A maioria das pessoas experimenta a Internet por meio de produtos: um site que carrega instantaneamente, uma chamada de vídeo que (na maior parte) funciona, um pagamento que é compensado em segundos. Por trás dessas experiências estão protocolos — regras compartilhadas que permitem que sistemas diferentes troquem mensagens com confiabilidade suficiente para serem úteis.
Um protocolo é como concordar em uma linguagem comum e etiqueta para comunicação: como é uma mensagem, como você inicia e encerra uma conversa, o que fazer quando algo está faltando e como saber para quem uma mensagem é destinada. Sem regras compartilhadas, toda conexão vira uma negociação pontual, e redes não escalam além de círculos pequenos.
Vint Cerf costuma ser creditado como um “pai da Internet”, mas é mais preciso (e mais útil) ver seu papel como parte de uma equipe que fez escolhas de projeto pragmáticas — especialmente em torno do TCP/IP — que transformaram “redes” em um internetwork. Essas escolhas não eram inevitáveis. Refletiam trade-offs: simplicidade vs. funcionalidades, flexibilidade vs. controle, e velocidade de adoção vs. garantias perfeitas.
As plataformas globais de hoje — apps web, serviços móveis, infraestrutura em nuvem e APIs entre empresas — ainda vivem ou morrem pela mesma ideia: se você padronizar as fronteiras certas, pode permitir que milhões de atores independentes construam em cima sem pedir permissão. Seu telefone se comunica com servidores em continentes diferentes não apenas porque o hardware ficou mais rápido, mas porque as regras da estrada permaneceram estáveis o suficiente para que inovação se acumulasse.
Essa mentalidade importa mesmo quando você está “apenas construindo software”. Por exemplo, plataformas de vibe-coding como Koder.ai têm sucesso quando fornecem um pequeno conjunto de primitivas estáveis (projetos, implantações, ambientes, integrações) enquanto deixam as equipes iterarem rapidamente nas bordas — seja gerando um frontend React, um backend Go + PostgreSQL, ou um app móvel em Flutter.
O que você vai tirar deste artigo
Tocaremos a história brevemente, mas o foco são decisões de projeto e suas consequências: como o empilhamento (layering) possibilitou crescimento, onde a entrega “boa o suficiente” destravou novas aplicações, e quais suposições iniciais estavam erradas sobre congestionamento e segurança. O objetivo é prático: leve o pensamento de protocolos — interfaces claras, interoperabilidade e trade-offs explícitos — e aplique ao design de plataformas modernas.
O problema antes da Internet: muitas redes, sem cola comum
Antes da “Internet” existir, havia muitas redes — só que não uma rede que todo mundo pudesse compartilhar. Universidades, laboratórios governamentais e empresas construíam seus próprios sistemas para resolver necessidades locais. Cada rede funcionava, mas raramente funcionavam juntas.
Uma linha do tempo rápida (alto nível)
- Final dos anos 1960: a ARPANET prova a ideia de conectar computadores distantes sobre uma rede compartilhada.
- Início dos anos 1970: novas redes por pacotes surgem, construídas por organizações diferentes com regras e equipamentos diferentes.
- Final dos anos 1970–início dos 1980: experimentos de interconexão amadurecem em padrões compartilhados que muitas redes podem adotar.
Por que havia tantas redes separadas
Múltiplas redes existiam por razões práticas, não porque as pessoas gostassem de fragmentação. Operadores tinham objetivos distintos (pesquisa, confiabilidade militar, serviço comercial), orçamentos diferentes e restrições técnicas distintas. Fornecedores de hardware vendiam sistemas incompatíveis. Algumas redes eram otimizadas para enlaces de longa distância, outras para ambientes de campus, e outras para serviços especializados.
O resultado foi muitas “ilhas” de conectividade.
O problema real: interconexão sem reescritas
Se você queria que duas redes conversassem, a opção bruta era reconstruir um lado para coincidir com o outro. Isso raramente acontece no mundo real: é caro, lento e politicamente complicado.
O que era necessário era uma cola comum — uma forma para redes independentes se interconectarem mantendo suas escolhas internas. Isso significava:
- permitir que redes diferentes mantivessem seu próprio hardware e práticas operacionais
- habilitar mensagens a viajarem por múltiplas redes como uma única jornada
- evitar um único dono ou controle central em que todos precisem confiar
Esse desafio preparou o terreno para as ideias de internetworking que Cerf e outros defenderam: conectar redes numa camada compartilhada, de modo que a inovação pudesse ocorrer acima dela e a diversidade pudesse continuar abaixo dela.
