05 de out. de 2025·8 min
RabbitMQ para suas aplicações: padrões, configuração e operações
Aprenda a usar RabbitMQ nas suas aplicações: conceitos centrais, padrões comuns, dicas de confiabilidade, escala, segurança e monitoramento para produção.
Por que RabbitMQ importa para equipes de aplicação
RabbitMQ é um broker de mensagens: ele fica entre partes do seu sistema e move de forma confiável “trabalho” (mensagens) de produtores para consumidores. Equipes de aplicação normalmente recorrem a ele quando chamadas diretas e síncronas (HTTP entre serviços, bancos de dados compartilhados, cron jobs) começam a criar dependências frágeis, carga desigual e cadeias de falha difíceis de depurar.
Que problemas o RabbitMQ resolve
Picos de tráfego e cargas desiguais. Se sua aplicação recebe 10× mais cadastros ou pedidos em uma janela curta, processar tudo imediatamente pode sobrecarregar serviços a jusante. Com RabbitMQ, os produtores enfileiram tarefas rapidamente e os consumidores as processam em um ritmo controlado.
Acoplamento apertado entre serviços. Quando o Serviço A precisa chamar o Serviço B e esperar, falhas e latência se propagam. Mensageria os desacopla: A publica uma mensagem e segue; B processa quando estiver disponível.
Tratamento de falhas mais seguro. Nem toda falha deve virar um erro mostrado ao usuário. RabbitMQ ajuda a tentar novamente o processamento em segundo plano, isolar mensagens “venenosas” e evitar perda de trabalho durante quedas temporárias.
Resultados típicos que as equipes observam
As equipes geralmente obtêm fluxos de trabalho mais suaves (amortecendo picos), serviços desacoplados (menos dependências em tempo de execução) e retries controlados (menos reprocesamento manual). Igualmente importante, fica mais fácil raciocinar sobre onde o trabalho está preso — no produtor, em uma fila ou no consumidor.
O que este guia cobre (e o que não cobre)
Este guia foca em RabbitMQ prático para equipes de aplicação: conceitos centrais, padrões comuns (pub/sub, work queues, retries e dead-letter queues) e preocupações operacionais (segurança, escala, observabilidade, troubleshooting).
Ele não pretende ser um walkthrough completo da especificação AMQP nem um mergulho em todos os plugins do RabbitMQ. O objetivo é ajudá-lo a projetar fluxos de mensagens que permaneçam manejáveis em sistemas reais.
Glossário rápido
- Produtor: um componente da aplicação que envia mensagens.
- Consumidor: um componente da aplicação que recebe e processa mensagens.
- Fila (queue): um buffer que mantém mensagens até que um consumidor as processe.
- Exchange: ponto de entrada que roteia mensagens para uma ou mais filas.
- Routing key: um rótulo usado pelas exchanges para decidir para onde enviar uma mensagem.
Noções básicas do RabbitMQ: o que é e quando usar
RabbitMQ é um broker de mensagens que roteia mensagens entre partes do seu sistema, de modo que produtores podem delegar trabalho e consumidores podem processá-lo quando estiverem prontos.
Mensageria AMQP vs chamadas HTTP diretas
Com uma chamada HTTP direta, o Serviço A envia uma requisição ao Serviço B e normalmente espera por uma resposta. Se o Serviço B está lento ou indisponível, o Serviço A falha ou fica bloqueado, e você precisa lidar com timeouts, retries e backpressure em todo chamador.
Com RabbitMQ (comumente via AMQP), o Serviço A publica uma mensagem no broker. O RabbitMQ armazena e roteia para a(s) fila(s) correta(s), e o Serviço B consome de forma assíncrona. A diferença chave é que você se comunica através de uma camada intermediária durável que tamponiza picos e suaviza cargas desiguais.
Quando mensageria é adequada (e quando não é)
Mensageria é uma boa escolha quando você:
- Quer desacoplar times/serviços para que possam deployar e escalar independentemente.
- Precisa de trabalho assíncrono (enviar e-mail, gerar PDFs, rodar checagens de fraude) sem bloquear uma requisição do usuário.
- Espera tráfego bursty e quer absorver picos com filas.
- Precisa de entrega confiável com acknowledgements, retries e dead-letter queues.
Mensageria é uma má escolha quando você:
- Realmente precisa de uma resposta imediata para servir a requisição (ex.: “esta senha é válida?”).
- Está fazendo leituras síncronas simples onde uma chamada direta é mais clara e fácil de depurar.
- Não tem um plano para versionamento de mensagens, retries e monitoramento (você só vai mover complexidade, não reduzi-la).
