14 окт. 2025 г.·7 мин
Что такое GraphQL? Понятное руководство по API и получению данных
Узнайте, что такое GraphQL, как работают запросы, мутации и схема, когда его использовать вместо REST, а также практические плюсы, минусы и примеры.
Узнайте, что такое GraphQL, как работают запросы, мутации и схема, когда его использовать вместо REST, а также практические плюсы, минусы и примеры.
GraphQL — это язык запросов и runtime для API. Проще говоря: это способ, которым приложение (веб, мобильное или сервис) просит у API данные в виде понятного, структурированного запроса — а сервер возвращает ответ, который соответствует этому запросу.
Многие API заставляют клиентов принимать то, что возвращает фиксированный эндпоинт. Это часто приводит к двум проблемам:
С GraphQL клиент может запрашивать именно те поля, которые ему нужны, ни больше и ни меньше. Это особенно полезно, когда разные экраны (или разные приложения) требуют разных «срезов» одних и тех же данных.
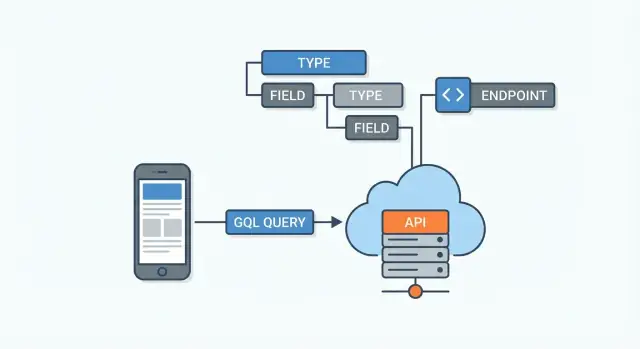
GraphQL обычно располагается между клиентскими приложениями и вашими источниками данных. Эти источники могут быть:
GraphQL‑сервер получает запрос, определяет, откуда взять каждое запрошенное поле, и затем собирает итоговый JSON‑ответ.
Думайте о GraphQL как о заказе ответа заданной формы:
GraphQL часто неверно понимают, поэтому несколько уточнений:
Если вы запомните основное определение — язык запросов + runtime для API — у вас будет правильная база для всего остального.
GraphQL был создан, чтобы решить практическую продуктовую проблему: команды тратили слишком много времени на подгонку API под реальные UI‑экраны.
Традиционные endpoint‑ориентированные API часто вынуждают выбирать между отправкой лишних данных или выполнением дополнительных вызовов, чтобы получить нужные данные. По мере роста продукта это проявляется в более медленных страницах, усложнённом коде клиента и в необходимости тесной координации между frontend и backend командами.
Перезакачка происходит, когда эндпоинт возвращает «полный» объект, даже если экрану нужно только несколько полей. Например, мобильный профиль может требовать только имя и аватар, а API возвращает адреса, настройки, поля аудита и другое. Это тратит трафик и ухудшает пользовательский опыт.
Недодача — противоположная ситуация: ни один эндпоинт не содержит всего нужного, поэтому клиент делает несколько запросов и склеивает результаты. Это добавляет задержку и увеличивает вероятность частичных ошибок.
Многие REST‑API реагируют на изменения добавлением новых эндпоинтов или версионированием (v1, v2, v3). Версионирование иногда необходимо, но оно создаёт долгую поддержку: старые клиенты продолжают использовать старые версии, а новые фичи накапливаются в других ветках.
Подход GraphQL — развивать схему за счёт добавления полей и типов со временем, сохраняя при этом существующие поля стабильными. Это часто снижает давление на создание «новых версий» только для поддержки новых UI‑потребностей.
Современные продукты редко имеют единственного потребителя. Веб, iOS, Android и партнёрские интеграции требуют разных форматов данных.
GraphQL спроектирован так, чтобы каждый клиент мог запросить именно те поля, которые ему нужны — без необходимости, чтобы бэкенд создавал отдельный эндпоинт для каждого экрана или устройства.
