15 июн. 2025 г.·8 мин
Доверить ИИ проектирование схем бэкенда, API и моделей данных
Исследуйте, как схемы и API, сгенерированные ИИ, ускоряют доставку, где они ошибаются и практический рабочий процесс для ревью, тестирования и управления дизайном бэкенда.
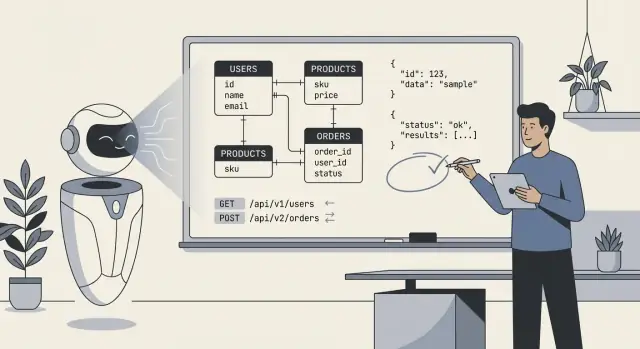
Что на самом деле означает «ИИ спроектировал наш бэкенд»
Когда говорят «ИИ спроектировал наш бэкенд», обычно имеют в виду, что модель сгенерировала первый черновик технического плана: таблицы базы данных (или коллекции), их взаимосвязи и API для чтения/записи данных. На практике это скорее «ИИ предложил структуру, которую можно реализовать и доработать», чем «ИИ всё построил сам».
Что обычно включает в себя бэкенд, спроектированный ИИ
Хотя бы минимально ИИ может сгенерировать:
- Схемы и сущности: таблицы/коллекции вроде
users,orders,subscriptions, поля и базовые типы. - Связи: one-to-many и many-to-many (например, заказ содержит много позиций; товар принадлежит многим категориям).
- Ограничения и валидации: обязательные поля, уникальные ключи, простые диапазоны, enum-подобные статусы и базовые правила ссылочной целостности.
- Поверхность API: CRUD-эндпойнты, формы запросов/ответов, паттерны пагинации, форматы ошибок и иногда рекомендации по версионированию.
Что ИИ не решит без вашего бизнес-контекста
ИИ может вывести «типичные» шаблоны, но не способен надёжно выбрать правильную модель при неоднозначных или доменно-специфичных требованиях. Он не знает ваших реальных политик по:
- Кто считается «пользователем» (роли? организации? гостевые аккаунты?).
- Какие поля юридически требуются, какие чувствительны или подлежат правилам хранения.
- Какие действия должны быть аудируемыми, обратимыми или требовать одобрения.
- Истинный смысл статусов (например,
cancelledvsrefundedvsvoided).
Правильное ожидание: кoупилот, а не окончательная инстанция
Относитесь к выходу ИИ как к быстрому, структурированному старту — полезному для исследования вариантов и обнаружения пропусков, но не как к спецификации, которую можно отправлять в продакшен без проверки. Ваша задача — предоставить чёткие правила и пограничные случаи, затем просмотреть то, что сгенерировал ИИ, так же, как вы бы проверили первый черновик младшего инженера: полезно, иногда впечатляет, но порой ошибается тонко.
Входные данные, определяющие качество вывода ИИ
ИИ может быстро набросать схему или API, но не может придумать недостающие факты, которые делают бэкенд «подходящим» для вашего продукта. Лучший результат получается, когда вы используете ИИ как быстрого младшего дизайнера: даёте чёткие ограничения — он предлагает варианты.
Какие входы действительно нужны ИИ
Перед запросом таблиц, эндпойнтов или моделей запишите базовое:
- Ключевые сущности и определения: какие объекты существуют (например, User, Subscription, Order) и что каждое значит в бизнесе.
- Основные рабочие процессы: основные пути (регистрация, оформление заказа, возвраты, утверждения) и состояния, через которые они проходят.
- Роли и права: кто что может (admin, staff, customer, auditor) и что нужно ограничивать.
- Потребности в отчётности и аналитике: вопросы, на которые нужно отвечать позже (месячная выручка, удержание когорт, метрики SLA), включая измерения для группировок.
- Интеграции и внешние идентификаторы: платёжные провайдеры, CRM, системы идентификации — и какие ID нужно сохранять.
