O que “crítico para o desempenho” realmente significa
“Crítico para o desempenho” não quer dizer “seria bom ser rápido”. Significa que a experiência se desfaz quando o app fica mesmo que um pouco lento, inconsistente ou atrasado. Usuários não apenas notam o lag—eles perdem um momento, tomam uma decisão errada ou deixam de confiar no app.
Exemplos cotidianos onde o desempenho é o produto
Alguns tipos comuns de app deixam isso claro:
- Câmera e vídeo: toca no obturador e espera-se a captura imediata. Atrasos podem perder o momento. Pré-visualização com stutter, foco lento ou frames perdidos fazem o app parecer pouco confiável.
- Mapas e navegação: o ponto azul precisa se mover suavemente, reroutes devem parecer instantâneos e a UI tem que permanecer responsiva enquanto GPS, carregamento de dados e renderização rodam em paralelo.
- Trading e finanças: uma cotação que atualiza tarde, um botão que registra tarde ou uma tela que congela em volatilidade pode afetar resultados diretamente.
- Jogos: quedas de frame e atraso de entrada não apenas “parecem ruins”—elas mudam o gameplay. Pacing consistente de frames importa tanto quanto FPS bruto.
Em todos esses casos, desempenho não é uma métrica técnica escondida. É visível, sentido e julgado em segundos.
O que “frameworks nativos” quer dizer (sem buzzwords)
Quando dizemos frameworks nativos, estamos falando de construir com as ferramentas que são first‑class em cada plataforma:
- iOS: Swift/Objective‑C com os SDKs do iOS da Apple (por exemplo, UIKit ou SwiftUI, além dos frameworks do sistema)
- Android: Kotlin/Java com os SDKs do Android (por exemplo Jetpack, Views/Compose, além das APIs de plataforma)
Nativo não significa automaticamente “engenharia melhor”. Significa que seu app fala a linguagem da plataforma diretamente—especialmente importante quando você está forçando o aparelho ao limite.
Frameworks multiplataforma podem ser uma ótima escolha para muitos produtos, particularmente quando velocidade de desenvolvimento e código compartilhado importam mais do que extrair cada milissegundo.
Este artigo não defende “nativo sempre”. Defende que, quando um app é verdadeiramente crítico para desempenho, frameworks nativos frequentemente eliminam categorias inteiras de overhead e limitações.
As dimensões que geralmente decidem
Avaliamos necessidades críticas de desempenho em algumas dimensões práticas:
- Latência: resposta ao toque, digitação, interações em tempo real, sincronização áudio/vídeo
- Renderização: rolagem suave, animações, pacing de frames, UI dirigida pela GPU
- Bateria e calor: eficiência sustentada em sessões longas
- Acesso a hardware/SO: pipelines de câmera, sensores, Bluetooth, execução em background, ML on‑device
São áreas onde usuários sentem a diferença—e onde frameworks nativos tendem a sobressair.
Frameworks multiplataforma podem parecer “suficientemente próximos” do nativo quando você constrói telas típicas, formulários e fluxos guiados por rede. A diferença geralmente aparece quando um app é sensível a pequenos atrasos, precisa de pacing consistente de frames ou tem que forçar o dispositivo por longos períodos.
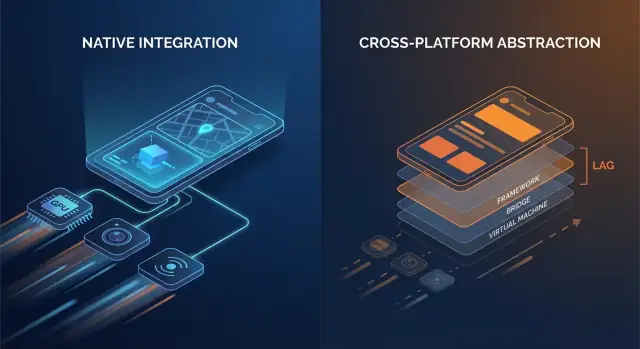
Código nativo normalmente conversa com as APIs do SO diretamente. Muitas pilhas multiplataforma adicionam uma ou mais camadas de tradução entre sua lógica e o que o aparelho finalmente renderiza.
