Что такое JOIN в SQL и зачем они нужны
SQL JOIN позволяет объединять строки из двух (или более) таблиц в один результат, сопоставляя их по связанному столбцу — обычно идентификатору (ID).
Почему JOIN важны
Большинство реальных баз данных намеренно разделены на отдельные таблицы, чтобы не дублировать информацию. Например, имя клиента хранится в таблице customers, а его покупки — в таблице orders. JOIN — это способ снова соединить эти части, когда вам нужны ответы.
Именно поэтому JOIN встречаются повсюду в отчётности и аналитике:
- Построение отчёта по продажам с именами клиентов, суммами заказов и статусом оплаты
- Поиск клиентов, которые ещё ничего не заказывали
- Аудит несоответствий, например, заказов без оплат
- Создание сводки «по одному ряду на клиента» из множества связанных строк
Без JOIN вы бы делали отдельные запросы и вручную объединяли результаты — это медленно, подвержено ошибкам и трудно воспроизводимо.
Если вы строите продукты поверх реляционной базы данных (дашборды, админки, внутренние инструменты, клиентские порталы), JOIN также превращают «сырые таблицы» в пользовательские представления. Платформы вроде Koder.ai (которая генерирует React + Go + PostgreSQL‑приложения из чата) по‑прежнему опираются на корректные JOIN, когда нужны точные списки, отчёты и экраны сверки — логика базы не исчезает, даже если разработка ускоряется.
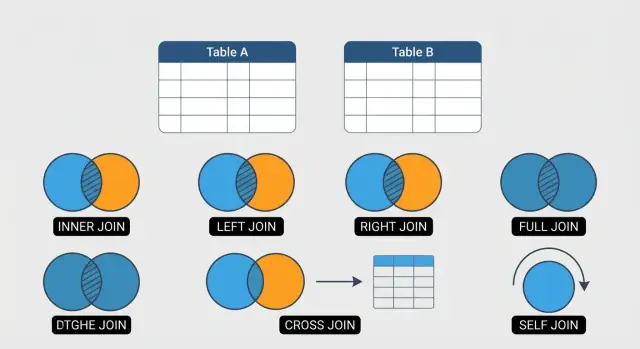
Шесть типов JOIN, которые вы будете использовать чаще всего
В этом руководстве мы сфокусируемся на шести JOIN, покрывающих большинство повседневных задач:
- INNER JOIN: возвращает только строки, которые совпадают в обеих таблицах (подходит для «покажи подтверждённые связи»).
- LEFT JOIN: сохраняет все строки из левой таблицы и при возможности добавляет данные из правой (подходит для «включать отсутствующие связанные данные»).
- RIGHT JOIN: зеркальное отражение LEFT JOIN (реже используется, но может быть удобен для читаемости).
- FULL OUTER JOIN: сохраняет все строки из обеих таблиц, объединяя их там, где возможно (отлично для сверок и поиска разрывов).
- CROSS JOIN: порождает все комбинации строк (полезно для генерации календарей, сценариев или тестовых данных — но его легко неправильно применить).
- SELF JOIN: соединяет таблицу саму с собой (удобно для иерархий, например, сотрудники/менеджеры).
Небольшая заметка по синтаксису
Синтаксис JOIN схож в большинстве СУБД (PostgreSQL, MySQL, SQL Server, SQLite). Есть небольшие отличия — особенно по FULL OUTER JOIN и некоторым краевым случаям — но концепции и основные шаблоны переносятся легко.
Примерные таблицы (customers, orders, payments)
Чтобы примеры были проще, мы используем три небольшие таблицы, которые отражают распространённую реальную схему: клиенты создают заказы, а заказы могут (или не могут) иметь оплаты.
Небольшая примечание: в примерах таблиц ниже показано лишь несколько столбцов, но в некоторых запросах далее используются дополнительные поля (например, order_date, created_at, status или paid_at) для демонстрации распространённых шаблонов. Считайте эти столбцы «типичными» для боевых схем.