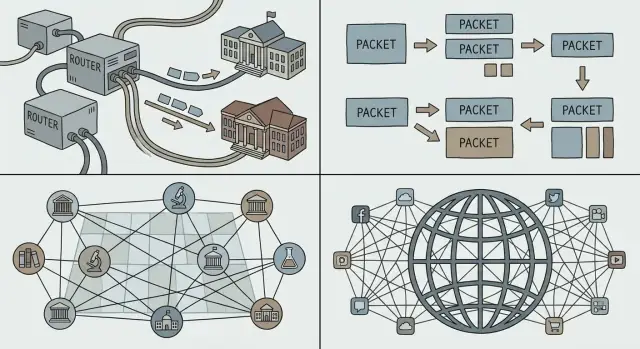
Comutação por pacotes: a base por trás de tudo
Se você já fez uma chamada telefônica, já sentiu a intuição por trás da comutação por circuito: uma “linha” dedicada é reservada para você de ponta a ponta durante a chamada. Isso funciona bem para voz em tempo real, mas é desperdiçador quando a conversa tem muito silêncio.
Comutação por pacotes inverte o modelo. Uma analogia cotidiana é o serviço postal: em vez de reservar uma rodovia privada da sua casa até a do amigo, você coloca sua mensagem em envelopes. Cada envelope (pacote) é etiquetado, roteado por vias compartilhadas e remontado no destino.
A maior parte do tráfego de computadores é explosiva (bursty). Um email, um download de arquivo ou uma página web não é um fluxo contínuo — é um pico rápido de dados, depois nada, depois outro pico. A comutação por pacotes permite que muitas pessoas compartilhem os mesmos enlaces de rede eficientemente, porque a rede carrega pacotes de quem tiver algo a enviar agora.
Essa é uma razão chave pela qual a Internet pôde suportar novas aplicações sem renegociar como a rede subjacente funcionava: você pode enviar uma mensagem minúscula ou um vídeo enorme usando o mesmo método básico — dividir em pacotes e enviar.
Escalar por distância — e por organizações
Pacotes também escalam socialmente, não apenas tecnicamente. Diferentes redes (operadas por universidades, empresas ou governos) podem se interconectar contanto que concordem em como encaminhar pacotes. Nenhum operador precisa “possuir” todo o caminho; cada domínio pode carregar tráfego até o próximo.
Os trade-offs: atraso, perda e controle
Porque pacotes compartilham enlaces, você pode ter atraso por enfileiramento, jitter ou até perda quando redes estão ocupadas. Essas desvantagens impulsionaram a necessidade de mecanismos de controle — retransmissões, ordenação e controle de congestionamento — para que a comutação por pacotes se mantenha rápida e justa mesmo sob carga pesada.
Internetworking e a separação TCP/IP: um empilhamento simples e poderoso
O objetivo que Cerf e colegas perseguiam não era “construir uma rede”. Era interconectar muitas redes — universitárias, governamentais, comerciais — enquanto deixava cada uma manter sua própria tecnologia, operadores e regras.
Uma grande ideia: dividir o trabalho em dois
TCP/IP é frequentemente descrito como uma “suíte”, mas o movimento de projeto pivotal é a separação de preocupações:
- IP (Internet Protocol) trata de endereçamento e roteamento: levar pacotes de uma rede a outra, salto a salto.
- TCP (Transmission Control Protocol) trata de entrega confiável (quando você precisa): ordenação, retransmissão e controle de fluxo para que aplicações possam tratar a conexão como um cano limpo.
Essa divisão permitiu que a “internet” agisse como um tecido comum de entrega, enquanto a confiabilidade virou um serviço opcional empilhado por cima.
Por que o empilhamento continua vencendo
O empilhamento (layering) torna sistemas mais fáceis de evoluir porque você pode atualizar uma camada sem renegociar tudo acima dela. Novos enlaces físicos (fibra, Wi‑Fi, celular), estratégias de roteamento e mecanismos de segurança podem surgir ao longo do tempo — ainda assim as aplicações falam TCP/IP e continuam funcionando.
É o mesmo padrão que equipes de plataforma adotam: interfaces estáveis, internos substituíveis.
