REST de Roy Fielding: Restrições que moldam as APIs Web modernas
Entenda as restrições REST de Roy Fielding e como elas moldam o design prático de APIs e apps web: client-server, sem estado, cache, interface uniforme, camadas e mais.
REST de Roy Fielding: Restrições que moldam as APIs Web modernas | Koder.ai
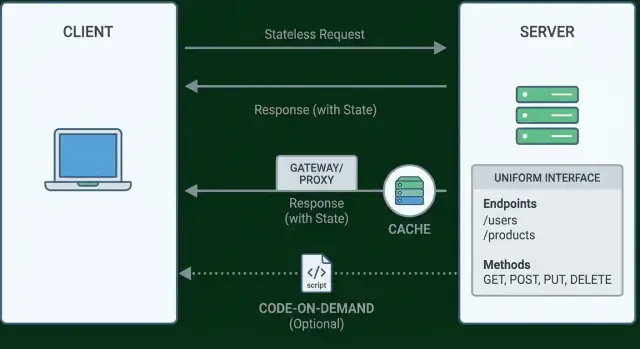
Por que o REST de Roy Fielding ainda importa\n\nRoy Fielding não é apenas um nome ligado a um buzzword de API. Ele foi um dos autores das especificações HTTP e URI e, em sua tese de doutorado, descreveu um estilo arquitetural chamado REST (Representational State Transfer) para explicar por que a Web funciona tão bem.\n\nEssa origem importa porque REST não foi inventado para criar “endpoints bonitos”. Foi uma maneira de descrever as restrições que permitem a uma rede global e bagunçada ainda assim escalar: muitos clientes, muitos servidores, intermediários, cache, falhas parciais e mudança contínua.\n\n### O que você vai tirar deste post\n\nSe você já se perguntou por que duas “APIs REST” parecem completamente diferentes — ou por que uma pequena escolha de design vira dor de cabeça com paginação, confusão de cache ou mudanças que quebram tudo — este guia foi feito para reduzir essas surpresas.\n\nVocê vai sair com:\n\n- decisões mais claras ao projetar ou avaliar uma API\n- um vocabulário melhor para discutir trade-offs com seu time\n- um senso prático de quais ideias REST importam realmente em projetos reais\n\n## REST em uma página: estilo, não um padrão\n\nREST não é uma checklist, um protocolo ou uma certificação. Fielding descreveu-o como um estilo arquitetural: um conjunto de restrições que, quando aplicadas em conjunto, produzem sistemas que escalam como a Web — simples de usar, capazes de evoluir com o tempo e amigáveis a intermediários (proxies, caches, gateways) sem coordenação constante.\n\n### O problema que o REST resolvia\n\nA Web inicial precisava funcionar entre muitas organizações, servidores, redes e tipos de cliente. Tinha de crescer sem controle central, sobreviver a falhas parciais e permitir que novas funcionalidades surgissem sem quebrar as antigas. REST resolve isso ao privilegiar um pequeno número de conceitos amplamente compartilhados (como identificadores, representações e operações padrão) em vez de contratos personalizados e fortemente acoplados.\n\n### “Restrições arquiteturais” em termos simples\n\nUma restrição é uma regra que limita liberdade de design em troca de benefícios. Por exemplo, você pode abrir mão do estado de sessão no servidor para que requisições possam ser atendidas por qualquer nó, o que melhora confiabilidade e escalabilidade. Cada restrição REST faz um trade-off parecido: menos flexibilidade ad-hoc, mais previsibilidade e evolutividade.\n\n### REST vs. APIs “parecidas com REST”\n\nMuitas APIs HTTP pegam ideias do REST (JSON sobre HTTP, endpoints, talvez códigos de status) mas não aplicam o conjunto completo de restrições. Isso não é “errado” — muitas vezes reflete prazos de produto ou necessidades internas. É apenas útil nomear a diferença: uma API pode ser orientada a recursos sem ser totalmente REST.\n\n### Modelo mental em um parágrafo\n\nPense num sistema REST como recursos (coisas que você pode nomear com URLs) que clientes interagem por meio de representações (a visão atual de um recurso, como JSON ou HTML), guiados por links (próximas ações e recursos relacionados). O cliente não precisa de regras secretas fora de banda; ele segue semântica padrão e navega usando links, do mesmo jeito que um navegador percorre a Web.\n\n## Recursos e Representações: o vocabulário central\n\nAntes de se perder em restrições e detalhes HTTP, REST começa com uma simples mudança de vocabulário: pense em recursos, não em ações.