Integrações webhook confiáveis: assinatura, idempotência, depuração
Aprenda integrações webhook confiáveis com assinatura, chaves de idempotência, proteção contra replay e um fluxo de debug rápido para falhas reportadas por clientes.
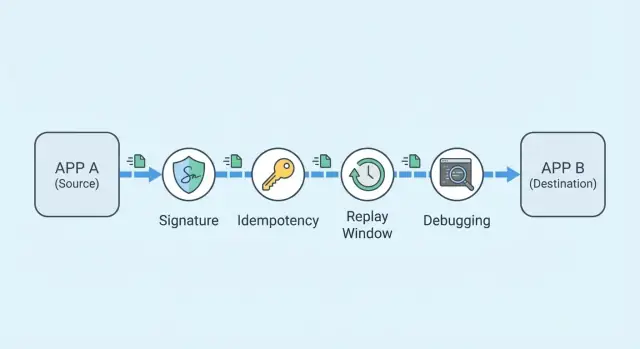
Por que webhooks falham na vida real
Quando alguém diz “os webhooks estão quebrados”, geralmente quer dizer três coisas: eventos nunca chegaram, eventos chegaram duas vezes, ou chegaram em uma ordem confusa. Do ponto de vista do cliente, o sistema “perdeu” algo. Do seu ponto de vista, o provedor enviou, mas seu endpoint não aceitou, não processou ou não registrou do jeito esperado.
Webhooks vivem na internet pública. Requisições atrasam, são re-enviadas e às vezes chegam fora de ordem. A maioria dos provedores faz retries agressivos quando vê timeouts ou respostas não 2xx. Isso transforma um pequeno problema (um banco de dados lento, um deploy, uma breve queda) em duplicações e condições de corrida.
Logs ruins fazem isso parecer aleatório. Se você não pode provar se uma requisição era autêntica, não pode agir com segurança. Se não consegue ligar a reclamação de um cliente a uma tentativa de entrega específica, acaba chutando.
A maioria das falhas no mundo real cai em alguns grupos:
- Eventos “faltando” (você timeoutou, retornou erro ou falhou depois de reconhecer)
- Duplicatas (retries somados a um handler não idempotente)
- Ordem errada (assumiu que ordem de entrega é ordem do evento)
- Requisições misteriosas (sem verificação de assinatura, então você não separa real de falso)
O objetivo prático é simples: aceitar eventos reais uma vez, rejeitar falsos e deixar um rastro claro para você depurar uma reclamação de cliente em minutos.
Como webhooks realmente se comportam
Um webhook é apenas uma requisição HTTP que um provedor envia para um endpoint que você expõe. Você não o puxa como uma chamada de API. O remetente empurra quando algo acontece, e seu trabalho é receber, responder rapidamente e processar com segurança.
Uma entrega típica inclui um corpo de requisição (frequentemente JSON) mais headers que ajudam a validar e rastrear o que você recebeu. Muitos provedores incluem um timestamp, um tipo de evento (como invoice.paid) e um ID único de evento que você pode guardar para detectar duplicatas.
O que surpreende times: a entrega quase nunca é “exatamente uma vez.” A maioria dos provedores visa “ao menos uma vez”, o que significa que o mesmo evento pode chegar várias vezes, às vezes minutos ou horas depois.
Retries acontecem por motivos mundanos: seu servidor está lento ou timeoutou, você retorna um 500, a rede deles não viu seu 200, ou seu endpoint ficou indisponível durante deploys ou picos de tráfego.
Timeout é especialmente traiçoeiro. Seu servidor pode receber a requisição e até terminar de processá-la, mas a resposta não chega ao remetente a tempo. Do ponto de vista do provedor, falhou, então ele reenvia. Sem proteção, você processa o mesmo evento duas vezes.
Um bom modelo mental é tratar a requisição HTTP como uma “tentativa de entrega”, não como “o evento”. O evento é identificado pelo seu ID. Seu processamento deve se basear nesse ID, não em quantas vezes o provedor chamou você.
