26 авг. 2025 г.·8 мин
Как создавать AI-first продукты с моделями в логике приложения
Практическое руководство по созданию AI-first продуктов, где модель управляет решениями: архитектура, подсказки, инструменты, данные, оценка, безопасность и мониторинг.
Что значит создавать AI-first продукт
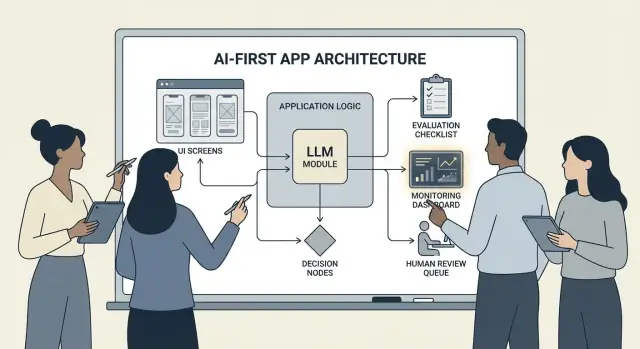
Создание AI-first продукта — это не просто «добавить чатбот». Это означает, что модель является реальной, работающей частью логики приложения — так же, как движок правил, индекс поиска или алгоритм рекомендаций.
Ваше приложение не просто использует ИИ; оно проектируется вокруг того факта, что модель будет интерпретировать ввод, выбирать действия и выдавать структурированные результаты, на которые опирается остальная система.
На практике: вместо жёсткой реализации каждого пути принятия решения («если X, то сделать Y») вы даёте модели обрабатывать нечеткие части — язык, намерение, неоднозначность, приоритезацию — а код отвечает за то, что должно быть точным: права доступа, платежи, записи в базу данных и соблюдение политик.
Когда AI-first подходит (и когда нет)
AI-first лучше работает, когда задача имеет:
- Множество допустимых вводов (свободный текст, неряшливые документы, разные цели пользователей)
- Слишком много крайних случаев, чтобы поддерживать правила вручную
- Ценность в суждении, суммировании или синтезе, а не в абсолютно детерминированном результате
Правила подходят чаще, когда требования стабильны и точны — расчёт налогов, логика складских запасов, проверки правомочности или регламентные рабочие процессы, где результат должен быть одинаковым каждый раз.
Общие цели продукта, которые поддерживает AI-first
Команды обычно применяют модель-управляемую логику, чтобы:
- Увеличить скорость: генерировать черновики ответов, извлекать поля, маршрутизировать запросы быстрее
- Персонализировать опыт: адаптировать объяснения, планы или рекомендации
- Поддерживать принятие решений: выделять компромиссы, генерировать варианты, суммировать доказательства
Компромиссы, к которым нужно быть готовым (и проектировать для них)
Модели могут быть непредсказуемыми, иногда уверенно ошибаться, а их поведение может измениться с изменением подсказок, провайдеров или контекста. Они также увеличивают затраты на запрос, могут добавить задержку и порождать проблемы с безопасностью и доверием (конфиденциальность, вредоносный контент, нарушение политик).
Правильный подход: модель — это компонент, а не волшебная коробка ответов. Относитесь к ней как к зависимости с требованиями, режимами отказа, тестами и мониторингом — так вы получите гибкость, не ставя продукт на шанс.
Выберите подходящий кейс и определите успех
Не каждая функция выигрывает от того, что модель управляет логикой. Лучшие AI-first кейсы начинаются с ясной задачи и заканчиваются измеримым результатом, который можно отслеживать неделю за неделей.
Начните с задачи, а не с модели
Запишите однострочную историю задачи: “Когда ___, я хочу ___, чтобы ___.” Затем сделайте результат измеримым.
Пример: «Когда я получаю длинное письмо от клиента, я хочу предложенный ответ, соответствующий нашим правилам, чтобы ответить за менее чем 2 минуты». Это намного практичнее, чем «добавить LLM к почте».
Сопоставьте точки принятия решений
Определите моменты, где модель будет выбирать действия. Эти точки принятия решений должны быть явными, чтобы их можно было тестировать.
Распространённые точки принятия решений:
- Классифицировать намерение и направить в нужный рабочий процесс
- Решить, задать уточняющий вопрос или продолжить
- Выбрать инструменты (поиск, CRM-запрос, черновик, создание тикета)
- Решить, когда эскалировать человеку
Если вы не можете назвать решения — вы не готовы выпускать логику, управляемую моделью.
