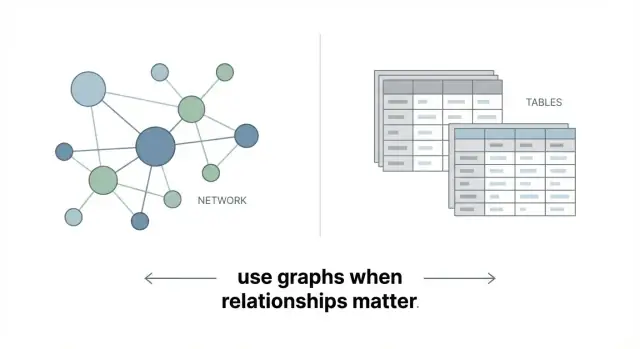
O que é um banco de dados em grafo (sem o hype)
Um banco de dados em grafo armazena dados como uma rede em vez de um conjunto de tabelas. A ideia central é simples:
- Nós são as “coisas” que importam (um cliente, produto, conta, dispositivo, localização).
- Relacionamentos conectam nós (cliente COMPROU produto, conta TRANSFERIU_PARA conta, usuário SEGUE usuário).
- Propriedades são os detalhes que você associa a nós e relacionamentos (nome, preço, timestamp, valor, status).
Isso é tudo: um banco de dados em grafo é construído para representar dados conectados diretamente.
Relacionamentos são “first-class”
Em um banco de dados em grafo, os relacionamentos não são um detalhe secundário—eles são armazenados como objetos reais e consultáveis. Um relacionamento pode ter suas próprias propriedades (por exemplo, um relacionamento PURCHASED pode armazenar data, canal e desconto), e você pode atravessar de um nó ao próximo de forma eficiente.
Isso importa porque muitas perguntas de negócio são naturalmente sobre caminhos e conexões: “Quem está conectado a quem?”, “A quantos passos está esta entidade?” ou “Quais são os links em comum entre essas duas coisas?”
Como isso difere de tabelas e joins
Bancos relacionais se saem muito bem com registros estruturados: clientes, pedidos, faturas. Lá, relacionamentos também existem, mas geralmente são representados indiretamente via chaves estrangeiras, e conectar múltiplos saltos muitas vezes significa escrever JOINs entre várias tabelas.
Grafos mantêm as conexões ao lado dos dados, então explorar relacionamentos em vários passos tende a ser mais direto para modelar e consultar.
Definindo expectativas
Bancos de dados em grafo são excelentes quando os relacionamentos são o ponto principal—recomendações, redes de fraude, mapeamento de dependências, grafos de conhecimento. Eles não são automaticamente melhores para relatórios simples, totais ou cargas altamente tabulares. O objetivo não é substituir todo banco de dados, mas usar grafo onde a conectividade gera valor.
Por que os relacionamentos mudam o jogo
A maioria das perguntas de negócio não trata apenas de registros individuais—trata de como as coisas se conectam.
Um cliente não é apenas uma linha; ele está ligado a pedidos, dispositivos, endereços, chamados de suporte, indicações e às vezes a outros clientes. Uma transação não é apenas um evento; está conectada a um comerciante, a um método de pagamento, a uma localização, a uma janela de tempo e a uma cadeia de atividades relacionadas. Quando a pergunta é “quem/o que está conectado a quem, e como?”, os dados de relacionamento viram protagonista.
Travessias: seguir conexões passo a passo
Bancos de dados em grafo são projetados para travessias: você começa em um nó e “anda” pela rede seguindo arestas.
Em vez de juntar tabelas repetidamente, você expressa o caminho que importa: Cliente → Dispositivo → Login → Endereço IP → Outros Clientes. Essa estrutura passo a passo combina com a forma como as pessoas investigam fraude, rastreiam dependências ou explicam recomendações.
Por que queries multi-hop ficam mais simples
A diferença real aparece quando você precisa de múltiplos saltos (dois, três, cinco passos) e não sabe de antemão onde aparecerão as conexões interessantes.
Num modelo relacional, perguntas multi-hop frequentemente viram longas cadeias de JOINs mais lógica extra para evitar duplicatas e controlar o comprimento do caminho. Em um grafo, “encontre todos os caminhos até N saltos” é um padrão normal e legível—especialmente no modelo de grafo por propriedades usado por muitos bancos de grafos.