- Ожидания по масштабу и производительности: порядки величин (сотни vs миллионы записей) и требования к задержкам.
- Соответствие и хранение: GDPR/CCPA, журналы аудита, правила удаления, требования к локации данных, сроки хранения.
- Операционные реалии: бэкапы, импорты, ручные правки и сценарии «служба поддержки должна редактировать X».
Почему нечеткие требования делают модели хрупкими
При расплывчатых требованиях ИИ склонен «угадывать» значения по умолчанию: везде опциональные поля, общие столбцы статуса, неясная ответственность и непоследовательные имена. Это часто приводит к схемам, которые выглядят разумно, но ломаются в реальной эксплуатации — особенно по правам доступа, отчётности и краевым случаям (возвраты, отмены, частичная отгрузка, многоэтапные утверждения). Позже это выльется в миграции, костыли и запутанные API.
Шаблон требований, который можно скопировать
Используйте это как начальную форму и вставьте в prompt:
Product summary (2–3 sentences):
Entities (name → definition):
-
Workflows (steps + states):
-
Roles & permissions:
- Role:
- Can:
- Cannot:
Reporting questions we must answer:
-
Integrations (system → data we store):
-
Constraints:
- Compliance/retention:
- Expected scale:
- Latency/availability:
Non-goals (what we won’t support yet):
-
Где ИИ особенно полезен: скорость, согласованность, полнота
ИИ лучше всего работает как быстрая машина черновиков: он может набросать разумную первую модель данных и соответствующий набор эндпойнтов за минуты. Эта скорость меняет способ работы — не потому что выход «волшебно правильный», а потому что у вас есть конкретное, с чем можно быстро итератировать.
Скорость: от пустой страницы до рабочей скелетной версии
Главная победа — устранение холодного старта. Дайте ИИ короткое описание сущностей, ключевых потоков и ограничений, и он предложит таблицы/коллекции, связи и базовую поверхность API. Особенно ценно для демо или исследования нестабильных требований.
Скорость полезна в:
- Прототипах для валидации концепции с реальными потоками данных
- Внутренних инструментах, где «достаточно хорошо» важнее идеальной модели
- Ранних итерациях продукта, где ожидается переписывание частей
Согласованность: скучные решения, выполненные одинаково
Люди устают и отклоняются от соглашений. ИИ не устает — он хорош в повторении соглашений по всему бэкенду:
- единообразные имена (
createdAt,updatedAt,customerId) - предсказуемые формы эндпойнтов (
/resources,/resources/:id) и полезных нагрузок - стандартная пагинация и параметры фильтрации
Эта согласованность упрощает документацию, тестирование и передачу проекта другому разработчику.
Полнота: «мы забыли эндпойнт?»
ИИ хорош в полноте. Если попросить полный набор CRUD плюс обычные операции (поиск, список, массовые обновления), он обычно генерирует более исчерпывающую начальную поверхность, чем поспешный человеческий черновик.
Обычная быстрая победа — стандартизованные ошибки: единый формат ошибки (code, message, details) по всем эндпойнтам. Даже при последующей доработке однообразный формат предотвращает смешение ad-hoc ответов.
Ключевой подход: пусть ИИ делает первые 80% быстро, а вы тратите время на те 20%, где требуется суждение — бизнес-правила, краевые случаи и «почему» модели.
Типичные режимы отказа в схемах, сгенерированных ИИ
Схемы от ИИ часто выглядят «чистыми»: аккуратные таблицы, разумные имена, связи, соответствующие happy path. Проблемы проявляются, когда в систему попадают реальные данные, реальные пользователи и реальные процессы.
Нормализация: слишком много или слишком мало
ИИ может колебаться между крайностями:
- Переизбыточная нормализация: дробление на кучу таблиц (например, отдельные таблицы для каждого атрибута), что делает общие запросы дорогими и увеличивает сложность join'ов.
- Недостаточная нормализация: вталкивание повторяющихся полей в одну таблицу (несколько столбцов адреса, денормализованные флаги статуса), что затрудняет валидацию и обновление.
Быстрая индикация: если ваши самые часто используемые страницы требуют 6+ join'ов — вероятно, переизбыточно; если для обновления одного значения нужно менять много строк — вероятно, недостаточно нормализовано.
