Почему приложения в реальном времени кажутся медленными, даже если код быстрый
Скорость имеет два лица: пропускная способность и задержка. Пропускная способность — это сколько работы вы выполняете в секунду (запросы, сообщения, кадры). Задержка — это сколько времени занимает одна единица работы от начала до конца.
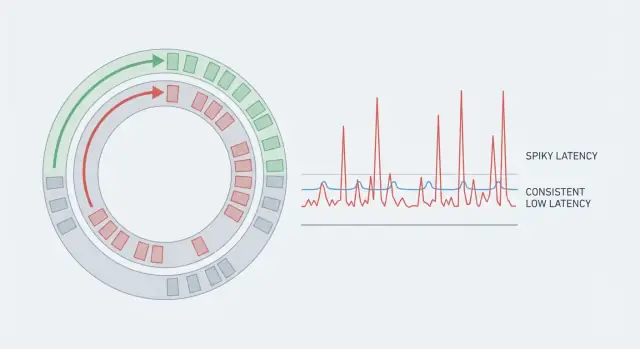
Система может иметь отличную пропускную способность и при этом казаться медленной, если некоторые запросы занимают значительно больше времени. Именно поэтому средние значения вводят в заблуждение. Если 99 действий занимают по 5 мс, а одно — 80 мс, среднее выглядит нормально, но тот, кто попал в кейс 80 мс, ощутит рывок. В реальных системах это важно, потому что такие редкие пики нарушают ритм.
Предсказуемая задержка — это не только стремление к низкому среднему. Это стремление к консистентности, чтобы большинство операций укладывались в узкий диапазон. Поэтому команды смотрят на хвост (p95, p99). Там прячутся паузы.
Пик в 50 мс может иметь значение в голосе и видео (глюки аудио), мультиплеере (резиновая синхронизация), реальной торговле (упущенные цены), промышленном мониторинге (опоздавшие оповещения) и живых дашбордах (цифры прыгают, оповещения кажутся ненадёжными).
Простой пример: чат‑приложение может доставлять сообщения быстро большую часть времени. Но если фоновая пауза задержит одно сообщение на 60 мс, индикаторы набора текста замерцают, и разговор будет казаться запаздывающим, хотя сервер «в целом» быстрый.
Если хотите, чтобы реальное время ощущалось реальным, вам нужны меньше сюрпризов, а не только более быстрый код.
Основы задержки: куда уходит время на самом деле
Большинство систем реального времени не медленны потому, что ЦПУ не справляется. Они кажутся медленными потому, что работа большую часть времени находится в ожидании: ожидании планирования, в очереди, в сети или в хранилище.
Сквозная задержка — это полное время от «что‑то случилось» до «пользователь увидел результат». Даже если ваш обработчик работает 2 мс, запрос всё равно может занять 80 мс, если он делит время ожиданий в пяти местах.
Полезный способ разбить путь:
- Сетевое время (клиент → край, сервис → сервис, повторы)
- Время планирования (поток ждёт запуска)
- Время в очереди (работа ждёт других задач)
- Время хранилища (диск, блокировки БД, промахи кэша)
- Время сериализации (кодирование/декодирование данных)
Эти ожидания складываются. Пара миллисекунд здесь и там превращают «быстрый» путь кода в медленный опыт.
Хвостовая задержка — то, из‑за чего пользователи начинают жаловаться. Средняя задержка может выглядеть нормально, но p95 или p99 означает самые медленные 5% или 1% запросов. Аутлайеры обычно приходят из редких пауз: цикл GC, «шумный сосед» на хосте, кратковременное блокирование, пополнение кэша или всплеск, создающий очередь.
Конкретный пример: обновление цены пришло по сети за 5 мс, ждало 10 мс занятого воркера, провело 15 мс в очереди за другими событиями и затем попало на задержку в базе 30 мс. Ваш код всё ещё выполнился за 2 мс, но пользователь ждал 62 мс. Цель — сделать каждый шаг предсказуемым, а не только сделать вычисления быстрыми.
Обычные источники джиттера помимо скорости кода
Быстрый алгоритм всё ещё может казаться медленным, если время на запрос скачет. Пользователи замечают пики, а не средние значения. Эти колебания — джиттер, и он часто приходит из вещей, которые ваш код полностью не контролирует.
Кэши CPU и поведение памяти — скрытые расходы. Если «горячие» данные не помещаются в кэш, ЦПУ ждёт RAM. Объектно‑тяжёлые структуры, разбросанная память и «ещё один поиск» превращаются в повторные промахи кэша.
