27 сент. 2025 г.·8 мин
Blue/Green и Canary-развертывания: понятная стратегия релизов
Научитесь выбирать между Blue/Green и Canary-развертываниями, как работает смещение трафика, что мониторить и какие практические шаги по раскату и откату обеспечат более безопасные релизы.
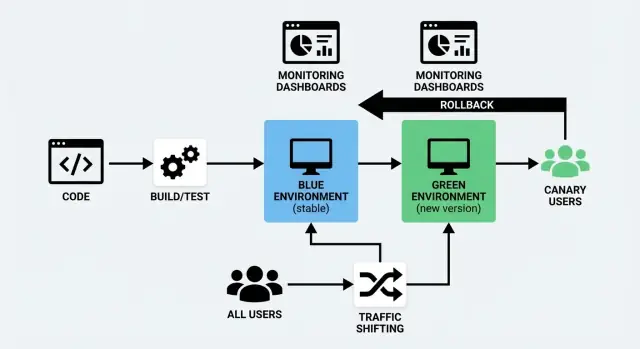
Что означают Blue/Green и Canary-развертывания
Выпуск нового кода рискован по простой причине: вы вряд ли полностью понимаете, как он поведёт себя, пока его не начнут использовать реальные пользователи. Blue/Green и Canary — два распространённых подхода, которые позволяют снизить этот риск, сохраняя время простоя близким к нулю.
Blue/Green простыми словами
Blue/Green-развертывание использует два отдельных, но похожих окружения:
- Blue: версия, которая сейчас обслуживает пользователей («живое» окружение).
- Green: второе, готовое окружение, куда разворачивается новая версия.
Вы подготавливаете Green в фоне — деплоите новый сбор, запускаете проверки, прогреваете — и переключаете трафик с Blue на Green, когда уверены. Если что-то идёт не так, можно быстро вернуть предыдущую версию.
Главная идея не в «двух цветах», а в чистом, обратимом переключении.
Canary простыми словами
Canary-релиз — это поэтапный выпуск. Вместо того чтобы переключать всех одновременно, новую версию показывают небольшой части пользователей (например, 1–5%). Если всё в порядке, раскат расширяют шаг за шагом до 100% трафика.
Ключевая идея — учиться на реальном трафике до окончательного перехода.
Общая цель: более безопасные релизы и минимальные простои
Оба подхода направлены на:
- уменьшение влияния ошибок на пользователей
- обеспечение «развертывания без простоя» (или максимально близкого к этому)
- упрощение и предсказуемость откатов
Они делают это по-разному: Blue/Green фокусируется на быстром переключении между окружениями, а Canary — на контролируемом воздействии через смещение трафика.
Нет единственно «лучшего» варианта
Ни один подход не превосходит другой во всех случаях. Выбор зависит от сценария использования продукта, уровня доверия к тестам, скорости, с которой нужны обратные данные, и типов отказов, которых вы хотите избегать.
Многие команды комбинируют подходы — используют Blue/Green для простоты инфраструктуры и Canary для постепенного покрытия реальных пользователей.
В следующих разделах мы сравним их и покажем, когда каждый подход работает лучше.
Blue/Green vs Canary: быстрое сравнение
Blue/Green и Canary — оба способа выпускать изменения без прерывания пользователей, но они отличаются тем, как трафик переходит на новую версию.
Как переключается трафик
Blue/Green содержит два полноценных окружения: «Blue» (текущая) и «Green» (новая). Вы проверяете Green, затем переключаете весь трафик разом, как один контролируемый тумблер.
Canary сначала отправляет новую версию небольшой доле пользователей (например, 1–5%), затем постепенно сдвигает трафик, наблюдая за поведением в реальном мире.