Request/response vs fluxo assíncrono (exemplo simples)
Síncrono (HTTP):
Um serviço de checkout chama um serviço de fatura via HTTP: “Crie fatura.” O usuário espera enquanto a geração da fatura ocorre. Se a faturação está lenta, a latência do checkout aumenta; se está down, o checkout falha.
Assíncrono (RabbitMQ):
O checkout publica invoice.requested com o id do pedido. O usuário recebe confirmação imediata de que o pedido foi recebido. A faturação consome a mensagem, gera a fatura e, então, publica invoice.created para que e-mail/notificações realizem o envio. Cada etapa pode re- tentar independentemente e quedas temporárias não quebram automaticamente o fluxo inteiro.
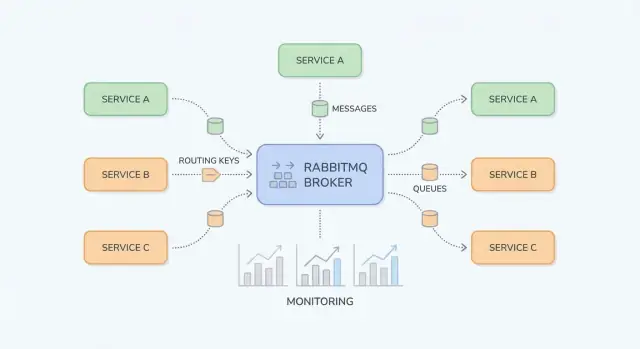
Blocos de construção: Exchanges, Filas e Roteamento
RabbitMQ é mais fácil de entender se você separar “onde as mensagens são publicadas” de “onde as mensagens são armazenadas”. Produtores publicam em exchanges; exchanges roteiam para filas; consumidores leem das filas.
Exchanges: como o RabbitMQ decide para onde mandar uma mensagem
Uma exchange não armazena mensagens. Ela avalia regras e encaminha mensagens para uma ou mais filas.
- Direct exchange: roteia por correspondência exata na routing key. Use quando quiser destinos claros e explícitos (ex.:
billingouemail). - Topic exchange: roteia usando padrões nas routing keys. Use para pub/sub flexível e comportamento “inscreva-se em uma categoria”.
- Fanout exchange: broadcast para toda fila ligada, ignorando routing keys. Use quando todo consumidor deve receber cada evento (ex.: invalidação de cache).
- Headers exchange: roteia com base em headers da mensagem em vez de routing keys. Use quando o roteamento depender de múltiplos atributos (ex.:
region=euEtier=premium), mas reserve para casos especiais pois é mais difícil de raciocinar.
Filas e bindings: como mensagens chegam ao lugar certo
Uma fila é onde mensagens ficam até que um consumidor as processe. Uma fila pode ter um ou muitos consumidores (consumidores competidores), e mensagens tipicamente são entregues a um consumidor por vez.
Um binding conecta uma exchange a uma fila e define a regra de roteamento. Pense assim: “Quando uma mensagem atingir a exchange X com routing key Y, entregue-a na fila Q.” Você pode ligar múltiplas filas à mesma exchange (pub/sub) ou ligar uma única fila várias vezes para diferentes routing keys.
Routing keys e padrões (topic exchanges)
Para direct exchanges, o roteamento é exato. Para topic exchanges, as routing keys se parecem com palavras separadas por ponto, por exemplo:
orders.createdorders.eu.refunded
Bindings podem incluir curingas:
*corresponde exatamente a uma palavra (ex.:orders.*casa comorders.created)#corresponde a zero ou mais palavras (ex.:orders.#casa comorders.createdeorders.eu.refunded)
Isso dá uma maneira limpa de adicionar novos consumidores sem mudar produtores — crie uma nova fila e ligue-a com o padrão necessário.
Acknowledgements de mensagem: ack, nack, requeue
Depois que o RabbitMQ entrega uma mensagem, o consumidor reporta o que aconteceu:
- ack: “Processado com sucesso.” RabbitMQ remove a mensagem da fila.
- nack (ou reject): “Falhou.” Você pode escolher descartá-la ou reencaminhá-la (requeue).
- requeue: coloca a mensagem de volta para ser tentada novamente (frequentemente imediatamente).
Cuidado com requeue: uma mensagem que sempre falha pode girar em loop e bloquear a fila. Muitas equipes combinam nacks com estratégia de retries e uma dead-letter queue (coberta abaixo) para que falhas sejam tratadas de forma previsível.
Casos de uso comuns em aplicações reais
RabbitMQ brilha quando você precisa mover trabalho ou notificações entre partes do sistema sem fazer tudo esperar por uma etapa lenta. Abaixo estão padrões práticos que surgem em produtos do dia a dia.
