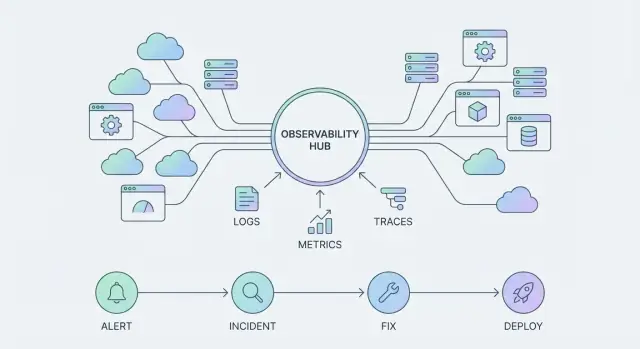
Почему наблюдаемость превращается в платформу
Инструмент наблюдаемости помогает ответить на конкретные вопросы о системе — обычно показывая графики, логи или результат запроса. Это то, чем вы «пользуетесь», когда возникает проблема.
Платформа наблюдаемости шире: она стандартизирует, как собирается телеметрия, как команды её исследуют и как инциденты обрабатываются от начала до конца. Это то, чем ваша организация «управляет» ежедневно, по множеству сервисов и команд.
От графиков к результатам
Большинство команд начинают с дашбордов: графики CPU, ошибки, несколько поисков по логам. Это полезно, но настоящая цель — не красивые графики, а быстрое обнаружение и быстрое разрешение.
Сдвиг к платформе происходит, когда вы перестаёте спрашивать «можем ли мы это отобразить?» и начинаете спрашивать:
- Найдёт ли on-call инженер корень проблемы за минуты, а не часы?
- Можно ли автоматически направлять правильное оповещение нужной команде?
- Можно ли превратить повторяющиеся паттерны инцидентов в повторяемые плейбуки?
Это вопросы, ориентированные на результат, и они требуют больше, чем визуализация: общих стандартов данных, согласованных интеграций и рабочих процессов, связывающих телеметрию с действием.
Три опоры, за которые вы на самом деле платите
По мере развития платформ вроде Datadog «поверхность продукта» — это не только дашборды. Это три взаимосвязанные опоры:
- Телеметрия: логи, метрики и трейсы, собираемые последовательно и помеченные достаточно хорошо, чтобы вы могли им доверять.
- Интеграции: преднастроенные соединения, упрощающие внедрение и расширяющие покрытие без кастомного «склеивания».
- Рабочие процессы: реакция на инциденты, маршрутизация оповещений, владение и последующие действия — чтобы обучение аккумулировалось.
Ценность платформы накапливается
Один дашборд помогает одной команде. Платформа становится сильнее с каждым подключенным сервисом, каждой добавленной интеграцией и каждым стандартизированным рабочим процессом. Со временем это накапливается в виде меньшего числа слепых зон, меньшего дублирования инструментов и коротких инцидентов — потому что каждое улучшение становится повторно используемым, а не одноразовым.
Телеметрия как поверхность продукта
Когда наблюдаемость превращается из «инструмента, к которому мы делаем запросы» в «платформу, на которой мы строим», телеметрия перестаёт быть сырым выхлопом и становится поверхностью продукта. То, что вы решаете эмитить — и насколько последовательно вы это делаете — определяет, что команды могут видеть, автоматизировать и во что верить.
Основные типы телеметрии (и для чего они нужны)
Большинство команд стандартизуют небольшой набор сигналов:
- Метрики: численные тренды во времени (латентность, доля ошибок, насыщение).
- Логи: детальные, человекочитаемые записи для расследований и аудита.
- Трейсы: пути запросов между сервисами, чтобы найти, где теряется время или происходят ошибки.
- События: дискритные записи «что-то изменилось» (деплои, feature flags, инциденты).
- Профили: поведение CPU/памяти для поиска дорогих участков кода.
Каждый сигнал полезен сам по себе. Вместе они становятся единым интерфейсом к вашим системам — тем, что вы видите в дашбордах, оповещениях, хронологиях инцидентов и постмортемах.
