Bancos de Dados SQL vs NoSQL: Diferenças Principais e Casos de Uso
Entenda as diferenças reais entre bancos de dados SQL e NoSQL: modelos de dados, escalabilidade, consistência e quando usar cada tipo em suas aplicações.
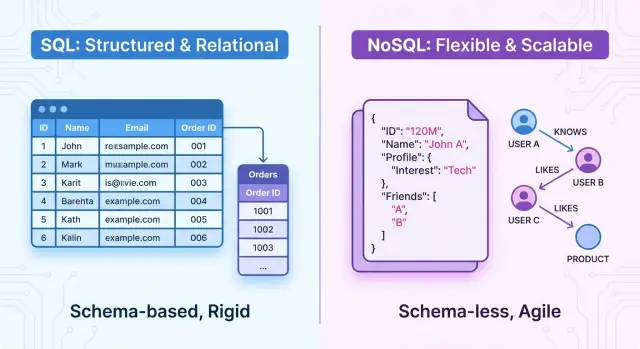
Visão geral: SQL e NoSQL em poucas palavras
Escolher entre bancos de dados SQL e NoSQL molda como você projeta, constrói e escala sua aplicação. O modelo de dados influencia tudo, desde estruturas e padrões de consulta até desempenho, confiabilidade e a velocidade com que sua equipe pode evoluir o produto.
Em alto nível, bancos SQL são sistemas relacionais. Os dados são organizados em tabelas com esquemas fixos, linhas e colunas. Relações entre entidades são explícitas (por chaves estrangeiras) e você consulta os dados usando SQL, uma linguagem declarativa poderosa. Esses sistemas enfatizam transações ACID, consistência forte e estrutura bem definida.
Bancos NoSQL são sistemas não relacionais. Em vez de um único modelo tabular rígido, oferecem vários modelos de dados projetados para necessidades diferentes, como:
- Key‑value stores
- Bancos de documentos
- Wide‑column stores
- Bancos de grafos
Ou seja, “NoSQL” não é uma única tecnologia, mas um termo guarda‑chuva para várias abordagens, cada uma com seus próprios trade‑offs em flexibilidade, desempenho e modelagem. Muitos sistemas NoSQL relaxam garantias rígidas de consistência em favor de alta escalabilidade, disponibilidade ou baixa latência.
Este artigo foca nas diferenças entre SQL e NoSQL — modelos de dados, linguagens de consulta, desempenho, escalabilidade e consistência (ACID vs consistência eventual). O objetivo é ajudar você a escolher entre SQL e NoSQL para projetos específicos e entender quando cada tipo de banco é mais adequado.
Você não precisa escolher apenas um. Muitas arquiteturas modernas usam persistência poliglota, onde bancos SQL e NoSQL coexistem em um sistema, cada um lidando com as cargas para as quais é mais indicado.
O que é um banco de dados SQL (relacional)?
Um banco de dados SQL (relacional) armazena dados em forma tabular estruturada e usa Structured Query Language (SQL) para definir, consultar e manipular esses dados. É construído em torno do conceito matemático de relações, que você pode pensar como tabelas bem organizadas.
Estrutura central: tabelas, linhas, colunas e esquemas
Os dados são organizados em tabelas. Cada tabela representa um tipo de entidade, como customers, orders ou products.
- Uma linha (registro) é uma única instância dessa entidade, como um cliente.\
- Uma coluna (campo) é um atributo específico, como
emailouorder_date.
Cada tabela segue um esquema fixo: uma estrutura pré‑definida que especifica
- quais colunas existem
- seus tipos de dados (ex.:
INTEGER,VARCHAR,DATE) - restrições (ex.:
NOT NULL,UNIQUE)
O esquema é aplicado pelo banco, o que ajuda a manter dados consistentes e previsíveis.
Chaves e relacionamentos
Bancos relacionais se destacam em modelar como entidades se relacionam.
- Uma primary key identifica exclusivamente cada linha em uma tabela (por exemplo,
customer_id).\ - Uma foreign key é uma coluna que referencia a primary key de outra tabela, vinculando linhas relacionadas.
Essas chaves permitem definir relacionamentos como:
- Um‑para‑muitos (um cliente, muitos pedidos)\
- Muitos‑para‑muitos (produtos em muitos pedidos, pedidos com muitos produtos)
Transações e propriedades ACID
Bancos relacionais suportam transações — grupos de operações que se comportam como uma unidade. Transações seguem as propriedades ACID:
- Atomicidade: todas as operações executam ou nenhuma executa.\
- Consistência: transações movem o banco de um estado válido para outro.\
- Isolamento: transações concorrentes não interferem entre si.\
- Durabilidade: uma vez comitada, a alteração é armazenada de forma segura.
Essas garantias são cruciais para sistemas financeiros, gestão de inventário e qualquer aplicação onde a correção é essencial.
