A maioria dos produtos começa com integrações ponto a ponto simples: Sistema A chama Sistema B, ou um pequeno script copia dados de um lugar para outro. Funciona até o produto crescer, as equipes se dividirem e o número de conexões se multiplicar. Logo, toda mudança precisa de coordenação entre vários serviços, porque um pequeno campo ou atualização de status pode repercutir por uma cadeia de dependências.
A velocidade costuma ser a primeira a se quebrar. Adicionar um novo recurso significa atualizar várias integrações, redeployar serviços e torcer para que nada mais dependesse do comportamento antigo.
Depois, depurar fica doloroso. Quando algo parece errado na interface, é difícil responder perguntas básicas: o que aconteceu, em que ordem e qual sistema escreveu o valor que você está vendo?
A peça que falta é frequentemente uma trilha de auditoria. Se os dados são empurrados diretamente de um banco para outro (ou transformados no caminho), você perde o histórico. Pode ver o estado final, mas não a sequência de eventos que levou até ali. Revisões de incidentes e suporte ao cliente sofrem porque você não consegue reproduzir o passado para confirmar o que mudou e por quê.
É aí que começa o argumento “quem possui a verdade”. Um time diz: “O serviço de billing é a fonte da verdade.” Outro diz: “O serviço de pedidos é.” Na prática, cada sistema tem uma visão parcial, e integrações ponto a ponto transformam esse desacordo em atrito diário.
Um exemplo simples: um pedido é criado, depois pago, depois reembolsado. Se três sistemas atualizam uns aos outros diretamente, cada um pode acabar com uma história diferente quando ocorrem retries, timeouts ou correções manuais.
Isso leva à questão central de design por trás do streaming de eventos com Kafka: você só precisa mover trabalho de um lugar para outro (uma fila), ou precisa de um registro compartilhado e durável do que aconteceu para que muitos sistemas possam ler, rebobinar e confiar (um log)? A resposta muda como você constrói, depura e evolui seu sistema.
Jay Kreps, Kafka e a ideia do log
Jay Kreps ajudou a moldar Kafka e, mais importante, a maneira como muitas equipes pensam sobre movimentação de dados. A mudança útil é de mentalidade: pare de tratar mensagens como entregas pontuais e comece a tratar a atividade do sistema como um registro.
A ideia central é simples. Modele mudanças importantes como um fluxo de fatos imutáveis:
- Um pedido foi criado.
- Um pagamento foi autorizado.
- Um usuário mudou seu e-mail.
Cada evento é um fato que não deve ser editado depois. Se algo mudar depois, você adiciona um novo evento que declara a nova verdade. Com o tempo, esses fatos formam um log: um histórico append-only do seu sistema.
É aqui que o streaming de eventos com Kafka difere de muitas configurações básicas de mensageria. Muitas filas são construídas em torno de “envie, processe, delete”. Isso é OK quando o trabalho é puramente uma passagem de mão. A visão de log diz: “guarde o histórico para que muitos consumidores possam usá-lo, agora e mais tarde.”
Reexecutar o histórico é o superpoder prático.
Se um relatório está errado, você pode reexecutar o mesmo histórico de eventos por um job de analytics corrigido e ver onde os números mudaram. Se um bug causou e-mails errados, você pode reproduzir eventos em um ambiente de teste e reproduzir a linha do tempo exata. Se um novo recurso precisa de dados antigos, você pode construir um consumidor que comece do início e se atualize no próprio ritmo.
Aqui vai um exemplo concreto. Imagine que você adiciona verificações de fraude depois de já ter processado meses de pagamentos. Com um log de pagamentos e eventos de conta, você pode reprocessar o passado para treinar ou calibrar regras com sequências reais, computar scores de risco para transações antigas e preencher retroativamente eventos fraud_review_requested sem reescrever seu banco de dados.
Perceba o que isso te força a fazer. Uma abordagem baseada em log te empurra a nomear eventos claramente, mantê-los estáveis e aceitar que múltiplas equipes e serviços vão depender deles. Também força perguntas úteis: Qual é a fonte da verdade? O que esse evento significa a longo prazo? O que fazemos quando cometemos um erro?