Publicação/assinatura de notificações (fanout/topic)
Quando múltiplos consumidores devem reagir ao mesmo evento — sem que o publicador saiba quem são — pub/sub é uma escolha limpa.
Exemplo: quando um usuário atualiza o perfil, você pode notificar indexação de busca, analytics e sincronização com CRM em paralelo. Com uma fanout exchange você broadcast para todas as filas ligadas; com uma topic exchange você roteia seletivamente (ex.: user.updated, user.deleted). Isso evita acoplamento rígido e permite que equipes adicionem novos assinantes sem mudar o produtor.
Work queues para jobs em background
Se uma tarefa leva tempo, empurre para uma fila e deixe workers processarem de forma assíncrona:
- processamento de imagem/vídeo
- envio de e-mails transacionais
- geração de PDFs ou relatórios
- importação/exportação de dados
Isso mantém requisições web rápidas enquanto permite escalar workers independentemente. Também é uma forma natural de controlar concorrência: a fila vira sua “lista de afazeres” e o número de workers, o “botão de vazão”.
Integração orientada a eventos entre serviços
Muitos fluxos de trabalho cruzam fronteiras de serviço: order → billing → shipping é o exemplo clássico. Em vez de um serviço chamar o próximo e bloquear, cada serviço pode publicar um evento ao terminar sua etapa. Serviços a jusante consomem eventos e continuam o fluxo.
Isso melhora resiliência (uma queda temporária no shipping não quebra o checkout) e deixa a ownership mais clara: cada serviço reage a eventos que lhe interessam.
Ponte para dependências lentas ou pouco confiáveis
RabbitMQ é também um buffer entre sua aplicação e dependências lentas/flaky (APIs de terceiros, sistemas legados, bancos em batch). Você enfileira requisições rapidamente e as processa com retries controlados. Se a dependência estiver down, o trabalho se acumula com segurança e é drenado depois — em vez de causar timeouts por toda a aplicação.
Se planeja introduzir filas gradualmente, um pequeno “outbox assíncrono” ou uma fila única de background jobs é um bom primeiro passo (veja /blog/next-steps-rollout-plan).
Projetando fluxos de mensagem que permanecem sustentáveis
Uma configuração RabbitMQ permanece agradável quando rotas são previsíveis, nomes são consistentes e payloads evoluem sem quebrar consumidores antigos. Antes de adicionar outra fila, certifique-se de que a “história” de uma mensagem seja óbvia: onde ela se origina, como é roteada e como um colega pode depurá-la fim-a-fim.
Escolha o tipo de exchange que combina com seu roteamento
Escolher a exchange certa reduz bindings únicos e fan-outs-surpresa:
- Direct exchange: melhor quando uma routing key mapeia para uma fila específica (ex.:
billing.invoice.created). - Topic exchange: melhor para pub/sub flexível com padrões (ex.:
billing.*.created,*.invoice.*). É a escolha mais comum para roteamento estilo evento sustentável. - Fanout exchange: melhor quando todo consumidor deve receber cada mensagem (raro para eventos de negócio; mais comum para sinais tipo broadcast).
Uma boa regra: se você está “inventando” lógica complexa de roteamento em código, talvez ela deva estar em um topic exchange em vez disso.
Noções básicas de esquema de mensagem: versionamento e compatibilidade
Trate corpos de mensagem como APIs públicas. Use versionamento explícito (por exemplo, um campo no topo schema_version: 2) e busque compatibilidade retroativa:
- Adicione campos; não renomeie/remova.
- Prefira campos opcionais com valores padrão seguros.
- Se uma mudança breaking for inevitável, publique um novo tipo de mensagem/routing key em vez de alterar silenciosamente a antiga.
Isso mantém consumidores antigos funcionando enquanto novos adotam a nova versão no seu próprio ritmo.
Correlation IDs e trace IDs para debug cross-service
Torne o troubleshooting barato padronizando metadados:
correlation_id: liga comandos/eventos que pertencem à mesma ação de negócio.trace_id(outraceparentW3C): conecta mensagens ao tracing distribuído através de HTTP e fluxos assíncronos.
Quando todo publicador define esses campos consistentemente, você pode seguir uma única transação por vários serviços sem adivinhações.
Convenções de nomes que escalam com seu sistema
Use nomes previsíveis e pesquisáveis. Um padrão comum:
- Exchanges:
<domínio>.<tipo>(ex.:billing.events) - Routing keys:
<domínio>.<entidade>.<verbo>(ex.:billing.invoice.created) - Filas:
<serviço>.<propósito>(ex.:reporting.invoice_created.worker)
Consistência vence esperteza: o futuro você (e seu time de plantão) agradecerá.
