03 окт. 2025 г.·6 мин
Данные снаружи и внутри — уроки Pat Helland для приложений
Узнайте идею Pat Helland о данных снаружи и внутри: как задать чёткие границы, сделать вызовы идемпотентными и согласовывать состояние при сетевых сбоях.
Узнайте идею Pat Helland о данных снаружи и внутри: как задать чёткие границы, сделать вызовы идемпотентными и согласовывать состояние при сетевых сбоях.
Когда вы создаёте приложение, легко представить, что запросы приходят аккуратно, по одному и в правильном порядке. Реальные сети так не работают. Пользователь нажимает «Оплатить» дважды, потому что экран завис. Мобильное соединение разрывается сразу после нажатия. Вебхук приходит позже или приходит дважды. Иногда он вообще не приходит.
Идея Pat Helland о данных снаружи vs внутри — это удобный способ мыслить об этом хаосе.
«Снаружи» — это всё, что ваше приложение не контролирует. Это место, где вы общаетесь с людьми и другими системами, и где доставка ненадёжна: HTTP‑запросы от браузеров и мобильных приложений, сообщения из очередей, сторонние вебхуки (платежи, почта, доставка) и повторы, инициированные клиентами, прокси или фоновыми задачами.
На стороне «снаружи» предполагайте, что сообщения могут задерживаться, дублироваться или приходить не в том порядке. Даже если что‑то «обычно надёжно», проектируйте так, чтобы выдержать день, когда это перестанет быть правдой.
«Внутри» — это то, что ваша система может сделать надёжным. Это долговечное состояние, которое вы храните, правила, которые вы применяете, и факты, которые вы сможете доказать позже:
Внутри вы защищаете инварианты. Если вы обещаете «одна оплата на заказ», это обещание должно соблюдаться внутри, потому что снаружи нельзя полагаться.
Сдвиг мышления прост: не предполагайте идеальную доставку или идеальное время. Относитесь к каждому взаимодействию снаружи как к ненадёжному предположению, которое может повториться, и делайте так, чтобы внутренняя часть реагировала безопасно.
Это важно даже для маленьких команд и простых приложений. Первый раз, когда сетевой сбой приведёт к дублю списания или застрявшему заказу, это перестаёт быть теорией и превращается в возврат средств, тикет в поддержку и потерю доверия.
Конкретный пример: пользователь нажимает «Оформить заказ», приложение отправляет запрос, и соединение падает. Пользователь пытается снова. Если внутри нет способа распознать «это та же попытка», вы можете создать два заказа, зарезервировать инвентарь дважды или отправить два подтверждения по почте.
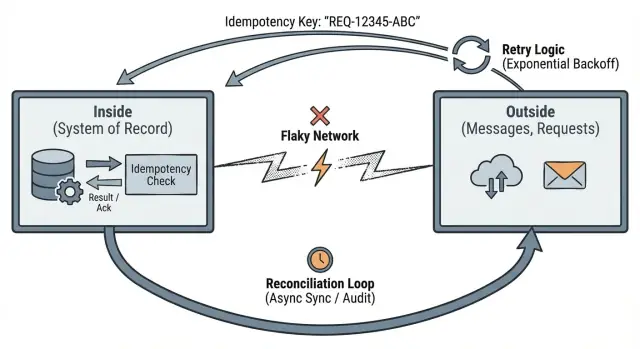
Идея Helland проста: внешний мир ненадёжен, но внутренняя часть вашей системы должна оставаться согласованной. Сети теряют пакеты, телефоны теряют сигнал, часы расходятся, и пользователи нажимают refresh. Ваше приложение не может это контролировать. Оно может контролировать то, что признаёт «истиной», когда данные пересекают чёткую границу.
Представьте, кто‑то заказывает кофе по телефону, идёт по зданию с плохим Wi‑Fi. Он нажимает «Оплатить». Крутится спиннер. Сеть пропадает. Он нажимает снова.
Возможно, первый запрос дошёл до сервера, но ответ не вернулся. А может, ни один запрос не дошёл. Для пользователя оба сценария выглядят одинаково.
Это и есть время и неопределённость: вы ещё не знаете, что произошло, и можете узнать позже. Система должна вести себя разумно, пока ждёт.
Приняв, что снаружи ненадёжно, несколько «странных» поведений становятся нормой:
Данные снаружи — это утверждение, а не факт. «Я заплатил» — это просто заявление, отправленное по ненадёжному каналу. Это становится фактом только после того, как вы зафиксируете это внутри системы в долговечном и согласованном виде.
Это подтолкнёт вас к трём практическим привычкам: обозначить чёткие границы, сделать повторы безопасными через идемпотентность и планировать согласование, когда реальность расходится.
Идея «снаружи vs внутри» начинается с практического вопроса: где начинается и заканчивается ваша истина?
Внутри границы вы можете давать строгие гарантии, потому что контролируете данные и правила. Снаружи вы делаете лучшие попытки и предполагаете, что сообщения могут быть потеряны, дублированы, задержаны или прийти не в порядке.
В реальных приложениях граница часто выглядит в местах типа:
После того как вы проводите эту линию, решите, какие инварианты внутри неё — не подлежат компромиссу. Примеры:
Граница также нуждается в понятных состояниях «где мы сейчас». Многие ошибки рождаются в промежутке между «мы получили» и «мы закончили». Полезный паттерн — различать три смысла:
Если команды пропускают это, появляются баги, которые проявляются только под нагрузкой или при частичных сбоях. Одна система понимает «оплачен» как списание денег; другая — как начало попытки оплаты. Такое несоответствие порождает дубликаты, застрявшие заказы и тикеты, которые никто не может воспроизвести.
Идемпотентность означает: если тот же самый запрос отправлен дважды, система воспримет его как один запрос и вернёт один и тот же результат.
Повторы нормальны. Таймауты случаются. Клиенты повторяют запросы. Если снаружи возможны повторы, внутренняя часть должна превратить это в стабильные изменения состояния.
Простой пример: мобильное приложение отправляет «оплатить $20», связь падает. Приложение повторяет запрос. Без идемпотентности клиент может списаться дважды. С идемпотентностью второй запрос возвращает результат первого списания.
Большинство команд используют один из этих паттернов (иногда смешивая):
Idempotency-Key: ...). Сервер сохраняет ключ и итоговый ответ.Когда приходит дубликат, лучшая реакция обычно не «409 conflict» или общая ошибка. Лучше вернуть тот же ответ, что вы вернули в первый раз, включая тот же ID ресурса и статус. Это делает повторы безопасными для клиентов и фоновых задач.
Запись об идемпотентности должна жить внутри вашей границы в долговом хранилище, а не в памяти. Если API перезапустится и забудет, гарантия безопасности исчезнет.
Храните записи достаточно долго, чтобы покрыть реалистичные повторы и отложенные доставки. Окно зависит от бизнес‑риска: минуты–часы для низкорисковых операций, дни для платежей/почты/отправок, и ещё дольше, если партнёры могут повторять запросы долго.
Распределённые транзакции звучат успокаивающе: один большой коммит через сервисы, очереди и базы. На практике они часто недоступны, медленны или слишком хрупки. Как только появляется сетевой переход, вы не можете предполагать, что всё зафиксировалось вместе.
Типичная ловушка — рабочий поток, который работает только если каждый шаг удаётся прямо сейчас: сохранить заказ, списать карту, зарезервировать инвентарь, отправить подтверждение. Если шаг 3 таймаутит, он провалился или прошёл? Если вы повторяете, дважды сможете ли вы списать или зарезервировать?
Два практических подхода этого избегают:
Выберите один стиль для конкретного workflow и придерживайтесь его. Смешивание «иногда делаем outbox», «иногда предполагаем синхронный успех» порождает краевые случаи, которые сложно протестировать.
Простое правило: если вы не можете атомарно зафиксировать изменения через границы, проектируйте под повторы, дубликаты и задержки.
Согласование признаёт простую истину: когда ваше приложение общается с другими системами по сети, вы иногда будете не соглашаться в том, что произошло. Запросы таймаутят, callback‑ы приходят с задержкой, люди повторяют действия. Согласование — это способ обнаружить расхождения и исправить их со временем.
Считайте внешние системы независимыми источниками истины. Ваше приложение хранит свою внутреннюю запись, но ему нужен способ сравнить её с тем, что сделали партнёры, провайдеры и сами пользователи.
Большинство команд используют набор простых инструментов (скучного — зато надёжного): воркер, который повторно пытает ожидающие действия и перепроверяет внешний статус; плановый скан на несоответствия; и небольшой административный инструмент для поддержки, чтобы повторить, отменить или пометить запись как просмотренную.
Согласование работает только если вы знаете, что сравнивать: внутренний ledger vs ledger провайдера (платежи), статус заказа vs статус отправки (fulfillment), состояние подписки vs выставление счёта.
Делайте состояния ремонтопригодными. Вместо резкого перехода из «created» в «completed» используйте промежуточные состояния вроде pending, on hold или needs review. Это позволяет честно сказать «мы не уверены», и даёт согласованию понятную точку для действий.
Фиксируйте небольшой аудиторский след по важным изменениям:
Пример: если ваше приложение запрашивало ярлык отправки и сеть упала, вы можете получить «нет ярлыка» внутри, в то время как перевозчик уже создал его. Воркера по согласованию может найти ярлык по correlation ID, продвинуть заказ дальше (или пометить на ревью, если данные не сходятся).
Приняв, что сеть подведёт, цель меняется. Вы не пытаетесь сделать так, чтобы каждый шаг завершался с первой попытки. Вы делаете шаги безопасными для повторения и лёгкими для исправления.
Напишите одно‑дневное заявление границы. Ясно опишите, что ваша система владеет (источник истины), что она зеркалит, а что только запрашивает у других.
Перечислите режимы отказа до описания счастливого пути. Минимум: таймауты (неизвестно, сработало ли), дубли запросов, частичный успех (один шаг случился, следующий — нет) и события вне порядка.
Выберите стратегию идемпотентности для каждого входа. Для синхронных API это обычно idempotency key + сохранённый результат. Для сообщений/событий — уникальный message ID и запись «я это уже обработал?».
Сначала зафиксируйте намерение, затем действуйте. Сначала сохраните что‑то долговечное вроде PaymentAttempt: pending или ShipmentRequest: queued, затем сделайте внешний вызов, затем зафиксируйте исход. Возвращайте стабильный reference ID, чтобы повторы ссылались на то же намерение, а не создавали новое.
Постройте согласование и путь ремонта и сделайте их видимыми. Согласование может быть джобом, который сканирует «ожидающие слишком долго» и перепроверяет статус. Путь ремонта — безопасное действие администратора: «retry», «cancel» или «mark resolved» с аудиторной заметкой. Добавьте простую наблюдаемость: correlation ID, явные поля статуса и несколько счётчиков (pending, retries, failures).
Пример: если чек‑аут таймаутит сразу после вызова платёжного провайдера, не делайте догадок. Сохраните попытку, верните её ID и позвольте пользователю повторить с тем же idempotency key. Потом согласование подтвердит, списал ли провайдер или нет, и обновит попытку без двойного списания.
Клиент нажимает «Оформить заказ». Ваш сервис отправляет запрос платежу провайдеру, но сеть нестабильна. У провайдера есть своя правда, у вас — своя база. Они разойдутся, если не спроектировать иначе.
С вашей точки зрения, снаружи — поток сообщений, которые могут приходить поздно, повторно или отсутствовать:
Ни один из этих шагов не гарантирует «exactly once». Они дают только «может быть».
Внутри границы храните долговечные факты и минимум данных, чтобы связать внешние события с этими фактами.
Когда клиент создал заказ, создайте запись order в состоянии pending_payment. Также создайте payment_attempt с уникальной ссылкой провайдера и idempotency_key, привязанным к действию клиента.
Если клиент таймаутит и повторяет запрос, ваш API не должен создавать второй заказ. Он должен посмотреть по idempotency_key и вернуть тот же order_id и текущий статус. Это предотвращает дубликаты при сетевых сбоях.
Теперь вебхук приходит дважды. Первый callback обновляет payment_attempt в authorized и переводит заказ в paid. Второй callback попадает в тот же обработчик, но вы обнаруживаете, что уже обработали это событие провайдера (сохранив ID события провайдера или проверив текущее состояние) и ничего не делаете. Всё ещё можно ответить 200 OK, потому что результат уже верен.
Наконец, согласование справляется с грязными случаями. Если заказ остаётся pending_payment слишком долго, фоновая задача делает запрос к провайдеру по сохранённой ссылке. Если провайдер говорит «authorized», но вы пропустили вебхук, вы обновляете записи. Если провайдер говорит «failed», а вы отметили paid, вы помечаете на ревью или запускаете компенсирующее действие вроде возврата.
Большинство дублей и «застрявших» рабочих процессов вызваны путаницей между тем, что произошло снаружи (запрос пришёл, сообщение принято) и тем, что вы надёжно зафиксировали внутри.
Классическая ошибка: клиент отправляет «place order», сервер начинает работу, сеть падает, и клиент повторяет. Если вы считаете каждый повтор как новое действие, получите двойные списания, дубли заказов или множественные письма.
Обычные причины:
Одна проблема усугубляет все остальные: нет аудита. Если вы просто перезаписываете поля и храните только последнее состояние, вы теряете доказательства, нужные для последующего согласования.
Хорошая проверка здравомыслия: «Если я запущу этот обработчик дважды, получу ли я тот же результат?» Если ответ «нет», дубликаты — не редкий крайний случай, а гарантированная ситуация.
Если запомнить одно: приложение должно оставаться корректным даже когда сообщения приходят поздно, приходят дважды или вообще не приходят.
Используйте этот чек‑лист, чтобы найти слабые места до того, как они превратятся в дубли, пропущенные обновления или застрявшие рабочие процессы:
Если вы не можете быстро ответить на один из пунктов — это уже полезно. Обычно это значит, что граница размыта или где‑то не хватает перехода состояния.
Практические шаги:
Сначала прорисуйте границы и состояния. Определите небольшой набор состояний на workflow (например: Created, PaymentPending, Paid, FulfillmentPending, Completed, Failed).
Добавьте идемпотентность там, где важнее всего. Начните с рискоёмких записей: создание заказа, захват платежа, возврат. Храните idempotency keys в PostgreSQL с уникальным ограничением, чтобы дубли отклонялись безопасно.
Отнеситесь к согласованию как к обычной функции. Запустите задание, которое ищет записи «ожидающие слишком долго», перепроверяет внешние системы и чинит локальное состояние.
Итеративно улучшайте. Корректируйте переходы и правила повторов, затем тестируйте, целенаправленно отправляя один и тот же запрос и повторно обрабатывая одно и то же событие.
Если вы быстро строите на чат‑ориентированной платформе типа Koder.ai (koder.ai), всё равно стоит заложить эти правила в генерируемые сервисы: скорость даёт автоматизацию, но надёжность приходит от чётких границ, идемпотентных обработчиков и процесса согласования.
“Снаружи” — это всё, что вы не контролируете: браузеры, мобильные сети, очереди, сторонние вебхуки, повторные попытки и таймауты. Предполагается, что сообщения могут задерживаться, дублироваться, теряться или приходить не в том порядке.
“Внутри” — это то, что вы контролируете: ваше сохранённое состояние, правила и факты, которые вы сможете доказать позже (обычно в базе данных).
Потому что сеть «врет» — таймаут клиента не означает, что сервер не обработал запрос. Вебхук, пришедший дважды, не означает, что провайдер выполнил действие дважды. Если каждый входящий запрос считать «новой истиной», вы получите дублирование заказов, двойные списания и застрявшие рабочие процессы.
Чёткая граница — это точка, где ненадёжное сообщение превращается в долговечный факт.
Распространённые границы:
После перехода данных через эту границу вы обеспечиваете инварианты внутри (например: order можно оплатить только один раз).
Используйте идемпотентность. Правило: одно и то же намерение должно давать один и тот же результат, даже если отправлено несколько раз.
Практические паттерны:
Не держите запись только в памяти. Храните её внутри вашей границы (например, в PostgreSQL), чтобы перезапуск сервиса не уничтожил защиту.
Правило удержания:
Храните достаточно долго, чтобы покрыть реалистичные повторы и отложенные колбэки.
Используйте состояния, которые допускают неопределённость.
Простая практическая схема:
pending_* (намерение принято, но исход неизвестен)succeeded / failed (записан окончательный результат)needs_review (обнаружено несоответствие, требуется человек или специальная задача)Потому что нельзя атомарно зафиксировать изменения сразу в нескольких системах по сети.
Если вы делаете «сохранить заказ → списать карту → зарезервировать инвентарь» синхронно, а шаг 2 таймаутит, вы не узнаете, повторять ли действие. Повтор может вызвать дублирование; отсутствие повтора — оставит работу незавершённой.
Проектируйте под частичный успех: сначала сохраняйте намерение, затем выполняйте внешние действия, затем фиксируйте результаты.
Паттерн outbox/inbox делает межсистемные сообщения надёжными без иллюзии надёжной сети.
Согласование — это процесс восстановления, когда ваша запись расходится с внешней системой.
Хорошие настройки по умолчанию:
needs_reviewЭто обязательно для платежей, логистики, подписок и всего, что работает с вебхуками.
Да. Быстрая сборка не отменяет сетевых сбоев — она лишь приближает вас к ним быстрее.
Если вы генерируете сервисы с Koder.ai, заложите эти правила с самого начала:
Тогда повторы и дублирующие колбэки станут рутинной задачей, а не дорогой неприятностью.
Это предотвращает догадки при таймаутах и упрощает согласование.