“Primitivas boas o suficiente” criam aplicações-surpresa
O IP não promete perfeição; fornece primitivas simples e universais: “aqui está um pacote” e “aqui está um endereço.” Essa moderação permitiu que aplicações inesperadas florescessem — email, web, streaming, chat em tempo real — porque inovadores podiam construir o que precisavam nas bordas sem pedir permissão à rede.
Se você está projetando uma plataforma, este é um teste útil: você está oferecendo alguns blocos de construção confiáveis, ou sobreajustando o sistema ao caso de uso favorito de hoje?
IP best-effort: rede simples, permita que apps inovem
Entrega “best-effort” é uma ideia direta: o IP tentará mover seus pacotes rumo ao destino, mas não promete que eles chegarão, cheguem em ordem ou cheguem a tempo. Pacotes podem ser descartados quando enlaces estão ocupados, atrasados por congestionamento ou tomar rotas diferentes.
Por que “sem garantias” ajudou a Internet a se espalhar
Essa simplicidade foi uma característica, não um defeito. Organizações diferentes podiam conectar redes muito distintas — enlaces caros e de alta qualidade em alguns lugares; enlaces ruidosos e de baixa largura em outros — sem exigir que todos atualizassem para a mesma infraestrutura premium.
O IP best-effort reduziu o “preço de entrada” para participar. Universidades, governos, startups e, eventualmente, residências puderam ingressar usando a conectividade que conseguiam pagar. Se o protocolo central exigisse garantias estritas de cada rede ao longo do caminho, a adoção teria estagnado: o elo mais fraco bloquearia toda a cadeia.
A confiabilidade ficou nas extremidades
Em vez de construir um núcleo perfeitamente confiável, a Internet empurrou a confiabilidade para os hosts (os dispositivos em cada extremidade). Se uma aplicação precisa de correção — como transferências de arquivo, pagamentos ou carregar uma página web — ela pode usar protocolos e lógica nas bordas para detectar perdas e recuperar:
- retransmitir dados faltantes
- reordenar pacotes
- verificar integridade e completude
O TCP é o exemplo clássico: converte um serviço de pacotes não confiável em um fluxo confiável fazendo o trabalho difícil nas extremidades.
Para equipes de plataforma, o IP best-effort criou uma base previsível: em qualquer lugar do mundo, você pode assumir o mesmo serviço básico — envie pacotes para um endereço e eles geralmente chegarão. Essa consistência tornou possível construir plataformas de software globais que se comportam de maneira semelhante através de países, operadoras e hardwares.
O princípio end-to-end e seus trade-offs no mundo real
Publique no seu domínio
Conecte um domínio personalizado para compartilhar um endpoint limpo e estável.
O princípio end-to-end é uma ideia enganadoramente simples: mantenha o “core” da rede o mais mínimo possível e coloque a inteligência nas bordas — nos dispositivos e nas aplicações.
Por que “bordas inteligentes” ajudaram o software a acelerar
Para construtores de software, essa separação foi um presente. Se a rede não precisa entender sua aplicação, você pode lançar novas ideias sem negociar mudanças com cada operador de rede.
Essa flexibilidade é uma grande razão pela qual plataformas globais puderam iterar rapidamente: email, web, voz/video e, depois, apps móveis, todos rodaram sobre a mesma canalização subjacente.
Os trade-offs: abuso, segurança e expectativas de QoS
Um núcleo simples também significa que o núcleo não “protege” por padrão. Se a rede apenas encaminha pacotes, é mais fácil que atacantes e abusadores usem essa abertura para spam, varreduras, ataques de negação de serviço e fraudes.
Qualidade de serviço é outra tensão. Usuários esperam chamadas de vídeo suaves e respostas instantâneas, mas a entrega best-effort pode produzir jitter, congestionamento e desempenho inconsistente. A abordagem end-to-end empurra muitas correções para cima: lógica de retry, buffering, adaptação de taxa e priorização a nível de aplicação.
Muito do que se pensa como “a internet” hoje é estrutura extra empilhada acima do núcleo mínimo: CDNs que aproximam o conteúdo dos usuários, criptografia (TLS) para privacidade e integridade, e protocolos de streaming que adaptam a qualidade às condições atuais. Mesmo capacidades “à cara de rede” — como proteção contra bots, mitigação de DDoS e aceleração de desempenho — são frequentemente entregues como serviços de plataforma na borda em vez de incorporadas ao próprio IP.
Endereçamento, roteamento e DNS: tornar uma rede global utilizável
Uma rede só vira “global” quando cada dispositivo pode ser alcançado com confiabilidade suficiente, sem que cada participante precise conhecer todo o resto. Esse é o trabalho de endereçamento, roteamento e DNS: três ideias que transformam um amontoado de redes conectadas em algo que pessoas (e software) realmente usam.
