26 de ago. de 2025·8 min
Como construir produtos AI-first com modelos na lógica do aplicativo
Guia prático para construir produtos AI-first onde o modelo dirige decisões: arquitetura, prompts, ferramentas, dados, avaliação, segurança e monitoramento.
O que significa construir um produto AI-first
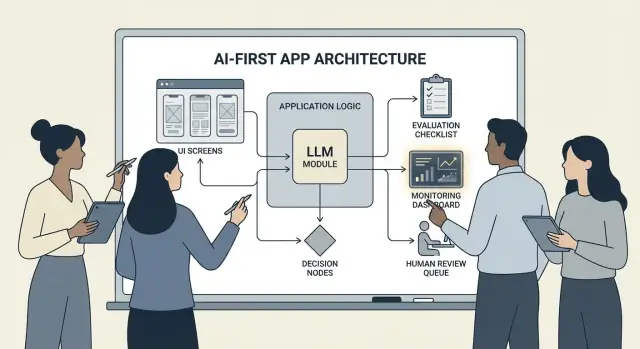
Construir um produto AI-first não é “adicionar um chatbot”. Significa que o modelo é uma parte real e funcional da lógica da sua aplicação — do mesmo jeito que um motor de regras, um índice de busca ou um algoritmo de recomendação.
Seu app não está apenas usando IA; ele é projetado em torno do fato de que o modelo vai interpretar entradas, escolher ações e produzir saídas estruturadas das quais o resto do sistema depende.
Na prática: em vez de codificar todas as rotas de decisão (“se X então fazer Y”), você deixa o modelo lidar com as partes difusas — linguagem, intenção, ambiguidade, priorização — enquanto seu código lida com o que precisa ser preciso: permissões, pagamentos, gravações no banco de dados e aplicação de políticas.
Quando AI-first é adequado (e quando não é)
AI-first funciona melhor quando o problema tem:
- Muitas entradas válidas (texto livre, documentos bagunçados, objetivos variados dos usuários)
- Demasiados casos-limite para manter regras manualmente
- Valor em julgamento, sumarização ou síntese em vez de determinismo perfeito
Automação baseada em regras costuma ser melhor quando os requisitos são estáveis e exatos — cálculos fiscais, lógica de inventário, checagens de elegibilidade ou fluxos de conformidade onde a saída deve ser a mesma sempre.
Objetivos de produto que o AI-first costuma apoiar
Times normalmente adotam lógica dirigida por modelos para:
- Aumentar a velocidade: redigir respostas, extrair campos, roteirizar pedidos mais rápido
- Personalizar experiências: adaptar explicações, planos ou recomendações
- Apoiar decisões: destacar trade-offs, gerar opções, resumir evidências
Compromissos que você precisa aceitar (e projetar para)
Modelos podem ser imprevisíveis, às vezes errar com confiança, e seu comportamento pode mudar conforme prompts, provedores ou contexto recuperado mudam. Eles também adicionam custo por requisição, podem introduzir latência e levantam preocupações de segurança e confiança (privacidade, saídas nocivas, violações de política).
A mentalidade correta é: o modelo é um componente, não uma caixa mágica de respostas. Trate-o como uma dependência com especificações, modos de falha, testes e monitoramento — assim você obtém flexibilidade sem apostar o produto em esperança.
Escolha o caso de uso certo e defina o sucesso
Nem todo recurso se beneficia de colocar um modelo no assento do motorista. Os melhores casos AI-first começam com um trabalho claro a ser feito e terminam com um resultado mensurável que você pode acompanhar semana a semana.
Comece pelo trabalho, não pelo modelo
Escreva uma história de trabalho em uma frase: “Quando ___, eu quero ___, para que eu possa ___.” Em seguida, torne o resultado mensurável.
Exemplo: “Quando recebo um e-mail longo de cliente, eu quero uma resposta sugerida que esteja de acordo com nossas políticas, para que eu possa responder em menos de 2 minutos.” Isso é muito mais acionável do que “adicione um LLM ao e-mail”.
Mapeie os pontos de decisão
Identifique os momentos em que o modelo escolherá ações. Esses pontos de decisão devem ser explícitos para que você possa testá-los.