Напишите критерии приёмки для поведения
Относитесь к поведению модели как к любому другому требованию продукта. Определите, что значит «хорошо» и «плохо» простыми словами.
Например:
- Хорошо: использует актуальную политику, ссылается на правильный ID заказа, задаёт один ясный вопрос при отсутствии данных
- Плохо: выдумывает скидки, ссылается на неподдерживаемые регионы или отвечает, не проверив необходимые данные
Эти критерии станут основой для вашего набора оценки позже.
Раннее определение ограничений
Перечислите ограничения, формирующие архитектурные решения:
- Время (цели по задержке ответа)
- Бюджет (стоимость на задачу)
- Соответствие (обработка ПДн, требования аудита)
- Поддерживаемые локали (языки, тон, культурные ожидания)
Определите метрики успеха для мониторинга
Выберите небольшой набор метрик, привязанных к задаче:
- Процент завершённых задач
- Точность (или соблюдение политики) на репрезентативных случаях
- CSAT или качественная оценка пользователей
- Сэкономленное время на задачу (или время до решения)
Если вы не можете измерить успех, вы будете спорить о впечатлениях вместо улучшения продукта.
Проектирование AI-ориентированного пользовательского потока и границ системы
AI-first поток — это не «экран, который вызывает LLM». Это сквозное путешествие, где модель принимает решения, продукт безопасно их выполняет, а пользователь остаётся ориентирован.
Нарисуйте сквозную петлю
Начните с простой цепочки: вводы → модель → действия → выводы.
- Вводы: что даёт пользователь (текст, файлы, выбор) плюс контекст приложения (уровень аккаунта, рабочее пространство, недавняя активность).
- Шаг модели: за что отвечает модель (классификация, черновик, суммирование, выбор следующего действия).
- Действия: что может сделать ваша система (поиск, создать задачу, обновить запись, отправить письмо).
- Выводы: что видит пользователь (черновик, объяснение, экран подтверждения, ошибка с дальнейшими шагами).
Эта карта проясняет, где допустима неопределённость (черновики) и где она недопустима (изменения в биллинге).
Проведите границу системы: модель vs детерминированный код
Отделяйте детерминированные пути (проверки прав, бизнес-правила, вычисления, записи в БД) от решений модели (интерпретация, приоритезация, генерация на естественном языке).
Полезное правило: модель может рекомендовать, но код должен проверять перед любыми необратимыми действиями.
Решите, где запускается модель
Выберите среду выполнения по ограничениям:
- Сервер: лучше для приватных данных, единообразных инструментов, логов аудита.
- Клиент: полезен для лёгкой помощи и приватной локальной обработки, но сложнее контролировать.
- Edge: быстрее глобальная задержка, но ограничения по зависимостям.
- Гибрид: быстрый детектор намерений на краю и тяжёлая работа на сервере.
Учитывайте бюджет по задержке, стоимости и правам на данные
Установите бюджет по задержке и стоимости на запрос (включая повторы и вызовы инструментов), затем спроектируйте UX вокруг него (потоковая выдача, прогрессивные результаты, «продолжить в фоне»).
Документируйте источники данных и права на каждом шаге: что модель может читать, что записывать и что требует явного подтверждения пользователя. Это становится контрактом для инженеров и доверия.
Паттерны архитектуры: оркестровка, состояние и трассировки
Когда модель — часть логики приложения, «архитектура» — это не только серверы и API, но и то, как вы надёжно выполняете цепочку модельных решений, не теряя контроля.
Оркестровка: дирижёр модельной работы
Оркестровка — слой, управляющий выполнением AI-задачи от начала до конца: подсказки и шаблоны, вызовы инструментов, память/контекст, повторы, таймауты и откаты.
Хорошие оркестраторы рассматривают модель как компонент пайплайна. Они решают, какую подсказку использовать, когда вызвать инструмент (поиск, база данных, email, платёж), как сжать или получить контекст и что делать, если модель вернула неверный результат.