Padrões de confiabilidade: Retries, DLQs e Idempotência
Transforme padrões em código rapidamente
Modele exchanges, filas e chaves de roteamento no chat e depois exporte o código-fonte.
Mensageria confiável é principalmente planejar para falhas: consumidores caem, APIs a jusante time-outam e alguns eventos são simplesmente malformados. RabbitMQ fornece as ferramentas, mas seu código precisa cooperar.
Entrega at-least-once (e o que isso significa para seu código)
Uma configuração comum é at-least-once: uma mensagem pode ser entregue mais de uma vez, mas não deve ser perdida silenciosamente. Isso normalmente ocorre quando um consumidor recebe uma mensagem, começa o trabalho e então falha antes de dar ack — o RabbitMQ reencaminhará.
A lição prática: duplicatas são normais, então seu handler deve ser seguro para rodar múltiplas vezes.
Estratégias de idempotência para consumidores
Idempotência significa “processar a mesma mensagem duas vezes tem o mesmo efeito que processá-la uma vez”. Abordagens úteis incluem:
- Chaves de deduplicação: inclua um
message_idestável (ou chave de negócio comoorder_id + event_type + version) e armazene em uma tabela/cache de “processados” com TTL. - Updates seguros: use gravações condicionais (ex.: atualize apenas se o status ainda for
PENDING) ou restrições de unicidade no banco para evitar criações duplicadas. - Padrões outbox/inbox: persista o recebimento do evento primeiro e então processe, assim retries não repetem efeitos colaterais.
Retries com TTL + DLX/DLQ
Retries funcionam melhor como um fluxo separado, não como um loop apertado no consumidor.
Um padrão comum é:
- Em falha transitória, rejeitar e rotear para uma fila de retry com TTL por fila (ou por mensagem).
- Quando o TTL expira, a mensagem é dead-lettered de volta para a fila original via uma dead-letter exchange (DLX).
- Monitore a contagem de tentativas via um header (ou encodifique no routing key) e pare após N tentativas.
Isso cria backoff sem manter mensagens “presas” como não confirmadas.
Mensagens venenosas: quarentena e replay
Algumas mensagens nunca vão ter sucesso (schema inválido, dados referenciados ausentes, bug de código). Detecte-as por:
- número máximo de tentativas alcançado
- falhas repetidas com a mesma assinatura de erro
Roteie essas para uma DLQ para quarentena. Trate a DLQ como uma caixa operacional: inspecione payloads, corrija o problema subjacente e então reproduza manualmente mensagens selecionadas (idealmente por uma ferramenta/script controlado) em vez de devolver tudo automaticamente à fila principal.
Performance e escala: dicas práticas de ajuste
O desempenho do RabbitMQ normalmente é limitado por alguns fatores práticos: como você gerencia conexões, a velocidade com que consumidores processam trabalho e se filas estão sendo usadas como “armazenamento”. O objetivo é vazão estável sem construir backlog crescente.
Conexões vs canais (reuso e limites)
Um erro comum é abrir uma nova conexão TCP para cada publisher ou consumidor. Conexões são mais pesadas do que parecem (handshakes, heartbeats, TLS), então mantenha-as de longa duração e reaproveite.
Use canais para multiplexar trabalho sobre um número menor de conexões. Regra prática: poucas conexões, muitos canais. Ainda assim, não crie milhares de canais sem critério — cada canal tem overhead e sua biblioteca cliente pode ter limites. Prefira um pequeno pool de canais por serviço e reuse canais para publicar.
Prefetch e concorrência (vazão sem sobrecarga)
Se consumidores puxam mensagens demais de uma vez, você verá picos de memória, tempos longos de processamento e latência desigual. Defina um prefetch (QoS) para que cada consumidor segure um número controlado de mensagens não acked.
Orientações práticas:
- Para jobs mais lentos (chamadas API, processamento de arquivos), comece com prefetch 1–10 por consumidor.
- Para handlers rápidos e leves em CPU, aumente prefetch gradualmente enquanto observa taxas de ack e recursos do host.
- Escale adicionando mais instâncias de consumidor (ou threads) antes de elevar drasticamente o prefetch.
Tamanho da mensagem: mantenha payloads enxutos
Mensagens grandes reduzem throughput e aumentam pressão de memória (em publishers, broker e consumidores). Se seu payload é grande (documentos, imagens, JSONs enormes), considere armazená-lo em outro lugar (object storage ou banco) e enviar apenas um ID + metadados pelo RabbitMQ.