Propriedades de relacionamento adicionam significado
Arestas não são apenas linhas; podem carregar dados:
- Tipo: purchased, referred, works_with
- Tempo: quando o relacionamento começou, terminou ou ocorreu pela última vez
- Peso: frequência, pontuação de confiança, valor, nível de risco
Essas propriedades permitem fazer perguntas melhores: “conectado nos últimos 30 dias”, “laços mais fortes” ou “caminhos que incluem transações de alto risco”—sem forçar tudo em tabelas de consulta separadas.
Casos de uso em que grafos se encaixam melhor
Grafos brilham quando suas perguntas dependem de conectividade: “quem está ligado a quem, por qual caminho e a quantos passos?” Se o valor dos seus dados vive nos relacionamentos (e não apenas em linhas de atributos), um modelo em grafo pode tornar tanto a modelagem quanto a consulta mais naturais.
Redes sociais e profissionais
Qualquer coisa que tenha formato de rede—amigos, seguidores, colegas, equipes, indicações—mapeia bem para nós e relacionamentos. Perguntas típicas incluem “conexões em comum”, “menor caminho para uma pessoa” ou “quem conecta esses dois grupos?” Essas consultas muitas vezes ficam estranhas (ou lentas) quando forçadas em muitas tabelas de junção.
Recomendações (e descoberta)
Motores de recomendação frequentemente dependem de conexões em vários passos: usuário → item → categoria → itens similares → outros usuários. Grafos são adequados para “pessoas que gostaram de X também gostaram de Y”, “itens frequentemente vistos juntos” e “encontre produtos conectados por atributos ou comportamento compartilhado”. Isso é especialmente útil quando os sinais são diversificados e você continua adicionando novos tipos de relacionamento.
Investigação de fraude e risco
Grafos de detecção de fraude funcionam bem porque comportamento suspeito raramente é isolado. Contas, dispositivos, transações, telefones, e-mails e endereços formam teias de identificadores compartilhados. Um grafo facilita detectar anéis, padrões repetidos e ligações indiretas (por exemplo, duas contas “não relacionadas” usando o mesmo dispositivo por meio de uma cadeia de atividades).
Mapeamento de dependências de rede e TI
Para serviços, hosts, APIs, chamadas e propriedade, a pergunta principal é dependência: “o que quebra se isso mudar?” Grafos suportam análise de impacto, exploração de causa raiz e consultas de “raio de explosão” quando sistemas estão interconectados.
Grafos de conhecimento
Grafos de conhecimento conectam entidades (pessoas, empresas, produtos, documentos) a fatos e referências. Isso ajuda em busca, resolução de entidade e rastreamento do “porquê” de um fato ser conhecido (proveniência) através de muitas fontes vinculadas.
Perguntas comuns de grafo que você resolve facilmente
Grafos brilham quando a pergunta é realmente sobre conexões: quem está ligado a quem, por qual cadeia e quais padrões se repetem. Em vez de fazer JOINs várias vezes, você pergunta sobre relacionamentos diretamente e mantém a consulta legível conforme a rede cresce.
1) Busca de caminho: “Como A e B estão conectados?”
Perguntas típicas:
- “Qual é o caminho mais curto deste cliente até aquele comerciante?”
- “Quais colegas conectam Alice e Bob, e em quantos passos?”
- “Mostre todas as rotas deste dispositivo até aquela conta em até 3 saltos.”
Isso é útil para suporte ao cliente (“por que sugerimos isto?”), conformidade (“mostre a cadeia de propriedade”) e investigações (“como isso se espalhou?”).
2) Detecção de comunidades: grupos e clusters na rede
Grafos ajudam a identificar agrupamentos naturais:
- “Quais clientes formam um cluster baseado em endereços, telefones e dispositivos compartilhados?”
- “Onde estão as comunidades mais coesas na nossa rede de fornecedores?”
Isto serve para segmentar usuários, encontrar quadrilhas de fraude ou entender como produtos são co-comprados. O importante é que o “grupo” é definido por como as coisas se conectam, não por uma única coluna.
3) Centralidade e influência: encontrar nós importantes
Às vezes a pergunta não é só “quem está conectado”, mas “quem importa mais” na teia:
- “Qual conta está em mais caminhos entre outras?”
- “Qual produto é a ponte mais forte entre dois segmentos de clientes?”
Esses nós centrais frequentemente apontam para influenciadores, infraestrutura crítica ou gargalos que valem a pena monitorar.