\n\n### Recurso = um substantivo que você pode identificar\n\nUm recurso é uma “coisa” endereçável no seu sistema: um usuário, uma fatura, uma categoria de produto, um carrinho. O importante é que seja um substantivo com identidade.\n\nPor isso /users/123 faz sentido: identifica o usuário com ID 123. Compare com URLs em forma de ação como /getUser ou /updateUserPassword. Esses descrevem verbos — operações — não a coisa sobre a qual você está operando.\n\nREST não diz que você não pode executar ações. Diz que ações devem ser expressas pela interface uniforme (para APIs HTTP, isso geralmente significa métodos como GET/POST/PUT/PATCH/DELETE) atuando sobre identificadores de recursos.\n\n### Representação = uma visão do recurso\n\nUma representação é o que você envia na rede como um snapshot ou visão daquele recurso em um ponto no tempo. O mesmo recurso pode ter múltiplas representações.\n\nPor exemplo, o recurso /users/123 pode ser representado como JSON para um app, ou HTML para um navegador.\n\n```http
GET /users/123
Accept: application/json
json
{
"id": 123,
"name": "Asha",
"email": ""
}
http
GET /users/123
Accept: text/html
json
{
"id": "ord_123",
"status": "pending",
"total": 49.90,
"_links": {
"self": { "href": "/orders/ord_123" },
"payment":{ "href": "/orders/ord_123/payment", "method": "POST" },
"cancel": { "href": "/orders/ord_123", "method": "DELETE" }
}
}
```\n\nSe o pedido depois ficar , o servidor pode parar de incluir e adicionar — sem quebrar um cliente bem comportado.\n\n### Quando hipermídia mais ajuda\n\nHipermídia brilha quando : passos de onboarding, checkout, aprovações, assinaturas ou qualquer processo onde “o que é permitido a seguir” muda baseado em estado, permissões ou regras de negócio.\n\nTambém reduz e suposições frágeis do cliente. Você pode reorganizar rotas, introduzir novas ações ou deprecar antigas enquanto mantém clientes funcionais desde que preserve o significado das relações de link.\n\n### Por que times pulam e o que perdem\n\nTimes frequentemente pulam HATEOAS porque dá trabalho extra: definir formatos de link, concordar em nomes de relações e ensinar desenvolvedores clientes a seguir links em vez de construir URLs.\n\nO que você perde é um benefício chave do REST: . Sem hipermídia, muitas APIs viram “RPC sobre HTTP” — usam HTTP, mas clientes ainda dependem fortemente de documentação fora de banda e templates de URL fixos.\n\n## Restrição 5: Sistema em camadas\n\nUm sistema em camadas significa que um cliente não precisa saber (e muitas vezes não consegue dizer) se está falando com o servidor de origem “real” ou com intermediários no caminho. Essas camadas podem incluir gateways de API, proxies reversos, CDNs, serviços de auth, WAFs, service meshes e até roteamento entre microserviços.\n\n### Por que camadas são úteis\n\nCamadas criam fronteiras claras. Times de segurança podem impor TLS, limites de taxa, autenticação e validação de requisições na borda sem mudar cada serviço backend. Times de operações podem escalar horizontalmente atrás de um gateway, adicionar cache em uma CDN ou redistribuir tráfego em incidentes. Para clientes, isso simplifica: um endpoint de API estável, cabeçalhos consistentes e formatos de erro previsíveis.\n\n### Trade-offs sentidos na prática\n\nIntermediários podem introduzir latência oculta (saltos extras, handshakes adicionais) e dificultar a depuração: o bug pode estar nas regras do gateway, no cache da CDN ou no código de origem. Cache também fica confuso quando camadas diferentes cacheiam de forma diversa, ou quando um gateway reescreve cabeçalhos que influenciam chaves de cache.\n\n### Dicas práticas para evitar que camadas prejudiquem\n\n- : aceite um ID de requisição (ou gere um) e propague-o por todo hop; inclua-o em respostas e logs.\n- : padronize corpos de erro e mapeie falhas upstream claramente (não transforme tudo em 500 genérico).\n- : timeouts de gateway, upstream e cliente devem estar alinhados para evitar desconexões misteriosas.