GraphQL‑API определяется его схемой. Думайте о ней как об соглашении между сервером и каждым клиентом: в ней перечислено, какие данные существуют, как они связаны и что можно запросить или изменить. Клиенты не угадывают эндпоинты — они читают схему и просят конкретные поля.
Схема состоит из типов (например, User или Post) и полей (например, name или title). Поля могут ссылаться на другие типы — так GraphQL моделирует связи.
Вот простой пример на SDL (Schema Definition Language):
type User {
id: ID!
name: String!
posts: [Post!]!
}
type Post {
id: ID!
title: String!
body: String
author: User!
comments: [Comment!]!
}
type Comment {
id: ID!
text: String!
author: User!
post: Post!
}
Поскольку схема строго типизирована, GraphQL может валидировать запрос до его выполнения. Если клиент запрашивает поле, которого нет (например, Post.publishDate, когда в схеме такого поля нет), сервер может отклонить запрос или частично выполнить его с явными ошибками — без двусмысленного «возможно работает» поведения.
Схемы проектируются для роста. Обычно можно добавлять новые поля (например, User.bio) без ломки существующих клиентов, потому что клиенты получают только то, что они запросили. Удаление или изменение полей чувствительнее, поэтому команды часто сначала помечают поля как deprecated и постепенно мигрируют клиентов.
GraphQL‑API обычно доступен через одну конечную точку (например, /graphql). Вместо множества URL для разных ресурсов (как /users, /users/123, /users/123/posts) вы отправляете запрос в одно место и описываете точные данные, которые хотите получить.
Запрос — это по сути «список покупок» полей. Вы можете запросить простые поля (например, id и name), а также вложенные данные (например, недавние посты пользователя) в одном запросе — без загрузки лишних полей.
Вот небольшой пример:
query GetUserWithPosts {
user(id: "123") {
id
name
posts(limit: 2) {
id
title
}
}
}
Ответы GraphQL предсказуемы: JSON, который вы получаете, зеркалит структуру запроса. Это упрощает работу на фронтенде, потому что не нужно гадать, где появятся данные или парсить разные форматы ответов.
Упрощённый пример ответа:
{
"data": {
"user": {
"id": "123",
"name": "Sam",
"posts": [
{ "id": "p1", "title": "Hello GraphQL" },
{ "id": "p2", "title": "Queries in Practice" }
]
}
}
}
Если вы не запросили поле, его не будет в ответе. Если запросили — ожидайте его в соответствующем месте, что делает GraphQL чистым способом получить именно те данные, которые нужны для экрана или фичи.
Запросы используются для чтения; мутации — для изменения данных в GraphQL‑API: создания, обновления или удаления записей.
Большинство мутаций следуют одной схеме:
input), например поля для обновления.Мутации в GraphQL обычно намеренно возвращают данные, а не просто success: true. Возврат обновлённого объекта (или хотя бы его id и ключевых полей) помогает UI:
Частый паттерн — «payload» тип, который включает и обновлённую сущность, и возможные ошибки.
mutation UpdateEmail($input: UpdateUserEmailInput!) {
updateUserEmail(input: $input) {
user {
id
email
}
errors {
field
message
}
}
}
Для API, ориентированных на UI, хорошее правило: возвращайте то, что нужно для отрисовки следующего состояния (например, обновлённый user и любые errors). Это упрощает клиент, исключает догадки о том, что поменялось, и облегчает аккуратную обработку ошибок.
Схема GraphQL описывает, что можно запрашивать. Резолверы описывают, как это получить. Резолвер — это функция, привязанная к конкретному полю в схеме. Когда клиент запрашивает это поле, GraphQL вызывает резолвер для получения или вычисления значения.
GraphQL выполняет запрос, обходя запрошенную структуру. Для каждого поля он находит соответствующий резолвер и вызывает его. Некоторые резолверы просто возвращают свойство объекта, уже находящегося в памяти; другие обращаются к базе данных, к другому сервису или комбинируют несколько источников.
