Kafka простыми словами
Apache Kafka — это распределённая платформа для потоковой передачи событий. Проще говоря, это общий долговечный «трубопровод», который позволяет множеству систем публиковать факты о том, что произошло, а другим системам — читать эти факты быстро, в масштабе и в порядке.
Команды используют Kafka, когда данные нужно перемещать надёжно между системами без тесной связки. Вместо того чтобы одно приложение напрямую вызывало другое (и терпело неудачу, если оно упало или стало медленным), продюсеры записывают события в Kafka. Потребители читают их, когда готовы. Kafka хранит события в течение настраиваемого периода, так что системы могут восстановиться после сбоев и даже переработать историю.
Несколько терминов, которые вы встретите
- Событие / Сообщение: запись о том, что произошло (например, «OrderPlaced» или «PaymentFailed»). Пользователи Kafka часто говорят «сообщение», но «событие» подчёркивает, что это изменение в реальном мире.
- Поток: непрерывный поток событий во времени.
- Лог: Kafka организует события как лог с добавлением в конец — новые события добавляются в конец, а читатели двигаются вперёд в своём темпе.
Для кого это руководство (и что вы узнаете)
Это руководство для инженеров, ориентированных на продукт, специалистов по данным и технических лидеров, которые хотят практическую ментальную модель Kafka.
Вы узнаете основные строительные блоки (producers, consumers, topics, brokers), как Kafka масштабируется с помощью партиций, как она хранит и воспроизводит события и где она вписывается в событийно-ориентированную архитектуру. Мы также рассмотрим типичные сценарии использования, гарантии доставки, основы безопасности, планирование эксплуатации и когда Kafka — (или не) подходящий инструмент.
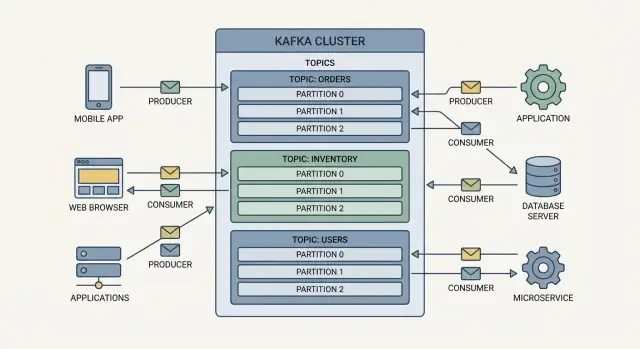
Основные понятия: продюсеры, потребители, топики, брокеры
Kafka проще всего понимать как общий лог событий: приложения записывают события туда, а другие приложения читают их позже — часто в реальном времени, иногда через часы или дни.
Продюсеры и потребители
Продюсеры — это записывающие стороны. Продюсер может публиковать событие вроде «order placed», «payment confirmed» или «temperature reading». Продюсеры не отправляют события напрямую конкретным приложениям — они отправляют их в Kafka.
Потребители — это читающие стороны. Потребитель может обновлять дашборд, запускать рабочий процесс отгрузки или загружать данные в аналитику. Потребители решают, что делать с событиями, и могут читать в своём темпе.
Топики: организация событий
События в Kafka группируются в топики, которые по сути являются именованными категориями. Например:
orders для событий, связанных с заказамиpayments для платежных событийinventory для изменений запасов
Топик становится «источником правды» для этого типа событий, что облегчает повторное использование данных несколькими командами без создания одноразовых интеграций.
Брокеры и кластеры
Брокер — это сервер Kafka, который хранит события и отдаёт их потребителям. Практически Kafka работает как кластер (несколько брокеров вместе), чтобы справляться с большим трафиком и оставаться работоспособным при падении машины.
Группы потребителей: масштабирование чтения без дублирования работы
Потребители часто работают в группе потребителей. Kafka распределяет чтение между участниками группы, так что вы можете добавить больше экземпляров потребителя для масштабирования обработки — без того, чтобы каждый экземпляр выполнял ту же работу.
Как топики и партиции позволяют Kafka масштабироваться
Kafka масштабируется, разделяя работу на топики (потоки связанных событий) и затем разбивая каждый топик на партиции (меньшие независимые куски этого потока).