\n- : seja claro sobre quais respostas são cacheáveis e quais cabeçalhos intermediários devem preservar.\n\nCamadas são poderosas — quando o sistema permanece observável e previsível.\n\n## Restrição 6 (Opcional): Código sob demanda\n\nCódigo sob demanda é a única restrição REST explicitamente . Significa que um servidor pode estender um cliente enviando que roda no lado do cliente. Em vez de embutir todo comportamento no cliente antecipadamente, o cliente pode baixar nova lógica conforme necessário.\n\n### O exemplo conhecido da web: JavaScript\n\nSe você já carregou uma página que depois fica interativa — validando um formulário, renderizando um gráfico, filtrando uma tabela — você já usou código sob demanda. O servidor entrega HTML e dados, mais que roda no navegador para fornecer comportamento.\n\nIsso é uma grande razão de a web poder evoluir rápido: um navegador pode permanecer um cliente de propósitos gerais, enquanto sites entregam novas funcionalidades sem exigir que o usuário instale um app inteiro.\n\n### Por que é opcional (e por que muitas APIs pulam)\n\nREST funciona totalmente sem código sob demanda porque as outras restrições já permitem escalabilidade, simplicidade e interoperabilidade. Uma API pode ser puramente orientada a recursos — servindo representações como JSON — enquanto clientes implementam seu próprio comportamento.\n\nMuitas APIs modernas evitam enviar código executável porque complica:\n\n- : código executável amplia superfície de ataque (injeção, supply-chain, scripts maliciosos).\n- : navegadores aplicam Content Security Policy (CSP) e organizações podem bloquear scripts inline ou origens desconhecidas.\n- : é mais difícil provar que código rodou num cliente em determinado momento se ele é buscado dinamicamente.\n\n### Quando código sob demanda ainda faz sentido\n\nCódigo sob demanda pode ser útil quando você controla o ambiente cliente e precisa liberar comportamento de UI rapidamente, ou quando quer um cliente fino que baixa “plugins” ou regras do servidor. Mas trate como uma ferramenta extra, não como um requisito.\n\nA lição: — e muitas APIs de produção fazem isso — porque a restrição é sobre extensibilidade opcional, não a base da interação orientada a recursos.\n\n## Aplicando REST hoje: escolhas práticas e deslizes comuns\n\nA maioria dos times não REST — eles adotam um estilo “meio REST” que mantém HTTP como transporte enquanto descarta silenciosamente restrições chave. Isso pode ser aceitável, desde que seja uma troca consciente e não um acidente que apareça depois como clientes frágeis e reescritas caras.\n\n### Atalhos REST-ish comuns (e por que acontecem)\n\nPadrões que aparecem repetidamente:\n\n- , , — fáceis de nomear, fáceis de ligar.\n- , , — métodos HTTP viram detalhe.\n- APIs “stateless” que ainda dependem de sticky sessions, memória server-side ou estado de fluxo implícito.\n\nEssas escolhas muitas vezes parecem produtivas no início porque espelham nomes de funções internas e operações de negócio.\n\n### Consequências que você notará depois\n\n- se clientes dependem de formas específicas de endpoints e comportamentos ad-hoc, pequenas refatorações do servidor viram breaking changes.\n- quando URLs codificam ações em vez de recursos estáveis, você acaba versionando em vez de evoluir representações.\n- ignorar cabeçalhos de cache ou usar POST para tudo impede que intermediários (e navegadores) te ajudam.\n- estado de sessão server-side complica escalabilidade horizontal e recuperação de falhas.\n\n### Checklist pragmático de alinhamento\n\nUse isto para revisar “quão REST nós somos, realmente?”:\n\n1. prefira sobre .\n2. GET para leitura, POST para criação, PUT/PATCH para atualização, DELETE para remoção.\n3. nada de memória do servidor necessária para entender “em que etapa o cliente está”.\n4. defina , e para respostas GET.