Выделение памяти добавляет свою случайность. Создание множества короткоживущих объектов увеличивает давление на кучу, что позже проявляется паузами (сборка мусора) или конфликтом аллокатора. Даже без GC частые аллокации фрагментируют память и ухудшают локальность.
Планирование потоков — ещё один источник. Когда поток дескедулируется, вы платите за переключение контекста и теряете «тёплую» кэш‑локализацию. На загруженной машине ваш «реального времени» поток может ждать позади чужой работы.
Стычки за блокировки часто рушат предсказуемость. Замок, который «чаще свободен», может превратиться в конвой: потоки просыпаются, борются за ресурс и снова засыпают. Работа всё ещё выполняется, но хвостовая задержка растёт.
Ожидания ввода‑вывода могут перевесить всё остальное. Один системный вызов, полный сетевой буфер, TLS‑рукопожатие, сброс на диск или медленный DNS создают резкий пик, который никакая микрооптимизация не исправит.
Если вы охотитесь за джиттером, начните с поиска промахов кэша (часто из‑за указательных структур и случайного доступа), частых аллокаций, переключений контекста из‑за слишком большого числа потоков или шумных соседей, конфликтов блокировок и любого блокирующего I/O (сеть, диск, синхронное логирование).
Пример: сервис дисплея цен может вычислять обновления за микросекунды, но один синхронный вызов логгера или конкурентный замок для метрик может периодически добавлять десятки миллисекунд.
Martin Thompson и что такое паттерн Disruptor
Martin Thompson известен в инженерии низкой задержки фокусом на поведении систем под нагрузкой: важна не просто средняя скорость, а предсказуемая скорость. Вместе с командой LMAX он помог популяризировать паттерн Disruptor — эталонный подход для перемещения событий через систему с малыми и стабильными задержками.
Подход Disruptor отвечает на причины, делающие многие «быстрые» приложения непредсказуемыми: конфликты и координацию. Обычные очереди часто полагаются на замки или тяжёлые атомарные операции, будят потоки туда‑сюда и создают всплески ожиданий, когда продьюсеры и консьюмеры спорят о разделе структуры.
Вместо очереди Disruptor использует кольцевой буфер: фиксированный по размеру циклический массив слотов для событий. Продьюсеры резервируют следующий слот, записывают данные и публикуют порядковый номер. Консьюмеры читают в порядке, следуя за этим порядком. Поскольку буфер предвыделен, вы избегаете частых аллокаций и снижаете давление на сборщик мусора.
Ключевая идея — принцип единого писателя: держите одну компоненту ответственной за конкретное разделяемое состояние (например, курсор, который продвигается по кольцу). Меньше писателей — меньше моментов «кто следующий?».
Обратное давление явное. Когда потребители отстают, продьюсеры в конце концов наталкиваются на слот, который ещё используется. В этот момент система должна ждать, терять данные или замедляться, но делает это контролируемо и прозрачно, а не прячет проблему в неограниченной очереди.
Основные идеи дизайна, которые держат задержку согласованной
То, что делает дизайн в стиле Disruptor быстрым, — это не хитрая микрооптимизация. Это удаление непредсказуемых пауз, возникающих, когда система конфликтует сама с собой: аллокации, промахи кэша, конкуренция за блокировки и «медленная» работа в горячем пути.
Полезная метафора — сборочная линия. События движутся по фиксированному маршруту с ясными передачами. Это сокращает разделяемое состояние и упрощает поддержание простоты и измеримости каждого шага.
Делайте память и данные предсказуемыми
Быстрые системы избегают внезапных аллокаций. Если вы заранее выделяете буферы и переиспользуете объекты сообщений, вы снижаете "иногда"‑спайки, вызванные сборкой мусора, ростом кучи и конфликтами аллокатора.
Полезно держать сообщения маленькими и стабильными. Когда данные, к которым вы обращаетесь для каждого события, помещаются в кэш ЦПУ, вы тратите меньше времени на ожидание памяти.
На практике обычно важны такие привычки: переиспользовать объекты вместо создания новых на событие, держать данные компактными, отдавать предпочтение одному писателю для разделяемого состояния и аккуратно батчить, чтобы платить за координацию реже.
