O que este post cobre (e por que importa)
O Snowflake popularizou uma ideia simples, mas de grande alcance em data warehousing na nuvem: manter armazenamento de dados e computação de consultas separados. Essa separação muda dois pontos problemáticos do dia a dia das equipes de dados—como os warehouses escalam e como você paga por eles.
Em vez de tratar o warehouse como uma única “caixa” fixa (onde mais usuários, mais dados ou consultas mais complexas disputam os mesmos recursos), o modelo do Snowflake permite armazenar os dados uma vez e ativar a quantidade certa de computação quando necessário. O resultado costuma ser tempo de resposta mais rápido, menos gargalos em picos de uso e controle mais claro sobre o que gera custo (e quando).
Tema #1: desempenho e escala sem os trade-offs usuais
Este post explica, em linguagem simples, o que realmente significa separar armazenamento e computação—e como isso afeta:
- Concorrência (muitas pessoas executando consultas ao mesmo tempo)
- Escala elástica (aumentar ou reduzir a computação)
- Comportamento de custos (pagar pela computação apenas enquanto ela roda, mais o armazenamento contínuo)
Também apontamos onde o modelo não resolve tudo magicamente—porque algumas surpresas de custo e desempenho vêm do desenho das cargas, não da plataforma em si.
Tema #2: por que o ecossistema pode importar tanto quanto a velocidade bruta
Uma plataforma rápida não é a história completa. Para muitas equipes, o time-to-value depende de quão fácil é conectar o warehouse às ferramentas que já usam—pipelines ETL/ELT, dashboards de BI, ferramentas de catálogo/governança, controles de segurança e fontes de dados de parceiros.
O ecossistema do Snowflake (incluindo padrões de compartilhamento de dados e distribuição estilo marketplace) pode encurtar prazos de implementação e reduzir engenharia customizada. Este post aborda como “profundidade do ecossistema” se manifesta na prática e como avaliá-la para sua organização.
Para quem é isto
Este guia é escrito para líderes de dados, analistas e tomadores de decisão não especialistas—qualquer pessoa que precise entender os trade-offs por trás da arquitetura do Snowflake, escala, custo e escolhas de integração sem se afogar em jargão do fornecedor.
Antes da separação: por que warehouses tradicionais alcançam limites
Warehouses tradicionais foram construídos em torno de uma suposição simples: você compra (ou aluga) uma quantidade fixa de hardware e roda tudo naquela mesma caixa ou cluster. Isso funcionava bem quando as cargas eram previsíveis e o crescimento era gradual—mas criou limites estruturais quando volumes de dados e número de usuários aceleraram.
O modelo clássico: clusters fixos e planejamento de capacidade cuidadoso
Sistemas on-prem e implantações iniciais na nuvem (lift-and-shift) tipicamente se pareciam com isto:
- Um único cluster MPP (processamento massivamente paralelo) lidava com armazenamento, CPU e memória juntos.
- Você dimensionava o cluster para a demanda de pico, porque redimensionar era lento, arriscado ou exigia downtime.
- Planejamento de capacidade virou um projeto recorrente: prever crescimento, justificar orçamento, comprar hardware, instalar e migrar.
Mesmo quando fornecedores ofereciam “nós”, o padrão central permanecia: escalar normalmente significava adicionar nós maiores ou mais nós a um ambiente compartilhado.
Os pontos dolorosos: escala lenta, gasto desperdiçado e enfileiramento
Esse desenho cria algumas dores comuns:
- Escala lenta: Se um pico de fechamento mensal precisa de mais potência, nem sempre se consegue adicionar rápido. Ou você espera, ou superprovisiona “por precaução”.
- Capacidade ociosa: Clusters dimensionados para picos ficam subutilizados a maior parte do tempo—mas você ainda paga por eles (custo de hardware, licenças, tempo de ops).
- Enfileiramento sob carga: Quando várias equipes executam consultas simultaneamente, competem pelos mesmos recursos. Jobs pesados podem bloquear dashboards interativos, causando timeouts, stakeholders frustrados e regras como “não rode essa consulta durante o horário comercial”.
