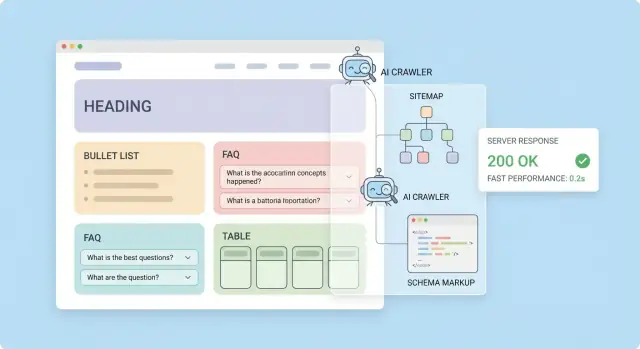
O que “otimizado para IA” realmente significa
“Otimizado para IA” costuma ser um termo de efeito, mas na prática significa que seu site é fácil para sistemas automatizados encontrarem, lerem e reutilizarem com precisão.
Quando as pessoas falam em rastreadores de IA, geralmente referem-se a bots operados por mecanismos de busca, produtos de IA ou provedores de dados que buscam páginas para alimentar funcionalidades como resumos, respostas, conjuntos de treinamento ou sistemas de recuperação. Indexação por LLMs normalmente significa transformar suas páginas em uma base de conhecimento pesquisável (frequentemente texto “fragmentado” com metadados) para que um assistente de IA recupere o trecho certo e o cite ou o reproduza.
Os objetivos reais
Otimização para IA é menos sobre “ranqueamento” e mais sobre quatro resultados:
- Descoberta: rastreadores alcançam suas URLs importantes de forma confiável.
- Parse: seu conteúdo é legível sem adivinhação (HTML limpo, estrutura previsível).
- Atribuição/citação: é óbvio quem escreveu, quando foi atualizado e quais fontes o sustentam.
- Qualidade de recuperação: trechos são autocontidos, específicos e fáceis de associar a uma pergunta.
Defina expectativas (e o que você pode controlar)
Ninguém pode garantir inclusão em um índice ou modelo específico. Provedores diferentes rastreiam de formas distintas, seguem políticas diferentes e atualizam em ritmos diferentes.
O que você pode controlar é tornar seu conteúdo simples de acessar, extrair e atribuir — assim, se for usado, será usado corretamente.
O que você implementará ao final
- Um site rastreável com regras de acesso claras (robots e diretivas meta)
- Práticas de URLs limpas e canônicas para reduzir duplicatas
- Sitemaps e links internos que colocam páginas-chave em destaque
- Conteúdo formatado em “fragmentos” que máquinas conseguem interpretar
- Dados estruturados para rotular sobre o que cada página trata
- Um simples arquivo
llms.txt para orientar descobertas focadas em LLMs
- Desempenho e respostas de servidor que evitem timeouts de rastreadores
- Sinais de confiança (autores, datas, fontes, propriedade) que suportem citação
- Uma rotina de testes para verificar o que os bots realmente veem
Se você está criando páginas e fluxos rapidamente, ajuda escolher ferramentas que não entrem em conflito com esses requisitos. Por exemplo, equipes que usam Koder.ai (plataforma de codificação por chat que gera frontends em React e backends Go/PostgreSQL) frequentemente incluem templates amigáveis a SSR/SSG, rotas estáveis e metadados consistentes desde cedo — assim “pronto para IA” vira padrão, não retrofit.
Estrutura de conteúdo que LLMs conseguem analisar facilmente
LLMs e rastreadores de IA não interpretam uma página como uma pessoa. Eles extraem texto, inferem relações entre ideias e tentam mapear sua página para uma única intenção clara. Quanto mais previsível sua estrutura, menos suposições erradas precisarão fazer.
Como é uma página “ideal”
Comece tornando a página fácil de escanear em texto puro:
- Um H1 claro que corresponda à promessa principal da página
- Seções curtas com títulos descritivos
- Ruído mínimo de barra lateral e menos chamadas “flutuantes” que interrompam a narrativa principal
Um padrão útil é: promessa → resumo → explicação → prova → próximos passos.