Делайте медленные пути очевидными
Приложения реального времени часто нуждаются в дополнительной работе: логирование, метрики, повторы или записи в базу. Мышление Disruptor — изолировать это от основного цикла, чтобы оно не могло блокировать его.
В потоке цен горячий путь может только валидировать тик и публиковать следующий снимок цены. Всё, что может застопорить (диск, сетевые вызовы, тяжёлая сериализация), перемещается в отдельного консюмера или боковой канал, чтобы предсказуемый путь оставался предсказуемым.
Архитектурные решения для предсказуемой задержки
Проверьте UX в реальном времени
Сгенерируйте клиент на Flutter, чтобы проверить тайминг тиков и плавность UI.
Предсказуемая задержка в основном — задача архитектуры. У вас может быть быстрый код и всё равно всплески, если слишком много потоков борются за одни и те же данные или если сообщения пересылаются по сети без нужды.
Начните с решения, сколько писателей и читателей трогают одну и ту же очередь или буфер. Один продьюсер проще держать плавным, потому что избегается координация. Мульти‑продьюсерные схемы повышают пропускную способность, но часто добавляют конфликты и ухудшают предсказуемость в худшем случае. Если нужны несколько производителей, уменьшайте совместные записи шардингом событий по ключу (например, по userId или instrumentId), чтобы у каждого шарда был свой «горячий» путь.
На стороне потребителей один консьюмер даёт самую стабильную временную характеристику, когда важен порядок, потому что состояние остаётся локальным для одного потока. Пулы воркеров полезны, когда задачи действительно независимы, но они добавляют задержки планирования и могут нарушать порядок, если не быть осторожным.
Батчинг — это компромисс. Малые батчи снижают накладные расходы (меньше пробуждений, меньше промахов кэша), но батчинг может добавить ожидание, если вы держите события ради полного батча. Если батчите в реальном времени, ограничьте время ожидания (например, «до 16 событий или 200 микросекунд, что наступит раньше»).
Границы сервисов тоже важны. Внутрипроцессная передача обычно лучше, когда нужна плотная задержка. Сетевые хопы дают масштабирование, но каждый хоп добавляет очереди, повторы и переменную задержку. Если нужен хоп, держите протокол простым и избегайте фан‑аута в горячем пути.
Практическое правило: держите путь с одним писателем на шард, масштабируйтесь шардингом ключей вместо общего горячего канала, батчьте с жёстким лимитом по времени, добавляйте пулы воркеров только для параллельной и независимой работы и рассматривайте каждый сетевой хоп как потенциальный источник джиттера, пока не измерите иначе.
Шаг за шагом: проектируем конвейер с низким джиттером
Начните с записанного бюджета задержки до того, как тронете код. Выберите цель (как «быстро» должно казаться) и p99 (какого значения нужно не превышать). Разделите это число по этапам: вход, валидация, сопоставление, сохранение и исходящие обновления. Если у этапа нет бюджета, у него нет ограничений.
Дальше нарисуйте полный поток данных и отметьте каждую передачу: границы потоков, очереди, сетевые хопы и обращения к хранилищу. Каждая передача — место, где прячется джиттер. Когда вы их видите, вы можете их сокращать.
Рабочий процесс, который держит дизайн честным:
- Напишите бюджет задержки для каждого этапа (цель и p99), плюс небольшой запас на неизвестное.
- Заметьте на схеме очереди, замки, аллокации и блокирующие вызовы.
- Выберите модель конкурентности, которую можно просто анализировать (один писатель, партиционированные воркеры по ключу или выделенный I/O‑поток).
- Определите форму сообщения заранее: стабильные схемы, компактные полезные нагрузки и минимальное копирование.
- Решите правила обратного давления заранее: отбрасывать, задерживать, деградировать или скидывать нагрузку. Сделайте это видимым и измеримым.
Затем решите, что можно сделать асинхронно, не сломав UX. Простое правило: всё, что меняет то, что пользователь видит «сейчас», остаётся на критическом пути. Всё остальное уходит в боковые пути.
Аналитика, аудит‑логи и вторичные индексы обычно безопасно отодвигать от горячего пути. Валидация, порядок и шаги, нужные для получения следующего состояния, как правило, остаются в нём.
Выбор рантайма и ОС, влияющий на хвостовую задержку
Быстрый код всё ещё может казаться медленным, когда рантайм или ОС приостанавливает вашу работу в неудачный момент. Цель — не только высокая пропускная способность, но и меньше сюрпризов в худших 1% запросов.
