Что такое графовая база данных (без хайпа)
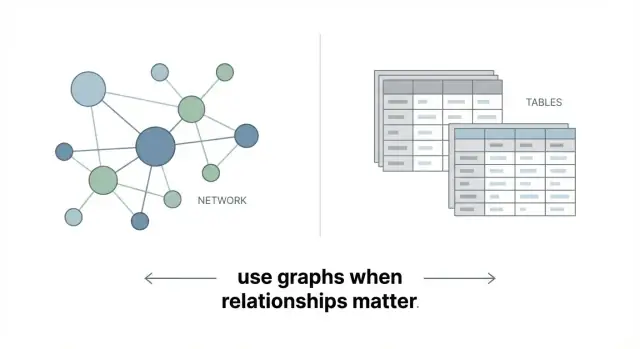
Графовая база данных хранит данные как сеть, а не как набор таблиц. Суть проста:
- Узлы — это «вещи», которые вам важны (покупатель, товар, счёт, устройство, местоположение).
- Связи соединяют узлы (customer BOUGHT product, account TRANSFERRED_TO account, user FOLLOWS user).
- Свойства — детали, которые вы повесите на узлы и связи (имя, цена, метка времени, сумма, статус).
Вот и всё: графовая база создана для прямого представления связанных данных.
Связи — «первоклассные» сущности
В графовой базе связи — не второстепенная мысль: они хранятся как реальные, запрашиваемые объекты. Связь может иметь свои свойства (например, у PURCHASED можно хранить дату, канал и скидку), и вы можете эффективно переходить от одного узла к другому.
Это важно, потому что многие бизнес-вопросы естественно про пути и связи: «Кто с кем связан?», «На сколько шагов удалён этот объект?» или «Какие общие связи между этими двумя вещами?»
Чем это отличается от таблиц и JOIN
Реляционные базы отлично работают с упорядоченными записями: клиенты, заказы, счета. Связи там тоже есть, но обычно представлены косвенно через внешние ключи, и объединение нескольких прыжков часто требует JOIN между несколькими таблицами.
Графы держат связи рядом с данными, поэтому исследовать многошаговые отношения обычно проще и естественнее моделировать и запрашивать.
Ожидания
Графовые базы великолепны, когда связи — это главное: рекомендации, мошеннические группы, картирование зависимостей, графы знаний. Они не автоматически лучше для простых отчётов, итогов или строго табличных нагрузок. Цель не заменить каждую БД, а использовать граф там, где связность создаёт ценность.
Почему связи меняют правила игры
Большинство бизнес‑вопросов не про отдельную запись — они про то, как вещи связаны.
Клиент — не просто строка; он связан с заказами, устройствами, адресами, обращениями в службу, рефералами и иногда с другими клиентами. Транзакция — не просто событие; она связана с торговцем, способом оплаты, локацией, временным окном и цепочкой связанных событий. Когда вопрос «кто/что с кем связано, и как?» — данные о связях выходят на первый план.
Траверсалы: следуем по связям шаг за шагом
Графовые базы спроектированы для траверсалов: вы начинаете с одного узла и «идёте» по сети, следуя рёбрам.
Вместо многократных JOIN вы выражаете интересующий путь: Customer → Device → Login → IP Address → Other Customers. Такое поэтапное описание совпадает с тем, как люди расследуют мошенничество, трассируют зависимости или объясняют рекомендации.
Почему многошаговые запросы становятся проще
Разница проявляется, когда нужны многошаговые переходы (2, 3, 5 шагов) и вы заранее не знаете, где появятся интересные связи.
В реляционной модели такие вопросы часто превращаются в длинные цепочки JOIN с дополнительной логикой, чтобы избегать дубликатов и контролировать длину пути. В графе «найди все пути до N шагов» — нормальный и читаемый паттерн, особенно в модели property graph.
Свойства связей добавляют смысл
Рёбра — не просто линии; они могут нести данные:
- Тип: purchased, referred, works_with
- Время: когда связь началась, закончилась или последний раз случалась
- Вес: частота, оценка уверенности, сумма, уровень риска
Эти свойства позволяют задавать более точные вопросы: «связи за последние 30 дней», «самые сильные привязки» или «пути, включающие высокорискованные транзакции» — без вынужденного перемещения всего в отдельные таблицы поиска.
Лучшие сценарии для графовых баз данных
Графы блистают, когда ваши вопросы зависят от связности: «кто с кем связан, через что и на сколько шагов?» Если ценность данных в связях (а не только в строках атрибутов), графовая модель делает моделирование и запросы более естественными.
