O que são Protobuf e JSON (e por que importam)
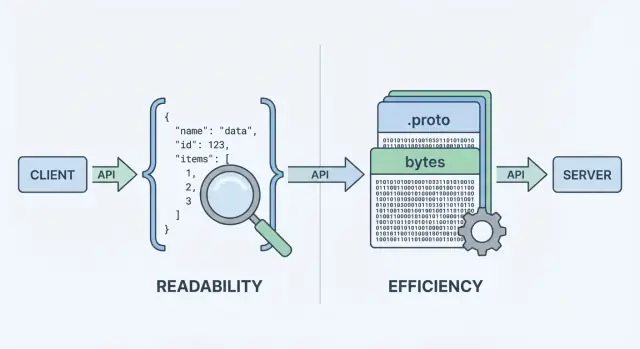
Quando sua API envia ou recebe dados, ela precisa de um formato de dados—uma forma padronizada de representar informações no corpo das requisições e respostas. Esse formato é então serializado (transformado em bytes) para transporte pela rede, e desserializado de volta em objetos utilizáveis no cliente e no servidor.
Duas escolhas comuns são JSON e Protocol Buffers (Protobuf). Ambos podem representar os mesmos dados de negócio (usuários, pedidos, timestamps, listas de itens), mas fazem trade-offs diferentes entre desempenho, tamanho de payload e fluxo de trabalho do desenvolvedor.
JSON: texto legível por humanos
JSON (JavaScript Object Notation) é um formato baseado em texto construído a partir de estruturas simples como objetos e arrays. É popular em APIs REST porque é fácil de ler, fácil de logar e fácil de inspecionar com ferramentas como curl e DevTools do navegador.
Uma grande razão para a ubiquidade do JSON: a maioria das linguagens tem suporte excelente, e você pode inspecionar visualmente uma resposta e entendê-la imediatamente.
Protobuf é um formato de serialização binária criado pelo Google. Em vez de enviar texto, ele envia uma representação binária compacta definida por um esquema (um arquivo .proto). O esquema descreve os campos, seus tipos e suas tags numéricas.
Por ser binário e guiado por esquema, o Protobuf normalmente produz payloads menores e pode ser mais rápido para fazer parsing—o que importa quando você tem alto volume de requisições, redes móveis ou serviços sensíveis à latência (comum em setups gRPC, mas não limitado a gRPC).
Mesmos dados, trade-offs diferentes
É importante separar o que você está enviando de como está codificando. Um “usuário” com id, nome e email pode ser modelado tanto em JSON quanto em Protobuf. A diferença é o custo em:
- Tamanho do payload (texto vs binário compacto)
- Tempo de CPU para serializar/desserializar
- Debugging e observabilidade (logs legíveis vs necessidade de ferramentas para binário)
- Compatibilidade e evolução (convenções informais em JSON vs esquemas impostos)
Não há resposta única. Para muitas APIs públicas, JSON continua sendo o padrão por ser acessível e flexível. Para comunicação interna entre serviços, sistemas sensíveis a desempenho ou contratos rigorosos, Protobuf pode ser mais adequado. O objetivo deste guia é ajudar a escolher com base em restrições — não em ideologia.
Como os dados da API são serializados e enviados
Quando uma API retorna dados, ela não pode enviar “objetos” diretamente pela rede. É preciso transformá-los em uma sequência de bytes primeiro. Essa conversão é a serialização—pense nela como empacotar dados em uma forma transportável. No outro lado, o cliente faz o reverso (desserialização), desempacotando os bytes de volta em estruturas de dados utilizáveis.
Uma viagem rápida do servidor ao cliente
Um fluxo típico de requisição/resposta se parece com isto:
- Servidor constrói uma resposta em seus próprios tipos em memória (objetos/structs/classes).
- Serializador codifica essa resposta em um payload (texto JSON ou binário Protobuf).