1) customers
Primary key: customer_id
| customer_id | name |
|---|
| 1 | Ava |
| 2 | Ben |
| 3 | Chen |
| 4 | Dia |
2) orders
Primary key: order_id
Foreign key: customer_id → customers.customer_id
| order_id | customer_id | order_total |
|---|
| 101 | 1 | 50 |
| 102 | 1 | 120 |
| 103 | 2 | 35 |
| 104 | 5 | 70 |
Обратите внимание: order_id = 104 ссылается на customer_id = 5, которого нет в customers. Такое «отсутствующее совпадение» полезно для демонстрации поведения LEFT JOIN, RIGHT JOIN и FULL OUTER JOIN.
3) payments
Primary key: payment_id
Foreign key: order_id → orders.order_id
| payment_id | order_id | amount |
|---|
| 9001 | 101 | 50 |
| 9002 | 102 | 60 |
| 9003 | 102 | 60 |
| 9004 | 999 | 25 |
Два важных учебных момента:
order_id = 102 имеет две строки оплаты (разделённая оплата). При соединении orders с payments этот заказ появится дважды — отсюда часто возникают неожиданные дубликаты.payment_id = 9004 ссылается на order_id = 999, которого нет в orders. Это ещё один «несопадающий» случай.
Чего ожидать при JOIN этих таблиц
- Совпадающие строки: например, клиент 1 ↔ заказы 101/102; заказ 101 ↔ платёж 9001.
- Несопадающие строки: например, клиенты 3 и 4 не имеют заказов; заказ 104 не имеет клиента; платёж 9004 не имеет заказа.
- Дубликаты: при соединении
orders и payments заказ 102 повторится из‑за двух связанных оплат.
INNER JOIN: только совпадающие строки
INNER JOIN возвращает только те строки, где есть совпадение в обеих таблицах. Если у клиента нет заказов, он не попадёт в результат. Если заказ ссылается на несуществующего клиента (битые данные), такой заказ тоже не появится.
Базовый шаблон
Вы выбираете «левую» таблицу, присоединяете «правую» и связываете их условием в ON.
SELECT
c.customer_id,
c.name,
o.order_id,
o.order_date
FROM customers c
INNER JOIN orders o
ON o.customer_id = c.customer_id;
Ключевая строчка — ON o.customer_id = c.customer_id: она говорит базе, как совпадают строки.
Реальный кейс: клиенты, которые сделали заказы
Если нужен список только тех клиентов, которые сделали хотя бы один заказ (и детали заказа), INNER JOIN — естественный выбор:
SELECT
c.name,
o.order_id,
o.total_amount
FROM customers c
INNER JOIN orders o
ON o.customer_id = c.customer_id
ORDER BY o.order_id;
Это полезно для рассылки по заказам или подсчёта выручки по клиентам (когда важны только клиенты с покупками).
Частая ошибка: отсутствие или неправильное условие соединения
Если вы пишете join, но забываете ON (или соединяете по неверным столбцам), можно случайно получить декартово произведение (каждый клиент с каждым заказом) или неверные совпадения.
Плохо (не делайте так):
SELECT c.name, o.order_id
FROM customers c
JOIN orders o;
Всегда указывайте явное условие в ON (или USING в тех случаях, когда это применимо — о нём ниже).
LEFT JOIN: сохранить всё из левой таблицы
LEFT JOIN возвращает все строки из левой таблицы, добавляя совпадающую информацию из правой, когда совпадение есть. Если совпадения нет, столбцы правой таблицы будут NULL.
Когда использовать
Применяйте LEFT JOIN, когда вам нужен полный список из основной таблицы и опциональные связанные данные.
Пример: «Покажи всех клиентов, и включи их заказы, если они есть.»
SELECT
c.customer_id,
c.name,
o.order_id,
o.order_date
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
ORDER BY c.customer_id;
- Клиенты с заказами появятся с деталями заказа.
- Клиенты без заказов всё равно появятся, но
o.order_id (и другие поля orders) будут NULL.