Adicione um TL;DR para compreensão rápida
Coloque um resumo curto próximo ao topo (2–5 linhas). Isso ajuda sistemas de IA a classificar a página rapidamente e capturar as afirmações-chave.
Exemplo de TL;DR:
TL;DR: Esta página explica como estruturar conteúdo para que rastreadores de IA possam extrair o tópico principal, definições e os principais pontos de forma confiável.
Mantenha um tópico principal por página
Indexação por LLM funciona melhor quando cada URL responde a uma intenção. Se você misturar objetivos não relacionados (por exemplo, “preços”, “docs de integração” e “história da empresa” na mesma página), a página ficará mais difícil de categorizar e pode aparecer para consultas erradas.
Se precisar cobrir intenções relacionadas mas distintas, divida em páginas separadas e conecte-as com links internos (por exemplo, /pricing, /docs/integrations).
Defina termos ambíguos e acrescente contexto
Se seu público pode interpretar um termo de maneiras diferentes, defina-o cedo.
Exemplo:
Otimização para rastreadores de IA: preparar conteúdo do site e regras de acesso para que sistemas automatizados possam descobrir, ler e interpretar páginas de forma confiável.
Use nomeação consistente para entidades
Escolha um nome por produto, recurso, plano e conceito-chave — e mantenha-o em todo lugar. A consistência melhora a extração (“Recurso X” sempre se refere à mesma coisa) e reduz confusão de entidades quando modelos resumem ou comparam suas páginas.
Títulos, listas e tabelas: deixe as páginas prontas para fragmentos
A maioria dos pipelines de indexação quebra páginas em fragmentos e armazena/recupera os trechos mais compatíveis depois. Seu trabalho é tornar esses fragmentos óbvios, autocontidos e fáceis de citar.
Use hierarquia clara H1–H3
Mantenha um H1 por página (a promessa), depois use H2s para seções principais e H3s para subtópicos.
Uma regra simples: se você puder transformar seus H2s em um índice que descreva a página inteira, você está no caminho certo. Essa estrutura ajuda sistemas de recuperação a anexar o contexto certo a cada fragmento.
Escreva títulos que se sustentem sozinhos
Evite rótulos vagos como “Visão geral” ou “Mais info”. Em vez disso, faça títulos que respondam à intenção do usuário:
- “Preços e o que está incluído”
- “Formatos de arquivo suportados e limites de tamanho”
- “Quanto tempo leva a configuração (prazos típicos)”
Quando um fragmento é extraído fora de contexto, o título frequentemente vira seu “título”. Faça-o significativo.
Prefira parágrafos curtos, listas e tabelas
Use parágrafos curtos (1–3 frases) para legibilidade e para manter fragmentos focados.
Listas com marcadores funcionam bem para requisitos, passos e destaques de recursos. Tabelas são ótimas para comparações porque preservam estrutura.
| Plano | Melhor para | Limite chave |
|---|
| Starter | Testar | 1 projeto |
| Team | Colaboração | 10 projetos |
Adicione FAQ para respostas diretas
Uma pequena seção de FAQ com respostas diretas e completas melhora a extração:
P: Vocês suportam uploads CSV?
R: Sim — CSV até 50 MB por arquivo.
Inclua “Próximos passos” e “Leituras relacionadas”
Feche páginas-chave com blocos de navegação para que usuários e rastreadores sigam caminhos baseados em intenção:
- Próximos passos: /pricing, /signup
- Leituras relacionadas: /blog/technical-seo-for-ai, /docs/sitemaps
Renderização: garanta que o conteúdo exista sem JavaScript
Rastreadores de IA nem sempre se comportam como um navegador completo. Muitos conseguem buscar e ler o HTML cru imediatamente, mas têm dificuldade (ou pulam) executar JavaScript, esperar por chamadas de API e montar a página após a hidratação. Se seu conteúdo chave aparece apenas depois da renderização no cliente, você corre o risco de ser “invisível” para sistemas que fazem indexação por LLM.
HTML vs páginas renderizadas por JavaScript
Com uma página HTML tradicional, o rastreador baixa o documento e pode extrair títulos, parágrafos, links e metadados de imediato.