Assinatura de webhooks em termos simples
Assinatura de webhook é como o remetente prova que uma requisição veio realmente dele e não foi alterada no caminho. Sem assinatura, qualquer um que adivinhe sua URL pode postar eventos falsos de “pagamento concluído” ou “usuário atualizado”. Pior, um evento real pode ser alterado em trânsito (valor, ID do cliente, tipo de evento) e ainda parecer válido para sua aplicação.
O padrão mais comum é HMAC com um segredo compartilhado. Ambos os lados conhecem o mesmo valor secreto. O remetente pega o payload exato do webhook (normalmente o corpo bruto da requisição), calcula um HMAC usando esse segredo e envia a assinatura junto com o payload. Seu trabalho é recalcular o HMAC sobre os mesmos bytes e verificar se as assinaturas coincidem.
Os dados de assinatura geralmente ficam num header HTTP. Alguns provedores também incluem um timestamp ali para que você possa adicionar proteção contra replay. Menos comumente, a assinatura fica embutida no corpo JSON, o que é mais arriscado porque parsers ou re-serialização podem mudar a formatação e quebrar a verificação.
Ao comparar assinaturas, não use uma comparação de string normal. Comparações básicas vazam diferenças de tempo que ajudam um atacante a adivinhar a assinatura correta em muitas tentativas. Use uma função de comparação em tempo constante da sua linguagem ou biblioteca criptográfica e rejeite em qualquer discrepância.
Se um cliente reporta “seu sistema aceitou um evento que nós nunca enviamos”, comece pelas checagens de assinatura. Se a verificação falha, provavelmente há um segredo diferente ou você está fazendo hash dos bytes errados (por exemplo, JSON parseado em vez do corpo bruto). Se passar, você pode confiar na identidade do remetente e seguir para dedup, ordenação e retries.
Passo a passo: verificar uma assinatura de webhook
O manejo confiável de webhooks começa com uma regra chata: verifique o que você recebeu, não o que você gostaria de ter recebido.
A maneira segura de verificar
Capture o corpo bruto da requisição exatamente como chegou. Não parseie e re-serialize o JSON antes de checar a assinatura. Pequenas diferenças (whitespace, ordem de chaves, unicode) mudam os bytes e podem fazer assinaturas válidas parecerem inválidas.
Então construa o payload exato que seu provedor espera que você assine. Muitos sistemas assinam uma string como timestamp + "." + raw_body. O timestamp não é decoração. Ele existe para que você possa rejeitar requisições antigas.
Calcule o HMAC usando o segredo compartilhado e o hash requerido (frequentemente SHA-256). Mantenha o segredo em um cofre seguro e trate-o como uma senha.
Por fim, compare seu valor computado com o header de assinatura usando uma comparação em tempo constante. Se não bater, retorne um 4xx e pare. Não “aceite mesmo assim”.
Uma checklist rápida de implementação:
- Leia o corpo como bytes uma vez, armazene e use esses mesmos bytes para verificação.
- Recrie a string assinada exatamente, incluindo separadores e formatação de timestamp.
- Calcule HMAC com o segredo e algoritmo corretos.
- Compare assinaturas de forma segura e rejeite divergências.
- Logue por que a verificação falhou (header ausente, timestamp ruim, mismatch) sem logar o segredo ou a assinatura completa.
Um exemplo rápido
Um cliente reporta “webhooks pararam de funcionar” depois que você adicionou middleware de parsing JSON. Você vê mismatches de assinatura, especialmente em payloads maiores. A correção normalmente é verificar usando o corpo bruto antes de qualquer parsing e logar qual passo falhou (por exemplo, “header de assinatura ausente” vs “timestamp fora da janela permitida”). Esse detalhe costuma reduzir o tempo de debug de horas para minutos.
Chaves de idempotência: aceitar uma vez, com segurança
Provedores reexecutam porque a entrega não é garantida. Seu servidor pode ficar indisponível por um minuto, um salto de rede pode perder a requisição, ou seu handler pode timeoutar. O provedor assume “talvez funcionou” e manda o mesmo evento de novo.
