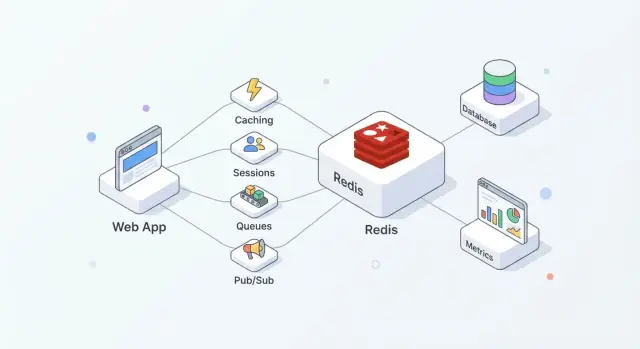
O que o Redis faz para aplicações modernas
O Redis é um armazenamento em memória frequentemente usado como uma camada “rápida” compartilhada para aplicações. As equipes gostam dele porque é simples de adotar, extremamente rápido para operações comuns e flexível o suficiente para assumir mais de um papel (cache, sessões, contadores, filas, pub/sub) sem exigir a introdução de um sistema novo para cada necessidade.
Na prática, o Redis funciona melhor quando você o trata como velocidade + coordenação, enquanto seu banco de dados primário continua sendo a fonte da verdade.
Onde o Redis se encaixa em uma arquitetura típica
Uma configuração comum se parece com isto:
- Banco de dados: dados duráveis e autoritativos (pedidos, usuários, faturas)
- Redis: acesso rápido e estado efêmero compartilhado (páginas em cache, tokens de sessão, contadores de limite de taxa)
- App: decide o que vai para cada lugar e quando atualizar, invalidar ou reconstruir
Essa separação mantém seu banco focado em correção e durabilidade, enquanto o Redis absorve leituras/gravações de alta frequência que, de outra forma, aumentariam latência ou carga.
Usado corretamente, o Redis tende a entregar alguns resultados práticos:
- Leituras mais rápidas: sirva dados frequentemente requisitados da memória em vez de consultar o banco a toda solicitação.
- Picos de tráfego mais suaves: caching e contadores leves ajudam a sobreviver a rajadas sem que o banco se torne gargalo.
- Coordenação mais simples: múltiplos servidores de app podem compartilhar estado efêmero (sessões, locks, chaves de deduplicação) em vez de reconstruir essa lógica por instância.
Quando o Redis não é a ferramenta certa
O Redis não substitui um banco de dados primário. Se você precisa de consultas complexas, garantias de armazenamento de longo prazo ou relatórios analíticos, o banco de dados continua sendo o local apropriado.
Além disso, não presuma que o Redis é “durável por padrão”. Se perder até mesmo alguns segundos de dados for inaceitável, você precisará de configurações de persistência cuidadosas — ou de outro sistema — conforme seus requisitos reais de recuperação.
Fundamentos do Redis que você deve saber antes de implementar
O Redis costuma ser descrito como um “key-value store”, mas é mais útil pensar nele como um servidor muito rápido que pode conter e manipular pequenos pedaços de dados por nome (a chave). Esse modelo incentiva padrões de acesso previsíveis: normalmente você sabe exatamente o que quer (uma sessão, uma página em cache, um contador) e o Redis pode buscar ou atualizar isso em uma única viagem.
Por que é rápido: memória em primeiro lugar
O Redis mantém os dados na RAM, por isso pode responder em microssegundos a poucos milissegundos. A troca é que RAM é limitada e mais cara que disco.
Decida cedo se o Redis será:
- Apenas uma camada de desempenho (cache puro), ou
- Parte do caminho do estado (sessões, filas), onde o comportamento em reinícios e as configurações de persistência importam
O Redis pode persistir dados em disco (snapshots RDB e/ou logs AOF append-only), mas a persistência adiciona overhead de escrita e impõe escolhas de durabilidade (por exemplo, “rápido, mas pode perder um segundo” vs “mais lento, porém mais seguro”). Trate a persistência como um botão que você ajusta com base no impacto ao negócio, não como uma caixa que se marca automaticamente.