Uma heurística útil: mantenha mensagens na ordem de KB, não MB.
Backpressure: prevenir crescimento infinito de filas
Crescimento de fila é um sintoma, não uma estratégia. Aplique backpressure para que produtores desacelerem quando consumidores não conseguem seguir o ritmo:
- Limite o trabalho do consumidor: cove concorrência e ajuste prefetch para manter trabalho inflight previsível.
- Detecte e reaja ao crescimento: alerte sobre profundidade de fila e taxa de publicação vs taxa de ack.
- Shed load: para eventos não críticos, descarte ou amostre mensagens antes de publicar durante spikes.
Em dúvida, mude um controle por vez e meça: taxa de publicação, taxa de ack, comprimento da fila e latência fim-a-fim.
Checklist de segurança para implantações RabbitMQ
Vá da ideia à implantação
Implemente e hospede seu app com filas após validar o fluxo no chat.
Segurança para RabbitMQ é em grande parte reforçar as “bordas”: como clientes se conectam, quem pode fazer o quê e como manter credenciais longe de lugares errados. Use este checklist como base e adapte às suas exigências de compliance.
Criptografe conexões com TLS
- Habilite TLS para todas as conexões de cliente (AMQP sobre TLS na porta 5671 ou porta escolhida) e prefira versões/ciphers TLS modernas.
- Use certificados que combinem com o hostname do broker que os clientes conectam.
- Planeje rotação de certificados: acompanhe datas de expiração, automatize renovações quando possível e ensaie procedimentos de reload para que rotação não vire incidente.
- Se puder, valide clientes com mTLS para serviços internos que manipulam dados sensíveis.
Autenticação e autorização
Permissões do RabbitMQ são poderosas quando usadas de forma consistente.
- Crie usuários separados para cada aplicação (evite contas “app” compartilhadas).
- Use vhosts para particionar tenants ou sistemas (ex.: um vhost por produto/time).
- Aplique privilégios de menor privilégio por vhost:
- Configure (criar/modificar recursos)
- Write (publicar)
- Read (consumir)
Separe dev/staging/prod com segurança
- Rode clusters separados por ambiente sempre que possível. Se precisar compartilhar infra, isole com vhosts estritos e credenciais separadas.
- Nunca aponte uma app de dev para um broker de prod “só para testar”. Impeça isso via políticas de rede e nomes DNS.
Trate segredos corretamente nas aplicações
- Não codifique credenciais em código, configs no git ou imagens de container.
- Injete segredos em tempo de execução via plataforma (secrets do Kubernetes, um secrets manager ou variáveis CI criptografadas).
- Rode credenciais periodicamente e remova usuários não usados.
Para hardening operacional (portas, firewalls e auditoria), mantenha um runbook interno curto e linke-o a partir de /docs/security para que as equipes sigam um padrão único.
Monitoramento e observabilidade: o que medir
Quando RabbitMQ se comporta mal, sintomas aparecem primeiro na aplicação: endpoints lentos, timeouts, atualizações faltando ou jobs que “nunca terminam”. Boa observabilidade permite confirmar se o broker é a causa, identificar o gargalo (publicador, broker ou consumidor) e agir antes que usuários notem.
Métricas chave do broker para acompanhar
Comece com um conjunto pequeno de sinais que mostram se as mensagens estão fluindo.
- Profundidade da fila (messages ready + unacked): profundidade crescente indica que consumidores não conseguem acompanhar ou estão presos.
- Taxa de publicações e taxa de acks: publicação crescendo enquanto acks ficam estáveis = backlog. Acks caindo de repente = falhas ou timeouts de consumidores.
- Utilização do consumidor: consumidores estão ociosos, saturados ou reiniciando frequentemente? Combine com prefetch e concorrência.
- Redeliveries / requeues: um forte indicador de erros de processamento, política de retry ruim ou mensagens venenosas.
Sinais de alerta que pegam incidentes cedo
Alerta em tendências, não apenas em thresholds absolutos.
- Backlog crescente por N minutos: profundidade consistentemente aumentando é mais acionável que “depth > X”.
- Redeliveries/requeues repetidos: aponta para loop de falha que consome CPU e bloqueia a fila.
- Churn de conexões e canais: desconexões frequentes podem indicar crashes de app, problemas de rede ou heartbeats mal configurados.
- Unacked alto por longos períodos: sugere consumidores travando ou levando muito tempo por mensagem.
Logs e rastreamento de mensagens durante incidentes
Logs do broker ajudam a separar “RabbitMQ caiu” de “clientes estão usando errado”. Procure falhas de autenticação, conexões bloqueadas (resource alarms) e erros frequentes de canal. No lado da aplicação, garanta que cada tentativa de processamento logue um correlation ID, nome da fila e resultado (acked, rejected, retried).
