O que é (e o que não é) uma réplica de leitura
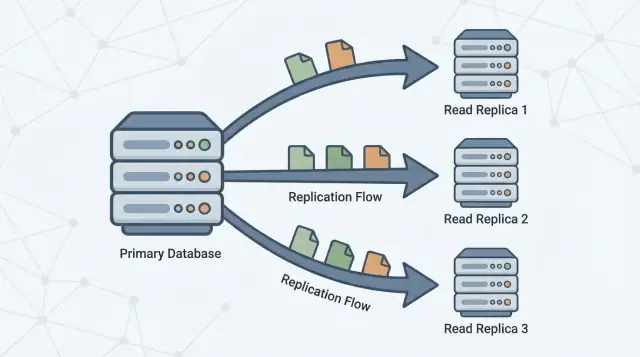
Uma réplica de leitura é uma cópia do seu banco de dados principal (frequentemente chamado de primário) que se mantém atualizada recebendo mudanças continuamente. Sua aplicação pode enviar consultas somente de leitura (como SELECT) para a réplica, enquanto o primário continua a processar todas as gravações (como INSERT, UPDATE e DELETE).
A promessa básica
A promessa é simples: mais capacidade de leitura sem aumentar a pressão sobre o primário.
Se seu app tem muito tráfego de “buscar” — páginas iniciais, páginas de produto, perfis de usuário, dashboards — mover parte dessas leituras para uma ou mais réplicas pode liberar o primário para focar nas gravações e nas leituras críticas. Em muitas configurações, isso exige mudanças mínimas na aplicação: você mantém um banco como fonte de verdade e adiciona réplicas como lugares adicionais para consultar.
O que uma réplica de leitura não é
Réplicas de leitura são úteis, mas não são um botão mágico de desempenho. Elas não:
- Aumentam a capacidade de gravação. Todas as gravações ainda chegam ao primário.
- Consertam consultas lentas. Se uma consulta é ineficiente (falta de índice, varreduras grandes, junções ruins), ela provavelmente será lenta também nas réplicas — só que lenta em outro lugar.
- Substituem um bom projeto de esquema e dados. Réplicas não resolvem hotspots, linhas muito grandes ou uma tabela gigante que contém tudo.
- Eliminam a necessidade de monitoramento. Réplicas adicionam partes móveis: lag, limites de conexão e comportamento de failover.
Expectativa para o restante do guia
Pense em réplicas como uma ferramenta de escala de leitura com trade-offs. O resto deste artigo explica quando elas realmente ajudam, as formas mais comuns pelas quais falham, e como conceitos como lag de replicação e consistência eventual afetam o que os usuários veem quando você começa a ler de uma cópia em vez do primário.
Por que réplicas de leitura existem
Um único servidor de banco de dados primário frequentemente começa parecendo “grande o suficiente”. Ele processa gravações (inserções, atualizações, deleções) e também responde a todas as requisições de leitura (SELECT) da sua aplicação, dashboards e ferramentas internas.
Conforme o uso cresce, leituras geralmente se multiplicam mais rápido que gravações: cada visualização de página pode disparar várias consultas, telas de busca podem se desdobrar em muitas buscas, e consultas analíticas podem varrer muitas linhas. Mesmo se o volume de gravação for moderado, o primário ainda pode se tornar um gargalo porque precisa fazer duas tarefas ao mesmo tempo: aceitar mudanças com segurança e rapidez, e servir um volume de leitura crescente com baixa latência.
Separando leituras de gravações
Réplicas de leitura existem para dividir esse trabalho. O primário fica focado em processar gravações e manter a “fonte da verdade”, enquanto uma ou mais réplicas lidam com consultas somente de leitura. Quando sua aplicação consegue rotear algumas consultas para réplicas, você reduz a pressão de CPU, memória e I/O no primário. Isso normalmente melhora a capacidade de resposta geral e deixa mais margem para picos de gravação.