Uma chave de idempotência é o número de recibo que você usa para reconhecer um evento que já processou. Não é um recurso de segurança e não substitui verificação de assinatura. Também não resolve condições de corrida a menos que você a grave e verifique em segurança sob concorrência.
Escolher a chave depende do que o provedor fornece. Prefira um valor que permaneça estável entre retries:
- Event ID (melhor quando um evento mapeia para uma única mudança de negócio)
- Delivery ID ou message ID (melhor quando retries mantêm o mesmo identificador de entrega)
- Um hash de campos estáveis (último recurso se nenhum ID existir)
Quando receber um webhook, grave a chave no armazenamento primeiro usando uma regra de unicidade para que só uma requisição “vença”. Depois processe o evento. Se ver a mesma chave outra vez, retorne sucesso sem repetir o trabalho.
Mantenha seu “recibo” armazenado pequeno mas útil: a chave, status de processamento (recebido/processado/falhou), timestamps (primeira vez visto/última vez visto) e um resumo mínimo (tipo de evento e ID do objeto relacionado). Muitos times retêm chaves por 7 a 30 dias para cobrir retries tardios e a maioria das reclamações de clientes.
Proteção contra replay sem bloquear tráfego real
Proteção contra replay evita um problema simples e desagradável: alguém captura uma requisição webhook real (com assinatura válida) e a envia novamente mais tarde. Se seu handler tratar cada entrega como nova, esse replay pode causar reembolsos duplicados, convites de usuário repetidos ou mudanças de status repetidas.
Uma abordagem comum é assinar não só o payload, mas também um timestamp. Seu webhook inclui headers como X-Signature e X-Timestamp. Ao receber, verifique a assinatura e também se o timestamp está fresco dentro de uma janela curta.
Clock drift é o que normalmente causa rejeições falsas. Seus servidores e os servidores do remetente podem discordar por um minuto ou dois, e redes podem atrasar entrega. Mantenha uma margem e logue por que você rejeitou uma requisição.
Regras práticas que funcionam bem:
- Aceite somente se
abs(now - timestamp) <= window(por exemplo, 5 minutos mais uma pequena folga). - Conte com idempotência como a rede de segurança real. Mesmo dentro da janela, retries não devem duplicar efeitos.
- Se rejeitar por tempo, retorne um 4xx claro e registre o timestamp recebido e o horário do seu servidor.
Se timestamps estiverem ausentes, você não pode fazer proteção contra replay baseada apenas no tempo. Nesse caso, apoie-se mais em idempotência (armazene e rejeite IDs de evento duplicados) e considere exigir timestamps na próxima versão do webhook.
Rotação de segredos também importa. Se você rotacionar segredos de assinatura, mantenha múltiplos segredos ativos por um curto período de sobreposição. Verifique contra o segredo mais novo primeiro e depois caia para os antigos. Isso evita quebra para clientes durante a implantação. Se sua equipe publica endpoints rapidamente (por exemplo, gerando código com Koder.ai e usando snapshots e rollback durante deploys), essa janela de sobreposição ajuda porque versões antigas podem ficar ativas por pouco tempo.
Projete o handler para que retries não te prejudiquem
Retries são normais. Assuma que cada entrega pode ser duplicada, atrasada ou fora de ordem. Seu handler deve se comportar igual se vir um evento uma vez ou cinco vezes.
Mantenha o caminho de requisição curto. Faça apenas o que for necessário para aceitar o evento e mova trabalho pesado para um job em background.
Um padrão simples que funciona em produção:
- Valide o básico (método, content-type, headers obrigatórios).
- Verifique autenticidade (assinatura) e rejeite tudo que falhar.
- Parseie e valide o payload.
- Deduplique usando o event ID (ou chave de idempotência) numa tabela com constraint única.
- Enfileire trabalho com o event ID e então responda.