Поиск «без совпадений» (классический шаблон)
Частая причина использовать LEFT JOIN — найти элементы, у которых нет связанных записей.
Пример: «Какие клиенты никогда не делали заказ?»
SELECT
c.customer_id,
c.name
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
WHERE o.order_id IS NULL;
Условие WHERE ... IS NULL оставляет только те строки левой таблицы, для которых не нашлось совпадения.
Осторожно: множественные совпадения умножают строки
LEFT JOIN может «дублировать» строки левой таблицы, если справа есть несколько совпадений.
Если у одного клиента 3 заказа, этот клиент появится 3 раза — по одному на каждый заказ. Это ожидаемое поведение, но может удивить, если вы пытаетесь посчитать клиентов.
Например, такой запрос считает строки (а не уникальных клиентов):
SELECT COUNT(*)
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id;
Если нужно считать клиентов, обычно считают ключ клиента (например, COUNT(DISTINCT c.customer_id)), в зависимости от метрики.
RIGHT JOIN: сохранить всё из правой таблицы
RIGHT JOIN сохраняет все строки из правой таблицы и только совпадающие строки из левой. Если совпадения нет, столбцы левой таблицы будут NULL. По сути — это зеркало LEFT JOIN.
Простой пример
Представьте, что вы хотите перечислить все платежи, даже если их нельзя связать с заказом (возможно, заказ удалили или данные о платеже грязные).
SELECT
o.order_id,
o.customer_id,
p.payment_id,
p.amount,
p.paid_at
FROM orders o
RIGHT JOIN payments p
ON o.order_id = p.order_id;
Что вы получите:
- Все платежи будут включены (потому что
payments справа).
- Если платёж не имеет соответствующего заказа,
o.order_id и o.customer_id будут NULL.
Тот же результат через LEFT JOIN (часто предпочтительней)
Чаще всего RIGHT JOIN можно переписать как LEFT JOIN, поменяв порядок таблиц:
SELECT
o.order_id,
o.customer_id,
p.payment_id,
p.amount,
p.paid_at
FROM payments p
LEFT JOIN orders o
ON o.order_id = p.order_id;
Это даёт тот же результат, но многим удобнее читать: сначала основная таблица (payments), затем опциональные данные.
Читаемость: почему многие избегают RIGHT JOIN
Многие SQL‑гайдлайны не рекомендуют RIGHT JOIN, так как он заставляет читателя мысленно «переворачивать» привычный порядок:
- «Начинаем с главной таблицы»
- «LEFT JOIN — добавляем дополнительные таблицы»
Когда опциональные связи консистентно записаны как LEFT JOIN, запросы легче просматривать.
Когда RIGHT JOIN всё же удобен
RIGHT JOIN может быть полезен при правке длинного запроса, где «главная» таблица уже стоит справа. Вместо переписывания всего запроса один JOIN можно быстро сменить на RIGHT JOIN.
FULL OUTER JOIN: сохранить все строки из обеих таблиц
Принесите навыки JOIN в команду
Переносите быстрый прототип в совместное рабочее пространство по мере роста проекта.
FULL OUTER JOIN возвращает все строки из обеих таблиц.
- Если строка совпадает по ключу, вы получаете одну комбинированную строку (как
INNER JOIN).
- Если строка есть только в левой таблице, она всё равно появится — с
NULL в колонках правой таблицы.
- Если строка есть только в правой таблице, она тоже появится — с
NULL в колонках левой таблицы.
Когда полезен
Классический кейс — сверка заказов и платежей:
- хотим увидеть оплаченные заказы (совпадения)
- неоплаченные заказы (есть заказ, нет оплаты)
- «сиротские» платежи (есть платёж, но нет заказа — ошибка данных)
Пример:
SELECT
o.order_id,
o.customer_id,
p.payment_id,
p.amount
FROM orders o
FULL OUTER JOIN payments p
ON p.order_id = o.order_id;
Поддержка в базах данных
FULL OUTER JOIN поддерживается в PostgreSQL, SQL Server и Oracle.