- O payload é enviado via HTTP/1.1, HTTP/2 ou HTTP/3 como bytes.
- Cliente recebe os bytes e então decodifica em seus próprios tipos em memória.
Esse “passo de codificação” é onde a escolha do formato importa. A codificação JSON produz texto legível como {\"id\":123,\"name\":\"Ava\"}. A codificação Protobuf produz bytes binários compactos que não fazem sentido para humanos sem ferramentas.
Porque cada resposta precisa ser empacotada e desempacotada, o formato influencia:
- Largura de banda (tamanho do payload): Payloads menores reduzem custos de transferência, o que ajuda em redes móveis e APIs de alto tráfego.
- Latência: Menos dados para transmitir pode significar respostas mais rápidas; codificação/decodificação mais veloz reduz o tempo de CPU.
- Fluxo do desenvolvedor: JSON é fácil de inspecionar em DevTools e logs; Protobuf frequentemente requer tipos gerados e ferramentas específicas de decodificação.
O estilo da API pode empurrar sua escolha
Seu estilo de API normalmente ajuda a decidir:
- APIs REST em JSON tipicamente usam JSON porque é amplamente suportado, fácil de testar com
curl e simples de logar e inspecionar.
- gRPC foi desenhado em torno do Protobuf por padrão. Usa HTTP/2 e geração de código, o que combina naturalmente com mensagens Protobuf fortemente tipadas.
Você pode usar JSON com gRPC (via transcoding) ou usar Protobuf sobre HTTP simples, mas a ergonomia padrão do seu stack — frameworks, gateways, bibliotecas cliente e hábitos de depuração — frequentemente decide o que é mais fácil de operar no dia a dia.
Tamanho do payload e velocidade: o que você normalmente ganha ou perde
Quando as pessoas comparam protobuf vs json, geralmente começam com duas métricas: quão grande é o payload e quanto tempo leva para codificar/decodificar. O resumo: JSON é texto e tende a ser verboso; Protobuf é binário e tende a ser compacto.
Tamanho do payload: binário compacto vs texto legível
JSON repete nomes de campos e usa representação textual para números, booleanos e estrutura, então frequentemente envia mais bytes na rede. Protobuf substitui nomes de campo por tags numéricas e empacota valores eficientemente, o que normalmente resulta em payloads visivelmente menores — especialmente para objetos grandes, campos repetidos e dados profundamente aninhados.
Dito isso, compressão pode reduzir a diferença. Com gzip ou brotli, as chaves repetidas do JSON comprimem muito bem, então a diferença de tamanho entre JSON e Protobuf pode diminuir em implantações reais. Protobuf também pode ser comprimido, mas o ganho relativo costuma ser menor.
Custo de CPU: parse de texto vs decodificação binária
Parsers JSON precisam tokenizar e validar texto, converter strings em números e lidar com casos de borda (escaping, whitespace, unicode). A decodificação Protobuf é mais direta: ler tag → ler valor tipado. Em muitos serviços, Protobuf reduz tempo de CPU e criação de lixo (garbage), o que pode melhorar latências em picos.
Impacto na rede: mobile e conexões de alta latência
Em redes móveis ou links de alta latência, menos bytes normalmente significam transferências mais rápidas e menos tempo de rádio (o que também ajuda bateria). Mas se suas respostas já são pequenas, overhead de handshake, TLS e processamento do servidor podem dominar — tornando a escolha do formato menos visível.
Como benchmarkar no seu próprio sistema
Meça com seus payloads reais:
- Escolha requisições/respostas representativas (pequenas, típicas, piores casos).
- Compare: tamanho bruto, tamanho comprimido (gzip/brotli), tempo de encode/decode e latência ponta a ponta.
- Rode testes com concorrência realista e registre p50/p95/p99.
Isso transforma debates sobre “serialização de API” em dados confiáveis para sua API.