Pontos de decisão comuns incluem:
- Classificar intenção e rotear para o fluxo correto
- Decidir se deve fazer uma pergunta de esclarecimento ou prosseguir
- Selecionar ferramentas (busca, consulta ao CRM, redação, criação de ticket)
- Decidir quando escalar para um humano
Se você não consegue nomear as decisões, não está pronto para lançar lógica dirigida por modelo.
Escreva critérios de aceitação para o comportamento
Trate o comportamento do modelo como qualquer outro requisito de produto. Defina o que é “bom” e “ruim” em linguagem simples.
Por exemplo:
- Bom: usa a política mais recente, cita o ID correto do pedido, faz uma pergunta clara se faltar informação
- Ruim: inventa descontos, referencia localidades não suportadas ou responde sem checar dados necessários
Esses critérios se tornam a base para seu conjunto de avaliação mais tarde.
Identifique restrições cedo
Liste as restrições que moldam suas escolhas de design:
- Tempo (metas de latência de resposta)
- Orçamento (custo por tarefa)
- Conformidade (tratamento de PII, requisitos de auditoria)
- Locales suportados (idiomas, tom, expectativas culturais)
Defina métricas de sucesso que você pode monitorar
Escolha um pequeno conjunto de métricas atreladas ao trabalho:
- Taxa de conclusão de tarefas
- Precisão (ou aderência à política) em casos representativos
- CSAT ou avaliação qualitativa do usuário
- Tempo economizado por tarefa (ou tempo para resolução)
Se você não consegue medir sucesso, acabará discutindo impressões em vez de melhorar o produto.
Projete o fluxo orientado por IA e os limites do sistema
Um fluxo AI-first não é “uma tela que chama um LLM”. É uma jornada ponta a ponta onde o modelo toma certas decisões, o produto as executa com segurança e o usuário permanece orientado.
Mapeie o loop ponta a ponta
Comece desenhando o pipeline como uma cadeia simples: entradas → modelo → ações → saídas.
- Entradas: o que o usuário fornece (texto, arquivos, seleções) mais o contexto do app (plano da conta, workspace, atividade recente).
- Etapa do modelo: pelo que o modelo é responsável (classificar, redigir, resumir, escolher próxima ação).
- Ações: o que seu sistema pode fazer (buscar, criar uma tarefa, atualizar um registro, enviar um e-mail).
- Saídas: o que o usuário vê (um rascunho, uma explicação, uma tela de confirmação, um erro com próximos passos).
Esse mapa força clareza sobre onde a incerteza é aceitável (rascunho) versus onde não é (mudanças de cobrança).
Desenhe limites do sistema: modelo vs código determinístico
Separe caminhos determinísticos (cheques de permissão, regras de negócio, cálculos, gravações no banco) das decisões dirigidas por modelo (interpretação, priorização, geração em linguagem natural).
Uma regra útil: o modelo pode recomendar, mas o código deve verificar antes de qualquer coisa irreversível.
Decida onde o modelo roda
Escolha um runtime com base nas restrições:
- Servidor: melhor para dados privados, ferramentas consistentes e logs de auditoria.
- Cliente: útil para assistências leves e privacidade por processamento local, mas mais difícil de controlar.
- Edge: menor latência global, porém dependências limitadas.
- Híbrido: divida detecção de intenção rápida na borda e trabalho pesado no servidor.
Planeje latência, custo e permissões de dados
Defina um orçamento por requisição de latência e custo (incluindo retries e chamadas de ferramentas) e projete a UX em torno disso (streaming, resultados progressivos, “continuar em segundo plano”).
Documente fontes de dados e permissões necessárias em cada etapa: o que o modelo pode ler, o que pode escrever e o que exige confirmação explícita do usuário. Isso vira um contrato para engenharia e confiança.
Padrões de arquitetura: orquestração, estado e rastros
Quando um modelo faz parte da lógica do app, “arquitetura” não é só servidores e APIs — é como você executa de forma confiável uma cadeia de decisões do modelo sem perder o controle.
Orquestração: o maestro do trabalho com o modelo
Orquestração é a camada que gerencia como uma tarefa de IA executa de ponta a ponta: prompts e templates, chamadas de ferramentas, memória/contexto, retries, timeouts e fallbacks.
Bons orquestradores tratam o modelo como um componente em um pipeline. Eles decidem qual prompt usar, quando chamar uma ferramenta (busca, banco, email, pagamento), como comprimir ou buscar contexto e o que fazer se o modelo retornar algo inválido.
