13 de mai. de 2025·8 min
Criar um app web para rastrear a adoção do produto por nível de conta
Aprenda a desenhar dados, eventos e dashboards para medir a adoção do produto por níveis de conta e agir com alertas e automações.
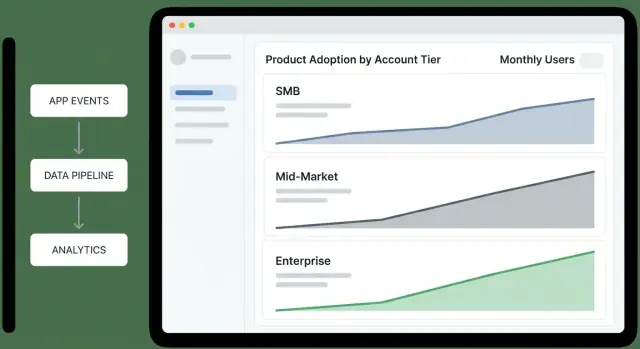
Aprenda a desenhar dados, eventos e dashboards para medir a adoção do produto por níveis de conta e agir com alertas e automações.
Antes de construir dashboards ou instrumentar eventos, deixe claro para que o app serve, quem ele atende e como os níveis de conta são definidos. A maioria dos projetos de “rastreamento de adoção” falha porque começa pelos dados e termina em desacordos.
Uma regra prática: se duas equipes não conseguem definir “adoção” na mesma frase, elas não vão confiar no dashboard depois.
Nomeie as audiências primárias e o que cada uma precisa fazer em seguida depois de ver os dados:
Um bom teste: cada público deve conseguir responder “e daí?” em menos de um minuto.
A adoção não é uma única métrica. Escreva uma definição com a qual a equipe concorde — geralmente uma sequência:
Mantenha ancorado no valor do cliente: quais ações sinalizam que eles estão obtendo resultados, não apenas explorando.
Liste seus níveis e torne a atribuição determinística. Níveis comuns incluem SMB / Mid-Market / Enterprise, Free / Trial / Paid, ou Bronze / Silver / Gold.
Documente as regras em linguagem simples (e depois, em código):
Anote as decisões que o app deve habilitar. Por exemplo:
Use-as como critérios de aceitação:
Níveis de conta se comportam de maneira diferente, então uma única métrica de “adoção” vai ou punir clientes pequenos ou esconder risco em clientes maiores. Comece definindo o que sucesso significa por nível, então escolha métricas que reflitam essa realidade.
Escolha um outcome primário que represente valor entregue:
Sua north star deve ser contável, segmentada por nível e difícil de manipular.
Escreva seu funil de adoção como estágios com regras explícitas — assim a resposta do dashboard não depende de interpretação.
Exemplo de estágios:
Diferenças por nível importam: “Activated” em Enterprise pode requerer uma ação do admin e ao menos uma ação de usuário final.
Use indicadores leading para detectar momentum inicial:
Use indicadores lagging para confirmar adoção durável:
Metas devem refletir o tempo esperado para obter valor e a complexidade organizacional. Ex.: SMB pode mirar ativação em 7 dias; Enterprise pode mirar integração em 30–60 dias.
Escreva metas para que alertas e scorecards se mantenham consistentes entre equipes.
Um modelo claro previne “math misterioso” depois. Você quer responder perguntas simples — quem usou o quê, em qual conta, sob qual nível, naquele ponto no tempo — sem costurar lógica ad-hoc em cada dashboard.
Comece com um conjunto pequeno de entidades que mapeiam como clientes realmente compram e usam seu produto:
account_id), nome, status e campos de lifecycle (created_at, churned_at).user_id, domínio do email (útil para casar), created_at, last_seen_at.workspace_id e chave estrangeira para account_id.Seja explícito sobre o “grain” analítico:
Um padrão prático é rastrear eventos a nível de usuário (com account_id anexado), e então agregar para métricas por conta. Evite eventos apenas a nível de conta a menos que não exista usuário (ex.: importações de sistema).