Pontos comuns de overhead incluem:
- Chamadas de bridge e troca de contexto: se sua camada de UI e lógica vivem em runtimes diferentes (por exemplo, um runtime gerenciado ou motor de script junto com código nativo), cada interação pode requerer um salto por uma fronteira.
- Serialização e cópia: dados passados entre fronteiras podem precisar ser convertidos (payloads tipo JSON, mapas tipados, buffers). Esse trabalho de conversão aparece em caminhos quentes como scroll ou digitação.
- Hierarquias de view extras: alguns frameworks criam sua própria árvore de UI e depois a mapeiam para views nativas (ou renderizam num canvas). Reconciliação e layout podem ficar mais caros que uma atualização direta de view nativa.
Nenhum desses custos é enorme isoladamente. A questão é repetição: eles podem ocorrer em cada gesto, em cada tick de animação e em cada item de lista.
Tempo de inicialização e “jank” em tempo de execução
Overhead não é só velocidade bruta; é também quando o trabalho acontece.
- Tempo de inicialização pode aumentar quando o app precisa inicializar um runtime adicional, carregar assets empacotados, aquecer um motor de UI ou reconstruir estado antes da primeira tela ficar interativa.
- Jank em tempo de execução frequentemente vem de pausas imprevisíveis: coleta de lixo, backpressure no bridge, diffing caro ou uma tarefa longa bloqueando a main thread exatamente quando a UI precisa cumprir o próximo frame.
Apps nativos também podem bater nesses problemas—mas há menos peças móveis, o que significa menos lugares onde surpresas se escondem.
Um modelo mental simples
Pense: menos camadas = menos surpresas. Cada camada adicional pode ser bem projetada, mas ainda assim introduz complexidade de escalonamento, mais pressão de memória e mais trabalho de tradução.
Quando o overhead é aceitável — e quando não é
Para muitos apps, o overhead é aceitável e o ganho de produtividade é real. Mas para apps críticos de desempenho—feeds de rolagem rápida, animações pesadas, colaboração em tempo real, processamento de áudio/vídeo ou qualquer coisa sensível à latência—esses custos “pequenos” podem se tornar visíveis para o usuário rapidamente.
Suavidade de UI: Frames, jank e caminhos nativos de renderização
UI suave não é só um “agradinho”—é um sinal direto de qualidade. Em uma tela a 60 Hz, seu app tem cerca de 16,7 ms para produzir cada frame. Em dispositivos 120 Hz, esse orçamento cai para 8,3 ms. Quando você perde essa janela, o usuário percebe como stutter (gagueira): rolagem que “agarra”, transições que engasgam ou um gesto que parece atrasado em relação ao dedo.
Por que frames perdidos são tão fáceis de notar
Pessoas não contam frames conscientemente, mas notam inconsciência. Um único frame perdido durante um fade lento pode ser tolerável; alguns frames perdidos durante uma rolagem rápida são imediatamente óbvios. Telas de alta taxa de atualização também elevam expectativas—depois que usuários experimentam 120 Hz, renderizações inconsistentes parecem piores do que em 60 Hz.
A main thread é o gargalo usual
A maioria dos frameworks de UI ainda depende de uma thread primária/UI para coordenar entrada, layout e desenho. Jank aparece quando essa thread faz trabalho demais dentro de um frame:
- Passes de layout pesados: hierarquias de view complexas, containers aninhados ou relayouts frequentes acionados por mudanças de constraints/tamanhos.
- Animações caras: animar propriedades que forçam relayout ou rerasterização em vez de deixar a GPU tratar transforms.
- Trabalho síncrono em callbacks de UI: parse de JSON, formatação de textos grandes ou execução de lógica de negócio durante eventos de scroll/gesto.
Frameworks nativos tendem a ter pipelines bem otimizados e melhores práticas mais claras para tirar trabalho da main thread, minimizar invalidações de layout e usar animações amigáveis à GPU.