Se usar tracing distribuído, propague cabeçalhos de trace através das propriedades da mensagem para conectar “requisição API → mensagem publicada → trabalho do consumidor”.
Dashboards e runbooks internos
Crie um dashboard por fluxo crítico: taxa de publicação, taxa de ack, profundidade, unacked, requeues e contagem de consumidores. Adicione links diretos no dashboard para seu runbook interno, ex.: /docs/monitoring, e uma checklist “o que checar primeiro” para quem estiver de plantão.
Depurando problemas comuns do RabbitMQ
Quando algo “simplesmente para de andar” no RabbitMQ, resista ao impulso de reiniciar primeiro. A maioria dos problemas vira óbvia assim que você olha para (1) bindings e roteamento, (2) saúde dos consumidores e (3) alarms de recurso.
Mensagens não consumidas
Se publishers reportam “enviado com sucesso” mas filas ficam vazias (ou a fila errada enche), verifique o roteamento antes do código.
Comece na UI de Management:
- Verifique o tipo de exchange e se a fila tem o binding esperado.
- Confirme que a routing key que o produtor publica corresponde ao padrão do binding (especialmente com exchanges
topic). - Garanta que você esteja publicando no vhost correto.
Se a fila tem mensagens mas ninguém consome, confirme:
- Um consumidor está conectado e subscrito na fila certa.
- O consumidor não está travado por prefetch muito baixo/alto ou bloqueado por trabalho lento a jusante.
- Acks estão acontecendo (unacked crescendo normalmente indica que o consumidor não está confirmando ou está sobrecarregado).
Duplicatas e mensagens fora de ordem
Duplicatas vêm tipicamente de retries (consumidor cai após processamento mas antes do ack), interrupções de rede ou requeues manuais. Mitigue tornando handlers idempotentes (por ex., dedupe por message ID no banco).
Entrega fora de ordem é esperado quando há múltiplos consumidores ou requeues. Se ordem importa, use um único consumidor para essa fila ou particione por chave em múltiplas filas.
Alarms de memória/disco
Alarms significam que RabbitMQ está se protegendo.
- Disk alarm: libere espaço em disco, mova logs ou expanda o volume; então confirme que o alarme foi limpo.
- Memory alarm: reduza mensagens em voo (menor prefetch, limite de concorrência), verifique por mensagens oversized.
Replay seguro de uma DLQ
Antes de reproduzir, corrija a causa-raiz e previna loops de mensagem venenosa. Re-enfileire em pequenos lotes, adicione um limite de retries e marque falhas com metadata (contagem de tentativas, último erro). Considere enviar mensagens reexecutadas a uma fila separada primeiro, para poder parar rapidamente se o erro repetir.
RabbitMQ vs Alternativas: escolhendo a ferramenta certa
Exporte e assuma o código-fonte
Obtenha uma base de código limpa que você possa revisar, testar e executar no seu próprio ambiente.
Escolher uma ferramenta de mensageria é mais sobre casar padrão de tráfego, tolerância a falhas e conforto operacional do que sobre “o melhor”.
Quando RabbitMQ é a escolha certa
RabbitMQ brilha quando você precisa de entrega confiável de mensagens e roteamento flexível entre componentes de aplicação. É uma boa escolha para workflows assíncronos clássicos — comandos, jobs em background, notificações fan-out e padrões request/response — especialmente quando você precisa:
- Acknowledgements por mensagem e backpressure (consumidores lentos não perdem trabalho silenciosamente)
- Roteamento rico (topics, headers, direct) sem reimplementá-lo
- Escala operacional simples para muitas equipes (adicione consumidores, ajuste prefetch, gerencie filas)
Se suas aplicações são orientadas a eventos mas o objetivo principal é mover trabalho em vez de manter um longo histórico de eventos, RabbitMQ é frequentemente um default confortável.
RabbitMQ vs sistemas de streaming tipo Kafka
Kafka e plataformas similares são construídas para streaming de alto throughput e logs de evento de longa retenção. Escolha um sistema tipo Kafka quando precisar de:
- Reprocessamento (replay) completo do histórico para consumidores
- Muito alto throughput com escala por partição
- Um único “source of truth” de eventos para analytics + serviços
Compromisso: sistemas estilo Kafka podem ter maior overhead operacional e forçar designs orientados a throughput (batching, estratégia de particionamento). RabbitMQ tende a ser mais fácil para throughput baixo-médio com latência fim-a-fim menor e roteamento complexo.