Experiência do desenvolvedor: legibilidade, depuração e logging
A experiência do desenvolvedor é onde o JSON costuma vencer por padrão. Você pode inspecionar uma requisição ou resposta JSON quase em qualquer lugar: DevTools do navegador, saída do curl, Postman, proxies reversos e logs em texto simples. Quando algo quebra, “o que realmente enviamos?” geralmente está a um copiar/colar de distância.
Protobuf é diferente: é compacto e estrito, mas não legível. Se você logar bytes Protobuf crus, verá blobs base64 ou binário ilegível. Para entender o payload, precisa do .proto correto e de um decodificador (por exemplo protoc, ferramentas específicas da linguagem ou os tipos gerados do seu serviço).
Fluxos de depuração na prática
Com JSON, reproduzir problemas é direto: pegue um payload logado, oculte segredos, reenvie com curl e você tem um caso de teste mínimo.
Com Protobuf, normalmente você depura:
- capturando o payload binário (frequentemente codificado em base64),
- decodificando-o com a versão correta do esquema,
- reencodificando-o para reproduzir a requisição.
Esse passo extra é administrável—mas somente se a equipe tiver um fluxo de trabalho repetível.
Logging estruturado ajuda ambos os formatos. Registre IDs de requisição, nomes de método, identificadores de usuário/conta e campos-chave em vez do corpo inteiro.
Para Protobuf especificamente:
- Registre uma visão de depuração decodificada e redigida (por exemplo, em JSON) junto ao payload binário quando for seguro.
- Armazene versão do esquema ou tipo da mensagem nos logs para evitar confusão sobre “qual
.proto usamos?”.
- Adicione um pequeno script interno (ou make target) que possa “decodificar este payload base64 com o esquema certo” para uso em on-call.
Para JSON, considere registrar JSON canonizado (ordem estável de chaves) para facilitar diffs e timelines de incidentes.
Esquema e segurança de tipos: flexibilidade vs limites
APIs não apenas movem dados—elas movem significado. A maior diferença entre JSON e Protobuf é o quão claramente esse significado é definido e aplicado.
JSON é “sem esquema” por padrão: você pode enviar qualquer objeto com quaisquer campos, e muitos clientes o aceitarão contanto que pareça razoável.
Essa flexibilidade é conveniente no começo, mas também pode esconder erros. Armadilhas comuns incluem:
- Campos inconsistentes:
userId em uma resposta, user_id em outra, ou campos faltando dependendo do caminho de código.
- Dados stringificados: números, booleanos ou datas enviados como strings como
"42", "true" ou "2025-12-23"—fáceis de produzir, fáceis de interpretar errado.
- Nulls ambíguos:
null pode significar “desconhecido”, “não definido” ou “intencionalmente vazio”, e diferentes clientes podem tratá-lo de formas distintas.
Você pode adicionar JSON Schema ou OpenAPI, mas o JSON em si não obriga consumidores a segui-lo.
Protobuf: contrato explícito via .proto
Protobuf exige um esquema definido em um arquivo .proto. O esquema é um contrato compartilhado que declara:
- quais campos existem,
- quais são seus tipos (string, inteiro, enum, message, etc.),
- e qual número de campo identifica cada campo na wire.
Esse contrato ajuda a evitar mudanças acidentais—como transformar um inteiro em string—porque o código gerado espera tipos específicos.
Detalhes de segurança de tipos que importam
Com Protobuf, números continuam números, enums ficam limitados a valores conhecidos, e timestamps são tipicamente modelados usando tipos bem-definidos (em vez de formatos de string ad-hoc). “Não definido” também fica mais claro: em proto3, ausência é distinta de valores default quando você usa campos optional ou tipos wrapper.
Se sua API depende de tipos precisos e parsing previsível entre equipes e linguagens, Protobuf fornece limites que o JSON normalmente alcança por convenção.
Versionamento e evolução de esquema sem quebrar clientes
APIs evoluem: você adiciona campos, ajusta comportamentos e aposenta partes antigas. O objetivo é mudar o contrato sem surpreender consumidores.