Se você quer avançar mais rápido da ideia para orquestração funcional, um fluxo de trabalho de prototipagem pode ajudar a criar esses pipelines sem reconstruir a infraestrutura do app do zero. Por exemplo, Koder.ai permite que times criem apps web (React), backends (Go + PostgreSQL) e até apps móveis (Flutter) via chat — então itere em fluxos como “entradas → modelo → chamadas de ferramentas → validações → UI” com recursos como modo de planejamento, snapshots e rollback, além de exportação de código-fonte quando estiver pronto para assumir o repositório.
Máquinas de estado para tarefas multi-etapa
Experiências multi-etapa (triagem → coletar info → confirmar → executar → resumir) funcionam melhor quando modeladas como workflow ou máquina de estados.
Um padrão simples é: cada passo tem (1) entradas permitidas, (2) saídas esperadas e (3) transições. Isso evita conversas que divagam e torna casos-limite explícitos — por exemplo, o que acontece se o usuário mudar de ideia ou fornecer informação parcial.
Raciocínio single-shot vs. multi-turn
Single-shot funciona bem para tarefas contidas: classificar uma mensagem, redigir uma resposta curta, extrair campos de um documento. É mais barato, rápido e fácil de validar.
Raciocínio multi-turn é melhor quando o modelo precisa perguntar para esclarecer ou quando ferramentas são necessárias de forma iterativa (ex.: planejar → buscar → refinar → confirmar). Use-o intencionalmente e limite loops com tetos de tempo/etapas.
Idempotência: evite efeitos colaterais repetidos
Modelos fazem retry. Redes falham. Usuários clicam duas vezes. Se uma etapa de IA pode causar efeitos colaterais — enviar um e-mail, reservar, cobrar — torne-a idempotente.
Táticas comuns: anexar uma chave de idempotência a cada ação “executar”, armazenar o resultado da ação e garantir que retries retornem o mesmo resultado em vez de repetir.
Traces: torne cada passo depurável
Adicione rastreabilidade para responder: O que o modelo viu? O que decidiu? Quais ferramentas rodaram?
Registre um rastro estruturado por execução: versão do prompt, entradas, IDs de contexto recuperado, requisições/respostas de ferramentas, erros de validação, retries e a saída final. Isso transforma “a IA fez algo estranho” em uma linha do tempo auditável e corrigível.
Prompting como lógica de produto: contratos e formatos claros
Quando o modelo faz parte da lógica da aplicação, seus prompts deixam de ser “texto” e passam a ser especificações executáveis. Trate-os como requisitos de produto: escopo explícito, saídas previsíveis e controle de mudanças.
Comece com um system prompt que defina o contrato
Seu system prompt deve definir o papel do modelo, o que ele pode e não pode fazer, e as regras de segurança relevantes para seu produto. Mantenha-o estável e reutilizável.
Inclua:
- Papel e objetivo: quem ele é (ex.: “assistente de triagem de suporte”) e o que significa sucesso.
- Limites de escopo: solicitações que ele deve recusar ou escalar.
- Regras de segurança: tratamento de PII, avisos médicos/jurídicos, não chutar respostas.
- Política de ferramentas: quando chamar ferramentas vs. responder diretamente.
Estruture prompts com entradas/saídas claras
Escreva prompts como definições de API: liste as entradas exatas que você fornece (texto do usuário, plano da conta, locale, trechos de política) e as saídas exatas que espera. Adicione 1–3 exemplos que correspondam ao tráfego real, incluindo casos-limite complicados.
Um padrão útil é: Contexto → Tarefa → Restrições → Formato de saída → Exemplos.
Use formatos restritos para resultados legíveis por máquina
Se o código precisa agir sobre a saída, não confie em prosa. Peça JSON que siga um schema e rejeite qualquer outra coisa.
{
"type": "object",
"properties": {
"intent": {"type": "string"},
"confidence": {"type": "number", "minimum": 0, "maximum": 1},
"actions": {
"type": "array",
"items": {"type": "string"}
},
"user_message": {"type": "string"}
},
"required": ["intent", "confidence", "actions", "user_message"],
"additionalProperties": false
}
Versione prompts e faça rollouts com segurança
Armazene prompts em controle de versão, marque releases e faça rollouts como features: deploy em estágios, A/B quando apropriado e rollback rápido. Registre a versão do prompt com cada resposta para depuração.