Single-threaded não significa lento
O Redis executa comandos majoritariamente em uma única thread, o que soa limitante até você lembrar duas coisas: operações tipicamente são pequenas, e não há overhead de locking entre múltiplas threads de trabalho. Contanto que você evite comandos caros e cargas úteis oversized, esse modelo pode ser extremamente eficiente sob alta concorrência.
Clientes, conexões e padrões de requisição
Seu app conversa com o Redis via TCP usando bibliotecas clientes. Use pool de conexões, mantenha requisições pequenas e prefira batching/pipelining quando precisar de múltiplas operações.
Planeje timeouts e tentativas: o Redis é rápido, mas redes não são, e sua aplicação deve degradar graciosamente quando o Redis estiver ocupado ou temporariamente indisponível.
Se você está construindo um serviço novo e quer padronizar essas bases rapidamente, uma plataforma como Koder.ai pode ajudar a esboçar uma aplicação React + Go + PostgreSQL e então adicionar funcionalidades com Redis (cache, sessões, limitação de taxa) via fluxo guiado por chat — ainda permitindo exportar o código-fonte e rodar onde for necessário.
Padrões de caching que funcionam em apps reais
O caching só ajuda quando há propriedade clara: quem preenche, quem invalida e o que significa “suficientemente fresco”.
O padrão cache-aside (o padrão para a maioria dos apps)
Cache-aside significa que sua aplicação — não o Redis — controla leituras e gravações.
Fluxo típico:
- Leitura: procure o item no Redis.
- Hit: retorne imediatamente.
- Miss: busque na fonte de dados primária (banco, API, serviço).
- Preencha: armazene o resultado no Redis com TTL.
- Retorne: responda ao chamador.
O Redis é um armazenamento rápido por chave; sua aplicação decide como serializar, versionar e expirar entradas.
TTLs: escolher expiração sem surpreender usuários
Um TTL é tanto uma decisão de produto quanto técnica. TTLs curtos reduzem obsolescência, mas aumentam a carga no banco; TTLs longos salvam trabalho, mas arriscam resultados desatualizados.
Dicas práticas:
- Combine com a taxa natural de atualização dos dados (por exemplo, preços vs foto de perfil).
- Use chaves versionadas para mudanças de esquema (ex.:
user:v3:123) para que formas antigas em cache não quebrem código novo.
- Trate dados obsoletos intencionalmente: para algumas visualizações, conteúdo levemente obsoleto é aceitável; para outras (inventário, autenticação), não é.
Evitando cache stampede
Quando uma chave quente expira, muitas requisições podem falhar ao mesmo tempo.
Defesas comuns:
- Coalescência de requisições: deixe apenas uma requisição reconstruir o valor enquanto as outras esperam ou servem a versão anterior.
- Jitter no TTL: adicione um pouco de aleatoriedade para que muitas chaves não expirem simultaneamente.
- Soft TTL: trate um valor como “obsoleto mas utilizável” por um breve período enquanto uma atualização em background atualiza o Redis.
O que cachear (e o que pular)
Bons candidatos incluem respostas de API, resultados de consultas caras e objetos computados (recomendações, agregações). Cachear páginas HTML completas pode funcionar, mas tenha cuidado com personalização e permissões — prefira fragmentos de cache quando houver lógica específica por usuário.
Armazenamento de sessões e fluxos de autenticação
O Redis é um local prático para manter estado de login de curta duração: IDs de sessão, metadados de refresh-token e flags de “lembrar este dispositivo”. O objetivo é tornar a autenticação rápida ao mesmo tempo em que mantém vida útil e revogação de sessões sob controle rigoroso.
Usando Redis para sessões de usuário
Um padrão comum é: sua aplicação emite um session ID aleatório, armazena um registro compacto no Redis e retorna o ID ao navegador como cookie HTTP-only. Em cada requisição, você consulta a chave de sessão e anexa identidade e permissões do usuário ao contexto da requisição.
O Redis funciona bem aqui porque leituras de sessão são frequentes e a expiração de sessão já é nativa.