Он не доступен в MySQL и SQLite (там нужны обходные пути).
Портативная альтернатива: UNION LEFT JOIN + RIGHT JOIN
Если СУБД не поддерживает FULL OUTER JOIN, его можно симулировать, объединив:
- все строки из
orders (с совпадениями платежей, если есть), и
- все строки из
payments, которые не совпали с заказом.
Один из шаблонов:
SELECT o.order_id, o.customer_id, p.payment_id, p.amount
FROM orders o
LEFT JOIN payments p
ON p.order_id = o.order_id
UNION
SELECT o.order_id, o.customer_id, p.payment_id, p.amount
FROM orders o
RIGHT JOIN payments p
ON p.order_id = o.order_id;
Подсказка: когда вы видите NULL с одной стороны, это сигнал, что запись отсутствовала в другой таблице — как раз то, что нужно для аудитов и сверок.
CROSS JOIN: все комбинации (используйте с осторожностью)
CROSS JOIN возвращает все возможные пары строк из двух таблиц. Если в таблице A 3 строки, а в таблице B 4 строки, результат будет иметь 3 × 4 = 12 строк. Это же декартово произведение.
Это звучит пугающе — и действительно может быть опасным — но полезно, когда вам действительно нужны комбинации.
Небольшой безопасный пример: размеры × цвета (создание SKU)
Допустим, опции продукта хранятся в отдельных таблицах:
sizes: S, M, Lcolors: Red, Blue
CROSS JOIN может сгенерировать все варианты (удобно для создания SKU, предзаполнения каталога или тестирования):
SELECT
s.size,
c.color
FROM sizes AS s
CROSS JOIN colors AS c;
Результат (3 × 2 = 6 строк):
- S / Red
- S / Blue
- M / Red
- M / Blue
- L / Red
- L / Blue
Главное предупреждение: результат быстро растёт
Поскольку количество строк умножается, CROSS JOIN может быстро «взорваться»: 10 000 клиентов × 50 продуктов = 500 000 строк. 100 000 × 100 000 = 10 000 000 000 строк.
Это может замедлить запрос, перегрузить память и дать бесполезный объём данных. Если нужны комбинации, держите входные таблицы малыми и добавляйте ограничения.
SELF JOIN: таблица, соединённая сама с собой
Практикуйте JOIN-запросы в приложении
Создайте приложение на базе PostgreSQL и примените логику JOIN в реальном интерфейсе.
SELF JOIN — это соединение таблицы с самой собой. Это полезно, когда одна строка таблицы ссылается на другую строку той же таблицы — чаще всего для иерархий (сотрудники и их менеджеры).
Почему нужны псевдонимы и как они помогают
Поскольку вы используете одну и ту же таблицу дважды, нужно дать каждой «копии» своё имя‑псевдоним. Псевдонимы делают запрос читаемым и указывают SQL, к какой «стороне» вы обращаетесь.
Обычно используют:
e для сотрудника (employee)m для менеджера (manager)
Практический пример: сотрудники и их менеджеры
Предположим, есть таблица employees со столбцами:
idnamemanager_id (ссылается на id другого сотрудника)
Чтобы вывести сотрудника вместе с именем его менеджера:
SELECT
e.id,
e.name AS employee_name,
m.name AS manager_name
FROM employees e
LEFT JOIN employees m
ON e.manager_id = m.id;
Обработка топ‑уровневых сотрудников (NULL в manager_id)
Обратите внимание: в примере используется LEFT JOIN, а не INNER JOIN. Это важно, потому что у некоторых сотрудников может не быть менеджера (например, CEO). В таких случаях manager_id часто равен NULL, и LEFT JOIN сохранит строку сотрудника, а manager_name будет NULL.
Если применить INNER JOIN, топ‑уровневые сотрудники исчезнут из результата, так как для них нет совпадающей строки менеджера.