Quando uma fila simples pode bastar
Se você tem um app produzindo jobs e um pool de workers consumindo — e está satisfeito com semântica simples — uma fila baseada em Redis (ou um serviço gerenciado de task queue) pode ser suficiente. Equipes normalmente superam essa solução quando precisam de garantias mais fortes de entrega, dead-lettering, múltiplos padrões de roteamento ou separação clara entre produtores e consumidores.
Considerações de migração se suas necessidades mudarem
Projete contratos de mensagem como se você pudesse migrar depois:
- Mantenha schemas versionados e compatíveis retroativamente.
- Evite features específicas do broker embutidas no payload (coloque roteamento em headers/metadata, não no corpo).
- Construa produtores/consumidores para rodarem em paralelo durante uma migração.
Se mais tarde precisar de streams reprocessáveis, você pode espelhar eventos do RabbitMQ para um sistema log-based enquanto mantém RabbitMQ para workflows operacionais. Para um plano de rollout prático, veja /blog/rabbitmq-rollout-plan-and-checklist.
Próximos passos: plano de rollout e checklist da equipe
Implantar RabbitMQ funciona melhor quando você o trata como um produto: comece pequeno, defina propriedade e prove confiabilidade antes de expandir para mais serviços.
Checklist inicial (adoção por um serviço)
Escolha um fluxo que se beneficie de processamento assíncrono (ex.: envio de e-mails, geração de relatórios, sincronização com API externa).
- Defina o contrato de mensagem: campos obrigatórios, versão e o que significa “sucesso”.
- Crie uma exchange + uma fila com convenção de nomes clara.
- Defina limites de concorrência do consumidor e prefetch para evitar sobrecarregar sistemas a jusante.
- Adicione comportamento de retry (com backoff) e uma dead-letter queue (DLQ) desde o primeiro dia.
- Faça handlers idempotentes (seguros para processar a mesma mensagem duas vezes).
- Documente passos operacionais de “estancar o sangue” (pausar consumidor, drenar fila, reproduzir DLQ).
Se precisar de um template de referência para nomes, tiers de retry e políticas básicas, centralize em /docs.
À medida que implementar esses padrões, considere padronizar o scaffolding entre equipes. Por exemplo, times usando Koder.ai frequentemente geram um esqueleto pequeno de produtor/consumidor a partir de um prompt de chat (incluindo convenções de nomes, wiring de retry/DLQ e cabeçalhos de trace/correlation), exportam o código para revisão e iteram em "planning mode" antes do rollout.
Propriedade operacional (deixe explícito)
RabbitMQ funciona quando “alguém é dono da fila”. Decida isso antes de ir para produção:
- Quem monitora: normalmente time de plataforma/SRE cuida da saúde do broker; times de serviço cuidam de suas filas e comportamento de consumidores.
- Quem lida com DLQ: time de serviço on-call (com caminho claro de escalonamento).
- Runbooks: um runbook a nível de broker e um runbook por serviço para filas críticas.
Se estiver formalizando suporte ou hospedagem gerenciada, alinhe expectativas cedo (veja /pricing) e defina um canal de contato para incidentes e onboarding em /contact.
Experimentos iniciais (comprove antes de escalar)
Execute exercícios pequenos e com prazo para ganhar confiança:
- Load test: valide throughput, concorrência de consumidores e latência sob condições de pico.
- Failure drills: mate consumidores, simule reinícios do broker, force latência de rede, verifique comportamento de retries e DLQ.
- Versionamento de schema: introduza uma v2 enquanto consumidores v1 ainda rodam; confirme compatibilidade e passos de rollout.
Uma vez que um serviço esteja estável por algumas semanas, replique os mesmos padrões — não reinventem por time.
Perguntas frequentes
Quando uma equipe de aplicação deve usar RabbitMQ em vez de chamadas HTTP diretas?
Use RabbitMQ quando você quiser desacoplar serviços, absorver picos de tráfego ou mover trabalho lento para fora do caminho da requisição.
Casos adequados incluem jobs em background (e-mails, PDFs), notificações de evento para múltiplos consumidores e fluxos que devem continuar durante quedas temporárias de dependências a jusante.
Evite quando você realmente precisa de uma resposta imediata (leitura/validação simples) ou quando não há compromisso com versionamento, retries e monitoramento — esses itens não são opcionais em produção.
Como escolher entre direct, topic, fanout e headers exchanges?
Publique em uma exchange e roteie para filas:
- Use uma direct exchange quando uma routing key deve mapear para um destino específico.
- Use uma topic exchange quando você quer padrões flexíveis como
orders.*ouorders.#. - Use uma fanout exchange quando todo consumidor deve receber cada mensagem.