Com uma página pesada em JS, a resposta inicial pode ser uma casca (alguns divs e scripts). O texto significativo aparece apenas depois que os scripts executam, os dados carregam e os componentes renderizam. Esse segundo passo é onde a cobertura cai: alguns rastreadores não executam scripts; outros executam com timeouts ou suporte parcial.
Prefira server-rendered (ou híbrido) para conteúdo crítico
Para páginas que você quer indexar — descrições de produto, preços, FAQs, docs — prefira:
- Server-Side Rendering (SSR): conteúdo já na resposta HTML inicial
- Geração estática (SSG/ISR): HTML pré-construído com atualizações periódicas
- Renderização híbrida: renderize no servidor o conteúdo principal e melhore com JS para interatividade
O objetivo não é “sem JavaScript”. É HTML significativo primeiro, JS em segundo lugar.
Não esconda texto importante atrás de UI “invisível”
Abas, accordions e controles “ler mais” são aceitáveis se o texto estiver no DOM. Problemas surgem quando o conteúdo da aba é carregado apenas após um clique, ou injetado depois de uma requisição no cliente. Se esse conteúdo importa para descoberta por IA, inclua-o no HTML inicial e use CSS/ARIA para controlar visibilidade.
Testes rápidos para identificar lacunas de renderização
Faça estas verificações:
- View Source: mostra o HTML entregue pelo servidor (o que muitos rastreadores veem)
- Inspect Element: mostra o DOM pós-JS (o que um navegador real termina com)
Se seus títulos, texto principal, links internos ou respostas de FAQ aparecem apenas no Inspect Element e não no View Source, trate como risco de renderização e mova esse conteúdo para a saída renderizada no servidor.
Rastreadores de IA e bots tradicionais precisam de regras de acesso claras e consistentes. Se você acidentalmente bloquear conteúdo importante — ou permitir rastreadores em áreas privadas ou “bagunçadas” — pode desperdiçar orçamento de rastreio e poluir o que é indexado.
robots.txt: o controlador de tráfego do site
Use robots.txt para regras amplas: quais pastas (ou padrões de URL) devem ser rastreadas ou evitadas.
Uma linha de base prática:
- Allow/Disallow: bloqueie áreas não públicas como
/admin/, /account/, resultados de busca internos ou URLs com muitos parâmetros que geram combinações quase infinitas.
- Crawl-delay: adicione apenas se seu servidor tiver dificuldade com tráfego de bots. Muitos bots grandes o ignoram, então não confie nele como principal mecanismo de controle.
- Sitemap directive: aponte rastreadores para a localização canônica do seu sitemap para que a descoberta seja previsível.
Exemplo:
User-agent: *
Disallow: /admin/
Disallow: /account/
Disallow: /internal-search/
Sitemap: /sitemap.xml
Importante: bloquear com robots.txt impede o rastreio, mas não garante que uma URL não apareça num índice se for referenciada em outro lugar. Para controlar indexação, use diretivas ao nível da página.
Use meta name=\"robots\" em páginas HTML e X-Robots-Tag em cabeçalhos para arquivos não-HTML (PDFs, feeds, exportações geradas).
Padrões comuns:
- Páginas finas ou utilitárias (filtros, variantes de ordenação, vistas para impressão):
noindex,follow para que os links ainda passem, mas a página em si fique fora dos índices.
- Áreas privadas ou sensíveis: não confie só em
noindex — proteja com autenticação e considere também bloquear o rastreio.
- Versões duplicadas (por exemplo, URLs de preview):
noindex junto com canonicalização correta (coberto depois).
Um conjunto simples de regras por ambiente (prod vs staging)
Documente — e aplique — regras por ambiente:
- Produção: rastreável por padrão; bloqueie apenas áreas claramente não públicas ou de baixo valor.
- Staging/preview: exija login; adicione também
noindex globalmente (baseado em cabeçalho é mais simples) para evitar indexação acidental.
Se seus controles de acesso afetam dados de usuários, certifique-se de que a política visível ao usuário corresponda à realidade (veja /privacy e /terms quando relevante).
URLs canônicas, duplicatas e higiene de redirecionamentos
Crie URLs estáveis por padrão
Gere apps em React, Go e PostgreSQL mantendo canonicals e redirecionamentos previsíveis.