Replicação em uma frase
Replicação é o mecanismo que mantém réplicas atualizadas copiando mudanças do primário para outros servidores. O primário registra mudanças, e as réplicas aplicam essas mudanças para poderem responder consultas usando dados quase idênticos.
Esse padrão é comum em vários sistemas de banco de dados e serviços gerenciados (por exemplo PostgreSQL, MySQL e variantes em nuvem). A implementação exata difere, mas o objetivo é o mesmo: aumentar a capacidade de leitura sem forçar o primário a escalar verticalmente para sempre.
Como a replicação funciona (modelo mental simples)
Pense no banco primário como a “fonte da verdade”. Ele aceita cada gravação — criando pedidos, atualizando perfis, registrando pagamentos — e atribui uma ordem definida a essas mudanças.
Uma ou mais réplicas então seguem o primário, copiando essas mudanças para poderem responder consultas de leitura (como “mostre meu histórico de pedidos”) sem colocar mais carga no primário.
O fluxo básico
- Primário aceita gravações e as registra num log durável (o nome exato varia conforme o banco).
- Réplica(s) transmitem ou buscam essas entradas de log do primário.
- Réplica(s) reproduzem as mesmas mudanças na mesma ordem, gradualmente alcançando o primário.
Leituras podem ser servidas pelas réplicas, mas gravações continuam indo ao primário.
Replicação síncrona vs assíncrona (visão geral)
A replicação pode ocorrer em dois modos amplos:
- Síncrona: o primário espera que uma réplica (ou um quórum) confirme que recebeu a mudança antes de considerar a gravação “confirmada”. Isso reduz leituras obsoletas, mas pode aumentar a latência de gravação e deixar as gravações sensíveis a problemas de rede/réplica.
- Assíncrona: o primário confirma a gravação imediatamente, e as réplicas se atualizam depois. Isso mantém as gravações rápidas e resilientes, mas as réplicas podem ficar temporariamente atrás.
Lag de replicação e “consistência eventual”
Esse atraso — réplicas ficando atrás do primário — é chamado de lag de replicação. Não é automaticamente uma falha; muitas vezes é o trade-off normal que você aceita para escalar leituras.
Para o usuário final, o lag aparece como consistência eventual: depois que você muda algo, o sistema ficará consistente em todos os lugares, mas não necessariamente instantaneamente.
Exemplo: você atualiza seu endereço de e-mail e atualiza a página de perfil. Se a página for servida por uma réplica que está alguns segundos atrás, você pode ver temporariamente o e-mail antigo — até a réplica aplicar a atualização e “alcançar” o primário.
Quando réplicas de leitura realmente ajudam
Réplicas de leitura ajudam quando seu banco primário está saudável para gravações mas fica sobrecarregado atendendo tráfego de leitura. Elas são mais eficazes quando você pode descarregar uma parcela relevante do SELECT sem mudar como você grava dados.
Sinais de que você é bound por leitura (não por gravação)
Procure padrões como:
- CPU alta no primário durante picos de tráfego, enquanto o throughput de gravação não está anormalmente alto
- Alta proporção de consultas
SELECT comparada a INSERT/UPDATE/DELETE
- Consultas de leitura ficando mais lentas durante picos, mesmo com gravações estáveis
- Saturação do pool de conexões causada por endpoints pesados de leitura (páginas de produto, feeds, resultados de busca)
Como confirmar que leituras são o problema (métricas a checar)
Antes de adicionar réplicas, valide com alguns sinais concretos:
- CPU vs I/O: O primário está com CPU no limite quando a latência de leitura sobe? Ou o gargalo é I/O de disco?
- Mix de consultas: Percentual de tempo gasto em
SELECT (do slow query log/APM).
- p95/p99 de latência de leitura: Monitore endpoints de leitura e latência de consultas separadamente.