O valor não está na personalidade. Está em perceber que um log compartilhado pode se tornar a memória do seu sistema, e memória é o que permite que sistemas cresçam sem quebrar toda vez que você adiciona um novo consumidor.
Fila vs log: o modelo mental mais simples
Uma fila de mensagens é como uma fila de afazeres para o seu software. Produtores colocam trabalho na fila, consumidores pegam o próximo item, fazem o trabalho e o item some. O sistema se preocupa principalmente em garantir que cada tarefa seja tratada uma vez, o mais rápido possível.
Um log é diferente. É um registro ordenado de fatos que aconteceram, mantido em sequência durável. Consumidores não “tiram” eventos. Eles leem o log no próprio ritmo e podem lê-lo de novo mais tarde. No streaming de eventos com Kafka, esse log é a ideia central.
Uma forma prática de lembrar a diferença:
- Fila = trabalho a ser feito. Uma vez que um worker confirma, desaparece.
- Log = histórico do que aconteceu. Eventos ficam disponíveis por um período de retenção.
A retenção muda o design. Com uma fila, se você depois precisar de um novo recurso que dependa de mensagens antigas (analytics, checagens de fraude, replays após um bug), geralmente precisa adicionar um banco de dados separado ou começar a capturar cópias extras em outro lugar. Com um log, replay é normal: você pode reconstruir uma visão derivada lendo desde o início (ou desde um checkpoint conhecido).
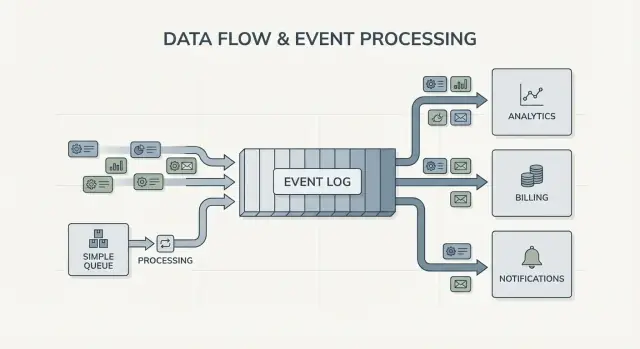
Fan-out é outra grande diferença. Imagine um serviço de checkout emitir OrderPlaced. Com uma fila, você geralmente escolhe um grupo de workers para processar, ou duplica o trabalho em múltiplas filas. Com um log, billing, e-mail, inventário, indexação de busca e analytics podem todos ler o mesmo fluxo de eventos de forma independente. Cada time pode andar no seu próprio ritmo, e adicionar um novo consumidor depois não exige mudar o produtor.
Então o modelo mental é direto: use uma fila quando você está movendo tarefas; use um log quando está registrando eventos que várias partes da empresa podem querer ler, agora ou depois.
O que o event streaming muda no design do sistema
Event streaming muda a pergunta padrão. Em vez de perguntar “Para quem devo enviar essa mensagem?”, você começa registrando “O que acabou de acontecer?” Isso parece pequeno, mas muda como você modela o sistema.
Você publica fatos como OrderPlaced ou PaymentFailed, e outras partes do sistema decidem se, quando e como reagirão.
Com Kafka event streaming, produtores param de precisar de uma lista de integrações diretas. Um serviço de checkout pode publicar um evento, e não precisa saber se analytics, e-mail, checagens de fraude ou um serviço de recomendações futuro vão usá-lo. Consumidores novos podem surgir depois, consumidores antigos podem ser pausados, e o produtor continua se comportando do mesmo jeito.
Isso também muda como você se recupera de erros. Em um mundo apenas com mensagens, quando um consumidor perde algo ou tem um bug, os dados muitas vezes ficam “perdidos” a menos que você tenha backups personalizados. Com um log, você corrige o código e reexecuta o histórico para reconstruir o estado correto. Isso frequentemente é melhor do que editar tabelas manualmente ou scripts avulsos que ninguém confia.
Na prática, a mudança aparece de algumas formas confiáveis: você trata eventos como registro durável, adiciona funcionalidades assinando em vez de modificar produtores, pode reconstruir read models (índices de busca, dashboards) do zero e obtém timelines mais claras do que ocorreu entre serviços.