Если вы хотите быстрее перейти от идеи к рабочей оркестровке, рабочий процесс vibe-coding поможет прототипировать такие пайплайны без полной перестройки скелета приложения. Например, Koder.ai позволяет командам создавать веб-приложения (React), бэкенды (Go + PostgreSQL) и даже мобильные приложения (Flutter) через чат — затем итеративно отлаживать потоки вроде «вводы → модель → вызовы инструментов → валидации → UI» с режимами планирования, снимками и откатом, плюс экспорт исходников, когда вы готовы владеть репозиторием.
Машины состояний для многошаговых задач
Многошаговые сценарии (триаж → сбор информации → подтверждение → выполнение → суммирование) лучше моделировать как workflow или машину состояний.
Простой паттерн: каждый шаг имеет (1) допустимые входы, (2) ожидаемые выходы и (3) переходы. Это предотвращает блуждание разговоров и делает крайние случаи явными — например, что происходит, если пользователь передумал или дал неполную информацию.
Одноразовое vs многошаговое рассуждение
Одноразовое (single-shot) хорошо для ограниченных задач: классифицировать сообщение, написать короткий ответ, извлечь поля из документа. Это дешевле, быстрее и проще валидировать.
Многошаговое рассуждение лучше, когда модель должна задавать уточняющие вопросы или когда инструменты нужны итеративно (например, план → поиск → уточнение → подтверждение). Используйте его целенаправленно и ограничивайте количество итераций/времени.
Идемпотентность: избегайте повторных побочных эффектов
Модели повторяют запросы. Сети падают. Пользователи кликают дважды. Если AI-шаг может вызвать побочный эффект — отправку письма, бронирование, списание — сделайте его идемпотентным.
Распространённые приёмы: прикреплять ключ идемпотентности к каждому «выполнить» действию, сохранять результат действия и гарантировать, что повторы возвращают тот же результат, а не повторяют операцию.
Трассировки: делайте каждый шаг дебажимым
Добавьте трассируемость, чтобы можно было ответить: Что увидела модель? Какое решение приняла? Какие инструменты работали?
Логируйте структурированную трассировку на запуск: версия подсказки, входы, идентификаторы извлечённого контекста, запросы/ответы инструментов, ошибки валидации, повторы и финальный вывод. Это превращает «ИИ сделал что-то странное» в аудируемую, исправимую временную шкалу.
Подсказки как логика продукта: чёткие контракты и форматы
Когда модель — часть логики приложения, ваши подсказки перестают быть «копирайтом» и становятся исполняемой спецификацией. Относитесь к ним как к требованиям продукта: явный объём, предсказуемые выходы и контроль изменений.
Начните с системной подсказки, задающей контракт
Ваша системная подсказка должна определять роль модели, что она может и не может делать, и правила безопасности, важные для продукта. Держите её стабильной и переиспользуемой.
Включите:
- Роль и цель: кто это (например, «ассистент триажа поддержки») и как выглядит успех.
- Границы: какие запросы нужно отклонять или эскалировать.
- Правила безопасности: обработка ПДн, медицинские/юридические отговорки, запрет на домыслы.
- Политику инструментов: когда вызывать инструменты, а когда отвечать напрямую.
Структурируйте подсказки с явными входами/выходами
Пишите подсказки как API: перечислите точные входы (текст пользователя, уровень аккаунта, локаль, фрагменты политики) и точные ожидаемые выходы. Добавьте 1–3 примера, соответствующих реальному трафику, включая сложные кейсы.
Полезный шаблон: Контекст → Задача → Ограничения → Формат вывода → Примеры.
Используйте ограниченные форматы для машинно-читаемых результатов
Если код должен действовать на выходе, не полагайтесь на проза. Запрашивайте JSON, соответствующий схеме, и отвергайте всё остальное.
{
\"type\": \"object\",\n \"properties\": {\n \"intent\": {\"type\": \"string\"},\n \"confidence\": {\"type\": \"number\", \"minimum\": 0, \"maximum\": 1},\n \"actions\": {\n \"type\": \"array\",\n \"items\": {\"type\": \"string\"}\n },\n \"user_message\": {\"type\": \"string\"}\n },\n \"required\": [\"intent\", \"confidence\", \"actions\", \"user_message\"],\n \"additionalProperties\": false\n}
Версионируйте подсказки и выкатывайте безопасно
Храните подсказки в контроле версий, помечайте релизы и выкатывайте как фичи: поэтапный релиз, A/B там, где нужно, и быстрый откат. Логируйте версию подсказки с каждым ответом для отладки.