\n5. códigos de status consistentes e formatos de resposta reduzem casos especiais.\n\n### Onde isso aparece quando você está realmente construindo\n\nRestrições REST não são só teoria — são guardrails que você sente enquanto entrega. Quando você gera uma API rápido (por exemplo, scaffolding de uma frontend React com backend em Go + PostgreSQL), o erro mais fácil é deixar “o que for mais rápido de conectar” ditar sua interface.\n\nSe você usa uma plataforma de vibe-coding como para construir um app web a partir de chat, ajuda trazer essas restrições REST para a conversa cedo — nomear recursos primeiro, manter sem estado, definir formatos de erro consistentes e decidir onde cache é seguro. Assim, mesmo iterações rápidas produzem APIs previsíveis para clientes e mais fáceis de evoluir. (E como Koder.ai suporta exportação de código-fonte, você pode continuar refinando contrato e implementação conforme os requisitos amadurecem.)\n\n### Conclusões para times de API e web apps\n\nDefina seus recursos-chave primeiro, depois escolha restrições conscientemente: se você está pulando cache ou hipermídia, documente por quê e o que está usando em vez disso. O objetivo não é pureza — é clareza: identificadores de recurso estáveis, semântica previsível e trade-offs explícitos que mantêm clientes resilientes conforme seu sistema evolui.
Perguntas frequentes
O que Roy Fielding quis dizer com “REST”, e por que não é um padrão?
REST (Representational State Transfer) é um estilo arquitetural descrito por Roy Fielding para explicar por que a Web escala.
Não é um protocolo ou uma certificação — é um conjunto de restrições (cliente–servidor, sem estado, cacheável, interface uniforme, sistema em camadas, código sob demanda opcional) que trocam alguma flexibilidade por escalabilidade, evolutividade e interoperabilidade.
Por que duas “APIs REST” frequentemente parecem completamente diferentes?
Porque muitas APIs adotam apenas parte das ideias REST (JSON sobre HTTP, URLs amigáveis) e ignoram outras (regras de cache ou hipermídia, por exemplo).
Duas APIs chamadas “REST” podem parecer muito diferentes dependendo de se elas:
modelam recursos estáveis vs. endpoints de ação
usam semântica HTTP de forma consistente (métodos, códigos de status, cabeçalhos)
suportam caching e intermediários
reduzem acoplamento do cliente com links descobráveis
Qual é a diferença prática entre “recursos” e “ações” no design de URLs?
Um recurso é um substantivo identificável (ex.: /users/123). Um endpoint de ação é um verbo incorporado na URL (ex.: /getUser, /updatePassword).
Design orientado a recursos tende a envelhecer melhor porque identificadores permanecem estáveis enquanto fluxos e UIs mudam. Ações ainda podem existir, mas normalmente são expressas via métodos HTTP e representações, em vez de caminhos em forma de verbo.
O que é uma “representação” e por que o recurso não é o JSON?
Recurso é o conceito (por exemplo, “usuário 123”). Representação é o snapshot que você transfere (JSON, HTML etc.).
Isso importa porque você pode evoluir ou adicionar representações sem mudar o identificador do recurso. Clientes devem depender do significado do recurso, não de um único formato de payload.
Como a separação cliente–servidor ajuda equipes de API no dia a dia?
A separação cliente–servidor mantém preocupações independentes:
Cliente: UI, interação, navegação, validação local, estados de carregamento
Servidor: autenticação/autorização, regras de negócio, persistência, auditoria
Se uma decisão afeta segurança, dinheiro, permissões ou consistência compartilhada, pertence ao servidor. Essa separação permite “um backend, várias frontends” (web, mobile, parceiros).
O que significa “stateless” para uma API HTTP, e o que muda na prática?
Estar sem estado significa que o servidor não depende de sessão armazenada para entender uma requisição. Cada requisição inclui o que é necessário (autenticação + contexto).