Отсутствующие краевые случаи, важные в продакшене
ИИ часто упускает «скучные» требования, формирующие реальную архитектуру:
- Мультиарендность: забытый
tenant_idв таблицах или отсутствие учета масштабирования в уникальных ограничениях. - Soft delete: добавили
deleted_at, но не обновили правила уникальности и шаблоны запросов, чтобы исключать удалённые записи. - Аудит: отсутствие
created_by/updated_by, истории изменений или неизменяемых event-логов. - Часовые пояса: смешение
dateиtimestampбез правила (хранить в UTC vs отображать локально), что приводит к ошибкам ±1 дня.
Неверные предположения о уникальности и жизненном цикле
ИИ может предположить:
- поле глобально уникально, хотя уникальность нужна в пределах тенанта (например, «invoice_number»),
- поле обязательно, хотя на этапе онбординга оно опционально,
- одного статуса недостаточно, когда нужен жизненный цикл (draft → active → suspended → archived).
Эти ошибки проявляются в неловких миграциях и костылях на стороне приложения.
Пробелы в производительности
Большинство сгенерированных схем не учитывают, как вы будете запрашивать данные:
- отсутствие составных индексов для частых фильтров (tenant_id + created_at),
- нет плана для «горячих путей» (последние элементы, счётчики непрочитанных),
- сильная зависимость от JSON-полей без стратегии индексирования.
Если модель не может описать 5 главных запросов приложения — она не сможет корректно спроектировать схему под них.
Проектирование API: что ИИ делает правильно и где ошибается
ИИ часто неплохо генерирует API, которое «выглядит стандартно». Он отражает знакомые паттерны из популярных фреймворков и публичных API, что экономит время. Риск в том, что он оптимизирует под правдоподобие, а не под правильность для вашего продукта, данных и будущих изменений.
Что ИИ обычно делает правильно
Базовая модель ресурсов. При ясном домене ИИ выбирает адекватные имена и URL-структуру (например, /customers, /orders/{id}, /orders/{id}/items). Он также хорошо держит единообразие именования по эндпойнтам.
Сквозная заготовка эндпойнтов. ИИ часто включает необходимое: list vs detail, create/update/delete и предсказуемые формы запросов/ответов.
Базовые соглашения. Если явно запросить, он стандартизирует пагинацию, фильтрацию и сортировку (например ?limit=50&cursor=... или ?page=2&pageSize=25, ?sort=-createdAt, ?status=active).
Где ИИ часто ошибается
Протекающие абстракции. Классическая ошибка — экспонирование внутренних таблиц как «ресурсов», особенно когда схема содержит join-таблицы, денормализованные поля или колонки аудита. В результате API вроде /user_role_assignments отражает реализацию, а не пользовательскую концепцию («роли пользователя»), что усложняет использование и будущие изменения.
Несогласованная обработка ошибок. ИИ может смешивать стили: иногда возвращать 200 с телом ошибки, иногда использовать 4xx/5xx. Нужен чёткий контракт:
- используйте правильные HTTP-коды (
400,401,403,404,409,422) - единый формат ошибки (например,
{ "error": { "code": "...", "message": "...", "details": [...] } })
Версионирование как мысль задним числом. Многие дизайны от ИИ пропускают стратегию версионирования до момента боли. Решите с дня 1: path-версионирование (/v1/...) или версионирование через заголовки, и определите, что считается ломайщим изменением.
Правило практичности
Используйте ИИ для скорости и согласованности, но рассматривайте проект API как продуктовый интерфейс. Если эндпойнт повторяет структуру базы вместо модели мышления пользователя — это признак, что ИИ оптимизировал для простоты генерации, а не для долгосрочной удобочитаемости.
Практический рабочий процесс, чтобы использовать ИИ и не потерять контроль
Контролируйте реализацию
Сохраняйте полный контроль, экспортируя исходный код при необходимости кастомизации.
Относитесь к ИИ как к быстрому младшему дизайнеру: хорош в черновиках, но не несёт ответственности за финальную систему. Цель — использовать скорость, сохраняя архитектуру осознанной, рецензируемой и тестируемой.
Если вы используете платформу вроде Koder.ai, это разделение обязанностей особенно важно: платформа может быстро набросать и реализовать бэкенд (например, сервисы на Go с PostgreSQL), но вы всё равно должны задать инварианты, границы авторизации и правила миграций, с которыми готовы жить.