Соберите набор тестов для подсказок
Создайте небольшой репрезентативный набор кейсов (happy path, неоднозначные запросы, нарушения политик, длинные вводы, разные локали). Запускайте их автоматически при каждом изменении подсказки и прерывайте сборку, если выходы ломают контракт.
Вызов инструментов: пусть модель решает, код выполняет
Сохраняйте полный контроль над кодом
Владейте репозиторием: экспортируйте исходный код из Koder.ai, когда будете готовы.
Вызов инструментов — это чистейший способ разделить ответственность: модель решает что надо сделать и какую возможность использовать, а ваш код выполняет действие и возвращает проверенные результаты.
Так вы держите факты, вычисления и побочные эффекты (создание тикетов, обновления записей, отправка писем) в детерминированном, проверяемом коде — не в свободном тексте.
Дизайн небольшого, целевого набора инструментов
Начните с набора инструментов, покрывающих 80% запросов и легко защищаемых:
- Поиск (документация/центр помощи) для ответов на вопросы о продукте
- Запрос в БД (сначала только чтение) для статуса пользователя/аккаунта/заказа
- Калькулятор для цен, сумм, конвертаций и правиловой арифметики
- Тикетинг для открытия обращения в поддержку, когда нужен человек
Держите назначение каждого инструмента узким. Инструмент «всё в одном» становится трудно тестируемым и легко используется неправильно.
Валидируйте входы, санитизируйте выходы
Относитесь к модели как к ненадёжному вызывающему.
- Валидируйте входы инструментов строгими схемами (типы, диапазоны, перечисления). Отвергайте или исправляйте опасные аргументы (например, отсутствующие ID, чересчур широкие запросы).
- Санитизируйте выходы инструментов перед тем, как вернуть их модели: удаляйте секреты, нормализуйте форматы и возвращайте только поля, которые модели действительно нужны.
Это уменьшает риск инъекций подсказок через извлечённый текст и ограничивает утечку данных.
Добавьте права и лимиты на каждый инструмент
Каждый инструмент должен обеспечивать:
- Проверки прав доступа (кто может смотреть какие записи, выполнять какие действия)
- Ограничения скорости (на пользователя/сессию/инструмент) чтобы снизить злоупотребления и бесконтрольные циклы
Если инструмент меняет состояние (тикеты, возвраты), требуйте усилённой авторизации и записывайте аудит.
Всегда поддерживайте путь «без инструментов»
Иногда лучше не выполнять действие: ответить из доступного контекста, задать уточняющий вопрос или объяснить ограничения. Сделайте «без инструментов» полноценным исходом, чтобы модель не вызывала инструменты просто ради видимости активности.
Данные и RAG: привяжите модель к вашей реальности
Если ответы продукта должны соответствовать вашим политикам, инвентарю, контрактам или внутренним знаниям, вы должны привязать модель к вашим данным — а не только к её общему обучению.
RAG vs дообучение vs простой контекст
- Простой контекст (вставка нескольких абзацев в подсказку) подходит, когда знание небольшое, стабильное и вы можете отправлять его каждый раз (например, короткая таблица цен).
- RAG (Retrieval-Augmented Generation) лучше, когда информация большая, часто меняется или требует ссылок (статьи справочного центра, документация продукта, данные по аккаунту).
- Дообучение (fine-tuning) полезно для согласованного стиля/формата или доменных паттернов — не как основной способ «хранить факты». Используйте его для улучшения тона и следования правилам; комбинируйте с RAG для актуальности.
Основы индексирования: деление на куски, метаданные, актуальность
Качество RAG в основном — проблема инжестирования.
Делите документы на фрагменты, подходящие для вашей модели (часто по несколько сотен токенов), желательнo выровненные по естественным границам (заголовки, записи FAQ). Храните метаданные: заголовок, секция, версия/продукт, аудитория, локаль и права доступа.
Планируйте свежесть: расписание переиндексации, отслеживание «последнее обновление» и протухание старых фрагментов. Устаревший фрагмент с высоким рангом тихо ухудшит весь функционал.
Цитирование и калиброванные ответы
Поручите модели ссылаться на источники, возвращая: (1) ответ, (2) список ID/URL фрагментов, и (3) заявление о степени уверенности.
Если поиск по источникам пустой или слабый, инструктируйте модель признать это и предложить следующие шаги («я не нашёл этой политики; вот к кому обратиться»). Избегайте заполнения пробелов домыслами.