Endereçamento vs. roteamento (a versão simples)
Um endereço é um identificador que diz à rede onde algo está. No IP, esse “onde” é expresso em forma numérica estruturada.
Roteamento é o processo de decidir como mover pacotes na direção desse endereço. Roteadores não precisam de um mapa completo de todas as máquinas do mundo; eles só precisam de informação suficiente para encaminhar tráfego passo a passo na direção certa.
O ponto é que decisões de encaminhamento podem ser locais e rápidas, enquanto o resultado global ainda parece alcançabilidade mundial.
Por que hierarquia e agregação tornam a escala possível
Se cada endereço de dispositivo tivesse de ser listado em todos os lugares, a Internet entraria em colapso sob sua própria contabilidade. O endereçamento hierárquico permite agrupar endereços (por exemplo, por rede ou provedor), de modo que roteadores possam manter rotas agregadas — uma entrada que representa muitos destinos.
Esse é o segredo nada glamouroso por trás do crescimento: tabelas de roteamento menores, menos atualizações e coordenação mais simples entre organizações. A agregação é também por que políticas de alocação de endereços IP importam para operadores: afetam diretamente o custo de manter o sistema global coerente.
Humanos não querem digitar números, e serviços não querem ficar amarrados a uma única máquina. DNS (Domain Name System) é a camada de nomes que mapeia nomes legíveis (como api.example.com) para endereços IP.
Para equipes de plataforma, o DNS é mais que conveniência:
- Suporta bases de usuários globais ao dirigir usuários para regiões próximas.
- Ajuda serviços distribuídos a mover e escalar sem mudar a configuração do cliente.
- Habilita apps multi-região e estratégias de failover onde o nome permanece estável enquanto a infraestrutura subjacente muda.
Em outras palavras, endereçamento e roteamento tornam a Internet alcançável; DNS a torna utilizável — e operacionalmente adaptável — em escala de plataforma.
Padrões abertos e interoperabilidade: a roda que impulsionou a adoção
Teste o fluxo de trabalho para free
Experimente o fluxo de trabalho gratuitamente para validar sua ideia antes de se comprometer.
Um protocolo só vira “a Internet” quando muitas redes e produtos independentes podem usá-lo sem pedir permissão. Uma das escolhas mais espertas em torno do TCP/IP não foi apenas técnica — foi social: publicar as especificações, convidar críticas e permitir que qualquer um as implementasse.
RFCs: publicar a receita
A série Request for Comments (RFC) transformou ideias de rede em documentos compartilhados e citáveis. Em vez de um padrão caixa-preta controlado por um fornecedor, os RFCs tornaram as regras visíveis: o que cada campo significa, o que fazer em casos de borda, e como permanecer compatível.
Essa abertura fez duas coisas. Primeiro, reduziu o risco para adotantes: universidades, governos e empresas podiam avaliar o projeto e construir com base nele. Segundo, criou um ponto de referência comum, de modo que desacordos pudessem ser resolvidos com atualizações do texto em vez de negociações privadas.
Interoperabilidade destrava ecossistemas
Interoperabilidade é o que torna “multi-fornecedor” real. Quando roteadores, sistemas operacionais e aplicações diferentes conseguem trocar tráfego de forma previsível, compradores não ficam presos. A competição muda de “de qual rede você pode entrar?” para “qual produto é melhor?” — o que acelera melhorias e reduz custos.
Compatibilidade também cria efeitos de rede: cada nova implementação TCP/IP torna toda a rede mais valiosa, porque pode conversar com todo o resto. Mais usuários atraem mais serviços; mais serviços atraem mais usuários.
Os limites: padrões ainda exigem trabalho
Padrões abertos não removem atrito — eles o redistribuem. RFCs envolvem debate, coordenação e às vezes mudanças lentas, especialmente quando bilhões de dispositivos já dependem do comportamento atual. A vantagem é que a mudança, quando ocorre, é legível e amplamente implementável — preservando o benefício central: todo mundo ainda pode se conectar.
Quando se diz “plataforma”, geralmente significa um produto com outras pessoas construindo em cima dele: apps de terceiros, integrações e serviços que rodam sobre trilhos compartilhados. Na internet, esses trilhos não são a rede privada de uma única empresa — são protocolos comuns que qualquer um pode implementar.
TCP/IP não criou a web, a nuvem ou lojas de apps sozinho. Ele fez uma base estável e universal onde essas coisas puderam se espalhar com confiança.
Uma vez que redes puderam se interconectar via IP e aplicações confiaram no TCP para entrega, tornou-se prático padronizar blocos de construção de nível mais alto:
- A web (HTTP + navegadores): um cliente pode alcançar muitos servidores, em qualquer lugar.
- APIs: serviços expõem funções pela rede de forma previsível.
- SaaS e nuvem: software passou de “instalado localmente” para “entregue pela rede”, porque a rede era consistente o bastante para apostar um negócio nela.
- Ecossistemas de apps e marketplaces: distribuição, atualizações e integrações tornaram-se expectativas normais.
O presente do TCP/IP para a economia das plataformas foi previsibilidade: você podia construir uma vez e alcançar muitas redes, países e tipos de dispositivo sem negociar conectividade sob medida a cada vez.
Protocolos estáveis reduzem custos de troca
Uma plataforma cresce mais rápido quando usuários e desenvolvedores sentem que podem sair — ou pelo menos não estão presos. Protocolos abertos e amplamente implementados reduzem custos de troca porque:
- Usuários podem trocar de provedor mantendo ferramentas familiares (email é o exemplo clássico).
- Desenvolvedores podem reaproveitar habilidades e código entre fornecedores (uma requisição ainda é uma requisição).
- Novos entrantes podem interoperar em vez de começar do zero.
Essa interoperabilidade “sem pedir permissão” é por que mercados globais de software formaram-se em torno de padrões compartilhados em vez de um único dono de rede.
Blocos habilitados por protocolos (exemplos rápidos)
- HTTP fez “buscar um recurso de qualquer lugar” um comportamento padrão para software.
- TLS adicionou confidencialidade e integridade para que comércio e identidade funcionassem em escala.
- SMTP transformou email em um sistema entre provedores, não um jardim murado.
Esses protocolos ficam acima do TCP/IP, mas dependem da mesma ideia: se as regras são estáveis e públicas, plataformas competem por produto — sem quebrar a capacidade de conectar.
Realidade da escala: congestionamento, latência e a necessidade de resiliência
A mágica da Internet é que ela funciona através de oceanos, redes móveis, hotspots Wi‑Fi e roteadores de escritório sobrecarregados. A verdade menos mágica: ela sempre opera sob restrições. Largura de banda é limitada, latência varia, pacotes se perdem ou se reordenam, e o congestionamento pode surgir de repente quando muitas pessoas compartilham o mesmo caminho.
As restrições que você não pode ignorar
Mesmo que seu serviço seja “baseado em nuvem”, seus usuários o experimentam pelo ponto mais estreito da rota até eles. Uma chamada de vídeo em fibra e a mesma chamada num trem lotado são produtos diferentes, porque latência (atraso), jitter (variação) e perda moldam a percepção do usuário.
Controle de congestionamento, conceitualmente
Quando tráfego demais atinge os mesmos enlaces, filas se formam e pacotes caem. Se todo remetente reagir enviando ainda mais (ou tentando novamente com agressividade), a rede pode entrar em colapso por congestionamento — muito tráfego, pouca entrega útil.
Controle de congestionamento é o conjunto de comportamentos que mantém o compartilhamento justo e estável: sondar capacidade disponível, reduzir quando sinais (perda/latência) indicam sobrecarga e então aumentar cautelosamente. O TCP popularizou esse ritmo de “retroceder, depois recuperar” para que a rede permanecesse simples enquanto os endpoints se adaptam.
Como isso moldou decisões de produto
Porque redes são imperfeitas, aplicações bem-sucedidas fazem trabalho extra silenciosamente:
- Cache para evitar viagens caras repetidas (CDNs, caches locais, respostas de API memoizadas).
- Retries com timeouts para recuperar perdas — mas não imediatamente e não para sempre.
- Backoff exponencial para que um serviço em dificuldade não seja martelado mais durante um incidente.
Projete como se a rede falhasse, breve e frequentemente:
- Faça operações idempotentes para que retries não dupliquem compras ou mensagens.
- Prefira degradação graciosa (conteúdo desatualizado, qualidade reduzida) ao invés de falha total.
- Instrumente percentis de latência e taxas de erro por região/tipo de rede, não apenas médias.
Resiliência não é um recurso extra — é o preço de operar em escala Internet.
Segurança e confiança: o que suposições iniciais erraram
Economize com créditos ganhos
Ganhe créditos ao compartilhar o que você criou ou indicar outros desenvolvedores.
O TCP/IP funcionou porque facilitou que qualquer rede se conectasse a qualquer outra. O custo oculto dessa abertura é que qualquer um também pode lhe enviar tráfego — bom ou ruim.
Conectividade aberta também habilita abuso
O desenho inicial da internet assumia uma comunidade relativamente pequena e orientada à pesquisa. Quando a rede se tornou pública, a mesma filosofia de “apenas encaminhar pacotes” permitiu spam, fraude, entrega de malware, ataques de negação de serviço e personificação. O IP não verifica quem você é. Email (SMTP) não exigia prova de que você possuía o endereço “From”. E roteadores nunca foram feitos para julgar intenção.
Segurança deixou de ser opcional e virou fundamental
À medida que a internet virou infraestrutura crítica, segurança deixou de ser uma característica que se adiciona depois e tornou-se um requisito na construção de sistemas: identidade, confidencialidade, integridade e disponibilidade precisaram de mecanismos explícitos. A rede manteve-se em grande parte best-effort e neutra, mas aplicações e plataformas tiveram que assumir que o meio é não confiável.
Mitigações construídas por cima (resumo)
Não “consertamos” o IP policando cada pacote. Em vez disso, a segurança moderna é em camadas acima dele:
- Criptografia (ex.: TLS/HTTPS) para evitar escutas e adulterações
- Autenticação (certificados, tokens assinados, MFA) para provar identidades
- Zero trust para evitar confiança implícita baseada em localização de rede
Trate a rede como hostil por padrão. Use o princípio do menor privilégio em toda parte: escopos estreitos, credenciais de curta duração e padrões seguros por omissão. Verifique identidades e entradas em cada fronteira, criptografe em trânsito e projete para cenários de abuso — não apenas para os caminhos felizes.
A internet não “venceu” porque cada rede concordou no mesmo hardware, fornecedor ou conjunto perfeito de funcionalidades. Ela perdurou porque escolhas de protocolo chave facilitaram que sistemas independentes se conectassem, melhorassem e continuassem funcionando mesmo quando partes falhavam.
Decisões de projeto a copiar
Empilhamento com seams claros. TCP/IP separou “mover pacotes” de “fazer aplicações confiáveis.” Essa fronteira permitiu que a rede ficasse generalista enquanto apps evoluíam rápido.
Simplicidade no núcleo. Entrega best-effort significou que a rede não precisou entender as necessidades de cada aplicação. Inovação ocorreu nas bordas, onde novos produtos podiam ser lançados sem negociar com uma autoridade central.
Interoperabilidade em primeiro lugar. Especificações abertas e comportamento previsível permitiramm que organizações diferentes construíssem implementações compatíveis — criando um ciclo de adoção compounding.
Traduza isso em estratégia de produto
Se você está construindo uma plataforma, trate interconexão como um recurso, não como um efeito colateral. Prefira um pequeno conjunto de primitivas que muitas equipes possam compor a um grande conjunto de funcionalidades “inteligentes” que prendem usuários a um único caminho.
Projete para evolução: suponha que clientes serão antigos, servidores serão novos e algumas dependências estarão parcialmente fora do ar. Sua plataforma deve degradar-se com graça e ainda ser útil.
Se você usa um ambiente de construção rápida como o Koder.ai, os mesmos princípios aparecem como capacidades de produto: uma etapa clara de planejamento (para que interfaces sejam explícitas), iteração segura via snapshots/rollback e comportamento previsível de deployment/hosting que permite múltiplas equipes moverem-se rápido sem quebrar consumidores.
- APIs: Mantenha um núcleo estável; adicione capacidades opcionais sem quebrar clientes antigos.
- Compatibilidade: Versione deliberadamente; evite remover campos/comportamentos; documente garantias.
- Comportamento em falhas: Timeouts, retries com backoff, chaves de idempotência e códigos de erro claros.
- Interoperabilidade: Publique esquemas/especificações; forneça implementações de referência e testes de conformidade.
- Observabilidade: IDs de correlação, logs estruturados e SLOs que reflitam a experiência do usuário.
- Controle de mudanças: Janelas de deprecação, feature flags e guias de migração.
Leituras recomendadas
- /blog/api-design-basics
- /blog/platform-strategy
- /blog/versioning-and-backward-compatibility
- /blog/graceful-degradation-patterns