Compatibilidade para trás vs para frente (em termos simples)
- Compatível para trás: servidores novos podem conversar com clientes antigos. Clientes antigos ignoram o que não entendem e continuam funcionando.
- Compatível para frente: clientes novos podem conversar com servidores antigos. Clientes novos lidam com campos ausentes e usam defaults.
Uma boa estratégia de evolução mira ambos, mas compatibilidade para trás é geralmente o mínimo aceitável.
Protobuf: números de campo são a verdadeira identidade
Em Protobuf, cada campo tem um número (por exemplo, email = 3). Esse número—não o nome do campo—é o que vai na wire. Os nomes são principalmente para humanos e para o código gerado.
Por isso:
-
Mudanças seguras (geralmente)
- Adicionar novos campos opcionais com números nunca usados.
- Adicionar novos valores de enum (idealmente sem reordenar os existentes).
- Descontinuar um campo (parar de usá-lo) enquanto mantém o número reservado.
-
Mudanças arriscadas (frequentemente quebram)
- Reusar um número de campo para outro significado ou tipo.
- Mudar o tipo de um campo de forma incompatível (ex.: string → int).
- Remover um campo sem reservar seu número (uso futuro pode corromper significado).
- Renomear é “seguro na wire”, mas pode quebrar código gerado e suposições downstream.
Boa prática: use reserved para números/nomes antigos e mantenha um changelog.
JSON: versionamento por convenções e disciplina
JSON não tem esquema embutido, então compatibilidade depende de padrões adotados:
- Prefira mudanças aditivas: adicione campos novos em vez de alterar os existentes.
- Trate campos desconhecidos como ignoráveis e campos ausentes como “usar um default sensato”.
- Evite mudar tipos (ex.: número → string). Se necessário, introduza um novo nome de campo.
Deprecações e uma política clara
Documente de forma antecipada: quando um campo é deprecado, por quanto tempo será suportado e o que o substitui. Publique uma política simples de versionamento (por exemplo, “mudanças aditivas são não disruptivas; remoções exigem nova versão major”) e siga-a.
Escolher entre JSON e Protobuf frequentemente depende de onde sua API vai rodar—e do que sua equipe quer manter.
Navegadores vs servidores: vantagem “padrão” do JSON
JSON é praticamente universal: todo navegador e runtime backend consegue parseá-lo sem dependências extras. Em uma web app, fetch() + JSON.parse() é o caminho natural, e proxies, gateways e ferramentas de observabilidade costumam “entender” JSON por padrão.
Protobuf também pode rodar no navegador, mas não é um custo zero. Normalmente você adiciona uma biblioteca Protobuf (ou código JS/TS gerado), gerencia o tamanho do bundle e decide se vai enviar Protobuf por endpoints HTTP que suas ferramentas de navegador conseguem inspecionar facilmente.
Mobile e SDKs backend: onde Protobuf se destaca
Em iOS/Android e em linguagens backend (Go, Java, Kotlin, C#, Python etc.), o suporte a Protobuf é maduro. A grande diferença é que Protobuf pressupõe que você usará bibliotecas por plataforma e geralmente gerará código a partir de .proto.
A geração de código traz benefícios reais:
- Modelos e enums tipados, com erros detectados mais cedo quando clientes divergem do contrato
- Bibliotecas de serialização mais rápidas e formas de dados consistentes entre serviços
Também adiciona custos:
- Passos de build (gerar código no CI, manter artefatos gerados sincronizados)
- Complexidade de repositório/processo (publicar pacotes
.proto compartilhados, travamento de versões)
Protobuf está fortemente associado ao gRPC, que entrega uma história completa de ferramentas: definições de serviço, stubs clientes, streaming e interceptors. Se você está considerando gRPC, Protobuf é o encaixe natural.