Bancos SQL comuns
Sistemas relacionais populares incluem:
- MySQL e MariaDB\
- PostgreSQL\
- Microsoft SQL Server\
- Oracle Database
Todos implementam SQL e frequentemente adicionam extensões e ferramentas próprias para administração, tuning e segurança.
O que é um banco de dados NoSQL (não relacional)?
Bancos NoSQL são armazenamentos não relacionais que não usam o modelo tradicional de tabela–linha–coluna dos sistemas SQL. Em vez disso, focam em modelos de dados flexíveis, escalabilidade horizontal e alta disponibilidade, muitas vezes à custa de garantias transacionais estritas.
Modelos de dados flexíveis
Muitos bancos NoSQL são descritos como sem esquema ou com esquema flexível. Em vez de definir um esquema rígido desde o início, você pode armazenar registros com campos ou estruturas diferentes na mesma coleção ou bucket.
Isso é especialmente útil para:
- Requisitos de aplicação em evolução\
- Dados semiestruturados (logs, eventos, perfis de usuário)\
- Armazenar dados aninhados como documentos JSON
Como campos podem ser adicionados ou omitidos por registro, desenvolvedores iteram rapidamente sem migrar o esquema a cada alteração.
Principais tipos de NoSQL
NoSQL é um termo guarda‑chuva cobrindo vários modelos distintos:
- Bancos de documentos: armazenam dados como documentos tipo JSON com campos aninhados. Ex.: MongoDB, Couchbase.\
- Chave–valor: arrays associativos simples onde cada chave mapeia para um valor. Ótimo para cache e sessões. Ex.: Redis, Amazon DynamoDB (modo chave–valor).\
- Column‑family (wide‑column): organizam dados por famílias de colunas para alto throughput de escrita e tabelas largas. Ex.: Apache Cassandra, HBase.\
- Grafos: focados em nós e relacionamentos, ideais para dados altamente conectados. Ex.: Neo4j, Amazon Neptune.
Modelos de consistência
Muitos sistemas NoSQL priorizam disponibilidade e tolerância a partições, oferecendo consistência eventual em vez de transações ACID estritas em todo o conjunto de dados. Alguns oferecem níveis de consistência ajustáveis ou recursos transacionais limitados (por documento, partição ou intervalo de chaves), permitindo escolher entre garantias mais fortes e maior desempenho para operações específicas.
Modelos de dados: estrutura, esquemas e relacionamentos
A modelagem de dados é onde SQL e NoSQL mais divergem. Ela determina como você projeta recursos, consulta dados e faz evolucionar sua aplicação.
Estrutura e esquemas
Bancos SQL usam esquemas estruturados e predefinidos. Você projeta tabelas e colunas desde o início, com tipos e restrições rígidas:
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(100) NOT NULL
);
CREATE TABLE orders (
id INT PRIMARY KEY,
user_id INT NOT NULL,
total DECIMAL(10, 2) NOT NULL,
FOREIGN KEY (user_id) REFERENCES users(id)
);
Cada linha deve obedecer ao esquema. Alterá‑lo depois geralmente requer migrações (ALTER TABLE, backfilling, etc.).
Bancos NoSQL tipicamente suportam esquemas flexíveis. Um store de documentos pode permitir que cada documento tenha campos diferentes:
{
"_id": 1,
"name": "Alice",
"orders": [
{ "id": 101, "total": 49.99 },
{ "id": 102, "total": 15.50 }
]
}
Campos podem ser adicionados por documento sem uma migração central. Alguns NoSQL têm esquemas opcionais ou aplicados, mas em geral são mais soltos.
Normalização vs desnormalização
Modelos relacionais incentivam normalização: dividir dados em tabelas relacionadas para evitar duplicação e manter integridade. Isso favorece gravações consistentes e menores em armazenamento, mas leituras complexas podem exigir joins entre muitas tabelas.
Modelos NoSQL frequentemente preferem desnormalização: embutir dados relacionados para as leituras mais importantes. Isso melhora desempenho de leitura e simplifica consultas, mas gravações podem ficar mais lentas ou complexas porque a mesma informação pode residir em vários locais.
Modelando relacionamentos
No SQL, relacionamentos são explícitos e aplicados:
- Um‑para‑muitos: chaves estrangeiras (users → orders)\
- Muitos‑para‑muitos: tabelas de associação (users_roles)
No NoSQL, relacionamentos são modelados por:
- Embeddings (documento do usuário contém array de orders) para dados fortemente acoplados\
- Referências (user_id dentro do documento de pedido) para coleções grandes ou fracamente acopladas
A escolha depende dos padrões de acesso:
- Se você sempre busca um usuário e seus 10 pedidos mais recentes juntos, embutir pode ser ideal.\
- Se pedidos são enormes, atualizados frequentemente ou acessados independentemente, referências com consultas separadas são melhores.
