Esclareça o problema de dependência que você está resolvendo
Antes de desenhar telas ou escolher stack, deixe claro o que “dependência” significa na sua organização. Se as pessoas usam a palavra para descrever tudo, seu app acabará rastreando nada direito.
Defina “dependência” em termos simples
Escreva uma definição de uma frase que todos possam repetir e depois liste o que qualifica. Categorias comuns incluem:
- Item de trabalho: outra equipe precisa construir uma feature, consertar um bug ou entregar um ticket.
- Entregável: um documento, conjunto de dados, design ou asset necessário para prosseguir.
- Decisão: um acordo ou aprovação que desbloqueia a implementação.
- Ambiente/acesso: credenciais, infraestrutura, ambientes de teste ou aprovações.
Defina também o que não é uma dependência (por exemplo, “melhorias desejáveis”, riscos gerais ou tarefas internas que não bloqueiam outra equipe). Isso mantém o sistema limpo.
Identifique para quem o app é
O rastreamento de dependências falha quando é construído apenas para PMs ou apenas para engenheiros. Nomeie seus usuários principais e o que cada um precisa em 30 segundos:
- Líderes de equipe / gerentes de engenharia: o que está bloqueando a entrega e quem tem a próxima ação.
- PMs / gerentes de programa: datas de repasse, compromissos e caminhos de escalonamento.
- Engenheiros: o pedido exato, contexto e critérios de aceite.
- Liderança / operações: previsibilidade de entrega, menos surpresas e relatórios de tendência.
Escolha métricas de sucesso mensuráveis
Escolha um pequeno conjunto de resultados, como:
- Menos “bloqueadores surpresa” descobertos tardiamente em um sprint ou ciclo de release
- Menor tempo desde a criação da dependência → atribuição de propriedade aceita
- Mais repasses no prazo contra as datas acordadas
- Propriedade clara (menos itens com responsável “TBD”)
Liste os pontos de dor que você eliminará
Capture os problemas que seu app precisa resolver no dia 1: planilhas desatualizadas, donos pouco claros, datas perdidas, riscos escondidos e atualizações espalhadas por chats.
Mapeie dependências, estados e definições
Depois de alinhar o que você vai rastrear e para quem, trave o vocabulário e o ciclo de vida. Definições compartilhadas transformam “uma lista de tickets” em um sistema que reduz bloqueios.
Escolha um conjunto pequeno de tipos que cubra a maioria das situações reais e faça cada tipo fácil de reconhecer:
- Blocked-by: Equipe A não pode entregar até a Equipe B completar algo.
- Provides-to: Equipe B fornece um artefato/serviço que a Equipe A consumirá.
- Waiting-on: Similar a blocked-by, mas frequentemente com limite de tempo (aprovação, acesso, decisão).
- Recurso compartilhado: Equipes disputam as mesmas pessoas, ambiente, orçamento ou fornecedor.
- Restrição de sequência: O trabalho deve ocorrer em uma ordem específica mesmo sem bloqueio direto.
O objetivo é consistência: duas pessoas devem classificar a mesma dependência da mesma forma.
Defina os atributos mínimos (e exija-os)
Um registro de dependência deve ser pequeno, mas completo o suficiente para gerenciar:
- Equipe dona (responsável pela entrega)
- Equipe solicitante (que precisa do resultado)
- Data de entrega (quando o solicitante precisa)
- Status (veja o ciclo abaixo)
- Nível de risco (por exemplo, Baixo/Médio/Alto)
- Notas (contexto, pressupostos)
- Links para trabalho de origem (issue no Jira, doc, PR, incidente etc.)
Se permitir criar uma dependência sem equipe dona ou data, você estará construindo um “rastreador de preocupações”, não uma ferramenta de coordenação.
Concorde sobre estados do ciclo de vida e o que os move
Use um modelo de estado simples que corresponda a como as equipes trabalham na prática:
Proposed → Accepted → In progress → Ready → Delivered/Closed, além de Rejected.