Повторяемый цикл: prompt → draft → review → tests → revise
Начинайте с плотного prompt'а, описывающего домен, ограничения и что считается успехом. Попросите сначала концептуальную модель (сущности, связи, инварианты), а не сразу таблицы.
Затем итерация в фиксированном цикле:
- Prompt: укажите требования, non-goals, предположения по масштабу и соглашения по именованию.
- Draft: попросите ИИ предложить концептуальную модель + первичную схему + API-контракты.
- Review: проверьте корректность домена, учтённые краевые случаи и соответствие продуктовым решениям.
- Tests: сгенерируйте или напишите тесты, кодирующие решения (валидации, авторизация, идемпотентность, безопасность миграций).
- Revise: верните обратно то, что не прошло (замечания ревью и падения тестов) и запросите исправленную версию.
Этот цикл работает потому, что превращает «предложения ИИ» в артефакты, которые можно доказать или отвергнуть.
Разделяйте концептуальную модель, физическую схему и API-контракты
Держите три слоя отдельно:
- Концептуальная модель: что важно бизнесу (например, «подписку можно приостановить», «счёт должен ссылаться на платёжный период»).
- Физическая схема: как вы храните это (таблицы/коллекции, индексы, ограничения, партиционирование).
- API-контракты: как клиенты с этим взаимодействуют (ресурсы, форматы запросов/ответов, коды ошибок, стратегия версионирования).
Просите ИИ выводить эти слои отдельными разделами. Когда что-то меняется (новый статус или правило), обновляйте сначала концептуальный слой, затем согласовывайте схему и API. Это уменьшает случайную связанность и облегчает рефакторы.
Фиксируйте решения заметками дизайна
Каждая итерация должна оставлять след. Используйте короткие заметки в стиле ADR (не более страницы), фиксирующие:
- Решение: что выбрано (например, «soft delete через
deleted_at»). - Обоснование: почему (требования аудита, процесс восстановления).
- Альтернативы: и почему отвергнуты.
- Последствия: влияние на миграции, сложность запросов, поведение API.
Когда вы вставляете обратную связь в ИИ, включайте релевантные заметки дословно. Это не даст модели «забыть» предыдущие выборы и поможет команде в будущем.
Prompt'ы, которые дают лучшие схемы и API
ИИ проще направлять, если относиться к prompt'у как к задаче написания спецификации: определите домен, сформулируйте ограничения и требуйте конкретных артефактов (DDL, таблицы эндпойнтов, примеры). Цель — не «будь креативным», а «будь точным».
Prompt'ы для сущностей и связей (с ограничениями)
Просите модель не только схему, но и правила, поддерживающие её согласованность.
- «Спроектируй реляционную схему для subscriptions с сущностями: User, Plan, Subscription, Invoice. Укажи кардинальности, уникальные ограничения и стратегию soft-delete. Правила: одна активная подписка на пользователя; счёт должен ссылаться на неизменяемую цену плана в момент покупки; валюта — ISO-код; метки времени — в UTC.»
Если у вас уже есть соглашения, укажите их: стиль именования, тип ID (UUID vs bigint), политика nullable и ожидания по индексам.
Prompt'ы для эндпойнтов и контрактов (с примерами)
Запрашивайте таблицу API с явными контрактами, а не просто список маршрутов.
- «Предложи REST-эндпойнты для управления Subscriptions. Для каждого эндпойнта: method, path, auth, query params, request JSON, response JSON, error codes и рекомендации по идемпотентности. Приведи примеры успешного выполнения и двух вариантов ошибок.»
Добавьте бизнес-поведение: стиль пагинации, поля для сортировки и правила фильтрации.
Prompt'ы для миграций и обратной совместимости
Заставьте модель мыслить в релизах.
- «Мы добавляем
billing_addressв Customer. Предложи безопасный план миграции: SQL для форвард-миграции, шаги для backfill, rollout с feature-flag и стратегию отката. API должна оставаться совместимой 30 дней; старые клиенты могут не передавать поле.»
Антипаттерны в prompt'ах, которых стоит избегать
Расплывчатые prompt'ы дают расплывчатые системы.