Важные плюсы и минусы
| Фактор | Blue/Green | Canary |
|---|---|---|
| Скорость | Очень быстрое переключение после валидации | Медленнее по замыслу (поэтапный раскат) |
| Риск | Средний: если релиз плохой, все пользователи пострадают после переключения | Ниже: проблемы часто проявляются до полного раската |
| Сложность | Умеренная (два окружения, чистое переключение) | Выше (разделение трафика, анализ, поэтапные шаги) |
| Стоимость | Выше (во время релиза фактически дублируете мощности) | Часто ниже (можно наращивать на существующих мощностях) |
| Подходит для | Крупных, координируемых изменений | Частых, небольших улучшений |
Простой алгоритм выбора
Выбирайте Blue/Green, когда нужна чистая и предсказуемая точка переключения — особенно для больших изменений, миграций или релизов, где важно чёткое разделение «старого» и «нового».
Выбирайте Canary, когда вы часто выпускаете, хотите безопасно получать обратную связь от реального использования и предпочитаете уменьшать радиус поражения, позволяя метрикам управлять каждым шагом.
Если не уверены, начните с Blue/Green ради операционной простоты, а затем добавьте Canary для критичных сервисов, когда практики мониторинга и отката будут отлажены.
Когда Blue/Green — правильный выбор
Blue/Green хорош, когда вы хотите, чтобы релиз выглядел как «щелчок выключателя». У вас два production-подобных окружения: Blue (текущая) и Green (новая). Когда Green проверена, вы направляете туда пользователей.
Когда нужно почти нулевое время простоя
Если продукт не может позволить видимых окон обслуживания — корзины покупок, системы бронирования, панели для авторизованных пользователей — Blue/Green помогает, потому что новая версия запускается, прогревается и проверяется до того, как на неё пойдут реальные пользователи. Большая часть «времени деплоя» происходит в стороне, а не перед клиентами.
Когда нужен максимально простой откат
Откат часто сводится к перенаправлению трафика обратно на Blue. Это полезно, когда:
- релиз должен быть обратимым в течение нескольких минут
- нужно избегать экстренных хотфиксов в условиях стресса
- требуется чёткий, повторяемый сценарий реакции на сбой
Ключевое преимущество — откат не требует пересборки или повторного деплоя, это просто переключение трафика.
Когда изменения в базе данных совместимы
Blue/Green проще, когда миграции БД обратно-совместимы, потому что в короткий период Blue и Green могут сосуществовать (и оба могут читать/писать, в зависимости от маршрутизации и фоновых задач).
Подходят изменения:
- добавление (nullable) колонок, новых таблиц
- расширение форматов данных так, чтобы старый код мог их игнорировать
Рискованно:
- удаление колонок, переименование полей или изменение значений «на месте» — это может нарушить обещание «быстрого отката», если не спланировать многоэтапные миграции.
Когда вы можете позволить себе дублирование окружений и контроль маршрутизации
Blue/Green требует дополнительных ресурсов (два стека) и механизма для управления трафиком (балансировщик нагрузки, ingress или роутинг платформы). Если у вас уже есть автоматизация для создания окружений и чистый рычаг маршрутизации, Blue/Green становится практичным дефолтом для релизов с высокой уверенностью и низкой драмой.
Когда Canary-релизы лучше подходят
Canary — это стратегия, при которой вы сначала выкатываете изменение небольшой части реальных пользователей, изучаете поведение, а затем расширяете. Это правильный выбор, когда вы хотите снизить риск, не останавливая мир ради большого «всё разом» релиза.
У вас много трафика и понятные сигналы
Canary особенно полезен для высоконагруженных приложений, потому что даже 1–5% трафика способны быстро дать значимую выборку. Если вы уже отслеживаете чёткие метрики (ошибки, задержки, конверсия, завершение оплат, таймауты API), вы можете верифицировать релиз на основе реального использования, а не полагаться только на тестовые окружения.
Вы беспокоитесь о производительности и крайних случаях
Некоторые проблемы проявляются только под реальной нагрузкой: медленные запросы к БД, промахи кэша, региональные задержки, редкие устройства или нестандартные пользовательские потоки. Canary позволяет убедиться, что изменение не увеличивает ошибки и не ухудшает производительность, прежде чем охватить всех.