Se você constrói uma API REST tradicional em JSON, o ecossistema do JSON (DevTools do navegador, depuração via curl, gateways genéricos) continua mais simples—especialmente para APIs públicas e integrações rápidas.
Prototipar ambas opções sem se comprometer cedo demais
Se você ainda está explorando a superfície da API, ajuda prototipar rapidamente em ambos os estilos antes de padronizar. Por exemplo, equipes usam frequentemente uma API REST JSON para compatibilidade ampla e um serviço interno gRPC/Protobuf para eficiência, e então benchmarkam payloads reais antes de decidir o que vira “padrão”.
Ajuste operacional: cache, gateways e observabilidade
Escolher entre JSON e Protobuf não é só sobre tamanho do payload ou velocidade. Também afeta quão bem sua API se encaixa em camadas de cache, gateways e nas ferramentas que sua equipe usa durante incidentes.
Cache e CDNs
A maior parte da infraestrutura de cache HTTP (caches do navegador, proxies reversos, CDNs) é otimizada em torno de semântica HTTP, não de um formato de corpo específico. Um CDN pode cachear qualquer byte desde que a resposta seja cacheável.
Dito isto, muitas equipes esperam JSON na borda porque é fácil de inspecionar e solucionar problemas. Com Protobuf, o cache ainda funciona, mas seja deliberado sobre:
- Chaves de cache (URL, query params e especialmente
Vary)
- Cabeçalhos de cache claros (
Cache-Control, ETag, Last-Modified)
- Evitar fragmentação acidental de cache ao suportar múltiplos formatos
Negociação de conteúdo (Content-Type e Accept)
Se você suportar JSON e Protobuf, use negociação de conteúdo:
- Clientes enviam
Accept: application/json ou Accept: application/x-protobuf
- Servidor responde com o
Content-Type correspondente
Garanta que caches entendam isso adicionando Vary: Accept. Caso contrário, um cache pode armazenar uma resposta em JSON e servi-la a um cliente Protobuf (ou vice-versa).
Gateways, proxies e observabilidade
Gateways de API, WAFs, transformadores de requisição/resposta e ferramentas de observabilidade costumam assumir corpos JSON para:
- Validação de requisição e checagens de esquema
- Registro e redação a nível de campo
- Métricas derivadas de campos do payload
- Depuração em dashboards e visualizadores de trace
Protobuf binário pode limitar essas funcionalidades, a menos que seu tooling entenda Protobuf (ou você adicione passos de decodificação).
Orientação prática para ambientes mistos
Um padrão comum é JSON na borda, Protobuf internamente:
- Endpoints REST públicos: JSON para compatibilidade e operações mais fáceis
- Chamadas internas serviço-a-serviço: Protobuf (frequentemente via gRPC) para eficiência
Isso mantém integrações externas simples enquanto captura os benefícios de desempenho do Protobuf onde você controla ambos os lados.
Considerações de segurança e confiabilidade
Escolher JSON ou Protobuf muda como os dados são codificados e parseados—mas não substitui requisitos centrais de segurança como autenticação, criptografia, autorização e validação no servidor. Um serializador rápido não salva uma API que aceita entrada não confiável sem limites.
Pode ser tentador tratar Protobuf como “mais seguro” por ser binário e menos legível. Isso não é estratégia de segurança. Atacantes não precisam que seus payloads sejam legíveis por humanos—eles só precisam do endpoint. Se a API vaza campos sensíveis, aceita estados inválidos ou tem autenticação fraca, trocar o formato não resolve.
Criptografe transporte (TLS), aplique checagens de autorização, valide entradas e registre com segurança independentemente do uso de JSON REST ou grpc protobuf.
Superfície de ataque: payloads, parsers e validação
Ambos os formatos compartilham riscos comuns:
- Payloads superdimensionados: documentos JSON grandes ou mensagens Protobuf enormes podem causar pressão de memória, parsing lento ou negação de serviço.