Ferramentas e integrações: poderosas, mas frequentemente frágeis
Como esses warehouses eram acoplados ao ambiente, integrações cresceram organicamente: scripts ETL customizados, conectores feitos à mão e pipelines pontuais. Funcionavam—até que um schema mudou, um sistema upstream foi movido ou uma nova ferramenta foi introduzida. Manter tudo funcionando podia parecer manutenção constante em vez de progresso contínuo.
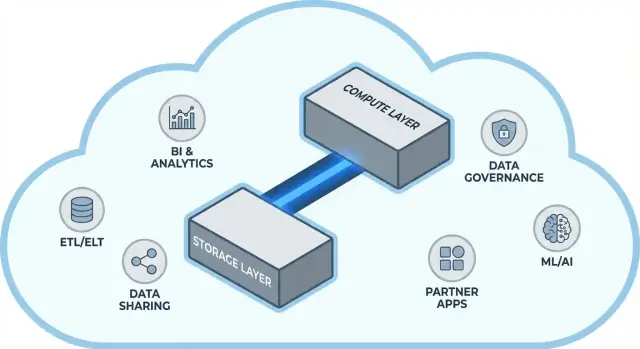
A ideia central: separar armazenamento e computação
Warehouses tradicionais frequentemente amarram duas tarefas bem diferentes: armazenamento (onde seus dados ficam) e computação (a potência que lê, junta, agrega e grava esses dados).
Armazenamento vs. computação (em termos simples)
Armazenamento é como uma despensa de longo prazo: tabelas, arquivos e metadados são mantidos de forma segura e barata, desenhados para durabilidade e disponibilidade contínua.
Computação é como a equipe de cozinha: são CPUs e memória que de fato “cozinham” suas consultas—executando SQL, ordenando, escaneando, montando resultados e atendendo múltiplos usuários ao mesmo tempo.
A mudança-chave: escalá-los independentemente
O Snowflake separa esses dois para que você possa ajustar cada um sem forçar o outro a mudar.
- Se o volume de dados cresce, você adiciona mais armazenamento (geralmente incremental e previsível).
- Se o tráfego de relatórios dispara, você adiciona mais computação (redimensionando ou adicionando warehouses virtuais) sem mover ou duplicar os dados.
Na prática, isso muda operações do dia a dia: você não precisa “comprar computação a mais” só porque o armazenamento está crescendo, e pode isolar cargas (por exemplo, analistas vs. jobs de ETL) para que não se afetem mutuamente.
O que isso não é
Essa separação é poderosa, mas não é mágica.
- Não é “escala grátis.” Mais ou maiores warehouses geralmente significam maior gasto com computação.
- Não é economia automática sempre. Consultas mal escritas, agendas de refresh desnecessárias ou warehouses sempre ativos ainda podem gerar custos.
- Não é uma desculpa para ignorar planejamento. Você ainda precisa escolher tamanhos de warehouse, definir regras de suspensão automática e alinhar computação ao uso do negócio.
O valor é o controle: pagar por armazenamento e computação em termos diferentes e casar cada um ao que suas equipes realmente precisam.
Arquitetura do Snowflake em termos simples
O Snowflake é mais fácil de entender como três camadas que trabalham juntas, mas escalam de forma independente.
1) Armazenamento: armazenamento de objetos na nuvem
Suas tabelas vivem como arquivos de dados no armazenamento de objetos do provedor de nuvem (pense S3, Azure Blob ou GCS). O Snowflake gerencia formatos de arquivo, compressão e organização para você. Você não “anexa discos” nem dimensiona volumes—o armazenamento cresce conforme os dados crescem.
2) Computação: warehouses virtuais
A computação é empacotada como warehouses virtuais: clusters independentes de CPU/memória que executam consultas. Você pode rodar múltiplos warehouses contra os mesmos dados ao mesmo tempo. Essa é a diferença chave em relação a sistemas antigos, onde cargas pesadas disputavam o mesmo pool de recursos.