Партиции = параллелизм и пропускная способность
Топик с одной партицией может быть прочитан только одним потребителем одновременно в рамках группы потребителей. Добавьте партиций — и вы сможете добавить больше потребителей для параллельной обработки событий. Так Kafka поддерживает высокообъёмную потоковую передачу событий и конвейеры данных в реальном времени, не превращая каждую систему в узкое место.
Партиции также помогают распределять нагрузку по брокерам. Вместо одной машины, которая обрабатывает все записи и чтения для топика, несколько брокеров могут размещать разные партиции и делить трафик.
Упорядоченность: что Kafka гарантирует (и что нет)
Kafka гарантирует упорядоченность в пределах одной партиции. Если события A, B и C записаны в ту же партицию в таком порядке, потребители прочитают их A → B → C.
Упорядоченность между разными партициями не гарантируется. Если вам нужен строгий порядок для конкретной сущности (например, клиента или заказа), обычно всё событие для этой сущности направляют в одну партицию.
Ключи решают, куда уходят события
Когда продюсер отправляет событие, он может включить ключ (например, order_id). Kafka использует ключ, чтобы последовательно маршрутизировать связанные события в одну и ту же партицию. Это даёт предсказуемое упорядочивание по ключу, при этом общий топик масштабируется по многим партициям.
Реплики поддерживают доступность данных
Каждая партиция может быть реплицирована на другие брокеры. Если один брокер выходит из строя, другой с репликой может взять на себя. Репликация — одна из причин, по которой Kafka доверяют для критичных систем: она повышает доступность и поддерживает отказоустойчивость без необходимости реализовывать собственную логику фейловера в каждом приложении.
Хранение, ретенция и повторное проигрывание событий
Ключевая идея в Apache Kafka — события не просто передаются и забываются. Они записываются на диск в упорядоченный лог, поэтому потребители могут читать их сейчас или позже. Это делает Kafka полезной не только для перемещения данных, но и для хранения долговечной истории происходящего.
События персистятся, а не просто «в пути»
Когда продюсер отправляет событие в топик, Kafka дописывает его в хранилище на брокере. Потребители затем читают из этого хранимого лога в своём темпе. Если потребитель не работал в течение часа, события всё ещё существуют, и он сможет наверстать после восстановления.
Ретенция: как долго Kafka хранит данные
Kafka хранит события в соответствии с политиками ретенции:
- Ретенция по времени: хранить события в течение заданного периода (например, 7 дней).
- Ретенция по объёму: хранить события, пока лог не достигнет настроенного размера, затем удалять самые старые данные.
Ретенция конфигурируется на уровне топика, что позволяет по-разному относиться к «аудиторским» топикам и к высокообъёмной телеметрии.
Компактация: хранение последнего значения по ключу
Некоторые топики больше похожи на журнал изменений, чем на исторический архив — например, «текущие настройки клиента». Логовая компактция сохраняет по крайней мере последнее событие для каждого ключа, при этом старые устаревшие записи могут удаляться. Вы по-прежнему получаете долговой источник истины для актуального состояния без неограниченного роста данных.
Повторное проигрывание событий: восстановление состояния и исправление ошибок
Поскольку события остаются в хранилище, вы можете повторно проигрывать их, чтобы восстановить состояние:
- перестроить индекс поиска или материализованное представление с нуля
- восстановить сервис после неудачного деплоя, переобработав с более ранней точки
- подключить нового потребителя и дать ему прочитать исторические данные
На практике воспроизведение контролируется откуда потребитель «начинает читать» (его оффсетом), что даёт командам мощную подстраховку при эволюции систем.
Основы надёжности и отказоустойчивости
Kafka создана так, чтобы данные продолжали течь даже при сбоях частей системы. Она делает это с помощью репликации, чётких правил о том, кто «владеет» партицией, и настраиваемых подтверждений записи.
Репликация: лидер и фолловеры (в общих чертах)
У каждой партиции топика есть один лидер и один или несколько фолловеров-реплик на других брокерах. Продюсеры и потребители общаются с лидером этой партиции.
Фолловеры непрерывно копируют данные лидера. Если лидер падает, Kafka может поднять актуального фолловера до роли лидера, чтобы партиция оставалась доступной.
Что происходит при падении брокера (кратко)
Если брокер падает, партиции, для которых он был лидером, становятся недоступны на короткое время. Контроллер Kafka обнаруживает проблему и запускает выбор лидера для этих партиций.