Construa uma suíte de testes de prompt
Crie um pequeno conjunto representativo de casos (caminho feliz, solicitações ambíguas, violações de política, entradas longas, diferentes locales). Execute-os automaticamente a cada mudança de prompt e falhe o build quando saídas quebrarem o contrato.
Chamada de ferramentas: deixe o modelo decidir, deixe o código executar
Itere sem medo
Experimente prompts e ferramentas e reverta rapidamente quando algo quebrar.
Tool calling é a forma mais limpa de dividir responsabilidades: o modelo decide o que precisa acontecer e qual capacidade usar, enquanto seu código realiza a ação e retorna resultados verificados.
Isso mantém fatos, cálculos e efeitos colaterais (criar tickets, atualizar registros, enviar e-mails) em código determinístico e auditável — em vez de confiar em texto livre.
Projete um conjunto pequeno e intencional de ferramentas
Comece com um punhado de ferramentas que cubram 80% dos pedidos e sejam fáceis de proteger:
- Busca (sua docs/central de ajuda) para responder perguntas sobre o produto
- Consulta ao BD (apenas leitura primeiro) para status de usuário/conta/pedido
- Calculadora para preços, totais, conversões e cálculos baseados em regras
- Ticketing para abrir solicitações de suporte quando o usuário precisar de acompanhamento humano
Mantenha o propósito de cada ferramenta estreito. Uma ferramenta que faz “qualquer coisa” fica difícil de testar e fácil de ser mal utilizada.
Valide entradas, sanitize saídas
Trate o modelo como um chamador não confiável.
- Valide inputs de ferramentas com schemas estritos (tipos, ranges, enums). Rejeite ou corrija argumentos inseguros (ex.: IDs faltando, consultas excessivamente amplas).
- Sanitize outputs de ferramentas antes de devolver ao modelo: remova segredos, normalize formatos e retorne apenas os campos que o modelo precisa.
Isso reduz o risco de prompt-injection via texto recuperado e limita vazamentos acidentais de dados.
Adicione permissões e limites por ferramenta
Cada ferramenta deve aplicar:
- Checagens de permissão (quem pode acessar quais registros, quais ações)
- Rate limits (por usuário/sessão/ferramenta) para reduzir abuso e loops fora de controle
Se uma ferramenta pode alterar estado (ticketing, reembolsos), exija autorização mais forte e escreva um log de auditoria.
Sempre suporte um caminho "sem ferramenta"
Às vezes a melhor ação é nenhuma ação: responder a partir do contexto existente, fazer uma pergunta de esclarecimento ou explicar limitações.
Faça do “sem ferramenta” um resultado de primeira classe para que o modelo não chame ferramentas só para parecer ocupado.
Dados e RAG: faça o modelo aterrissar na sua realidade
Se as respostas do seu produto precisam bater com suas políticas, inventário, contratos ou conhecimento interno, você precisa de uma forma de fundamentar o modelo nos seus dados — não apenas no que ele aprendeu em treino.
RAG vs. fine-tuning vs. contexto simples
- Contexto simples (colar alguns parágrafos no prompt) funciona quando o conhecimento é pequeno, estável e você pode enviar sempre (ex.: uma pequena tabela de preços).
- RAG (Retrieval-Augmented Generation) é melhor quando a informação é grande, muda frequentemente ou precisa de citações (ex.: artigos da central de ajuda, docs de produto, dados específicos de conta).
- Fine-tuning é bom quando você quer estilo/formato consistente ou padrões de domínio — não como modo primário de “armazenar fatos”. Use para melhorar como o modelo escreve e segue regras; combine com RAG para verdade atualizada.
Noções básicas de ingestão: chunking, metadados, atualidade
A qualidade de RAG é majoritariamente um problema de ingestão.
Divida documentos em pedaços apropriados ao modelo (frequentemente algumas centenas de tokens), idealmente alinhados a limites naturais (títulos, entradas de FAQ). Armazene metadados como: título do documento, seção, produto/versão, público, locale e permissões.
Planeje a atualidade: agende reindexação, acompanhe “última atualização” e expire chunks antigos. Um chunk obsoleto que rankea alto degrada silenciosamente a feature.
Citações e respostas calibradas
Faça o modelo citar fontes retornando: (1) resposta, (2) lista de IDs/URLs dos trechos, e (3) uma declaração de confiança.
