28 авг. 2025 г.·8 мин
Автодополнение и устойчивость к опечаткам для поиска в индийской электронной торговле
Узнайте, как настроить автодополнение и устойчивость к опечаткам для индийского e‑commerce: планирование синонимов, местные термины, транслитерация и аналитика для улучшения результатов.
Почему названия товаров в Индии ломают поиск
Поиск в индийском e‑commerce терпит неудачу по простой причине: люди не называют одно и то же одинаково. Один и тот же товар могут вводить на английском, хинди, тамильском или смешанно, и в каждом регионе свои обычные слова.
Покупатель может искать «atta», «aata», «gehu ka atta» или только по названию бренда. Другой вводит «jeera», «zeera» или просто «cumin». Если в каталоге есть только одна из этих форм, вполне нормальный запрос может ничего не вернуть.
Небольшие различия в написании вредят сильнее, чем вы думаете, потому что поисковики часто трактуют запрос как точный текст. Одна пропущенная гласная, лишний пробел или другой порядок слов может вытеснить нужный товар из верхних результатов или привести к нулевым результатам.
Распространённые причины, по которым названия товаров в Индии разбиваются на множество версий:
- Несколько алфавитов и транслитераций (хинди, записанный латиницей; локальные написания)
- Региональные термины для одного и того же предмета (продукты, одежда, хозяйственные товары)
- Название бренда впереди или общая форма («Surf Excel 1kg» vs «detergent powder»)
- Сокращения и разговорные формы («kurti» vs «kurta top», «1 ltr» vs «1L»)
- Опечатки с клавиатуры и автокоррекция («pista» → «pita», «saree» vs «sarri»)
Автодополнение и устойчивость к опечаткам меняют опыт покупателя. Автодополнение сокращает усилия, подсказывая формулировку, понятную вашему магазину, до того как пользователь нажмёт поиск. Устойчивость к опечаткам предотвращает провалы «почти правильных» запросов, чтобы покупатель всё равно видел релевантные товары при неточном написании.
Практическая цель автодополнения и устойчивости к опечаткам в индийском e‑commerce — не «идеальная языковая поддержка», а измеримый результат: меньше нулевых результатов и быстрее находят товары, чтобы больше покупателей попадали на список товаров, а не в тупик.
Ключевые идеи простым языком
Хороший поиск в Индии — это скорее понимание того, как люди реально вводят названия товаров, чем сложные алгоритмы. Многие покупатели смешивают английский с местными словами, пишут одно и то же по‑разному и ожидают, что поиск всё равно «поняет».
Автодополнение помогает до того, как запрос закончён. Когда кто‑то вводит «jeer…», вы можете предложить «jeera rice», «jeera powder» или «jeera whole». Хорошее автодополнение снижает усилия и мягко подталкивает покупателей к словам, которые есть в каталоге.
Устойчивость к опечаткам означает, что вы всё равно совпадаете, когда пользователь делает вероятную ошибку, например «zeera» vs «jeera» или «shampo» vs «shampoo». Цель — исправлять распространённые ошибки без смены смысла. Слишком большая толерантность приводит к странным совпадениям (например, короткий запрос «ram» внезапно начинает совпадать с несвязанными товарами).
Синонимы просты: разные слова — одно намерение. «Atta» и «wheat flour» должны вести к одному набору товаров. В индийском e‑commerce синонимы часто включают региональные слова, разговорные названия и близкие по смыслу термины.
Транслитерация — это когда люди пишут слова на индийском языке латиницей. Кто‑то может ввести «namkeen», «nimeen» или «namkin» в зависимости от привычки и клавиатуры. Правила транслитерации помогают сопоставить такие варианты, даже если в каталоге используется только одно написание.
Практически об автодополнении и устойчивости к опечаткам в индийском e‑commerce:
- Автодополнение направляет пользователя к валидному, популярному запросу.
- Устойчивость к опечаткам спасает пользователя, когда он неправильно написал валидный запрос.
- Синонимы связывают разные слова с одним покупательским намерением.
- Транслитерация связывает разные написания одного и того же местного слова.
Когда это ясно, можно построить небольшой контролируемый набор соответствий и расширять его с помощью реальной аналитики поиска, а не догадываться.