4) Correspondência de padrões: “encontre triângulos” e “aneles suspeitos”
Grafos são ótimos para buscar formas repetíveis:
- Triângulos: “A conhece B, B conhece C e C conhece A.”
- Anéis: “Contas transferindo fundos em loop.”
Em Cypher (uma linguagem comum de consulta em grafos), um padrão de triângulo pode parecer:
MATCH (a)-[:KNOWS]-\u003e(b)-[:KNOWS]-\u003e(c)-[:KNOWS]-\u003e(a)
RETURN a,b,c
Mesmo que você nunca escreva Cypher, isso ilustra por que grafos são acessíveis: a consulta espelha a imagem na sua cabeça.
Grafo vs Relacional: a diferença real
Bancos relacionais são ótimos no que foram feitos para: transações e registros bem estruturados. Se seus dados cabem bem em tabelas (clientes, pedidos, faturas) e você os recupera principalmente por IDs, filtros e agregados, sistemas relacionais são frequentemente a escolha mais simples e segura.
O problema dos JOINs não é “joins são ruins”—é joins profundos
JOINs são OK quando são ocasionais e rasos. O atrito começa quando suas perguntas mais importantes exigem muitos JOINs, o tempo todo, entre várias tabelas.
Exemplos:
- “Quais clientes compraram de vendedores conectados a este fornecedor por dois intermediários?”
- “Encontre todos os dispositivos que compartilharam rede com dispositivos usados por contatos próximos desta conta.”
Em SQL, isso pode virar consultas longas com self-joins repetidos e lógica complexa. Também pode ficar mais difícil de tunar à medida que a profundidade dos relacionamentos cresce.
Grafos tornam “caminhadas” multi-step uma operação de primeira classe
Bancos de dados em grafo armazenam relacionamentos explicitamente, então travessias em múltiplos passos através de conexões são uma operação natural. Em vez de costurar tabelas em tempo de consulta, você percorre nós e arestas conectados.
Isso frequentemente significa:
- Consultas mais curtas para padrões multi-hop (a consulta lê mais como a pergunta)
- Complexidade mais previsível ao explorar profundidades variáveis (por exemplo, 2 a 6 saltos)
Uma regra prática
Se sua equipe frequentemente faz perguntas multi-hop—“conectado a”, “através de”, “na mesma rede que”, “a N passos”—um banco de dados em grafo vale a consideração.
Se sua carga principal é transações de alto volume, esquemas rígidos, relatórios e JOINs simples, o relacional geralmente é o padrão mais seguro. Muitos sistemas reais usam ambos; veja /blog/practical-architecture-graph-alongside-other-databases.
Quando um banco de dados em grafo é a ferramenta errada
Prototipar um recurso de grafo
Descreva seu caso de uso de grafo no chat e receba rapidamente um esqueleto de app em React e Go.
Grafos brilham quando os relacionamentos são o “evento principal”. Se o valor do seu app não depende de atravessar conexões (quem-conhece-quem, como itens se relacionam, caminhos, vizinhanças), um grafo pode adicionar complexidade sem muito retorno.
Se a maioria das requisições é “buscar usuário por ID”, “atualizar perfil”, “criar pedido”, e os dados que você precisa vivem em um registro (ou um conjunto previsível de tabelas), um banco de dados em grafo costuma ser desnecessário. Você gastará tempo modelando nós e arestas, ajustando travessias e aprendendo um novo estilo de consulta—enquanto um banco relacional resolve esse padrão de forma eficiente com ferramentas familiares.
Relatórios/BI que são principalmente agregações
Dashboards baseados em totais, médias e métricas agrupadas (receita por mês, pedidos por região, taxa de conversão por canal) normalmente cabem melhor em SQL e em sistemas analíticos columnar do que em consultas de grafo. Motores de grafo podem responder algumas perguntas de agregação, mas raramente são o caminho mais fácil ou rápido para cargas OLAP pesadas.
Necessidades transacionais fortes e recursos “nativos SQL”
Quando você depende de recursos SQL maduros—joins complexos com restrições rigorosas, estratégias avançadas de indexação, stored procedures ou padrões ACID estabelecidos—sistemas relacionais costumam ser a escolha natural. Muitos bancos de grafo suportam transações, mas o ecossistema e os padrões operacionais podem não coincidir com o que sua equipe já usa.
Se seus dados são em grande parte um conjunto de entidades independentes (tickets, faturas, leituras de sensores) com pouco cross-linking, um modelo em grafo pode soar forçado. Nesses casos, foque em um esquema relacional limpo (ou modelo de documentos) e considere grafos mais tarde se consultas centradas em relacionamentos se tornarem críticas.
