O que a indexação de banco de dados realmente faz
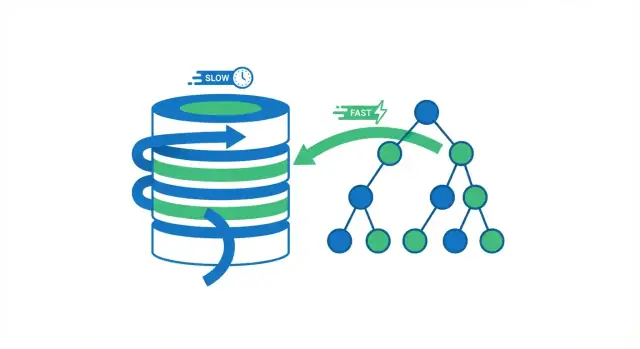
Um índice de banco de dados é uma estrutura de busca separada que ajuda o banco a encontrar linhas mais rápido. Não é uma segunda cópia da sua tabela. Pense nisso como as páginas de índice de um livro: você usa o índice para ir perto do lugar certo e então lê a página exata (linha) que precisa.
Sem um índice, o banco muitas vezes tem apenas uma opção segura: ler muitas linhas para verificar quais batem com a sua consulta. Isso pode ser aceitável quando a tabela tem alguns milhares de linhas. À medida que a tabela cresce para milhões de linhas, “ver mais linhas” vira mais leituras de disco, mais pressão de memória e mais trabalho da CPU — então a mesma consulta que antes parecia instantânea começa a ficar lenta.
O que um índice muda (e o que não muda)
Índices reduzem a quantidade de dados que o banco precisa inspecionar para responder perguntas como “encontre o pedido com ID 123” ou “busque usuários com este email”. Em vez de escanear tudo, o banco segue uma estrutura compacta que estreita rapidamente a busca.
Mas indexação não é uma solução universal. Algumas consultas ainda precisam processar muitas linhas (relatórios amplos, filtros de baixa seletividade, agregações pesadas). E índices têm custos reais: armazenamento extra e gravações mais lentas, porque inserts e updates também precisam atualizar o índice.
O que você vai aprender neste guia
Você verá:
- por que evitar varreduras completas de tabela é o grande ganho de velocidade
- como estruturas comuns de índice (como B-tree) tornam buscas rápidas
- quais consultas se beneficiam mais e quando não ajudam
- como escolher índices compostos/cobridores e validá‑los com um plano EXPLAIN
- como manter índices ao longo do tempo para que o desempenho não se degrade silenciosamente
O ganho central de velocidade: evitar varreduras completas
Quando um banco executa uma consulta, tem duas opções amplas: escanear a tabela inteira linha a linha, ou pular diretamente para as linhas que batem. A maior parte dos ganhos de indexação vem de evitar leituras desnecessárias.
Varredura completa vs. busca por índice
Uma varredura completa da tabela é exatamente o que parece: o banco lê cada linha, verifica se ela satisfaz a condição WHERE e só então retorna resultados. Isso é aceitável para tabelas pequenas, mas fica mais lento de forma previsível à medida que a tabela cresce — mais linhas significa mais trabalho.
Usando um índice, o banco pode frequentemente evitar ler a maioria das linhas. Em vez disso, consulta primeiro o índice (uma estrutura compacta feita para busca) para encontrar onde as linhas correspondentes estão e depois lê apenas essas linhas específicas.
Uma analogia simples
Pense em um livro. Se quiser cada página que mencione “fotossíntese”, você poderia ler o livro inteiro (varredura completa). Ou poderia usar o índice do livro, pular para as páginas listadas e ler apenas essas seções (busca por índice). A segunda abordagem é mais rápida porque você pula quase todas as páginas.
Por que menos leituras normalmente significa consultas mais rápidas
Bancos gastam muito tempo esperando por leituras — especialmente quando os dados não estão em memória. Diminuir o número de linhas (e páginas) que o banco precisa tocar normalmente reduz:
- leituras de disco/SSD
- tempo de CPU gasto avaliando filtros
- pressão de memória ao trazer dados desnecessários para o cache
Quando o ganho de velocidade aparece
Indexação ajuda mais quando os dados são grandes e o padrão de consulta é seletivo (por exemplo, buscar 20 linhas correspondentes em 10 milhões). Se sua consulta já retorna a maior parte das linhas, ou a tabela cabe confortavelmente em memória, uma varredura completa pode ser tão rápida — ou até mais rápida.