Eventos dizem o que aconteceu; snapshots dizem o que era verdade.
Não sobrescreva “nível atual” e perca contexto. Crie uma tabela account_tier_history:
account_id, tier_idvalid_from, valid_to (nullable para o atual)source (billing, sales override)Isso permite calcular adoção enquanto a conta era Team, mesmo que depois tenha subido de nível.
Escreva definições uma vez e trate-as como requisito de produto: o que conta como “usuário ativo”, como você atribui eventos a contas e como tratar mudanças de nível no meio do mês. Isso evita que dois dashboards mostrem duas verdades diferentes.
Sua analytics de adoção só será tão boa quanto os eventos coletados. Comece mapeando um pequeno conjunto de ações do “caminho crítico” que indicam progresso real para cada nível de conta, depois instrumente de forma consistente em web, mobile e backend.
Foque em eventos que representam passos significativos — não todo clique. Um conjunto inicial prático:
signup_completed (conta criada)user_invited e invite_accepted (crescimento de time)first_value_received (seu momento “aha”; defina explicitamente)key_feature_used (ação de valor repetível; pode haver múltiplos eventos por recurso)integration_connected (se integrações aumentam stickiness)Cada evento deve carregar contexto suficiente para slice por nível e por papel:
account_id (obrigatório)user_id (obrigatório quando envolver pessoa)tier (capture no momento do evento)plan (billing plan/SKU se relevante)role (ex.: owner/admin/member)workspace_id, feature_name, source (web/mobile/api), timestampUse um esquema previsível para que dashboards não virem um projeto de dicionário:
snake_case em minúsculas, verbo no passado (report_exported, dashboard_shared)account_id, não acctId)invoice_sent) ou um único evento com feature_name; escolha uma abordagem e mantenha-a.Suporte atividade anônima e autenticada:
anonymous_id na primeira visita e vincule ao user_id no login.workspace_id e mapeie para account_id no servidor para evitar bugs no cliente.Instrumente ações de sistema no backend para que métricas chave não dependam de browsers ou ad blockers. Exemplos: subscription_started, payment_failed, seat_limit_reached, audit_log_exported.
Esses eventos server-side também são ideais como gatilhos para alertas e workflows.
É aqui que o tracking vira um sistema: eventos chegam do app, são limpos, armazenados com segurança e transformados em métricas que sua equipe realmente usa.
A maioria das equipes usa uma mistura:
Qualquer que seja a escolha, trate ingestão como um contrato: se um evento não puder ser interpretado, deve ser quarentenado — não aceito silenciosamente.
No momento da ingestão, padronize os poucos campos que tornam reporting confiável:
account_id, user_id, e (se necessário) workspace_id.event_name, tier, plan, feature_key) e só adicione defaults quando explícito.Decida onde eventos brutos ficam baseado em custo e padrões de query:
Construa jobs diários/horários que produzam tabelas como:
Mantenha rollups determinísticos para poder reexecutá-los quando definições de nível ou backfills mudarem.
Defina retenção clara para:
Uma pontuação de adoção dá a times ocupados um número único para monitorar, mas só funciona se for simples e explicável. Mire em uma pontuação 0–100 que reflita comportamentos significativos (não atividade de vaidade) e que possa ser decomposta em “por que isso mudou”.
Comece com uma checklist ponderada de comportamentos, limitada a 100 pontos. Mantenha pesos estáveis por um trimestre para que tendências sejam comparáveis.
Exemplo de ponderação (ajuste para seu produto):
Cada comportamento deve mapear para uma regra clara de evento (ex.: “usou core” = core_action em 3 dias distintos). Quando o score mudar, armazene fatores contribuintes para mostrar: “+15 porque você convidou 2 usuários” ou “-10 porque o uso core caiu abaixo de 3 dias.”
Calcule o score por conta (snapshot diário ou semanal), depois agregue por nível usando distribuições, não apenas médias:
Acompanhe mudança semanal e mudança em 30 dias por nível, mas evite misturar tamanhos de nível:
Isso torna níveis pequenos legíveis sem deixar níveis grandes dominarem a narrativa.