Uma camada de serviços separada lida com o “cérebro” do sistema: autenticação, parsing e otimização de consultas, gerenciamento de transações/metadados e coordenação. Essa camada decide como executar uma consulta de forma eficiente antes da computação tocar os dados.
Como uma consulta flui
Quando você submete SQL, a camada de serviços do Snowflake o analisa, constrói um plano de execução e então entrega esse plano a um warehouse escolhido. O warehouse lê apenas os arquivos de dados necessários do armazenamento de objetos (e se beneficia de cache quando possível), processa-os e retorna resultados—sem mover permanentemente seus dados base para dentro do warehouse.
Concorrência e isolamento (sem jargões)
Se muitas pessoas executam consultas ao mesmo tempo, você pode:
- usar warehouses separados para equipes/cargas diferentes (isolamento de workload), ou
- habilitar warehouses multicluster para que o Snowflake adicione mais clusters de computação quando a demanda aumentar, reduzindo depois.
Essa é a base arquitetural por trás do desempenho do Snowflake e do controle sobre “vizinho barulhento”.
Escala e concorrência: o que realmente muda
A grande mudança prática do Snowflake é que você escala computação independentemente dos dados. Em vez de “o warehouse ficou maior”, você ganha a capacidade de ajustar recursos por workload—sem copiar tabelas, reparticionar discos ou agendar downtime.
Elasticidade: redimensionar computação sem mover dados
No Snowflake, um virtual warehouse é o motor de computação que roda consultas. Você pode redimensioná-lo (por exemplo, de Small para Large) em segundos, e os dados permanecem no armazenamento compartilhado. Isso significa que o ajuste fino de performance frequentemente se torna uma questão simples: “Essa carga precisa de mais potência agora?”
Isso também permite picos temporários: aumente a escala para um fechamento de fim de mês e depois reduza quando o pico terminar.
Concorrência: menos brigas por fila
Sistemas tradicionais costumam forçar equipes diferentes a compartilhar a mesma computação, transformando horas ocupadas em uma fila no caixa.
O Snowflake permite rodar warehouses separados por time ou por workload—por exemplo, um para analistas, outro para dashboards e outro para ETL. Como esses warehouses leem o mesmo dado subjacente, você reduz o problema de “meu dashboard deixou seu relatório lento” e torna a performance mais previsível.
Trade-offs que você vai notar
A computação elástica não é sucesso automático. Problemas comuns incluem:
- Cold starts: warehouses suspensos podem demorar um pouco para retomar, o que adiciona latência a jobs infrequentes.
- Escolhas de dimensionamento: oversizing desperdiça dinheiro; undersizing causa consultas lentas e frustração.
- São necessários guardrails: use suspensão/retomada automática, monitores de recursos e responsabilidade clara para que warehouses não fiquem ociosos ou proliferem sem controle.
A mudança líquida: escalabilidade e concorrência deixam de ser projetos de infraestrutura e viram decisões de operação do dia a dia.
Modelo de custos: onde ocorrem economias (e onde não)
Prototipe um app de dados rápido
Crie um app de métricas com backend Snowflake a partir do chat e compartilhe com as partes interessadas rapidamente.
Como a cobrança do Snowflake funciona na prática
O “pague pelo que usar” do Snowflake é basicamente dois medidores rodando em paralelo:
- Computação: cobrada pelo tempo que seu warehouse virtual fica em execução (em créditos).
- Armazenamento: cobrado pela quantidade de dados armazenados (mais qualquer armazenamento extra para recursos como Time Travel/Fail-safe).
Essa separação é onde economias podem acontecer: você pode manter muitos dados relativamente baratos e ligar computação apenas quando precisa.