Design de chaves e gerenciamento de TTL
Projete chaves para que sejam fáceis de varrer e revogar:
sess:{sessionId} → payload da sessão (userId, issuedAt, deviceId)user:sessions:{userId} → um Set de session IDs ativos (opcional, para “desconectar em todos”)
Use um TTL em sess:{sessionId} que corresponda ao tempo de vida da sessão. Se você rotaciona sessões (recomendado), crie um novo session ID e delete o antigo imediatamente.
Cuidado com “sliding expiration” (estender TTL a cada requisição): isso pode manter sessões vivas indefinidamente para usuários muito ativos. Um compromisso mais seguro é estender o TTL apenas quando ele estiver perto de expirar.
Revogação e logout entre dispositivos
Para deslogar um único dispositivo, delete sess:{sessionId}.
Para deslogar em todos os dispositivos, ou:
- delete todos os session IDs encontrados em
user:sessions:{userId}, ou
- mantenha um timestamp
user:revoked_after:{userId} e trate qualquer sessão emitida antes dele como inválida
O método do timestamp evita fan-out de deletes em larga escala.
Privacidade e considerações de segurança
Armazene o mínimo necessário no Redis — prefira IDs em vez de dados pessoais. Nunca armazene senhas em texto ou segredos de longa duração. Se precisar guardar dados relacionados a tokens, armazene hashes e use TTLs curtos.
Restrinja quem pode conectar ao Redis, exija autenticação e mantenha session IDs com alta entropia para evitar ataques de adivinhação.
Limitação de taxa e prevenção de abuso
Rate limiting é onde o Redis brilha: é rápido, compartilhado entre instâncias e oferece operações atômicas que mantêm contadores consistentes sob tráfego intenso. É útil para proteger endpoints de login, buscas caras, fluxos de redefinição de senha e qualquer API que possa ser raspada ou alvo de bruteforce.
Modelos comuns de rate limiting
Fixed window é o mais simples: “100 requisições por minuto.” Você conta requisições no bucket do minuto atual. É fácil, mas pode permitir rajadas na borda (ex.: 100 às 12:00:59 e 100 às 12:01:00).
Sliding window suaviza as bordas olhando para os últimos N segundos/minutos em vez do bucket atual. É mais justo, mas normalmente custa mais (pode exigir sorted sets ou mais bookkeeping).
Token bucket é ótimo para lidar com rajadas. Usuários “ganham” tokens ao longo do tempo até um limite; cada requisição consome um token. Isso permite explosões curtas enquanto ainda impõe uma taxa média.
Blocos seguros: INCR/EXPIRE e atomicidade
Um padrão fixo comum é:
INCR key para incrementar um contadorEXPIRE key window_seconds para definir/resetar o TTL
O problema é fazer isso com segurança. Se você fizer INCR e EXPIRE como chamadas separadas, uma queda entre elas pode criar chaves que nunca expiram.
Abordagens mais seguras incluem:
- Use um script Lua para executar
INCR e definir EXPIRE apenas quando o contador é criado.
- Ou use
SET key 1 EX <ttl> NX para inicialização, e então INCR depois (frequentemente ainda embrulhado em um script para evitar races).
Operações atômicas importam mais quando o tráfego explode: sem elas, duas requisições podem “ver” a mesma cota restante e ambas passarem.
Escopo: por usuário, por IP, por rota (e rajadas)
A maioria dos apps precisa de camadas múltiplas:
- Por usuário para chamadas autenticadas (ex.:
rl:user:{userId}:{route})
- Por IP para endpoints anônimos ou pré-auth (ex.: tentativas de login)
- Por rota para proteger pontos quentes (busca, exportações, relatórios)
Para endpoints com tráfego em rajadas, token bucket (ou uma janela fixa generosa mais uma janela curta de “burst”) ajuda a evitar penalizar picos legítimos como carregamentos de página ou reconexões móveis.
Quando o Redis está indisponível: fail-open vs fail-closed
Decida antecipadamente o que é “seguro”:
- Fail-open: permita requisições se o Redis não estiver acessível. Melhor experiência e uptime, porém proteção de abuso mais fraca.
- Fail-closed: negue requisições quando o Redis estiver fora. Proteção mais forte, mas risco de tornar partes do app parcialmente offline.
Um compromisso comum é fail-open para rotas de baixo risco e fail-closed para rotas sensíveis (login, reset de senha, OTP), com monitoramento para que você perceba quando o rate limiting parou de funcionar.
Construa e ganhe créditos
Ganhe créditos compartilhando o que você criou no Koder.ai ou indicando um colega.
O Redis pode alimentar jobs em background quando você precisa de uma fila leve para enviar e-mails, redimensionar imagens, sincronizar dados ou executar tarefas periódicas. A chave é escolher a estrutura certa e definir regras claras para retries e tratamento de falhas.
Lists, sorted sets e streams: qual usar e por quê
Lists são a fila mais simples: produtores LPUSH, workers BRPOP. São fáceis, mas você precisará de lógica extra para jobs “em voo”, retries e visibility timeouts.
Sorted sets brilham quando agendamento importa. Use o score como timestamp (ou prioridade) e os workers pegam o próximo job devido. Isso serve para jobs atrasados e filas com prioridade.
Streams costumam ser a melhor opção por padrão para distribuição de trabalho durável. Suportam consumer groups, mantêm histórico e permitem que múltiplos workers coordenem sem que você precise inventar sua própria lista de processamento.
Acknowledgements, retries e dead-letter handling
Com consumer groups de Streams, um worker lê uma mensagem e depois a ACKa. Se um worker cair, a mensagem permanece pendente e pode ser reclamada por outro worker.
Para retries, acompanhe contagens de tentativa (no payload da mensagem ou em uma chave lateral) e aplique backoff exponencial (frequentemente via um sorted set como “agenda de retries”). Após um limite máximo de tentativas, mova o job para uma dead-letter queue (outro stream ou lista) para revisão manual.
Estratégias de idempotência para workers
Pressupõe-se que jobs podem rodar duas vezes. Torne handlers idempotentes:
- Use uma chave de idempotência (ex.:
job:{id}:done) com SET ... NX antes de efeitos colaterais
- Projete operações como upserts, não “criar cegamente”
- Registre IDs de requisição externos ao chamar APIs de terceiros
Manter jobs pequenos e usar backpressure
Mantenha payloads pequenos (guarde dados grandes em outro lugar e passe referências). Adicione backpressure limitando o comprimento da fila, desacelerando produtores quando o lag aumenta e escalando workers com base na profundidade pendente e no tempo de processamento.
Pub/Sub e distribuição de eventos
Redis Pub/Sub é a maneira mais simples de transmitir eventos: publishers enviam uma mensagem a um canal, e todo subscriber conectado a recebe imediatamente. Não há polling — apenas um “push” leve que funciona bem para atualizações em tempo real.
Usos comuns em que Pub/Sub se encaixa bem
Pub/Sub é ideal quando você prioriza velocidade e fan-out sobre entrega garantida:
- Notificações ao usuário ("seu relatório está pronto")
- Atualizações de UI em tempo real (presença, indicadores de digitação, dashboards)
- Fan-out interno de eventos (um evento dispara múltiplos serviços)
Um modelo mental útil: Pub/Sub é como uma estação de rádio. Quem está sintonizado ouve a transmissão, mas ninguém recebe uma gravação automaticamente.
Limites-chave a planejar
Pub/Sub tem trade-offs importantes:
- Sem persistência: se ninguém está inscrito no momento da publicação, a mensagem se perde.
- Confiabilidade do subscriber: se um subscriber desconecta ou está sobrecarregado, pode perder mensagens.
- Sem replay ou acknowledgements: você não pode pedir ao Redis que “entregue até confirmar”.
Por isso, Pub/Sub é ruim para workflows em que cada evento deve ser processado (exatamente uma vez — ou mesmo ao menos uma vez).
Quando preferir Redis Streams
Se você precisa de durabilidade, retries, consumer groups ou backpressure, Redis Streams costumam ser a escolha preferida. Streams permitem armazenar eventos, processá-los com acknowledgements e recuperar após reinícios — muito mais próximo de uma fila leve e durável.
Padrões para apps multi-instância
Em implantações reais você terá múltiplas instâncias de app inscritas. Algumas dicas práticas:
- Namespace os canais para evitar colisões:
app:{env}:{domain}:{event} (ex.: shop:prod:orders:created).
- Separe canais de broadcast vs. direcionados: broadcast para
notifications:global e direcione usuários com notifications:user:{id}.
- Mantenha payloads pequenos e autocontidos: inclua um ID e metadados mínimos; busque detalhes em outro local só se necessário.
Assim, Pub/Sub vira um sinal rápido de evento, enquanto Streams (ou outra fila) lida com eventos que você não pode perder.
Escolhendo as estruturas de dados certas no Redis
Projete o uso do Redis desde o início
Use o modo de planejamento para mapear chaves, TTLs e comportamento em falhas antes de codificar.
Escolher uma estrutura não é apenas “o que funciona” — impacta uso de memória, velocidade de consulta e a simplicidade do seu código ao longo do tempo. Uma boa regra é escolher a estrutura que corresponda às perguntas que você fará depois (padrões de leitura), não apenas a forma como armazena hoje.
Guia rápido de seleção (strings, hashes, sets, sorted sets)
- Strings: melhores para valores únicos (blob JSON, flag de recurso, HTML em cache). Também ótimas para contadores atômicos com
INCR/DECR.
- Hashes: melhores para “um objeto com campos” (campos de perfil do usuário, totais do carrinho). Ideais quando você atualiza propriedades individuais com frequência.
- Sets: melhores para unicidade e checagens de pertencimento (o usuário já resgatou o cupom X?).
SISMEMBER é rápido e operações de conjuntos são fáceis.
- Sorted sets (ZSETs): melhores para dados ranqueados e queries “top N” (leaderboards, listas de prioridade, pontuação baseada em tempo).
Atualizações atômicas, contadores e leaderboards
Operações Redis são atômicas ao nível do comando, então você pode incrementar contadores sem condições de corrida. Page views e contadores de rate-limit usam strings com INCR mais expiry.
Leaderboards tiram proveito dos sorted sets: atualize scores (ZINCRBY) e busque os top players (ZREVRANGE) de forma eficiente, sem escanear todas as entradas.
Usando hashes para reduzir número de chaves e melhorar organização
Se você criar muitas chaves como user:123:name, user:123:email, user:123:plan, multiplica overhead por chave e complica o gerenciamento. Um hash user:123 com campos (name, email, plan) mantém dados relacionados juntos e normalmente reduz contagem de chaves. Também facilita updates parciais (atualize um campo em vez de reescrever um JSON inteiro).
Considerações de memória que afetam seu custo
- Muitas chaves pequenas podem custar mais memória do que você espera por causa do overhead por chave.
- Hashes costumam ser mais eficientes em memória para objetos pequenos a médios sob uma única chave.
- Sorted sets são poderosos, mas podem ser mais pesados que sets/strings — use quando ranqueamento ou consultas por score forem realmente necessárias.
Quando em dúvida, modele uma amostra pequena e meça uso de memória antes de comprometer uma estrutura para dados de alto volume.
Persistência, replicação e segurança de dados
O Redis é frequentemente descrito como “em memória”, mas você ainda tem escolhas sobre o que acontece quando um nó reinicia, um disco enche ou um servidor desaparece. A configuração certa depende de quanto dado você pode perder e com que rapidez precisa se recuperar.
RDB vs AOF: o que cada um fornece
RDB snapshots salvam um dump pontual do dataset. São compactos e rápidos de carregar na inicialização, o que pode tornar reinícios mais rápidos. A troca é que você pode perder as escritas mais recentes desde o último snapshot.
AOF (append-only file) registra operações de escrita conforme acontecem. Tipicamente reduz a perda potencial de dados porque mudanças são gravadas mais continuamente. Arquivos AOF podem crescer mais e replays na inicialização podem levar mais tempo — embora o Redis possa reescrever/compactar o AOF para mantê-lo manejável.
Muitas equipes executam ambos: snapshots para reinícios mais rápidos e AOF para melhor durabilidade de gravações.
Como a persistência afeta latência e reinicializações
Persistência não é gratuita. Escritas em disco, políticas de fsync do AOF e operações de rewrite em background podem adicionar picos de latência se seu armazenamento for lento ou saturado. Por outro lado, persistência torna reinícios menos assustadores: sem persistência, um reinício não planejado significa um Redis vazio.
Replicação e objetivos de failover
A replicação mantém uma cópia (ou cópias) dos dados em réplicas para permitir failover quando o primário cai. O objetivo costuma ser alta disponibilidade, não consistência perfeita. Em falhas, réplicas podem ficar ligeiramente atrás, e um failover pode perder as últimas escritas em alguns cenários.
Defina sua perda aceitável de dados e tempo de recuperação
Antes de ajustar qualquer coisa, escreva dois números:
- Perda aceitável de dados (RPO): “Podemos perder até X segundos/minutos de dados.”
- Tempo de recuperação (RTO): “Precisamos estar de volta em Y segundos/minutos.”
Use essas metas para escolher frequência de RDB, configurações de AOF e se você precisa de réplicas (e failover automatizado) para o papel do seu Redis — cache, store de sessão, fila ou datastore primário.
Escalando Redis: de uma instância a um cluster
Um único nó Redis pode te levar surpreendentemente longe: é simples de operar, fácil de raciocinar e muitas vezes rápido o suficiente para caches, sessões ou filas. Escalar se torna necessário quando você atinge limites rígidos — normalmente teto de memória, saturação de CPU ou quando um único nó vira ponto único de falha inaceitável.
Quando mover de uma instância para múltiplas
Considere adicionar mais nós quando um (ou mais) destes for verdadeiro:
- Seu dataset não cabe mais na RAM com folga segura.
- Picos de latência durante o tráfego porque o nó está limitado por CPU.
- Você precisa de maior disponibilidade do que “reiniciar e recuperar”.
- Você tem múltiplas cargas competindo (ex.: cache + filas) e quer isolamento.
Um passo prático inicial é separar workloads (duas instâncias Redis independentes) antes de pular para um cluster.
Sharding e Redis Cluster em termos simples
Sharding significa dividir suas chaves por vários nós Redis para que cada nó armazene apenas uma parcela dos dados. Redis Cluster é a maneira embutida do Redis para fazer isso automaticamente: o espaço de chaves é dividido em slots, e cada nó possui alguns desses slots.
O ganho é mais memória total e maior vazão agregada. A troca é complexidade adicional: operações multi-chave ficam restritas (as chaves devem estar no mesmo shard) e depurar envolve mais peças móveis.
Chaves quentes e distribuição desigual de tráfego
Mesmo com sharding “ uniforme”, o tráfego real pode ser desigual. Uma chave popular única (uma “hot key”) pode sobrecarregar um nó enquanto outros ficam ociosos.
Mitigações incluem adicionar TTLs curtos com jitter, dividir o valor em múltiplas chaves (hashing de chave) ou redesenhar padrões de acesso para dispersar leituras.
Um Redis Cluster exige um cliente ciente do cluster que descubra a topologia, roteie requisições para o nó certo e siga redirecionamentos quando slots se moverem.
Antes de migrar, confirme:
- Seu driver na linguagem suporta Redis Cluster totalmente.
- Sua estratégia de pooling funciona com múltiplos nós.
- Seu código evita comandos multi-key entre shards diferentes (ou usa hash tags para manter chaves relacionadas juntas).
Escalar funciona melhor quando é uma evolução planejada: valide com testes de carga, instrumente latência por chave e migre tráfego gradualmente em vez de simplesmente alternar tudo de uma vez.
Essenciais de segurança para implantações Redis
Implemente cache inteligente
Faça protótipos de cache-aside, TTLs e lógica de invalidação sem começar do zero.
O Redis é frequentemente tratado como “tubulação interna”, e é exatamente por isso que é um alvo frequente: uma única porta exposta pode se transformar em vazamento total de dados ou emum cache controlado por um invasor. Assuma que o Redis é infraestrutura sensível, mesmo que você armazene apenas dados “temporários”.