Benefícios: escalabilidade horizontal mais simples (qualquer nó pode tratar qualquer requisição) e depuração facilitada (o contexto fica visível nas requisições e logs).
Padrões comuns:
Quais cabeçalhos de cache importam mais, e quando devo usá-los?
Respostas cacheáveis permitem que clientes e intermediários reutilizem respostas de forma segura, reduzindo latência e carga no servidor.
Ferramentas HTTP práticas:
Cache-Control para frescor e escopo
REST é apenas “usar GET/POST/PUT/DELETE corretamente”, ou é algo maior?
A interface uniforme é sobre consistência para que clientes não precisem de regras especiais por endpoint.
Na prática, foque em:
O que é HATEOAS (hipermídia) e quando realmente vale a pena?
Hipermídia significa que respostas incluem links para ações válidas, então clientes seguem links em vez de codificar templates de URL.
É mais útil quando fluxos mudam com base no estado ou permissões (checkout, aprovações, onboarding). Um cliente bem-comportado se mantém resiliente se o servidor adicionar/remover ações alterando o conjunto de links.
Times pulam isso porque exige trabalho extra (formato de links, nomes de relações), mas o custo é acoplamento maior com documentação e rotas fixas.
Como “sistemas em camadas” afetam comportamento, desempenho e depuração de APIs?
Sistemas em camadas permitem intermediários (CDNs, gateways, proxies, camadas de autenticação) para que o cliente não precise saber qual componente respondeu.
Para evitar que camadas virem pesadelos de depuração:
propague um ID de requisição/correlação por toda a cadeia
mapeie erros explicitamente (não transforme tudo em 500 genérico)
alinhe timeouts por hop (cliente, gateway, upstream)
documente comportamento de cache e preserve cabeçalhos relevantes
Camadas são uma vantagem quando o sistema é observável e previsível.
\n\nPode retornar uma página HTML que renderiza os mesmos detalhes do usuário.\n\nA ideia-chave: **o recurso não é o JSON** e não é o HTML. Esses são apenas formatos usados para representá-lo.\n\n### Por que esse enquadramento muda o design de APIs\n\nUma vez que você modela sua API em torno de recursos e representações, várias decisões práticas ficam mais fáceis:\n\n- **Nomes permanecem estáveis.** `/users/123` continua válido mesmo se sua UI, fluxos ou modelo de dados mudarem.\n- **Endpoints ficam mais simples.** Em vez de inventar uma URL nova para cada operação, você reutiliza URLs de recurso e varia o método ou a representação.\n- **Código cliente fica menos acoplado.** Clientes focam em “buscar o usuário” ou “atualizar campos do usuário” em vez de memorizar um catálogo de endpoints de ação.\n\nEssa mentalidade orientada a recursos é a base sobre a qual as restrições REST se apoiam. Sem ela, “REST” muitas vezes se reduz a “JSON sobre HTTP com URLs bonitas.”\n\n## Restrição 1: Separação Cliente–Servidor\n\nA separação cliente–servidor é a maneira do REST de impor uma divisão clara de responsabilidades. O cliente foca na experiência do usuário (o que as pessoas veem e fazem), enquanto o servidor foca em dados, regras e persistência (o que é verdadeiro e o que é permitido). Quando você mantém essas preocupações separadas, cada lado pode mudar sem forçar uma reescrita do outro.\n\n### O que vive no cliente vs. no servidor?\n\nNo dia a dia, o cliente é a “camada de apresentação”: telas, navegação, validação local para feedback rápido e comportamento otimista (como mostrar um comentário novo imediatamente). O servidor é a “fonte da verdade”: autenticação, autorização, regras de negócio, armazenamento de dados, auditoria e tudo que precisa permanecer consistente entre dispositivos.\n\nUma regra prática: se uma decisão afeta segurança, dinheiro, permissões ou consistência de dados compartilhados, ela pertence ao servidor. Se afeta apenas como a experiência se sente (layout, dicas de entrada locais, estados de carregamento), pertence ao cliente.