Рантаймы со сборкой мусора (JVM, Go, .NET) хороши для продуктивности, но могут вносить паузы, когда нужно очистить память. Современные сборщики лучше, чем раньше, но хвостовая задержка всё ещё может прыгать, если вы создаёте много короткоживущих объектов под нагрузкой. Языки без GC (Rust, C, C++) избегают пауз GC, но перекладывают цену на ручное владение и дисциплину аллокаций. В любом случае поведение памяти важно не меньше, чем скорость CPU.
Практическая привычка простая: найдите места аллокаций и сделайте их «скучными». Переиспользуйте объекты, заранее задавайте размеры буферов и избегайте превращать горячие данные в временные строки или карты.
Выбор потоковой модели тоже проявляется в джиттере. Каждая дополнительная очередь, асинхронный хоп или передача в пул потоков добавляют ожидание и увеличивают дисперсию. Предпочитайте небольшое число долгоживущих потоков, держите границы продьюсер‑консьюмер ясными и избегайте блокирующих вызовов в горячем пути.
Несколько настроек ОС и контейнера часто решают, будет ли хвост плавным или скачкообразным. Троттлинг CPU из‑за жёстких лимитов, шумные соседи на шаред‑хосте и неудачно размещённое логирование/метрики могут создать внезапные замедления. Если меняете что‑то одно, начните с измерения скорости аллокаций и переключений контекста во время всплесков задержки.
Данные, хранилище и границы сервисов без неожиданных пауз
От паттерна к прототипу
Превратите эту статью в рабочий скелет в стиле Disruptor, который можно бенчмаркить прямо сейчас.
Многие пики задержки — это не «медленный код», а ожидания, которые вы не запланировали: блокировка в базе, шторм повторов, зависимый запрос, который застревает, или промах кэша, превращающийся в полный круг.
Держите критический путь коротким. Каждый дополнительный хоп добавляет планирование, сериализацию, сетевые очереди и места блокировки. Если запрос можно ответить в одном процессе и из одного хранилища — делайте это первым. Делите на сервисы только тогда, когда каждый вызов опционален или строго ограничен по времени.
Ограниченное ожидание — разница между быстрыми средними и предсказуемой задержкой. Ставьте жёсткие таймауты на удалённые вызовы и быстро фейлите, когда зависимость нездорова. Цепи защит (circuit breakers) — не только чтобы спасать сервера. Они ограничивают, как долго пользователи могут застрять.
Когда доступ к данным блокирует, разделяйте пути. Чтения часто хотят индексированных, денормализованных, кэш‑дружелюбных форм. Записи требуют надёжности и упорядоченности. Разделение может убрать конкуренцию и сократить время удержания блокировок. Если согласованность допускает, запись только в лог (append‑only) часто ведёт себя предсказуемее, чем обновления in‑place, вызывающие горячие блоки строк или фоновое обслуживание.
Простое правило для приложений реального времени: персистентность не должна лежать на критическом пути, если она не нужна для корректности. Часто лучшая модель: обновить в памяти, ответить, а затем асинхронно сохранить с механизмом реплея (outbox или write‑ahead log).
Во многих конвейерных решениях на кольцевом буфере это выглядит так: опубликовать в памяти, обновить состояние, ответить, затем отдельный консьюмер батчит записи в PostgreSQL.
Реалистичный пример: обновления в реальном времени с предсказуемой задержкой
Представьте приложение для совместной работы (или небольшую мультиплеерную игру), которое шлёт обновления каждые 16 мс (примерно 60 раз в секунду). Цель не «быстро в среднем», а «обычно укладываться в 16 мс», даже если у одного пользователя плохое соединение.
Простой поток в стиле Disruptor выглядит так: ввод пользователя становится небольшим событием, публикуется в предвыделенный кольцевой буфер, затем обрабатывается фиксированным набором обработчиков по порядку (validate -> apply -> prepare outbound messages) и в конце рассылается клиентам.
Батчинг полезен на краях. Например, группируйте исходящие записи по клиенту один раз за тик, чтобы реже вызывать сетевой слой. Но не батчьте внутри горячего пути так, что вы ждёте "ещё немного" ради большего количества событий. Ожидание — это способ пропустить тик.