Например, если в схеме есть User.posts, резолвер posts может выполнить запрос к таблице posts по userId или вызвать отдельный сервис Posts.
Резолверы — это клей между схемой и реальными системами:
Это сопоставление гибкое: вы можете менять реализацию бэкенда без изменения формы запроса клиента — пока схема остаётся стабильной.
Поскольку резолверы могут выполняться для каждого поля и для каждого элемента в списке, легко случайно запустить много маленьких вызовов (например, получить посты для 100 пользователей 100 отдельными запросами). Этот паттерн «N+1» делает ответы медленными.
Распространённые решения включают батчинг и кэширование (например, сбор ID и выборка одним запросом) и осознанный контроль за тем, какие вложенные поля вы поощряете запрашивать.
Авторизация часто реализуется в резолверах (или общем middleware), потому что резолверы знают, кто делает запрос (через context) и к каким данным обращаются. Валидация обычно происходит на двух уровнях: GraphQL обрабатывает типовую/структурную валидацию автоматически, а резолверы — бизнес‑правила (например, «только админы могут установить это поле»).
Одно, что удивляет новичков в GraphQL: запрос может «успешно выполниться» и при этом содержать ошибки. Это потому, что GraphQL ориентирован на поля: если некоторые поля удалось разрешить, а другие — нет, вы можете получить частичный набор данных.
Типичный ответ GraphQL может содержать и data, и массив errors:
{
"data": {
"user": {
"id": "123",
"email": null
}
},
"errors": [
{
"message": "Not authorized to read email",
"path": ["user", "email"],
"extensions": { "code": "FORBIDDEN" }
}
]
}
Это удобно: клиент всё ещё может отрисовать то, что есть (например, профиль пользователя), и обработать отсутствующее поле.
data часто равен null.Пишите сообщения ошибок для конечного пользователя, а не для отладки. Избегайте раскрытия трасс стека, имён баз данных или внутренних ID. Хороший паттерн:
messageextensions.coderetryable: true)Логируйте подробности на сервере с ID запроса, чтобы расследовать инциденты, не раскрывая внутренностей клиенту.
Определите небольшой «контракт» ошибок, который будут разделять веб и мобильные клиенты: общие значения extensions.code (например, UNAUTHENTICATED, FORBIDDEN, BAD_USER_INPUT), правила, когда показывать toast vs inline‑ошибки по полям, и как обрабатывать частичные данные. Согласованность предотвращает ситуацию, когда каждый клиент придумывает свои правила обработки ошибок.
Подписки (subscriptions) — это способ GraphQL пушить данные клиентам по мере их изменения, вместо того чтобы клиент спрашивал «есть ли обновления» постоянно. Обычно они работают через постоянное соединение (чаще WebSocket), чтобы сервер мог немедленно отправлять события при их появлении.
Подписка похожа на запрос, но результатом не является единичный ответ. Это поток результатов — каждое событие в потоке соответствует обновлению.
Под капотом клиент «подписывается» на тему (например, messageAdded в чате). Когда сервер публикует событие, все подключённые подписчики получают полезную нагрузку, соответствующую набору полей, указанному в подписке.
Подписки хороши, когда изменения нужно видеть мгновенно:
При polling клиент спрашивает «появилось ли что‑то?» каждые N секунд. Это просто, но часто тратит запросы (особенно если изменений нет) и ощущается с задержкой.
С подписками сервер сам отправляет обновление сразу. Это может снизить ненужный трафик и улучшить ощущение скорости — ценой поддержания соединений и управления real‑time инфраструктурой.
Подписки не всегда оправданы. Если обновления редки, не критичны по времени или их легко пакетировать, polling (или повторное получение после действия пользователя) часто достаточен.
Они добавляют операционную нагрузку: масштабирование соединений, авторизация в долгоживущих сессиях, повторные попытки и мониторинг. Правило: используйте подписки только если реальное время — это продуктовая необходимость, а не просто «приятная фича».