Documente regras de mudança de estado. Por exemplo: “Accepted requer uma equipe dona e uma data alvo inicial”, ou “Ready requer evidência”.
Torne o “feito” inequívoco
Para o fechamento, exija tudo a seguir:
- Critérios de aceite: o que conta como completo
- Aprovação: quem confirma (nome/equipe)
- Evidência/link: PR, nota de release, captura de tela, documento ou ticket
- Timestamp: quando foi aceito/fechado
Essas definições viram a espinha dorsal dos filtros, lembretes e revisões de status mais adiante.
Desenhe um modelo de dados simples que escala
Uma ferramenta de rastreamento de dependências vence ou perde dependendo se as pessoas conseguem descrever a realidade sem brigar com a ferramenta. Comece com um pequeno conjunto de objetos que bate com a linguagem das equipes e só aumente a estrutura onde isso evita confusão.
Objetos principais (mantenha-os simples)
Use um punhado de registros primários:
- Equipe: o grupo que possui trabalho ou fornece uma dependência.
- Projeto/Iniciativa: um contêiner para trabalho com resultado claro.
- Item de trabalho: a unidade que as pessoas executam (feature, tarefa, epic, link de ticket).
- Dependência: uma promessa entre um solicitante e um provedor.
- Marco/Release: um checkpoint orientado por data que dependências podem bloquear.
Evite criar tipos separados para cada caso extremo. É melhor adicionar alguns campos (ex.: “type: data/API/approval”) do que dividir o modelo cedo demais.
Relacionamentos que refletem coordenação real
Dependências frequentemente envolvem múltiplos grupos e múltiplas tarefas. Modele isso explicitamente:
- Teams ↔ Dependencies: muitos-para-muitos (uma dependência pode ter várias equipes provedoras; uma equipe pode estar em muitas dependências).
- Dependencies ↔ Work items: muitos-para-muitos (uma dependência pode bloquear vários itens; um item pode depender de várias dependências).
Isso evita o pensamento frágil “uma dependência = um ticket” e possibilita relatórios consolidados.
Auditabilidade: torne mudanças confiáveis
Todo objeto primário deve incluir campos de auditoria:
- Criado por / criado em, atualizado por / atualizado em
- Histórico de mudanças (o que mudou e quando)
- Comentários (decisões e contexto)
- Anexos/links (especificações, docs, issues do Jira, notas de reunião)
Suporte leve para dependências externas
Nem toda dependência tem uma equipe no seu organograma. Adicione um registro Owner/Contact (nome, organização, email/Slack, notas) e permita que dependências apontem para ele. Isso mantém bloqueios de fornecedor ou de “outra departamento” visíveis sem forçá-los à hierarquia interna.
Defina papéis, propriedade e permissões
Se papéis não forem explícitos, o rastreamento vira um thread de comentários: todo mundo assume que outra pessoa é responsável e as datas são “ajustadas” sem contexto. Um modelo de papéis claro mantém o app confiável e faz escalonamento previsível.
Papéis principais (mantenha simples)
Comece com quatro papéis de uso diário e um administrativo:
- Requester: cria a solicitação e fornece o “porquê”, data requerida e critérios de aceite.
- Owner: a única pessoa responsável por entregar (ou rejeitar formalmente) a dependência.
- Approver: confirma o compromisso quando a dependência impacta capacidade, escopo ou planejamento de release.
- Viewer: pode acompanhar progresso e comentar, mas não altera compromissos.
- Admin: gerencia configuração (equipes, permissões, templates).
Regras de propriedade que previnem ambiguidade
Faça do Owner obrigatório e singular: uma dependência, um responsável. Ainda é possível suportar colaboradores (contribuidores de outras equipes), mas colaboradores não substituem responsabilidade.
Adicione um caminho de escalonamento quando um Owner não responde: primeiro notificar o Owner, depois o manager (ou líder de equipe), depois o dono do programa/release — conforme sua estrutura.