Соберите словарь индийских названий (входные данные)
Хороший словарь для поиска начинается с ваших собственных данных, а не с догадок. Цель проста: зафиксировать, как люди реально называют товары в Индии, включая местные термины, написания и сокращения, чтобы автодополнение и устойчивость к опечаткам имели надёжную базу.
Сначала проанализируйте каталог. Названия товаров, категории, атрибуты, варианты, бренды, размеры упаковок и единицы измерения часто содержат «официальную» формулировку, до которой должны доходить поисковые запросы. Для бакалеи это могут быть и общие, и специфичные термины вроде «toor dal», «arhar dal» и «split pigeon peas», если вы их используете.
Дальше соберите реальный язык клиентов. Логи поиска показывают, что люди вводят, когда спешат; чаты службы поддержки показывают, как они описывают товар, если не могут его найти. Даже несколько недель логов выявят повторяющиеся паттерны типа «aata/atta», «dahi/curd» или «chilli/chili».
Соберите входы из пяти источников, затем объедините и очистите их:
- Текст из каталога (названия, атрибуты, варианты, бренды, размеры)
- Поисковые запросы (включая запросы с нулевыми результатами)
- Чаты поддержки и заметки звонков
- Региональные и локальные термины, которые уже используются внутри команды
- Сокращения единиц и наборов (ml, ltr, pcs, combo, 1+1)
Наконец, отделите общие термины от брендовых. «Atta» должно соответствовать многим товарам, в то время как название бренда не должно случайно подтягивать нерелевантные позиции. Держите два помеченных списка (generic vs brand), чтобы позже правила не размывали намерение и не путали ранжирование.
Пошагово: план синонимов и транслитераций
Начните с малого. Выберите 20–50 категорий, которые формируют большинство запросов и выручки, например бакалея, уход за собой и популярная электроника. Это держит работу в фокусе и позволяет быстро увидеть эффект от автодополнения и устойчивости к опечаткам.
Затем создайте одну общую «таблицу имен», которую смогут редактировать все (мерч, контент, поддержка). Сначала держите её в таблице, потом синхронизируйте в индекс поиска.
1) Сделайте канонический список
Для каждой категории выберите один термин, который система будет считать «основным» (каноническим). Используйте то, что узнают покупатели, а не то, как называет поставщик.
Создайте строки вида:
| Canonical term | Synonyms (same product) | Common misspellings | Transliterations | Notes |
|---|---|---|---|---|
| cumin | jeera | jeera, jeeraa | zeera, zira | Keep “caraway” separate |
| face wash | cleanser | fash wash | fes wash | Don’t map to “face cream” |
Добавьте единицы и паттерны упаковок как отдельные, многоразовые токены: 1kg, 500 g, 2x, combo pack, family pack. Они часто приводят к нулевым результатам, потому что пользователи вводят всё вместе.
2) Установите жёсткие правила «одного товара»
Синоним должен означать, что клиент будет доволен тем же набором результатов. Напишите короткое правило, которому команда сможет следовать:
- Разрешено: региональные варианты названий, сокращения бренда, распространённые написания
- Разрешено: хинглиш‑транслитерация, если смысл остаётся тот же
- Не разрешено: соседние товары (cleanser vs toner, cumin vs carom)
- Не разрешено: разные размеры как синонимы (размер — это фильтр)
- Не разрешено: «healthy» или «premium» как синоним базового товара
3) Упростите сопровождение
Назначьте ответственного за каждую категорию и установите простой цикл обзора (сначала еженедельно). Если поддержка видит жалобы «не могу найти», они добавляют термин в таблицу в тот же день.
Если вы строите это в кастомном стеке поиска, инструмент вроде Koder.ai может помочь быстро создать админ‑экран и процесс синхронизации, сохранив список синонимов доступным для нетехнических команд.
Дизайн автодополнения, который «чувствуется» правильно в Индии
Автодополнение должно быть быстрым, знакомым и снисходительным. В индийском e‑commerce главный выигрыш — полезные подсказки уже по первым буквам. Люди часто печатают быстро, переходят между английским и местными словами и не помнят точного написания.