Onde os custos aumentam
A maior parte do gasto “inesperado” vem de comportamentos de computação, não do armazenamento. Drivers comuns incluem:
- Warehouses sobredimensionados (escolher um tamanho maior do que a carga precisa)
- Workloads sempre ligados (warehouses deixados rodando à noite ou fim de semana)
- Consultas ineficientes (varreduras sem filtro, joins desnecessários, transformações pesadas rodando repetidamente)
- Padrões de alta concorrência (muitos dashboards pequenos atualizando constantemente)
Separar armazenamento e computação não torna consultas eficientes automaticamente—SQL ruim ainda pode queimar créditos rápido.
Controles práticos que funcionam no mundo real
Você não precisa do departamento financeiro para gerenciar isso—apenas alguns guardrails:
- Suspensão/retomada automática para parar de pagar por tempo ocioso
- Monitores de recurso para alertar ou limitar uso de créditos por warehouse/time
- Agendamento (rodar jobs batch em janelas definidas; pausar dev/test fora do horário)
- Right-sizing e testes com tamanhos menores antes de escalar para cima
Usado corretamente, o modelo recompensa disciplina: computação de curta duração e bem dimensionada, pareada com crescimento previsível de armazenamento.
Compartilhamento de dados e colaboração como recurso de primeira classe
O Snowflake trata o compartilhamento como algo projetado na plataforma—não como um paliativo preso a exports, drops de arquivos e ETL pontual.
Compartilhar sem copiar (em muitos casos)
Em vez de enviar extratos, o Snowflake pode permitir que outra conta consulte os mesmos dados subjacentes por meio de um “share” seguro. Em muitos cenários, os dados não precisam ser duplicados em um segundo warehouse ou empurrados para o armazenamento de objetos para download. O consumidor vê o banco/tabela compartilhada como se fosse local, enquanto o provedor mantém controle sobre o que é exposto.
Essa abordagem desacoplada é valiosa porque reduz a proliferação de dados, acelera o acesso e diminui o número de pipelines que você precisa construir e manter.
Padrões comuns de colaboração
Compartilhamento com parceiros e clientes: Um fornecedor pode publicar datasets curados para clientes (por exemplo, analytics de uso ou dados de referência) com limites claros—apenas schemas, tabelas ou views permitidas.
Compartilhamento interno por domínio: Times centrais podem expor datasets certificados para produto, finanças e operações sem que cada time construa suas próprias cópias. Isso apoia uma cultura de “um conjunto de números” enquanto permite que times rodem sua própria computação.
Colaboração governada: Projetos conjuntos (por exemplo, com agência, fornecedor ou subsidiária) podem trabalhar sobre um dataset compartilhado enquanto colunas sensíveis são mascaradas e o acesso é auditado.
Limitações a planejar
Compartilhamento não é “configurar e esquecer”. Você ainda precisa de:
- Governança: propriedade clara, revisões de acesso e políticas para PII/dados regulados.
- Contratos e expectativas: quem paga pela computação, SLAs, retenção e o que acontece quando definições mudam.
- Descobribilidade: sem catálogo e boa nomenclatura, as pessoas não vão encontrar (ou confiar) nos dados certos. Alinhe shares com documentação e seu catálogo de dados, se houver.
Um warehouse rápido é valioso, mas a velocidade sozinha raramente determina se um projeto é entregue no prazo. O que costuma fazer a diferença é o ecossistema ao redor da plataforma: conexões prontas, ferramentas e know-how que reduzem trabalho customizado.
Na prática, um ecossistema inclui:
- Conectores para fontes e destinos (apps SaaS, bancos de dados, ferramentas de streaming)
- Ferramentas parceiras para ingestão, transformação, BI, qualidade de dados e observabilidade
- Apps e integrações nativas que rodam próximas aos dados
- Templates e arquiteturas de referência (modelos comuns, padrões, guias de implantação)
- Conhecimento da comunidade: exemplos, fóruns, meetups e disponibilidade de contratação
Por que o ecossistema pode vencer benchmarks para velocidade de entrega
Benchmarks medem uma fatia estreita de performance em condições controladas. Projetos reais passam a maior parte do tempo em:
- Fazer os dados entrarem de forma confiável e incremental
- Modelar, testar e documentar datasets
- Tarefas operacionais (monitoramento, alertas, controle de custos)
- Revisões de segurança, controles de acesso e auditorias
Se sua plataforma tiver integrações maduras para essas etapas, você evita construir e manter código “cola”. Isso normalmente encurta timelines de implementação, melhora confiabilidade e facilita trocar times ou fornecedores sem reescrever tudo.