Приватные данные: контроль доступа и редактирование
Применяйте доступ до извлечения (фильтруйте по правам пользователя/организации) и снова до генерации (редактируйте чувствительные поля).
Рассматривайте эмбеддинги и индексы как чувствительные хранилища с логами аудита.
Когда поиск не помог: плавные откаты
Если топ-результаты не релевантны или пусты, откатайтесь к: уточняющему вопросу, маршрутизации к человеку или переключению в режим без RAG, где модель объясняет ограничения вместо угадывания.
Надёжность: ограждения, валидация и кэширование
Когда модель встроена в логику приложения, «в основном хорошо» недостаточно. Надёжность — это когда пользователи видят предсказуемое поведение, система безопасно потребляет выходы, а ошибки деградируют плавно.
Определите цели надёжности (до исправлений)
Запишите, что для фичи означает «надёжно»:
- Постоянные выходы: похожие входы должны давать сопоставимые ответы (тон, уровень детализации)
- Стабильные форматы: ответ должен быть парсабелен каждый раз (JSON, список, поля)
- Ограниченное поведение: чёткие пределы (не догадываться, ссылаться на источники, задавать вопрос при неуверенности)
Эти цели становятся критериями приёмки для подсказок и кода.
Ограждения: валидация, фильтрация и принудительное соблюдение политик
Обращайтесь с выводом модели как с недоверенным вводом.
- Валидация схемы: требуйте строгого формата (например, JSON с обязательными ключами) и отвергайте всё, что не парсится.
- Фильтры контента: запускайте проверки на мат, детекторы ПДн или валидаторы политик на входах пользователя и выходах модели.
- Бизнес-правила: принуждайте ограничения в коде (диапазоны цен, правила правомочности, допустимые действия), даже если подсказка их упоминает.
Если валидация провалилась — возвращайте безопасный откат (задайте уточняющий вопрос, переключитесь на более простой шаблон или маршрутизируйте к человеку).
Повторы, которые действительно помогают
Избегайте слепых повторов. Повтор выполняйте с изменённой подсказкой, адресующей режим отказа:
- «Верните только валидный JSON. Никакого markdown.»
- «Если не уверен, установите
confidenceв low и задайте один вопрос.»
Ограничивайте число повторов и логируйте причины отказа.
Детерминированная постобработка
Используйте код для нормализации того, что модель выдаёт:
- канонизируйте единицы, даты и имена
- удаляйте дубликаты
- применяйте ранжирование или пороговые правила
Это снижает вариативность и упрощает тестирование.
Кэширование без угрозы приватности
Кэшируйте повторяющиеся результаты (идентичные запросы, общие эмбеддинги, ответы инструментов) для снижения затрат и задержки.
Предпочитайте:
- короткие TTL для пользовательских данных
- ключи кэша, исключающие сырые ПДн (или аккуратно хешированные)
- флаги «не кэшировать» для чувствительных сценариев
Правильно сделанное кэширование повышает согласованность и сохраняет доверие пользователя.
Безопасность и доверие: снижайте риски, не убивая UX
Быстро прототипируйте логику ИИ
Постройте рабочий процесс, ориентированный на ИИ, с чатом и безопасно итеративно улучшайте с помощью снимков и отката.
Безопасность — не отдельный слой комплаенса, который вы навешиваете в конце. В AI-first продуктах модель влияет на действия, формулировки и решения — поэтому безопасность должна быть частью продуктового контракта: что ассистент может делать, что обязан отказать и когда просить помощи.
Ключевые заботы о безопасности, которые нужно спроектировать
Назовите риски, с которыми реально столкнётся ваше приложение, и подберите контролы:
- Чувствительные данные: идентификаторы, креденшелы, приватные документы и всё регулируемое
- Опасные инструкции: указания, которые могут привести к самоповреждению, насилию, незаконной деятельности или опасным медицинским/финансовым шагам
- Смещение и несправедливые исходы: разное качество обслуживания или рекомендации для разных групп
Разрешённые/заблокированные темы + пути эскалации
Опишите явную политику, которую продукт может обеспечивать. Сделайте её конкретной: категории, примеры и ожидаемые ответы.
Используйте три уровня:
- Разрешено: отвечать как обычно.