Retorne 2xx somente depois de verificar a assinatura e registrar o evento (ou enfileirá-lo). Se você responder 200 antes de salvar qualquer coisa, pode perder eventos durante um crash. Se fizer trabalho pesado antes de responder, timeouts disparam retries e você pode repetir efeitos colaterais.
Sistemas downstream lentos são a principal razão pela qual retries viram problema. Se seu provedor de email, CRM ou banco estiver lento, deixe uma fila absorver o atraso. O worker pode retryar com backoff, e você pode alertar sobre jobs travados sem bloquear o remetente.
Eventos fora de ordem também acontecem. Por exemplo, um subscription.updated pode chegar antes de subscription.created. Construa tolerância verificando estado atual antes de aplicar mudanças, permitindo upserts e tratando “não encontrado” como motivo para tentar novamente depois (quando fizer sentido) em vez de como falha permanente.
Erros comuns que causam bugs difíceis de rastrear
Muitos problemas “aleatórios” são auto-infligidos. Parecem redes instáveis, mas se repetem em padrões, geralmente após um deploy, rotação de segredo ou pequena mudança no parsing.
O bug de assinatura mais comum é fazer hash dos bytes errados. Se você parseia JSON primeiro, seu servidor pode reformatar (whitespace, ordem de chaves, formatação de números). Então você verifica a assinatura contra um corpo diferente do que o remetente assinou, e a verificação falha mesmo com payload genuíno. Sempre verifique contra os bytes brutos exatamente como recebidos.
A próxima grande fonte de confusão são secrets. Times testam em staging mas acidentalmente verificam com o segredo de produção, ou mantêm um segredo antigo depois da rotação. Quando um cliente reporta falhas “só em um ambiente”, assuma segredo errado ou config errada primeiro.
Alguns erros que levam a longas investigações:
- Logar o corpo completo para debugar e vazar tokens, emails ou dados de pagamento nos logs.
- Retornar 500 enquanto também realiza efeitos colaterais (enviar emails, atualizar pedidos). Retries repetirão esses efeitos.
- Usar uma chave de idempotência que não é verdadeiramente única (por exemplo, tipo de evento + minuto). Eventos reais são descartados como “duplicados”.
- Tratar 2xx como “processado” quando seu código apenas enfileirou o trabalho que depois falhou.
Exemplo: um cliente diz “order.paid nunca chegou”. Você vê falhas de assinatura começando após um refactor que trocou o middleware de parsing da requisição. O middleware lê e re-encoda o JSON, então sua checagem de assinatura agora usa um corpo modificado. A correção é simples, mas só se você souber procurar por isso.
Depure falhas relatadas por clientes rapidamente
Quando um cliente diz “seu webhook não foi acionado”, trate como um problema de rastreio, não de adivinhação. Aperte em uma tentativa exata de entrega do provedor e siga-a pelo seu sistema.
Comece pegando o identificador de entrega do provedor, request ID ou event ID da tentativa que falhou. Com esse único valor você deve conseguir encontrar a entrada de log correspondente rapidamente.
A partir daí, cheque três coisas em ordem:
- A verificação de assinatura passou?
- O timestamp ou verificação de replay passou (se você usar)?
- A idempotência tratou como novo ou como duplicado?
Confirme então o que você retornou ao provedor. Um 200 lento pode ser tão ruim quanto um 500 se o provedor timeoutar e reexecutar. Veja código de status, tempo de resposta e se seu handler reconheceu antes de fazer trabalho pesado.
Se precisar reproduzir, faça com segurança: armazene uma amostra bruta redigida (headers-chave mais corpo bruto) e reproduza em um ambiente de teste usando o mesmo segredo e código de verificação.
Checklist rápido que você pode rodar em 10 minutos
Quando uma integração de webhook começa a falhar “aleatoriamente”, velocidade importa mais que perfeição. Este runbook pega as causas usuais.
Pegue um exemplo concreto primeiro: nome do provedor, tipo de evento, timestamp aproximado (com timezone) e qualquer event ID que o cliente possa ver.