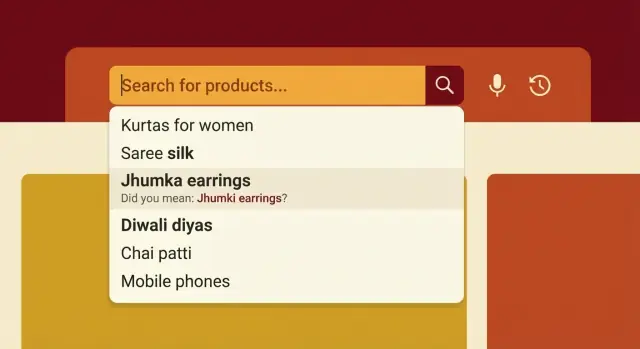
Начните с настройки на префиксы. По первым 2–4 символам уже должны быть сильные, высокоинтенсивные подсказки. Если кто‑то пишет «sha», не тратьте верхние слоты на редкие позиции. Покажите то, что чаще всего имеют в виду покупатели и что у вас есть в продаже в большом количестве.
Делайте подсказки с учётом категории, а не только слов. Если пользователь вводит локальный термин «shakkar», подсказки должны явно указывать на категорию (sugar) и популярные подтипы (порошковый, органический и т.д.). Это снижает путаницу и уменьшает шанс выбрать неправильный результат.
Держите подсказки короткими и читаемыми. Хороший паттерн: бренд + товар (если бренд действительно популярен) или товар + ключевой атрибут. Избегайте набивания размеров, длинных серийных номеров и множества атрибутов в одной строке.
Практические UI‑правила, которые обычно работают:
- Показывайте максимум 5–8 подсказок, с акцентом на верхние 3 для конверсии.
- Нормализуйте пробелы и пунктуацию, чтобы «t-shirt», «tshirt» и «t shirt» вели к одному набору подсказок.
- Отдавайте приоритет товарам и категориям, которые вы действительно можете выполнить сейчас (в наличии и активные лоты).
- Смешивайте типы аккуратно: 1–2 подсказки категорий, затем товары, затем бренды.
- Не показывайте подсказки, которые вы не можете продать (отключённые категории, снятые бренды).
Пример: покупатель вводит «dett». В Индии многие имеют в виду «Dettol» (намерение бренда), но некоторые хотят «handwash» или «sanitizer» (намерение товара). Ваше автодополнение может показать «Dettol Handwash», «Dettol Sanitizer» и категорию «Handwash», чтобы покрыть оба намерения без лишних догадок.
Когда вы делаете это последовательно, автодополнение и устойчивость к опечаткам в индийском e‑commerce перестают быть про хитрые алгоритмы и становятся про то, чтобы дать покупателю следующий очевидный шаг.
Настройте устойчивость к опечаткам без странных совпадений
Тестируйте поиск на мобильных
Создайте лёгкое Flutter-приложение для QA поиска и быстрого просмотра правил на ходу.
Устойчивость к опечаткам помогает людям находить товары, даже если они опечатались. Но если сделать её слишком свободной, поиск начнёт показывать «достаточно близкие» товары, которые кажутся неверными. Цель проста: поймать очевидные ошибки и быть осторожным, когда намерение может поменяться.
Начните с безопасных правил на основе расстояния редактирования и длины слова. Короткие слова ломаются легко, поэтому для них нужно держать строгие правила. Более длинные слова выдерживают большую гибкость.
- 1–4 буквы: разрешить 0–1 правок (пример: «atta» → «atta», «atta» → «attta»)
- 5–8 букв: разрешить до 2 правок
- 9+ букв: разрешить до 3 правок
- Если запрос состоит из нескольких слов, применяйте правки к каждому слову, но ограничьте суммарное число правок для всего запроса
Обращайтесь с числами отдельно. «1kg» и «10kg» никогда не должны быть взаимозаменяемы, и «500ml» не должно превращаться в «1500ml». Практическое правило: не применять устойчивость к опечаткам внутри числовых токенов и не менять единицы. Разрешайте только форматирующие правки типа пробелов или регистра («1 kg», «1KG», «1kg»).
Защитите названия брендов и высокоинтенционные термины от «исправления» в общие слова. Держите маленький список защищённых терминов (топ‑бренды, private labels и похожие запросы). Если запрос близко совпадает с защищённым термином, предпочтительнее показать подсказку, чем молча переписать запрос.
Ошибки соседних клавиш распространены на мобильных, особенно для хинглиш. Добавьте дополнительную толерантность для соседних клавиш (a‑s, i‑o, n‑m), но только когда остальная часть слова сильно совпадает.