- «Спроектируй базу данных для e-commerce» (слишком широко)
- «Сделай это масштабируемым и безопасным» (нет измеримых ограничений)
- «Сгенерируй лучшую схему» (нет доменных правил)
- «Создай API для всего» (нет приоритетов и границ)
Если хотите лучший результат — уточняйте правила, краевые случаи и формат результата.
Чеклист для человека перед релизом
Сделайте доступным для пользователей
Подключите бэкенд к пользовательскому домену, когда будете готовы поделиться.
ИИ может набросать приличный бэкенд, но безопасная публикация требует человеческой проверки. Рассматривайте этот чеклист как gate для релиза: если вы не можете уверенно ответить на пункт — остановитесь и исправьте перед тем, как данные окажутся в проде.
Чеклист по схеме (таблицы, коллекции, колонки)
- Первичные ключи: у каждой таблицы есть явный PK. Если используются UUID, подтвердите стратегию генерации (в БД или в приложении) и индексирование.
- Внешние ключи и ограничения: добавьте FK там, где связи реальны. Проверьте намерения для ON DELETE/ON UPDATE (restrict vs cascade vs set null).
- Уникальности: обеспечьте уникальность в БД (не только в коде): email'ы, внешние ID, составные ограничения (напр.,
(tenant_id, slug)). - Nullability: пересмотрите каждое nullable-поле. Если «неизвестно» отличается от «пусто», моделируйте это явно.
- Индексы: добавьте индексы для частых фильтров/сортировок/джоинoв. Уберите случайные индексы на полях с низкой кардинальностью.
- Согласованность имен: выберите соглашения (singular vs plural, суффиксы
_id, временные поля) и применяйте ровно.
Решения по целостности данных (дорогие для изменения позже)
Зафиксируйте правила система в письменном виде:
- Референтная целостность: какие связи никогда не должны быть разорваны? Какие могут быть best-effort?
- Cascading rules: если родитель удаляется, должны ли дети удаляться, становиться сиротами или блокироваться?
- Стратегия soft delete: при использовании soft delete убедитесь, что запросы не «воскрешают» удалённые записи. Решите, должны ли уникальные ограничения игнорировать soft-deleted строки.
Чеклист по API (поведение и безопасность)
- Аутентификация и авторизация: укажите, кто может вызывать каждый эндпойнт и к чему он имеет доступ (особенно для мультиарендности).
- Валидация: валидируйте типы, диапазоны, форматы и кросс-поле правила. Не полагайтесь на ошибки БД как на единственный механизм валидации.
- Лимиты и защита от абуза: установите разумные дефолты, по пользователю/токену/IP там, где нужно.
- Идемпотентность: для операций создания/платежей поддерживайте идемпотентные ключи или детерминированные request-id.
- Единообразные ошибки: стандартизируйте форму ошибок и HTTP-коды. Убедитесь, что сообщения не выдают внутренности.
Перед слиянием выполните быстрый сценарий: «happy path + worst path»: нормальный запрос, неверный запрос, неавторизованный запрос, сценарий высокой нагрузки. Если поведение API вас удивляет — оно удивит и ваших пользователей.
Стратегия тестирования для бэкендов, сгенерированных ИИ
ИИ может быстро сгенерировать схему и поверхность API, но он не доказывает, что бэкенд корректно ведёт себя при реальном трафике, реальных данных и будущем развитии. Относитесь к выходу ИИ как к черновику и фиксируйте его тестами.
Контрактные тесты для API
Начните с контрактных тестов, проверяющих запросы, ответы и семантику ошибок — не только «happy path». Запустите их против реального экземпляра сервиса (или контейнера).
Сфокусируйтесь на:
- статусах и телах ошибок (
400vs404vs409) - граничных случаях валидации (пустые строки, слишком большие полезные нагрузки, неожиданные поля)
- стабильности пагинации и сортировки (порядок, корректность курсора)
- идемпотентности для create/update (безопасные повторные запросы, использование idempotency key, если есть)
Если публикуете OpenAPI-спецификацию, генерируйте тесты из неё — но также добавьте вручную написанные случаи для сложных правил, которые спецификация не выразит (правила авторизации, бизнес-ограничения).
Тесты миграций и планы отката
Сгенерированные ИИ схемы часто пропускают операционные детали: безопасные значения по умолчанию, backfill и обратимость. Добавьте тесты миграций, которые:
- применяют миграции на пустой БД и на «грязном» старом снапшоте
- проверяют ограничения (уникальность, FK) после backfill
- отрабатывают откат (или, по крайней мере, план forward-fix) для каждой миграции
Держите скриптованный план отката для продакшена: что делать, если миграция медленная, блокирует таблицы или ломает совместимость.