Uma boa regra: se você consegue descrever suas consultas principais sem palavras como “conectado”, “caminho”, “vizinhança” ou “recomendar”, um banco de dados em grafo pode não ser a escolha inicial certa.
Compromissos a conhecer antes de escolher grafo
Grafos brilham quando você precisa seguir conexões com rapidez—mas essa força tem custo. Antes de se comprometer, vale entender onde grafos tendem a ser menos eficientes, mais caros ou simplesmente diferentes para operar no dia a dia.
Custo e pegada
Bancos de dados em grafo frequentemente armazenam e indexam relacionamentos de forma que tornam “saltos” rápidos (por exemplo, de um cliente para seus dispositivos para suas transações). O trade-off é que podem custar mais em memória e armazenamento do que uma solução relacional comparável, especialmente quando você adiciona índices para buscas comuns e mantém dados de relacionamento prontamente acessíveis.
Nem toda consulta fica mais rápida
Se sua carga parece uma planilha—varreduras grandes tipo tabela, consultas de relatório sobre milhões de linhas ou agregação pesada (totais, médias, rollups)—um banco de dados em grafo pode ser mais lento ou mais caro para obter o mesmo resultado. Grafos são otimizados para travessias (“quem está conectado a quê?”), não para esmagar grandes lotes de registros independentes.
Diferenças operacionais
A complexidade operacional pode ser um fator real. Backups, escalonamento e monitoramento são diferentes do que muitas equipes estão acostumadas com sistemas relacionais. Algumas plataformas de grafo escalam melhor aumentando máquina (scale-up), enquanto outras suportam scale-out mas exigem planejamento cuidadoso sobre consistência, replicação e padrões de consulta.
Habilidades e ferramentas
Sua equipe pode precisar de tempo para aprender novos padrões de modelagem e abordagens de consulta (por exemplo, o modelo de grafo por propriedades e linguagens como Cypher). A curva de aprendizado é administrável, mas ainda é um custo—especialmente se você estiver substituindo fluxos de trabalho maduros baseados em SQL.
Uma abordagem prática é usar grafo onde relacionamentos são o produto e manter sistemas existentes para relatórios, agregação e análise tabular.
Noções básicas de modelagem de dados: nós, arestas e esquemas
Assuma o resultado
Mantenha o controle com exportação do código-fonte quando seu piloto estiver pronto para o repositório principal.
Uma maneira útil de pensar sobre modelagem em grafo é simples: nós são coisas e arestas são relacionamentos entre coisas. Pessoas, contas, dispositivos, pedidos, produtos, locais—essas são nós. “Comprou”, “logou de”, “trabalha_com”, “é_pai_de”—essas são arestas.
Grafos por propriedade vs triples RDF
A maioria dos bancos de dados de produto usa o modelo de grafo por propriedades: tanto nós quanto arestas podem ter propriedades (campos chave–valor). Por exemplo, uma aresta PURCHASED pode armazenar date, amount e channel. Isso torna natural modelar “relacionamentos com detalhes.”
RDF representa conhecimento como triples: subject – predicate – object. É ótimo para vocabulários interoperáveis e para ligar dados entre sistemas, mas frequentemente desloca “detalhes do relacionamento” para nós/triples adicionais. Na prática, você notará que RDF o empurra em direção a ontologias padrão e padrões SPARQL, enquanto grafos por propriedade parecem mais próximos da modelagem de dados de aplicação.
Linguagens de consulta em termos simples
- Cypher (popular com grafos por propriedade) lê-se como um padrão que você quer encontrar: “(Customer)-[PURCHASED]-\u003e(Product).”
- Gremlin é mais como uma travessia passo a passo: comece aqui, caminhe por arestas assim, filtre e então agregue.
- SPARQL é a linguagem do mundo RDF, casando padrões de grafo contra triples, muitas vezes usando vocabulários compartilhados.
Você não precisa memorizar sintaxe cedo—o que importa é que consultas em grafo geralmente são expressas como caminhos e padrões, não como JOINs de tabelas.
O que “esquema” significa em sistemas de grafo
Grafos são frequentemente flexíveis quanto ao esquema, o que significa que você pode adicionar um novo rótulo de nó ou propriedade sem uma migração pesada. Mas flexibilidade ainda exige disciplina: defina convenções de nomenclatura, propriedades obrigatórias (por exemplo, id) e regras para tipos de relacionamento.