Como as estruturas de índice tornam as buscas rápidas
Índices funcionam porque organizam valores para que o banco possa pular perto do que você quer em vez de checar cada linha.
Índices B-tree: o cavalo de trabalho padrão
A estrutura de índice mais comum em bancos SQL é a B-tree (ou “B+tree”). Conceitualmente:
- os valores ficam ordenados
- o índice é dividido em páginas (blocos) que apontam para outras páginas e, por fim, para as linhas da tabela
Por ser ordenada, uma B-tree é ótima para tanto buscas de igualdade (WHERE email = ...) quanto consultas por intervalo (WHERE created_at >= ... AND created_at < ...). O banco navega até a vizinhança certa de valores e então varre para frente em ordem.
O que “logarítmico” significa (sem matemática)
Dizem que buscas em B-tree são “logarítmicas”. Na prática, isso significa: conforme sua tabela cresce de milhares para milhões de linhas, o número de passos para encontrar um valor cresce devagar, não proporcionalmente.
Em vez de “o dobro de dados significa o dobro do trabalho”, é mais como “muito mais dados significa apenas alguns passos extras de navegação”, porque o banco segue ponteiros por um pequeno número de níveis na árvore.
Alguns motores também oferecem índices hash. Eles podem ser muito rápidos para checagens de igualdade exata porque o valor é transformado em um hash e usado para localizar a entrada diretamente.
A troca: índices hash geralmente não ajudam com intervalos ou leituras ordenadas, e disponibilidade/comportamento variam entre bancos.
Detalhes de engine diferem, a ideia permanece
PostgreSQL, MySQL/InnoDB, SQL Server e outros armazenam e usam índices de formas distintas (tamanho de página, clustering, colunas incluídas, verificações de visibilidade). Mas o conceito central é o mesmo: índices criam uma estrutura compacta e navegável que permite localizar linhas correspondentes com muito menos trabalho do que escanear a tabela inteira.
Consultas que mais se beneficiam de índices
Índices não aceleram “SQL” em geral — aceleram padrões de acesso específicos. Quando um índice casa com a forma como sua consulta filtra, junta ou ordena, o banco pode pular direto para as linhas relevantes em vez de ler a tabela toda.
Padrões de consulta mais amigáveis a índices
1) Filtros WHERE (especialmente em colunas seletivas)
Se sua consulta frequentemente reduz uma tabela grande para um pequeno conjunto de linhas, um índice é geralmente o primeiro lugar a procurar. Um exemplo clássico é buscar um usuário por identificador.
Sem um índice em users.email, o banco pode ter de escanear cada linha:
SELECT * FROM users WHERE email = '[email protected]';
Com um índice em email, ele localiza rapidamente a(s) linha(s) correspondente(s) e para.
2) Chaves de JOIN (foreign keys e chaves referenciadas)
Joins são onde “pequenas ineficiências” viram grandes custos. Se você une orders.user_id com users.id, indexar as colunas de join (tipicamente orders.user_id e a chave primária users.id) ajuda o banco a casar linhas sem escaneamentos repetidos.
3) ORDER BY (quando você quer resultados já ordenados)
Ordenar é caro quando o banco precisa coletar muitas linhas e ordená‑las depois. Se você frequentemente roda:
SELECT * FROM orders WHERE user_id = 42 ORDER BY created_at DESC;
um índice que alinhe user_id e a coluna de ordenação pode permitir ao engine ler as linhas na ordem necessária em vez de ordenar um grande resultado intermediário.
4) GROUP BY (quando o agrupamento alinha com um índice)
Agrupar pode se beneficiar quando o banco consegue ler os dados em ordem agrupada. Não é garantia, mas se você costuma agrupar por uma coluna que também é usada para filtrar (ou é naturalmente agrupada no índice), o engine pode fazer menos trabalho.