- Taxa de acerto do buffer/cache: Uma baixa taxa pode significar que leituras estão forçando acesso a disco.
- Principais consultas por tempo total: Uma consulta cara pode dominar a “carga de leitura”.
Não pule correções mais baratas
Frequentemente, o melhor primeiro passo é ajustar: adicionar o índice certo, reescrever uma consulta, reduzir chamadas N+1 ou cachear leituras quentes. Essas mudanças podem ser mais rápidas e mais baratas do que operar réplicas.
Checklist rápido: réplicas vs ajuste
Escolha réplicas se:
- A maior parte da carga é leitura e as leituras já estão razoavelmente otimizadas
- Você pode tolerar leituras ocasionalmente obsoletas para as consultas descarregadas
- Precisa de capacidade adicional rapidamente sem fazer mudanças arriscadas em esquema/consultas
Escolha ajuste primeiro se:
- Poucas consultas dominam o tempo total de leitura
- Índices faltantes ou junções ineficientes são óbvios
- Leituras são lentas mesmo com baixo tráfego (sinal de problemas de design de consulta)
Casos de uso em que se encaixam melhor
Réplicas de leitura são mais valiosas quando o primário lida com gravações (checkouts, cadastros, atualizações), mas uma grande parcela do tráfego é intensiva em leitura. Numa arquitetura primário–réplica, direcionar as consultas corretas para réplicas melhora o desempenho sem mudar funcionalidades da aplicação.
1) Dashboards e análises que não devem atrasar transações
Dashboards costumam executar consultas longas: agrupamentos, filtros em grandes intervalos, ou junções múltiplas. Essas consultas competem com trabalho transacional por CPU, memória e cache.
Uma réplica de leitura é um bom lugar para:
- Cargas de trabalho internas de relatório
- Dashboards administrativos
- Visões de métricas diárias/semanais
Você mantém o primário focado em transações rápidas e previsíveis enquanto as leituras analíticas escalam de forma independente.
Navegação de catálogo, perfis de usuários e feeds de conteúdo podem gerar um alto volume de consultas semelhantes. Quando essa pressão de escala de leitura é o gargalo, réplicas podem absorver tráfego e reduzir picos de latência.
Isso é especialmente eficaz quando leituras têm muitos misses de cache (muitas consultas únicas) ou quando não dá para confiar apenas no cache da aplicação.
3) Jobs em background que varrem muitos dados
Exportações, backfills, recomputação de resumos e jobs tipo “encontre todos os registros que batem X” podem causar thrash no primário. Executar essas varreduras numa réplica costuma ser mais seguro.
Apenas garanta que o job tolere consistência eventual: com lag de replicação, ele pode não ver as atualizações mais recentes.
Se você atende usuários globalmente, posicionar réplicas mais perto deles pode reduzir o tempo de ida e volta. O trade-off é maior exposição a leituras obsoletas durante lag ou problemas de rede, então é melhor para páginas onde “quase atualizado” é aceitável (navegação, recomendações, conteúdo público).
Onde réplicas podem piorar as coisas
Estruture uma camada de dados segura
Crie uma camada de acesso a dados limpa que possa ser estendida para separação de leitura/escrita depois.
Réplicas são ótimas quando “próximo o suficiente” é aceitável. Elas falham quando seu produto assume que cada leitura reflete imediatamente a última gravação.
O sintoma clássico: “eu acabei de atualizar, por que não mudou?”
Um usuário edita o perfil, envia um formulário ou altera configurações — e o próximo carregamento vem de uma réplica alguns segundos atrás. A atualização teve sucesso, mas o usuário vê dados antigos, tenta novamente, faz submissões duplicadas ou perde confiança.
Isso é particularmente doloroso em fluxos onde o usuário espera confirmação imediata: mudar e-mail, alternar preferências, enviar um documento, postar um comentário e depois ser redirecionado.
