14 нояб. 2025 г.·8 мин
Craig McLuckie и cloud-native: побеждает платформенное мышление
Практический взгляд на роль Craig McLuckie в принятии cloud-native и на то, как платформенное мышление превратило контейнеры в надёжную продакшен-инфраструктуру.
Практический взгляд на роль Craig McLuckie в принятии cloud-native и на то, как платформенное мышление превратило контейнеры в надёжную продакшен-инфраструктуру.
Команды не испытывают проблем потому что не умеют запустить контейнер. Проблемы возникают, когда нужно безопасно управлять сотнями контейнеров, обновлять их без простоя, восстанавливаться при ошибках и при этом выпускать фичи по графику.
История «cloud-native» в контексте Craig McLuckie важна тем, что это не пафосный отчёт о красивых демо. Это запись о том, как контейнеры стали операбельными в реальных условиях — там, где случаются инциденты, есть требования по соответствию и бизнес ожидает предсказуемой доставки.
«Cloud-native» — это не просто «работать в облаке». Это подход к созданию и эксплуатации ПО, при котором можно часто разворачивать, масштабироваться при изменении спроса и быстро исправлять сбои.
На практике это обычно означает:
Ранние попытки использовать контейнеры напоминали набор инструментов: команды брали Docker, склеивали скриптами и надеялись, что операция справится. Платформенное мышление меняет это. Вместо того чтобы каждая команда изобретала собственный путь в продакшен, строят общие «покрытые дороги» — платформу, которая делает безопасный, соответствующий и наблюдаемый путь ещё и простым.
Этот сдвиг — мост от «мы умеем запускать контейнеры» к «мы можем вести бизнес на их основе».
Для тех, кто отвечает за результаты, а не только за архитектурные схемы:
Если ваша цель — надёжная доставка в масштабе, эта история содержит практические уроки.
Craig McLuckie — одно из наиболее узнаваемых имён, связанных с ранним cloud-native движением. Его часто упоминают в разговорах про Kubernetes, Cloud Native Computing Foundation (CNCF) и идею того, что инфраструктуру стоит воспринимать как продукт — а не как кучу тикетов и устных знаний.
Важно быть точным. McLuckie не «один изобретал cloud-native», и Kubernetes никогда не был продуктом одного человека. Kubernetes создали команды в Google, и McLuckie был частью раннего усилия.
За что его часто ценят — это умение превратить инженерную идею в то, что индустрия могла реально принять: усиление работы с сообществом, более понятная упаковка и продвижение повторяемых операционных практик.
Через историю Kubernetes и эпоху CNCF послание McLuckie было не про модные архитектуры, а про предсказуемость продакшена. Это означает:
Если вы слышали термины «paved roads», «golden paths» или «platform as a product», вы обходите ту же идею: снизить когнитивную нагрузку команд, сделав правильное действие простым.
Этот пост — не биография. McLuckie служит удобной опорной точкой, поскольку его работа лежит на пересечении трёх сил, изменивших доставку ПО: контейнеры, оркестрация и построение экосистемы. Уроки здесь не про личность — они про то, почему платформенное мышление оказалось ключом к запуску контейнеров в реальном продакшене.
Идея контейнеров возникла задолго до того, как ярлык «cloud-native» стал общим. Проще говоря, контейнер — это способ упаковать приложение вместе с файлами и библиотеками, которые ему нужны, чтобы оно работало одинаково на разных машинах — как отправить товар в закрытой коробке со всеми деталями внутри.
На старте многие команды использовали контейнеры для побочных проектов, демо и рабочих процессов разработчиков. Они отлично подходили для быстрого прототипирования сервисов, поднятия тестовых окружений и уменьшения «работает у меня» при передаче работы.
Но переход от нескольких контейнеров к продакшен-системе, работающей 24/7 — это уже другая задача. Инструментарий был, но операционная история была неполной.
Типичные проблемы проявлялись быстро:
Контейнеры помогли сделать ПО портативным, но портативность сама по себе не гарантировала надёжности. Командам всё ещё требовались согласованные практики релизов, чёткая ответственность и операционные ограждения — чтобы контейнеризованные приложения не работали лишь эпизодически, а функционировали предсказуемо каждый день.