Se você quer que sistemas de IA (e rastreadores) entendam e citem suas páginas de forma confiável, precisa reduzir situações de “mesmo conteúdo, muitas URLs”. Duplicatas desperdiçam orçamento de rastreio, dividem sinais e podem fazer com que a versão errada seja indexada ou referenciada.
Crie URLs limpas e estáveis
Aponte para URLs que permaneçam válidas por anos. Evite expor parâmetros desnecessários como IDs de sessão, opções de ordenação ou códigos de rastreamento em URLs indexáveis (por exemplo: ?utm_source=..., ?sort=price, ?ref=). Se parâmetros são necessários para funcionalidade (filtros, paginação, busca interna), garanta que a versão “principal” ainda seja acessível em uma URL limpa e estável.
URLs estáveis melhoram citações a longo prazo: quando um LLM aprende ou armazena uma referência, é muito mais provável que continue apontando para a mesma página se sua estrutura de URLs não mudar a cada redesign.
Adicione um rel=\"canonical\" em páginas onde duplicatas são esperadas:
- Variantes de produto que compartilham a maior parte do conteúdo
- Vistas de categoria filtradas
- Versões com parâmetros de rastreamento
Tags canônicas devem apontar para a URL preferida e indexável (idealmente essa URL canônica deve retornar 200).
Higiene de redirecionamentos: simples e previsível
Quando uma página se move permanentemente, use um redirecionamento 301. Evite cadeias de redirecionamento (A → B → C) e loops; eles desaceleram rastreadores e podem levar a indexação parcial. Redirecione URLs antigas diretamente para o destino final e mantenha redirecionamentos consistentes entre HTTP/HTTPS e www/non-www.
Use hreflang apenas para equivalentes verdadeiros
Implemente hreflang somente quando tiver equivalentes realmente localizados (não apenas snippets traduzidos). Hreflang incorreto pode criar confusão sobre qual página deve ser citada para qual audiência.
Sitemaps e links internos para descoberta confiável
Sitemaps e links internos são seu “sistema de entrega” para descoberta: dizem aos rastreadores o que existe, o que importa e o que deve ser ignorado. Para rastreadores de IA e indexação por LLMs, o objetivo é simples — torne suas melhores URLs limpas fáceis de encontrar e difíceis de perder.
Crie sitemaps XML que listem apenas as URLs certas
Seu sitemap deve incluir apenas URLs canônicas e indexáveis. Se uma página está bloqueada por robots.txt, marcada noindex, redirecionada ou não é a versão canônica, não pertence ao sitemap. Isso mantém o orçamento de rastreio focado e reduz a chance de um LLM capturar uma versão duplicada ou desatualizada.
Seja consistente com formatos de URL (barra final, minúsculas, HTTPS) para que o sitemap reflita suas regras canônicas.
Separe sitemaps grandes e use um índice de sitemaps
Se você tem muitas URLs, divida em vários arquivos de sitemap (limite comum: 50.000 URLs por arquivo) e publique um índice de sitemaps que liste cada sitemap. Organize por tipo de conteúdo quando ajudar, por exemplo:
/sitemaps/pages.xml/sitemaps/blog.xml/sitemaps/docs.xml
Isso facilita a manutenção e ajuda a monitorar o que está sendo descoberto.
Use lastmod como um sinal de confiança, não como timestamp de deploy
Atualize lastmod com critério — apenas quando a página mudar significativamente (conteúdo, preço, política, metadados chave). Se toda URL atualizar a cada deploy, rastreadores passam a ignorar o campo, e atualizações importantes podem ser revisitadas mais tarde do que o desejado.
Links internos: torne seu site navegável como um mapa
Uma estrutura forte em hub-and-spoke ajuda usuários e máquinas. Crie hubs (páginas de categoria, produto ou tópico) que apontem para as páginas “spoke” mais importantes e assegure que cada spoke linke de volta para seu hub. Adicione links contextuais no corpo do texto, não apenas em menus.
Se você publica conteúdo educacional, mantenha pontos de entrada principais óbvios — envie usuários para /blog para artigos e /docs para referência aprofundada.
Dados estruturados: ajude máquinas a entender suas páginas
Planeje suas alterações de SEO para IA
Mapeie suas tarefas de SSR, robots e schema antes de gerar código e templates.