Telas que “precisam estar atualizadas” (não arrisque aqui)
Algumas leituras não toleram obsolescência, nem que seja momentânea:
- Carrinhos e totais de checkout
- Saldos de carteira, pontos de fidelidade, contagens de inventário
- Telas de “meu pagamento foi processado?”
Se uma réplica estiver atrás, você pode mostrar total de carrinho errado, vender estoque em excesso ou exibir saldo desatualizado. Mesmo que o sistema corrija depois, a experiência do usuário (e o volume de suporte) sofre.
Ferramentas administrativas precisam da verdade mais fresca
Dashboards internos frequentemente guiam decisões reais: revisão de fraude, suporte ao cliente, atendimento de pedidos, moderação e respostas a incidentes. Se uma ferramenta administrativa lê de réplicas, você corre o risco de agir sobre dados incompletos — por exemplo, reembolsar um pedido já reembolsado ou perder o último status.
Correção prática: rotear “leia suas gravações” para o primário
Um padrão comum é rotear condicionalmente:
- Após um usuário gravar, envie as leituras de confirmação subsequentes para o primário por uma janela curta (segundos a minutos).
- Mantenha leituras de fundo, anônimas ou não críticas nas réplicas.
Isso preserva os benefícios das réplicas sem transformar consistência em um jogo de adivinhação.
Entendendo lag de replicação e leituras obsoletas
Lag de replicação é o atraso entre quando uma gravação é confirmada no primário e quando essa mesma mudança fica visível numa réplica. Se sua app ler de uma réplica durante esse atraso, pode retornar resultados “obsoletos” — dados que eram verdadeiros há pouco, mas já não são.
Por que o lag acontece
Lag é normal e normalmente cresce sob estresse. Causas comuns:
- Picos de carga no primário: muitas gravações significam mais mudanças para enviar e aplicar.
- Réplica subdimensionada ou ocupada: a réplica não aplica mudanças tão rápido quanto elas chegam (CPU, I/O de disco).
- Latência ou jitter de rede: atrasos no fluxo de replicação.
- Transações grandes / atualizações em massa: uma grande mudança pode demorar para serializar, transferir e reproduzir.
Como leituras obsoletas aparecem no comportamento do produto
Lag não afeta só “frescura” — afeta a correção do ponto de vista do usuário:
- Um usuário atualiza o perfil e ao atualizar a página vê o valor antigo.
- Contagens de “mensagens não lidas” ou badges derivam porque os contadores são computados a partir de linhas ligeiramente antigas.
- Telas de administração/relatórios perdem pedidos, reembolsos ou mudanças de status recentes.
Comece decidindo o que sua feature tolera:
- Adicione uma janela de tolerância: “Dados podem ter até 30 segundos de atraso” é aceitável para muitos dashboards.
- Roteie leitura-após-gravação para o primário: depois que um usuário altera algo, leia aquela entidade do primário por um curto período.
- Mensagens na UI: defina expectativas (“Atualizando…”, “Pode demorar alguns segundos para aparecer”).
- Lógica de retry: se uma leitura crítica não encontra um registro recém-gravado, tente novamente no primário ou após pequeno atraso.
O que monitorar e alertar
Monitore lag de réplica (tempo/bytes atrás), taxa de aplicação da réplica, erros de replicação e CPU/disk I/O da réplica. Alerta quando o lag ultrapassar sua tolerância acordada (por exemplo, 5s, 30s, 2m) e quando o lag continuar crescendo com o tempo (sinal de que a réplica não vai conseguir alcançar sem intervenção).
Escala de leitura vs escala de gravação (trade-offs chave)
Ganhe créditos por publicar
Compartilhe o que você construiu com Koder.ai e ganhe créditos pelo programa de conteúdo.
Réplicas de leitura são uma ferramenta para escala de leitura: adicionar mais lugares para servir SELECT. Não são uma ferramenta para escala de gravação: aumentar quantas operações de INSERT/UPDATE/DELETE seu sistema pode aceitar.
Escalando leituras: para que réplicas servem
Quando você adiciona réplicas, você adiciona capacidade de leitura. Se sua aplicação está limitada por endpoints pesados de leitura (páginas de produto, feeds, buscas), você pode espalhar essas consultas por várias máquinas.
Isso costuma melhorar:
- Latência de consulta sob carga (menos contenção no primário)
- Throughput de leituras (mais CPU/memória/I/O disponível para
SELECT)
- Isolamento para leituras pesadas, como relatórios, para que não interfiram no tráfego transacional
Escalando gravações: o que réplicas não fazem
Uma ideia errada comum é “mais réplicas = mais throughput de gravação.” Num setup primário–réplica típico, todas as gravações ainda vão para o primário. De fato, mais réplicas podem aumentar levemente o trabalho do primário, porque ele precisa gerar e enviar dados de replicação para cada réplica.
Se sua dor é throughput de gravação, réplicas não vão resolver. Você geralmente mira outras abordagens (tuning de queries/índices, batch, particionamento/sharding ou mudar o modelo de dados).
Limites de conexão e pooling: o gargalo oculto
Mesmo que réplicas deem mais CPU para leituras, você ainda pode bater em limites de conexão primeiro. Cada nó de banco tem um número máximo de conexões concorrentes, e adicionar réplicas pode multiplicar os lugares que sua app poderia conectar — sem reduzir a demanda total.
Regra prática: use pooling de conexões (ou um pooler) e mantenha contagens intencionais de conexões por serviço. Caso contrário, réplicas podem simplesmente virar “mais bancos para sobrecarregar”.
Custo: capacidade não é grátis
Réplicas adicionam custos reais:
- Mais nós (gasto com computação)
- Mais armazenamento (cada réplica geralmente armazena uma cópia completa)
- Maior esforço operacional (monitoramento de lag, estratégias de backup/restore, alterações de esquema, resposta a incidentes)
O trade-off é simples: réplicas podem comprar folga para leituras e isolamento, mas adicionam complexidade e não movem o teto de gravação.
Alta disponibilidade e failover: o que réplicas podem fazer
Réplicas de leitura podem melhorar a disponibilidade de leitura: se seu primário estiver sobrecarregado ou temporariamente indisponível, você ainda pode servir parte do tráfego somente de leitura a partir das réplicas. Isso pode manter páginas visíveis ao cliente (para conteúdo que tolera ligeira obsolescência) e reduzir o impacto de um incidente no primário.
O que réplicas não fornecem sozinhas é um plano completo de alta disponibilidade. Uma réplica normalmente não está pronta para aceitar gravações automaticamente, e uma “cópia legível existe” é diferente de “o sistema pode aceitar gravações de forma segura e rápida”.
Failover normalmente significa: detectar falha do primário → escolher uma réplica → promovê-la a novo primário → redirecionar gravações (e normalmente leituras) para o nó promovido.
Alguns bancos gerenciados automatizam grande parte disso, mas a ideia central é a mesma: você está mudando quem pode aceitar gravações.
Riscos chave para planejar
- Dados desatualizados na réplica: a réplica pode estar atrás. Se você promovê-la, pode perder as gravações mais recentes que não chegaram.
- Evitar split-brain: você deve prevenir que dois nós aceitem gravações ao mesmo tempo. Por isso promoções costumam ser controladas por uma autoridade única (plano de controle gerenciado, sistema de quórum ou procedimentos operacionais rigorosos).
- Roteamento e caches: sua app precisa de um jeito confiável para trocar alvos — connection strings, DNS, proxies ou um roteador de banco. Garanta que o tráfego de gravação não continue indo para o primário antigo por engano.
Teste como se fosse uma feature
Trate failover como algo a praticar. Faça exercícios em staging (e com cuidado em produção em janelas de baixo risco): simule perda do primário, meça tempo de recuperação, verifique roteamento e confirme que a aplicação lida com períodos somente leitura e reconexões de forma limpa.