Платформенное мышление — это момент, когда компания перестаёт относиться к инфраструктуре как к разовому проекту и начинает воспринимать её как внутренний продукт. «Клиенты» — это ваши разработчики, аналитики данных и все, кто выпускает ПО. Цель продукта — не больше серверов или YAML, а более плавный путь от идеи до продакшена.
У настоящей платформы есть чёткое обещание: «Если вы строите и деплоите через эти пути, вы получите надёжность, безопасность и предсказуемую доставку». Это обещание требует продуктовых привычек — документации, поддержки, версионирования и обратной связи. Нужен продуманный пользовательский опыт: разумные настройки по умолчанию, покрытые дороги и запасной выход, когда командам действительно нужен уникальный путь.
Стандартизация снимает усталость от принятия решений и предотвращает случайную сложность. Когда команды разделяют одни и те же паттерны деплоя, логирования и контроля доступа, проблемы становятся повторяемыми — а значит решаемыми. Дежурство улучшаетcя, потому что инциденты выглядят знакомо. Безопасность проходит быстрее, поскольку платформа закладывает ограждения, а не полагается на то, что каждая команда всё заново изобретёт.
Речь не о том, чтобы загнать всех в одну коробку. Скорее — договориться об 80% вещей, которые должны быть скучными, чтобы команды могли сосредоточиться на тех 20%, которые приносят ценность бизнесу.
Раньше инфраструктура часто зависела от особых знаний: несколько людей знали, какие сервера запатчены, какие настройки безопасны и какие скрипты — «правильные». Платформенное мышление заменяет это повторяемыми паттернами: шаблоны, автоматизированное provision-ление и согласованные окружения от разработки до продакшена.
Правильно сделанные платформы обеспечивают лучшее управление при меньшем количестве бумажной работы. Политики становятся автоматическими проверками, согласования — аудируемыми рабочими процессами, а доказательства соответствия генерируются по мере деплоя — так организация получает контроль, не замедляя всех.
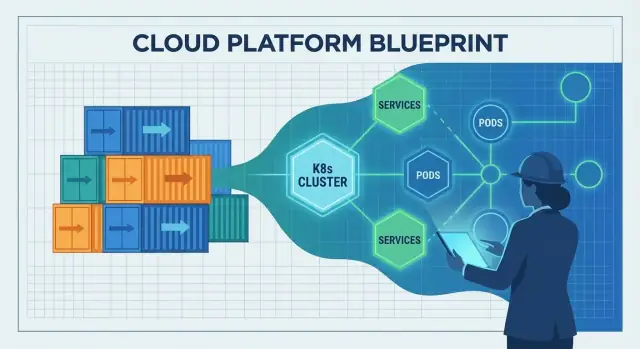
Контейнеры упростили упаковку и доставку приложения. Сложность начиналась после развёртывания: где его разместить, как поддерживать в здоровом состоянии и как адаптироваться при росте нагрузки или отказах инфраструктуры.
Это пустота, которую заполнил Kubernetes. Он превратил «кучу контейнеров» в объект, которым можно управлять день за днём, даже когда серверы падают, выходят новые релизы и растёт нагрузка.
Kubernetes часто называют «оркестратором контейнеров», но практические проблемы точнее такие:
Без оркестратора команды начинают скриптовать эти поведения и вручную управлять исключениями — пока скрипты не перестают соответствовать реальности.
Kubernetes популяризировал идею общего control plane: одно место, где вы объявляете, чего хотите («запусти 3 копии этого сервиса»), а платформа постоянно работает, чтобы реальность соответствовала этому намерению.
Это большой сдвиг в распределении ответственности:
Kubernetes не появился просто потому что контейнеры стали модными. Он вырос из уроков по эксплуатации больших флотилий: воспринимать инфраструктуру как систему с обратными связями, а не как набор разовых задач на серверах. Этот операционный подход — причина, по которой он стал мостом от «мы можем запускать контейнеры» к «мы можем надёжно их эксплуатировать в продакшене».
Cloud-native не только добавил инструменты — он изменил ритм работы по доставке ПО. Команды перешли от «ручных серверов и runbooks» к системам, управляемым через API, автоматизацию и декларативную конфигурацию.
Cloud-native предполагает, что инфраструктура программируема. Нужна база данных, балансировщик или новое окружение? Вместо ручной настройки команды описывают желаемое и позволяют автоматизации создать это.