Uma lente simples de avaliação: cobertura, qualidade, manutenibilidade
Ao avaliar um ecossistema, procure por:
- Cobertura: suporta suas fontes-chave, ferramentas de BI, orquestração e necessidades de governança?
- Qualidade: conectores são mantidos ativamente, bem documentados e comprovados na sua escala?
- Manutenibilidade: quanto esforço contínuo é necessário—upgrades, mudanças que quebram, debugging e suporte?
A performance te dá capacidade; o ecossistema costuma determinar quão rápido você transforma essa capacidade em resultados de negócio.
Ecossistema de integração: como trazer, tirar e usar dados
Vá da demo para a implantação
Implemente seu protótipo e itere com snapshots e rollback conforme os requisitos mudam.
O Snowflake pode rodar consultas rápidas, mas o valor aparece quando os dados se movem de forma confiável pela sua stack: das fontes para o Snowflake e de volta para as ferramentas que as pessoas usam todo dia. A “última milha” costuma determinar se uma plataforma parece sem esforço—ou constantemente frágil.
Categorias principais de integração para planejar
A maioria dos times precisa de uma mistura de:
- ELT/ETL para ingestão de bancos de dados, apps SaaS, arquivos e armazenamento de objetos
- BI e analytics para dashboards, exploração self-serve e camadas semânticas
- Reverse ETL para enviar dados curados de volta ao CRM, marketing e sistemas de suporte
- Orquestração para agendamento, dependências, backfills e promoção de ambientes
- Streaming para eventos near-real-time e change data capture
- Ferramentas de ML para pipelines de features, workflows de treino e monitoramento de modelos
Perguntas para fazer antes de escolher conectores
Nem todas as ferramentas “compatíveis com Snowflake” se comportam do mesmo modo. Durante a avaliação, foque em detalhes práticos:
- O conector é certificado/suportado (e por quem)? Qual o caminho de escalonamento?
- Ele suporta cargas incrementais limpas (CDC, timestamps, high-water marks)?
- Como lida com schema drift—novas colunas, mudanças de tipo, campos excluídos?
- Quais são as garantias sobre retries, deduplicação e exactly-once vs at-least-once?
Não ignore a operação
Integrações também precisam de prontidão para o dia 2: monitoramento e alertas, ganchos para linhagem/catalog, e fluxos de resposta a incidentes (ticketing, on-call, runbooks). Um ecossistema forte não é só mais logos—são menos surpresas quando pipelines quebram às 2h da manhã.
Governança, segurança e confiança em escala
À medida que times crescem, a parte mais difícil de analytics muitas vezes não é velocidade—é garantir que as pessoas certas acessem os dados certos, pelo motivo certo, com prova de que os controles funcionam. As funcionalidades de governança do Snowflake são desenhadas para essa realidade: muitos usuários, muitos produtos de dados e compartilhamentos frequentes.
Fundamentos de governança que realmente funcionam
Comece com papéis claros e uma mentalidade de menor privilégio. Em vez de conceder acesso diretamente a indivíduos, defina papéis como ANALYST_FINANCE ou ETL_MARKETING, depois conceda esses papéis a bancos de dados, schemas, tabelas e (quando necessário) views específicas.
Para campos sensíveis (PII, identificadores financeiros), use políticas de mascaramento para que as pessoas possam consultar datasets sem ver valores brutos, a menos que seu papel permita. Combine isso com auditoria: registre quem consultou o quê e quando, para que equipes de segurança e compliance possam responder sem adivinhações.
Por que governança muda compartilhamento e self-service
Boa governança torna o compartilhamento mais seguro e escalável. Quando seu modelo de compartilhamento se baseia em papéis, políticas e acessos auditados, você pode habilitar self-service com confiança (mais usuários explorando dados) sem abrir espaço para exposições acidentais.