Условия соединения: ON vs USING (и почему это важно)
JOIN не «угадывает», как связаны таблицы — вы должны явно указать. Условие соединения описывает, как строки соответствуют друг другу, и его обычно помещают сразу после JOIN, потому что это объясняет, как таблицы связаны, а не как вы хотите отфильтровать итог.
ON: самое гибкое и распространённое
Используйте ON, когда вам нужен полный контроль над логикой соответствия — разные имена столбцов, несколько условий или дополнительные правила.
SELECT
c.customer_id,
c.name,
o.order_id,
o.created_at
FROM customers AS c
INNER JOIN orders AS o
ON o.customer_id = c.customer_id;
ON также позволяет задать более сложные условия (например, соответствие по двум столбцам) без неоднозначности.
USING: сокращение, но только для одноимённых столбцов
Некоторые СУБД (PostgreSQL, MySQL) поддерживают USING. Это удобный синтаксис, когда оба таблицы имеют столбец с одинаковым именем и вы хотите соединить по нему.
SELECT
customer_id,
name,
order_id
FROM customers
JOIN orders
USING (customer_id);
Одно преимущество: USING обычно возвращает только один столбец customer_id в выводе (вместо двух копий).
Избегайте неоднозначных имён столбцов: всегда квалифицируйте
После соединения столбцы часто повторяются (id, created_at, status). Если вы напишете SELECT id, СУБД может вернуть ошибку «ambiguous column» — или, что ещё хуже, вы случайно получите не тот id.
Предпочитайте префиксы таблиц (или псевдонимы) для ясности:
SELECT c.customer_id, o.order_id
FROM customers AS c
JOIN orders AS o
ON o.customer_id = c.customer_id;
Не используйте SELECT * в соединённых запросах
SELECT * быстро превращается в хаос при JOIN: вы подтягиваете ненужные столбцы, рискуете дубликатами имён и усложняете понимание результата. Лучше явно перечислять нужные столбцы — результат чище, поддерживать его проще, и часто это эффективнее при передаче по сети.
Фильтрация при JOIN: WHERE vs ON
При JOIN и WHERE, и ON «фильтруют», но делают это в разное время:
- ON решает, какие строки совпадают при выполнении соединения.
- WHERE фильтрует итоговый набор после того, как соединение уже выполнено.
Эта разница по времени — причина, почему люди случайно превращают LEFT JOIN в INNER JOIN.
Как WHERE может испортить LEFT JOIN
Допустим, вы хотите получить всех клиентов, даже тех, у кого нет недавних оплаченных заказов.
SELECT c.customer_id, c.name, o.order_id, o.status, o.order_date
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
WHERE o.status = 'PAID'
AND o.order_date >= DATE '2025-01-01';
Проблема: для клиентов без заказов o.status и o.order_date равны NULL. Условие WHERE отфильтрует такие строки, и ваши клиенты без заказов исчезнут — LEFT JOIN превратится в INNER JOIN.
Перенесите условия в ON, чтобы сохранить несопадающие строки
SELECT c.customer_id, c.name, o.order_id, o.status, o.order_date
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
AND o.status = 'PAID'
AND o.order_date >= DATE '2025-01-01';
Теперь клиенты без подходящих заказов всё ещё будут показываться (с NULL в полях заказа), что обычно и требуется при LEFT JOIN.
Короткий чеклист: что куда помещать
- Условия в ON — когда они описывают, какие строки правой таблицы могут совпасть (фильтры по статусу/дате/типу на присоединяемой таблице).
- Условия в WHERE — когда они описывают, какие итоговые строки вы хотите оставить (фильтры по левой таблице или когда вы намеренно требуете совпадения).
- Если нужно «сохранить все левые строки, но ограничить правые» — используйте LEFT JOIN + условия в ON.
- Если вы действительно хотите только совпадающие строки, используйте INNER JOIN (или явную проверку
WHERE o.order_id IS NOT NULL).