Ключевой сдвиг — декларативная конфигурация: вы определяете желаемое состояние («запусти 3 копии сервиса, выставь порт, лимит памяти X»), и платформа непрерывно стремится привести систему к этому состоянию. Это делает изменения рецензируемыми, повторяемыми и проще откатываемыми.
Традиционная доставка часто включала патчинг живых серверов. Со временем каждая машина становилась немного другой — конфигурационный дрейф, который проявляется при инцидентах.
Cloud-native подталкивает к иммутабельным релизам: собрать артефакт один раз (обычно контейнерный образ), развернуть его, а при необходимости изменить — выпустить новую версию, а не менять текущее. Вместе с автоматизированными релизами и health checks это уменьшает «загадочные» простои.
Контейнеры упростили упаковку и запуск многих мелких сервисов, что вдохновило микросервисную архитектуру. Микросервисы, в свою очередь, увеличили потребность в согласованных развёртываниях, масштабировании и обнаружении сервисов — областях, где оркестрация полезна.
Компромисс: больше сервисов — больше операционной нагрузки (наблюдаемость, сеть, управление версиями, реакция на инциденты). Cloud-native помогает управлять этой сложностью, но не устраняет её полностью.
Портируемость улучшилась, потому что команды стандартизировали примитивы развёртывания и API. Тем не менее «запусти где угодно» обычно требует усилий — различия в безопасности, хранилищах, сети и управляемых сервисах имеют значение. Cloud-native лучше понимать как снижение зависимости и трения, а не их полное устранение.
Kubernetes распространялся не только из-за мощи. Он распространился потому, что получил нейтральный дом, понятное управление и площадку, где конкурирующие компании могли сотрудничать без того, чтобы один вендор «владел» правилами.
Cloud Native Computing Foundation (CNCF) создала общие принципы управления: открытое принятие решений, предсказуемые процессы и публичные дорожные карты. Это важно для команд, делающих ставку на ключевую инфраструктуру. Когда правила прозрачны и не зависят от бизнес-модели одной компании, принятие кажется менее рискованным, а вклад — более привлекательным.
Хостя Kubernetes и сопутствующие проекты, CNCF помогла превратить «популярный open-source инструмент» в долгосрочную платформу с институциональной поддержкой. Это обеспечило:
С множеством участников (облачные провайдеры, стартапы, предприятия и независимые инженеры) Kubernetes развивался быстрее и в более практичных направлениях: сеть, хранилище, безопасность и операции дня-2. Открытые API и стандарты упростили интеграцию инструментов, что снизило привязку и повысило уверенность в использовании в продакшене.
CNCF также вызвала взрыв экосистемы: service mesh, ingress-контроллеры, CI/CD-инструменты, движки политик, стеки наблюдаемости и многое другое. Это богатство — сила, но оно создаёт и дублирование.
Для большинства команд успех приходит от выбора небольшого набора хорошо поддерживаемых компонентов, ориентации на совместимость и ясности в вопросах ответственности. Подход «лучшее от всего» часто ведёт к росту затрат на поддержку вместо улучшения доставки.
Контейнеры и Kubernetes решили большую часть вопроса «как мы запускаем ПО». Они не решили автоматически более сложный вопрос: «как мы удерживаем его работающим, когда приходят реальные пользователи?» Отсутствующий слой — операционная надёжность: ясные ожидания, общие практики и система, делающая правильное поведение поведением по умолчанию.
Команда может быстро выпускать, и в то же время быть в одной неудачной деплойной от хаоса, если продакшн-база не определена. Минимум, что нужно:
Без этой базы каждая служба придумывает свои правила, и надёжность становится вопросом везения.
DevOps и SRE внесли важные привычки: ответственность, автоматизация, измеряемая надёжность и извлечение уроков из инцидентов. Но одних привычек недостаточно, когда речь о десятках команд и сотнях сервисов.
Платформы делают эти практики повторяемыми. SRE задаёт цели (например, SLO) и обратные связи; платформа предоставляет покрытые дороги, чтобы их достигать.
Надёжная доставка обычно требует согласованного набора возможностей:
Хорошая платформа закладывает эти настройки в шаблоны, пайплайны и политики рантайма: стандартные дашборды, общие правила оповещений, ограждения при развёртывании и механизмы отката. Так надёжность перестаёт быть опцией и становится предсказуемым результатом выпуска ПО.