- Bugs em parsers: todo parser é código e código pode ter vulnerabilidades. O risco não é “JSON vs Protobuf” tanto quanto quais bibliotecas você usa e se são mantidas atualizadas.
- Lacunas de validação de esquema: JSON é flexível e pode aceitar campos inesperados ou tipos errados a menos que você valide (por exemplo, com JSON Schema). Protobuf adiciona restrições de tipo, mas ainda é possível aceitar dados semanticamente inválidos (ex.: quantidades negativas) sem validações extras.
Confiabilidade: limites, timeouts e rigor
Para manter APIs confiáveis sob carga e abuso, aplique as mesmas salvaguardas a ambos os formatos:
- Defina tamanho máximo de requisição e tamanho máximo de mensagem (incluindo tamanho descomprimido se suportar compressão).
- Use timeouts e cancelamento para evitar consumo de recursos por clientes lentos ou parsers lentos.
- Prefira validação estrita: rejeite campos de negócio obrigatórios faltantes, ranges inválidos e valores de enum desconhecidos quando apropriado.
- Tenha cuidado com logging: JSON é fácil de inspecionar, mas ambos os formatos podem expor segredos se você logar payloads crus.
Conclusão: “binário vs texto” afeta principalmente desempenho e ergonomia. Segurança e confiabilidade vêm de limites consistentes, dependências atualizadas e validação explícita—independentemente do serializador escolhido.
Quando escolher JSON vs quando escolher Protobuf
Escolher entre JSON e Protobuf é menos sobre qual é “melhor” e mais sobre o que sua API precisa otimizar: facilidade para humanos e alcance, ou eficiência e contratos rígidos.
Quando JSON é a escolha padrão
JSON é geralmente o padrão seguro quando você precisa de ampla compatibilidade e depuração simples.
Cenários típicos:
- APIs públicas onde você não controla os clientes (parceiros, terceiros, ferramentas desconhecidas)
- Clientes browser e web (suporte nativo a JSON, fácil inspeção em DevTools)
- Iteração rápida em estágios iniciais de produto (menos cerimônia, payloads simples)
- Fluxos orientados à depuração (copiar/colar requisições, logs legíveis, testes rápidos com cURL)
- Endpoints REST que serão amplamente cacheados ou proxied (suporte comum em gateways)
Quando Protobuf se destaca
Protobuf tende a ganhar quando desempenho e consistência valem mais do que legibilidade humana.
Cenários típicos:
- APIs de alto throughput onde você paga largura de banda ou opera em grande escala
- Muitas chamadas pequenas (serviços “chatty”) onde overhead de serialização soma
- Microserviços internos onde você controla ambos os lados e pode impor esquemas
- Sistemas baseados em gRPC (Protobuf é o encaixe natural e habilita ferramentas fortes)
- Ambientes mobile/edge onde payloads menores ajudam latência e bateria
Perguntas para guiar a decisão
Use estas perguntas para reduzir rapidamente a escolha:
- Quem consome a API? Clientes externos/públicos geralmente empurram para JSON.
- Você controla todos os clientes e implantações? Se sim, Protobuf fica mais fácil de adotar.
- Desempenho é um gargalo real? Meça: latência p95, CPU e custos de egress.
- Quão importante é tipagem estrita e contrato de esquema? Protobuf aplica limites.
- Seu tooling é maduro o bastante? Considere geração de código, checagens em CI e onboarding.
Uma matriz de decisão simples (expansível)
Você pode transformar isto em uma tabela no seu doc:
- Diversidade de clientes: Alta → JSON | Baixa/controlada → Protobuf
- Sensibilidade ao tamanho do payload: Baixa → JSON | Alta → Protobuf
- Restrições de latência/CPU: Flexíveis → JSON | Rígidas → Protobuf
- Necessidade de depuração/log manual: Intensa → JSON | Principalmente automatizada → Protobuf
- Disciplina de esquema: Opcional/frouxa → JSON | Contratos fortes → Protobuf
- Preferência de protocolo: REST → JSON (frequentemente) | gRPC → Protobuf (quase sempre)
Se ainda estiver em dúvida, a abordagem “JSON na borda, Protobuf internamente” costuma ser um compromisso pragmático.
