OLTP vs OLAP: o que são (sem jargão)
Quando as pessoas dizem “OLTP” e “OLAP”, estão falando de duas maneiras bem diferentes de usar um banco de dados.
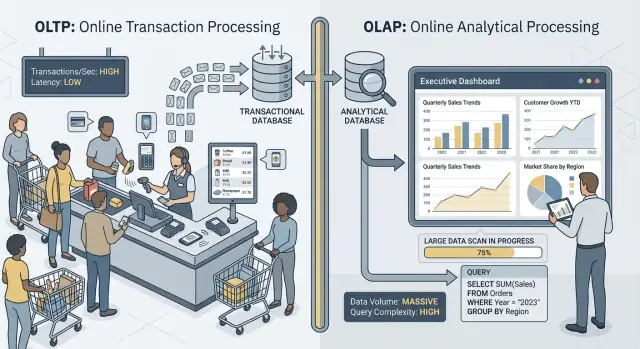
OLTP: o banco que faz o negócio rodar
OLTP (Online Transaction Processing) é a carga por trás das ações do dia a dia que precisam ser rápidas e corretas sempre. Pense: “salvar essa mudança agora.”
Tarefas típicas de OLTP incluem criar um pedido, atualizar inventário, registrar um pagamento ou alterar o endereço de um cliente. Essas operações geralmente são pequenas (poujas linhas), frequentes e precisam responder em milissegundos porque uma pessoa ou outro sistema está esperando.
OLAP: o banco que explica o negócio
OLAP (Online Analytical Processing) é a carga usada para entender o que aconteceu e por quê. Pense: “varrer muitos dados e sumarizá-los.”
Tarefas típicas de OLAP incluem dashboards, relatórios de tendência, análise de coortes, forecasting e perguntas do tipo “fatiar e cortar”, como: “Como a receita mudou por região e categoria de produto nos últimos 18 meses?” Essas consultas frequentemente leem muitas linhas, fazem agregações pesadas e podem rodar por segundos (ou minutos) sem estarem “erradas”.
Mesmos dados, objetivos diferentes — e necessidades diferentes
A ideia principal é simples: OLTP otimiza para escritas rápidas e consistentes e leituras pequenas, enquanto OLAP otimiza para leituras grandes e cálculos complexos. Como os objetivos diferem, as melhores configurações do banco, índices, layout de armazenamento e abordagem de escala costumam diferir também.
Também repare na palavra: raramente, não nunca. Algumas equipes pequenas conseguem compartilhar um banco por algum tempo, especialmente com volume modesto de dados e disciplina de query. Seções posteriores cobrem o que quebra primeiro, padrões comuns de separação e como mover relatórios da produção com segurança.
Exemplos rápidos
- Checkout (OLTP): um cliente clica em “Pagar”, e seu app grava um pedido, o status do pagamento e atualiza o inventário.
- Dashboard de relatórios (OLAP): um gerente abre um painel que agrega milhares (ou milhões) de pedidos para mostrar taxa de conversão, ticket médio e tendências semanais.
Objetivos diferentes, métricas de sucesso diferentes
OLTP e OLAP podem ambos “usar SQL”, mas são otimizados para trabalhos distintos — e isso aparece no que cada um considera sucesso.
OLTP: velocidade, concorrência e correção
Sistemas OLTP (transacionais) alimentam operações do dia a dia: fluxos de checkout, atualizações de conta, reservas, ferramentas de suporte. As prioridades são simples:
- Tempos de resposta rápidos para leituras/escritas pequenas (pense em milissegundos)
- Muitos usuários concorrentes sem degradação
- Correção e consistência, porque um saldo errado ou pedido duplicado é um problema real de negócio
O sucesso costuma ser medido por métricas de latência como p95/p99, taxa de erro e comportamento sob pico de concorrência.
OLAP: varrer, agregar e flexibilidade
Sistemas OLAP (analíticos) respondem perguntas como “O que mudou neste trimestre?” ou “Qual segmento churnou após o novo preço?” Essas consultas frequentemente:
- Varrem grandes volumes de dados em muitas linhas
- Realizam agregações (SUM, COUNT, percentis) e joins
- Mudam frequentemente enquanto analistas exploram e refinam perguntas
Sucesso aqui é mais sobre throughput de consultas, tempo-para-insight e a capacidade de rodar queries complexas sem afinar cada relatório manualmente.
Por que “um sistema para tudo” cria trade-offs
Quando você força ambas as cargas em um único banco, está pedindo para ele ser ótimo simultaneamente em transações pequenas e de alto volume e em grandes varreduras exploratórias. O resultado costuma ser um compromisso: OLTP ganha latência imprevisível, OLAP é restringido para proteger a produção, e as equipes brigam sobre quais consultas são “permitidas”. Objetivos separados merecem métricas de sucesso separadas — e geralmente sistemas separados.
Contenção de recursos: quando analytics rouba das transações
Quando OLTP (as transações do seu app) e OLAP (relatórios e análises) rodam no mesmo banco, disputam pelos mesmos recursos finitos. O resultado não é só “relatórios mais lentos”. Frequentemente são checkouts mais lentos, logins travados e instabilidades imprevisíveis do app.
CPU e memória: queries longas vs consultas curtas
Consultas analíticas tendem a ser longas e pesadas: joins em tabelas grandes, agregações, ordenações e agrupamentos. Podem monopolizar núcleos de CPU e, tão importante quanto, memória para hash joins e buffers de ordenação.
Enquanto isso, consultas transacionais são pequenas e sensíveis à latência. Se a CPU estiver saturada ou a pressão de memória for alta, essas consultas pequenas começam a esperar pelas grandes — mesmo que cada transação só precise de alguns milissegundos de trabalho real.
I/O em disco: varreduras grandes vs muitas leituras/escritas pequenas
Analytics costuma disparar varreduras de tabela e ler muitas páginas sequencialmente. OLTP faz o oposto: muitas leituras aleatórias pequenas mais escritas constantes em índices e logs.
Junte-os e o subsistema de armazenamento precisa lidar com padrões de acesso incompatíveis. Caches que ajudavam o OLTP podem ser “lavados” por varreduras analíticas, e a latência de escrita pode disparar quando o disco está ocupado transmitindo dados para relatórios.
Pressão no pool de conexões e enfileiramento
Alguns analistas executando consultas amplas podem prender conexões por minutos. Se sua aplicação usa um pool de tamanho fixo, as requisições se enfileiram esperando por uma conexão livre. Esse efeito de enfileiramento pode fazer um sistema saudável parecer quebrado: a latência média pode estar aceitável, mas as caudas (p95/p99) ficam dolorosas.
O que os usuários realmente percebem
Externamente, isso aparece como timeouts, fluxos de checkout lentos, resultados de busca demorados e comportamento instável — muitas vezes “só durante relatórios” ou “só no fim do mês”. A equipe de app vê erros; a equipe de analytics vê queries lentas; o problema real é a contenção compartilhada por baixo.