Последовательность важнее объёма
Обычная ошибка — собирать «всё и сразу», но именовать сигналы непоследовательно. Если один сервис использует userId, другой — uid, а третий вообще ничего не логирует, вы не сможете надёжно разрезать данные, соединять сигналы или строить повторно используемые мониторы.
Команды получат больше пользы, согласовав несколько соглашений — имена сервисов, теги окружения, request ID и стандартный набор атрибутов — чем увеличивая объём инжеста.
Что на самом деле значит высокая кардинальность (и почему это важно)
Поля высокой кардинальности имеют много возможных значений (например, user_id, order_id, session_id). Они мощны для отладки «случилось только у одного клиента», но могут увеличить стоимость и замедлить запросы, если использовать их повсеместно.
Платформенный подход предполагает намеренное использование: держите высокую кардинальность там, где она даёт очевидную ценность при расследовании, и избегайте её в местах для глобальных агрегатов.
Единый контекст снижает работу по корреляции
Выигрыш — в скорости. Когда метрики, логи, трейсы, события и профили разделяют один и тот же контекст (service, version, region, request ID), инженеры тратят меньше времени на «склейку» доказательств и больше — на исправление реальной проблемы. Вместо прыжков между инструментами и догадок вы следуете одной нити от симптома к корню.
От сбора данных к стратегии телеметрии
Большинство команд начинают с «загнать данные внутрь». Это нужно, но это не стратегия. Стратегия телеметрии поддерживает быстрое онбординг и делает данные достаточно согласованными для общих дашбордов, надёжных оповещений и осмысленных SLO.
Общие пути инжеста (и где они полезны)
Datadog обычно получает телеметрию через несколько практических маршрутов:
- Агенты на хостах/VM: самый быстрый способ собрать инфраструктурные метрики, логи и APM с минимальными изменениями в коде.
- Коллекторы и шлюзы (например, OpenTelemetry Collector): полезны, когда нужен центральный контроль, мульти-дестинация, редактирование или стандартизованная обработка.
- APIs и прямые SDK: удобны для кастомных событий, бизнес-метрик или когда агент нецелесообразен.
- Интеграции для serverless: удобны для управляемых рантаймов, где вы не контролируете хост; при этом важно продумать, что эмитить.
Скорость vs стандартизация: решите, что для вас важнее
В начале побеждает скорость: команды ставят агент, включают несколько интеграций и сразу видят ценность. Риск в том, что каждая команда придумывает свои теги, имена сервисов и форматы логов — и кросс-сервисный обзор становится грязным, а оповещения — недоверенными.
Простое правило: разрешайте «быстрый старт», но требуйте «стандартизацию в течение 30 дней». Это даёт инерцию без закрепления хаоса.
Лёгкая конвенция имен и тегов
Вам не нужна огромная таксономия. Начните с малого набора, который обязан нести каждый сигнал (логи, метрики, трейсы):
service: короткое, стабильное, строчные буквы (например, checkout-api)env: prod, staging, devteam: идентификатор команды-владельца (например, payments)version: версия деплоя или git SHA
Если хотите ещё одну полезную метку, добавьте tier (frontend, backend, data) для упрощения фильтрации.
Сэмплинг, хранение и настройки с учётом стоимости
Проблемы со стоимостью часто возникают из-за слишком щедрых дефолтов:
- Трейсы: начните с head-based sampling для высоконагруженных эндпоинтов; держите 100% для критичных потоков.
- Логи: по умолчанию собирайте «ошибки + важные бизнес-события», а info/debug добавляйте выборочно с ограниченным хранением.
- Хранение: храните данные высокой детализации короткое время (дни), агрегаты и ключевые метрики — длиннее (недели/месяцы).
Цель не в том, чтобы собирать меньше, а в том, чтобы последовательно собирать правильные данные, чтобы масштабировать использование без сюрпризов.
Интеграции как реальный канал распространения
Большинство думают об инструментах наблюдаемости как о «чём-то, что ставят». На практике они распространяются по организации так же, как хорошие коннекторы: по одной интеграции за раз.
Что на самом деле значит «интеграция»
Интеграция — это не просто труба данных. Обычно она включает три части:
- Источники данных: сбор метрик, логов, трейсов, событий и топологии из уже запущенных систем (облака, Kubernetes, БД, CI/CD, SaaS).