Se a recuperação for fraca, instrua o modelo a dizer o que não pode confirmar e a oferecer próximos passos (“Não encontrei essa política; aqui está quem contactar”). Evite que ele preencha lacunas com suposições.
Dados privados: controle de acesso e redacção
Aplique controle de acesso antes da recuperação (filtrar por permissões do usuário/organização) e novamente antes da geração (redigir campos sensíveis).
Trate embeddings e índices como stores sensíveis com logs de auditoria.
Quando a recuperação falha: fallbacks graciosos
Se os melhores resultados forem irrelevantes ou vazios, faça fallback para: perguntar para esclarecer, rotear para suporte humano ou mudar para um modo sem RAG que explique limitações em vez de chutar.
Confiabilidade: guardrails, validação e cache
Quando um modelo está dentro da lógica do app, “bom na maioria das vezes” não basta. Confiabilidade significa que usuários veem comportamento consistente, seu sistema pode consumir saídas com segurança e falhas degradam de forma elegante.
Defina objetivos de confiabilidade (antes de aplicar correções)
Anote o que “confiável” significa para o recurso:
- Saídas consistentes: entradas semelhantes devem produzir respostas comparáveis (tom, nível de detalhe, restrições).
- Formatos estáveis: a resposta deve ser parseável sempre (JSON, lista de pontos, campos específicos).
- Comportamento limitado: limites claros sobre o que o modelo deve fazer (não chutar, citar fontes, perguntar quando incerto).
Esses objetivos viram critérios de aceitação para prompts e código.
Guardrails: valide, filtre e aplique políticas
Trate a saída do modelo como entrada não confiável.
- Validação de schema: exija formato estrito (ex.: JSON com chaves obrigatórias) e rejeite qualquer coisa que não parse.
- Filtros de conteúdo: rode checagens de profanidade, detectores de PII ou validadores de política tanto no input do usuário quanto na saída do modelo.
- Regras de negócio: aplique restrições em código (faixas de preço, regras de elegibilidade, ações permitidas), mesmo que o prompt as mencione.
Se a validação falhar, retorne um fallback seguro (perguntar, trocar de template mais simples ou rotear para humano).
Retries que realmente ajudam
Evite repetição cega. Faça retry com um prompt modificado que enderece o modo de falha:
- “Retorne apenas JSON válido. Sem markdown.”
- “Se estiver inseguro, defina
confidencecomo baixa e faça uma pergunta.”
Corte retries e registre o motivo de cada falha.
Pós-processamento determinístico
Use código para normalizar o que o modelo produz:
- canonicalize unidades, datas e nomes
- deduplicar itens
- aplicar regras de ranqueamento ou thresholds
Isso reduz variância e facilita testes.
Cache sem criar problemas de privacidade
Cacheie resultados repetíveis (ex.: consultas idênticas, embeddings compartilhados, respostas de ferramentas) para reduzir custo e latência.
Prefira:
- TTLs curtos para dados específicos de usuário
- chaves de cache que excluem PII bruto (ou façam hash com cuidado)
- flags “não cachear” para fluxos sensíveis
Feito corretamente, o cache melhora consistência sem comprometer a confiança do usuário.
Segurança e confiança: reduzir risco sem matar a UX
Prototipe lógica de IA rapidamente
Crie um fluxo de trabalho centrado em IA com chat e depois itere com segurança usando snapshots e rollback.
Segurança não é uma camada de compliance adicionada no fim. Em produtos AI-first, o modelo pode influenciar ações, redações e decisões — então segurança precisa ser parte do contrato do produto: o que o assistente pode fazer, o que deve recusar e quando pedir ajuda.
Principais riscos para projetar
Nomeie os riscos que seu app realmente enfrenta e mapeie cada um para um controle:
- Dados sensíveis: identificadores pessoais, credenciais, documentos privados e qualquer coisa regulada.
- Orientação prejudicial: instruções que podem facilitar autoagressão, violência, atividades ilegais ou conselhos médicos/financeiros inseguros.
- Viés e resultados injustos: qualidade inconsistente do serviço, recomendações ou decisões entre grupos.
Tópicos permitidos/bloqueados + caminhos de escalonamento
Escreva uma política explícita que seu produto possa aplicar. Seja concreto: categorias, exemplos e respostas esperadas.
Use três níveis:
- Permitido: responder normalmente.