Социальные и профессиональные сети
Всё, что похоже на сеть — друзья, подписчики, коллеги, команды, рефералы — легко отображается узлами и связями. Типичные вопросы: «взаимные связи», «кратчайший путь к человеку» или «кто связывает эти две группы?» Такие запросы часто неудобны или медленны при вынужденном использовании множества таблиц с JOIN.
Рекомендации (и discovery)
Рекомендательные системы часто зависят от многошаговых связей: пользователь → товар → категория → похожие товары → другие пользователи. Графы подходят для «люди, которые лайкали X, также лайкали Y», «часто просматриваемые вместе» и «найди товары, связанные общими атрибутами или поведением». Полезно, когда сигналы разнообразны и постоянно добавляются новые типы связей.
Мошенничество и расследования рисков
Графы для обнаружения мошенничества хороши, потому что подозрительное поведение редко изолировано. Аккаунты, устройства, транзакции, телефоны, e‑mail и адреса формируют сети общих идентификаторов. Граф упрощает поиск колец, повторяющихся шаблонов и косвенных связей (например, два «несвязанных» аккаунта используют одно устройство через цепочку активности).
Картирование сети и ИТ‑зависимостей
Для сервисов, хостов, API, вызовов и владения главный вопрос — зависимость: «что сломается, если это изменится?» Графы поддерживают анализ воздействия, поиск коренной причины и запросы «blast radius», когда системы взаимосвязаны.
Графы знаний
Графы знаний связывают сущности (люди, компании, продукты, документы) с фактами и ссылками. Это помогает в поиске, разрешении сущностей и прослеживании «почему» факт известен (происхождение) через множество связанных источников.
Частые графовые вопросы, которые легко решаются
Графовые БД хороши, когда вопрос действительно про связи: кто с кем связан, через какие цепочки и какие шаблоны повторяются. Вместо многократных JOIN вы задаёте вопрос о связях напрямую и держите запрос читаемым по мере роста сети.
1) Поиск пути: «Как A и B связаны?»
Типичные вопросы:
- «Какой кратчайший путь от этого клиента к тому торговцу?»
- «Какие коллеги связывают Алису и Боба и на сколько шагов?»
- «Покажите все маршруты от этого устройства до того аккаунта в пределах 3 прыжков.»
Это полезно для поддержки клиентов («почему мы это предложили?»), комплаенса («покажите цепочку владения») и расследований («как это распространилось?»).
2) Выявление сообществ: группы и кластеры в сети
Графы помогают обнаруживать естественные объединения:
- «Какие клиенты формируют кластер по общим адресам, телефонам и устройствам?»
- «Где находятся плотные сообщества в нашей сети поставщиков?»
Это можно использовать для сегментации пользователей, поиска мошеннических групп или понимания того, как продукты приобретаются совместно. «Группа» определяется способом связности, а не одним столбцом.
3) Центральность и влияние: поиск важных узлов
Иногда вопрос не просто «кто связан», а «кто важен» в сети:
- «Какой аккаунт лежит на большинстве путей между другими?»
- «Какой продукт является мостом между двумя сегментами клиентов?»
Такие центральные узлы указывают на инфлюенсеров, критическую инфраструктуру или узкие места, которые стоит мониторить.
4) Поиск шаблонов: «найти треугольники» и «кольца»
Графы отлично ищут повторяющиеся формы:
- Треугольники: «A знает B, B знает C, C знает A.»
- Кольца: «Аккаунты переводят деньги по кругу.»
В Cypher треугольник может выглядеть так:
MATCH (a)-[:KNOWS]-\u003e(b)-[:KNOWS]-\u003e(c)-[:KNOWS]-\u003e(a)
RETURN a,b,c
Даже если вы никогда не пишете Cypher, это показывает, почему графы понятны: запрос повторяет картинку в вашей голове.
Граф vs Реляционная: реальная разница
Реляционные БД хороши для того, для чего они созданы: транзакций и структурированных записей. Если данные аккуратно укладываются в таблицы (клиенты, заказы, счета) и вы в основном извлекаете по ID, фильтрам и агрегатам, реляционные системы часто — самый простой и надёжный выбор.
Проблема JOIN — не в том, что JOIN плохи, а в глубине JOIN
JOIN подходят, когда они редки и неглубоки. Трение начинается, когда ключевые вопросы требуют много JOIN, постоянно, между множеством таблиц.
Примеры:
- «Какие клиенты покупали у продавцов, связанных с этим поставщиком через двух посредников?»
- «Найдите все устройства, которые делили сеть с устройствами, использованными близкими контактами этого аккаунта.»
В SQL это превращается в длинные запросы с самообъединениями и сложной логикой. Их сложнее оптимизировать при росте глубины связей.
Графы делают многошаговые «прогулки» первоклассной операцией
Графы явно хранят связи, поэтому многошаговые переходы по соединениям — естественная операция. Вместо сшивания таблиц во время запроса вы проходите по узлам и рёбрам.