Também reduz fricção em esforços de compliance: políticas viram controles repetíveis em vez de exceções pontuais. Isso importa quando datasets são reutilizados entre projetos, departamentos ou parceiros externos.
Dicas práticas que evitam dor futura
- Convenções de nomenclatura: padronize nomes de databases/schemas que indiquem propósito e sensibilidade (ex.:
PROD_FINANCE, DEV_MARKETING, SHARED_PARTNER_X). Consistência acelera revisões e reduz erros.
- Separação de ambientes: mantenha DEV/TEST/PROD separadas logicamente, com controles mais rígidos em PROD. Trate dados de produção como exceção, não padrão.
- Revisões de acesso: defina cadência (mensal para dados de alto risco, trimestral caso contrário). Revise membros de papéis, usuários inativos e privilégios.
Confiança em escala é menos sobre um “controle perfeito” e mais sobre um sistema de hábitos pequenos e confiáveis que mantêm o acesso intencional e explicável.
Cargas de trabalho e padrões de boas práticas
Torne a governança utilizável
Configure um app simples de fluxo de solicitações de dados com governança que suas equipes realmente usem.
O Snowflake costuma brilhar quando muitas pessoas e ferramentas precisam consultar os mesmos dados por motivos diferentes. Como a computação é empacotada em warehouses independentes, você pode mapear cada workload a um formato e cronograma que fazem sentido.
Mapeamento comum de workloads
Analytics & dashboards: Coloque ferramentas de BI em um warehouse dedicado dimensionado para volume de consultas constante e previsível. Isso evita que refreshes de dashboard sejam retardados por exploração ad hoc.
Análise ad hoc: Dê aos analistas um warehouse separado (frequentemente menor) com suspensão automática ativada. Você obtém iteração rápida sem pagar por tempo ocioso.
Ciência de dados & experimentação: Use um warehouse dimensionado para varreduras maiores e picos ocasionais. Se experimentos gerarem picos, escale esse warehouse temporariamente sem afetar usuários de BI.
Apps de dados & analytics embutidos: Trate tráfego de app como um serviço de produção—warehouse separado, timeouts conservadores e monitores de recurso para evitar gastos-surpresa.
Se estiver construindo apps internos de dados leves (por exemplo, um portal de ops que consulta Snowflake e exibe KPIs), um caminho rápido é gerar um scaffolding React + API funcional e iterar com stakeholders. Plataformas como Koder.ai (uma plataforma vibe-coding que constrói apps web/servidor/móvel a partir de chat) podem ajudar times a prototipar esses apps com backing do Snowflake rapidamente e depois exportar o código-fonte quando estiverem prontos para operacionalizar.
Padrões de boas práticas que funcionam
Uma regra simples: separe warehouses por público e propósito (BI, ELT, ad hoc, ML, app). Combine isso com bons hábitos de consulta—evite SELECT * amplo, filtre cedo e observe joins ineficientes. No lado de modelagem, priorize estruturas que casem com a forma como as pessoas consultam (frequentemente uma camada semântica limpa ou marts bem definidos), em vez de super-otimizar layouts físicos.
Quando considerar alternativas ou complementos
O Snowflake não substitui tudo. Para workloads transacionais de alta taxa e baixa latência (OLTP típico), um banco especializado costuma ser melhor, usando o Snowflake para analytics, relatórios, compartilhamento e produtos de dados downstream. Configurações híbridas são comuns e frequentemente mais práticas.
Considerações de migração: o que planejar antes de mover
Migrar para Snowflake raramente é um “lift and shift”. A separação armazenamento/computação muda como você dimensiona, ajusta e paga pelas cargas—logo, planejar antecipadamente evita surpresas posteriores.
Uma sequência prática de migração
Comece com um inventário: quais fontes alimentam o warehouse, quais pipelines transformam, quais dashboards dependem disso e quem é dono de cada parte. Depois priorize por impacto e complexidade (ex.: relatórios críticos de finanças primeiro, sandboxes experimentais depois).