Если хотя бы одна фолловер-реплика достаточно синхронизирована, она может стать новым лидером и клиенты продолжат производить/потреблять. Если ни одна из реплик не в синхронизации, Kafka может приостановить записи (в зависимости от настроек), чтобы избежать потери подтверждённых данных.
Долговечность: фактор репликации и подтверждения
Два основных параметра, влияющих на долговечность:
- Replication factor: сколько копий каждой партиции хранится (например, 3 копии на 3 брокерах).
- Acknowledgments (acks): когда продюсер считает запись успешной.
В общих чертах:
- acks=0: продюсер не ждёт подтверждения — быстро, но возможна потеря сообщений.
- acks=1: лидер подтверждает запись — лучше, но если лидер упадёт до копирования фолловерами, можно потерять недавние записи.
- acks=all (или -1): лидер ждёт подтверждений от всех «в синхронизации» реплик — безопаснее, обычно немного медленнее.
Чтобы уменьшить дубли при повторных попытках, команды часто совмещают надёжные acks с идемпотентными продюсерами и корректной обработкой потребителей.
Компромисс задержка ↔ безопасность
Бóльшая безопасность обычно означает ждать больше подтверждений и держать больше реплик синхронизированными, что может добавить задержку и снизить пиковую пропускную способность.
Ниже задержка подходит для телеметрии или кликового потока, где допустима потеря; но для платежей, запасов и аудита обычно оправдана большая безопасность.
Роль Kafka в событийно-ориентированной архитектуре
Получайте кредиты за рекомендации
Поделитесь тем, что вы создали с Koder.ai, или порекомендуйте коллегу — и получайте кредиты.
Событийно-ориентированная архитектура (EDA) — это способ построения систем, где события бизнеса (заказ создан, оплата подтверждена, посылка отправлена) представлены как события, на которые другие части системы могут реагировать.
Публикация событий, реакция потребителей
Kafka часто находится в центре EDA как общий «поток событий». Вместо того, чтобы Сервис A вызывал Сервис B напрямую, Сервис A публикует событие (например, OrderCreated) в топик Kafka. Любое число других сервисов может потреблять это событие и реагировать — отправить письмо, зарезервировать запас, запустить проверку на мошенничество — без того чтобы Сервис A знал о них.
Слабая связанность (меньше прямых зависимостей)
Поскольку сервисы общаются через события, им не нужно согласовывать request/response API для каждой интеракции. Это уменьшает жёсткие зависимости между командами и упрощает добавление новых возможностей: можно ввести нового потребителя для имеющегося события без изменения продюсера.
Асинхронные рабочие процессы и устойчивость к пикам
EDA по своей природе асинхронна: продюсеры записывают события быстро, а потребители обрабатывают их в своём темпе. При пиковых нагрузках Kafka помогает буферизовать всплеск, чтобы downstream-системы не рухнули сразу. Потребители могут масштабироваться, чтобы нагнать отставание, и если один потребитель временно упадёт, он может возобновить чтение с места остановки.
Практическая ментальная модель
Думайте о Kafka как о «ленте активности» системы. Продюсеры публикуют факты; потребители подписываются на те факты, которые им нужны. Этот паттерн позволяет строить конвейеры данных в реальном времени и событийно-ориентированные рабочие процессы, при этом сервисы остаются проще и независимее.
Частые сценарии использования Kafka в современных системах
Kafka обычно появляется там, где нужно перемещать много мелких «фактов, что произошло» между системами — быстро, надёжно и так, чтобы несколько потребителей могли повторно использовать данные.
Трекинг активности и аудиторские логи
Приложения часто нуждаются в append-only истории: входы пользователей, изменения прав, обновления записей или действия администраторов. Kafka хорошо подходит как центральный поток этих событий, чтобы инструменты безопасности, отчётности и экспорта соответствовали одному источнику. Поскольку события хранятся в течение времени, их можно воспроизвести, чтобы восстановить аудит после ошибки или изменения схемы.
Связь микросервисов через события
Вместо прямых вызовов сервисы могут публиковать события вроде «order created» или «payment received». Другие сервисы подписываются и реагируют в своё время. Это уменьшает жёсткую связанность, помогает системам продолжать работу при частичных отказах и упрощает добавление новых возможностей (например, проверки на мошенничество) просто через потребление существующего потока.
Конвейеры данных в аналитику и хранилища
Kafka часто служит основой для переноса данных из операционных систем в аналитические платформы. Команды могут стримить изменения из баз данных и доставлять их в хранилище или data lake с низкой задержкой, сохраняя отделение продакшн-приложения от тяжёлых аналитических запросов.
IoT и телеметрия с пиковой нагрузкой
Датчики, устройства и телеметрия приложений часто приходят всплесками. Kafka способна поглотить импульсы, буферизовать их безопасно и позволить последующей обработке нагнать отставание — полезно для мониторинга, алёртинга и долгосрочного анализа.
Экосистема Kafka: Connect, Streams и инструменты
Kafka — это не только брокеры и топики. Большинство команд полагаются на сопутствующие инструменты, которые делают Kafka практичной для ежедневного перемещения данных, обработки потоков и эксплуатации.
Kafka Connect: перемещение данных без кастомного кода
Kafka Connect — это фреймворк интеграции Kafka для получения данных в Kafka (sources) и вывода из Kafka (sinks). Вместо поддержки одноразовых конвейеров вы запускаете Connect и настраиваете коннекторы.
Типичные примеры: чтение изменений из баз данных, приём событий SaaS или доставка данных из Kafka в хранилище/объектное хранилище. Connect также стандартизирует эксплуатационные аспекты: повторные попытки, оффсеты и параллелизм.
Kafka Streams: обработка в реальном времени внутри приложений
Если Connect отвечает за интеграцию, то Kafka Streams отвечает за вычисления. Это библиотека, которую вы добавляете в приложение для трансформации потоков в реальном времени — фильтрация событий, обогащение, объединение потоков и построение агрегатов (например, «заказов в минуту»).
Поскольку Streams-приложения читают из топиков и записывают обратно в топики, они естественно вписываются в EDA и масштабируются добавлением экземпляров.
Управление схемой: поддержание согласованности событий
По мере того как несколько команд публикуют события, важна согласованность. Управление схемой (часто через schema registry) определяет, какие поля должно иметь событие и как они могут эволюционировать. Это помогает избежать поломок, например когда продюсер переименовал поле, от которого зависит потребитель.
Инструменты: мониторинг ключевых метрик
Kafka чувствительна к эксплуатации, поэтому базовый мониторинг обязателен:
- Задержание потребителя (consumer lag): не отстают ли потребители?
- Пропускная способность: сколько событий в секунду проходит?
- Ошибки: ошибки fetch/produce, падения задач коннекторов
Большинство команд также используют UI для управления и автоматизацию для развёртываний, конфигурации топиков и политик доступа (см. /blog/kafka-security-governance).
Гарантии доставки и шаблоны обработки
Спланируйте конвейер Kafka
Отобразите топики, ключи, партиции и потребителей до написания кода в режиме планирования.
Kafka часто сводят к «долговечный лог + потребители», но что важнее для команд: «обработаю ли я каждое событие ровно один раз, и что происходит при сбое?» Kafka даёт строительные блоки, а вы выбираете компромиссы.
Гарантии доставки (вкратце)
At-most-once — вы можете потерять события, но не обработаете дубликаты. Такое поведение возникает, если потребитель закоммитил позицию раньше, чем завершил работу, и затем упал.
At-least-once — вы не потеряете события, но возможны дубликаты (например, потребитель обработал событие, упал и затем обработал его снова). Это наиболее распространённый режим по умолчанию.
Exactly-once стремится избежать и потерь, и дубликатов сквозь всю систему. В Kafka это обычно достигается через транзакционные продюсеры и совместимую обработку (часто через Kafka Streams). Это мощно, но требует аккуратной настройки и ограничений.
Идемпотентность и дедупликация
На практике многие системы принимают at-least-once и добавляют меры защиты:
- Идемпотентные записи: сделайте шаг «применения события» безопасным при повторе (upsert, условные обновления, уникальные ключи).
- Дедупликация: храните ID события (или бизнес-ключ) и игнорируйте повторы в пределах окна.
Оффсеты потребителей: ваши «закладки»
Оффсет — это позиция последней обработанной записи в партиции. При коммите оффсета вы говорите: «я завершил до этого места». Коммит слишком ранний → риск потери; слишком поздний → больше дублей после восстановления.
Повторы и «ядовитые» сообщения
Повторы должны быть ограничены и видимы. Распространённый паттерн:
- повторы с экспоненциальным бэкоффом для временных ошибок,
- затем отправка неудачных записей в dead-letter топик для инспекции и возможного повторного проигрывания.
Это не даёт одному сообщению блокировать всю группу потребителей, сохраняя при этом данные для последующего исправления.
Безопасность и вопросы управления данными
Kafka часто переносит бизнес-критичные события (заказы, платежи, активность пользователей). Поэтому безопасность и управление данными — часть дизайна, а не последума.
Аутентификация и авторизация
Аутентификация отвечает на «кто вы?», авторизация — на «что вам разрешено?». В Kafka аутентификация обычно делается через SASL (например, SCRAM или Kerberos), а авторизация — через ACL (списки контроля доступа) на уровне топиков, групп потребителей и кластера.
Практика — принцип наименьших привилегий: продюсеры пишут только в свои топики, потребители читают только нужные топики. Это снижает риск случайного доступа и уменьшает радиус возможного ущерба при компрометации учётных данных.
Шифрование в транзите (TLS)
TLS шифрует данные при передаче между приложениями, брокерами и инструментами. Без TLS события можно перехватить в внутренних сетях, не только в публичном интернете. TLS также помогает предотвращать атаки «man-in-the-middle», проверяя идентичность брокера.
Мультиарендность Kafka и соглашения по именованию
Когда несколько команд делят кластер, нужны защитные механизмы. Чётные соглашения по именованию топиков (например, <team>.<domain>.<event>.<version>) делают ownership очевидным и помогают автоматизации применять политики последовательно.
Сопровождайте соглашения квотами и шаблонами ACL, чтобы один шумный рабочий процесс не задушил остальных, и чтобы новые сервисы стартовали с безопасными настройками по умолчанию.
Управление данными: PII, ретенция и соответствие
Рассматривайте Kafka как систему учёта истории событий только тогда, когда это намеренно. Если события содержат PII, применяйте минимизацию данных (отправляйте идентификаторы вместо полных профилей), рассматривайте полевое шифрование и документируйте, какие топики чувствительны.
Настройки ретенции должны соответствовать юридическим и бизнес-требованиям. Если политика говорит «удалять через 30 дней», не храните 6 месяцев «на всякий случай». Регулярные ревью и аудиты помогают поддерживать конфигурации в актуальном соответствии с требованиями.
Эксплуатация Kafka: что команде нужно планировать
Быстро создайте демо Kafka
Превратите вашу модель Kafka в рабочее producer/consumer-приложение через чат.
Запуск Apache Kafka — это не «установил и забыл». Она ведёт себя скорее как общая служба: многие команды зависят от неё, и небольшие ошибки могут распространиться на downstream-приложения.
Базовое планирование ёмкости
Ёмкость Kafka — в основном задача расчёта, которую нужно пересматривать регулярно. Главные рычаги: партиции (параллелизм), пропускная способность (MB/s вход/выход) и рост хранилища (как долго вы храните данные).
Если трафик удваивается, может понадобиться больше партиций для распределения нагрузки по брокерам, больше диска для удержания ретенции и больше сетевого ресурса для репликации. Практическая привычка — прогнозировать пиковую скорость записи и умножать её на ретенцию, чтобы оценить рост диска, затем добавлять запас для репликации и «неожиданного успеха».
Рутинные операционные задачи
Ожидайте рутинной работы помимо поддержания серверов в рабочем состоянии:
- Обновления: планируйте скользящие обновления, тестируйте совместимость клиентов и выбирайте окна с наименьшим трафиком.
- Ребалансировка: ребалансы групп потребителей могут вызвать кратковременные паузы; нужны безопасные паттерны деплоя и понятная ответственность владельцев.
- Инцидент-ответ: имейте плейбуки для падения брокеров, переполнения диска и неправильно настроенных продюсеров, заливающих топик.
Драйверы стоимости и варианты развёртывания
Затраты определяются дисками, исходящим трафиком сети и количеством/размером брокеров. Управляемые Kafka-сервисы могут снизить нагрузку на команду и упростить обновления, тогда как собственное хостирование может быть дешевле в масштабе, если у вас есть опытные операторы. Компромисс — время восстановления и нагрузка на on-call команду.
Что измерять (чтобы не гадать)
Команды обычно мониторят:
- Сквозную задержку (produce → consume)
- Задержание потребителя (на сколько отстают потребители)
- Состояние брокера (использование диска, недореплированные партиции, ошибки запросов)
Хорошие дашборды и алёрты превращают Kafka из «чёрного ящика» в понятный сервис.
Когда использовать Kafka (и когда нет)
Kafka отлично подходит, когда нужно надёжно перемещать много событий, хранить их некоторое время и позволять множеству систем реагировать на одни и те же данные в своём темпе. Особенно полезна, когда требуется воспроизводимость данных (для бэктрека, аудитов или восстановления сервиса) и когда ожидается рост числа продюсеров/потребителей со временем.
Когда Kafka — отличное решение
Kafka проявляет себя при:
- потоках с высокой пропускной способностью (клики, заказы, сенсорные данные)
- множестве потребителей, нуждающихся в одних и тех же событиях (аналитика, мониторинг, антифрод, уведомления)
- необходимости воспроизведения и долговременной истории, а не просто «доставить и забыть»
- интеграционных задачах, где важно разграничение команд и сервисов
Когда Kafka может быть излишней
Kafka может быть избыточной, если ваши потребности просты:
- одна низкообъёмная очередь между двумя сервисами
- краткоживущие задачи (фоновые джобы), где воспроизведение не нужно
- команды, у которых нет ресурсов на эксплуатацию и мониторинг распределённой системы
В этих случаях операционные издержки (подбор размера кластера, обновления, мониторинг, on-call) могут перевесить преимущества.
Альтернативы и дополнения
- RabbitMQ: хорош для классических рабочих очередей и маршрутизации.
- NATS: лёгкие сообщения с низкой задержкой.
- Облачные pub/sub сервисы: подходят, если вы хотите управляемую инфраструктуру и упрощённую эксплуатацию.
Kafka также дополняет, но не заменяет: БД (system of record), кеши (быстрое чтение) и batch ETL (большие периодические преобразования).
Быстрый чеклист для решения
Спросите себя:
- Нужны ли нам несколько потребителей и возможность воспроизведения?
- Будет ли существенно расти пропускная способность?
- Нужна ли история/ретенция событий как функция?
- Можем ли мы обеспечить эксплуатационную поддержку (или взять управляемый Kafka)?
- Мы стримим события, а не просто отправляем команды/задачи?
Если на большинство вопросов ответ «да», Kafka обычно — разумный выбор.
Начало работы: простой путь внедрения
Kafka лучше всего подходит, когда вам нужен общий «источник правды» для потоков событий в реальном времени: много систем публикуют факты (создан заказ, авторизована оплата, изменился запас), и много систем потребляют эти факты для конвейеров, аналитики и реактивных фич.
Шаг 1: выберите одну конкретную задачу
Начните с узкого, ценного потока — например, публикация событий «OrderPlaced» для downstream-сервисов (email, антифрод, исполнение). Не превращайте Kafka в универсальную очередь с первого дня.
Шаг 2: определите события и топики
Запишите:
- События: что произошло, простыми бизнес-терминами
- Топики: где живут эти события (часто один топик на тип события или домен)
- Потребители: какие команды/сервисы нуждаются в событиях и зачем
Держите ранние схемы простыми и последовательными (временные метки, ID и понятное имя события). Решите заранее — будете ли вы строго применять схемы или эволюционировать аккуратно.
Шаг 3: установите владение и базовую эксплуатацию
Kafka успешна, когда кто-то отвечает за:
- создание топиков и соглашения по именованию
- политики ретенции и доступа
- обязанности on-call и плейбуки
Добавьте мониторинг сразу (consumer lag, здоровье брокеров, пропускная способность, ошибки). Если у вас ещё нет платформенной команды, начните с управляемого предложения и чётких лимитов.
Шаг 4: постройте «тонкий» первый конвейер
Произведите события из одной системы, потребьте их в одном месте и докажите замкнутый цикл end-to-end. Только потом расширяйте число потребителей, партиций и интеграций.
Если нужно быстро перейти от идеи к работающему событийно-ориентированному сервису, инструменты вроде Koder.ai помогают прототипировать сопутствующее приложение (React UI, Go backend, PostgreSQL) и итеративно добавлять продюсеров/потребителей Kafka через диалоговый рабочий процесс. Это удобно для создания внутренних дашбордов и лёгких сервисов-потребителей топиков, с возможностями планирования, экспорта кода, развёртывания и снимков со скатом назад.
Если вы проектируете EDA, посмотрите /blog/event-driven-architecture. Для оценки стоимости и окружений — /pricing.