Depois verifique:
- A verificação de assinatura usa os bytes brutos do corpo (antes do parsing JSON) e o segredo correto para aquele ambiente.
- As checagens de replay fazem sentido para comportamento real de retry (e o relógio do seu servidor está sadio).
- A idempotência realmente deduplica (constraint única, gravada antes do processamento, retenção sensata).
- Seu handler reconhece apenas depois da validação e gravação/enfileiramento durável.
- Logs incluem um recibo mínimo pesquisável: provider, event_id, signature_ok, replay_ok, idempotency_status, response_code, latency_ms.
Se o provedor diz “reexecutamos 20 vezes”, cheque padrões comuns primeiro: segredo errado (signature falha), clock drift (janela de replay), limites de tamanho de payload (413), timeouts (sem resposta) e picos de 5xx de dependências downstream.
Exemplo: traçando um relato de “evento faltando” de ponta a ponta
Um cliente escreve: “Perdemos um evento invoice.paid ontem. Nosso sistema nunca atualizou.” Aqui está uma forma rápida de traçar.
Primeiro, confirme se o provedor tentou a entrega. Pegue o event ID, timestamp, URL de destino e o código exato de resposta que seu endpoint retornou. Se houve retries, note a causa da primeira falha e se um retry posterior teve sucesso.
Em seguida, valide o que seu código viu na borda: confirme o segredo de assinatura configurado para aquele endpoint, recompute a verificação de assinatura usando o corpo bruto e cheque o timestamp da requisição contra sua janela permitida.
Cuidado com janelas de replay durante retries. Se sua janela é de 5 minutos e o provedor reexecuta 30 minutos depois, você pode rejeitar um retry legítimo. Se essa é sua política, documente; se não, aumente a janela ou mude a lógica para que a idempotência seja a defesa principal contra duplicações.
Se assinatura e timestamp estiverem ok, siga o event ID pelo seu sistema e responda: você processou, deduplicou ou descartou?
Desfechos comuns:
- Deduplicado: a chave de idempotência já existe, então você retornou 200 sem re-executar lógica de negócio.
- Rejeitado: validação falhou (signature mismatch, timestamp velho, headers ausentes).
- Timeout: o handler demorou demais, o provedor marcou como falha e reexecutou.
Ao responder ao cliente, seja objetivo e específico: “Recebemos tentativas de entrega às 10:03 e 10:33 UTC. A primeira timeoutou após 10s; o retry foi rejeitado porque o timestamp estava fora da nossa janela de 5 minutos. Aumentamos a janela e adicionamos reconhecimento mais rápido. Por favor reenvie o event ID X se necessário.”
Próximos passos: torne isso repetível
A maneira mais rápida de parar incêndios com webhooks é fazer cada integração seguir o mesmo roteiro. Escreva o contrato que você e o remetente concordam: headers obrigatórios, método exato de assinatura, qual timestamp usar e quais IDs você trata como únicos.
Depois padronize o que vocês gravam para cada tentativa de entrega. Um pequeno log de recibo costuma ser suficiente: received_at, event_id, delivery_id, signature_valid, idempotency_result (novo/duplicado), handler_version e status de resposta.
Um fluxo que se mantém útil conforme você cresce:
- Mantenha um endpoint de teste dedicado que valide assinaturas e retorne 2xx sem executar ações de negócio.
- Armazene o corpo bruto da requisição e headers-chave por um curto período, apenas tempo suficiente para debugar e reproduzir.
- Construa um job de reprocessamento seguro para replay que reexecute eventos armazenados pelo mesmo caminho de handler.
- Tenha um checklist interno que suporte, QA e engenharia sigam.
Se você constrói apps com Koder.ai (koder.ai), o Planning Mode é uma maneira útil de definir o contrato do webhook primeiro (headers, assinatura, IDs, retry behavior) e depois gerar um endpoint consistente e um registro de recibo entre projetos. Essa consistência é o que torna a depuração rápida em vez de heróica.
Perguntas frequentes
Why do webhooks seem to “randomly” fail or duplicate in production?