Вам нужны поэтапные раскаты, а не единый переключатель
Если вы часто выпускаете, у вас несколько команд или изменения можно вводить постепенно (UI-правки, эксперименты с ценами, логика рекомендаций), canary-раскаты подходят естественно. Вы можете расширять доли: 1% → 10% → 50% → 100% по мере получения сигналов.
Фича-флаги — часть вашего инструментария
Canary особенно хорошо сочетается с фича-флагами: вы деплоите код безопасно, затем включаете функциональность для подмножества пользователей, регионов или аккаунтов. Это делает откаты менее драматичными — часто достаточно просто выключить флаг, не деплоив новую сборку.
Если вы идёте в сторону прогрессивной доставки, canary-релизы часто являются наиболее гибкой отправной точкой.
См. также: /blog/feature-flags-and-progressive-delivery
Основы смещения трафика (без жаргона)
Смещение трафика — это контроль того, кому и когда попадает новая версия приложения. Вместо мгновенного переключения всех запросов вы поэтапно (или выборочно) переводите запросы со старой версии на новую. Это практическое ядро как Blue/Green, так и Canary, и то, что делает реалистичным «развертывание без простоя».
«Рулевое управление»: где маршрутизируется трафик
Трафик можно переключать на нескольких уровнях стека. Выбор зависит от того, что вы уже используете и насколько точный контроль вам нужен.
- Балансировщик нагрузки: распределяет входящие запросы между окружениями или наборами серверов.
- Ingress-контроллер (Kubernetes): направляет трафик в разные Service по правилам.
- Service mesh: управляет трафиком между сервисами с точными правилами и улучшенной видимостью.
- CDN / крайняя маршрутизация: полезно, когда вы хотите принимать решения близко к пользователям, обычно для веб-трафика.
Вам не нужно всё сразу. Выберите один «источник истины» для решений о маршрутизации, чтобы управление релизами не превратилось в гадание.
Распространённые способы разделения трафика
Большинство команд используют один (или комбинацию) из подходов для смещения трафика:
- По процентам: 1% → 5% → 25% → 50% → 100%. Классический canary-паттерн.
- По заголовкам: направлять запросы с определённым заголовком (например, от QA-инструментов или внутренних тестеров) на новую версию.
- По когортам пользователей: вначале определённые группы — сотрудники, бета-пользователи, регион или тариф.
Процентный подход проще объяснить, но когорты часто безопаснее, потому что вы контролируете какие пользователи увидят изменение (и избегаете сюрпризов для ключевых клиентов в первые часы).
Сессии и кэши: два «подводных камня»
Две вещи часто ломают хорошие планы развертывания:
Привязка сессий (sticky sessions). Если система привязывает пользователя к конкретному серверу/версии, то 10%-й сплит может не соответствовать фактическому поведению. Это также вызывает странные баги, когда пользователь переключается между версиями в рамках одной сессии. По возможности используйте общее хранилище сессий или гарантируйте, что маршрутизация держит пользователя на одной версии.
Прогрев кэша. Новые версии часто попадают в холодные кэши (CDN, приложение, кэш запросов БД). Это может выглядеть как регрессия производительности даже при исправном коде. Планируйте время на прогрев кэшей перед увеличением трафика, особенно для страниц с большим трафиком и дорогих эндпоинтов.
Делайте изменения маршрутизации контролируемыми операциями
Обращайтесь с изменениями маршрутизации как с продакшн-изменениями, а не как с кнопкой «нажать по желанию».
Документируйте:
- кто может менять распределение трафика
- как оно утверждается (on-call? менеджер релизов? тикет?)
- где это делается (конфиг LB, правила ingress, политики mesh)
- что значит «стоп» (триггер для приостановки раската и следования плану отката)
Небольшая опора на управление предотвращает ситуацию, когда кто-то «просто подтянул до 50%», пока вы ещё выясняете, здоров ли канарей.
Что мониторить во время раската
Внедряйте экспериментальные идеи в мобильные приложения
Создайте мобильное приложение на Flutter и безопасно вносите изменения при выпуске.