- Обогащение: добавление контекста, чтобы телеметрия была сразу полезной — имена сервисов, окружения, теги владения, версии деплоя и метаданные облака.
- Действия: использование полученных данных — создание тикетов, пейджинг on-call, аннотирование деплоев, масштабирование ресурсов или запуск руководов.
Последняя часть делает интеграции каналом распространения. Если инструмент только читает, это место для дашбордов. Если он ещё и пишет — он становится частью ежедневной работы.
Почему интеграции ускоряют принятие
Хорошие интеграции сокращают время настройки, поставляя разумные дефолты: преднастроенные дашборды, рекомендованные мониторы, правила парсинга и общие теги. Вместо того чтобы каждая команда придумывала свой «CPU dashboard» или «Postgres alerts», вы получаете общий стартовый набор, соответствующий лучшим практикам.
Команды всё ещё кастомизируют — но от общей базы. Это важно при консолидации инструментов: интеграции создают повторяемые паттерны, которые новые сервисы копируют, что держит рост под контролем.
Приоритизируйте двунаправленные интеграции
При оценке спрашивайте: может ли интеграция принимать сигналы и выполнять действия? Примеры: открытие инцидента в системе тикетов, обновление инцидент-канала или прикрепление ссылки на трейc в PR/деплой-вью. В таких двунаправленных сетапах рабочие процессы начинают казаться «нативными».
Простой метод приоритезации
Начните с малого и предсказуемого:
- Критическая инфраструктура сначала (провайдер облака, Kubernetes, балансировщики, основные БД).
- Пайплайн деплоя (CI/CD, feature flags, трекинг релизов), чтобы телеметрия коррелировала с изменениями.
- Подключайте SaaS по команде (очереди, кеши, auth, платежи), когда теги и владение стабильны.
Если нужен простой эвристический совет: приоритет отдавайте интеграциям, которые сразу улучшают реакцию на инциденты, а не тем, которые просто добавляют ещё графиков.
Стандартные представления: сервисы, дашборды и мониторы
Стандартные представления — это то, где платформа наблюдаемости становится удобной в повседневной работе. Когда команды разделяют одну и ту же модель — что такое «сервис», что значит «здорово» и куда кликать первым делом — отладка ускоряется, а передачи ответственности становятся чище.
Начните с «золотых сигналов» и делайте их видимыми
Выберите небольшой набор «золотых сигналов» и сопоставьте каждому конкретный, повторяемый дашборд. Для большинства сервисов это:
- Латентность (p95/p99 по ключевым эндпоинтам)
- Трафик (requests per second, jobs processed)
- Ошибки (скорость и топ типов ошибок)
- Насыщение (CPU, память, глубина очереди, соединения БД)
Ключ — последовательность: один макет дашборда для всех сервисов лучше десяти хитрых кастомных.
Каталог сервисов создаёт общее владение
Каталог сервисов (даже лёгкий) превращает «кто-то должен это смотреть» в «эта команда отвечает за это». Когда сервисы помечены владельцами, окружениями и зависимостями, платформа может мгновенно ответить на вопросы: какие мониторы применяются к сервису? Какие дашборды открыть? Кому придёт пейдж?
Ясность уменьшает переписку в Slack во время инцидентов и помогает новым инженерам самообслуживаться.
Строительные блоки, которые масштабируются
Относитесь к этим артефактам как к стандартным, а не опциональным:
- Дашборды для золотых сигналов и ключевых зависимостей
- Мониторы привязанные к SLO или симптомам, влияющим на пользователей
- Ноутбуки для расследований и хронологий инцидентов
- Рукбуки (ссылки из мониторов) для первых 5–10 минут реакции
Антипаттерны, которых стоит избегать
Vanity-дашборды (красивые графики без решений), одноразовые оповещения (созданные в спешке и никогда не настроенные) и не документированные запросы (только один человек понимает фильтр) создают шум платформы. Если запрос важен — сохраните его, дайте понятное имя и прикрепите к сервисному представлению.
Рабочие процессы: где наблюдаемость приносит бизнес-ценность
Сделайте постмортемы повторяемыми
Создайте форму разбора после инцидента, которая фиксирует, что изменилось и что автоматизировать дальше.