Componentes nativos vs UI renderizada customizada
Uma diferença chave é o caminho de renderização:
- Componentes nativos da plataforma normalmente mapeiam diretamente para widgets otimizados pelo SO e sistemas de compositing.
- Abordagens de UI custom‑renderizada (comuns em stacks multiplataforma) podem adicionar uma árvore de render separada, uploads extras de textura ou trabalho adicional de reconciliação. Isso pode ser ok—até sua tela ficar pesada em animações ou listas e o overhead começar a competir com um orçamento de frame apertado.
Onde você sente: exemplos reais de tela
Listas complexas são o teste clássico: rolagem rápida + carregamento de imagens + alturas dinâmicas de células podem criar churn de layout e pressão de GC/memória.
Transições podem revelar ineficiências de pipeline: animações com elementos compartilhados, desfoques de fundo e sombras em camadas são visualmente ricas, mas podem elevar o custo da GPU e overdraw.
Telas com muitos gestos (drag‑to‑reorder, swipe cards, scrubbers) são implacáveis porque a UI precisa responder continuamente. Quando frames chegam atrasados, a UI deixa de “estar presa” ao dedo do usuário—exatamente o que apps de alto desempenho evitam.
Baixa latência: toque, digitação, áudio e UX em tempo real
Latência é o tempo entre uma ação do usuário e a resposta do app. Não é “velocidade” geral, mas a lacuna que você sente quando toca um botão, digita um caractere, arrasta um slider, desenha uma linha ou toca uma nota.
Input → resposta: onde “rápido” vira “parece certo”
Regras práticas aproximadas:
- 0–50 ms: parece instantâneo. Toques e digitação parecem conectados ao dedo.
- 50–100 ms: geralmente aceitável, mas começa a parecer “macio”, especialmente ao arrastar.
- 100–200 ms: atraso perceptível. Digitar parece estar atrasado; desenhar linhas “persegue” a caneta.
- 200 ms+: frustrante. Usuários desaceleram para compensar.
Apps críticos vivem e morrem por essas lacunas.
Loops de evento, escalonamento e “thread hops”
A maioria dos frameworks trata entrada em uma thread, roda lógica do app em outro lugar e então pede à UI para atualizar. Quando esse caminho é longo ou inconsistente, a latência dispara.
Camadas multiplataforma podem adicionar passos extras:
- Entrada chega → traduzida para eventos do framework
- Lógica roda em um runtime separado (frequentemente com seu próprio event loop)
- Mudanças de estado são serializadas e enviadas de volta
- Atualizações de UI são agendadas mais tarde, às vezes perdendo o próximo frame
Cada handoff (um “thread hop”) adiciona overhead e, mais importante, jitter—o tempo de resposta varia, o que costuma parecer pior que um atraso constante.
Frameworks nativos tendem a ter um caminho mais curto e previsível do toque → atualização de UI porque se alinham de perto com o escalonador do SO, sistema de input e pipeline de renderização.
UX em tempo real: áudio, vídeo e colaboração ao vivo
Alguns cenários têm limites rígidos:
- Monitoramento de áudio/instrumentos: latência de ida e volta costuma precisar ficar em torno de <~20 ms para soar jogável.
- Chamadas de voz/vídeo: você pode usar buffers para esconder problemas de rede, mas controles de UI (mute, alto‑falante, legendas) devem responder imediatamente.
- Colaboração ao vivo (docs, whiteboards): edições locais devem aparecer instantaneamente, mesmo que a sincronização remota leve mais tempo.
Implementações nativas facilitam manter o “caminho crítico” curto—priorizando input e render sobre trabalho em background—para que interações em tempo real permaneçam justas e confiáveis.
Recursos profundos de hardware e SO: nativo primeiro, sempre
Implemente e reverta rapidamente
Implemente no Koder.ai e reverta instantaneamente com snapshots quando um experimento prejudicar o desempenho.