- Ограничено: отвечать с оговорками (например, общая информация, без пошаговых инструкций).
- Блокировано: отказаться и направить на эскалацию (поддержка, ресурсы или человек).
Эскалация должна быть продуктовым потоком, а не просто сообщением об отказе. Предложите опцию «Поговорить с человеком» и убедитесь, что передача включает контекст, который пользователь уже предоставил (с согласием).
Человеческий обзор для действий с сильными последствиями
Если модель может вызвать реальные последствия — платежи, возвраты, изменения аккаунта, отмены, удаление данных — добавьте контрольную точку.
Хорошие паттерны: экраны подтверждения, «черновик → утвердить», лимиты (пороговые суммы) и очередь ручной проверки для крайних случаев.
Раскрытия, согласия и тестируемые политики
Сообщайте пользователям, когда они взаимодействуют с ИИ, какие данные используются и что сохраняется. Запрашивайте согласие там, где нужно, особенно для сохранения разговоров или использования данных для улучшения системы.
Обращайтесь с внутренними политиками безопасности как с кодом: версионируйте их, документируйте причины и добавляйте тесты (пример подсказок + ожидаемые исходы), чтобы безопасность не регрессировала с каждым изменением подсказок или модели.
Оценка: тестируйте модель как любой критический компонент
Если LLM может менять поведение продукта, нужно воспроизводимо доказывать, что он по‑прежнему работает — до того, как пользователи обнаружат регрессии.
Относитесь к подсказкам, версиям модели, схемам инструментов и настройкам поиска как к артефактам релиза, требующим тестирования.
Соберите набор оценок из реальности
Собирайте реальные намерения пользователей из тикетов поддержки, поисковых запросов, логов чатов (с согласием) и записей продаж. Превратите их в тестовые кейсы, включающие:
- Частые запросы (happy-path)
- Неоднозначные запросы, требующие уточнений
- Крайние случаи (нехватка данных, конфликтующие требования, необычные форматы)
- Сценарии, чувствительные к политике (персональные данные, запрещённый контент)
Каждый кейс должен включать ожидаемое поведение: ответ, принятое решение (например, «вызвать инструмент A») и любую требуемую структуру (поля JSON, обязательные ссылки и т.д.).
Выбирайте метрики, соответствующие риску продукта
Одна метрика не описывает качество. Используйте небольшой набор метрик, которые соответствуют исходам пользователей:
- Точность / успех задачи: достигнута ли цель пользователя?
- Основанность: подкреплены ли утверждения предоставленным контекстом или источниками?
- Валидность формата: соответствует ли вывод контракту (JSON, таблица, пункты)?
- Уровень отказов: отказывается ли модель, когда должна — и избегает отказов, когда можно ответить?
Отслеживайте также стоимость и задержку; «лучше» модель, удваивающая время ответа, может снизить конверсию.
Запускайте оффлайн-оценки при каждом изменении
Выполняйте оффлайн-оценки до релиза и после каждого изменения подсказки, модели, инструмента или поиска. Версионируйте результаты, чтобы сравнивать прогон и быстро находить, что сломалось.
Добавьте онлайн-тесты с ограждениями
Используйте A/B-тестирование для измерения реальных исходов (завершение задачи, правки, оценки пользователей), но добавьте защитные механизмы: определите условия остановки (всплески невалидных выходов, отказов или ошибок инструментов) и откатывайте автоматически при превышении порогов.
Мониторинг в продакшене: дрейф, отказы и обратная связь
Экспериментируйте без страха
Экспериментируйте с подсказками и инструментами, затем быстро откатывайтесь при сбоях.
Выпуск AI-first функции — не финиш. На реальных пользователях модель столкнётся с новой формулировкой, крайними случаями и меняющимися данными. Мониторинг превращает «работает в стейджинге» в «продолжает работать через месяц».
Логируйте важное (без сбора секретов)
Фиксируйте достаточно контекста, чтобы воспроизвести ошибки: намерение пользователя, версию подсказки, вызовы инструментов и финальный вывод модели.
Логируйте ввод/вывод с приватной редакцией. Обращайтесь с логами как с чувствительными данными: удаляйте email, телефоны, токены и свободный текст с личными деталями. Держите режим «debug», который можно включить временно для конкретных сессий, вместо массового детального логирования по умолчанию.