Padrões práticos de roteamento (separação leitura/gravação)
Réplicas só ajudam se o tráfego realmente alcançá-las. “Separação de leitura e gravação” é o conjunto de regras que envia gravações ao primário e leituras elegíveis às réplicas — sem quebrar a correção.
Padrão 1: divisão na aplicação
A abordagem mais simples é roteamento explícito na camada de acesso a dados:
- Todas as gravações (
INSERT/UPDATE/DELETE, mudanças de esquema) vão para o primário.
- Apenas leituras selecionadas podem usar uma réplica.
Isso é fácil de raciocinar e de desfazer. Também é onde você pode codificar regras de negócio como “após checkout, sempre ler o status do pedido no primário por um tempo”.
Padrão 2: divisão via proxy ou driver
Algumas equipes preferem um proxy de banco ou driver inteligente que entende endpoints de primário vs réplica e roteia com base no tipo de consulta ou nas configurações da conexão. Isso reduz mudanças no código da aplicação, mas cuidado: proxies não conseguem saber com segurança quais leituras são “seguras” do ponto de vista do produto.
Escolhendo quais consultas podem ir para réplicas
Bons candidatos:
- Workloads de analytics, relatórios e dashboards
- Páginas de busca/navegação onde dados levemente obsoletos são aceitáveis
- Jobs em background que fazem retries e não precisam do valor mais recente
Evite rotear leituras que seguem imediatamente uma gravação do usuário (por exemplo, “atualizar perfil → recarregar perfil”) a menos que você tenha uma estratégia de consistência.
Transações e consistência de sessão
Dentro de uma transação, mantenha todas as leituras no primário.
Fora de transações, considere sessões “leia-sua-gravação”: depois de uma gravação, fixe esse usuário/sessão ao primário por um TTL curto, ou direcione consultas de acompanhamento específicas ao primário.
Comece pequeno e meça
Adicione uma réplica, roteie um conjunto limitado de endpoints/consultas e compare antes/depois:
- CPU do primário e read IOPS
- Utilização da réplica
- Taxa de erro e percentis de latência
- Incidentes ligados a leituras obsoletas
Expanda o roteamento somente quando o impacto for claro e seguro.
Monitoramento e operações básicas
Faça mudanças com confiança
Teste migrações e reversões com segurança enquanto avalia os compromissos da replicação.
Réplicas de leitura não são “configure e esqueça”. São servidores de banco extras com limites de desempenho próprios, modos de falha e tarefas operacionais. Um pouco de disciplina de monitoramento costuma ser a diferença entre “réplicas ajudaram” e “réplicas adicionaram confusão”.
O que observar (as poucas métricas que importam)
Foque em indicadores que expliquem sintomas visíveis ao usuário:
- Lag da réplica: quão atrás do primário a réplica está (segundos, bytes ou posição WAL/LSN dependendo do banco). Esse é seu aviso cedo para leituras obsoletas.
- Erros de replicação: conexões quebradas, falhas de auth, disco cheio ou problemas de slot de replicação. Trate isso como incidente, não ruído.
- Latência de consulta (p50/p95) em réplica vs primário: réplicas podem ficar lentas mesmo com primário bem, por diferença de cache, hardware ou consultas longas.
- Taxa de acerto do cache: uma réplica com muitos misses pode ter latência maior após reinícios ou mudanças de tráfego.
Planejamento de capacidade: quantas réplicas são necessárias?
Comece com uma réplica se seu objetivo é descarregar leituras. Adicione mais quando houver uma restrição clara:
- Throughput de leitura: uma réplica pode não aguentar pico de QPS ou consultas analíticas pesadas.
- Isolamento: dedique uma réplica para workloads de relatório para que dashboards não roubem recursos do tráfego de usuário.
- Geografia: uma réplica por região reduz latência de leitura, mas aumenta custo operacional.
Regra prática: escale réplicas somente depois de confirmar que leituras são o gargalo (não índices, consultas lentas ou cache da aplicação).
Tarefas operacionais comuns
- Backups: decida onde os backups rodam. Fazer backup a partir de uma réplica pode reduzir carga no primário, mas verifique requisitos de consistência e saúde da réplica.
- Mudanças de esquema: teste migrações com replicação em mente (DDL longos podem aumentar lag). Coordene rollouts para que app e esquema permaneçam compatíveis durante a propagação.
- Janelas de manutenção: patching ou reinício de réplicas reduz temporariamente a capacidade de leitura. Planeje rotações para não ficar abaixo da folga necessária.
Checklist de troubleshooting: “réplicas estão lentas”
- Verifique o lag da réplica: se estiver alto, usuários podem estar tentando repetir ações ou vendo dados obsoletos.
- Compare slow query logs na réplica vs primário: consultas de relatório muitas vezes aparecem aqui.
- Verifique CPU, memória, disk I/O e rede no host da réplica.
- Procure contenção de locks ou transações longas no primário que atrasem a replicação.
- Confirme que seu roteamento de leitura não está sobrecarregando uma única réplica (balanceamento desigual).
- Valide que índices existem nas réplicas (elas devem espelhar o primário) e que estatísticas estão atualizadas.
Alternativas e um framework simples de decisão
Réplicas de leitura são uma das ferramentas para escala de leitura, mas raramente são a primeira alavanca. Antes de adicionar complexidade operacional, verifique se uma solução mais simples traz o mesmo resultado.
Alternativas para tentar primeiro
Cache pode remover classes inteiras de leituras do banco. Para páginas majoritariamente de leitura (detalhes de produto, perfis públicos, configuração), um cache na aplicação ou CDN pode reduzir muito a carga — sem introduzir lag de replicação.
Índices e otimização de consultas frequentemente superam réplicas no caso comum: algumas consultas caras consumindo CPU. Adicionar o índice certo, reduzir colunas retornadas, evitar N+1 e consertar junções ruins pode transformar “precisamos de réplicas” em “só precisávamos de um plano melhor”.
Views materializadas / pré-agregação ajudam quando o workload é inerentemente pesado (analytics, dashboards). Em vez de reexecutar consultas complexas, você armazena resultados calculados e atualiza em um cronograma.
Quando considerar particionamento/sharding
Se suas gravações são o gargalo (hot rows, contenção de locks, limites de I/O de escrita), réplicas não ajudarão muito. É aí que particionar tabelas por tempo/cliente ou shardear por ID de cliente pode espalhar a carga de gravação e reduzir contenção. É um passo arquitetural maior, mas resolve a restrição real.
Um framework simples de decisão
Faça quatro perguntas:
- Qual é o objetivo? Reduzir latência de leitura, descarregar relatórios ou melhorar alta disponibilidade?
- Quão frescas precisam ser as leituras? Se você não tolera leituras obsoletas, réplicas podem causar problemas visíveis.
- Qual é seu orçamento? Réplicas acrescentam custo infra e esforço operacional contínuo.
- Quanta complexidade você pode absorver? Separação leitura/gravação, lidar com consistência eventual e testar failover não são triviais.
Se você está prototipando um produto novo ou levantando um serviço rapidamente, ajuda incorporar essas restrições na arquitetura desde cedo. Por exemplo, equipes que usam o Koder.ai muitas vezes começam com um único primário por simplicidade e só migraram para réplicas quando dashboards, feeds ou relatórios internos passaram a competir com tráfego transacional. Um fluxo de trabalho orientado ao planejamento facilita decidir quais endpoints toleram consistência eventual e quais devem sempre ler a partir do primário.
Se quiser ajuda para escolher um caminho, veja /pricing para opções ou navegue por guias relacionados em /blog.