Permissões: proteja compromissos, não visibilidade
Separe “editar detalhes” de “mudar compromissos”. Um padrão prático:
- Requester pode criar, adicionar contexto e propor datas; não pode marcar “Committed” sem aprovação.
- Owner pode atualizar status, adicionar notas de entrega e propor novas datas; só fecha quando critérios de aceite forem atendidos.
- Approver pode definir estados de compromisso (Committed/Rejected) e aprovar mudanças de data.
- Viewer vê e comenta; não edita.
Se suportar iniciativas privadas, defina quem pode vê-las (ex.: apenas equipes envolvidas + Admin). Evite “dependências secretas” que surpreendam times de entrega.
Orientação RACI na UI
Não esconda responsabilidade em um documento de política. Mostre-a em cada dependência:
- Accountable (A): Owner
- Responsible (R): Colaboradores (opcional)
- Consulted (C): Approver e equipes impactadas
- Informed (I): Viewers/watchers
Rotular “Accountable vs Consulted” diretamente no formulário reduz erros de roteamento e acelera revisões de status.
Planeje UX: vistas que equipes realmente usarão
Um rastreador de dependências só funciona se as pessoas acharem seus itens em segundos e atualizá-los sem pensar. Desenhe em torno das perguntas mais comuns: “O que eu estou bloqueando?”, “O que está me bloqueando?” e “Algo está prestes a atrasar?”.
Telas principais para lançar cedo
Comece com um conjunto pequeno de vistas que correspondem à forma como as equipes falam sobre trabalho:
- Lista de dependências: uma tabela filtrável de “todas as dependências abertas” com ações rápidas.
- Detalhe da dependência: um lugar para entender a solicitação, status, donos, datas e histórico.
- Vista da equipe: tudo que uma equipe deve entregar e o que a bloqueia, com prioridades claras.
- Vista da iniciativa: dependências agrupadas por projeto/release para que líderes identifiquem risco.
- Linha do tempo: vista leve de datas para vencimentos e handoffs (mantenha simples—não é um Gantt completo).
Torne criação e atualizações sem atrito
A maioria das ferramentas falha na “atualização diária”. Otimize para velocidade:
- Templates e campos padrão (tipos comuns de dependência, regras de SLA/data pré-preenchidas).
- Edição inline nas listas e nas páginas de detalhe (sem modais para mudanças simples).
- Controles amigáveis ao teclado para usuários avançados (ordem de tab, salvar rápido, atalhos previsíveis).
Faça o status impossível de interpretar errado
Use cor + rótulo de texto (nunca apenas cor) e mantenha vocabulário consistente. Adicione um “Última atualização” em destaque em cada dependência e um aviso de obsolescência quando não for tocada por um período definido (por exemplo, 7–14 dias). Isso incentiva atualizações sem forçar reuniões.
Reduza reuniões capturando contexto
Cada dependência deve ter um único fio que contenha:
- Comentários e atualizações de progresso
- Decisões (com data e quem concordou)
- Links para trabalho de apoio (tickets, docs)
Quando a página de detalhe conta a história completa, revisões de status ficam mais rápidas — e muitos syncs rápidos desaparecem porque a resposta já está escrita.
Construa fluxos de trabalho para solicitações, atualizações e fechamento
Inclua outras equipes
Convide outra equipe para experimentar o Koder.ai e ganhe créditos com indicações.
Um rastreador de dependências ganha ou perde pelas ações cotidianas que suporta. Se as equipes não conseguem rapidamente solicitar trabalho, responder com um compromisso claro e fechar com prova, seu app vira um “quadro informativo” em vez de uma ferramenta de execução.
Fluxo central: request → decision → commitment
Comece com um único fluxo “Criar solicitação” que capture o que a equipe provedora precisa entregar, por que importa e quando é necessário. Mantenha estruturado: data requerida, critérios de aceite e link para o epic/spec relevante.