GraphQL часто описывают как «мощь для клиента», но у этой мощности есть издержки. Понимание компромиссов заранее помогает решить, когда GraphQL действительно подходит, а когда он избыточен.
Главное преимущество — гибкое получение данных: клиенты могут запрашивать ровно те поля, которые им нужны, что уменьшает перезакачку и ускоряет изменения UI.
Ещё один большой плюс — сильный контракт в виде схемы. Схема становится единственным источником правды по типам и доступным операциям, что улучшает сотрудничество и инструменты.
Команды часто наблюдают большой прирост продуктивности фронтенда, потому что разработчики могут итеративно добавлять фичи без ожидания новых эндпоинтов, а инструменты вроде Apollo Client помогают генерировать типы и упрощают получение данных.
GraphQL может усложнить кэширование. В REST кэш часто привязан к URL; в GraphQL многие запросы идут на одну конечную точку, поэтому кэширование опирается на форму запроса, нормализованные кэши и аккуратную конфигурацию сервер/клиент.
На сервере есть подводные камни с производительностью. Небольшой на вид запрос может вызвать множество бэкенд‑вызовов, если не продумать резолверы (решения: батчинг, предотвращение N+1, контроль дорогих полей).
Также присутствует кривая обучения: схемы, резолверы и клиентские паттерны могут быть непривычны командам, привыкшим к энпоинтам.
Поскольку клиент может запросить много данных, GraphQL‑API должны ограничивать глубину и сложность запросов, чтобы предотвратить злоупотребления или случайные «слишком большие» запросы.
Аутентификацию и авторизацию следует проверять на уровне поля, а не только на уровне маршрута, потому что разные поля могут иметь разные правила доступа.
Операционно стоит инвестировать в логирование, трейсинг и мониторинг, понимающие GraphQL: отслеживайте имена операций, переменные (аккуратно), тайминги резолверов и частоту ошибок, чтобы быстро находить медленные запросы и регрессии.
GraphQL и REST оба помогают приложениям общаться с серверами, но структурируют этот разговор по‑разному.
REST — на основе ресурсов. Вы получаете данные, вызывая разные эндпоинты (URL), представляющие «вещи», например /users/123 или /orders?userId=123. Каждый эндпоинт возвращает фиксированную форму данных, определённую сервером.
REST также опирается на семантику HTTP: методы GET/POST/PUT/DELETE, коды статусов и правила кэширования. Это удобно при простом CRUD или когда критично кэширование на уровне браузера/прокси.
GraphQL — на основе схемы. Вместо множества эндпоинтов вы обычно имеете одну конечную точку, и клиент посылает запрос, описывающий нужные поля. Сервер валидирует запрос по схеме GraphQL и возвращает ответ, соответствующий форме запроса.
Эта «выборка клиентом» причина, по которой GraphQL часто сокращает перезакачку и недодачу, особенно для UI‑экранов, которым нужны данные из нескольких связанных моделей.
REST чаще подходит, когда:
Многие команды смешивают подходы:
Практический вопрос не «что лучше?», а «что подходит этой задаче с наименьшей сложностью?».
Проектирование GraphQL‑API проще, если рассматривать его как продукт для людей, создающих экраны, а не как точную копию вашей базы данных. Начинайте с малого, проверяйте на реальных сценариях и расширяйте по мере роста потребностей.
Перечислите ключевые экраны (например, «Список продуктов», «Детали продукта», «Оформление заказа»). Для каждого экрана выпишите точные поля и взаимодействия, которые нужны.
Это помогает избежать «бог‑запросов», уменьшает перезакачку и проясняет, где нужны фильтрация, сортировка и пагинация.
Сначала определите основные типы (например, User, Product, Order) и их связи. Затем добавьте:
Предпочитайте именование, отражающее бизнес‑логику, а не структуру базы. "placeOrder" лучше передаёт смысл, чем "createOrderRecord".