Um dashboard de visão por nível deve permitir que um executivo responda em menos de um minuto: “Quais níveis estão melhorando, quais estão piorando e por quê?” Trate-o como uma tela de decisão, não um álbum de relatórios.
Funil por nível (Awareness → Activation → Habit): “Onde as contas estão travando por nível?” Mantenha passos consistentes com seu produto (ex.: “Usuários convidados” → “Primeira ação chave completada” → “Ativos semanais”).
Taxa de ativação por nível: “Novas ou reativadas contas estão alcançando o primeiro valor?” Mostre a taxa com o denominador (contas elegíveis) para distinguir sinal de ruído amostral.
Retenção por nível (ex.: 7/28/90 dias): “As contas continuam usando após o primeiro sucesso?” Mostre uma linha simples por nível; evite segmentar demais na visão geral.
Profundidade de uso (amplitude de recursos): “Elas estão adotando várias áreas do produto ou permanecem rasas?” Um gráfico de barras empilhadas por nível funciona bem: % usando 1 área, 2–3 áreas, 4+ áreas.
Adicione duas comparações em todos os lugares:
Use deltas consistentes (variação em pontos percentuais) para que executivos possam escanear rapidamente.
Mantenha filtros limitados, globais e persistentes:
Se um filtro mudaria definições de métrica, não o ofereça aqui — empurre para drill-downs.
Inclua um pequeno painel para cada nível: “O que mais se associou com alta adoção neste período?” Exemplos:
Mantenha explicável: prefira “Contas que configuraram X nos primeiros 3 dias retêm 18pp a mais” em vez de saídas de modelos opacas.
Coloque Cartões KPI por nível no topo (ativação, retenção, profundidade), uma rolagem com gráficos de tendência no meio e drivers + próximas ações embaixo. Cada widget deve responder uma pergunta — caso contrário, não pertence ao resumo executivo.
Um dashboard por nível é útil para priorização, mas o trabalho real acontece quando você clica para entender por que um nível mudou e quem precisa de atenção. Desenhe drill-downs como um caminho guiado: nível → segmento → conta → usuário.
Comece com uma tabela de visão do nível, depois permita fatiar em segmentos significativos sem construir relatórios customizados. Filtros comuns:
Cada página de segmento deve responder: “Quais contas estão puxando o score de adoção deste nível para cima ou para baixo?” Inclua uma lista ranqueada de contas com mudança de score e top features contribuintes.
O perfil da conta deve parecer um dossiê:
Mantenha escaneável: mostre deltas (“+12 esta semana”) e anote picos com o evento que os causou.
Na página da conta, liste usuários por atividade recente e papel. Clicar um usuário mostra uso de features e último contexto de visualização.
Adicione views de coorte para explicar padrões: mês de signup, programa de onboarding e nível no momento do signup. Isso ajuda CS a comparar semelhantes em vez de misturar contas novas com maduras.
Inclua uma view “Quem usa o quê” por nível: taxa de adoção, frequência e tendências de recursos, com lista clicável de contas que usam (ou não) cada recurso.
Para CS e Sales, adicione opções de exportar/compartilhar: exportar CSV, views salvas e links internos compartilháveis (ex.: /accounts/{id}) que abrem com filtros aplicados.
Dashboards ajudam a entender, mas times agem quando recebem um nudge no momento certo. Alertas devem estar ligados ao nível de conta para que CS e Sales não sejam inundados com ruído de baixo valor — ou, pior, percam problemas críticos em contas de alto valor.
Comece com um conjunto pequeno de sinais “algo está errado”:
Torne esses sinais sensíveis ao nível. Ex.: Enterprise pode alertar em 15% de queda semana a semana em um workflow core, enquanto SMB pode exigir 40% para evitar ruído de churn por uso esporádico.
Alertas de expansão devem destacar contas que estão crescendo em valor:
Novamente, thresholds variam por nível: um único power user pode ser relevante para SMB, enquanto Enterprise precisa de adoção multi-equipe.