Роллаут — это не просто «удачно ли деплоится». Важно понять: «получают ли реальные пользователи худший опыт?» Проще сохранять спокойствие при Blue/Green или Canary, если вы смотрите небольшой набор сигналов, отвечающих на вопрос: система здорова и изменение вредит клиентам?
Четыре основных сигнала: ошибки, задержки, насыщение, влияние на пользователя
Уровень ошибок: отслеживайте HTTP 5xx, сбои запросов, тайм-ауты и ошибки зависимостей (БД, оплаты, внешние API). Канареечный релиз с небольшим увеличением «малых» ошибок может создать большой объём поддержки.
Задержки: смотрите p50 и p95 (и p99, если есть). Изменение, которое держит среднюю задержку стабильной, всё равно может порождать долгие хвосты, которые ощущают пользователи.
Насыщение: мониторьте степень загрузки системы — CPU, память, диск IO, соединения с БД, глубину очередей, пул потоков. Проблемы насыщения часто проявляются раньше, чем полный отказ.
Сигналы влияния на пользователя: измеряйте то, что действительно важно — ошибки при оплате, успешность входа, возвращаемость результатов поиска, падения приложения, время загрузки ключевых страниц. Эти метрики часто важнее инфраструктурных показателей.
Соберите "дашборд релиза", который понятен всем
Создайте небольшой дашборд, помещающийся на один экран и расшариваемый в канале релиза. Делайте его одинаковым для каждого раската, чтобы люди не тратили время на поиск графиков.
Включите:
- уровень ошибок (в целом + по ключевым эндпоинтам)
- задержки (p50/p95 для критических путей)
- насыщение (топ-3 ограничений вашей архитектуры, например CPU приложения, соединения БД, глубина очередей)
- KPI влияния на бизнес (1–3 основных пользовательских потока)
Если вы проводите canary, сегментируйте метрики по версиям/группам инстансов, чтобы сравнивать canary vs baseline напрямую. Для blue/green сравнивайте новые и старые окружения в окне переключения.
Установите чёткие пороги для паузы/отката
Решите правила до начала смещения трафика. Примеры порогов:
- рост уровня ошибок на X% относительно базовой линии в течение Y минут
- p95 превышает фиксированный лимит (или растёт на X% относительно базовой линии)
- KPI влияния на пользователя упал ниже приемлемого минимума
Конкретные числа зависят от сервиса, но важно договориться заранее. Если все знают план отката и триггеры, не будет обсуждений в тот момент, когда клиенты страдают.
Оповещения, сфокусированные на окне раската
Добавьте (или временно ужесточьте) алёрты специально на период раската:
- неожиданные пики 5xx/таймаутов
- внезапный регресс по задержкам на ключевых путях
- быстрый рост сигналов насыщения (пулы соединений, очереди)
Делайте оповещения действующими: «что изменилось, где и что делать дальше». Если алерт шумит, люди пропустят важный сигнал во время смещения трафика.
Предрелизные проверки, которые ловят проблемы заранее
Большинство провалов раскатов вызвано не «большими багами», а небольшими несоответствиями: пропущенный конфиг, неправильная миграция БД, истёкший сертификат или интеграция, работающая по-другому в новом окружении. Предрелизные проверки — шанс поймать это, пока радиус поражения ещё мал.
Начните с health-check и smoke-тестов
Перед любым смещением трафика (и для blue/green, и для canary) убедитесь, что новая версия жива и может обслуживать запросы.
- проверьте health-эндпоинты приложения (и не просто «процесс запущен»)
- валидируйте зависимости: БД, кэш, очереди, хранилище объектов, провайдеры email/SMS
- убедитесь, что секреты и переменные окружения присутствуют и корректно сфокусированы
Прогоните короткие end-to-end тесты против нового окружения
Unit-тесты полезны, но они не доказывают, что развернутая система работает. Запустите короткий автоматизированный набор end-to-end тестов против Green, который укладывается в несколько минут.