A partir daí, imponha um estado de resposta explícito:
- Accept (compromete-se com uma data)
- Decline (com razão obrigatória)
- Propose new date (contra-oferta com explicação)
Isso evita o modo de falha mais comum: dependências “talvez” silenciosas que parecem OK até explodirem.
Expectativas estilo SLA que evitam obsolescência
Defina expectativas leves no próprio workflow. Exemplos:
- Resposta em X dias úteis após a criação
- Cadência de atualização (por exemplo, semanal ou sempre que o status mudar)
- Marcar como stale se não houver atualização por Y dias e a data estiver dentro de Z dias
O objetivo não é polícia; é manter compromissos atuais para que o planejamento permaneça honesto.
Permita que as equipes marquem uma dependência como At risk com uma nota curta e próximo passo. Quando alguém muda uma data ou status, exija um motivo (um dropdown + texto livre). Essa regra single cria um histórico que torna retrospectivas e escalonamentos factuais, não emocionais.
Fechamento que prova que o trabalho realmente foi feito
“Fechar” deve significar que a dependência foi satisfeita. Requisite evidência: link para PR mesclado, ticket liberado, documento ou nota de aprovação. Se o fechamento for vago, equipes colocarão itens “verdes” cedo para reduzir ruído.
Ações em massa para planejamento semanal
Suporte atualizações em lote durante revisões: selecione múltiplas dependências e defina o mesmo status, adicione uma nota compartilhada (ex.: “replanejado após reset do Q1”) ou solicite updates. Isso mantém o app rápido o bastante para uso em reuniões, não só depois delas.
Adicione alertas e notificações sem criar spam
Notificações devem proteger a entrega, não distrair. A maneira mais fácil de criar ruído é alertar todo mundo sobre tudo. Em vez disso, desenhe alertas em torno de pontos de decisão (alguém precisa agir) e sinais de risco (algo está derivando).
Mantenha a primeira versão focada em eventos que mudam o plano ou requerem resposta explícita:
- Nova solicitação criada (a equipe dona recebe notificação)
- Aceitação necessária (dependência atribuída aguardando confirmação)
- Data alterada (qualquer alteração nas datas prometidas/necessárias)
- Status em risco / bloqueado (flag de risco levantado)
- Atualização estagnada (sem update em X dias para dependência ativa)
Cada gatilho deve mapear para um passo seguinte claro: aceitar/recusar, propor nova data, adicionar contexto ou escalar.
Entregue pelos canais que as equipes já checam
Padronize em notificações in-app (para vincular o alerta ao registro) mais email para o que não pode esperar.
Ofereça integrações de chat opcionais — Slack ou Microsoft Teams — mas trate-as como mecanismos de entrega, não como sistema de registro. Mensagens de chat devem linkar profundamente para o item (por exemplo, /dependencies/123) e incluir contexto mínimo: quem precisa agir, o que mudou e até quando.
Forneça controles em nível de equipe e usuário:
- Alertas imediatos para aceitação, bloqueado, vencido
- Modo digest (diário/semanal) para updates de baixa urgência como pequenas mudanças de data ou comentários
- Agrupamento e deduplicação (um resumo por dependência por janela de tempo)
Aqui também entram os “watchers”: notifique o requester, a equipe dona e stakeholders explicitamente adicionados — evite broadcasts amplos.
Escalone apenas quando padrões indicarem risco
Escalonamento deve ser automatizado, mas conservador: alerte quando uma dependência está atrasada, quando a data foi adiada repetidamente ou quando um status bloqueado não tem atualização por um período definido.
Direcione escalonamentos ao nível certo (líder de equipe, PM de programa) e inclua o histórico para que o destinatário aja sem perseguir contexto.
Escolha integrações que eliminem trabalho duplicado
Assuma sua base de código
Exporte o código-fonte completo quando quiser levar o desenvolvimento totalmente para dentro da empresa.