A observabilidade melhora porque o log de eventos vira uma referência compartilhada. Quando algo dá errado, você pode seguir uma sequência de negócio: pedido criado, inventário reservado, pagamento refeito, envio agendado. Essa linha do tempo é frequentemente mais fácil de entender que logs de aplicação espalhados, porque está focada em fatos de negócio.
Um exemplo concreto: se um bug de desconto precificar pedidos mal por duas horas, você corrige e reexecuta os eventos afetados para recalcular totais, atualizar faturas e refrescar analytics. Você corrige resultados re-derivando-os, não chutando quais tabelas devem ser patchadas manualmente.
Quando uma fila simples é suficiente
Uma fila simples é a ferramenta certa quando você está movendo trabalho, não construindo um registro de longo prazo. O objetivo é entregar uma tarefa para um worker, executá-la e depois esquecer. Se ninguém precisa reprocessar o passado, inspecionar eventos antigos ou adicionar novos consumidores depois, uma fila mantém as coisas mais simples.
Filas brilham para jobs em background: enviar e-mails de cadastro, redimensionar imagens após upload, gerar um relatório noturno ou chamar uma API externa lenta. Nesses casos a mensagem é só um ticket de trabalho. Uma vez que um worker termina, o ticket cumpriu seu papel.
Uma fila também se encaixa no modelo usual de propriedade: um grupo de consumidores é responsável por fazer o trabalho, e outros serviços não devem ler a mesma mensagem independentemente.
Uma fila geralmente é suficiente quando a maioria destas é verdadeira:
- Os dados têm valor de curta duração.
- Um time ou serviço possui o job de forma end-to-end.
- Replays e retenção longa não são requisitos.
- Depuração não depende de reexecutar histórico.
Exemplo: um produto faz upload de fotos de usuários. O app escreve uma tarefa “resize image” em uma fila. O Worker A pega, cria thumbnails, armazena e marca a tarefa como concluída. Se a tarefa rodar duas vezes, o resultado é o mesmo (idempotente), então entrega ao menos uma vez é aceitável. Nenhum outro serviço precisa ler essa tarefa depois.
Se suas necessidades começarem a caminhar para fatos compartilhados (muitos consumidores), replay, auditoria ou “o que o sistema acreditava na semana passada?”, é aí que Kafka event streaming e uma abordagem baseada em log começam a compensar.
Quando uma abordagem baseada em log compensa
Um sistema baseado em log compensa quando eventos deixam de ser mensagens pontuais e passam a ser histórico compartilhado. Em vez de “envie e esqueça”, você guarda um registro ordenado que muitos times podem ler, agora ou depois, no próprio ritmo.
O sinal mais claro é múltiplos consumidores. Um evento como OrderPlaced pode alimentar billing, e-mail, checagens de fraude, indexação e analytics. Com um log, cada consumidor lê o mesmo stream de forma independente. Você não precisa construir um pipeline de fan-out customizado ou coordenar quem recebe a mensagem primeiro.
Outra vantagem é poder responder “O que sabíamos então?” Se um cliente questiona uma cobrança ou uma recomendação pareceu errada, um histórico append-only torna possível reexecutar os fatos conforme chegaram. Essa trilha de auditoria é difícil de acrescentar a uma fila simples depois.
Você também ganha uma maneira prática de adicionar funcionalidades sem reescrever as antigas. Se você adiciona uma nova página de “status de envio” meses depois, um novo serviço pode se inscrever e preencher o histórico existente para criar seu estado, em vez de pedir exports a outros sistemas.
Uma abordagem baseada em log costuma valer a pena quando você reconhece uma ou mais destas necessidades:
- Os mesmos eventos devem alimentar vários sistemas (analytics, busca, billing, ferramentas de suporte).
- Você precisa de replay, auditoria ou investigações com base em fatos passados.
- Novos serviços precisam backfill a partir do histórico sem jobs ad-hoc.
- A ordenação importa por entidade (por pedido, por usuário).
- Os formatos de evento vão evoluir e você precisa de uma forma controlada de versionamento.
Um padrão comum é um produto que começa com pedidos e e-mails. Mais tarde, finanças quer relatórios de receita, produto quer funis e ops quer um dashboard ao vivo. Se cada nova necessidade te força a copiar dados por um novo pipeline, os custos aparecem rápido. Um log compartilhado deixa equipes construir sobre a mesma fonte de verdade, mesmo com crescimento e alterações nas formas dos eventos.