Em seguida, converta SQL e lógica ETL. Muito SQL padrão transfere, mas detalhes como funções, tratamento de datas, código procedural e padrões de tabelas temporárias frequentemente precisam ser reescritos. Valide resultados cedo: rode saídas paralelas, compare contagens de linhas e agregados, e confirme casos de borda (nulos, fusos horários, lógica de deduplicação). Por fim, planeje o cutover: janela de congelamento, caminho de rollback e uma definição clara de “pronto” para cada dataset e relatório.
Riscos típicos para observar
Dependências ocultas são as mais comuns: uma extração para planilha, uma string de conexão codificada, um job downstream que ninguém lembra. Surpresas de performance podem ocorrer quando suposições antigas de tuning não se aplicam (ex.: uso excessivo de warehouses minúsculos, ou execução de muitas consultas pequenas sem considerar concorrência). Picos de custo normalmente vêm de deixar warehouses rodando, retentativas descontroladas ou duplicação de workloads de dev/test. Gaps de permissão aparecem ao migrar de papéis grosseiros para governança mais granular—testes devem incluir execuções por usuários com “least privilege”.
Gestão de mudança (não pule)
Defina um modelo de propriedade (quem é dono dos dados, pipelines e custos), ofereça treinamento baseado em papéis para analistas e engenheiros e defina um plano de suporte para as primeiras semanas após o cutover (on-call, runbook de incidentes e um local para reportar problemas).
Escolher uma plataforma moderna de dados não é só sobre velocidade máxima em benchmarks. É sobre se a plataforma se encaixa nas suas cargas reais, na forma de trabalho do time e nas ferramentas que vocês já usam.
Checklist prático de avaliação
Use essas perguntas para guiar sua short-list e conversas com fornecedores:
- Workloads: Você roda principalmente dashboards agendados, análise ad-hoc, ciência de dados, ELT/ETL ou apps voltados ao cliente? Precisa de janelas batch previsíveis ou de capacidade elástica por picos?
- Necessidades de concorrência: Quantas pessoas (ou apps) vão consultar ao mesmo tempo e quão “picada” é a utilização durante o horário comercial?
- Requisitos de compartilhamento: Precisa compartilhar dados vivos com parceiros, unidades de negócio ou clientes sem enviar arquivos? Espera consumir datasets de terceiros?
- Ajuste de ferramentas: Seus BI, orquestração, catálogo e fluxos de CI/CD vão integrar bem? O que quebra se você mudar?
- Governança e segurança: Precisa de controle de acesso fino, trilhas de auditoria, mascaramento, políticas de retenção e separação clara de funções?
- Restrições de custo: Quais custos importam mais—gasto steady-state, pico horário ou habilidade de desligar computação? Como prevenir desperdício “sempre ligado”?
Plano piloto curto (2–4 semanas)
Escolha duas ou três bases representativas (não amostras pequenas): uma tabela fato grande, uma fonte semi-estruturada bagunçada e um domínio crítico.
Então rode consultas reais de usuários: dashboards no pico da manhã, exploração de analistas, cargas agendadas e alguns joins de pior caso. Acompanhe: tempo de consulta, comportamento de concorrência, tempo de ingestão, esforço operacional e custo por workload.
Se a avaliação incluir “quão rápido conseguimos entregar algo útil”, acrescente um pequeno deliverable ao piloto—como um app interno de métricas ou um fluxo governado de solicitação de dados que consulte o Snowflake. Construir essa camada fina normalmente revela realidades de integração e segurança mais rápido do que benchmarks isolados, e ferramentas como Koder.ai podem acelerar o ciclo de protótipo para produção gerando a estrutura do app via chat e permitindo exportar o código.
Próximos passos sugeridos
Se quiser ajuda para estimar gastos e comparar opções, comece em /pricing.
Para orientações de migração e governança, navegue por artigos relacionados em /blog.