Наблюдаемость становится «реальной» для бизнеса, когда она сокращает время между проблемой и уверенным исправлением. Это происходит через рабочие процессы — повторяемые пути от сигнала к действию и от действия к обучению.
Путь инцидента: оповещение → триаж → коммуникация → смягчение → обучение
Масштабируемый рабочий процесс — это не просто пейджинг.
Оповещение должно открывать сфокусированный цикл триажа: подтвердить влияние, определить затронутый сервис и подтянуть самый релевантный контекст (последние деплои, здоровье зависимостей, всплески ошибок, сигналы насыщения). Затем коммуникация превращает техническое событие в координированный ответ — кто владеет инцидентом, что видят пользователи и когда будет следующее обновление.
Смягчение — это набор «безопасных действий» под рукой: feature flags, смена трафика, откат, лимиты скорости или известный обходной путь. Наконец, обучение закрывает цикл лёгким ревью: что изменилось, что сработало и что стоит автоматизировать дальше.
Инструменты инцидентов + ChatOps = сотрудничество, а не героизм
Платформы вроде Datadog добавляют ценность, когда они поддерживают совместную работу: каналы инцидентов, статус-апдейты, передачи смен и единые хронологии. Интеграции ChatOps превращают оповещения в структурированные разговоры — создание инцидента, назначение ролей и публикация ключевых графиков и запросов прямо в треде, чтобы все видели одни и те же доказательства.
Что действительно должно быть в полезном рукбуке
Полезный рукбук короткий, категоричный и безопасный. Он должен содержать: цель (восстановить сервис), явных владельцев/ротации on-call, пошаговые проверки, ссылки на правильные дашборды/мониторы и «безопасные действия», уменьшающие риск (с шагами отката). Если выполнить его в 3 утра небезопасно — значит он не готов.
Связывайте инциденты с деплоями и изменениями
Корень проблемы ищется быстрее, когда инциденты автоматически коррелируются с деплоями, изменениями конфигураций и переключениями feature flags. Сделайте «что поменялось?» первоочередным представлением, чтобы триаж начинался с доказательств, а не с догадок.
SLO и бюджеты ошибок как операционная система команды
Что такое SLO (и почему он лучше «зелёного дашборда»)
SLO (Service Level Objective) — это простое обещание о качестве пользовательского опыта за окно времени — например, «99.9% запросов успешны за 30 дней» или «p95 загрузки страниц < 2 секунды».
Это лучше «зелёного дашборда», потому что дашборды часто показывают состояние системы (CPU, память, глубина очереди), а не влияние на клиента. Сервис может выглядеть зелёным, но при этом ухудшать опыт пользователей (например, зависимость тайм-аутится или ошибки сконцентрированы в одном регионе). SLO заставляют измерять то, что реально чувствует пользователь.
Бюджеты ошибок: общий язык для обсуждения риска
Бюджет ошибок — это допустимый уровень ненадёжности, вытекающий из SLO. Если вы обещаете 99.9% успеха за 30 дней, у вас примерно 43 минуты допустимых ошибок за этот интервал.
Это даёт практическую систему принятия решений:
- бюджет в норме: внедряем фичи, проводим эксперименты, берём разумный риск
- бюджет горит: замедляем релизы, фокусируемся на надёжности, уменьшаем изменения
- бюджет исчерпан: приостанавливаем рискованные деплои и устраняем главные источники ошибок
Вместо споров на встречах по релизам вы обсуждаете число, которое видит вся команда.
Оповещать по скорости сжигания, а не по каждой вспышке
Лучше оповещать по burn rate (насколько быстро расходуется бюджет ошибок), а не по сырым счётчикам ошибок. Это уменьшает шум:
- кратковременный всплеск, который саморегулируется, может никого не пейджить
- затяжная проблема, которая быстро исчерпает бюджет, вызовет понятное и действенное оповещение
Многие команды используют два окна: быстрый burn (быстро пейджить) и медленный burn (тикет/уведомление).
Лёгкий стартовый набор SLO для типичного веб-сервиса
Начните с малого — 2–4 SLO, которые вы действительно будете использовать:
- Доступность: % успешных запросов (например, HTTP 2xx/3xx) за 30 дней.