Tipos de relacionamento, direção e propriedades
Escolha tipos de relacionamento que expliquem significado (“FRIEND_OF” vs “CONNECTED”). Use direção para clarificar semântica (por exemplo, FOLLOWS do seguidor para o criador), e adicione propriedades de aresta quando o relacionamento tiver fatos próprios (tempo, confiança, papel, peso).
Como decidir se seu problema é dirigido por relacionamentos
Um problema é “dirigido por relacionamentos” quando a parte difícil não é armazenar registros—é entender como as coisas se conectam e como essas conexões mudam o significado dependendo do caminho escolhido.
Comece escrevendo suas 5–10 principais perguntas em linguagem natural—aquelas que as partes interessadas repetem e que seu sistema atual responde de forma lenta ou inconsistente. Bons candidatos a grafo geralmente incluem frases como “conectado a”, “através de”, “similar a”, “em N passos” ou “quem mais”.
Exemplos:
- “Quais clientes estão ligados a este anel de fraude por dispositivos e endereços compartilhados?”
- “Quais produtos costumam ser comprados juntos por pessoas que também viram X?”
- “Quais fornecedores são impactados indiretamente se esta fábrica ficar offline?”
Traduza a pergunta em entidades e interações
Depois de ter as perguntas, mapeie substantivos e verbos:
- Entidades-chave viram nós (Customer, Account, Device, Product, Supplier).
- Interações viram relacionamentos (PAID_WITH, LOGGED_IN_FROM, BOUGHT, SUPPLIES).
Então decida o que deve ser relacionamento versus nó. Uma regra prática: se algo precisa de seus próprios atributos e você vai conectar múltiplas partes a ele, transforme em nó (por exemplo, um “Order” ou “Login event” pode ser nó quando carrega detalhes e conecta muitas entidades).
Facilite filtragem e pontuação
Adicione propriedades que permitam restringir resultados e ranquear relevância sem JOINs extras ou pós-processamento. Propriedades de alto valor típicas incluem tempo, valor, status, canal e pontuação de confiança.
Se a maioria das suas perguntas importantes exigir conexões multi-step mais filtragem por essas propriedades, provavelmente você tem um problema dirigido por relacionamentos onde grafos brilham.
Arquitetura prática: grafo junto a outros bancos
A maioria das equipes não substitui tudo por um banco de grafo. Uma abordagem prática é manter seu “sistema de registro” onde já funciona bem (frequentemente SQL) e usar um banco de grafo como motor especializado para perguntas pesadas em relacionamentos.
Mantenha a fonte da verdade no SQL (ou no seu datastore principal)
Use seu banco relacional para transações, restrições e entidades canônicas (clientes, pedidos, contas). Depois projete uma visão de relacionamentos em um banco de grafo—apenas os nós e arestas necessários para consultas conectadas.
Isso mantém auditoria e governança de dados simples enquanto desbloqueia travessias rápidas.
Construa o grafo para um recurso, não para a empresa toda
Um banco de grafo brilha quando você o conecta a um recurso com escopo claro, como:
- Recomendações (“pessoas que compraram X também compraram Y”)
- Pontuação de risco (anéis de fraude, dispositivos compartilhados, instrumentos de pagamento comuns)
- Resolução de identidade (ligar perfis entre sistemas)
Comece com um recurso, uma equipe e um resultado mensurável. Você pode expandir depois se provar valor.
Se o seu gargalo é entregar o protótipo (e não debater o modelo), uma plataforma de vibe-coding como Koder.ai pode ajudar a montar um app simples com grafo rapidamente: você descreve o recurso no chat, gera uma UI em React e backend em Go/PostgreSQL, e itera enquanto seu time de dados valida o esquema e as consultas do grafo.
Estratégias de sincronização: batch vs quase em tempo real
Quão fresco o grafo precisa ser?
- Atualizações em batch (hora a hora/noite) são mais simples e muitas vezes suficientes para analytics, descoberta e muitos motores de recomendação.
- Streams quase em tempo real (minutos/segundos) servem para detecção de fraude e decisões operacionais.
Um padrão comum: escreva transações no SQL → publique eventos de mudança → atualize o grafo.
Identificadores consistentes e propriedade clara
Grafos ficam bagunçados quando IDs divergem.
Defina identificadores estáveis (por exemplo, customer_id, account_id) que batam entre sistemas e documente quem “possui” cada campo e relacionamento. Se dois sistemas podem criar a mesma aresta (por exemplo, “knows”), decida qual ganha.
Se planeja um piloto, veja /blog/getting-started-a-low-risk-pilot-plan para uma abordagem de rollout por estágios.
Começando: um plano de piloto de baixo risco
Itere com segurança
Experimente mudanças intensas no grafo e reverta se o modelo precisar ser repensado.
Um piloto em grafo deve ser um experimento, não uma reescrita. O objetivo é provar (ou refutar) que consultas pesadas em relacionamentos ficam mais simples e rápidas—sem apostar toda a infraestrutura de dados.
1) Escolha um recorte pequeno e de alto valor
Comece com um conjunto limitado de dados que já cause dor: muitos JOINs, SQL frágil ou consultas lentas de “quem está conectado a quê?”. Mantenha limitado a um fluxo de trabalho (por exemplo: customer ↔ account ↔ device, ou user ↔ product ↔ interaction) e defina um punhado de consultas que deseja responder ponta a ponta.
2) Defina métricas de sucesso antes de construir
Meça mais que velocidade:
- Complexidade da consulta: Quantas linhas, joins ou tabelas intermediárias leva hoje vs. no grafo?
- Latência: Tempo para retornar resultados em volumes realistas de dados.
- Tempo do desenvolvedor: Quanto tempo para construir e mudar consultas quando requisitos mudam?
Se você não souber os números “antes”, não confiará nos “depois”.
3) Mantenha o modelo propositivo (evite espalhamento de grafo)
É tentador modelar tudo como nós e arestas. Resista. Observe o “graph sprawl”: muitos tipos de nós/arestas sem uma consulta clara que os demande. Cada novo label ou relacionamento deve ganhar seu lugar habilitando uma pergunta real.
4) Trate governança como parte do piloto
Planeje privacidade, controle de acesso e retenção de dados cedo. Dados de relacionamento podem revelar mais do que registros individuais (por exemplo, conexões que implicam comportamento). Defina quem pode consultar o quê, como resultados são auditados e como dados são apagados quando exigido.
5) Execute ao lado do seu banco atual
Use uma sincronização simples (batch ou streaming) para alimentar o grafo enquanto seu sistema atual permanece fonte da verdade. Quando o piloto provar valor, amplie o escopo—com cuidado, caso a caso.
Checklist rápido de decisão: use grafo para relacionamentos
Se vai escolher um banco, não comece pela tecnologia—comece pelas perguntas que precisa responder. Grafos brilham quando seus problemas mais difíceis são sobre conexões e caminhos, não apenas armazenar registros.
Um rápido “isso é dirigido por relacionamentos?”
Use este checklist para checar o ajuste antes de investir:
- Profundidade de relacionamento: Você frequentemente precisa seguir relacionamentos 2+ saltos (A→B→C→D) para obter uma resposta?
- Padrões de consulta: Suas perguntas-chave são sobre padrões (por exemplo, “pessoas que compartilham empregadores e telefones”) em vez de filtros de tabela única?
- Frequência de atualização: Relacionamentos mudam com frequência (novas conexões, remoções, papéis que mudam) e você precisa refletir essas mudanças rapidamente?
- Escala: O conjunto de dados é grande o suficiente para que juntar muitas tabelas (ou costurar no código da aplicação) esteja ficando lento, caro ou frágil?
Se você respondeu “sim” para a maioria, um grafo pode ser um bom ajuste—especialmente quando precisa de correspondência multi-hop como:
- “Encontre o caminho mais curto entre duas entidades.”
- “Mostre todas as contas conectadas a este dispositivo em até 3 passos.”
- “Recomende itens baseado em vizinhos compartilhados, não apenas categorias.”
Se seu trabalho é principalmente consultas simples (por ID/email) ou agregações (“vendas totais por mês”), um banco relacional ou um repositório de chave-valor/documento geralmente é mais simples e mais barato de operar.
Como reduzir o risco da decisão
Escreva suas 10 principais perguntas de negócio em frases simples, teste-as com dados reais em um piloto pequeno. Cronometre as consultas, anote o que é difícil de expressar e mantenha um registro curto de mudanças de modelo necessárias. Se seu piloto virar “mais JOINs” ou “mais caching”, isso sinaliza que grafo pode valer a pena. Se for principalmente contagens e filtros, provavelmente não valerá.