Инструменты cloud-native могут быть мощными и при этом казаться «слишком сложными» для продуктовых команд. Инженерия платформ стремится закрыть этот разрыв. Миссия проста: снизить когнитивную нагрузку у команд приложений, чтобы они могли выпускать фичи, не становясь полупрофессиональными инженерами инфраструктуры.
Хорошая команда платформы рассматривает внутреннюю инфраструктуру как продукт: понятные пользователи (разработчики), чёткие результаты (безопасная повторяемая доставка) и цикл обратной связи. Вместо того чтобы отдавать набор Kubernetes-примитивов, платформа предлагает опинионированные способы сборки, деплоя и эксплуатации сервисов.
Практический критерий: может ли разработчик пройти путь от идеи до работающего сервиса, не открывая десяток тикетов? Инструменты, сокращающие этот путь при сохранении ограждений, соответствуют цели cloud-native-платформы.
Большинство платформ — это набор повторно используемых «покрытых дорог», которые команды могут выбирать по умолчанию:
Цель не в том, чтобы скрыть Kubernetes — а в том, чтобы упаковать его в разумные настройки по умолчанию, предотвращающие случайную сложность.
В этом духе, Koder.ai можно использовать как слой «ускорителя DX» для команд, которые хотят быстро поднять внутренние инструменты или продуктовые фичи через чат, а затем экспортировать исходники при интеграции с более формальной платформой. Для команд платформы его режим планирования и встроенные снимки/откат также могут отражать ту же позицию «надёжность прежде всего», которую вы хотите видеть в продакшн-процессах.
Любая покрытая дорога — это компромисс: больше согласованности и безопасных операций, но меньше уникальных возможностей. Платформенные команды лучше всего работают, когда предлагают:
Успех платформы виден измеримо: быстрее онбординг новых инженеров, меньше самописных скриптов деплоя, меньше «снежинок»-кластеров и ясная ответственность при инцидентах. Если команды могут ответить «кто владеет этим сервисом и как мы деплоим?» без собраний — платформа выполняет свою работу.
Cloud-native может ускорять доставку и упрощать операции — но только если команды понимают, что именно они хотят улучшить. Многие тормоза возникают, когда Kubernetes и его экосистема становятся целью, а не средством.
Распространённая ошибка — внедрять Kubernetes потому что «так поступают современные команды», без чёткой цели: сократить lead time, снизить количество инцидентов или улучшить согласованность окружений. В результате много миграционной работы без видимого эффекта.
Если критерии успеха не заданы заранее, каждое решение становится субъективным: какой инструмент выбрать, насколько стандартизировать и когда платформа «готова».
Kubernetes — фундамент, а не полная платформа. Команды часто быстро добавляют надстройки — service mesh, несколько ingress-контроллеров, кастомные операторы, движки политик — без ясных границ или владельцев.
Ещё одна ловушка — переусложнение: кастомные YAML-паттерны, самописные шаблоны и единичные исключения, которые понимает только автор. Сложность растёт, онбординг замедляется, апгрейды становятся рискованными.
Cloud-native упрощает создание ресурсов — и их забывание. Разрастание кластеров, неиспользуемые namespace'ы и чрезмерно выделенные ресурсы тихо увеличивают расходы.
Проблемы безопасности так же часто включают:
Начните с малого: 1–2 чётко ограниченных сервиса. Задайте стандарты рано (golden paths, утверждённые базовые образы, правила обновления) и держите поверхность платформы сознательно ограниченной.
Измеряйте результаты: частоту развёртываний, среднее время восстановления и время разработчика до первого деплоя — и относитесь к любым метрикам, которые не улучшаются, как к необязательным.
Вы не «принимаете cloud-native» одним махом. Успешные команды следуют той же идее, что и в эпоху McLuckie: строят платформу, которая делает правильный путь лёгким.
Начните с малого, затем формализуйте удачные практики.
Если вы экспериментируете с новыми рабочими процессами, полезно прототипировать «золотой путь» целиком до того, как стандартизировать его. Например, команды могут использовать Koder.ai, чтобы быстро сгенерировать рабочее веб-приложение (React), бэкенд (Go) и базу данных (PostgreSQL) через чат, а затем воспринимать полученную кодовую базу как стартовую точку для шаблонов платформы и конвенций CI/CD.