- Restrito: responder com limitações (ex.: informação geral apenas, sem passo a passo).
- Bloqueado: recusar e rotear para um caminho de escalonamento (suporte, recursos ou humano).
O escalonamento deve ser um fluxo de produto, não apenas uma mensagem de recusa. Forneça uma opção “Falar com uma pessoa” e assegure que o handoff inclua o contexto já compartilhado (com consentimento).
Revisão humana para ações de alto impacto
Se o modelo pode desencadear consequências reais — pagamentos, reembolsos, alterações de conta, cancelamentos, exclusão de dados — adicione um checkpoint.
Padrões sólidos incluem: telas de confirmação, “rascunho e depois aprovar”, limites (caps de valor) e fila de revisão humana para casos-limite.
Divulgações, consentimento e políticas testáveis
Informe usuários quando estão interagindo com IA, quais dados são usados e o que é armazenado. Peça consentimento quando necessário, especialmente para salvar conversas ou usar dados para melhorar o sistema.
Trate políticas internas de segurança como código: versioná-las, documentar rationale e adicionar testes (prompts de exemplo + resultados esperados) para que a segurança não regresse a cada mudança de prompt ou modelo.
Avaliação: teste o modelo como qualquer outro componente crítico
Se um LLM pode alterar o que seu produto faz, você precisa de uma forma repetível de provar que ele ainda funciona — antes que usuários descubram regressões por você.
Trate prompts, versões de modelo, schemas de ferramentas e configurações de recuperação como artefatos de release que exigem testes.
Construa um conjunto de avaliação a partir da realidade
Colete intenções reais de usuários a partir de tickets de suporte, consultas de busca, logs de chat (com consentimento) e chamadas de vendas. Transforme-os em casos de teste que incluam:
- Pedidos comuns do dia a dia
- Prompts ambíguos que exigem perguntas de esclarecimento
- Casos-limite (dados faltando, restrições conflitantes, formatos incomuns)
- Cenários sensíveis à política (dados pessoais, conteúdo proibido)
Cada caso deve incluir comportamento esperado: resposta, decisão tomada (ex.: “chamar ferramenta A”) e qualquer estrutura exigida (campos JSON presentes, citações incluídas, etc.).
Escolha métricas que correspondam ao risco do produto
Uma única métrica não capturará qualidade. Use um pequeno conjunto de métricas que mapeiem para resultados do usuário:
- Precisão / sucesso da tarefa: resolveu o objetivo do usuário?
- Groundedness: as afirmações são suportadas por contexto ou fontes?
- Validade de formato: a saída bate com o contrato (JSON, tabela, bullets)?
- Taxa de recusa: recusou quando devia — e evitou recusar quando não devia?
Monitore custo e latência junto com qualidade; um modelo “melhor” que dobra o tempo de resposta pode prejudicar conversões.
Rode avaliações offline a cada mudança
Execute avaliações offline antes do release e após toda mudança em prompt, modelo, ferramenta ou recuperação. Mantenha resultados versionados para comparar execuções e descobrir rapidamente o que quebrou.
Adicione testes online com guardrails
Use testes A/B para medir resultados reais (taxa de conclusão, edições, avaliações de usuários), mas acrescente limites de segurança: defina condições de parada (picos em saídas inválidas, recusas ou erros de ferramenta) e faça rollback automático quando thresholds forem excedidos.
Monitoramento em produção: drift, falhas e feedback
Crie pipelines de orquestração
Converta entradas e chamadas ao modelo/ferramentas em um fluxo real de app testável de ponta a ponta.
Lançar um recurso AI-first não é o ponto final. Com usuários reais, o modelo verá novas formulações, casos-limite e dados em mudança. Monitoramento transforma “funcionou em staging” em “continua funcionando no próximo mês”.
Registre o que importa (sem coletar segredos)
Capture contexto suficiente para reproduzir falhas: intenção do usuário, versão do prompt, chamadas de ferramentas e a saída final do modelo.
Registre entradas/saídas com redacção que preserve a privacidade. Trate logs como dados sensíveis: remova emails, telefones, tokens e textos livres que possam conter detalhes pessoais. Tenha um “modo debug” que você possa ativar temporariamente para sessões específicas em vez de logar tudo por padrão.
Monitore os sinais certos
Vigie taxas de erro, falhas de ferramentas, violações de schema e drift. Concretamente, acompanhe:
- Taxa de sucesso e timeouts em chamadas de ferramenta (o modelo escolheu a ferramenta certa e ela executou?)