Когда исправление неоднозначно, показывайте его как подсказку, а не выполняйте молчаливую замену. Например, если «dove» может стать «done» или «dovee», покажите «Did you mean dove?» и оставьте оригинальные результаты видимыми. Это сохраняет доверие и снижает раздражение.
Транслитерация и местные термины (практические правила)
Индийские запросы часто смешивают скрипты и привычки в одной строке: «जीरा rice», «jeera चावल», «zeera rice» или «poha nashta». Поиск должен трактовать их как одно намерение, а не как разные миры. Для автодополнения и устойчивости к опечаткам цель проста: сопоставить множество способов написания названия товара с одним чистым значением.
Начните с небольшого практичного набора правил и расширяйте его только по мере подтверждения их работоспособности.
Практические правила нормализации
- Принимайте смешение скриптов, нормализуя всё в общую «поисковую форму» (оригинальный запрос сохраняйте для аналитики, а сопоставление делайте по нормализованной форме).
- Добавляйте пары транслитераций только для топ‑товаров сначала (например: namkeen, bhujia, poha, jeera). Включайте распространённые написания, которые люди действительно вводят.
- Обрабатывайте варианты долгих гласных как явные пары там, где это важно (poha vs pauha, jeera vs zeera), вместо попыток угадать все возможные сдвиги гласных.
- Используйте звуковые замены аккуратно и строго: v‑w, b‑v, j‑z. Применяйте их только к известным товарным токенам, а не ко всему запросу, чтобы избежать странных совпадений.
- Держите названия брендов и SKU в основном «как введено», чтобы случайно не переписать их в что‑то другое.
Какие языки поддерживать в первую очередь
Выбирайте по трафику и нулевым результатам, а не по амбициям. Частый порядок: английский + хинглиш сначала, затем добавить хинди‑скрипт, если существенная доля запросов его использует. Если позже появится спрос в каком‑то регионе, расширяйте набор языков по одной категории за раз.
Петля аналитики: улучшайте поиск на основе реального поведения
Держите код под своим контролем
Сохраняйте полный контроль: экспортируемый исходный код, когда вы будете готовы сменить стек.
Качество поиска — это не одноразовая настройка. Делайте из этого еженедельную привычку: смотрите, что люди вводят, что кликают и где сдаются. Так автодополнение и устойчивость к опечаткам улучшаются без догадок.
Начните с небольшого набора ключевых метрик и держите их постоянными из недели в неделю:
- Доля нулевых результатов (в целом и по топ‑запросам)
- Доля доработки запроса (пользователи переименовывают или добавляют фильтры сразу после поиска)
- Добавления в корзину после поиска (или клики по товарам после поиска, если корзины шумные)
- Использование автодополнения (клики на подсказки vs полное ручное введение)
- Влияние исправлений (исправленные опечатки, которые приводят к кликам vs отказы)
Раз в неделю вытягивайте топ‑запросы без результатов и классифицируйте каждый. Держите категории простыми, чтобы команды действительно пользовались ими: отсутствует синоним (jeera vs zeera), вариация написания, несоответствие бренда или модели, неверный язык/скрипт или пробел в каталоге (товар не в наличии). Цель — отделить «поиску нужен синоним» от «товара нет в наличии».
Данные автодополнения часто дают самый быстрый выигрыш. Если пользователи часто игнорируют подсказки и допечатывают до конца, ваши подсказки могут быть слишком общими, неправильно упорядоченными или отсутствовать локальные термины. Если они нажимают подсказки, но затем дорабатывают или покидают страницу, подсказка может выглядеть правильно, но вести на слабые результаты.
Опечатки требуют аудита, а не просто увеличения толерантности. Выбирайте 20–50 исправленных запросов в неделю и маркируйте их:
- Полезные (исправлено к нужному товару)
- Безвредные (достаточно близко, пользователь всё равно нашёл товары)
- Вредные (исправлено к другому товару или категории)
Вынесите это в простой дашборд, который продукт и маркетинг могут просмотреть за 2 минуты: топ нулевых запросов с назначенной причиной, топ подсказок автодополнения и их кликабельность, и краткий список действий для следующего релиза. Если вы быстро строите внутренние инструменты (например, в Koder.ai), этот дашборд и недельный экспорт — хорошие первые проекты.