Нагрузочное тестирование под реальные шаблоны запросов
Не тестируйте абстрактные эндпойнты. Снимите реальные шаблоны запросов (просмотры списков, поиск, join'ы, агрегации) и нагрузите их.
Измеряйте:
- p95/p99 latency по эндпойнтам
- количество запросов к БД и медленные запросы
- использование индексов (и отсутствующие индексы)
Здесь ИИ чаще всего подводит: «разумные» таблицы, которые при нагрузке дают дорогие join'ы.
Основы безопасности в тестировании
Добавьте автоматические проверки на:
- правила AuthZ (пользователь A не может получить данные пользователя B)
- инъекции (SQL/NoSQL, path traversal, JSON injection)
- обработку чувствительных данных (нет секретов в логах, корректное маскирование полей, шифрование где нужно)
Даже базовые проверки предотвращают самые дорогие ошибки ИИ: работающие, но излишне открытые эндпойнты.
Миграции, рефакторинг и долгосрочная поддерживаемость
ИИ может набросать хорошую «версию 0» схемы, но бэкенд живёт до версии 50. Разница между системой, которая стареет достойно, и той, что разваливается — в том, как вы эволюционируете: миграции, контролируемые рефакторинги и документация намерений.
Безопасное развитие схем, сгенерированных ИИ
Обращайтесь с каждым изменением схемы как с миграцией, даже если ИИ советует «просто alter table». Используйте явные обратимые шаги: сначала добавляйте новые колонки, делайте backfill, потом ужесточайте ограничения. Предпочитайте аддитивные изменения (новые поля, таблицы) разрушительным изменениям (переименования/удаления), пока не подтвердите, что ничего не зависит от старой формы.
Когда просите ИИ обновить схему, включайте текущую схему и правила миграций, которые вы соблюдаете (например: «не дропать колонки; использовать expand/contract»). Это уменьшит шанс предложить теоретически корректную, но рискованную в продакшене правку.
Как справляться с ломающими изменениями без хаоса
Ломающие изменения редко происходят в одно мгновение — это переход.
- Депрекации: поддерживайте старые поля/эндпойнты, логируйте их использование.
- Dual-write: записывайте и в старую, и в новую структуру в период перехода.
- Backfills: выполняйте одноразовую или инкрементальную задачу для заполнения новых структур.
ИИ полезен в составлении пошагового плана (включая SQL-фрагменты и порядок rollout), но вы должны проверить влияние на runtime: блокировки, долгие транзакции и возможность прерывания backfill.
Рефакторинг моделей данных без переписывания всего
Рефакторинг должен стремиться к изоляции изменений. Если нужно нормализовать, разбить таблицу или ввести event-log, сохраняйте совместимые слои: представления, трансляционный код или «shadow» таблицы. Просите ИИ предложить рефакторинг, сохраняющий API-контракты, и перечислить, что должно измениться в запросах, индексах и ограничениях.
Документируйте предположения, чтобы будущие prompt'ы были последовательны
Большая часть дискрепанса возникает, когда следующий prompt забывает первоначальный замысел. Держите короткий «контракт модели данных»: правила именования, стратегия ID, семантика временных меток, политика soft-delete и инварианты («сумма заказа вычисляется, а не хранится»). Ссылайтесь на него в внутренних доках (например, /docs/data-model) и переиспользуйте в будущих prompt'ах, чтобы система проектировалась в одних и тех же границах.
Соображения по безопасности и приватности
Итерации без страха
Экспериментируйте с миграциями и безопасно откатывайтесь с помощью снимков и отката.
ИИ может быстро набросать таблицы и эндпойнты, но он не несёт ответственности за риски. Рассматривайте безопасность и приватность как первоочередные требования, которые вы добавляете в prompt, а затем проверяете при ревью — особенно для чувствительных данных.
Начинайте с классификации данных
Перед принятием любой схемы пометьте поля по чувствительности (публичные, внутренние, конфиденциальные, регламентируемые). Классификация определяет, что шифруется, маскируется или минимизируется.
Например: пароли никогда не хранятся в явном виде (только солёные хэши), токены короткоживущие и шифруются в покое, PII (email/телефон) может требовать маскирования в админских видах и экспортe. Если поле не нужно для ценности продукта — не храните его: ИИ часто добавляет «полезные» атрибуты, увеличивающие поверхность утечки.
Контроль доступа: RBAC vs ABAC
ИИ обычно по умолчанию делает простые проверки ролей. RBAC легко понимать, но он ломается для правил владения («пользователи видят только свои счета») или контекстных правил («служба поддержки видит данные только в рамках активного тикета»). ABAC справляется с этим лучше, но требует явных политик.
Будьте ясны, какой подход вы используете, и обеспечьте единообразное применение по эндпойнтам — особенно по спискам/поиску, где чаще всего происходят утечки.
Предотвращайте случайное логирование чувствительных полей
Сгенерированный код может логировать полные тела запросов, заголовки или строки БД при ошибках. Это приводит к утечке паролей, токенов и PII в логи и APM-инструменты.
Установите дефолты: структурированные логи, allowlist полей для логирования, редактирование секретов (Authorization, cookies, reset tokens) и избегайте логирования «сырого» payload'а при ошибках валидации.
Приватность, хранение и удаление
Проектируйте возможность удаления с самого начала: удаления по запросу пользователя, закрытие аккаунта и «право быть забытым». Определите сроки хранения по классам данных (журналы аудита vs маркетинговые эвенты) и убедитесь, что можете доказать, что и когда было удалено.
Если вы храните логи аудита, держите минимальные идентификаторы, защищайте их более жёстко и документируйте, как экспортировать или удалить данные по запросу.
Когда стоит использовать ИИ (а когда нет)
ИИ лучше всего, когда вы относитесь к нему как к быстрому младшему архитектору: хорош для первого черновика, слаб для доменно‑критичных компромиссов. Важный вопрос: не «Может ли ИИ спроектировать мой бэкенд?», а «Какие части ИИ может безопасно набросать, а какие требуют экспертного контроля?».
Подходящие случаи: черновики, прототипы и понятные паттерны
ИИ экономит время при:
- Небольших прототипах, внутренних инструментах и MVP, где цель — быстрое обучение.
- CRUD‑нагруженных системах с знакомыми сущностями (пользователи, заказы, подписки) и стандартными ограничениями.
- Моментах «пустой страницы»: генерация начальной схемы, поверхности API и соглашений по именам для итерации.
Здесь ИИ ценен за скорость, согласованность и полноту — особенно если вы понимаете поведение продукта и видите ошибки.
Неподходящие случаи: регламентированные, высокорисковые или глубокодоменные системы
Будьте осторожны (или используйте ИИ только как источник вдохновения), когда работаете в:
- Финансах: книги учёта, сверки, журналы аудита и правила идемпотентности, требующие точности.
- Здравоохранении: пациентские данные, модели согласия, правила хранения и интероперабельности.
- Сферах, критичных по безопасности: где «разумное предположение» может привести к серьёзному инциденту.
В таких областях экспертность важнее скорости ИИ. Тонкие требования — юридические, клинические, бухгалтерские — часто отсутствуют в prompt'е, и ИИ уверенно заполнит пробелы.
Руководство по решению: использовать ИИ для черновиков, требовать одобрения людей
Практическое правило: дайте ИИ предлагать варианты, но требуйте финального ревью по инвариантам модели данных, границам авторизации и стратегии миграций. Если вы не можете назвать ответственного за схемы и контракты API — не выпускайте продукт, спроектированный ИИ.
Следующие шаги
Если вы оцениваете рабочие процессы и защитные механизмы, смотрите сопутствующие материалы в /blog. Если хотите помощь в применении этих практик в процессе вашей команды, посмотрите /pricing.
Если вам нужен end-to-end рабочий процесс, где можно итерировать через чат, генерировать рабочее приложение и при этом сохранять контроль через экспорт исходников и rollback-friendly снапшоты — Koder.ai спроектирован именно под такой стиль build-and-review.
FAQ
Что на практике значит «ИИ спроектировал наш бэкенд»?
Обычно это означает, что модель сгенерировала первый черновик из:
- сущностей/таблиц (или коллекций) и полей
- связей и базовых ограничений
- стартового набора CRUD-подобных API-эндпойнтов
Команда людей по-прежнему должна проверить бизнес-правила, границы безопасности, производительность запросов и безопасность миграций, прежде чем выпускать в продакшен.