Перед добавлением нового инструмента спросите:
Отслеживайте результаты, а не использование инструментов:
Если хотите примеры хороших «пакетов MVP платформы», смотрите /blog. Для бюджетирования и планирования развёртывания можно также обратиться к /pricing.
Главный урок последнего десятилетия прост: контейнеры «выиграли» не потому что это умная упаковка. Они выиграли потому, что платформенное мышление сделало их надёжными — повторяемые развёртывания, безопасные релизы, согласованные контролы безопасности и предсказуемые операции.
Следующая глава не будет про один прорывной инструмент. Она про то, чтобы cloud-native стал максимально скучным в хорошем смысле: меньше сюрпризов, меньше одноразовых исправлений и более плавный путь от кода к продакшену.
Policy-as-code становится стандартом. Вместо ручной проверки каждого релиза команды кодируют правила безопасности, сети и соответствия, чтобы ограждения работали автоматически и были аудируемыми.
Опыт разработчика (DX) воспринимают как продукт. Ожидайте больше фокуса на покрытых дорогах: шаблоны, среды самообслуживания и ясные golden paths, снижающие когнитивную нагрузку без ограничения автономии.
Проще операции, а не больше дашбордов. Лучшие платформы будут скрывать сложность: опинионированные настройки по умолчанию, меньше движущихся частей и встроенные паттерны надёжности, а не приклеенные сверху.
Прогресс cloud-native замедляется, когда команды гоняются за фичами, а не за результатами. Если вы не можете объяснить, как новый инструмент уменьшает lead time, снижает частоту инцидентов или улучшает безопасность — скорее всего, это не приоритет.
Оцените текущие болевые точки доставки и сопоставьте их с потребностями платформы:
Считайте ответы бэклогом платформы — и измеряйте успех по результатам, которые команды ощущают каждую неделю.
Cloud-native — это подход к созданию и эксплуатации ПО, при котором вы можете часто разворачивать, масштабироваться при изменении нагрузки и быстро восстанавливаться после сбоев.
На практике это обычно включает контейнеры, автоматизацию, мелкие сервисы и стандартные способы наблюдения, защиты и управления тем, что работает.
Контейнер помогает доставлять ПО последовательно, но сам по себе он не решает сложные производственные задачи: безопасные обновления, обнаружение сервисов, контроли безопасности и устойчивая наблюдаемость.
Проблема становится очевидной, когда вы переходите от нескольких контейнеров к сотням, работающим круглосуточно.
«Платформенное мышление» — это отношение к внутренней инфраструктуре как к внутреннему продукту с понятными пользователями (разработчиками) и обещанием (безопасная, повторяемая доставка).
Вместо того чтобы каждая команда придумывала свой путь в продакшен, организация строит общие покрытые дороги (golden paths) с разумными настройками по умолчанию и поддержкой.
Kubernetes даёт операционный слой, который превращает «кучу контейнеров» в систему, которую можно эксплуатировать ежедневно:
Он также вводит общий , где вы объявляете желаемое состояние, а система стремится привести реальность в соответствие.
Декларативная конфигурация означает, что вы описываете что вы хотите (желаемое состояние), а не пишете пошаговые инструкции.
Практические преимущества:
Под «immutable deployments» понимают, что вы не патчите живые серверы на месте. Вы собираете артефакт один раз (часто контейнерный образ) и разворачиваете именно этот артефакт.
Чтобы изменить систему, вы выпускаете новую версию, а не редактируете запущенное окружение. Это снижает дрейф конфигураций и делает инциденты проще для воспроизведения и отката.
CNCF дала Kubernetes нейтральный дом: прозрачное управление, предсказуемые процессы и место, где конкурирующие компании могли сотрудничать без риска, что один вендор диктует правила.
Это помогло:
Продакшн-база — это минимальный набор возможностей и практик, делающий надёжность предсказуемой, например:
Без этого каждая служба придумывает собственные правила, и надёжность превращается в удачу.
Инженерия платформ концентрируется на снижении когнитивной нагрузки разработчиков, упаковывая cloud-native-примитивы в опинионированные настройки по умолчанию:
Цель — не скрыть Kubernetes, а сделать корректный путь самым простым.
Частые ошибки при внедрении cloud-native:
Как избежать тормозов: