 (page-based), além de ?sort=-createdAt e filtros como ?status=active.
Abstrações que vazam. Um erro clássico é expor tabelas internas diretamente como “recursos”, especialmente quando o esquema tem tabelas de join, campos denormalizados ou colunas de auditoria. O resultado são endpoints como /user_role_assignments que refletem detalhe de implementação em vez do conceito voltado ao usuário. Isso torna a API mais difícil de usar e de evoluir.
Tratamento inconsistente de erros. A IA pode misturar estilos: às vezes retornar 200 com corpo de erro, às vezes usar códigos 4xx/5xx. Você quer um contrato claro:
400, 401, 403, 404, 409, 422){ "error": { "code": "...", "message": "...", "details": [...] } })Versionamento deixado para depois. Muitos designs gerados pulam a estratégia de versionamento até que vire problema. Decida desde o dia um se usará versionamento no path (/v1/...) ou via header, e defina o que caracteriza uma quebra. Mesmo que nunca atualize, ter as regras evita rupturas acidentais.
Use IA para velocidade e consistência, mas trate o design de API como uma interface de produto. Se um endpoint espelha seu banco de dados em vez do modelo mental do usuário, é sinal de que a IA otimizou pela geração fácil—não pela usabilidade a longo prazo.
Trate a IA como um designer júnior rápido: ótima gerando rascunhos, não responsável pelo sistema final. O objetivo é usar a velocidade dela mantendo sua arquitetura intencional, revisável e testada.
Se estiver usando uma ferramenta vibe-coding como Koder.ai, essa separação de responsabilidades fica ainda mais importante: a plataforma pode rascunhar e implementar rapidamente um backend (por exemplo, serviços Go com PostgreSQL), mas você ainda precisa definir invariantes, limites de autorização e regras de migração que aceita viver.
Comece com um prompt conciso que descreva domínio, restrições e “o que é sucesso”. Peça primeiro um modelo conceitual (entidades, relacionamentos, invariantes), não tabelas.
Depois itere num loop fixo:
Esse loop funciona porque transforma sugestões da IA em artefatos que podem ser provados ou rejeitados.
Mantenha três camadas distintas:
Peça à IA que entregue essas seções separadas. Quando algo mudar (ex.: um novo status), atualize primeiro a camada conceitual e depois reconcile esquema e API. Isso reduz acoplamento acidental e torna refactors menos dolorosos.
Cada iteração deve deixar rastros. Use resumos tipo ADR (uma página ou menos) que capturem:
deleted_at”).Quando colar feedback de volta na IA, inclua as notas relevantes verbatim. Isso evita que o modelo “esqueça” escolhas anteriores e ajuda sua equipe no futuro.
A IA é mais fácil de guiar quando você trata o prompt como um exercício de escrita de especificação: defina o domínio, declare restrições e insista em entregáveis concretos (DDL, tabela de endpoints, exemplos). O objetivo não é “ser criativo”—é “ser preciso”.
Peça modelo de dados e regras que o mantenham consistente.
Se você já tem convenções, declare: estilo de nomeação, tipo de ID (UUID vs bigint), política de nullability e expectativas de indexação.
Solicite uma tabela de API com contratos explícitos, não apenas uma lista de rotas.
Acrescente comportamento de negócio: estilo de paginação, campos de ordenação e como funcionam os filtros.
Faça o modelo pensar em releases.
billing_address ao Customer. Forneça um plano de migração seguro: SQL de migração forward, passos de backfill, rollout com feature-flag e estratégia de rollback. A API deve permanecer compatível por 30 dias; clientes antigos podem omitir o campo.”Prompts vagos produzem sistemas vagos.
Quando quiser saída melhor, aperte o prompt: especifique regras, casos de borda e o formato do entregável.
A IA pode rascunhar um backend decente, mas enviá‑lo com segurança ainda demanda uma checagem humana. Trate este checklist como um “gate de release”: se você não souber responder um item com confiança, pause e corrija antes que dane dados de produção.
(tenant_id, slug))._id, timestamps) e aplique uniformemente.Confirme as regras do sistema por escrito:
Antes do merge, rode uma revisão “caminho feliz + pior caminho”: uma requisição normal, uma inválida, uma não autorizada e um cenário de alto volume. Se o comportamento da API surpreende você, vai surpreender também seus usuários.
A IA pode gerar um esquema e superfície de API plausíveis rapidamente, mas não pode provar que o backend se comporta corretamente sob tráfego real, dados reais e mudanças futuras. Trate a saída da IA como rascunho e fixe‑a com testes que travem comportamento.
Comece com testes de contrato que validem requests, responses e semântica de erro—não só caminhos felizes. Faça uma pequena suíte rodando contra uma instância real (ou container) do serviço.
Foque em:
Se publicar um OpenAPI, gere testes a partir dele—mas adicione casos escritos à mão para partes que o spec não expressa (regras de autorização, constraints de negócio).
Esquemas gerados frequentemente esquecem detalhes operacionais: defaults seguros, backfills e reversibilidade. Adicione testes de migração que:
Mantenha um plano de rollback scriptado para produção: o que fazer se uma migração for lenta, travar tabelas ou quebrar compatibilidade.
Não faça benchmark de endpoints genéricos. Capture padrões representativos (views de listagem principais, buscas, joins, agregações) e teste carga nesses.
Meça:
É aqui que designs de IA costumam falhar: tabelas “razoáveis” que geram joins caros sob carga.
Adicione verificações automatizadas para:
Mesmo testes básicos de segurança previnem a classe mais custosa de erros da IA: endpoints que funcionam, mas expõem demais.
A IA pode rascunhar um bom esquema “versão 0”, mas seu backend viverá até a versão 50. A diferença entre um backend que envelhece bem e outro que desaba sob mudanças é como você o evolui: migrações, refactors controlados e documentação clara de intenções.
Trate cada mudança de esquema como uma migração, mesmo que a IA sugira “basta alterar a tabela”. Use passos explícitos e reversíveis: adicione colunas novas primeiro, faça backfill, então aplique constraints. Prefira mudanças aditivas (novos campos/tabelas) sobre destrutivas (rename/drop) até provar que nada depende da forma antiga.
Quando pedir à IA atualizações de esquema, inclua o esquema atual e as regras de migração que você segue (ex.: “não dropar colunas; usar expand/contract”). Isso reduz chances de ela propor mudanças corretas em teoria mas arriscadas em produção.
Mudanças quebradoras raramente são um único instante; são uma transição.
A IA ajuda a gerar o plano passo a passo (incluindo trechos SQL e ordem de rollout), mas você deve validar impacto em runtime: locks, transações longas e se o backfill é resiliente.
Refactors devem isolar mudanças. Se precisar normalizar, dividir uma tabela ou introduzir um log de eventos, mantenha camadas de compatibilidade: views, código de tradução ou tabelas “shadow”. Peça à IA um refactor que preserve contratos de API existentes e liste o que precisa mudar em queries, índices e constraints.
A maior causa de drift a longo prazo é o próximo prompt esquecer a intenção original. Mantenha um “contrato de modelo de dados” curto: regras de nomeação, estratégia de IDs, semântica de timestamps, política de soft-delete e invariantes (“order total é derivado, não armazenado”). Linke nos docs internos (ex.: /docs/data-model) e reutilize no futuro para que a IA projete dentro dos mesmos limites.
A IA pode rascunhar tabelas e endpoints rapidamente, mas ela não “possui” seu risco. Trate segurança e privacidade como requisitos de primeira classe que você adiciona ao prompt e verifica na revisão—especialmente para dados sensíveis.
Antes de aceitar qualquer esquema, rotule campos por sensibilidade (público, interno, confidencial, regulado). Essa classificação deve guiar o que é criptografado, mascarado ou minimizado.
Por exemplo: senhas nunca devem ser armazenadas em texto (somente hashes com salt), tokens devem ser de curta duração e criptografados em repouso, e PII como email/telefone pode precisar de mascaramento em views administrativas e exports. Se um campo não é necessário para valor de produto, não o armazene—IA frequentemente adiciona atributos “legais de ter” que aumentam exposição.
APIs geradas tendem a usar checagens simples por “papel”. RBAC é fácil, mas falha com regras de propriedade (“usuários só veem suas invoices”) ou regras de contexto (“suporte vê dados só durante ticket ativo”). ABAC lida melhor com isso, mas exige políticas explícitas.