- Use uma apenas para casos especiais em que o roteamento dependa de múltiplos atributos.
A maioria das equipes adota topic exchanges por padrão para roteamento estilo evento mais sustentável.
Qual a diferença entre uma fila e um binding, e como o roteamento costuma falhar?
Uma fila armazena mensagens até que um consumidor as processe; um binding é a regra que conecta uma exchange a uma fila.
Para depurar problemas de roteamento:
- Confirme o tipo de exchange e o padrão de binding da fila.
- Verifique se a routing key que o produtor publica bate com o binding (especialmente com curingas de topic).
- Cheque se você está publicando/consumindo no vhost correto.
Essas três verificações explicam a maioria dos incidentes “publicado mas não consumido”.
Qual é o padrão mais simples de “work queue” para jobs em background?
Use uma work queue quando você quer que uma dentre muitas workers processe cada tarefa.
Dicas práticas:
- Faça cada mensagem representar uma unidade de trabalho (pequena, retryável).
- Ajuste o prefetch para que os workers não peguem muitas mensagens não confirmadas.
- Aumente escala adicionando instâncias de consumidor antes de elevar muito o prefetch.
- Mantenha payloads pequenos (envie IDs + metadados; armazene blobs grandes em outro lugar).
O que significa entrega at-least-once e como eu lido com duplicatas?
Entrega "at-least-once" significa que uma mensagem pode ser entregue mais de uma vez (por exemplo, se o consumidor cair depois de executar o trabalho, mas antes do ack).
Torne os consumidores seguros assim:
- Use um
message_idestável (ou chave de negócio) e registre IDs processados com TTL. - Projete atualizações seguras (por exemplo, atualize apenas se o status ainda for
PENDING, use restrições de unicidade). - Separe efeitos colaterais para que retries não cobrem em dobro, nem enviem e-mails duplicados ou criem registros duplicados.
Como devo implementar retries e dead-letter queues (DLQ) no RabbitMQ?
Evite loops de requeue apertados. Uma abordagem comum é filas de retry + DLQ:
- Em falha transitória, rejeite para uma fila de retry com TTL (backoff).
- Quando o TTL expira, a mensagem é dead-lettered de volta à fila principal via um DLX.
- Controle a contagem de tentativas (header ou metadata) e pare após N tentativas.
- Envie falhas permanentes para uma DLQ para quarentena.
Reproduza da DLQ somente após corrigir a causa-raiz e faça replays em pequenos lotes.
Como manter contratos de mensagem sustentáveis à medida que os serviços evoluem?
Comece com nomes previsíveis e trate mensagens como APIs públicas:
- Adicione
schema_versionao payload. - Prefira mudanças aditivas (adicione campos; não renomeie/remova).
- Para mudanças breaking, publique um novo tipo de mensagem / routing key.
Padronize também metadados:
Quais métricas e alertas importam mais para RabbitMQ em produção?
Concentre-se em alguns sinais que mostram se o trabalho está fluindo:
- Profundidade da fila (ready + unacked)
- Taxa de publicação vs taxa de ack
- Redeliveries/requeues (frequentemente indica loops de falha)
- Contagem/utilização de consumidores e churn de reinícios
Alerta em tendências (por exemplo, “backlog crescendo por 10 minutos”), e use logs que incluam nome da fila, correlation_id e o resultado do processamento (acked/retried/rejected).
Qual é o checklist mínimo de segurança para implantar RabbitMQ?
Faça o básico de forma consistente:
- Use TLS para conexões de cliente; considere mTLS para tráfego interno sensível.
- Crie um usuário por aplicação (sem credenciais compartilhadas).
- Use vhosts para isolar ambientes/tenants e aplique privilégios de menor privilégio (configure/write/read).
- Não codifique segredos; injete em tempo de execução e roteie credenciais regularmente.
Mantenha um runbook interno curto para que as equipes sigam um padrão único (por exemplo, link em /docs/security).
Como eu depuro “mensagens não estão sendo consumidas” ou “tudo está travado”?
Comece localizando onde o fluxo para:
- Se as filas estão vazias, verifique exchange/bindings/routing key e vhost.
- Se mensagens estão na fila mas não se movem, verifique conexões de consumidor, prefetch e se o unacked está subindo.
- Se vê duplicatas ou processamento fora de ordem, presume retries e consumidores concorrentes; mitigue com idempotência e particionamento quando a ordem for importante.
- Se acionam alarmes de disco/memória, reduza mensagens em voo (prefetch/concurrency), desacelere produtores e trate limites de recurso antes de reiniciar.
Reiniciar raramente é a primeira ou melhor ação.