Dados estruturados etiquetam o que uma página é (um artigo, produto, FAQ, organização) num formato que máquinas leem de forma confiável. Mecanismos de busca e sistemas de IA não precisam adivinhar qual texto é o título, quem escreveu ou qual é a entidade principal — eles podem analisar diretamente.
Escolha o tipo Schema.org correto
Use tipos Schema.org que correspondam ao seu conteúdo:
- Article (posts de blog, notícias, guias)
- FAQPage (seções de perguntas e respostas)
- HowTo (instruções passo a passo)
- Product (páginas de preço, detalhe de produto)
- Organization (identidade da sua empresa)
Escolha um tipo primário por página e depois adicione propriedades de suporte (por exemplo, um Article pode referenciar uma Organization como publisher).
Rastreadores e buscadores comparam dados estruturados com a página visível. Se seu markup declara um FAQ que não está na página, ou lista um autor que não aparece, você cria confusão e corre o risco de ter o markup ignorado.
Para páginas de conteúdo, inclua author além de datePublished e dateModified quando forem reais e significativas. Isso torna frescor e responsabilidade mais claros — duas coisas que LLMs frequentemente consideram ao decidir o que confiar.
Se você tem perfis oficiais, adicione links sameAs (por exemplo, perfis sociais verificados da empresa) no seu schema Organization.
Exemplo: Article JSON-LD
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "Build a Website Ready for AI Crawlers and LLM Indexing",
"author": { "@type": "Person", "name": "Jane Doe" },
"datePublished": "2025-01-10",
"dateModified": "2025-02-02",
"publisher": {
"@type": "Organization",
"name": "Acme",
"sameAs": ["https://www.linkedin.com/company/acme"]
}
}
Por fim, valide com ferramentas comuns (Rich Results Test do Google, Schema Markup Validator). Corrija erros e trate avisos de forma pragmática: priorize os ligados ao seu tipo escolhido e às propriedades-chave (título, autor, datas, informações do produto).
llms.txt: um guia simples para descoberta orientada a LLMs
Um llms.txt é um pequeno arquivo legível por humanos que funciona como um “cartão de índice” do seu site, apontando rastreadores focados em modelos de linguagem (e as pessoas que os configuram) para os pontos de entrada mais importantes: docs, páginas-chave de produto e qualquer material de referência que explique sua terminologia.
Não é um padrão com comportamento garantido entre todos os rastreadores, e não substitui sitemaps, canônicos ou controles de robots. Pense nele como um atalho útil para descoberta e contexto.
Onde colocá-lo
Coloque na raiz do site para que seja fácil de localizar:
A ideia é a mesma do robots.txt: localização previsível, fetch rápido.
O que incluir (e o que evitar)
Mantenha curto e curado. Bons candidatos:
- Entradas primárias: visão geral do produto, preços, começar
- Hubs de documentação: home dos docs, referência de API, guias SDK, tutoriais
- Glossário/terminologia: página que define termos do domínio e nomenclatura preferida
- Políticas relevantes para reuso: licenciamento, expectativas de atribuição, notas sobre uso de dados
Considere também adicionar notas de estilo breves que reduzam ambiguidade (por exemplo, “Chamamos clientes de ‘workspaces’ na UI”). Evite cópia longa de marketing, despejo completo de URLs ou qualquer coisa que conflite com suas URLs canônicas.
Aqui vai um exemplo simples:
# llms.txt
# Purpose: curated entry points for understanding and navigating this site.
## Key pages
- / (Homepage)
- /pricing
- /docs
- /docs/getting-started
- /docs/api
- /blog
## Terminology and style
- Prefer “workspace” over “account”.
- Product name is “Acme Cloud” (capitalized).
- API objects: “Project”, “User”, “Token”.
## Policies
- /terms
- /privacy
Consistência é mais importante que volume:
- Liste apenas URLs que deseja que sejam descobertas e citadas.
- Garanta que as páginas listadas retornem 200 e tenham o canônico correto.
- Se uma página for substituída, atualize o link em vez de confiar em redirecionamentos.
- Não inclua URLs bloqueadas por
robots.txt (cria sinais mistos).