Índices B-tree são especialmente bons para condições de intervalo — pense em datas, preços e consultas “entre”:
SELECT * FROM orders
WHERE created_at >= '2025-01-01' AND created_at < '2025-02-01';
Para dashboards, relatórios e telas de “atividade recente”, esse padrão é onipresente, e um índice na coluna de intervalo costuma trazer melhoria imediata.
O tema é simples: índices ajudam quando espelham como você busca e ordena. Se suas consultas se alinham com esses padrões de acesso, o banco faz leituras direcionadas em vez de varreduras amplas.
Seletividade: por que alguns índices não ajudam
Um índice ajuda principalmente quando reduz bastante o número de linhas que o banco precisa tocar. Essa propriedade chama‑se seletividade.
O que “seletividade” significa na prática
Seletividade é basicamente: quantas linhas batem para um dado valor? Uma coluna altamente seletiva tem muitos valores distintos, então cada busca bate em poucas linhas.
- Alta seletividade:
email, user_id, order_number (frequentemente únicos ou quase)
- Baixa seletividade:
is_active, is_deleted, status com poucos valores comuns
Com alta seletividade, um índice pula direto para um pequeno conjunto de linhas. Com baixa seletividade, o índice aponta para um grande trecho da tabela — então o banco ainda tem de ler e filtrar muito.
Por que índices booleanos (e semelhantes) desapontam
Considere uma tabela com 10 milhões de linhas e uma coluna is_deleted onde 98% são false. Um índice em is_deleted não ajuda muito para:
SELECT * FROM orders WHERE is_deleted = false;
O conjunto de correspondência ainda é quase a tabela inteira. Usar o índice pode até ser mais lento que uma varredura sequencial porque o engine faz trabalho extra pulando entre entradas do índice e páginas da tabela.
Por que o banco pode ignorar seu índice
Os planejadores estimam custos. Se um índice não reduzir o trabalho o suficiente — porque muitas linhas batem, ou porque a consulta também precisa da maior parte das colunas — eles podem escolher uma varredura completa.
Distribuição de dados não é fixa. Uma coluna status pode começar bem distribuída e depois derivar para que um valor domine. Se estatísticas não forem atualizadas, o planejador pode tomar decisões ruins, e um índice que antes ajudava pode parar de compensar.
Índices compostos e cobridores (e ordem das colunas)
Índices de coluna única são um bom começo, mas muitas consultas reais filtram por uma coluna e ordenam ou filtram por outra. É aí que índices compostos (multi‑coluna) brilham: um índice pode servir várias partes da consulta.
Ordem das colunas: a regra “da esquerda para a direita”
A maioria dos bancos (especialmente com B-tree) só consegue usar um índice composto de forma eficiente a partir das colunas mais à esquerda. Pense no índice como ordenado primeiro por A, depois por B, e assim por diante.
Isso significa:
- um índice em (account_id, created_at) é ótimo para consultas que filtram por
account_id e então ordenam/filtram por created_at
- o mesmo índice geralmente não ajuda uma consulta que filtra apenas por
created_at (porque não é a coluna mais à esquerda)
Um padrão prático: timelines por conta
Uma carga comum é “mostre os eventos mais recentes para esta conta”. Esse padrão:
SELECT id, created_at, type
FROM events
WHERE account_id = ?
ORDER BY created_at DESC
LIMIT 50;
frequentemente se beneficia muito de:
CREATE INDEX events_account_created_at
ON events (account_id, created_at);
O banco pula direto para a porção do índice daquela conta e lê em ordem temporal, em vez de escanear e ordenar um conjunto grande.
Índices cobridores: quando o índice é a resposta
Um índice cobridor contém todas as colunas que a consulta precisa, de modo que o banco pode retornar resultados apenas a partir do índice sem olhar as linhas da tabela (menos leituras, menos I/O randômico).
Cuidado: adicionar colunas extras pode tornar o índice grande e caro.
Não crie compostos largos “por via das dúvidas”
Índices compostos largos podem desacelerar gravações e consumir muito armazenamento. Adicione‑os apenas para consultas específicas de alto valor e verifique com um plano EXPLAIN e medições reais antes e depois.