- Латентность: p95 под порогом (разделяйте чтение/запись по необходимости).
- Критичный путь (например, checkout): успешность ключового бизнес-пути.
- Актуальность (если применимо): фоновые джобы выполняются в пределах X минут.
Когда эти метрики стабильны, можно расширять — иначе вы просто построите ещё одну стену дашбордов. Для дополнительной информации смотрите /blog/slo-monitoring-basics.
Оповещения, которые масштабируются без выгорания
Стандартизируйте теги без лишних усилий
Создайте интерфейс проверки правил тегирования, чтобы помочь командам стандартизировать сервис, окружение, команду и версию.
Оповещения — это то место, где многие программы наблюдаемости буксуют: данные есть, дашборды красивые, но on-call становится шумным и недоверенным. Если люди привыкают игнорировать оповещения, платформа теряет способность защищать бизнес.
Почему возникает усталость от оповещений (и почему сигналы дублируются)
Частые причины:
- слишком много «FYI» оповещений, не требующих действий
- копирование порогов между различными сервисами без учёта контекста
- множество инструментов/команд оповещающих об одном и том же (напр., APM и log-based мониторы одновременно)
- шумные метрики (скачки перцентилей, эффекты автоскейлинга), которые триггерят флуктуации вместо реальных проблем
В Datadog-домене дублирующие сигналы часто появляются, когда мониторы создаются с разных «поверхностей» (метрики, логи, трейсы) без выбора каноничного источника пейджа.
Маршрутизация: владение, серьёзность и «тихие часы»
Масштабирование оповещений начинается с правил маршрутизации, понятных людям:
- владение: у каждого монитора должен быть явный владелец (команда) и путь эскалации
- серьёзность: оставьте пейджинг для срочных пользовательских проблем; используйте тикеты/чат для менее серьёзных
- окна обслуживания: плановые деплои, миграции и нагрузочные тесты не должны генерить пейджи
Простые правила, которые делают оповещения полезными
Полезный дефолт: оповещайте по симптомам, а не по каждому изменению метрики. Пейджьте по тому, что чувствует пользователь (доля ошибок, проваленые checkout, устойчивая латентность, burn SLO), а не по «входам» (CPU, количество подов), если они не предсказывают влияние.
Ритм ревью оповещений, который действительно работает
Сделайте гигиену алертов частью операций: ежемесячная зачистка и настройка мониторов. Удаляйте мониторы, которые никогда не срабатывают, подстраивайте пороги, которые срабатывают слишком часто, и объединяйте дубликаты так, чтобы у каждого инцидента был один главный пейдж плюс вспомогательный контекст.
Сделано правильно, оповещения становятся рабочим процессом, которому люди доверяют — а не фоновым шумом.
Управление: как платформа остаётся удобной по мере роста
Называть наблюдаемость «платформой» — это не только иметь логи, метрики и трейсы в одном месте. Это также управление: согласованность и ограждения, которые сохраняют систему удобной, когда число команд, сервисов, дашбордов и алертов множится.
Без управления Datadog (или любая платформа) может превратиться в шумный альбом: сотни чуть-чуть разных дашбордов, непоследовательные теги, неясное владение и оповещения, которым никто не доверяет.
Управление — это проблема людей и процессов
Хорошее управление проясняет, кто решает что и кто отвечает, когда платформа становится грязной:
- платформенная команда: задаёт стандарты (теги, шаблоны дашбордов), предоставляет общие компоненты и поддерживает интеграции
- владельцы сервисов: отвечают за качество телеметрии своих сервисов и за то, чтобы мониторы были осмысленными
- безопасность и комплаенс: устанавливают правила обработки данных (PII, хранение, границы доступа) и ревью для рисковых интеграций
- лидерство: связывает управление с бизнес-приоритетами и финансирует работу
Практические механизмы, которые предотвращают «разрастание» наблюдаемости
Небольшие контролы эффективнее длинных политик:
- шаблоны по умолчанию: стартовые дашборды и пакеты мониторов по типу сервиса (API, worker, БД)
- политика тегов: небольшой обязательный набор (например,
service, env, team, tier) и ясные правила для необязательных тегов. По возможности — контроль через CI.