Porque a entrega de webhooks costuma ser at-least-once, não exatamente uma vez. Os provedores reexecutam em timeouts, respostas 5xx e às vezes quando não veem seu 2xx a tempo, então você pode ter duplicações, atrasos e entregas fora de ordem mesmo quando tudo parece “funcionar”.
What’s the safest basic flow for handling a webhook request?
Siga esta regra: verifique a assinatura primeiro, depois grave/deduplique o evento, responda 2xx, e então faça o trabalho pesado assincronamente.
Se você fizer trabalho pesado antes de responder, baterá em timeouts e acionará retries; se responder antes de gravar qualquer coisa, pode perder eventos em crashes.
How do I avoid signature mismatches when verifying webhooks?
Use os bytes brutos do corpo da requisição exatamente como chegaram. Não parseie JSON e re-serialize antes da verificação—espaços, ordem de chaves e formatação de números podem quebrar assinaturas.
Também verifique que você está recriando exatamente o payload que o provedor assina (frequentemente timestamp + "." + raw_body).
What should my endpoint do when signature verification fails?
Retorne um 4xx (comum 400 ou 401) e não processe o payload.
Registre um motivo mínimo (header de assinatura ausente, mismatch, janela de timestamp inválida), mas não registre segredos nem payloads sensíveis completos.
What is an idempotency key for webhooks, and which value should I use?
Uma chave de idempotência é um identificador estável e único que você armazena para que retries não reapliquem efeitos colaterais.
Melhores opções:
- Event ID (ideal quando um evento corresponde a uma mudança de negócio)
- Delivery/message ID (se permanecer constante entre retries)
- Hash de campos estáveis (último recurso)
Imponha com uma constraint de unicidade para que apenas uma requisição “vença” sob concorrência.
How do I dedupe webhooks without race conditions?
Grave a chave de idempotência antes de fazer efeitos colaterais, com uma regra de unicidade. Depois:
- Marque como processada após sucesso, ou
- Registre status de falha para que possa reprocessar com segurança
Se o insert falhar porque a chave já existe, retorne 2xx e pule a ação de negócio.
How do I add replay protection without rejecting legitimate retries?
Inclua um timestamp nos dados assinados e rejeite requisições fora de uma janela curta (por exemplo, alguns minutos).
Para não bloquear retries legítimos:
- Permita algum clock drift
- Registre seu horário e o timestamp recebido em rejeições
- Trate idempotência como a defesa principal contra duplicações; a janela de tempo serve principalmente para evitar replays tardios
How should I handle out-of-order webhook events?
Não presuma que a ordem de entrega seja a ordem dos eventos. Faça handlers tolerantes:
- Use upserts quando possível
- Verifique o estado atual antes de aplicar mudanças
- Se um objeto não for encontrado, considere tentar novamente depois (via fila) em vez de falhar permanentemente
Armazene o event ID e o tipo para poder raciocinar sobre o que aconteceu mesmo com ordem estranha.
What should I log so webhook debugging doesn’t turn into guessing?
Registre um pequeno “recibo” por tentativa de entrega para rastrear um evento de ponta a ponta:
- provider, event_id, delivery_id
- signature_ok, replay_ok
- resultado de idempotência (novo/duplicado)
- response_code, latency_ms
- timestamps (received/first_seen/last_seen)
Mantenha logs pesquisáveis por event ID para que o suporte responda rapidamente aos clientes.
What’s a fast way to investigate a customer report that “a webhook never arrived”?
Peça um identificador concreto: event ID ou delivery ID, mais um timestamp aproximado.
Depois verifique nesta ordem:
- Resultado da verificação de assinatura
- Resultado da janela de timestamp/replay (se usada)
- Resultado de idempotência (novo vs duplicado)
- O que vocês retornaram (código de status + latência)
Se você usa Koder.ai, mantenha o padrão do handler consistente (verificar → gravar/dedupe → enfileirar → responder). A consistência torna essas checagens rápidas em incidentes.