Processo leve de manutenção (trimestral)
Uma rotina prática e manejável:
- Revisão trimestral (15 minutos): clique em cada link do
llms.txt e confirme se continua sendo o melhor ponto de entrada.
- Após grandes releases: adicione/remove hubs de docs quando reestruturar a navegação.
- Integre em checagens existentes: atualize
llms.txt sempre que atualizar seu sitemap ou mudar canônicos.
Feito direito, llms.txt permanece pequeno, preciso e realmente útil — sem prometer como qualquer rastreador específico irá se comportar.
Desempenho e respostas de servidor que rastreadores apreciam
Rastreadores (incluindo focados em IA) se comportam muito como usuários impacientes: se seu site for lento ou instável, eles buscarão menos páginas, farão menos tentativas e atualizarão seus índices com menos frequência. Bom desempenho e respostas de servidor confiáveis aumentam as chances de seu conteúdo ser descoberto, re-rastread o e mantido atualizado.
Velocidade e disponibilidade: o que rastreadores “sentem”
Se seu servidor frequentemente dá timeout ou retorna erros, um rastreador pode reduzir a atividade automaticamente. Isso significa que páginas novas demoram mais para aparecer e atualizações podem não ser refletidas rapidamente.
Busque disponibilidade estável e tempos de resposta previsíveis durante horários de pico — não apenas ótimas notas de laboratório.
Melhore TTFB e reduza payload
Time to First Byte (TTFB) é um forte sinal de saúde do servidor. Algumas ações de grande impacto:
- Use CDN para cache de páginas públicas e habilite cache de origem quando possível.
- Ative compressão (Brotli ou gzip) para HTML, CSS e JavaScript.
- Mantenha HTML enxuto: evite scripts inline enormes ou tags de rastreamento excessivas.
- Redimensione e comprima imagens para que páginas não peçam downloads pesados só para entender o conteúdo.
Mesmo que rastreadores não “vejam” imagens como pessoas, arquivos grandes desperdiçam tempo de rastreio e banda.
Retorne os códigos HTTP corretos
Rastreadores usam códigos para decidir o que manter e o que descartar:
- 200 para páginas válidas com conteúdo.
- 301 para movimentos permanentes (e mantenha cadeias de redirecionamento curtas).
- 404 quando uma página não existe.
- 410 quando uma página foi removida intencionalmente e deve ser eliminada mais rápido.
- Trate 5xx com cuidado: corrija causas raízes rapidamente e considere uma página fallback leve apenas se ela ainda retornar o código de erro correto.
Não esconda conteúdo central atrás de logins
Se o texto principal do artigo exige autenticação, muitos rastreadores indexarão apenas a casca. Mantenha acesso de leitura central público ou forneça um preview rastreável que inclua o conteúdo-chave.
Rate limiting sem bloquear rastreadores legítimos
Proteja seu site contra abuso, mas evite bloqueios bruscos. Prefira:
- Limites token-bucket com picos razoáveis
- Listas de permissão para faixas de IPs de rastreadores conhecidos (quando disponíveis)
- Respostas claras 429 com cabeçalhos
Retry-After
Isso mantém o site seguro enquanto permite rastreadores responsáveis fazerem seu trabalho.
Sinais de confiança: fontes, autores e propriedade clara
Torne páginas fáceis de rastrear, rápido
Crie páginas prontas para IA com HTML renderizado no servidor, rotas limpas e metadados consistentes desde o primeiro dia.
“E‑E‑A‑T” não exige grandes alegações ou selos sofisticados. Para rastreadores de IA e LLMs, significa basicamente que seu site é claro sobre quem escreveu algo, de onde vieram os fatos e quem é responsável por mantê‑lo.
Torne a origem óbvia (e verificável)
Ao afirmar um fato, anexe a fonte o mais próximo possível da afirmação. Priorize referências primárias e oficiais (leis, órgãos normativos, docs de fornecedores, artigos revisados) em vez de resumos de segunda mão.
Por exemplo, ao mencionar comportamento de dados estruturados, cite a documentação do Google (“Google Search Central — Structured Data”) e, quando relevante, as definições do schema (“Schema.org vocabulary”). Se discutir diretivas de robots, referencie padrões e docs oficiais do rastreador (por exemplo, “RFC 9309: Robots Exclusion Protocol”). Mesmo que você não linke externamente a cada menção, inclua detalhes suficientes para que alguém localize o documento exato.
Mostre autoria e propriedade editorial
Adicione byline do autor com uma biografia curta, credenciais e responsabilidades. Depois, deixe a propriedade explícita:
- Um proprietário claro do site (empresa/entidade legal) no rodapé
- Página de contato com canais reais (não só um formulário)
- Uma página Sobre explicando missão e processo editorial (veja /about)
Mantenha afirmações específicas — e guarde comprovantes
Evite linguagem como “melhor” e “garantido”. Descreva o que você testou, o que mudou e quais são os limites. Adicione notas de atualização no topo ou rodapé de páginas-chave (por exemplo, “Atualizado em 2025-12-10: clarificada a manipulação de canônicos para redirecionamentos”). Isso cria uma trilha de manutenção que humanos e máquinas podem interpretar.
Mantenha um glossário consistente
Defina termos centrais uma vez e use-os consistentemente no site (por exemplo, “AI crawler”, “LLM indexing”, “rendered HTML”). Uma página de glossário leve (por exemplo, /glossary) reduz ambiguidade e facilita sumarizações precisas.
Testes, monitoramento e melhorias contínuas
Um site pronto para IA não é um projeto único. Pequenas mudanças — como um update de CMS, um novo redirecionamento ou uma navegação redesenhada — podem quebrar silenciosamente descoberta e indexação. Uma rotina simples de testes evita que você especule quando tráfego ou visibilidade mudarem.
Observe sinais que indicam problemas de descoberta
Comece pelo básico: monitore erros de rastreio, cobertura de índice e suas páginas mais linkadas. Se rastreadores não conseguem buscar URLs chave (timeouts, 404s, recursos bloqueados), a indexação por LLM tende a degradar rápido.
Monitore também:
- Páginas que saem repentinamente da cobertura do índice
- URLs importantes que param de receber links internos
- Picos inesperados em páginas “duplicadas” ou “excluídas”
Verifique releases como um engenheiro de confiabilidade
Após lançamentos (mesmo “pequenos”), reveja o que mudou:
- Redirecionamentos: URLs antigas estão corretamente levando usuários e bots ao novo destino?
- Canônicos: templates mudaram e passaram a apontar canônicos para o lugar errado?
- Sitemaps: continuam válidos, atualizados e sem URLs quebradas?
Uma auditoria pós‑release de 15 minutos frequentemente captura problemas antes que virem perdas de visibilidade de longo prazo.
Teste como suas páginas são resumidas
Escolha um punhado de páginas de alto valor e teste como são resumidas por ferramentas de IA ou scripts internos de sumarização. Procure por:
- Definições ausentes (a frase “o que é isto?” não fica clara)
- Títulos que não correspondem às seções reais da página
- Detalhes chave enterrados em parágrafos longos sem rótulos
Se os resumos forem vagos, a correção costuma ser editorial: títulos H2/H3 mais fortes, primeiros parágrafos mais claros e terminologia mais explícita.
Crie um checklist recorrente de “prontidão para IA”
Transforme o que aprender em um checklist periódico e atribua um responsável (um nome real, não “marketing”). Mantenha-o vivo e acionável — então vincule a versão mais recente internamente para que toda a equipe use o mesmo playbook. Publique uma referência leve como /blog/ai-seo-checklist e atualize conforme seu site e ferramentas evoluam.
Se sua equipe entrega rápido (especialmente com desenvolvimento assistido por IA), considere adicionar checagens de “prontidão para IA” no fluxo de build/release: templates que sempre outputam tags canônicas, campos consistentes de autor/data e conteúdo principal renderizado no servidor. Plataformas como Koder.ai podem ajudar ao tornar esses padrões repetíveis em novas páginas React e superfícies de app — e ao permitir iteração via planning mode, snapshot e rollback quando uma mudança impacta acidentalmente a rastreabilidade.
Pequenas melhorias contínuas se acumulam: menos falhas de rastreio, indexação mais limpa e conteúdo mais fácil de entender por pessoas e máquinas.