- доступ и владение: role-based доступы для чувствительных данных и требование владельца для дашбордов/мониторов
- флоу одобрения для изменений с высоким воздействием: мониторы, которые пейджят людей, лог-пайплайны, влияющие на стоимость, и интеграции с чувствительными данными должны проходить ревью
Переиспользование лучше изобретения заново
Самый быстрый способ масштабировать качество — делиться тем, что работает:
- общие библиотеки: внутренние пакеты или сниппеты, стандартизирующие поля логов, атрибуты трейсов и общие метрики
- повторно используемые дашборды и мониторы: центральный каталог «золотых» шаблонов, которые команды могут клонировать и адаптировать
- версируемые стандарты: относитесь к ключевым активам как к коду — документируйте изменения, удаляйте старые паттерны и анонсируйте обновления
Если хотите, чтобы это прижилось, сделайте управляемый путь — лёгким: меньше кликов, быстрее настройка и понятное владение.
Стоимость, ценность и маховик платформы
Когда наблюдаемость ведёт себя как платформа, появляется экономика платформ: чем больше команд подключено, тем больше телеметрии производится, и тем полезнее становится платформа.
Это создаёт маховик:
- больше сервисов → лучше видимость и корреляция
- лучше видимость → быстрее диагностика, меньше повторных инцидентов, больше доверия
- больше доверия → больше команд инструментируют и интегрируют → ещё больше данных
Но тот же цикл увеличивает стоимость. Больше хостов, контейнеров, логов, трейсов, синтетики и кастомных метрик могут расти быстрее бюджета, если не управлять ими сознательно.
Практические рычаги управления стоимостью (не убивая сигнал)
Вам не нужно «выключить всё». Начните с формирования данных:
- Сэмплинг: держите высокую детализацию трейсов для критичных эндпоинтов, агрессивнее сэмплируйте в других местах.
- Уровни хранения: короткое хранение для raw, high-volume логов; длинное хранение для отобранных стримов безопасности/аудита.
- Фильтрация и парсинг логов: отбрасывайте очевидный шум (health checks, статические ассеты) и стандартизируйте парсинг, чтобы можно было маршрутизировать по атрибутам.
- Агрегация метрик: предпочитайте перцентили, скорости и роллапы вместо неограниченной кардинальности (например, по user IDs).
KPI, которые связывают стоимость с результатом
Отслеживайте небольшой набор метрик, показывающих окупаемость платформы:
- MTTD (mean time to detect)
- MTTR (mean time to resolve)
- количество инцидентов и повторные инциденты (один и тот же корень)
- частота деплоев (и change failure rate, если вы её отслеживаете)
Квартальный обзор «ценность vs стоимость» (без обвинений)
Сделайте это обзором продукта, а не аудитом. Пригласите владельцев платформы, несколько команд-сервисов и финансы. Просмотрите:
- главные драйверы стоимости по типам данных (логи/метрики/трейсы) и по командам
- главные победы: инциденты сократились, предотвращённые аутеджи, удалённый рутин
- 2–3 согласованных действия (например, скорректировать правила сэмплинга, добавить уровни хранения, починить шумную интеграцию)
Цель — совместная ответственность: стоимость становится входной переменной для улучшения инструментирования, а не поводом прекратить наблюдаемость.
Что это значит для вашего стека инструментов наблюдаемости
Владейте исходным кодом
Быстро сгенерируйте внутренний инструмент, затем экспортируйте исходный код в репозиторий и проверьте.
Если наблюдаемость превращается в платформу, ваш стек перестаёт быть набором точечных решений и становится общей инфраструктурой. Этот сдвиг делает разрастание инструментов большим, чем просто неудобство: он создаёт дублирующее инструментирование, непоследовательные определения (что считается ошибкой?) и повышенную нагрузку на on-call, потому что сигналы не вяжутся между логами, метриками, трейсами и инцидентами.
Консолидация не обязательно = один вендор для всего. Это значит меньше систем записи телеметрии и реакции, ясное владение и меньше мест, которые надо проверять во время простоя.