Избежание дубликатов и сюрпризов «многие‑ко‑многим»
Быстро создайте панель администратора
Быстро создавайте CRUD-экраны на React, Go и PostgreSQL, затем уточняйте запросы.
JOINы не просто «добавляют столбцы» — они могут умножать строки. Это обычно корректно, но часто удивляет, когда суммы вдруг удваиваются.
Почему строки умножаются
JOIN возвращает одну выходную строку для каждой пары совпадающих строк.
- Один‑ко‑многим: у одного клиента может быть много заказов. При соединении
customers и orders клиент может появляться несколько раз.
- Многие‑ко‑многим: если вы соединяете
orders с payments (несколько платежей на заказ) и одновременно с order_items (несколько позиций в заказе), вы получите эффект умножения: payments × items на заказ.
Предагрегируйте перед соединением
Если цель — «одна строка на клиента» или «одна строка на заказ», сначала агрегируйте «множественную» сторону, а затем соединяйте.
(Пример с payment_totals есть выше.)
DISTINCT — крайняя мера
SELECT DISTINCT может выглядеть как решение, но оно скрывает причину:
- Может убрать легитимные строки.
- Скрывает плохое условие соединения.
- Портит правильные суммы и подсчёты.
Используйте DISTINCT только когда уверены, что дубликаты случайны и понимаете их источник.
Быстрая проверка: сверяйте счётчики
Перед тем как доверять результатам, сравните количество строк:
- Посчитайте строки в основной таблице (например, orders).
- Посчитайте строки после JOIN.
- Если количество неожиданно выросло, разберитесь, какие ключи дают множественные совпадения и нужно ли вам предагрегировать.
Базовые приёмы оптимизации и краткая шпаргалка
JOINы часто «винят» в медленных запросах, но реальная причина — объём работы и доступность индексов.
Индексы (концептуально) и почему они важны
Индекс — это как содержание в книге. Без него СУБД может перебрать много строк, чтобы найти совпадения для условия JOIN. Если на ключах соединения (customers.customer_id и orders.customer_id) есть индексы, СУБД может быстро перейти к нужным строкам.
Если столбец часто используется в ON, его стоит проиндексировать.
Соединяйте по стабильным ключам
По возможности используйте стабильные уникальные идентификаторы:
- Хорошо:
customers.customer_id = orders.customer_id
- Рискованно:
customers.email = orders.email или customers.name = orders.name
Имена меняются и могут повторяться, email может отличаться по регистру/формату. ID предназначены для корректного и стабильного совпадения и обычно индексированы.
Сокращайте объём работы как можно раньше
Две простые практики ускоряют JOIN:
- Выбирайте меньше столбцов. Избегайте
SELECT * при соединении — лишние столбцы увеличивают память и трафик.
- Ограничивайте строки до или во время JOIN. Фильтруйте ранние наборы.
Пример: сначала ограничьте заказы, затем соединяйте:
SELECT c.customer_id, c.name, o.order_id, o.created_at
FROM customers c
JOIN (
SELECT order_id, customer_id, created_at
FROM orders
WHERE created_at >= DATE '2025-01-01'
) o
ON o.customer_id = c.customer_id;
Если вы внедряете такие запросы в приложение (например, страницу отчёта в PostgreSQL), инструменты вроде Koder.ai помогут быстро сгенерировать каркас (схема, эндпоинты, UI), но вы по‑прежнему контролируете JOIN‑логику, от которой зависит корректность.
Быстрая шпаргалка по JOIN
- INNER JOIN → только строки, совпадающие в обеих таблицах
- LEFT JOIN → все строки из левой таблицы, плюс совпадения из правой (
NULL, если нет)
- RIGHT JOIN → все строки из правой таблицы, плюс совпадения из левой (
NULL, если нет)
- FULL OUTER JOIN → все строки из обеих таблиц; совпадения объединяются, несопадающие стороны показывают
NULL
- CROSS JOIN → каждая возможная комбинация строк (произведение; используйте осторожно)
- SELF JOIN → таблица, соединённая с собой (полезно для иерархий и сравнений)