Держите имена согласованными: единственное для элемента (product), множественное для коллекций (products). Для пагинации обычно выбирают одно из двух:
Решение на раннем этапе важно, так как оно формирует структуру ответов API.
GraphQL поддерживает описания прямо в схеме — используйте их для типов, аргументов и тонкостей. Добавьте примерчики в документацию (включая пагинацию и общие сценарии ошибок). Хорошо описанная схема делает introspection и API‑explorers гораздо полезнее.
Начать с GraphQL значит выбрать пару надёжных инструментов и настроить рабочий процесс. Не нужно брать всё сразу — настройте один запрос от начала до конца и расширяйтесь.
Выбирайте сервер по вашему стеку и по тому, сколько «из коробки» вы хотите получить:
Практический шаг: опишите небольшую схему (пара типов + один запрос), реализуйте резолверы и подключите реальный источник данных (хотя бы список в памяти).
Если хотите быстрее перейти от идеи к рабочему API, платформы вроде Koder.ai могут помочь с генерацией прототипа full‑stack (React на фронтенде, Go + PostgreSQL на бэкенде) и итерацией по схеме/резолверам через чат — затем можно экспортировать код.
На фронтенде выбор часто зависит от желания иметь опинионированные конвенции или гибкость:
Если вы мигрируете с REST, начните с GraphQL для одного экрана или фичи и пока держите REST для остального, пока подход не подтвердит себя.
Рассматривайте схему как контракт API. Полезные уровни тестирования:
Чтобы углубиться, продолжите с:
GraphQL — это язык запросов и runtime для API. Клиенты отправляют запрос, описывающий точные поля, которые им нужны, а сервер возвращает JSON-ответ, повторяющий эту структуру.
Проще всего думать о GraphQL как об уровне между клиентами и одним или несколькими источниками данных (базы данных, REST‑сервисы, сторонние API, микросервисы).
GraphQL в первую очередь решает две проблемы:
Разрешая клиенту запрашивать только конкретные поля (включая вложенные), GraphQL снижает лишнюю передачу данных и упрощает код клиента.
GraphQL — не:
Рассматривайте его как контракт API + механизм исполнения, а не как панацею для хранения или производительности.
Большинство GraphQL‑API экспонируют единую конечную точку (часто /graphql). Вместо множества URL вы отправляете разные операции (queries/mutations) на эту одну точку.
Практическое следствие: кэширование и наблюдаемость чаще зависят от имени операции + переменных, а не от URL.
Схема — это контракт API. Она определяет:
User, Post)User.name)User.posts)Поскольку схема , сервер может валидировать запросы до их выполнения и давать понятные ошибки, когда поля не существуют.
Запросы GraphQL — это операции чтения. Вы указываете нужные поля, и возвращаемый JSON соответствует структуре запроса.
Советы:
query GetUserWithPosts) для лучшей отладки и мониторинга.posts(limit: 2)).Мутации — это операции записи (create/update/delete). Частая схема:
inputВозвращать данные (а не просто success: true) удобно для UI: это позволяет мгновенно обновить экран и поддерживать кэш в согласованном состоянии.
Резолверы — это функции на уровне поля, которые объясняют, как получить или вычислить значение поля.
На практике резолверы могут:
Авторизация часто проверяется в резолверах (или в общем middleware), потому что они знают, кто делает запрос и к каким данным обращаются.
Легко создать паттерн N+1 (например, загружать посты отдельно для каждого из 100 пользователей).
Распространённые решения:
Измеряйте время выполнения резолверов и следите за повторяющимися внешними вызовами в рамках одного запроса.
GraphQL может вернуть частичные данные вместе с массивом errors. Это случается, когда некоторые поля удалось разрешить, а другие — нет (например, поле запрещено или произошёл таймаут во внешнем сервисе).
Хорошие практики:
messageextensions.code (например, FORBIDDEN, BAD_USER_INPUT)Клиенты должны решить, когда рендерить частичные данные, а когда считать операцию полностью неудачной.