- Conformidade de formato/schema (seus validadores rejeitaram?)
- Uso de fallback (com que frequência você teve que rotear para um caminho mais seguro ou simples)
- Bloqueios de segurança (com que frequência você recusou ou sanitizou)
Para drift, compare o tráfego atual com sua baseline: mudanças na mistura de tópicos, idioma, comprimento médio de prompt e intenções “desconhecidas”. Drift nem sempre é ruim — mas é sempre um indicativo para reavaliar.
Alertas, runbooks e resposta a incidentes
Defina thresholds de alerta e runbooks on-call. Alertas devem mapear para ações: reverter uma versão de prompt, desativar uma ferramenta instável, apertar validação ou trocar para um fallback.
Planeje resposta a incidentes para comportamentos inseguros ou incorretos. Defina quem pode acionar switches de segurança, como notificar usuários e como documentar e aprender com o evento.
Feche o ciclo com feedback do usuário
Use loops de feedback: polegares pra cima/baixo, códigos de motivo, relatórios de bug. Peça um “por quê?” leve (fatos errados, não seguiu instruções, inseguro, muito lento) para encaminhar problemas ao ajuste certo — prompt, ferramentas, dados ou política.
UX para lógica dirigida por modelo: transparência e controle
Recursos dirigidos por modelo parecem mágicos quando funcionam — e frágeis quando não. A UX tem que assumir incerteza e ainda ajudar usuários a completar a tarefa.
Mostre o “porquê” sem sobrecarregar as pessoas
Usuários confiam mais em saídas de IA quando veem de onde vieram — não porque queiram uma aula, mas porque isso os ajuda a decidir se devem agir.
Use divulgação progressiva:
- Comece com o resultado (resposta, rascunho, recomendação).
- Ofereça um toggle “Por quê?” ou “Mostrar trabalho” que revele entradas chave: a solicitação do usuário, ferramentas usadas e fontes ou registros consultados.
- Se usar recuperação, mostre citações que vão ao trecho exato (ex.: “Baseado em: Política §3.2”). Mantenha escaneável.
Se tiver um explicador mais profundo, linke internamente (ex.: /blog/rag-grounding) em vez de encher a UI com detalhes.
Projete para incerteza (sem avisos assustadores)
Um modelo não é uma calculadora. A interface deve comunicar confiança e convidar verificação.
Padrões práticos:
- Indicadores de confiança em linguagem simples (“Provavelmente correto”, “Precisa revisão”) em vez de precisão falsa.
- Opções, não respostas únicas: “Aqui estão 3 formas de responder.” Isso reduz o custo de uma primeira tentativa errada.
- Confirmações para ações de alto impacto (enviar e-mails, deletar dados, cobrar). Faça uma pergunta clara: “Enviar esta mensagem para 12 destinatários?”
Facilite correção e recuperação
Usuários devem poder guiar a saída sem recomeçar:
- Edição inline com “Aplicar mudanças” para que o modelo continue a partir das correções do usuário.
- “Regenerar” com controles (tom, extensão, restrições) em vez de reroll aleatório.
- “Desfazer” e um histórico visível para que erros sejam reversíveis.
Forneça uma rota de escape
Quando o modelo falha — ou o usuário está inseguro — ofereça um fluxo determinístico ou ajuda humana.
Exemplos: “Mudar para formulário manual”, “Usar template” ou “Contactar suporte” (ex.: /support). Isso não é um fallback constrangedor; é como proteger a conclusão da tarefa e a confiança.
Do protótipo à produção (sem reconstruir tudo)
A maioria dos times não falha porque LLMs são incapazes; falham porque o caminho do protótipo para um recurso confiável, testável e monitorável é mais longo do que esperavam.
Uma forma prática de encurtar esse caminho é padronizar o “esqueleto do produto” cedo: máquinas de estado, schemas de ferramentas, validação, rastros e uma história de deploy/rollback. Plataformas como Koder.ai podem ser úteis quando você quer montar um fluxo AI-first rapidamente — construindo UI, backend e banco de dados juntos — e então iterar com snapshots/rollback, domínios customizados e hospedagem. Quando estiver pronto para operacionalizar, é possível exportar o código-fonte e continuar com seu CI/CD e stack de observabilidade preferidos.