Roteie alertas para onde o trabalho acontece:
Mantenha o payload acionável: nome da conta, nível, o que mudou, janela de comparação e um link para o drill-down (ex.: /accounts/{account_id}).
Todo alerta precisa de um dono e um playbook curto: quem responde, as 2–3 checagens iniciais (freshness dos dados, releases recentes, mudanças de admin) e o outreach recomendado ou guidance in-app.
Documente playbooks junto às definições de métrica para que respostas sejam consistentes e alertas continuem confiáveis.
Se métricas de adoção guiam decisões por nível (outreach CS, precificação, bets de roadmap), os dados precisam de guardrails. Um pequeno conjunto de checagens e hábitos de governança evita “quedas misteriosas” em dashboards e mantém stakeholders alinhados sobre o que os números significam.
Valide eventos o mais cedo possível (SDK cliente, gateway de API, ou worker de ingestão). Rejeite ou quarentena eventos não confiáveis.
Implemente checagens como:
account_id ou user_id ausentes (ou valores que não existem na tabela de contas)tier inválidos (fora do enum aprovado)Mantenha uma tabela de quarentena para inspecionar eventos ruins sem poluir analytics.
Rastreamento de adoção é sensível a tempo; eventos tardios distorcem métricas semanais e rollups por nível. Monitore:
Encaminhe monitores para um canal on-call, não para todo mundo.
Retries acontecem (redes móveis, redelivery de webhooks, replays de batch). Torne a ingestão idempotente usando um idempotency_key ou um event_id estável, e dedupe dentro de uma janela de tempo.
Suas agregações devem ser seguras para re-execução sem double counting.
Crie um glossário que defina cada métrica (inputs, filtros, janela de tempo, regras de atribuição de nível) e trate-o como a fonte única de verdade. Vincule dashboards e docs a esse glossário (ex.: /docs/metrics).
Adicione logs de auditoria para mudanças em definições de métrica e regras de scoring — quem mudou o quê, quando e por quê — para que alterações em tendências possam ser explicadas rapidamente.
Analytics de adoção só é útil se as pessoas confiam nele. A abordagem mais segura é projetar seu app de tracking para responder perguntas de adoção coletando o mínimo de dados sensíveis possível, e fazer “quem pode ver o quê” um recurso de primeira classe.
Comece com identificadores suficientes para insights de adoção: account_id, user_id (ou id pseudonimizado), timestamp, feature, e um pequeno conjunto de propriedades de comportamento (plano, nível, plataforma). Evite capturar nomes, emails, inputs em texto livre ou qualquer coisa que possa conter segredos.
Se precisar de análise a nível de usuário, armazene identificadores de usuário separadamente do PII e una apenas quando necessário. Considere IPs e identificadores de dispositivo como sensíveis; se não são necessários para scoring, não os retenha.
Defina papéis claros:
Padrão para views agregadas. Faça drill-down por usuário uma permissão explícita e oculte campos sensíveis (emails, nomes completos, ids externos) a menos que o papel realmente exija.
Dê suporte a pedidos de deleção, podendo remover histórico de eventos de um usuário (ou anonimizar) e deletar dados de conta no fim de contrato.
Implemente regras de retenção (ex.: manter eventos brutos por N dias, agregados por mais tempo) e documente-as na política. Registre consentimento e responsabilidades de processamento quando aplicável.
A maneira mais rápida de gerar valor é escolher uma arquitetura que case com onde seus dados já vivem. Você pode evoluir depois — o que importa é entregar insights confiáveis por nível rapidamente.
Warehouse-first analytics: eventos fluem para um warehouse (BigQuery/Snowflake/Postgres), então você calcula métricas de adoção e as serve para um web app leve. Ideal se você já usa SQL, tem analistas ou quer uma fonte de verdade compartilhada com outros relatórios.
App-first analytics: seu web app grava eventos no próprio banco e calcula métricas na aplicação. Pode ser mais rápido para produtos pequenos, mas é fácil ultrapassar quando volume cresce e reprocessamento histórico vira necessário.
Um padrão prático para a maioria das equipes SaaS é warehouse-first com um pequeno banco operacional para tabelas de configuração (níveis, definições de métrica, regras de alerta).
Entregue uma primeira versão com:
3–5 métricas (ex.: contas ativas, uso de recurso chave, adoption score, retenção semanal, time-to-first-value).
Uma página de visão por nível: adoption score por nível + tendência no tempo.
Uma view de conta: nível atual, última atividade, principais recursos usados e um resumo simples do “porquê” do score.
Adicione loops de feedback cedo: permita que Sales/CS sinalizem “isso parece errado” direto do dashboard. Versione definições de métrica para poder mudar fórmulas sem reescrever histórico silenciosamente.
Implante gradualmente (um time → toda a org) e mantenha um changelog de atualizações de métricas no app (ex.: /docs/metrics) para que stakeholders sempre saibam o que estão vendo.
Se quiser sair da “spec” para um app interno funcionando rápido, uma abordagem vibe-coding pode ajudar — especialmente no MVP, quando você valida definições, não aperfeiçoa infraestrutura.
Com Koder.ai, times podem prototipar um app de analytics de adoção via interface de chat enquanto geram código real e editável. Isso é útil porque o escopo é transversal (UI React, API, modelo Postgres e rollups agendados) e tende a evoluir enquanto stakeholders convergem em definições.
Um fluxo comum:
Como Koder.ai suporta deploy/hosting, domínios customizados e exportação de código, pode ser uma forma prática de chegar a um MVP interno crível mantendo suas escolhas arquiteturais futuras (warehouse-first vs app-first) em aberto.
Comece com uma definição compartilhada de adoção como uma sequência:
Depois torne isso sensível ao nível (por exemplo, SMB: ativação em 7 dias; Enterprise: ativação que exige ações do administrador + usuários finais).
Porque os níveis se comportam de forma diferente. Uma única métrica pode:
Segmentar por nível permite definir metas realistas, escolher a north-star certa por nível e disparar alertas adequados para contas de maior valor.
Use um conjunto de regras determinísticas e documentadas:
account_tier_history com valid_from / .Escolha um resultado primário por nível que reflita valor real:
Deve ser contável, difícil de manipular e claramente ligado a resultados do cliente — não cliques.
Defina estágios explícitos e regras de qualificação para evitar interpretações divergentes. Exemplo:
Instrumente um conjunto pequeno de eventos críticos do caminho principal:
signup_completeduser_invited, invite_acceptedfirst_value_received (defina seu “aha” precisamente)Inclua propriedades que permitam slicing e atribuição confiáveis:
Use ambos:
Snapshots costumam armazenar usuários ativos, contagens de recursos chave, componentes da pontuação de adoção e o nível naquela data — assim mudanças de nível não reescrevem histórico.
Torne-a simples, explicável e estável:
core_action em 3 dias distintos dentro de 14 dias).Agregue por nível usando distribuições (mediana, percentis, % acima de um limiar), não só médias.
Faça alertas sensíveis ao nível e acionáveis:
Roteie notificações para onde o trabalho acontece (Slack/email para urgente, digest semanal para baixa urgência) e inclua: o que mudou, janela de comparação e um link de drill-down como /accounts/{account_id}.
valid_toIsso evita que dashboards mudem de significado quando contas fizerem upgrade ou downgrade.
Ajuste os requisitos por nível (por exemplo, Enterprise pode exigir ação do admin e de usuários finais).
key_feature_used (ou eventos por recurso)integration_connectedPriorize eventos que representam progresso rumo a resultados, não todo clique na UI.
account_id (obrigatório)user_id (obrigatório quando envolver pessoa)tier (capturado no momento do evento)plan / SKU (se relevante)role (owner/admin/member)workspace_id, feature_name, source, timestampUse nomenclatura consistente (snake_case) para evitar que consultas se tornem um projeto de tradução.