Autenticação e controle de acesso
Comece ativando autenticação e usando ACLs (Redis 6+). ACLs permitem:
- criar usuários separados para apps, workers e admins
- restringir comandos (ex.: permitir GET/SET mas negar CONFIG)
- limitar chaves por prefixo (útil em setups multi-tenant)
Evite compartilhar uma senha entre todos os componentes. Em vez disso, emita credenciais por serviço e mantenha permissões estreitas.
Isolamento de rede e TLS
O controle mais efetivo é não ser alcançável. Faça o bind do Redis em uma interface privada, coloque-o em uma sub-rede privada e restrinja tráfego de entrada com security groups/firewalls apenas aos serviços que precisam.
Use TLS quando o tráfego do Redis cruzar fronteiras de host que você não controla totalmente (multi-AZ, redes compartilhadas, nós Kubernetes ou ambientes híbridos). TLS previne sniffing e roubo de credenciais, e vale o pequeno overhead para sessões, tokens ou qualquer dado relacionado a usuários.
Comandos perigosos e má configuração
Bloqueie comandos que podem causar grande dano se abusados. Exemplos comuns para desabilitar ou restringir via ACLs: FLUSHALL, FLUSHDB, CONFIG, SAVE, DEBUG e EVAL (ou pelo menos controlar scripting cuidadosamente). Proteja com cuidado a abordagem rename-command — ACLs costumam ser mais claras e fáceis de auditar.
Gerenciamento de segredos e rotação
Armazene credenciais do Redis em seu gerenciador de segredos (não em código ou imagens de contêiner) e planeje rotação. A rotação é mais fácil quando os clientes podem recarregar credenciais sem redeploy, ou quando você suporta duas credenciais válidas durante uma janela de transição.
Se quiser um checklist prático, mantenha um nos seus runbooks junto com suas notas em /blog/monitoring-troubleshooting-redis.
Monitoramento, troubleshooting e higiene operacional
O Redis muitas vezes “parece bem”… até que o tráfego mude, memória suba ou um comando lento trave tudo. Uma rotina leve de monitoramento e um checklist de incidentes claro previnem a maioria das surpresas.
Métricas que realmente importam
Comece com um conjunto pequeno que todos na equipe entendam:
- Memória usada vs maxmemory: observe tendências, não apenas o uso atual.
- Cache hit rate (se você estiver usando como cache): hits baixos geralmente significam design de chave ruim, TTLs curtos ou leituras sendo contornadas.
- Latência: acompanhe p95/p99; picos importam mais que médias.
- Evictions: evictions sustentadas costumam indicar subdimensionamento ou TTLs errados.
- Lag de replicação (se houver réplicas): lag crescente pode quebrar escala de leitura e confiança no failover.
Troubleshooting rápido: slowlog e estatísticas de comandos
Quando algo está “lento”, confirme com as próprias ferramentas do Redis:
- SLOWLOG ajuda a identificar comandos caros (frequentemente grandes queries de range, fetches de valores grandes ou scans completos acidentais).
- Command stats (via INFO) mostram quais comandos dominam. Um salto súbito em
KEYS, SMEMBERS ou LRANGE grande é um sinal de alerta comum.
Se a latência subir enquanto a CPU parece ok, também considere saturação de rede, payloads oversized ou clientes bloqueados.
Planejamento de capacidade e folga
Planeje crescimento mantendo folga (comum 20–30% de memória livre) e revisite suposições após lançamentos ou flags de recurso. Trate “evictions constantes” como um incidente, não como um aviso.
Um runbook simples de incidentes
Durante um incidente, verifique (em ordem): memória/evictions, latência, conexões de cliente, slowlog, lag de replicação e deploys recentes. Anote as causas recorrentes e corrija permanentemente — apenas alertas não bastam.
Se sua equipe estiver iterando rapidamente, ajuda incorporar essas expectativas operacionais ao fluxo de desenvolvimento. Por exemplo, com o modo de planejamento e snapshots/rollback do Koder.ai, você pode prototipar recursos com Redis (caching, rate limiting), testá-los sob carga e reverter mudanças com segurança — mantendo a implementação no seu código por exportação de fonte.