Desempenho não é só velocidade de CPU ou taxa de frames. Para muitos apps, os momentos decisivos acontecem nas bordas—onde seu código toca câmera, sensores, rádios e serviços em nível de SO. Essas capacidades são projetadas e lançadas como APIs nativas primeiro, e essa realidade molda o que é viável (e quão estável será) em stacks multiplataforma.
Acesso ao hardware raramente é genérico
Recursos como pipelines de câmera, AR, BLE, NFC e sensores de movimento frequentemente exigem integração fina com frameworks específicos do dispositivo. Wrappers multiplataforma podem cobrir casos comuns, mas cenários avançados tendem a revelar lacunas.
Exemplos onde APIs nativas importam:
- Controles avançados de câmera: foco e exposição manuais, captura RAW, vídeo em alta taxa de quadros, ajuste HDR, troca entre múltiplas câmeras (wide/tele), dados de profundidade e comportamento em baixa luminosidade.
- Experiências AR: capacidades do ARKit/ARCore evoluem rápido (occlusion, detecção de planos, reconstrução de cena).
- BLE e modos background: scanning, comportamento de reconexão e “funciona com a tela desligada” dependem de regras de execução em background da plataforma.
- NFC: acesso a elemento seguro, limites de emulação de cartão e gerenciamento de sessões de leitura são altamente específicos da plataforma.
- Dados de saúde: permissões do HealthKit/Google Fit, tipos de dados e entrega em background podem ser nuanceados e exigir tratamento nativo.
Atualizações do SO chegam primeiro ao nativo
Quando iOS ou Android libera novos recursos, APIs oficiais aparecem primeiro nos SDKs nativos. Camadas multiplataforma podem levar semanas (ou mais) para adicionar bindings, atualizar plugins e resolver casos de borda.
Essa demora não é só inconveniente—pode criar risco de confiabilidade. Se um wrapper não foi atualizado para uma nova versão do SO, você pode ver:
- fluxos de permissão que quebram,
- tarefas em background que ficam restritas,
- crashes acionados por mudanças no comportamento do sistema,
- regressões que só ocorrem em certos modelos de dispositivo.
Para apps críticos, frameworks nativos reduzem o problema de “esperar pelo wrapper” e permitem que equipes adotem novas capacidades do SO no dia 1—frequentemente a diferença entre lançar um recurso neste trimestre ou no próximo.
Bateria, memória e calor: desempenho que você sente ao longo do tempo
Velocidade em uma demo rápida é só metade da história. O desempenho que os usuários lembram é aquele que se mantém após 20 minutos de uso—quando o telefone está quente, a bateria caiu e o app entrou/ saiu do background algumas vezes.
De onde vem o consumo de bateria
A maioria dos “drains misteriosos” é auto‑infligida:
- Wake locks e timers descontrolados impedem a CPU de dormir, mesmo com a tela apagada.
- Trabalho em background que nunca para de fato (polling, checagens frequentes de localização, tentativas de rede repetidas) soma rapidamente.
- Redraws excessivos—reconstruir UI ou rerenderizar animações mais vezes do que o necessário—mantêm CPU/GPU ocupados.
Frameworks nativos tipicamente oferecem ferramentas mais claras e previsíveis para agendar trabalho eficientemente (tarefas background, job scheduling, refresh gerenciado pelo SO), para que você faça menos trabalho e o faça nos momentos certos.
Pressão de memória: a fonte oculta de stutters
Memória não afeta só se o app vai crashar—ela afeta a suavidade.
Muitas pilhas multiplataforma dependem de um runtime gerenciado com coleta de lixo (GC). Quando a memória sobe, o GC pode pausar o app brevemente para limpar objetos não usados. Você não precisa entender o interior para sentir: micro‑congelamentos ocasionais durante scroll, digitação ou transições.
Apps nativos tendem a seguir padrões da plataforma (como ARC — contagem automática de referências em iOS), o que frequentemente espalha o trabalho de limpeza de forma mais uniforme. O resultado pode ser menos pausas-surpresa—especialmente sob condições de memória apertada.
