Escalando em linguagem simples
Escalar significa “lidar com mais sem cair”. Esse “mais” pode ser:
- Mais usuários usando o produto ao mesmo tempo
- Mais requisições de API por segundo
- Mais dados armazenados e consultados
- Mais trabalho em background (e-mails, processamento de vídeo, relatórios) rodando nos bastidores
Quando as pessoas falam de escalabilidade, geralmente querem melhorar um ou mais destes:
- Capacidade: quanto tráfego ou dados o sistema aguenta.\n- Velocidade: quão rápido responde sob carga.\n- Confiabilidade: quão bem continua funcionando quando algo quebra.
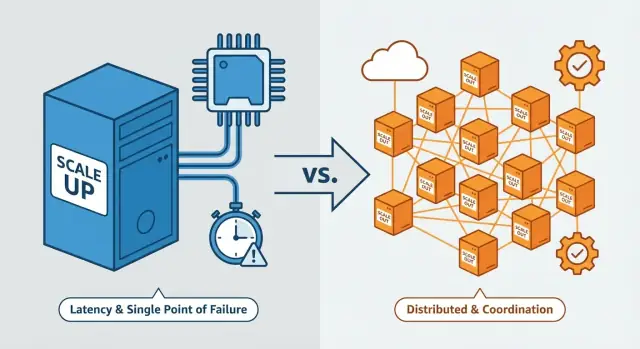
A maior parte disso se resume a um tema: escalar verticalmente preserva a sensação de “um único sistema”, enquanto escalar horizontalmente transforma seu sistema em um grupo coordenado de máquinas independentes — e é nessa coordenação que a dificuldade explode.
Escala vertical vs horizontal (definições rápidas)
Escala vertical (scale up)
Escala vertical significa tornar uma máquina mais poderosa. Você mantém a mesma arquitetura básica, mas atualiza o servidor (ou VM): mais núcleos de CPU, mais RAM, discos mais rápidos, maior throughput de rede.
Pense nisso como comprar um caminhão maior: ainda há um motorista e um veículo, só que carrega mais.
Escala horizontal (scale out)
Escala horizontal significa adicionar mais máquinas ou instâncias e repartir o trabalho entre elas — frequentemente atrás de um balanceador de carga. Em vez de um servidor mais forte, você roda vários servidores trabalhando juntos.
É como usar mais caminhões: dá para mover mais carga no total, mas agora há agendamento, roteamento e coordenação a considerar.
O que geralmente força a decisão?
Gatilhos comuns incluem:
- Picos de tráfego (campanhas de marketing, sazonalidade, crescimento viral)
- Crescimento contínuo do produto ao longo de meses/anos
- Conjuntos de dados maiores (mais clientes, mais eventos, mais histórico para armazenar)
Uma nuance importante: a maioria dos sistemas reais usa ambos
Times costumam escalar verticalmente primeiro porque é rápido (upgrade da máquina), e então escalar horizontalmente quando uma única máquina atinge limites ou quando é necessária maior disponibilidade. Arquiteturas maduras frequentemente misturam os dois: nós maiores e mais nós, dependendo do gargalo.
Por que escalar verticalmente parece mais simples
A escala vertical é atraente porque mantém seu sistema em um só lugar. Com um único nó, normalmente existe uma única fonte de verdade para memória e estado local. Um processo possui o cache em memória, a fila de jobs, a sessão (se a sessão estiver na memória) e arquivos temporários.
Menos partes móveis
Em um servidor só, muitas operações são diretas porque há pouca ou nenhuma coordenação entre nós:
- Depuração é mais fácil porque logs e métricas tendem a estar em um lugar só.
- Falhas são mais claras: ou a máquina está saudável ou não está.
- Muitos gargalos são locais e mensuráveis.
Ao escalar verticalmente, você puxa alavancas familiares: adicionar CPU/RAM, usar storage mais rápido, melhorar índices, ajustar queries e configurações. Não é preciso redesenhar como os dados são distribuídos ou como múltiplos nós concordam sobre “o que acontece a seguir”.
Os trade-offs que você aceita
Escala vertical não é “de graça”—apenas mantém a complexidade contida.
Eventualmente você atinge limites: a maior instância disponível, retornos decrescentes ou uma curva de custo íngreme no topo. Você também assume mais risco de downtime: se a máquina grande falhar ou precisar de manutenção, uma grande parte do sistema cai com ela, a menos que você tenha colocado redundância.
Sobrecarga de coordenação: mais nós, mais regras
Quando você escala horizontalmente, você não ganha apenas “mais servidores”. Você ganha mais atores independentes que precisam concordar sobre quem é responsável por cada pedaço de trabalho, em que momento e usando quais dados.
Com uma máquina, a coordenação é frequentemente implícita: um espaço de memória, um processo, um lugar para procurar estado. Com muitas máquinas, coordenação vira uma feature que você precisa projetar.
Como a coordenação aparece na prática
Padrões e ferramentas comuns incluem:
- Eleição de líder: escolher um nó para tomar decisões (por exemplo, qual worker processa o próximo job). Se o líder morrer, todos devem concordar sobre o substituto.
- Locks/leases: garantir que apenas um nó execute uma tarefa por vez (como enviar uma fatura ou rodar uma migração). Leases expiram, relógios derivam, e “quem tem o lock” vira complicado.
- Sistemas de consenso: um pequeno grupo de nós mantém uma visão acordada de estado crítico (configuração, membros, liderança). Poderoso—mas operacionalmente exigente.
Sintomas quando a coordenação dá errado
Bugs de coordenação raramente parecem crashes limpos. Mais frequentemente você vê:
- Condições de corrida: dois nós agem sobre os mesmos dados na ordem errada.
- Trabalho duplicado: o mesmo job roda duas vezes porque dois workers acharam que estava disponível.
- Split brain: um problema de rede cria dois “líderes”, cada um tomando decisões conflitantes.
Esses problemas muitas vezes aparecem só sob carga real, durante deploys ou quando falhas parciais ocorrem (um nó lento, um switch perde pacotes, uma zona dá um pipoco). O sistema parece bem—até ser estressado.
Particionamento de dados e sharding são difíceis de acertar
Ao escalar horizontalmente, você muitas vezes não pode manter todos os dados em um só lugar. Você os divide entre máquinas (shards) para que vários nós armazenem e sirvam requisições em paralelo. Essa divisão é onde a complexidade começa: toda leitura e escrita depende de “qual shard tem esse registro?”.
Estratégias comuns: range vs hash
Particionamento por intervalo (range) agrupa dados por uma chave ordenada (por exemplo, usuários A–F no shard 1, G–M no shard 2). É intuitivo e suporta bem consultas por faixa (“mostrar pedidos da semana passada”). O lado ruim é carga desigual: se uma faixa fica popular, aquele shard vira gargalo.
Particionamento por hash aplica uma função de hash à chave e distribui os resultados pelos shards. Espalha o tráfego de forma mais uniforme, mas dificulta consultas por faixa porque registros relacionados ficam dispersos.
Rebalanceamento não é grátis
Adicionar um nó e querer usá-lo significa mover dados. Remover um nó (planejado ou por falha) exige que outros shards assumam. Rebalancing pode desencadear grandes transferências, aquecimentos de cache e quedas temporárias de performance. Durante a movimentação, também é preciso prevenir leituras obsoletas e gravações mal roteadas.
Partições quentes e skew
Mesmo com hashing, o tráfego real não é uniforme. Uma conta de celebridade, um produto popular ou padrões de acesso por tempo podem concentrar leituras/escritas em um shard. Um shard quente pode limitar a taxa de transferência do sistema inteiro.
Trabalho operacional que você não pode ignorar
Sharding introduz responsabilidades contínuas: manter regras de roteamento, executar migrações, fazer backfills após mudanças de esquema e planejar splits/merges sem quebrar clientes.
Estado: sessões, caches e trabalho em background
Explore o scale out com segurança
Teste padrões stateless e ideias de estado compartilhado sem montar toda a pipeline primeiro.