Сфокусируйтесь на сценариях, пересекающих сервисы (web → API → БД → внешние сервисы) и включите хотя бы один «реальный» запрос для каждой ключевой интеграции.
Проверьте критические пользовательские сценарии
Автотесты иногда упускают очевидное. Сделайте целенаправленную человеческую проверку ваших основных потоков:
- вход и восстановление пароля
- процесс оплаты/чекаут (включая сценарии отказа)
- ключевые CRUD-действия
Если у вас разные роли (админ и клиент), прогоните хотя бы по одному сценарию для каждой роли.
Ведите чеклист готовности к релизу
Чеклист превращает народную мудрость в повторяемую стратегию:
- миграции БД применены и обратимы (или явно безопасны)
- готовность наблюдаемости: логи, дашборды, оповещения для ключевых метрик
- план отката проверен (кто, как и что значит «стоп»)
Когда эти проверки рутинны, смещение трафика становится контролируемым шагом, а не прыжком в неизвестность.
Blue/Green: практический плейбук
Планируйте выпуск заранее
Пропишите шаги, проверки и триггеры отката до того, как направите трафик на новую версию.
Blue/Green-раскат проще проводить по чеклисту: подготовка, деплой, валидация, переключение, наблюдение и уборка.
1) Деплойте в Green (не трогая пользователей)
Разверните новую версию в Green, пока Blue продолжает обслуживать трафик. Синхронизируйте конфигурации и секреты, чтобы Green была зеркалом.
2) Проверьте Green до переключения трафика
Сначала быстрые проверки с высоким сигналом: приложение стартует корректно, ключевые страницы загружаются, оплата/вход работают, логи в норме. Запустите автоматические smoke-тесты, если они есть. Также проверьте дашборды и оповещения для Green.
3) Планируйте миграции БД безопасно (expand/contract)
Blue/Green становится сложнее при изменениях базы данных. Применяйте подход expand/contract:
- Expand: добавляйте новые колонки/таблицы обратно-совместимым способом.
- Разверните Green так, чтобы она работала с обоими схемами.
- Contract: удаляйте старые поля только после вывода Blue и уверенности в стабильности новой версии.
Это предотвращает ситуацию «Green работает, а Blue ломается» во время переключения.
4) Прогрейте кэши и настройте фоновые задачи
Перед переключением прогрейте критические кэши (главная страница, частые запросы), чтобы пользователи не столкнулись с «холодным стартом».
Для фоновых задач/воркеров решите, кто их выполняет:
- запускайте задания в одном окружении во время переключения, чтобы избежать двойной обработки
5) Переключите трафик и наблюдайте
Переключите маршрутизацию с Blue на Green (балансировщик/DNS/ingress). Наблюдайте за уровнем ошибок, задержками и бизнес-метриками в коротком окне.
6) Проверка после переключения и уборка
Сделайте спотовую проверку «реальным пользователем», затем держите Blue доступной как резерв. Когда всё стабильно, отключите фоновые задачи в Blue, заархивируйте логи и де-провизионьте Blue, чтобы снизить стоимость и путаницу.
Canary: практический плейбук
Canary-раскат — про безопасное обучение. Вместо того чтобы отправить всех пользователей на новую версию, вы открываете её небольшой части трафика, внимательно наблюдаете и расширяете. Цель не «идти медленно», а «подтвердить безопасность» на каждом шаге.
Простой план нарастания (1–5% → 25% → 50% → 100%)
- Подготовьте канарейку
Разверните новую версию рядом со стабильной. Убедитесь, что можете маршрутизировать определённый процент трафика на неё и что обе версии видны в мониторинге (отдельные дашборды или теги помогают).
- Этап 1: 1–5%
Начните с малого. Здесь быстро проявляются очевидные проблемы: битые эндпоинты, пропущенные конфиги, сюрпризы в миграциях или неожиданные задержки.
Записывайте на этапе:
- что изменено в релизе (включая «малые» конфиги)
- что вы ожидали увидеть
- что наблюдали (ошибки, задержки, влияние на пользователей)
- Этап 2: 25%
Если первый этап чист, увеличьте до ~25% трафика. Теперь вы увидите больше реального разнообразия: разные поведения пользователей, редкие устройства, крайние случаи и большую конкуренцию.
- Этап 3: 50%
Половина трафика показывает вопросы по ёмкости и производительности. Если есть предел масштабирования, часто первые признаки проявляются именно здесь.
- Этап 4: 100% (промоция)
Когда метрики стабильны и влияние на пользователей приемлемо, переключите весь трафик на новую версию и объявите её промотированной.
Как выбирать интервалы нарастания (сколько ждать на каждом шаге)
Время на каждом шаге зависит от риска и объёма трафика:
- Высокий риск или низкий трафик: дожидайтесь больше данных (например, 30–60 минут или больше). Для сервисов с низким трафиком может потребоваться несколько часов, чтобы собрать значимые паттерны.
- Низкий риск и высокий трафик: можно сокращать этапы (например, 5–15 минут), потому что данные собираются быстро.
Учтите бизнес-циклы. Если продукт испытывает пики (обеденные часы, выходные, расчётные периоды), прогоняйте канарейку достаточно долго, чтобы покрыть типичные условия, в которых возникают проблемы.
Автоматизируйте промоцию и откат
Ручные раскаты добавляют сомнения и непоследовательность. Автоматизируйте, где возможно:
- промоция, когда ключевые метрики держатся в пределах порогов в течение заданного окна
- откат, когда пороги нарушаются (например, рост ошибок или задержек)
Автоматизация не убирает человеческое суждение — она убирает задержки.
Рассматривайте каждый этап как эксперимент
На каждом шаге записывайте:
- краткое описание изменений
- критерии успеха (какие метрики должны оставаться стабильными)
- наблюдаемые результаты (включая «ничего необычного»)
- решение (промоция, удержание или откат) и почему
Эти заметки превращают историю раскатов в практический плейбук и облегчают разбор инцидентов впоследствии.
Планы отката и обработка сбоев
Откаты проще, когда вы заранее решаете, что считать «плохо» и кто может нажать кнопку. План отката — не пессимизм, а способ не допустить, чтобы небольшая проблема вылилась в длочный простой.
Определите явные триггеры отката
Выберите короткий список сигналов с явными порогами, чтобы не было споров в инциденте. Частые триггеры:
- уровень ошибок: всплески 5xx, неудачные оплаты, ошибки входа, таймауты API
- задержки: p95/p99 выше согласованного предела в течение устойчивого окна (например, 5–10 минут)
- бизнес-KPI: резкое падение конверсии, успешности платежей, регистраций или рост отмен
Сделайте триггер измеримым (например, "p95 > 800ms в течение 10 минут") и привяжите к владельцу (on-call, менеджер релизов) с правом действовать немедленно.
Делайте откат быстрым (и скучным)
Скорость важнее изящества. Откат должен быть одним из двух:
- обратное смещение трафика (обычно для blue/green и canary): вернуть трафик на предыдущую, известную рабочую версию
- деплой предыдущей сборки: если изменилась инфраструктура, запушить последнюю стабильную сборку и снова прогнать проверки
Избегайте сначала «поправим руками и продолжим раскат» — сначала стабилизируйте, потом расследуйте.
Планируйте частичные откаты
При canary-раскате некоторые пользователи могли создать данные под новой версией. Решите заранее:
- следует ли немедленно вернуть канареечных пользователей назад или оставить их на канаре при оценке?
- если форматы данных изменились, совместима ли БД назад? Если нет, откат потребует отдельной стратегии.
Разбор после инцидента, улучшающий следующий релиз
Когда всё стабильно, напишите короткий постмортем: что вызвало откат, какие сигналы были упущены и что поменять в чеклисте. Рассматривайте это как цикл улучшения процесса релизов, а не поиск виновных.
Фича-флаги и прогрессивная доставка
Сделайте релизы рутинными
Сделайте деплои повторяемыми с хостингом, подходящим для часто создаваемых и выпускаемых приложений.
Фича-флаги позволяют разделить «деплой» (доставка кода в прод) и «релиз» (включение для людей). Это важно, потому что вы можете использовать ту же пайплайн-логику — blue/green или canary — при контроле доступа к фиче простой переключатель.
Деплой без стресса, релиз с намерением
С флагами вы можете смёржить и развернуть код, даже если функциональность ещё не готова для всех. Код присутствует, но неактивен. Когда уверены, включаете флаг поэтапно — часто это быстрее, чем новый деплой — и если что-то не так, просто выключаете флаг.
Таргетированное включение (не всё или ничего)
Прогрессивная доставка — про постепенное расширение доступа. Флаг можно включить для:
- конкретной группы пользователей (сотрудники, бета, платный тариф)
- региона (начать с одной страны или дата-центра)
- процента пользователей (1% → 10% → 50% → 100%)
Это особенно полезно, когда canary показывает, что новая версия стабильна, но вы хотите отдельно управлять риском фичи.
Ограничения, чтобы избежать «долга флагов»
Фича-флаги мощны, но требуют управления:
- владение: у каждого флага есть ответственный человек или команда
- сроки: задавайте дату удаления или ревью, чтобы старые флаги не копились
- документация: опишите, что делает флаг, кого затрагивает и как откатить
Практическое правило: если никто не может ответить "что произойдёт, когда мы выключим этот флаг?", флаг ещё не готов.
Для углублённого руководства по флагам и стратегии релизов см. /blog/feature-flags-release-strategy.
Как выбрать стратегию и начать
Выбор между blue/green и canary — не про «что лучше». Это про то, какой риск вы хотите контролировать и что ваша команда и инструменты способны операционно поддерживать.
Быстрый способ принять решение
Если приоритет — чистое, предсказуемое переключение и простой «кнопки возврата», blue/green обычно проще.
Если приоритет — уменьшение радиуса поражения и обучение по реальному трафику до полного охвата, canary безопаснее — особенно при частых релизах или сложных для тестирования изменениях.
Практическое правило: выбирайте подход, который команда сможет провести последовательно даже в 2:00 ночи, когда что-то пойдёт не так.
Начните с малого: пилот
Выберите один сервис (или один пользовательский поток) и проведите пилот для нескольких релизов. Выберите что-то важное, но не критичное до такой степени, чтобы все затаились. Цель — выстроить мышечную память по смещению трафика, мониторингу и откату.
Напишите простой ранбуk (и назначьте владельца)
Коротко — страница хватает:
- что значит «хорошо» (ключевые метрики и пороги)
- кто отвечает во время релиза
- как приостановить, откатить и коммуницировать
Убедитесь, что есть ответственный. Стратегия без владельца остаётся рекомендацией.
Используйте то, что у вас уже есть
Перед внедрением новых платформ посмотрите на уже используемые инструменты: настройки балансировщика, скрипты деплоя, существующий мониторинг и процесс инцидентов. Добавляйте новые инструменты только тогда, когда они реально снимают фрикцию, с которой вы столкнулись в пилоте.
Если вы быстро создаёте и выпускаете сервисы, платформы, объединяющие генерацию приложений и управление деплоем, тоже могут снизить операционный труд. Например, Koder.ai — платформа, позволяющая командам создавать веб- и мобильные приложения из чат-интерфейса и затем деплоить их с функционалом «snapshots и rollback», поддержкой пользовательских доменов и экспортом исходников. Такие возможности хорошо коррелируют с основной целью этой статьи: сделать релизы повторяемыми, наблюдаемыми и обратимыми.
Рекомендуемые следующие шаги
Если хотите увидеть варианты реализации и поддерживаемые рабочие процессы, просмотрите /pricing и /docs/deployments. Затем запланируйте пилотный релиз, зафиксируйте, что сработало, и итеративно улучшайте ранбук после каждого раската.