Следите за правильными сигналами
Контролируйте частоту ошибок, сбои инструментов, нарушения схем и дрейф. Конкретно отслеживайте:
- Успешность вызовов инструментов и таймауты (модель выбрала правильный инструмент, и он выполнился?)
- Соответствие выходов формату/схеме (валидация отвергла?)
- Использование откатов (как часто приходилось переключаться на безопасный или упрощённый путь)
- Блокировки по безопасности (как часто пришлось отказать или санитизировать)
Для дрейфа сравнивайте текущий трафик с базой: изменения тематики, языкового микса, средней длины подсказок и числа «неизвестных» намерений. Дрейф не всегда плох — но он всегда сигнал к переоценке.
Оповещения, рукбуки и инцидент-ответ
Настройте пороги оповещений и рукбуки. Оповещения должны соответствовать действиям: откат подсказки, отключение нестабильного инструмента, ужесточение валидации или переключение на откат.
Спланируйте реакцию на инциденты по небезопасному или неверному поведению. Определите, кто может включать аварийные переключатели, как уведомлять пользователей и как вы будете документировать и извлекать уроки.
Замкните цикл через обратную связь пользователей
Используйте петли обратной связи: лайк/дизлайк, коды причин, отчёты об ошибках. Просите краткие «почему?» варианты (неверно, не выполнил инструкцию, небезопасно, слишком медленно), чтобы направлять исправления к подсказкам, инструментам, данным или политике.
UX для модельной логики: прозрачность и контроль
Фичи, управляемые моделью, кажутся волшебными, когда работают — и хрупкими, когда нет. UX должен принимать неопределённость и при этом помогать пользователям завершать задачу.
Показывайте «почему» без перегрузки
Пользователи больше доверяют выводам ИИ, когда видят источник — не для лекции, а чтобы решить, стоит ли действовать.
Используйте прогрессивное раскрытие:
- Начните с результата (ответ, черновик, рекомендация).
- Предложите переключатель «Почему?» или «Показать работу», раскрывающий ключевые входы: запрос пользователя, использованные инструменты и источники/записи. Если используется поиск, показывайте цитаты с переходом к отрывку (например, “По: Политика §3.2”). Делайте это легко просматриваемым.
Если нужен более глубокий эксплейнер, ведите на внутреннюю страницу (например, /blog/rag-grounding), а не загромождайте UI подробностями.
Дизайн для неопределённости (без пугающих предупреждений)
Модель — не калькулятор. Интерфейс должен показывать уверенность и давать возможность проверки.
Практические шаблоны:
- Подсказки уверенности простым языком («Вероятно верно», «Нуждается в проверке»), а не фальшивая точность.
- Варианты вместо единственного ответа: «Вот 3 варианта ответа». Это снижает стоимость неправильной первой попытки.
- Подтверждения для действий с последствиями (отправка писем, удаление данных, оплата). Задайте один понятный вопрос: «Отправить это сообщение 12 получателям?»
Сделайте исправление и восстановление лёгкими
Пользователи должны направлять вывод без начала с нуля:
- Редактирование в тексте с кнопкой «Применить изменения», чтобы модель продолжила с учётом правок.
- «Перегенерировать» с контролями (тон, длина, ограничения) вместо слепого реролла.
- «Отменить» и видимая история, чтобы ошибки были обратимы.
Предоставьте аварийный выход
Когда модель падает — или пользователь не уверен — предложите детерминированный поток или помощь человека.
Примеры: «Перейти к ручной форме», «Использовать шаблон» или «Связаться с поддержкой» (например, /support). Это не позорный откат; это способ защитить завершение задачи и доверие.
От прототипа к продакшену (без полной переделки)
Большинство команд не терпят неудачу из‑за возможностей LLM; они терпят неудачу, потому что путь от прототипа к надёжной, тестируемой и мониторимой фиче длиннее, чем ожидалось.
Практичный способ сократить этот путь — стандартизировать «скелет продукта» рано: машины состояний, схемы инструментов, валидация, трассировки и история выката/развёртывания. Платформы вроде Koder.ai могут быть полезны, если вы хотите быстро развернуть AI-first рабочий процесс — создавая UI, бэкенд и базу данных вместе — и затем итеративно работать со снимками/откатами, собственными доменами и хостингом. Когда будете готовы к операционализации, можно экспортировать исходный код и продолжить с вашим CI/CD и стеком наблюдаемости.