Índices são muitas vezes descritos como “velocidade grátis”, mas não são. Estruturas de índice precisam ser mantidas sempre que a tabela muda, e consomem recursos reais.
INSERT/UPDATE/DELETE mais lentos (porque todo índice precisa ser atualizado)
Quando você INSERT uma nova linha, o banco não escreve apenas a linha — também insere entradas correspondentes em cada índice dessa tabela. O mesmo vale para DELETE e muitos UPDATEs.
Por isso “mais índices” podem desacelerar cargas com muitas gravações. Um UPDATE que altera uma coluna indexada pode ser especialmente caro: o banco pode ter de remover a antiga entrada do índice e adicionar a nova (e em algumas engines isso pode disparar splits de página ou rebalanceamentos internos). Se seu app faz muitas gravações — eventos de pedido, dados de sensores, logs de auditoria — indexar tudo pode deixar o banco lento mesmo com leituras rápidas.
Cada índice ocupa espaço em disco. Em tabelas grandes, índices podem rivalizar (ou exceder) o tamanho da própria tabela, especialmente se houver vários índices sobrepostos.
Isso também afeta memória. Bancos dependem fortemente de caching; se seu working set inclui vários índices grandes, o cache precisa manter mais páginas para continuar rápido. Caso contrário, você verá mais I/O em disco e desempenho menos previsível.
O equilíbrio prático
Indexar é escolher o que acelerar. Se a sua carga é de leitura, mais índices podem valer a pena. Se é de escrita, priorize índices que suportem suas consultas mais importantes e evite duplicatas. Uma regra útil: adicione um índice só quando você conseguir nomear a consulta que ele ajuda — e verifique que o ganho na leitura compensa o custo de escrita e manutenção.
Como provar que um índice ajuda: EXPLAIN e medições
Adicionar um índice parece que deve ajudar — mas você pode (e deve) verificar. As duas ferramentas que tornam isso concreto são o plano de consulta (EXPLAIN) e medições reais antes/depois.
Leia o plano: o índice está realmente sendo usado?
Execute EXPLAIN (ou EXPLAIN ANALYZE) na consulta exata que importa.
- Tipo de varredura: um Seq Scan / Full Table Scan significa que o banco está lendo a tabela inteira. Um Index Scan / Index Seek (ou Index Range Scan) sugere que está usando um índice para reduzir linhas.
- Linhas estimadas vs. reais (especialmente em
EXPLAIN ANALYZE): se o plano estimou 100 linhas mas tocou na prática 100.000, o otimizador errou — muitas vezes porque as estatísticas estão desatualizadas ou o filtro é menos seletivo que o esperado.
- Passos de sort: se você vê uma operação explícita Sort, o banco está ordenando depois de buscar. Se um novo índice casa com o
ORDER BY, esse sort pode desaparecer, o que é um grande ganho.
Meça corretamente: antes/depois, mesmas condições
Faça benchmark da consulta com os mesmos parâmetros, em dados representativos, e capture latência (p50/p95) e linhas processadas.
Cuidado com cache: a primeira execução pode ser mais lenta porque os dados não estão em memória; execuções repetidas podem parecer “resolvidas” mesmo sem índice. Para não se enganar, compare várias execuções e foque em mudanças de plano (índice usado, menos linhas lidas) além do tempo bruto.
Se EXPLAIN ANALYZE mostra menos linhas tocadas e menos passos caros (como sorts), você provou que o índice ajuda — não apenas torceu para que ajudasse.
Erros comuns que anulam benefícios de índice
Você pode adicionar o “índice certo” e ainda assim não ver melhoria se a consulta estiver escrita de forma que impeça o banco de usá‑lo. Esses problemas são sutis, porque a consulta continua correta — só que forçada para um plano mais lento.
Anti‑padrões que bloqueiam uso de índice
1) Wildcards no início
Quando você escreve:
WHERE name LIKE '%term'
o banco não consegue usar um índice B-tree normal para pular ao ponto certo, porque não sabe onde em ordem começaria “%term”. Frequentemente cai numa varredura ampla.