Estratégias de migração: movendo entre JSON e Protobuf
Migrar formatos é menos sobre reescrever tudo e mais sobre reduzir risco para consumidores. Movimentos mais seguros mantêm a API utilizável durante a transição e facilitam rollback.
1) Comece pequeno: um endpoint ou serviço interno
Escolha uma área de baixo risco—frequentemente uma chamada interna entre serviços ou um único endpoint somente leitura. Isso permite validar o esquema Protobuf, clientes gerados e mudanças na observabilidade sem transformar toda a API em um projeto big-bang.
Um passo prático inicial é adicionar uma representação Protobuf para um recurso existente enquanto mantém a forma JSON inalterada. Você rapidamente descobrirá onde seu modelo é ambíguo (null vs ausente, números vs strings, formatos de data) e poderá resolver isso no esquema.
2) Rode JSON e Protobuf em paralelo (temporariamente)
Para APIs externas, suporte duplo costuma ser o caminho mais suave:
- Negocie formato via cabeçalhos
Content-Type e Accept.
- Exponha um endpoint separado (ex.:
/v2/...) somente se a negociação for difícil com seu tooling.
Nesse período, garanta que ambos os formatos sejam produzidos a partir da mesma fonte de verdade para evitar drift sutil.
Planeje para:
- Testes de compatibilidade: clientes antigos contra servidores novos, e clientes novos contra servidores antigos.
- Testes de contrato: valide campos obrigatórios, comportamento default e respostas de erro.
- Benchmarks: meça tamanho de payload, CPU e latência (incluindo compressão e TLS), não apenas “velocidade na wire”.
4) Documente o esquema e publique exemplos
Publique arquivos .proto, comentários de campo e exemplos concretos de requisição/resposta (em JSON e Protobuf) para que consumidores verifiquem interpretações. Um curto “guia de migração” e um changelog reduzem carga de suporte e aceleram adoção.
Práticas recomendadas e um checklist rápido
Escolher entre JSON e Protobuf costuma ser mais sobre a realidade do seu tráfego, clientes e restrições operacionais. O caminho mais confiável é medir, documentar decisões e manter mudanças de API previsíveis.
Meça antes de otimizar
Rode um pequeno experimento em endpoints representativos.
Monitore:
- Tamanho do payload (mediana e p95)
- Latência ponta a ponta (cliente → servidor → cliente)
- CPU e memória nos serviços que fazem (de)serialização
- Taxas de erro e timeouts
Faça isso em staging com dados similares aos de produção e depois valide em produção em um pequeno slice de tráfego.
Mantenha esquemas e contratos previsíveis
Quer use JSON Schema/OpenAPI ou .proto:
- Use convenções de nomes consistentes entre endpoints e campos.
- Defina defaults claros e documente-os. “Ausente” vs “vazio” não deve surpreender clientes.
- Prefira mudanças aditivas: adicione campos opcionais em vez de alterar significado.
- Deprecate campos com notas e prazos explícitos; mantenha os campos deprecados até que os clientes migrem.
Faça da experiência do desenvolvedor uma prioridade
Mesmo que escolha Protobuf por desempenho, mantenha a documentação amigável:
- Inclua exemplos de requisições/respostas (caminho feliz e erros comuns).
- Forneça snippets copiáveis para as linguagens mais comuns.
- Documente como inspecionar payloads em logs ou usando tooling.
Se você mantém docs ou guias de SDK, linke-os claramente (por exemplo: /docs e /blog). Se precificação ou limites de uso afetam escolhas de formato, deixe isso visível também (/pricing).
Checklist rápido