\n\n### Por que isso se encaixa em padrões modernos\n\nEssa restrição mapeia diretamente para setups comuns:\n\n- **SPA + API**: um app web (React/Vue/etc.) itera na UI enquanto a API continua servindo recursos.\n- **Apps móveis**: clientes iOS e Android podem compartilhar as mesmas regras e endpoints do servidor.\n- **Integrações de terceiros**: parceiros consomem as mesmas capacidades do servidor sem precisar da sua UI.\n\nSeparação cliente–servidor é o que torna “um backend, muitas frontends” realista.\n\n### Armadilha comum: vazar estado de UI em sessões do servidor\n\nUm erro frequente é armazenar estado de fluxo de UI no servidor (por exemplo: “em qual passo do checkout o usuário está”) numa sessão server-side. Isso acopla o backend a um fluxo de tela específico e dificulta a escalabilidade.\n\nPrefira enviar o contexto necessário em cada requisição (ou derivá-lo de recursos armazenados), para que o servidor permaneça focado em recursos e regras — não em lembrar como uma UI específica está progredindo.\n\n## Restrição 2: Interações sem estado\n\nSem estado significa que o servidor não precisa lembrar nada sobre um cliente entre requisições. Cada requisição carrega todas as informações necessárias para entendê-la e respondê-la corretamente — quem é o chamador, o que ele quer e qualquer contexto necessário para processá-la.\n\n### Por que isso importa\n\nQuando requisições são independentes, você pode adicionar ou remover servidores atrás de um balanceador de carga sem se preocupar com “qual servidor conhece minha sessão”. Isso melhora escalabilidade e resiliência: qualquer instância pode tratar qualquer requisição.\n\nTambém simplifica operações. Depurar costuma ser mais fácil porque o contexto completo está visível na requisição (e nos logs), em vez de escondido em memória de sessão do servidor.\n\n### Os trade-offs sentidos em APIs reais\n\nAPIs sem estado normalmente enviam um pouco mais de dados por chamada. Em vez de depender de uma sessão armazenada no servidor, os clientes incluem credenciais e contexto a cada vez.\n\nVocê também precisa ser explícito sobre fluxos “estaduais” (como paginação ou checkouts em vários passos). REST não proíbe experiências multi-etapa — ele apenas empurra o estado para o cliente ou para recursos do servidor que são identificáveis e recuperáveis.\n\n### Padrões práticos (e o que resolvem)\n\n- **Tokens de autenticação (ex.: Bearer JWTs)**: toda requisição inclui um header `Authorization: Bearer …` para que qualquer servidor possa autenticá-la.\n- **Chaves de idempotência**: para operações como “criar pagamento”, clientes enviam um `Idempotency-Key` para que reenvios não dupliquem trabalho.\n- **IDs de correlação**: um header como `X-Correlation-Id` permite traçar uma ação de usuário por serviços e logs, mesmo em um sistema distribuído.\n\nPara paginação, evite “servidor lembra a página 3.” Prefira parâmetros explícitos como `?cursor=abc` ou um link `next` que o cliente possa seguir, mantendo o estado de navegação nas respostas em vez da memória do servidor.\n\n## Restrição 3: Respostas cacheáveis\n\nCache é sobre reutilizar uma resposta anterior com segurança para que o cliente (ou algo entre os pontos) não precise pedir ao seu servidor para fazer o mesmo trabalho novamente. Feito corretamente, reduz latência para usuários e carga para você — sem mudar o significado da API.\n\n### O que “cacheável” significa na prática\n\nUma resposta é cacheável quando é seguro que outra requisição receba o mesmo payload por algum período. Em HTTP, você comunica essa intenção com cabeçalhos de cache:\n\n- `Cache-Control`: o painel principal (quanto tempo manter, se pode ser guardado por caches compartilhados, etc.)\n- `ETag` e `Last-Modified`: validadores que permitem ao cliente perguntar “isso mudou?” e obter um barato `304 Not Modified`\n- `Expires`: maneira mais antiga de expressar frescor, ainda vista por aí\n\nIsso é maior do que “cache do navegador”. Proxies, CDNs, gateways de API e até apps móveis podem reutilizar respostas quando as regras estão claras.