Какую информацию стоит дать ИИ перед запросом схемы или API?
Дайте AI конкретные данные, которые он не сможет надежно угадать:
- определения сущностей (что каждое слово означает в бизнесе)
- ключевые рабочие процессы и переходы состояний
- роли/права доступа и границы тенантов
- вопросы для отчётности, которые понадобятся позже
- интеграции и внешние идентификаторы, которые нужно сохранять
- цели по нагрузке/латентности
- правила соответствия, хранения и удаления данных
Чем четче ограничения, тем меньше ИИ «заполняет пробелы» хрупкими значениями по умолчанию.
Почему следует разделять концептуальную модель, физическую схему и API?
Начните с концептуальной модели (бизнес-концепты + инварианты), затем выводите:
- физическую схему (таблицы, ограничения, индексы)
- API-контракты (ресурсы, полезные нагрузки, ошибки)
Разделение слоев упрощает изменение хранения без поломки API и позволяет править API, не нарушая бизнес-правил.
Какие наиболее частые сбои встречаются в схемах, сгенерированных ИИ?
Типичные проблемы:
- избыточная или недостаточная нормализация (много join'ов vs дублирование данных)
- отсутствие scoping'а для мультиарендности (
tenant_idи составные уникальные ограничения) - ошибки со soft-delete (уникальности и запросы не учитывают
deleted_at)
Как убедиться, что схема, сгенерированная ИИ, не будет медленной в продакшене?
Попросите ИИ проектировать вокруг ваших топовых запросов, затем проверьте:
- какие фильтры/сортировки наиболее частые (например,
tenant_id + created_at) - какие эндпойнты «горячие» (последние элементы, счётчики непрочитанных)
- где нужны составные индексы
- где будут частые и дорогие join'ы
Если вы не можете перечислить топ‑5 запросов/эндпойнтов, план индексации считается неполным.
Что ИИ обычно делает неправильно при генерации REST API?
ИИ хорошо создаёт стандартную структуру, но стоит следить за:
- эндпойнтами, которые отражают таблицы (утечка абстракций, например ресурсы join-таблиц)
- смешанной семантикой ошибок (иногда
200с телом ошибки, иногда4xx/5xx) - отсутствием правил версионирования и политики при ломающих изменениях
Обращайтесь с API как с продуктовым интерфейсом: моделируйте эндпойнты вокруг представления пользователя, а не деталей базы данных.
Какой безопасный рабочий процесс для итераций с ИИ, чтобы не потерять контроль?
Используйте повторяемый цикл:
- Prompt: ограничения, non-goals, соглашения по именованию и предположения по масштабу
- Draft: концептуальная модель + схема + API-контракты
- Review: проверка доменных правил, краёв и безопасности
Как стандартизировать обработку ошибок в API, сгенерированном ИИ?
Используйте согласованные HTTP-коды и единый формат ошибки, например:
Что тестировать в первую очередь для бэкенда, сгенерированного ИИ?
Сфокусируйтесь на тестах, которые фиксируют поведение:
- контрактные тесты API (коды ответа, граничные случаи валидации, стабильность пагинации)
- тесты авторизации (пользователь А не может получить доступ к ресурсам пользователя Б)
- тесты идемпотентности для операций создания/платежей
- тесты миграций (применение из пустой БД + со старым снимком; проверка ограничений после backfill)
- базовые тесты безопасности (инъекции, редактирование логов для чувствительных полей)
Тесты — это способ «владеть» дизайном вместо слепого принятия предположений ИИ.
Когда плохо полагаться на ИИ в проектировании бэкенда?
Хорошо использовать ИИ для черновиков, когда шаблоны понятны (MVP, внутренние инструменты). Будьте осторожны, если:
- требования регулируются или высокорисковы (финансы, здравоохранение, критичные по безопасности системы)
- корректность зависит от тонких доменных правил (ведомости, сверки, согласия)
- вы не можете назвать человека, ответственного за инварианты схемы, границы авторизации и стратегию миграций
Политика: ИИ предлагает варианты, но люди обязаны подписываться на инварианты схемы, авторизацию и стратегию выпуска/миграций.