Ao escalar horizontalmente, você não só adiciona servidores—você adiciona cópias da sua aplicação. A parte difícil é o estado: qualquer coisa que sua app “lembre” entre requisições ou enquanto um trabalho está em progresso.
Sessões: onde fica o login?
Se um usuário faz login no Servidor A e a próxima requisição cai no Servidor B, o B sabe quem é esse usuário?
- Sessões sticky mantêm o usuário sendo enviado ao mesmo servidor. Simples, mas frágil: reinícios e carga desigual viram problemas visíveis ao usuário.
- Um store de sessão compartilhado (Redis ou DB) permite que qualquer servidor trate qualquer requisição. Mais robusto—mas adiciona custo e uma dependência. Se o store de sessão fica lento, o app inteiro parece lento.
Caches: rápidos até discordarem
Caches aceleram, mas múltiplos servidores significam múltiplos caches. Agora você lida com:
- Invalidation: quando dados mudam, como impedir que todo cache sirva valores antigos?
- Coerência: nós podem discordar sobre o que é “verdade” por curtos períodos.
- Taxas de hit desiguais: um servidor está quente enquanto outro está frio, gerando performance inconsistente.
Trabalho em background: evitar processamento duplo
Com muitos workers, jobs em background podem rodar duas vezes a menos que você desenhe para isso. Normalmente precisa-se de uma fila, leases/locks ou lógica idempotente para que “enviar fatura” ou “cobrar cartão” não ocorra duas vezes—especialmente em retries e reinícios.
Consistência e concorrência se multiplicam
Com um único nó (ou um banco primário único), geralmente há uma fonte clara de verdade. Ao escalar, dados e requisições se espalham por máquinas, e manter todos em sincronia vira uma preocupação constante.
Consistência forte vs eventual (em linguagem simples)
- Consistência forte: depois que uma escrita é bem-sucedida, todo leitor vê imediatamente o valor mais recente.
- Consistência eventual: updates se propagam, mas por uma janela curta alguns leitores podem ver valores antigos.
Consistência eventual costuma ser mais rápida e barata em escala, mas introduz casos de borda surpreendentes.
O que dá errado em sistemas reais
Problemas comuns incluem:
- Leituras obsoletas: um usuário atualiza o endereço, refaz a página e ainda vê o antigo.
- Conflitos de escrita: duas atualizações quase simultâneas se sobrepõem.
- Atualizações perdidas: “last write wins” descarta silenciosamente uma mudança que deveria ter sido mesclada.
Padrões que reduzem o estrago
Você não elimina falhas, mas pode projetar para elas:
- Chaves de idempotência: retries de “criar pagamento” não cobram duas vezes.
- Retries com backoff: tentar após 200ms, depois 400ms, depois 800ms (com jitter) para evitar stampedes.
- Deduplicação: quando mensagens chegam duas vezes, processá-las uma vez.
Por que transações distribuídas são complicadas
Uma transação entre serviços (pedido + inventário + pagamento) exige que múltiplos sistemas concordem. Se um passo falha no meio, é preciso ações compensatórias e registros cuidadosos. O comportamento clássico “tudo ou nada” é difícil quando redes e nós falham independentemente.
Onde consistência forte importa mais
Use consistência forte para coisas que devem estar corretas: pagamentos, saldos de conta, contagem de inventário, reservas de assentos. Para dados menos críticos (analytics, recomendações), consistência eventual costuma ser aceitável.
Rede: latência, timeouts e retries
Quando você escala verticalmente, muitas “chamadas” são chamadas de função no mesmo processo: rápidas e previsíveis. Ao escalar horizontalmente, a mesma interação vira uma chamada de rede—adicionando latência, jitter e modos de falha que seu código precisa tratar.
Latência não é só “um pouco mais lenta”
Chamadas de rede têm overhead fixo (serialização, enfileiramento, hops) e overhead variável (congestionamento, roteamento, vizinhos barulhentos). Mesmo que a latência média esteja ok, a latência de cauda (1–5% mais lentos) pode dominar a experiência do usuário porque uma única dependência lenta trava toda a requisição.
Largura de banda e perda de pacotes também viram restrições: em altas taxas de requisição, payloads “pequenos” somam, e retransmissões aumentam silenciosamente a carga.
Timeouts, retries e storm de retries
Sem timeouts, chamadas lentas se acumulam e threads ficam presas. Com timeouts e retries, você pode se recuperar—até que retries amplifiquem a carga.
Um padrão comum é o retry storm: um backend fica lento, clientes dão timeout e re-tentam; as tentativas aumentam a carga, e o backend fica ainda mais lento.
Retries seguros normalmente exigem:
- timeouts conservadores baseados em dados reais de latência
- retries limitados (frequentemente 0–1) com backoff exponencial e jitter
- regras claras sobre o que é seguro retryar (operações idempotentes)
Balanceadores de carga e descoberta de serviço
Com múltiplas instâncias, clientes precisam saber para onde enviar requisições—via um load balancer ou descoberta de serviço + balanceamento no cliente. De qualquer forma, você adiciona partes móveis: health checks, drenagem de conexões, distribuição desigual de tráfego e risco de rotear para uma instância meio quebrada.
Backpressure e rate limiting
Para evitar que a sobrecarga se espalhe, você precisa de backpressure: filas limitadas, circuit breakers e rate limiting. O objetivo é falhar rápido e de forma previsível em vez de deixar uma pequena lentidão virar um incidente de sistema inteiro.
Modos de falha mudam: falha parcial vira normal
Transforme reversões em rotina
Capture um ponto estável antes de grandes mudanças e reverta rápido se necessário.
Escalar verticalmente tende a falhar de forma direta: uma máquina maior ainda é um ponto único. Se ela fica lenta ou cai, o impacto é óbvio.
Escala horizontal muda as contas. Com muitos nós, é normal que algumas máquinas estejam doentes enquanto outras estão bem. O sistema está “up”, mas usuários ainda veem erros, páginas lentas ou comportamento inconsistente. Isso é falha parcial, e vira o estado padrão que você projeta para suportar.
Como falhas parciais viram cascatas
Em uma arquitetura escalada, serviços dependem de outros serviços: bancos, caches, filas, APIs downstream. Um problema pequeno pode se propagar:
- Um nó não alcança o banco → ele re-tenta agressivamente
- Retries aumentam a carga no BD → latência sobe para todos
- Latência maior provoca mais timeouts → mais retries → mais carga
- Filas enchem, caches falham e APIs downstream são bombardeadas
Redundância ajuda, mas adiciona regras
Para sobreviver a falhas parciais, sistemas adicionam redundância:
- Replicação: múltiplas cópias de dados ou serviços
- Quorums: “sucesso só se N de M réplicas concordarem”
- Deploy multi-zona: espalhar zonas para que uma não derrube tudo
Isso aumenta disponibilidade, mas introduz casos de borda: split-brain, réplicas obsoletas e decisões sobre o que fazer quando o quorum não é alcançado.
Ferramentas de resiliência que você acaba precisando
Padrões comuns incluem:
- Circuit breakers para parar de chamar uma dependência com falha
- Bulkheads para isolar falhas e evitar que um componente ruidoso afunde tudo
- Degradação graciosa para servir uma experiência mais simples ao invés de erros duros
Observabilidade e depuração entre muitas máquinas
Com uma única máquina, a “história do sistema” vive em um lugar: um conjunto de logs, um gráfico de CPU, um processo para inspecionar. Com escala horizontal, a história fica espalhada.
Mais máquinas, mais contexto faltando
Cada nó adicional adiciona outro fluxo de logs, métricas e traces. O difícil não é coletar dados—é correlacioná-los. Um erro no checkout pode começar num nó web, chamar dois serviços, bater num cache e ler de um shard específico, deixando pistas em lugares e timelines diferentes.
Problemas também se tornam seletivos: um nó com configuração errada, um shard quente, uma zona com latência maior. Depurar pode parecer aleatório porque “funciona bem” na maior parte do tempo.
Tracing e IDs de correlação (versão em linguagem simples)
Tracing distribuído é como anexar um número de rastreio a uma requisição. Um ID de correlação é esse número. Você o passa pelos serviços e o inclui nos logs para poder puxar um ID e ver toda a jornada fim a fim.
Alertas que ajudam em vez de sobrecarregar
Mais componentes normalmente significam mais alertas. Sem ajuste, times ficam em alerta-fatiga. Mire em alertas acionáveis que esclareçam:
- O que está quebrado
- Quem é impactado
- O que checar primeiro
Observe saturação, não só erros
Problemas de capacidade frequentemente aparecem antes de falhas. Monitore sinais de saturação como CPU, memória, profundidade de fila e uso de pools de conexão. Se saturação aparece em apenas um subconjunto de nós, suspeite de balanceamento, sharding ou deriva de configuração—não só “mais tráfego”.
Deploys, upgrades e rollbacks ficam mais arriscados
Ao escalar horizontalmente, um deploy deixa de ser “trocar uma caixa”. É coordenar mudanças em muitas máquinas mantendo o serviço disponível.
Rolling updates, canários e blue/green
Deploys horizontais costumam usar rolling updates (substituir nós gradualmente), canários (enviar pequena porcentagem de tráfego para a nova versão) ou blue/green (trocar tráfego entre dois ambientes completos). Reduzem o blast radius, mas exigem: mudança de tráfego, health checks, drenagem de conexões e uma definição do que é “bom o suficiente” para prosseguir.
Desencontro de versões é o padrão
Durante um deploy gradual, versões antigas e novas rodam lado a lado. Esse desencontro significa que seu sistema deve tolerar comportamento misto:
- Nodes novos chamando nodes antigos (e vice-versa)
- Clientes antigos atingindo servidores novos
- Formatos de cache ou payloads de jobs diferentes em trânsito
Compatibilidade vira requisito
APIs precisam de compatibilidade retroativa/para frente, não apenas correção. Mudanças de esquema no BD devem ser aditivas quando possível (adicionar colunas nullable antes de torná-las obrigatórias). Formatos de mensagem devem ser versionados para que consumidores entendam eventos antigos e novos.
Fazer rollback de código é fácil; rollback de dados não é. Se uma migração apaga ou reescreve campos, código mais antigo pode falhar ou manipular registros incorretamente. Migrações “expandir/contrair” ajudam: deployar código que suporte ambos os esquemas, migrar dados e só depois remover caminhos antigos.
Config e segredos devem ser consistentes
Com muitos nós, gerenciamento de configuração faz parte do deploy. Um único nó com config stale, feature flag errada ou credenciais expiradas pode criar falhas intermitentes difíceis de reproduzir.
Expanda para mobile rapidamente
Crie um app Flutter que se mantém sincronizado com as mudanças no backend.
Escala horizontal pode parecer mais barata no papel: muitas instâncias pequenas, cada uma com preço horário baixo. Mas o custo total não é só compute. Adicionar nós também significa mais rede, mais monitoramento, mais coordenação e mais tempo gasto mantendo a consistência.
Menos caixas grandes vs muitas instâncias pequenas
Escala vertical concentra gasto em menos máquinas—muitas vezes menos hosts para patchar, menos agentes para rodar, menos logs para enviar, menos métricas para coletar.
Com escala horizontal, o preço por unidade pode ser menor, mas você frequentemente paga por:
- Load balancers, descoberta de serviço e banda extra
- Mais réplicas para atingir metas de performance e disponibilidade
- Capacidade base maior porque você precisa de folga em vários pontos, não só em um
Utilização e superprovisionamento
Para lidar com picos com segurança, sistemas distribuídos frequentemente rodam com capacidade subutilizada. Você mantém folga em múltiplas camadas (web, workers, DB, caches), o que pode significar pagar por capacidade ociosa em dezenas ou centenas de instâncias.
Custo operacional: o multiplicador oculto
Escala horizontal aumenta carga de on-call e exige ferramentas maduras: ajuste de alertas, runbooks, exercícios de incidentes e treinamento. Times também gastam tempo em limites de propriedade (quem é dono de qual serviço?) e coordenação de incidentes.
O resultado: “mais barato por unidade” pode sair mais caro no total quando se inclui tempo de pessoas, risco operacional e o trabalho necessário para fazer muitas máquinas se comportarem como um sistema único.
Escolhendo o caminho certo: quando escalar vertical vs horizontal
Escolher entre escalar verticalmente (máquina maior) e horizontalmente (mais máquinas) não é só uma questão de preço. É sobre o formato da carga de trabalho e quanta complexidade operacional seu time pode absorver.
Critérios de decisão que realmente importam
Comece pela carga de trabalho:
- Tipo de trabalho: jobs ligados à CPU frequentemente se beneficiam de scale up; tráfego de requisições frequentemente se beneficia de scale out atrás de balanceamento.
- Estado: se requisições dependem de estado local (sessões, caches, trabalho em progresso), scale out te força a redesenhar onde esse estado vive.
- Necessidade de consistência: se a correção é crítica (pagamentos, inventário), scale out introduz trade-offs mais difíceis sobre concorrência e consistência.
- Taxa de crescimento e picos: crescimento previsível pode ser tratado por escala vertical em etapas; picos imprevisíveis podem empurrar para capacidade horizontal.
Uma progressão prática (que economiza tempo)
Um caminho comum e sensato:
- Otimizar gargalos óbvios (queries lentas, índices faltando, endpoints ineficientes).
- Escalar verticalmente primeiro (VM/instância maior), porque muda menos pressupostos.
- Escalar horizontalmente quando um único nó for realmente o fator limitante—ou quando você precisar de disponibilidade que uma máquina não oferece.
Padrões híbridos são normais
Muitos times mantêm o banco vertical (ou levemente clusterizado) enquanto escalam a camada de aplicação sem estado horizontalmente. Isso limita a dor do sharding enquanto permite adicionar capacidade web rapidamente.
Sinais de prontidão para escalar horizontalmente
Você está mais perto quando tem monitoramento e alertas sólidos, failover testado, testes de carga e deploys repetíveis com rollbacks seguros.
Perguntas a fazer antes de se comprometer
- Podemos atingir metas otimizando ou escalando verticalmente pelos próximos 6–12 meses?
- Onde vão morar sessões, caches e jobs em background?
- Precisamos de consistência forte, e quais falhas são aceitáveis?
- Qual é o plano para particionamento de dados (se houver) e rebalancing?
- Temos ferramentas para depurar problemas em múltiplos nós?
Onde a Koder.ai se encaixa (ajuda prática sem reinventar tudo)
Muita dor de escala não é só “arquitetura”—é o loop operacional: iterar com segurança, deployar com confiança e fazer rollback rápido quando a realidade diverge do plano.
Se você está construindo sistemas web, backend ou mobile e quer mover rápido sem perder controle, Koder.ai pode ajudar a prototipar e entregar mais rápido enquanto você toma decisões de escala. É uma plataforma vibe-coding onde você constrói aplicações via chat, com uma arquitetura baseada em agentes nos bastidores. Na prática isso significa que você pode:
- Levantar rapidamente um app React, um backend Go + PostgreSQL ou um app Flutter, e iterar conforme descobre gargalos.
- Usar o planning mode para pensar nas mudanças de “scale up vs. scale out” antes de implementá-las.
- Reduzir risco de deploy com snapshots e rollback, algo que importa mais à medida que você adiciona nós e o desencontro de versões vira comum.
- Exportar código-fonte quando quiser migrar para seu próprio pipeline, e fazer deploy/hosting com domínios customizados.
Como a Koder.ai roda globalmente na AWS, ela também pode suportar deploys em diferentes regiões para atender restrições de latência e transferência de dados—útil quando disponibilidade multi-zona ou multi-região entra na sua história de escala.