Seja claro sobre o padrão usado e garanta que cada endpoint o aplique consistentemente—especialmente list/search, que são pontos comuns de vazamento.
Código gerado pode logar corpos inteiros de requisição, headers ou linhas do DB durante erros. Isso pode vazar senhas, tokens e PII em logs e ferramentas APM.
Defina defaults: logs estruturados, allowlist de campos para log, redigir segredos (Authorization, cookies, reset tokens) e evitar logar payloads crus em falhas de validação.
Projete exclusão desde o dia um: deletes iniciados pelo usuário, encerramento de conta e fluxos de “direito ao esquecimento”. Defina janelas de retenção por classe de dado (ex.: eventos de auditoria vs eventos de marketing) e garanta que você pode provar o que foi excluído e quando.
Se manter logs de auditoria, guarde identificadores mínimos, proteja com acesso restrito e documente como exportar ou excluir dados quando solicitado.
A IA brilha quando você a trata como um arquiteto júnior rápido: ótima em rascunhos, fraca em tradeoffs críticos de domínio. A questão certa não é “a IA pode projetar meu backend?” e sim “quais partes a IA pode rascunhar com segurança, e quais precisam de propriedade especializada?”.
A IA economiza tempo quando você constrói:
Aqui, a IA agrega velocidade, consistência e cobertura—especialmente quando você já sabe o comportamento desejado e consegue detectar erros.
Tenha cautela (ou use a IA apenas como inspiração) em:
Nessas áreas, expertise de domínio vale mais que velocidade da IA. Requisitos sutis—legais, clínicos, contábeis, operacionais—frequentemente não estão no prompt, e a IA preencherá lacunas com confiança.
Uma regra prática: deixe a IA propor opções, mas obrigue revisão final sobre invariantes do modelo, limites de autorização e estratégia de migração. Se você não pode nomear quem é responsável pelo esquema e contratos de API, não entregue um backend projetado só pela IA.
Se está avaliando fluxos e guardrails, veja guias relacionados em /blog. Se quiser ajuda aplicando essas práticas ao processo da sua equipe, confira /pricing.
Se prefere um fluxo end-to-end onde pode iterar via chat, gerar um app funcional e ainda manter controle via exportação de código e snapshots com rollback, Koder.ai foi pensado para esse estilo de build-and-review.
Geralmente significa que o modelo gerou um primeiro rascunho de:
Uma equipe humana ainda precisa validar regras de negócio, limites de segurança, desempenho das consultas e segurança das migrações antes de enviar para produção.
Forneça entradas concretas que a IA não pode adivinhar com segurança:
Quanto mais claras as restrições, menos a IA "preencherá lacunas" com padrões frágeis.
Comece por um modelo conceitual (conceitos de negócio + invariantes), depois derive:
Manter essas camadas separadas facilita mudar o armazenamento sem quebrar a API — ou revisar a API sem corromper regras de negócio.
Problemas comuns incluem:
tenant_id e constraints únicas compostas)deleted_at)Peça à IA para projetar em torno das suas principais consultas e então verifique:
tenant_id + created_at)Se você não consegue listar as 5 principais consultas/endpoints, trate qualquer plano de indexação como incompleto.
A IA é boa em scaffolding padrão, mas fique atento a:
200 com erros, inconsistência entre 4xx/5xx)Trate a API como interface de produto: modele endpoints em torno de conceitos do usuário, não da implementação do banco de dados.
Use um ciclo repetível:
Use códigos de status consistentes e um único envelope de erro, por exemplo:
400, 401, 403, 404, 409, , Priorize testes que consolidem comportamento:
Os testes são como você “possui” o design em vez de herdar suposições da IA.
Use IA principalmente para rascunhos quando os padrões forem bem conhecidos (MVPs CRUD, ferramentas internas). Tenha cautela quando:
Boa política: a IA pode propor opções, mas humanos devem aprovar invariantes do esquema, autorização e estratégia de rollout/migração.
Um esquema pode parecer “limpo” e ainda falhar com fluxos reais e carga.
Isso transforma a saída da IA em artefatos que podem ser comprovados ou rejeitados em vez de confiar apenas em texto.
422429{"error":{"code":"...","message":"...","details":[]}}
Além disso, garanta que mensagens de erro não vazem internos (SQL, stack traces, segredos) e mantenham consistência entre todos os endpoints.