Calor e desempenho sustentado
Calor é desempenho. Conforme dispositivos esquentam, o SO pode throttlear CPU/GPU para proteger o hardware, e a taxa de frames cai. Isso é comum em workloads sustentadas como jogos, navegação turn‑by‑turn, câmera + filtros ou áudio em tempo real.
Código nativo pode ser mais eficiente energeticamente nesses cenários porque usa APIs aceleradas por hardware e sintonizadas pelo SO para tarefas pesadas—por exemplo, pipelines nativos de reprodução de vídeo, amostragem eficiente de sensores e codecs de mídia da plataforma—reduzindo trabalho desperdiçado que vira calor.
Quando “rápido” também significa “fresco e estável”, frameworks nativos frequentemente têm vantagem.
Perfilamento e depuração: ver os gargalos reais
Lance com um domínio personalizado
Hospede seu app no Koder.ai e adicione um domínio personalizado quando estiver pronto.
Trabalho de performance vence ou perde por visibilidade. Frameworks nativos normalmente entregam os ganchos mais profundos no sistema operacional, runtime e pipeline de renderização—porque são feitos pelos mesmos fornecedores que definem essas camadas.
Apps nativos podem anexar profilers nas fronteiras onde atrasos são introduzidos: main thread, render thread, compositor do sistema, stack de áudio e subsistemas de rede/armazenamento. Quando você persegue um stutter que acontece a cada 30 segundos, ou um consumo de bateria que só aparece em certos dispositivos, esses traces “abaixo do framework” são frequentemente o único caminho para uma resposta definitiva.
Ferramentas nativas comuns (os suspeitos usuais)
Você não precisa decorar tudo para se beneficiar, mas é bom saber o que existe:
- Xcode Instruments (Time Profiler, Allocations, Leaks, Core Animation, Energy Log)
- Xcode Debugger (inspeção de threads, memory graph, breakpoints simbólicos)
- Android Studio Profiler (CPU, Memory, Network, Energy)
- Perfetto / System Trace (tracing de sistema no Android)
- Ferramentas de GPU como as ferramentas Metal do Xcode ou inspetores de GPU de fabricantes (para diagnosticar overdraw, custo de shaders, pacing de frames)
Essas ferramentas respondem perguntas concretas: “Qual função está quente?”, “Qual objeto nunca é liberado?”, “Qual frame perdeu seu deadline, e por quê?”.
Os bugs do “último 5%”: congelamentos, leaks e quedas de frame
Os problemas de performance mais difíceis costumam se esconder em casos de borda: um deadlock raro de sincronização, um parse de JSON lento na main thread, uma view específica que dispara layout caro ou um vazamento de memória que só aparece após 20 minutos.
Perfilamento nativo permite correlacionar sintomas (um congelamento ou jank) com causas (uma stack de chamadas específica, padrão de alocações ou pico da GPU) em vez de depender em tentativa e erro.
Correções mais rápidas para problemas de alto impacto
Maior visibilidade reduz o tempo para consertar porque transforma debates em evidência. Equipes podem capturar um trace, compartilhá‑lo e concordar no gargalo rapidamente—frequentemente reduzindo dias de especulação para um patch focado e um resultado mensurável antes/depois.
Confiabilidade em escala: dispositivos, atualizações do SO e casos de borda
Desempenho não é a única coisa que quebra quando você roda em milhões de telefones—consistência também. O mesmo app pode se comportar diferente entre versões do SO, customizações de OEM e até drivers de GPU de fabricantes. Confiabilidade em escala é a habilidade de manter o app previsível quando o ecossistema não é.
Por que “mesmo Android/iOS” nem sempre é o mesmo
No Android, skins de OEM podem ajustar limites de background, notificações, pickers de arquivo e gerenciamento de energia. Dois dispositivos na mesma versão do Android podem diferir porque fabricantes embarcam componentes e patches diferentes.
GPUs adicionam outra variável. Drivers de fabricantes (Adreno, Mali, PowerVR) divergem em precisão de shader, formatos de textura e otimizações. Um caminho de render que parece ok em uma GPU pode apresentar flicker, banding ou crashes raros em outra—especialmente em volta de vídeo, câmera e gráficos customizados.
iOS é mais fechado, mas atualizações do SO ainda alteram comportamento: fluxos de permissão, peculiaridades do teclado/autofill, regras de sessão de áudio e políticas de tarefas em background podem mudar entre versões menores.
Plataformas nativas expõem as APIs “reais” primeiro. Quando o SO muda, SDKs e documentação nativas geralmente refletem isso imediatamente, e ferramentas de plataforma (Xcode/Android Studio, logs do sistema, símbolos de crash) se alinham com o que está rodando nos dispositivos.
Stacks multiplataforma adicionam outra camada de tradução: o framework, seu runtime/rendering e plugins. Quando surge um caso de borda, você depura tanto seu app quanto a bridge.
Risco de dependência: atualizações, breaking changes e qualidade de plugins
Atualizações de framework podem introduzir mudanças de runtime (threading, rendering, input de texto, handling de gestos) que só falham em certos dispositivos. Plugins podem ser piores: alguns são wrappers finos; outros embutem código nativo pesado com manutenção inconsistente.
Checklist: vetando bibliotecas de terceiros em caminhos críticos
- Manutenção: lançamentos recentes, triagem ativa de issues, propriedade clara.
- Paridade nativa: usa APIs oficiais da plataforma (não hooks privados/sem suporte).
- Desempenho: benchmarks, evita cópias/allocs extras, hops mínimos de bridge.
- Modos de falha: fallbacks graciosos, timeouts e relatórios de erro.
- Compatibilidade: testada entre versões do SO, dispositivos OEM e vendors de GPU.
- Observabilidade: logs, símbolos de crash e casos de teste reproduzíveis.
- Segurança de upgrade: disciplina semver, changelogs e notas de migração.
Em escala, confiabilidade raramente é sobre um bug—é sobre reduzir o número de camadas onde surpresas podem se esconder.
Gráficos, mídia e ML: quando o nativo é uma vantagem clara
Itere com segurança usando snapshots
Mantenha demos estáveis enquanto ajusta a fluidez da UI com snapshots e rollback.
Algumas cargas de trabalho penalizam mesmo pequenas quantidades de overhead. Se seu app precisa de FPS sustentado alto, trabalho pesado de GPU ou controle estrito sobre decodificação e buffers, frameworks nativos geralmente vencem porque podem usar os caminhos mais rápidos da plataforma diretamente.
Workloads que favorecem fortemente o nativo
Nativo é uma escolha clara para cenas 3D, experiências AR, jogos em alta FPS, edição de vídeo e apps centrados em câmera com filtros em tempo real. Esses casos não são só “pesados em computação”—são pesados em pipeline: você está movendo texturas e frames grandes entre CPU, GPU, câmera e encoders dezenas de vezes por segundo.
Cópias extras, frames atrasados ou sincronização desencontrada aparecem imediatamente como frames perdidos, aquecimento excessivo ou controles lentos.
Acesso direto a APIs de GPU, codecs e aceleração
No iOS, código nativo pode falar com Metal e com a stack de mídia do sistema sem camadas intermediárias. No Android, pode acessar Vulkan/OpenGL e codecs da plataforma via NDK e APIs de mídia.
Isso importa porque submissão de comandos GPU, compilação de shaders e gerenciamento de texturas são sensíveis a como o app agenda trabalho.
Pipelines de renderização e uploads de textura (em alto nível)
Um pipeline típico em tempo real é: capturar ou carregar frames → converter formatos → upload de texturas → rodar shaders na GPU → compor UI → apresentar.
Código nativo pode reduzir overhead mantendo dados em formatos amigáveis à GPU por mais tempo, agrupando draw calls e evitando uploads repetidos de textura. Mesmo uma conversão desnecessária por frame (por exemplo, RGBA ↔ YUV) pode adicionar custo suficiente para quebrar reprodução suave.