Impacto em requisitos em evolução
Com SQL, mudanças de esquema exigem mais planejamento, mas fornecem garantias fortes e consistência em todo o dataset. Refatorações são explícitas: migrações, backfills, atualização de constraints.
Com NoSQL, requisitos em mudança são geralmente mais fáceis de suportar no curto prazo. Você pode começar a armazenar campos novos imediatamente e atualizar documentos antigos gradualmente. A troca é que o código da aplicação deve lidar com várias formas de documento e casos de borda.
Escolher entre modelos normalizados (SQL) e desnormalizados (NoSQL) não é "melhor ou pior", mas alinhar a estrutura de dados com seus padrões de consulta, volume de gravação e frequência de mudanças do modelo de domínio.
Linguagens de consulta e padrões de acesso
SQL: declarativo e padronizado
Bancos SQL são consultados com uma linguagem declarativa: você descreve o que quer, não como buscá‑lo. Constructs como SELECT, WHERE, JOIN, GROUP BY e ORDER BY permitem expressar questões complexas sobre várias tabelas em uma única instrução.
Como SQL é padronizado (ANSI/ISO), a maioria dos sistemas relacionais compartilha uma sintaxe central comum. Fornecedores adicionam extensões, mas habilidades e consultas transferem‑se razoavelmente entre PostgreSQL, MySQL, SQL Server, etc.
Essa padronização traz um ecossistema rico: ORMs, query builders, ferramentas de reporting, BI, frameworks de migração e otimizadores de consulta. Muitos desses integrados funcionam com pouco esforço em vários bancos SQL, reduzindo vendor lock‑in e acelerando desenvolvimento.
NoSQL: APIs de consulta e padrões
Sistemas NoSQL expõem consultas de formas variadas:
- Stores de documentos (MongoDB, Couchbase) usam objetos de consulta tipo JSON e às vezes sua própria linguagem de consulta.
- Chave‑valor (Redis, APIs estilo DynamoDB) focam em lookups por chave primária e um conjunto limitado de consultas por índice secundário.
- Wide‑column (Cassandra, HBase) otimizam para consultas que seguem chaves primárias e padrões de clustering.
- Motores de busca (Elasticsearch, Solr) usam DSLs voltadas a full‑text e relevância.
Alguns NoSQL oferecem pipelines de agregação ou mecanismos tipo MapReduce para analytics, mas joins cross‑collection ou cross‑partition são limitados ou ausentes. Em vez disso, dados relacionados são frequentemente embutidos ou desnormalizados.
Padrões de acesso e produtividade
Consultas relacionais frequentemente dependem de joins: normalizar dados e reconstruir entidades em tempo de leitura. Isso é poderoso para reporting ad‑hoc e perguntas em evolução, mas joins complexos podem ser difíceis de otimizar.
Padrões NoSQL tendem a ser centrados em documento ou chave: projete dados em torno das consultas mais frequentes da aplicação. Leituras ficam rápidas e simples — muitas vezes um único lookup por chave — mas mudar padrões de acesso depois pode exigir remodelagem.
Para produtividade e aprendizado:
- O modelo declarativo do SQL e a abundância de recursos tornam‑no acessível e duradouro como habilidade.\
- Consultas NoSQL podem ser mais fáceis para padrões simples e previsíveis, mas cada sistema tem sua sintaxe e limites, portanto habilidades são menos portáveis.
Equipes que precisam de consultas ad‑hoc ricas sobre relacionamentos geralmente preferem SQL. Equipes com padrões de acesso estáveis em altíssima escala costumam achar os modelos de consulta NoSQL mais alinhados às suas necessidades.
Consistência, transações e trocas do teorema CAP
ACID: garantias rígidas em sistemas SQL
A maioria dos bancos SQL foi projetada em torno de transações ACID:
- Atomicidade: uma transação termina totalmente ou falha totalmente.\
- Consistência: cada transação comitada mantém as regras e constraints.\
- Isolamento: transações concorrentes não apresentam efeitos visíveis indesejados (com níveis de isolamento como READ COMMITTED, REPEATABLE READ, SERIALIZABLE).\
- Durabilidade: após o commit, dados sobrevivem a falhas (via write‑ahead logs, replicação, etc.).
Isso torna bancos SQL ideais quando correção é mais importante que vazão bruta de gravações.
BASE e consistência eventual em muitos NoSQL
Muitos bancos NoSQL tendem a BASE:
- Basicamente Disponível: o sistema tenta permanecer disponível e responder.\
- Estado suave: dados podem estar temporariamente inconsistentes entre réplicas.\
- Consistência eventual: se não houver novas atualizações, todas as réplicas convergirão.
Gravações podem ser muito rápidas e distribuídas, mas uma leitura pode ver dados defasados por um curto período.
Teorema CAP na prática
CAP diz que um sistema distribuído sob partições de rede deve escolher entre:
- Consistência (C): todos os clientes veem os mesmos dados ao mesmo tempo.\
- Disponibilidade (A): toda requisição recebe uma resposta.
Você não pode garantir ambos C e A durante uma partição.
Padrões típicos:
- Muitas implantações SQL favorecem consistência forte: melhor para pagamentos, inventário, saldos, reservas, onde uma leitura desatualizada pode causar perdas.\
- Muitos setups NoSQL favorecem disponibilidade e consistência eventual: adequado para analytics, feeds sociais, catálogos de produtos, logs, caching, onde pequenas inconsistências temporárias são aceitáveis e velocidade/uptime são mais valiosas.
Sistemas modernos frequentemente misturam modos (por exemplo, consistência ajustável por operação) para que diferentes partes da aplicação escolham as garantias necessárias.
Escalabilidade e diferenças de desempenho
Como bancos SQL normalmente escalam
Bancos SQL tradicionais são projetados para um único nó poderoso.
Normalmente você começa escalando verticalmente: mais CPU, RAM e discos rápidos em um servidor. Muitos mecanismos também suportam réplicas de leitura: nós adicionais que atendem apenas leituras enquanto todas as gravações vão ao primário. Esse padrão funciona bem para:
- Volume moderado de gravações\
- Consultas analíticas ou de reporting intensas\
- Workloads onde consistência forte é crítica
No entanto, escala vertical esbarra em limites de hardware e custo, e réplicas de leitura podem introduzir lag de replicação.
NoSQL e escala horizontal
Sistemas NoSQL geralmente são concebidos para escala horizontal: espalhar dados por muitos nós usando sharding/particionamento. Cada shard contém um subconjunto dos dados, então leituras e gravações podem ser distribuídas, aumentando throughput.
Essa abordagem serve para:
- Workloads massivos com muitas gravações\
- Conjuntos de dados muito grandes que excedem o armazenamento de uma máquina\
- Aplicações globais que precisam de dados próximos aos usuários
A troca é maior complexidade operacional: escolher chaves de shard, lidar com rebalanceamento e consultas cross‑shard.
Padrões de desempenho e indexação
Para workloads leitura‑pesada com joins e agregações complexas, um banco SQL bem indexado pode ser extremamente rápido, pois o otimizador usa estatísticas e planos de consulta.
Muitos sistemas NoSQL favorecem padrões de acesso simples por chave. Eles são excelentes para lookups de baixa latência e alto throughput quando consultas são previsíveis e dados são modelados conforme os padrões de acesso, não para consultas ad‑hoc.
Latência em clusters NoSQL pode ser muito baixa, mas consultas cross‑partition, índices secundários e operações multi‑documento podem ser mais lentas ou limitadas. Operacionalmente, escalar NoSQL geralmente significa mais gestão de cluster, enquanto escalar SQL normalmente significa mais hardware e indexação cuidadosa em menos nós.
Quando um banco SQL costuma ser a escolha certa
Workloads transacionais e críticos para o negócio
Bancos relacionais brilham quando você precisa de OLTP (processamento de transações online) confiável:
- Sistemas financeiros (pagamentos, contabilidade, trading)\
- Gestão de pedidos e inventário\
- ERP, CRM e plataformas de faturamento
Esses sistemas dependem de transações ACID, consistência estrita e comportamento claro de rollback. Se uma transferência nunca pode cobrar em duplicidade ou perder dinheiro entre duas contas, um banco SQL costuma ser mais seguro que a maioria das opções NoSQL.
Dados estruturados e relacionamentos complexos
Quando o modelo de dados é bem entendido e estável, e entidades são fortemente interrelacionadas, um banco relacional é frequentemente a escolha natural. Exemplos:
- Clientes, pedidos, faturas, produtos e remessas\
- Registros de saúde com pacientes, consultas, prescrições e exames
Schemas normalizados, chaves estrangeiras e joins facilitam impor integridade e consultar relacionamentos complexos sem duplicação.
Análises em esquemas bem definidos
Para reporting e BI sobre dados claramente estruturados (star/snowflake schemas, data marts), bancos relacionais e warehouses compatíveis com SQL são normalmente preferidos. Times de analytics conhecem SQL e ferramentas existentes (dashboards, ETL, governança) se integram diretamente.
Maturidade, habilidades e conformidade
Debates relacionais vs não relacionais muitas vezes esquecem a maturidade operacional. Bancos SQL oferecem:
- Confiabilidade e ferramentas comprovadas\
- Um grande universo de engenheiros, DBAs e analistas fluentes em SQL\
- Recursos para auditoria, controle de acesso, criptografia e backups que atendem a regulamentações (financeiro, governo, saúde)
Quando auditorias, certificações ou exposição legal são preocupações, um banco SQL costuma ser a escolha mais direta e defensável no trade‑off SQL vs NoSQL.
Quando um banco NoSQL costuma ser a escolha certa
NoSQL tende a ser melhor quando escala, flexibilidade e acesso sempre‑ativo importam mais que joins complexos e garantias transacionais estritas.
Sistemas de alto tráfego e grande escala
Se você espera alto volume de gravações, picos imprevisíveis ou datasets que cresçam para terabytes, sistemas NoSQL (chave‑valor ou wide‑column) são mais fáceis de escalar horizontalmente. Sharding e replicação costumam ser embutidos, permitindo adicionar capacidade com nós em vez de replanejar um servidor poderoso.
Isso é comum em:
- Aplicações web e mobile de alto tráfego\
- Backends de jogos e leaderboards em tempo real\
- Ad tech, motores de recomendação e personalização
Flexibilidade durante iteração rápida do produto
Quando o modelo de dados muda frequentemente, um design flexível é valioso. Bancos de documentos permitem evoluir campos e estruturas sem migrações constantes.
Funciona bem para:
- Sistemas de gestão de conteúdo e catálogos de produtos\
- Perfis e preferências de usuário\
- Feeds de atividade e logs de eventos, onde novos tipos surgem regularmente
IoT, caching e séries temporais
Stores NoSQL são fortes para workloads append‑heavy e ordenados por tempo:
- Telemetria e sensores IoT\
- Métricas, logging e monitoramento\
- Camadas de cache para dados frequentemente lidos (sessões, tokens, feature flags)
Bancos chave‑valor e time‑series são otimizados para gravações muito rápidas e leituras simples.
Distribuição global e experiências sempre ativas
Plataformas NoSQL frequentemente priorizam geo‑replicação e gravações multi‑região, permitindo usuários em todo o mundo ler e gravar com baixa latência. Isso é útil quando:
- O app precisa ficar disponível durante falhas regionais\
- Usuários em continentes diferentes exigem tempos de resposta locais
A troca é aceitar consistência eventual em vez de ACID estrito entre regiões.
Trade‑offs e limitações
Escolher NoSQL costuma implicar abrir mão de recursos comuns em SQL:
- Consistência mais fraca ou configurável; nem toda leitura vê a última gravação\
- Consultas ad‑hoc e joins limitados; modelar queries antecipadamente é necessário\
- Mais responsabilidade na aplicação para garantir integridade de dados
Quando esses trade‑offs são aceitáveis, NoSQL oferece melhor escalabilidade, flexibilidade e alcance global.
Padrões híbridos e persistência poliglota
Persistência poliglota significa usar deliberadamente várias tecnologias de banco no mesmo sistema, escolhendo a melhor ferramenta para cada tarefa em vez de forçar tudo em uma única loja.
Arquitetura híbrida típica
Um padrão comum é:
- SQL para dados centrais: pedidos, pagamentos, perfis de usuário, configurações — onde você precisa de consistência, transações e consultas ricas.\
- NoSQL para sessões e cache: um key‑value (estilo Redis) para sessões, limites de taxa, feature flags ou agregados quentes; às vezes um document store para preferências ou feeds de atividade.
Isso mantém o “sistema de registro” em um relacional, enquanto offloada workloads voláteis ou leitura‑pesadas ao NoSQL.
Misturando tipos diferentes de NoSQL
Você também pode combinar sistemas NoSQL:
- Chave‑valor para caching e sessões.\
- Documento para conteúdo ou dados de usuário com esquemas flexíveis.\
- Wide‑column / séries temporais para métricas e logs de eventos.\
- Motor de busca (ex.: Lucene) para full‑text e queries analíticas.
O objetivo é alinhar cada datastore a um padrão de acesso específico: lookups simples, agregados, busca ou leituras baseadas em tempo.
Integração e custos operacionais
Arquiteturas híbridas dependem de pontos de integração:
- ETL ou streaming para sincronizar dados entre lojas ou construir modelos de leitura.\
- Event streaming para propagar mudanças (p.ex., do SQL para caches ou stores analíticos).\
- APIs que abstraem os bancos para que serviços não precisem saber onde os dados ficam.
A troca é overhead operacional: mais tecnologias para aprender, monitorar, proteger, fazer backup e depurar. Persistência poliglota funciona melhor quando cada datastore adicional resolve um problema real e mensurável — não apenas por ser moderno.
Como escolher entre SQL e NoSQL para um projeto
Escolher entre SQL e NoSQL é alinhar dados e padrões de acesso à ferramenta certa, não seguir modismos.
1. Comece pelos seus dados e relacionamentos
Pergunte:
- Meus dados são naturalmente tabulares com entidades claras (usuários, pedidos, faturas)?\
- Tenho muitos joins e relacionamentos ricos (1‑para‑muitos, muitos‑para‑muitos)?
Se sim, um banco relacional costuma ser a escolha padrão. Se seus dados são similares a documentos, aninhados ou variam muito entre registros, um banco de documentos ou outro modelo NoSQL pode ser mais adequado.
2. Esclareça necessidades de consistência e transação
- Preciso de transações ACID multi‑linha/multi‑tabela para corretude (p.ex., pagamentos, inventário)?\
- É aceitável que algumas leituras retornem dados ligeiramente defasados?
Consistência estrita e transações complexas favorecem SQL. Alta vazão de gravações com consistência relaxada pode favorecer NoSQL.
3. Entenda escala e desempenho
- Volume de leitura/gravação esperado agora? E em 2–3 anos?\
- Preciso de baixa latência em várias regiões?
Muitos projetos escalam bastante com SQL usando bom indexamento e hardware. Se você prevê escala muito grande com padrões simples (key‑value, séries temporais), NoSQL pode ser mais econômico.
4. Padrões de consulta e reporting
- Vou precisar de análises ad‑hoc, joins e relatórios flexíveis?\
- Quem consultará os dados (só engenheiros ou também analistas/usuários de negócio)?
SQL brilha para consultas complexas e ferramentas BI. Muitos bancos NoSQL são otimizados para caminhos de acesso pré‑definidos, tornando novas consultas mais difíceis.
5. Habilidades da equipe, tooling e hospedagem
- O que sua equipe já domina: SQL, modelagem de esquemas, ou sistemas NoSQL específicos?\
- Quais serviços estão disponíveis no seu ambiente (Postgres/MySQL gerenciados, MongoDB gerenciado, DynamoDB, etc.)?\
- Qual ecossistema tem melhores bibliotecas, drivers e monitoramento para sua stack?
Prefira tecnologias que sua equipe consiga operar com confiança, especialmente em produção.
6. Custo e complexidade operacional
- Podemos arcar com operar clusters distribuídos NoSQL, ou um banco SQL gerenciado atende nossas necessidades?\
- Como comparam custos de armazenamento e gravação/leitura para nossa carga esperada?
Um banco SQL gerenciado geralmente é mais simples e barato até que você realmente o ultrapasse.
7. Sempre teste com cargas realistas
Antes de decidir:
- Modele um subconjunto representativo dos dados em um esquema SQL e em um modelo NoSQL candidato.\
- Implemente algumas consultas e gravações críticas.\
- Faça testes de carga com volumes e padrões realistas.\
- Meça latência, throughput, taxas de erro e esforço operacional.
Use medições reais — não suposições — para escolher. Para muitos projetos, começar com SQL é o caminho mais seguro, com opção de introduzir componentes NoSQL depois para casos específicos de alta escala ou especializados.
Mitos comuns sobre bancos SQL e NoSQL
Mito 1: NoSQL vai substituir SQL
NoSQL não veio para matar bancos relacionais; veio para complementá‑los.
Bancos relacionais ainda dominam sistemas de registro: finanças, RH, ERP, inventário e qualquer fluxo onde consistência e transações são essenciais. NoSQL é forte onde esquemas flexíveis, alta vazão de gravações ou leituras globais são mais importantes.
A maioria das organizações usa ambos, escolhendo a ferramenta certa para cada carga.
Mito 2: Bancos SQL não escalam horizontalmente
Relacionais historicamente escalaram verticalmente, mas motores modernos suportam:
- Réplicas de leitura\
- Sharding/partitioning\
- SQL distribuído (sistemas NewSQL)
Escalar um sistema relacional pode ser mais trabalhoso do que adicionar nós a alguns clusters NoSQL, mas escala horizontal é possível com bom design e ferramentas.
Mito 3: NoSQL não tem esquemas ou regras
“Sem esquema” significa que o esquema é imposto pela aplicação, não pelo banco.
Stores de documento, chave‑valor e wide‑column ainda têm estrutura. A flexibilidade é poderosa, mas sem contratos de dados claros, governança e validação, os dados tornam‑se inconsistentes rapidamente.
Mito 4: Um tipo é sempre mais rápido
Desempenho depende muito mais de modelagem, indexação e padrões de acesso do que do rótulo “SQL vs NoSQL”.
Uma coleção NoSQL mal indexada será mais lenta que uma tabela relacional bem ajustada para muitas consultas. Similarmente, um esquema relacional que ignora padrões de consulta será pior que um modelo NoSQL alinhado às consultas.
Mito 5: SQL é sempre mais seguro e confiável que NoSQL
Muitos bancos NoSQL suportam durabilidade, criptografia, auditoria e controle de acesso. Por outro lado, um banco relacional mal configurado pode ser inseguro e frágil.
Segurança e confiabilidade dependem do produto específico, implantação, configuração e maturidade operacional — não apenas da categoria “SQL” ou “NoSQL”.
Estratégias de migração e coexistência
Times mudam entre SQL e NoSQL por duas razões principais: escala e flexibilidade. Um produto de alto tráfego pode manter um banco relacional como sistema de registro e introduzir NoSQL para leituras em escala ou novos recursos com esquemas flexíveis.
Padrões de migração
Uma migração completa de uma vez é arriscada. Opções mais seguras incluem:
- Migração incremental: isolar um contexto delimitado (p.ex., catálogo de produtos) e mover apenas esses dados e tráfego para NoSQL, mantendo o resto em SQL.\
- Gravações duplas: por um período, serviços escrevem em SQL e NoSQL. Quando a nova loja provada em produção, desative o caminho antigo.\
- Pipelines de sincronização: mantenha um banco primário e envie mudanças ao outro via CDC, filas de mensagens ou jobs ETL.
Armadilhas de esquema e modelagem
Ao migrar de SQL para NoSQL, evitar simplesmente espelhar tabelas como documentos ou key‑value. Isso pode causar:
- NoSQL excessivamente normalizado com muitos joins na aplicação\
- Documentos que crescem sem controle
Projete os novos padrões de acesso primeiro e modele NoSQL para as consultas reais.
Coexistência e redes de segurança
Um padrão comum é SQL para dados autoritativos (cobranças, contas) e NoSQL para visões otimizadas de leitura (feeds, busca, cache). Independentemente do mix, invista em:
- Backfills e rollbacks repetíveis\
- Validação de dados entre lojas\
- Testes de carga que reflitam padrões reais de consulta
Isso mantém migrações controladas em vez de movimentos dolorosos irreversíveis.
Resumo e recomendações práticas
SQL e NoSQL diferem principalmente em quatro áreas:
- Modelo de dados – SQL usa tabelas, linhas e esquemas bem definidos; NoSQL prefere documentos, pares chave‑valor, wide‑columns ou grafos, com estrutura mais flexível.\
- Consultas – SQL oferece uma linguagem expressiva única; NoSQL normalmente usa APIs específicas ou sintaxes próprias.\
- Consistência & transações – SQL centra‑se em ACID e consistência forte; muitos NoSQL sacrificam algumas garantias por disponibilidade, escala ou latência.\
- Escala – SQL tradicionalmente escala verticalmente (e cada vez mais horizontalmente via clustering); NoSQL costuma ser projetado para shard/replicar em muitos nós.
Nenhuma categoria é universalmente melhor. A escolha certa depende de seus requisitos reais, não de slogans.
Como decidir na prática
-
Anote suas necessidades:\
- Estrutura de dados e relacionamentos\
- Padrões de consulta e reporting\
- Expectativas de consistência vs disponibilidade\
- Pico de tráfego, volume de dados e metas de latência\
- Habilidades operacionais e tooling da equipe
-
Padrão sensato:\
- Prefira SQL para sistemas transacionais, analytics e dados empresariais bem estruturados.\
- Considere NoSQL para workloads de alta gravação, muito grande escala ou dados semiestruturados/variáveis.
-
Comece pequeno e meça:\
- Construa um slice vertical fino ou um POC.\
- Colete métricas: latência de consulta, throughput, taxas de erro e esforço operacional.\
- Itere no esquema, índices e particionamento baseado no uso real.
-
Mantenha a porta aberta para híbridos:\
- Use múltiplos bancos se diferentes partes do sistema tiverem necessidades distintas.\
- Documente decisões, trade‑offs e padrões na base de conhecimento interna (por exemplo em
/docs/architecture/datastores).
Para aprofundar, estenda este panorama com padrões internos, checklists de migração e leituras adicionais no seu manual de engenharia ou em /blog.
Perguntas frequentes
Qual é a diferença principal entre bancos de dados SQL e NoSQL?
SQL (relacional):
- Usam tabelas com linhas e colunas.
- Aplicam um esquema fixo (colunas, tipos, restrições definidos).
- Utilizam SQL como linguagem de consulta padronizada.
- Enfatizam transações ACID e consistência forte.
NoSQL (não relacional):
- Utilizam modelos flexíveis (documentos, chave‑valor, wide‑column, grafos).
- Frequentemente permitem dados com esquemas flexíveis ou ausentes.
- Usam APIs de consulta ou DSLs específicas do banco.
- Muitas vezes trocam algumas garantias de consistência por escalabilidade e disponibilidade.
Quando um banco de dados SQL costuma ser a melhor escolha?
Use um banco SQL quando:
- Seus dados são bem estruturados e relacionais (usuários, pedidos, faturas).
- Você precisa de transações ACID envolvendo várias linhas/tabelas.
- Corretude e consistência são mais importantes que taxa bruta de processamento.
- Você prevê muitas consultas ad‑hoc, joins e necessidades de reporting.
- Conformidade, auditoria e manutenibilidade de longo prazo são críticas.
Para a maioria dos novos sistemas de registro, SQL é um padrão sensato.
Quando um banco de dados NoSQL costuma ser a melhor escolha?
NoSQL é ideal quando:
- Você precisa escalar gravações e armazenamento horizontalmente por muitos nós.
- Seus dados são semiestruturados, aninhados ou mudam de formato com frequência.
- Os padrões de acesso são bem conhecidos e podem ser modelados em torno de chaves ou documentos.
- Inconsistências temporárias são aceitáveis (por exemplo, feeds, logs, visões analíticas).
- Você lida com telemetria IoT, séries temporais, caching ou conteúdo gerado por usuários em grande escala.
Como os esquemas e o modelamento de dados diferem entre SQL e NoSQL?
Bancos SQL:
- Usam esquemas predefinidos; cada linha deve corresponder à definição da tabela.
- Encorajam normalização para reduzir duplicação e reforçar integridade.
- Usam chaves estrangeiras e restrições para gerir relacionamentos.
Bancos NoSQL:
- Permitem que documentos/registro tenham campos diferentes na mesma coleção.
- Frequentemente incentivam desnormalização e embutimento de dados relacionados.
- Transferem mais responsabilidade para a aplicação para impor regras de dados.
Isso significa que o controle de esquema se desloca do banco (SQL) para a aplicação (NoSQL).
Como SQL e NoSQL diferem em consistência e transações?
Bancos SQL:
- Centram‑se em transações ACID com consistência forte.
- São ideais quando toda leitura deve ver um estado válido e atualizado.
Muitos sistemas NoSQL:
- Privilegiam disponibilidade e tolerância a partições.
- Usam propriedades BASE e consistência eventual: réplicas convergem com o tempo.
- Podem oferecer consistência configurável por operação ou por partição.
Escolha SQL quando leituras desatualizadas forem perigosas; escolha NoSQL quando pequenas defasagens forem aceitáveis em troca de escala e disponibilidade.
Como SQL e NoSQL costumam escalar?
Bancos SQL normalmente:
- Começam com escalabilidade vertical (servidores mais potentes).
- Adicionam réplicas de leitura para ampliar leituras.
- Às vezes usam sharding ou produtos de SQL distribuído para escala horizontal.
Bancos NoSQL normalmente:
- São projetados para escalabilidade horizontal desde o início.
- Fazem sharding/particionamento dos dados entre muitos nós.
- Facilitam aumentar capacidade adicionando servidores commodity.
A troca é que clusters NoSQL costumam ser mais complexos operacionalmente, enquanto SQL pode encontrar limites em um único nó mais cedo.
Posso usar SQL e NoSQL juntos no mesmo sistema?
Sim. Persistência poliglota é comum:
- Use SQL como sistema de registro autoritativo (pagamentos, contas, entidades centrais).
- Adicione NoSQL para sessões, caches, feeds, logs ou busca.
Padrões de integração incluem:
- Captura de alterações (CDC) ou streams do SQL para NoSQL.
- Jobs ETL periódicos para construir visões otimizadas para leitura.
- Serviços que escondem as lojas subjacentes por APIs estáveis.
A chave é adicionar cada datastore extra apenas quando ele resolver um problema claro.
Como devo abordar a migração entre SQL e NoSQL?
Para migrar com segurança:
- Identifique um contexto delimitado (por exemplo, catálogo de produtos) para migrar.\
- Modele os dados em torno dos novos padrões de acesso, não fazendo cópia tabela‑a‑tabela.\
- Use gravações duplas ou CDC para manter as lojas antigas e novas sincronizadas temporariamente.\
- Valide os dados entre as lojas e planeje backfills repetíveis.\
- Desvie tráfego incrementalmente, com rollback preparado.
Evite migrações “big‑bang”; prefira passos incrementais bem monitorados.
Quais fatores devo avaliar ao escolher entre SQL e NoSQL?
Considere:
- Estrutura de dados: tabular com relacionamentos claros versus documentos/eventos flexíveis.\
- Necessidades de consistência: ACID estrito versus aceitabilidade de defasagem.\
- Escala e latência: volume de gravação esperado, tamanho do conjunto de dados, usuários globais.\
- Padrões de consulta: joins ad‑hoc e análises versus buscas previsíveis por chave/documento.\
- Habilidades da equipe e ferramentas: o que sua equipe sabe operar com confiança.\
- Custos e operação: opções gerenciadas versus rodar clusters distribuídos.
Protótipos para fluxos críticos e medições de latência, throughput e complexidade ajudam a decidir antes de comprometer uma tecnologia.
Quais são alguns mitos comuns sobre bancos de dados SQL vs NoSQL?
Equívocos comuns incluem:
- "NoSQL substituirá SQL" – na prática, eles se complementam.\
- "SQL não escala horizontalmente" – sistemas relacionais modernos suportam réplicas, sharding e SQL distribuído.\
- "NoSQL não tem esquema" – esquemas existem, mas frequentemente são aplicados pela aplicação ou validadores.\
- "Um tipo é sempre mais rápido" – performance depende de modelagem, indexação e carga de trabalho.
Avalie produtos e arquiteturas específicas em vez de confiar em mitos de categoria.