Alternativas:
- Use uma busca por prefixo:
WHERE name LIKE 'term%'.
- Se precisar de “contains”, considere um índice especializado (full‑text/trigram) em vez de esperar que um índice padrão ajude.
2) Funções em colunas indexadas
Isso parece inofensivo:
WHERE LOWER(email) = '[email protected]'
Mas LOWER(email) altera a expressão, então o índice em email não pode ser usado diretamente.
Alternativas:
- Armazene dados normalizados (por exemplo, emails em minúsculas) e consulte
WHERE email = ....
- Ou crie um índice de expressão/função (depende do banco) especificamente para
LOWER(email).
Bloqueadores de índice que as pessoas perdem
Conversões implícitas de tipo: comparar tipos diferentes pode obrigar o banco a castar um lado, o que pode desabilitar o índice. Exemplo: comparar uma coluna integer com uma literal string.
Collations/encodings inconsistentes: se a comparação usa uma collation diferente da que o índice foi criado (comum em texto entre localidades), o otimizador pode evitar o índice.
Checklist rápido: “por que meu índice não é usado?”
- A condição começa com um wildcard (
LIKE '%x')?
- Você aplica uma função na coluna indexada (
LOWER(col), DATE(col), CAST(col)) ?
- Os tipos são idênticos em ambos os lados (sem cast implícito)?
- A collation/locale é consistente para a comparação?
- O predicado é seletivo o suficiente (não corresponde a grande parte da tabela)?
- Você filtra/ordena nas colunas mais à esquerda de um índice composto?
- Você checou o plano com
EXPLAIN para confirmar a escolha do banco?
Manutenção de índices: estatísticas, bloat e saúde a longo prazo
Índices não são “coloque e esqueça”. Com o tempo, dados mudam, padrões de consulta mudam e a forma física de tabelas e índices se distancia do ideal. Um índice bem escolhido pode ficar menos efetivo — ou até prejudicial — se não for mantido.
Estatísticas: o mapa do planejador pode ficar desatualizado
A maioria dos bancos usa um planejador para escolher como rodar uma consulta: qual índice usar, ordem de joins, se uma busca por índice vale a pena. Para isso, o planejador usa estatísticas — resumos sobre distribuição de valores, contagem de linhas e skew.
Quando estatísticas estão velhas, as estimativas de linhas do planejador podem estar muito erradas. Isso leva a escolhas ruins de plano, como escolher um índice que retorna muito mais linhas que o esperado ou pular um índice que seria mais rápido.
Correção rotineira: agende atualizações regulares de estatísticas (geralmente ANALYZE ou similar). Após grandes cargas, deletes massivos ou churn significativo, atualize as estatísticas mais cedo.
Bloat e fragmentação: quando estruturas ficam bagunçadas
À medida que linhas são inseridas, atualizadas e deletadas, índices podem acumular bloat (páginas extras sem dados úteis) e fragmentação (dados espalhados que aumentam I/O). O resultado é índices maiores e mais leituras, especialmente para consultas por intervalo.
Correção rotineira: periodicamente reconstrua ou reorganize índices muito usados quando crescerem desproporcionalmente ou quando o desempenho degradar. Ferramentas e impacto variam por banco; trate isso como uma operação medida, não uma regra cega.
Monitore ao longo do tempo, não apenas uma vez
Monitore:
- consultas lentas (latência, frequência e piores candidatos)
- uso de índices (índices nunca usados vs. índices “quentes”)
- crescimento de tamanho de índices e mudanças de plano repentinas
Esse feedback ajuda a detectar quando manutenção é necessária — e quando um índice deve ser ajustado ou removido. Para mais sobre validar melhorias, veja /blog/how-to-prove-an-index-helps-explain-and-measurements.
Um fluxo prático para adicionar o índice certo
Adicionar um índice deve ser uma mudança deliberada, não um palpite. Um fluxo leve mantém o foco em ganhos mensuráveis e evita “proliferação de índices”.
Comece com evidência: logs de consultas lentas, traços APM ou relatos de usuários. Escolha uma consulta que seja lenta e frequente — um relatório raro de 10s importa menos que uma busca comum de 200 ms.