Integrações devem eliminar re-digitação, não adicionar overhead de setup. A abordagem mais segura é começar com os sistemas que as equipes já confiam (issue trackers, calendários e identidade), manter a primeira versão read-only ou unidirecional e só expandir depois que houver dependência do app.
Escolha um rastreador primário (Jira, Linear ou Azure DevOps) e suporte um fluxo simples link-first:
- Um registro de dependência armazena uma URL do tracker e key (ex.:
PROJ-123).
- Seu app puxa status (Open/In Progress/Done), responsável e data de entrega em um agendamento.
- Atualizações permanecem no tracker inicialmente; seu app reflete-as.
Isso evita “duas fontes de verdade” ao mesmo tempo que dá visibilidade. Depois, adicione sync bidirecional opcional para um pequeno subconjunto de campos (status, due date) com regras claras de conflito.
Adicione milestones do calendário (read-only primeiro)
Marcos e deadlines frequentemente ficam em Google Calendar ou Outlook. Comece lendo eventos para a sua linha do tempo (ex.: “Release Cutoff”, “Janela de UAT”) sem escrever de volta.
A sincronização de calendário em modo leitura permite que equipes planejem onde já fazem isso, enquanto seu app mostra impactos e datas próximas em um só lugar.
Single sign-on reduz fricção de onboarding e deriva de permissões. Escolha conforme a realidade do cliente:
- Google Workspace (comum em orgs menores)
- Microsoft Entra ID (comum em enterprise)
- Okta (comum em ambientes mistos)
Se estiver no início, entregue um provedor primeiro e documente como solicitar outros.
Ofereça uma API pequena e webhooks bem documentados
Mesmo times não técnicos se beneficiam quando operações internas podem automatizar handoffs. Forneça alguns endpoints e hooks com exemplos copy-paste.
curl -X POST /api/dependencies \\
-H \"Authorization: Bearer $TOKEN\" \\
-d '{\"title\":\"API contract from Payments\",\"trackerUrl\":\"https://jira/.../PAY-77\"}'
Webhooks como dependency.created e dependency.status_changed permitem integrações com ferramentas internas sem esperar pela sua roadmap. Para mais, linke para /docs/integrations.
Crie dashboards e relatórios para revisões de status
Dashboards são onde um app de dependências ganha seu valor: eles transformam “acho que estamos bloqueados” numa imagem clara e compartilhada do que precisa atenção antes da próxima checagem.
Dashboards para diferentes audiências
Um dashboard “tamanho único” costuma falhar. Em vez disso, desenhe algumas vistas que batem com como as pessoas conduzem reuniões:
- Vista do líder de equipe: mostra o que sua equipe deve e está esperando, focada em datas, status e próximo passo.
- Vista do programa: agrupa dependências por iniciativa/release e destaca gargalos entre equipes (onde múltiplos itens esperam a mesma equipe ou marco).
- Resumo executivo: roll-up compacto: total de dependências abertas, quantas estão em risco, o que virou vencido e os 3 maiores bloqueios. Mantenha escaneável.
Relatórios que impulsionam decisões (não trabalho inútil)
Construa um conjunto pequeno de relatórios que as pessoas realmente usarão em revisões:
- Dependências vencidas: ordenadas por dias atrasados e severidade/risco.
- Principais equipes que bloqueiam: quem tem mais dependências esperando (e tendência ao longo do tempo).
- Marcos próximos em risco: marcos nas próximas 2–4 semanas com dependências abertas ou sinalizadas como “at risk”.
Cada relatório deve responder: “Quem precisa fazer o quê a seguir?” Inclua dono, data esperada e última atualização.
Filtros que importam
Torne filtros rápidos e óbvios, porque a maioria das reuniões começa com “mostre só…”.
Suporte filtros como equipe, iniciativa, status, intervalo de data, nível de risco e tags (ex.: “revisão de segurança”, “contrato de dados”, “release train”). Salve conjuntos de filtros comuns como vistas nomeadas (ex.: “Release A — próximos 14 dias”).