Распространённые ошибки и ловушки
Большинство проблем поиска в Индии связаны не с «большим количеством синонимов». Они возникают из нескольких предсказуемых ошибок, которые постепенно ведут пользователей к неправильным результатам и теряют доверие.
Одна из главных ловушек — слишком широкие синонимы, которые смешивают разные товары. Если «cream» и «lotion» станут взаимозаменяемыми, пользователи, ищущие густой крем для лица, могут попасть на лёгкий лосьон для тела и уйти. Держите синонимы точными: связывайте варианты одного и того же намерения, а не соседние категории.
Ещё одна ошибка — игнорирование упаковки и единиц. «Oil 1L» и «oil 5L» — разные покупки, как и «atta 5 kg» и «atta 10 kg». Если правила игнорируют единицы, пользователь, который пополняет запас оптом, может получить маленькие упаковки, и ранжирование будет выглядеть случайным.
Высокоэффективные ошибки, за которыми стоит следить:
- Обрисовывать разные продукты как синонимы (cream vs lotion, shampoo vs conditioner)
- Игнорировать размеры, количество и слова единиц (1L, 5L, 500 ml, 10 pcs)
- Позволять устойчивости к опечаткам «исправлять» имена брендов в другие бренды
- Показывать подсказки автодополнения, которых вы не можете доставить по этому индексу
- Настроить и забыть правила, особенно после промо‑акций и сезонных пиков
Названия брендов требуют особой аккуратности. Если кто‑то пишет «Himalya face wash», а настройки опечаток «исправляют» это в другой бренд, это будет восприниматься как притягивание трафика. Безопасное правило: быть более снисходительным к общим словам («shampu»), но строже — к брендам и модельным токенам.
Автодополнение тоже может навредить, если предлагает недоступные товары. Например, предлагать «ghee 2L», потому что это частый запрос, хотя в наличии только 1L — это разочарование. Предпочитайте подсказки, которые вы действительно можете выполнить сегодня.
Если вы внедряете автодополнение и устойчивость к опечаткам, заведите привычку обзора: после недели продаж проверьте новые топ‑запросы, растущие опечатки и нулевые результаты. Даже небольшие сезонные сдвиги (свадебный сезон, муссон, экзамены) меняют то, как люди ищут.
Если хотите быстро протестировать изменения правил, Koder.ai может помочь прототипировать сервис правил поиска и админ‑страницу для управления синонимами, единицами и защитой брендов, а затем экспортировать код, когда будете готовы.
Реальный пример: исправляем поиск «jeera rice» и «zeera rice»
Покупатель вводит «zeera rice» и получает нулевые результаты. Они не ищут другой товар — имелось в виду «jeera rice» (cumin rice), но они написали так, как говорят.
Исправьте это двумя небольшими и безопасными изменениями: синонимом для распространённых вариантов написания и консервативным правилом устойчивости к опечаткам. В этом запросе трактуйте «zeera» как транслитерационный вариант «jeera», а не как отдельный смысл.
Практическая привязка, которая обычно работает:
- Синоним запроса: zeera -> jeera
- Синоним запроса: zira -> jeera
- Оставьте названия товаров в каталоге без переименований (не меняйте SKU)
Добавьте правило устойчивости, жёсткое для коротких слов. Например, разрешать 1 правку (один неверный, пропущенный или переставленный символ) только когда длина токена ≥ 5. Это помогает поймать «jeera» vs «jeeraa», но избегает ложных совпадений на очень коротких словах.
После изменений автодополнение должно направлять покупателя, а не слишком догадываться. Когда они вводят «zee…», предложите:
- «jeera rice»
- «jeera basmati rice»
- «jeera (cumin)"
А при отправке «zeera rice» результаты должны показывать ваши товары «jeera rice» вверху, плюс смежные позиции вроде cumin и basmati в зависимости от правил ранжирования.
Через неделю проверьте аналитику поиска по поведению, а не только по кликам:
- Доля нулевых результатов для «zeera», «zira» и «jeera»
- Доля доработки запроса (перепечатали ли пользователи?)
- Конверсия в добавления в корзину после поиска для этих запросов
- Топ кликов, чтобы убедиться, что синоним не подтягивает нерелевантные товары
Если результаты ухудшаются (например, «zira» начинает совпадать с брендом «zera» или другой категорией), быстро откатите только эту группу синонимов, а не всю систему. Держите версионированную конфигурацию, чтобы откат занимал минуты. Такой плотный цикл обратной связи — суть автодополнения и устойчивости к опечаткам для индийского e‑commerce.