Capture o SQL exato e o padrão de parâmetros (por exemplo: WHERE user_id = ? AND status = ? ORDER BY created_at DESC LIMIT 50). Pequenas diferenças mudam qual índice ajuda.
2) Meça uma linha de base
Registre latência atual (p50/p95), linhas escaneadas e impacto CPU/IO. Salve o plano atual (EXPLAIN / EXPLAIN ANALYZE) para comparar depois.
3) Projete o menor índice útil
Escolha colunas que correspondam a como a consulta filtra e ordena. Prefira o índice mínimo que faça o plano parar de escanear grandes ranges.
Teste em staging com volume de dados parecido com produção. Índices podem parecer ótimos em datasets pequenos e desapontar em escala.
Em tabelas grandes, use opções online quando suportadas (por exemplo, PostgreSQL CREATE INDEX CONCURRENTLY). Agende mudanças em horários de menor tráfego se o banco puder bloquear gravações.
Rerun a mesma consulta e compare:
- forma do plano (mudou de full scan para acesso por índice?)
- tempo de execução e linhas escaneadas
- impacto nas gravações (latência de insert/update)
6) Tenha um plano de rollback
Se o índice aumentar o custo de gravação ou lotar memória, remova‑o limpo (por ex., DROP INDEX CONCURRENTLY onde disponível). Mantenha a migração reversível.
7) Documente o “porquê”
Na migração ou nas notas de esquema, escreva qual consulta o índice serve e qual métrica melhorou. O futuro você (ou um colega) saberá por que ele existe e quando é seguro deletar.
Onde o Koder.ai se encaixa nesse fluxo
Se você está construindo um serviço novo e quer evitar “proliferação de índices” cedo, o Koder.ai pode ajudar a iterar mais rápido no ciclo completo: gerar um app React + Go + PostgreSQL a partir do chat, ajustar migrations de schema/índices conforme requisitos mudam e exportar o código quando quiser assumir manualmente. Na prática, isso facilita ir de “este endpoint está lento” para “aqui está o plano EXPLAIN, o índice mínimo e uma migration reversível” sem esperar por um pipeline tradicional completo.
Quando indexação não basta (e o que fazer em seguida)
Índices são uma alavanca enorme, mas não são um botão mágico de “deixe rápido”. Às vezes a parte lenta de uma requisição acontece após o banco encontrar as linhas certas — ou seu padrão de consulta faz da indexação a escolha errada.
Casos em que indexação não é a correção principal
Se sua consulta já usa um bom índice mas ainda está lenta, procure por:
- Paginação ausente (ou incorreta): buscar a página 1.000 com
OFFSET 999000 pode ser lento mesmo com índices. Prefira paginação por keyset (ex.: “me dê linhas após o último id/timestamp visto”).
- Retornar dados demais: selecionar linhas largas (
SELECT *) ou retornar dezenas de milhares de registros pode tornar-se gargalo na rede, serialização JSON ou processamento da aplicação.
- Mismatch de esquema: joins excessivos por normalização extrema, valores buscáveis dentro de blobs JSON/texto, ou tipos errados podem forçar operações caras que índices não mascaram totalmente.
Otimizações complementares que frequentemente importam mais
- Reescrever a consulta: remova joins desnecessários, evite funções em colunas indexadas no WHERE e simplifique predicados com muitos ORs.
- Limitar colunas e linhas: selecione só o que precisa, adicione LIMITs sensatos e pagine resultados conscientemente.
- Cache: cacheie leituras quentes no nível da aplicação ou use um cache read‑through para consultas repetidas caras.
- Particionamento: se a maioria das consultas atinge dados “recentes”, particione por tempo (ou outra fronteira natural) para reduzir o espaço de busca.
Se quiser um método mais profundo para diagnosticar gargalos, combine isso com o fluxo em /blog/how-to-prove-an-index-helps.
Priorize: corrija o maior gargalo primeiro
Não chute. Meça onde o tempo é gasto (execução do banco vs. linhas retornadas vs. código da aplicação). Se o banco está rápido mas a API está lenta, mais índices não vão ajudar.
Checklist rápido