Exportação e compartilhamento
Nem todo mundo viverá no seu app o dia todo. Forneça:
- Export CSV para análise leve e compartilhamento pontual.
- Links compartilháveis para um dashboard ou relatório filtrado (ex.: /reports/overdue?team=payments). Mantenha links internos e estáveis.
Se oferecer nível pago, mantenha controles de compartilhamento para admins e aponte para /pricing para detalhes.
Escolha uma stack e arquitetura práticas
Você não precisa de uma plataforma complexa para entregar um app de rastreamento de dependências. Um MVP pode ser um sistema simples em três partes: UI web para humanos, API para regras e integrações, e um banco de dados como fonte da verdade. Otimize por “fácil de mudar” em vez de “perfeito”. Você aprenderá mais com uso real do que com meses de arquitetura antecipada.
Uma stack MVP simples
Um começo pragmático pode ser:
- Web UI: React, Vue, ou páginas server-rendered (Rails/Django) se quiser telas CRUD mais rápidas.
- API: Node (Express/Nest), Python (FastAPI/Django), ou Rails — escolha o que sua equipe já domina.
- Banco: Postgres costuma ser a melhor escolha padrão para dados relacionais como dependências, donos, status e timestamps.
Se esperar integração com Slack/Jira em breve, mantenha integrações como módulos/jobs separados que falem com a API, em vez de deixar ferramentas externas escreverem direto no banco.
Se quiser chegar a um produto funcional sem montar tudo do zero, um fluxo de vibe-coding pode ajudar: por exemplo, Koder.ai pode gerar UI React e backend Go + PostgreSQL a partir de uma especificação por chat, permitindo iterar com modos de planejamento, snapshots e rollback. Você ainda controla arquitetura, mas encurta o caminho de “requisitos” para “pilotável”, e pode exportar o código quando for internalizar.
Básicos técnicos que você vai agradecer por ter
- Autenticação: SSO (SAML/OIDC) quando possível; caso contrário login seguro por email.
- Logging: logs estruturados de requests mais rastreamento de erros para debugar “por que isso mudou?”.
- Rate limits: proteja a API de integrações barulhentas e loops acidentais.
- Backups: backups diários automatizados e restores testados (não pule o teste de restauração).
A maioria das telas são listas: dependências abertas, bloqueadores por equipe, mudanças da semana. Projete para isso:
- Adicione indexes para filtros comuns (status, equipe dona, due date, updated_at).
- Use paginação em todos os lugares.
- Forneça busca (full-text básica do Postgres geralmente é suficiente).
Privacidade e confiança
Dados de dependência podem incluir detalhes sensíveis de entrega. Use princípio do menor privilégio (visibilidade por equipe onde apropriado) e mantenha logs de auditoria para edições — quem mudou o quê e quando. Esse histórico reduz debates em revisões e torna a ferramenta confiável.
Plano de rollout: piloto, migração e adoção
Ganhe recompensas por compartilhar
Compartilhe o que você construiu com Koder.ai e ganhe créditos pelo programa de conteúdo.
Colocar um app de rastreamento em produção é menos sobre recursos e mais sobre mudar hábitos. Trate o rollout como um lançamento de produto: comece pequeno, prove valor e escale com um ritmo operacional claro.
Escolha 2–4 equipes trabalhando numa única iniciativa compartilhada (por exemplo, um release train ou um programa para um cliente). Defina critérios de sucesso mensuráveis em poucas semanas:
- Menos bloqueadores “desconhecidos” em revisões de status
- Menor tempo de “dependência levantada” até “dono atribuído”
- Mais entregas no prazo para a iniciativa piloto
Mantenha a configuração do piloto mínima: só os campos e vistas necessários para responder “o que está bloqueado, por quem e até quando?”.