Когда что‑то замедляется, рассматривайте это как задачу с локализацией. Если один обработчик тормозит, изолируйте его за собственным буфером и публикуйте лёгкую работу вместо блокировки основного цикла. Если один клиент медленный, не позволяйте ему заблокировать вещатель; дайте каждому клиенту маленькую очередь отправки и отбрасывайте или коалесцируйте старые обновления, чтобы сохранять последнее состояние. Если глубина буфера растёт, применяйте обратное давление на границе (перестаньте принимать дополнительные входы для тика или деградируйте фичи).
Вы поймёте, что всё работает, когда числа станут скучными: глубина бэклога держится около нуля, отбрасываемые/коалесцируемые события редки и объяснимы, а p99 остаётся ниже бюджета тика при реалистичной нагрузке.
Частые ошибки, создающие пики задержки
Постройте предсказуемый конвейер
Прототипируйте конвейер с низкой задержкой на основе событий из одного чата в Koder.ai.
Большинство пиков — самопосаженные. Код может быть быстрым, но система всё равно останавливается, когда ждёт других потоков, ОС или чего‑то вне кэша ЦПУ.
Повторяющиеся ошибки:
- Использование общих блокировок повсюду, потому что это кажется простым. Одна конкурирующая блокировка может остановить много запросов.
- Смешивание медленного I/O в горячем пути: синхронное логирование, записи в БД или удалённые вызовы.
- Неограниченные очереди. Они прячут перегрузку до тех пор, пока не накопится секунды бэклога.
- Наблюдение за средними вместо p95 и p99.
- Перетюнинг слишком рано. Закрепление потоков не поможет, если задержки идут от GC, конкуренции или ожидания сокета.
Быстрый способ уменьшить пики — сделать ожидания видимыми и ограниченными. Вынесите медленную работу в отдельный путь, ограничьте очереди и решите заранее, что делать при переполнении (отбрасывать, сбрасывать нагрузку или деградировать функции).
Быстрая чек‑лист для предсказуемой задержки
Относитесь к предсказуемой задержке как к фиче продукта, а не случаю. Прежде чем оптимизировать код, убедитесь, что у системы есть ясные цели и ограничители.
- Установите явную цель p99 (и p99.9, если нужно), затем напишите бюджет задержки по этапам.
- Держите горячий путь свободным от блокирующего I/O. Если I/O должен быть, вынесите его в боковой путь и решите, что делать при задержке.
- Используйте ограниченные очереди и опишите поведение при перегрузке (отбрасывать, деградировать, коалесцировать или давить назад).
- Измеряйте постоянно: глубина бэклога, время на этапе и хвостовая задержка.
- Минимизируйте аллокации в горячем цикле и делайте их легко заметными в профиле.
Простой тест: сымитируйте всплеск (в 10× нормальная нагрузка на 30 секунд). Если p99 взлетает, спросите, где происходят ожидания: растущие очереди, медленный консьюмер, пауза GC или общий ресурс.
Следующие шаги: как применить это в своём приложении
Относитесь к паттерну Disruptor как к рабочему процессу, а не к выбору библиотеки. Докажите предсказуемую задержку с тонким срезом до добавления фич.
Выберите одно действие пользователя, которое должно ощущаться мгновенным (например, «пришла новая цена — UI обновился»). Запишите сквозной бюджет, затем измеряйте p50, p95 и p99 с самого начала.
Последовательность, которая обычно работает:
- Постройте тонкий конвейер с одним входом, одним основным циклом и одним выходом. Рано валидируйте p99 под нагрузкой.
- Явно разделите ответственности (кто владеет состоянием, кто публикует, кто потребляет) и держите разделяемое состояние маленьким.
- Добавляйте конкурентность и буферизацию малыми шагами и держите изменения обратимыми.
- Разворачивайте как можно ближе к пользователям при жёстком бюджете, затем снова измеряйте под реалистичной нагрузкой (те же размеры полезных нагрузок, те же шаблоны всплесков).
Если вы строите на Koder.ai (koder.ai), полезно сначала смоделировать поток событий в Planning Mode, чтобы очереди, блокировки и границы сервисов не возникли по случайности. Снапшоты и откаты также упрощают многократные эксперименты с задержкой и откат изменений, которые улучшают пропускную способность, но ухудшают p99.
Держите измерения честными. Используйте фиксированный тест‑скрипт, прогрейте систему и записывайте и пропускную способность, и задержку. Когда p99 прыгает при нагрузке, не начинайте сразу с «оптимизации кода». Ищите паузы из‑за GC, шумных соседей, всплесков логирования, планирования потоков или скрытых блокирующих вызовов.