\n\n### O que normalmente é seguro cachear (e o que não é)\n\nBons candidatos:\n\n- Dados públicos idênticos para todos (catálogos de produtos, documentação, flags de recurso que não são específicas por usuário)\n- Recursos somente leitura que mudam raramente (configuração estática, dados de referência)\n- Respostas GET que não dependem de cookies ou autenticação\n\nGeralmente ruins para cache:\n\n- Dados pessoais ligados a uma conta (perfis, pedidos, mensagens)\n- Respostas relacionadas a autenticação (trocas de token, estado de sessão)\n- Qualquer coisa que varie por usuário, a menos que você trate explicitamente (ex.: regras `private`)\n\n### Resultados práticos que você notará\n\n- Páginas mais rápidas e apps mais responsivos (menos espera na rede)\n- Custos menores de servidor e banco (menos computação repetida)\n- Menos incidentes de “limite de taxa” (leituras em cache reduzem volume de requisições)\n\nA ideia chave: cache não é detalhe. É uma restrição REST que recompensa APIs que comunicam frescor e validação claramente.\n\n## Restrição 4: Interface uniforme (o que isso realmente significa)\n\nA **interface uniforme** é frequentemente entendida apenas como “use GET para ler e POST para criar”. Isso é só uma parte. A ideia de Fielding é maior: APIs devem ser consistentes o suficiente para que clientes não precisem de conhecimento especial endpoint-a-endpoint para usá-las.\n\n### As quatro partes da interface uniforme\n\n1) **Identificação de recursos**: você nomeia *coisas* (recursos) com identificadores estáveis (tipicamente URLs), não ações. Pense `/orders/123`, não `/createOrder`.\n\n2) **Manipulação via representações**: clientes mudam um recurso enviando uma representação (JSON, HTML, etc.). O servidor controla o recurso; o cliente troca representações dele.\n\n3) **Mensagens autodescritivas**: cada requisição/resposta deve carregar informação suficiente para ser entendida — método, código de status, cabeçalhos, tipo de mídia e um corpo claro. Se o significado está escondido em docs fora de banda, clientes ficam fortemente acoplados.\n\n4) **Hipermídia (HATEOAS)**: respostas devem incluir links e ações permitidas para que clientes possam seguir o fluxo sem codificar cada padrão de URL.\n\n### Por que reduz acoplamento\n\nUma interface consistente torna clientes menos dependentes de detalhes internos do servidor. Com o tempo, isso significa menos breaking changes, menos “casos especiais” e menos retrabalho quando times evoluem endpoints.\n\n### Heurísticas práticas que você pode aplicar\n\n- **Use códigos de status consistentemente**: ex.: `200` para leituras bem-sucedidas, `201` para recursos criados (com `Location`), `400` para validação, `401/403` para auth, `404` quando um recurso não existe.\n- **Padronize seu formato de erro** pela API. Campos exemplo: `code`, `message`, `details`, `requestId`.\n- **Mantenha tipos de mídia e cabeçalhos significativos** (`Content-Type`, cabeçalhos de cache), para que mensagens se expliquem.\n\nInterface uniforme é sobre **previsibilidade e evolutividade**, não apenas “verbos corretos”.\n\n## Mensagens autodescritivas: projetando para compreensão\n\nUma mensagem “autodescritiva” diz ao receptor como interpretá-la — sem exigir conhecimento tribal fora de banda. Se um cliente (ou intermediário) não consegue entender o que uma resposta *significa* apenas olhando os cabeçalhos HTTP e o corpo, você criou um protocolo privado sobre HTTP.\n\n### Use tipos de mídia para explicar o payload\n\nA vitória mais simples é ser explícito com `Content-Type` (o que você está enviando) e frequentemente `Accept` (o que você deseja de volta). Uma resposta com `Content-Type: application/json` diz ao cliente as regras básicas de parsing, mas você pode ir além com tipos de mídia vendor ou baseados em profile quando o significado importa.