2) Migre de planilhas sem importar o caos
A maioria das equipes já rastreia dependências em planilhas. Importe-as, mas faça isso intencionalmente:
- Mapeie colunas para campos (descrição, equipe solicitante, equipe dona, data, status, razão do bloqueio)
- Limpe duplicatas e normalize nomes de equipes antes da importação
- Decida o que fazer com linhas “históricas” (geralmente é melhor arquivar do que migrar)
Faça um curto QA de dados com usuários do piloto para confirmar definições e corrigir entradas ambíguas.
A adoção gruda quando o app apoia uma cadência existente. Forneça:
- Um treinamento de 15–20 minutos com 2–3 dependências reais
- Uma rotina semanal de atualização (ex.: toda terça antes do cross-team sync)
- Uma regra clara: dependências sem dono ou data não são “registradas”, estão incompletas
Se estiver iterando rápido (por exemplo, no Koder.ai), use ambientes/snapshots para testar mudanças em campos obrigatórios, estados e dashboards com os times pilotos — e faça rollout (ou rollback) sem impactar todo mundo.
4) Crie um loop de feedback e itere
Rastreie onde as pessoas travam: campos confusos, estados faltantes ou vistas que não respondem perguntas de revisão. Reveja feedback semanalmente durante o piloto e ajuste campos e vistas padrão antes de convidar mais equipes. Um simples link “Report an issue” para /support mantém o ciclo curto.
Evite armadilhas e planeje a próxima iteração
Depois do lançamento, os maiores riscos não são técnicos — são comportamentais. Equipes não abandonam ferramentas porque “não funcionam”, mas porque atualizar parece opcional, confuso ou ruidoso.
Modos de falha comuns (e como preveni-los)
Muitos campos. Se criar uma dependência parece preencher um formulário, as pessoas adiam. Comece com um conjunto mínimo de campos obrigatórios: título, equipe solicitante, equipe dona, “próxima ação”, data e status.
Propriedade pouco clara. Se não ficar óbvio quem deve agir, dependências viram threads de status. Torne “owner” e “próxima ação/owner” explícitos e mostre-os em destaque.
Sem hábito de atualizar. Mesmo uma UI ótima falha se itens ficam obsoletos. Adicione lembretes suaves: destaque itens estagnados, envie lembretes apenas quando a data estiver próxima ou a última atualização for antiga, e torne atualizações fáceis (um clique + nota curta).
Excesso de notificações. Se todo comentário notifica todo mundo, usuários vão silenciar o sistema. Por padrão, use watchers opt-in e envie resumos (diários/semanais) para baixa urgência.
Governança: evite deriva na taxonomia
Decida quem administra tags, lista de equipes e categorias. Tipicamente é um program manager ou papel de ops com controle leve. Defina política de aposentadoria: arquive iniciativas antigas após X dias fechadas e revise tags não usadas trimestralmente.
Próximos passos sugeridos
Depois da adoção inicial, considere upgrades que agreguem valor:
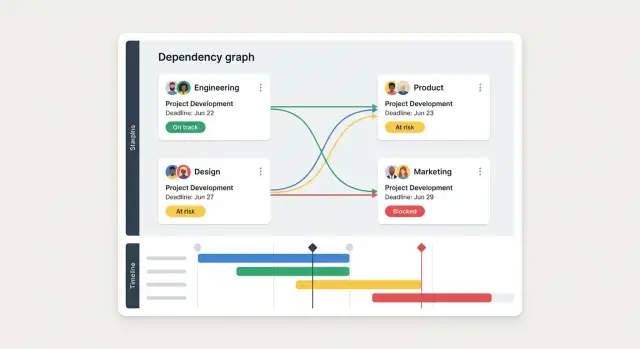
- Vista em grafo de dependências para releases complexos
- Pontuação de risco (envelhecimento, datas perdidas, tags de alto impacto)
- Analytics de SLA para identificar gargalos crônicos
- Templates por departamento para criar tipos comuns com um clique
Priorize cada ideia ligando-a a um ritual de revisão (status semanal, planejamento de release, retrospectiva) para que as melhorias venham do uso real.