Короткий чек‑лист перед релизом изменений
Сделайте панель аналитики поиска
Преобразуйте логи поиска в недельную панель: нулевые результаты, доработки и исправления.
Перед тем как выпустить новые синонимы, автодополнение или настройки опечаток, сделайте быструю проверку, смешав реальные данные запросов и ручное тестирование. Это защищает от «полезных» изменений, которые создают шум (например, неверные совпадения двух похожих слов).
Используйте этот короткий пред‑релизный чек‑лист:
- Вытяните топ‑50 запросов за последние 7–14 дней и сгруппируйте их по намерению (бренд, общий товар, вариант вроде размера или цвета, и задача вроде «масло против выпадения волос»). Если запрос может означать два вещи, отметьте оба.
- Вытяните топ‑50 нулевых запросов и решите исправление для каждого: сопоставить с существующей категорией, добавить синоним (локальный термин или написание), добавить недостающий товар или заблокировать, если запрос нерелевантен. Не откладывайте на «потом».
- Обновите список синонимов и транслитераций с указанием владельца, даты последнего обновления и краткой причины. Это предотвращает хаотичные правки вроде «atta = aata = aataa» в трёх местах.
- Протестируйте автодополнение в топ‑категориях реальными фразами пользователей: английский, хинглиш и распространённые сокращения. Проверьте, что подсказки не прыгают к нишевым товарам слишком рано и что включены популярные варианты (как «1kg», «500g», «pack of 2»).
- Протестируйте устойчивость к опечаткам 20 сложными запросами: ошибки в брендах (особенно двойные буквы), смешанные числа («iPhone 15 pro 256»), и похожие слова («jeera/zeera», «besan/besan flour»). Убедитесь, что топ‑результаты остаются корректными, а не просто «похожими».
Если что‑то не проходит, релизьте меньший набор изменений первым. Плавный и контролируемый релиз лучше, чем большой апдейт, который делает поиск случайным.
Следующие шаги: простой план релиза (и как сделать это быстрее)
Начните с одной категории с очевидной проблемой поиска: бакалея, товары личного ухода или аксессуары для мобильных. Держите объём маленьким на одну неделю, чтобы увидеть причинно‑следственную связь. Выберите 2–3 метрики успеха, которыми реально можно повлиять: доля нулевых результатов, конверсия поиск→клик по товару и добавление в корзину после поиска.
Простой рабочий план релиза:
- День 1: Базовые метрики — соберите текущие показатели, топ‑запросы и топ‑нулевых запросов для категории.
- День 2–3: Выпустите небольшой словарь — добавьте ограниченный набор синонимов и хинглиш‑транслитераций для топ‑50 запросов и топ‑20 паттернов брендов/размеров.
- День 4: Ограждения — добавьте исключения там, где меняется смысл (например, «atta» не должен совпадать с «ATA», если это бренд или код в каталоге).
- День 5–6: Мониторинг — отслеживайте выигрыши (меньше нулевых результатов, больше кликов) и просадки (нерелевантные клики, рост возврата к поиску).
- День 7: Решение — оставить, подправить или откатить, затем планировать следующий пакет на основе увиденных улучшений.
Делайте изменения обратимыми. Относитесь к правилам синонимов и опечаток как к коду: версионируйте, снимайте снимки и держите путь отката. Если новое правило вдруг заставляет «face wash» показывать «dishwash liquid», вы должны откатиться за минуты, а не дни.
Владение процессом важнее сложных правил. Назначьте одного человека на 30‑минутный еженедельный обзор: топ новых нулевых запросов, топ «хороших исправлений» и всплески низкокачественных кликов.
Если хотите быстрее итераций, Koder.ai поможет реализовать слой поиска чат‑управляемо, использовать режим планирования для картирования правил и метрик перед релизом и сохранить экспортируемый исходный код, чтобы ваша команда владела решением в долгосрочной перспективе. Он также поддерживает снимки и откат — идеально, когда правка поиска нужна быстро.
Планируйте следующую итерацию по измеряемым результатам. Например, если «zeera rice» стал конвертировать, но «jeera» теперь совпадает с нерелевантными «zera» товарами, следующая задача — ужесточить это правило, а не переписывать всю систему.