\n\nAbordagens exemplares:\n\n- **Tipo genérico + campos estáveis**: `application/json` com um esquema cuidadosamente mantido. Mais fácil para a maioria dos times.\n- **Tipos de mídia vendor**: `application/vnd.acme.invoice+json` para sinalizar uma representação específica.\n- **Perfis**: mantenha `application/json`, adicione um parâmetro `profile` ou link para um perfil que define semântica.\n\n### Versionamento e compatibilidade (sem quebrar clientes)\n\nVersionamento deve proteger clientes existentes. Opções populares incluem:\n\n- **Versionamento na URL** (`/v1/orders`): óbvio, mas pode incentivar “fork” de representações em vez de evoluí-las.\n- **Versionamento por header ou tipo de mídia** (via `Accept`): mantém URLs estáveis e torna “o que isso significa” parte da mensagem.\n- **Evolução aditiva**: prefira adicionar novos campos e manter os antigos funcionando; depreque gradualmente.\n\nEscolha o que escolher, vise compatibilidade retroativa por padrão: não renomeie campos casualmente, não mude significados silenciosamente e trate remoções como breaking changes.\n\n### Erros consistentes e nomes claros\n\nClientes aprendem mais rápido quando erros são iguais em todo lugar. Escolha uma forma única de erro (ex.: `code`, `message`, `details`, `traceId`) e use-a em todos os endpoints. Use nomes de campo claros e previsíveis (`createdAt` vs. `created_at`) e mantenha uma convenção única.\n\n### Documentação ajuda — mas clareza deve viver na mensagem\n\nBoa documentação acelera adoção, mas não pode ser o único lugar onde o significado existe. Se um cliente precisa ler uma wiki para saber se `status: 2` significa “pago” ou “pendente”, a mensagem não é autodescritiva. Cabeçalhos bem projetados, tipos de mídia e payloads legíveis reduzem essa dependência e tornam sistemas mais fáceis de evoluir.\n\n## Hipermídia (HATEOAS): a ideia REST mais pulada\n\nHipermídia (resumida em HATEOAS: *Hypermedia As The Engine Of Application State*) significa que um cliente não precisa “conhecer” as próximas URLs da API antecipadamente. Em vez disso, cada resposta inclui **próximos passos descobráveis** como links: para onde ir em seguida, quais ações são possíveis e às vezes qual método HTTP usar.\n\n### Como isso parece na prática\n\nEm vez de codificar caminhos como `/orders/{id}/cancel`, o cliente segue links fornecidos pelo servidor. O servidor está basicamente dizendo: “Dado o estado atual deste recurso, aqui estão os movimentos válidos.”\n\n
paid
cancel
refund
fluxos evoluem
URLs codificadas
baixo acoplamento
Use IDs de tracing end-to-end
Deixe a propagação de erro explícita
Defina timeouts por hop
Documente comportamento de cache
opcional
código executável
JavaScript
Segurança
Políticas de conteúdo
Auditoria e compliance
você pode seguir REST totalmente sem código sob demanda
rejeita
Endpoints RPC:
/doThing
/runReport
/users/activate
URLs cheias de verbo:
/createOrder
/updateProfile
/deleteItem
Sessões escondidas:
Clientes frágeis:
Versionamento difícil:
comportamentos
Misses de cache (e latência maior):
Problemas de escala:
Nomeie recursos, não ações:
/orders/{id}
/createOrder
Use métodos HTTP intencionalmente:
Torne requisições independentes:
Aproveite cache onde for seguro:
Cache-Control
ETag
Vary
Padronize erros e tipos de mídia:
Koder.ai
Authorization: Bearer … em cada chamada
chaves de idempotência para reenvios seguros
paginação explícita (?cursor=... ou link next) em vez de “servidor lembra a página 3”
ETag / Last-Modified para validação (304 Not Modified)
Vary quando a resposta varia por cabeçalhos como Accept
Regra geral: cacheie agressivamente dados públicos e compartilhados; trate dados específicos do usuário com cuidado (private ou não cacheável).
identificadores de recurso estáveis
uso correto dos métodos HTTP
códigos de status consistentes (200, 201 + Location, 400, 401/403, 404)
corpo de erro padronizado (ex.: code, message, details, requestId)
Isso reduz acoplamento e torna mudanças menos propensas a quebrar clientes.