Что консолидация реально решает
Разрастание инструментов часто скрывает издержки в трёх местах: время на переключение между UI, хрупкие интеграции, которые нужно поддерживать, и фрагментированное управление (имена, теги, хранение, доступ).
Более консолидационная платформа уменьшает переключения контекста, стандартизирует представления сервисов и делает рабочие процессы инцидентов повторяемыми.
Чеклист для принятия решений (быстро и практично)
При оценке стека (включая Datadog или альтернативы) проверьте:
- обязательные интеграции: провайдер облака, Kubernetes, CI/CD, управление инцидентами, пейджинг и ключевые хранилища данных — плюс любые бизнес-системы, без которых вы не можете выпускать
- рабочие процессы: можно ли пройти путь alert → owner → runbook → timeline → postmortem без ручного копирования/вставки?
- управление: стандарты тегов, контроль доступа, хранение и ограждения против разрастания дашбордов/мониторов
- модель ценообразования: что драйвит стоимость (хосты, контейнеры, инжест логов, индексированные трейсы)? Можно ли прогнозировать рост без сюрпризов?
Запустите пилот с ясной метрикой успеха
Выберите один-два сервиса с реальным трафиком. Определите одну метрику успеха, например «время до нахождения корня упало с 30 до 10 минут» или «сократить шумные оповещения на 40%». Инструментируйте только нужное и оцените результаты через две недели.
Храните внутреннюю документацию централизованно, чтобы знания накапливались — ссылаясь на пилотный рукбук, правила тегов и дашборды с одного места (например, /blog/observability-basics как внутренний стартовый пункт).
Практический план внедрения, который можно скопировать
Вы не «внедряете Datadog» единожды. Начинаете с малого, задаёте стандарты рано, затем масштабируете то, что работает.
Rollout 30/60/90 дней
Дни 0–30: Онборд (быстро доказать ценность)
Выберите 1–2 критичных сервиса и один клиент-ориентированный путь. Инструментируйте логи, метрики и трейсы последовательно, подключите уже используемые интеграции (облако, Kubernetes, CI/CD, on-call).
Дни 31–60: Стандартизация (сделать повторяемым)
Превратите полученные уроки в дефолты: именование сервисов, теги, шаблоны дашбордов, именование мониторов и владение. Создайте представления «золотых сигналов» (латентность, трафик, ошибки, насыщение) и минимальный набор SLO для ключевых эндпоинтов.
Дни 61–90: Масштаб (расширять без хаоса)
Онбордите дополнительные команды по тем же шаблонам. Введите управление (правила тегов, обязательные метаданные, процесс ревью для новых мониторов) и начните отслеживать «стоимость vs использование», чтобы платформа оставалась здоровой.
Где Koder.ai помогает (практично)
Когда вы воспринимаете наблюдаемость как платформу, часто появляются лёгкие «склейки»: UI каталога сервисов, хаб рукбуков, страница таймлайна инцидентов или внутренний портал, связывающий владельцев → дашборды → SLO → playbooks.
Это тот тип лёгкого внутреннего туллинга, который можно быстро собрать на Koder.ai — платформа vibe-coding, позволяющая генерировать веб-приложения через чат (обычно React на фронтенде, Go + PostgreSQL на бэкенде), с экспортом исходников и поддержкой деплоя. На практике команды используют её для прототипирования и доставки операционных поверхностей, которые упрощают управление и рабочие процессы без отвлечения продуктовой команды.
Быстрые победы, которые можно выпустить за неделю
- Топ-10 мониторов для availability, error rate, latency, saturation и ключевых зависимостей
- Маркеры деплоев (из CI/CD) на дашбордах и трейcах для мгновенной корреляции изменений
- Шаблон инцидента: что произошло, влияние, таймлайн, владельцы, ссылки на дашборды/запросы, дальнейшие шаги
Обучение, которое действительно заходит
Проведите два 45-минутных занятия: (1) «Как мы здесь делаем запросы» с общими паттернами (по сервису, env, региону, версии) и (2) «Плейбук по трассировке проблем» с простым потоком: подтвердить влияние → проверить маркеры деплоя → сузить до сервиса → смотреть трейсы → проверить здоровье зависимостей → принять решение об откате/смягчении.
Чеклист для копирования/вставки