Como decidir, passo a passo
Escolher entre uma fila simples e uma abordagem baseada em log é mais fácil quando você trata isso como uma decisão de produto. Comece pelo que precisa ser verdade daqui a um ano, não só pelo que funciona esta semana.
Uma decisão prática em 5 passos
-
Mapeie publishers e leitores. Anote quem cria eventos e quem os lê hoje, depois adicione consumidores prováveis (analytics, indexação, checagens de fraude, notificações). Se esperar muitos times lendo os mesmos eventos independentemente, um log começa a fazer sentido.
-
Pergunte se será necessário reler o histórico. Seja específico sobre o porquê: replay após um bug, backfills, ou consumidores que leem em velocidades diferentes. Filas são ótimas para passagem única. Logs são melhores quando você quer um registro que possa ser reprocessado.
-
Defina o que significa “feito”. Para alguns workflows, feito significa “o job rodou” (enviar um e-mail, redimensionar uma imagem). Para outros, feito significa “o evento é um fato durável” (um pedido foi feito, um pagamento foi autorizado). Fatos duráveis empurram você para um log.
-
Escolha expectativas de entrega e decida como lidar com duplicatas. Entrega ao menos uma vez é comum, o que significa que duplicatas podem ocorrer. Se uma duplicata pode causar dano (cobrar um cartão em dobro), planeje idempotência: armazene o ID do evento processado, use constraints únicas ou torne atualizações seguras para repetição.
-
Comece com uma fatia fina. Escolha um tópico de evento fácil de entender e cresça a partir daí. Se for com Kafka event streaming, mantenha o primeiro tópico focado, nomeie eventos claramente e evite misturar tipos de evento não relacionados.
Um exemplo concreto: se OrderPlaced vai alimentar envio, faturamento, suporte e analytics, um log deixa cada time ler no próprio ritmo e reprocessar após erros. Se você só precisa de um worker em background para enviar um recibo, uma fila simples costuma bastar.
Exemplo: eventos de pedido em um produto que cresce
Imagine uma pequena loja online. No começo ela só precisa receber pedidos, cobrar um cartão e criar uma solicitação de envio. A versão mais simples é um job em background que roda após o checkout: “process order”. Ele chama a API de pagamentos, atualiza a linha de pedidos no banco e então aciona o envio.
Esse estilo de fila funciona bem quando há um workflow claro, só precisa de um consumidor (o worker) e retries/dead letters cobrem a maior parte dos erros.
Começa a doer conforme a loja cresce. Suporte quer atualizações automáticas “onde está meu pedido?”. Finanças quer números diários de receita. Produto quer e-mails ao cliente. Uma checagem de fraude deveria ocorrer antes do envio. Com um único job “process order”, você acaba editando o mesmo worker repetidamente, adicionando ramificações e correndo risco de bugs no fluxo central.
Com uma abordagem baseada em log, o checkout gera pequenos fatos como eventos, e cada time pode se apoiar neles. Eventos típicos podem ser:
OrderPlacedPaymentConfirmedItemShippedRefundIssued
A mudança chave é propriedade. O serviço de checkout é dono de OrderPlaced. O serviço de pagamentos é dono de PaymentConfirmed. Shipping é dono de ItemShipped. Mais tarde, novos consumidores podem surgir sem mudar o produtor: um serviço de fraude lê OrderPlaced e PaymentConfirmed para pontuar risco, um serviço de e-mail envia recibos, analytics constrói funis e ferramentas de suporte mostram a linha do tempo.
É aí que Kafka event streaming compensa: o log guarda o histórico, então consumidores novos podem rebobinar e se atualizar desde o começo (ou de um ponto conhecido) em vez de pedir webhooks a cada time upstream.
O log ainda não substitui seu banco de dados. Você continua precisando de um BD para o estado atual: o último status do pedido, o cadastro do cliente, contagens de inventário e regras transacionais (como “não enviar a menos que o pagamento esteja confirmado”). Pense no log como o registro de mudanças e no banco como o lugar onde você consulta “o que é verdade agora”.
Erros comuns e armadilhas
Event streaming pode deixar sistemas mais limpos, mas alguns erros comuns podem apagar os benefícios rapidamente. A maioria vem de tratar o log de eventos como um controle remoto em vez de um registro.
Uma armadilha frequente é escrever eventos como comandos, tipo “SendWelcomeEmail” ou “ChargeCardNow”. Isso deixa consumidores fortemente acoplados à sua intenção. Eventos funcionam melhor como fatos: “UserSignedUp” ou “PaymentAuthorized”. Fatos envelhecem bem. Times novos podem reutilizá-los sem adivinhar o sentido.
Duplicatas e retries são outra grande fonte de dor. Em sistemas reais, produtores fazem retries e consumidores reprocessam. Se você não planejar, surgem cobranças em dobro, e-mails duplos e tickets de suporte. A solução não é exótica, mas precisa ser deliberada: handlers idempotentes, IDs de evento estáveis e regras de negócio que detectam “já aplicado”.
Armadilhas comuns:
- Escrever eventos no estilo comando que dizem ao serviço o que fazer em vez de registrar o que aconteceu.
- Construir consumidores que quebram se virem o mesmo evento duas vezes.
- Dividir streams cedo demais, espalhando um fluxo de negócio por muitos tópicos.
- Ignorar regras de schema até que uma pequena mudança quebre consumidores antigos.
- Tratar streaming como substituto de bom design de banco de dados.
Schema e versionamento merecem atenção especial. Mesmo que você comece com JSON, precisa de um contrato claro: campos obrigatórios, campos opcionais e como mudanças são implantadas. Uma pequena alteração como renomear um campo pode quebrar analytics, billing ou apps móveis que atualizam mais devagar.
Outra armadilha é criar streams demais. Times às vezes criam um novo stream para cada feature. Um mês depois ninguém sabe responder “Qual é o estado atual de um pedido?” porque a história está espalhada por muitos lugares.
Event streaming não elimina a necessidade de modelos de dados sólidos. Ainda é preciso um banco que represente a verdade atual. O log é história, não toda a sua aplicação.
Checklist rápido e próximos passos
Se você está em dúvida entre fila e Kafka event streaming, comece por checagens rápidas. Elas indicam se você precisa de uma passagem simples entre workers ou de um log reutilizável por anos.
Checagens rápidas
- Você precisa de replay (para backfills, correção de bugs ou novos recursos), e até que ponto?
- Mais de um consumidor precisará dos mesmos eventos agora ou em breve (analytics, busca, e-mails, fraude, billing)?
- Precisa de retenção para que times releiam a história sem pedir ao produtor que reenvie?
- Quão importante é ordenação, e em que nível: por entidade (pedido, usuário) ou global?
- Consumidores podem ser idempotentes (seguros para reprocessar sem cobrar/emvios/emails duplicados)?
Se respondeu “não” para replay, “um único consumidor” e “mensagens de curta duração”, uma fila básica geralmente basta. Se respondeu “sim” para replay, múltiplos consumidores ou retenção mais longa, uma abordagem baseada em log tende a compensar porque transforma um fluxo de fatos em uma fonte compartilhada que outros sistemas podem usar.
Próximos passos
Transforme as respostas em um plano pequeno e testável.
- Liste 5–10 eventos centrais em linguagem simples (ex.:
OrderPlaced, PaymentAuthorized, OrderShipped) e anote quem publica e quem consome cada um.
- Decida a chave de ordenação (geralmente por entidade, como
orderId) e documente o que “ordem correta” significa.
- Defina uma regra de idempotência por consumidor (por exemplo: armazenar o último ID de evento processado por pedido).
- Escolha uma meta de retenção que atenda suas necessidades (dias para fluxo tipo fila, semanas/meses quando replay importa).
- Execute uma fatia ponta a ponta em um sandbox antes de comprometer o sistema todo.
Se estiver prototipando rápido, você pode esboçar o fluxo de eventos no modo de planejamento do Koder.ai e iterar o design antes de consolidar nomes de eventos e regras de retry. Como o Koder.ai suporta export de código, snapshots e rollback, também é uma forma prática de testar uma fatia produtor-consumidor e ajustar formatos sem transformar experimentos iniciais em dívida de produção.