Inferência ML: throughput, latência e consumo
ML on‑device frequentemente depende de delegates/backends (Neural Engine, GPU, DSP/NPU). Integração nativa tende a expor esses recursos mais cedo e com mais opções de tunning—importante quando você se importa com latência de inferência e bateria.
Estratégia híbrida: módulos nativos para hotspots
Nem sempre você precisa de um app totalmente nativo. Muitas equipes mantêm UI multiplataforma para a maioria das telas e adicionam módulos nativos para os hotspots: pipelines de câmera, renderizadores customizados, engines de áudio ou inferência ML.
Assim você entrega desempenho quase nativo onde importa, sem reescrever todo o resto.
Escolher um framework é menos sobre ideologia e mais sobre casar expectativas do usuário com o que o dispositivo deve fazer. Se seu app parece instantâneo, fica frio e se mantém suave sob estresse, usuários raramente perguntam com o que ele foi construído.
Matriz prática de decisão
Use estas perguntas para restringir rapidamente:
- Expectativas do usuário: este é um app utilitário onde hiccups são toleráveis, ou uma experiência onde stutter quebra confiança (bancos, navegação, colaboração ao vivo, ferramentas criativas)?
- Necessidades de hardware: precisa do pipeline de câmera, periféricos Bluetooth, sensores, processamento background, áudio de baixa latência, AR ou trabalho pesado de GPU? Quanto mais “perto do metal”, mais o nativo compensa.
- Prazo e velocidade de iteração: multiplataforma pode reduzir time‑to‑market para UI simples e fluxos compartilhados. Nativo pode ser mais rápido para tuning de performance porque você trabalha direto com tooling e APIs da plataforma.
- Habilidades da equipe e contratação: uma equipe forte em iOS/Android entregará código nativo de alta qualidade mais rápido. Uma equipe pequena com experiência web pode alcançar um MVP funcional antes com multiplataforma—se as restrições de desempenho forem moderadas.
Se estiver prototipando direções múltiplas, pode validar flows rapidamente antes de investir em otimização nativa profunda. Por exemplo, equipes às vezes usam Koder.ai para gerar um web app funcional (React + Go + PostgreSQL) via chat, testar UX e modelo de dados, e então optar por uma build móvel nativa ou híbrida quando as telas críticas de desempenho estiverem definidas.
O que “híbrido” realmente significa (e por que frequentemente vence)
Híbrido não precisa significar “web dentro de um app”. Para produtos críticos de desempenho, híbrido geralmente significa:
- Core nativo + lógica de domínio compartilhada: mantenha networking, state e lógica de domínio compartilhados, enquanto UI e partes sensíveis ao desempenho permanecem nativas.
- Shell nativo + UI compartilhada quando seguro: use UI compartilhada para telas majoritariamente estáticas ou baseadas em formulários, e mantenha views com muitas animações ou em tempo real nativas.
Essa abordagem limita risco: você pode otimizar os caminhos mais quentes sem reescrever tudo.
Meça primeiro, depois decida
Antes de se comprometer, construa um pequeno protótipo da tela mais difícil (por exemplo, feed ao vivo, timeline do editor, mapa + overlays). Meça estabilidade de frames, latência de entrada, memória e bateria ao longo de 10–15 minutos. Use esses dados—não palpites—para escolher.
Se usar uma ferramenta assistida por IA como Koder.ai nas iterações iniciais, trate‑a como multiplicador de velocidade para explorar arquitetura e UX—não como substituto do perfilamento em dispositivo. Quando você mira uma experiência crítica de desempenho, a mesma regra vale: meça em dispositivos reais, defina orçamentos de performance e mantenha os caminhos críticos (renderização, input, mídia) o mais próximos do nativo que suas exigências demandarem.
Evite otimização prematura
Comece tornando o app correto e observável (profiling básico, logging e orçamentos de performance). Otimize apenas quando puder apontar um gargalo que os usuários realmente sentirão. Isso evita semanas gastas aparando milissegundos em código que não está no caminho crítico.