Это часто даёт:
- Короче запросы для многошаговых паттернов (запрос читается как сам вопрос)
- Более предсказуемую сложность при изучении путей переменной глубины (например, 2–6 шагов)
Практическое правило
Если ваша команда часто задаёт многошаговые вопросы — «связан с», «через», «в той же сети», «в пределах N шагов» — стоит рассмотреть графовую БД.
Если же ваша основная нагрузка — высоконагруженные транзакции, строгие схемы, отчёты и простые JOIN, SQL обычно лучше по умолчанию. Многие реальные системы используют оба подхода; см. /blog/practical-architecture-graph-alongside-other-databases.
Когда графовая база — неверный инструмент
Моделируйте узлы и ребра
Используйте режим планирования, чтобы наметить узлы, ребра и запросы до написания реализации.
Графы хороши, когда связи — «главное шоу». Если ценность приложения не зависит от переходов между сущностями (кто‑знает‑кого, как связаны предметы, пути, соседства), граф добавит сложности без пользы.
Простые CRUD и однозаписные выборки
Если большинство запросов — «получить пользователя по ID», «обновить профиль», «создать заказ», и нужные данные в одной записи (или предсказуемом небольшом наборе таблиц), граф часто избыточен. Придётся тратить время на моделирование узлов/рёбер, настройку траверсалов и изучение нового стиля запросов — тогда как реляционная БД справится быстрее и с привычным набором инструментов.
Отчёты/BI, основанные на агрегатах
Дашборды с суммами, средними и сводными метриками (выручка по месяцам, заказы по регионам, конверсия по каналам) обычно лучше делать в SQL или колонковых аналитических системах. Графы могут отвечать на некоторые агрегатные вопросы, но редко это самый простой или быстрый путь для тяжёлых OLAP‑нагрузок.
Сильные транзакционные требования и «SQL‑родные» фичи
Если вы завязаны на зрелые SQL‑возможности — сложные JOIN с жёсткими ограничениями, продвинутые стратегии индексирования, хранимые процедуры или устоявшиеся ACID‑паттерны — реляционные СУБД часто естественней. Многие графовые системы поддерживают транзакции, но окружающая экосистема и эксплуатационные практики могут отличаться от того, к чему привыкла команда.
В основном независимые записи с минимальными связями
Если данные — набор независимых сущностей (тикеты, счета, показания датчиков) с минимумом перекрёстных ссылок, графовая модель будет выглядеть натянутой. В таких случаях сосредоточьтесь на чистой реляционной схеме (или документной модели) и рассматривайте граф позже, если вопросы о связях станут ключевыми.
Хорошее правило: если вы можете описать свои основные запросы без слов «связан», «путь», «соседство» или «рекомендация», граф, вероятно, не лучший первичный выбор.
Компромиссы, которые стоит знать перед выбором графа
Графы быстры при прохождении связей — но это имеет цену. Прежде чем принимать решение, полезно понять, где графы менее эффективны, дороже или просто иначе эксплуатируются.
Стоимость и объём ресурсов
Графовые БД часто хранят и индексируют связи так, чтобы делать «хопы» быстрыми. Цена — больший объём памяти и хранилища по сравнению с эквивалентной реляционной системой, особенно если вы добавляете индексы для частых запросов и держите данные связей всегда доступными.
Не каждый запрос станет быстрее
Если ваша нагрузка похожа на таблицу — большие сканирования, отчёты по миллионам записей или тяжёлые агрегаты — граф может быть медленнее или дороже для тех же результатов. Графы оптимизированы для траверсалов («кто с кем связан?»), а не для обработки больших независимых наборов записей.
Операционные отличия
Эксплуатация может заметно отличаться: бэкапы, масштабирование и мониторинг не такие, как у привычных реляционных систем. Некоторые граф‑платформы лучше масштабируются вертикально (большие машины), другие поддерживают горизонтальное масштабирование, но требуют тщательного планирования согласованности, репликации и паттернов запросов.
Навыки и инструменты
Команде потребуется время на изучение новых шаблонов моделирования и подходов к запросам (например, property graph и языки вроде Cypher). Кривая обучения управляемая, но это всё же затраты — особенно если вы заменяете зрелые SQL‑воркфлоу.
Практичный подход — использовать граф там, где связи — продукт, а существующие системы держать для отчётов, агрегации и табличной аналитики.
Основы моделирования данных: узлы, рёбра и схемы
Тестируйте пути рекомендаций
Разверните прототип рекомендаций и уточняйте сигналы и связи по мере изучения.
Полезно думать просто: узлы — это вещи, а рёбра — отношения между вещами. Люди, аккаунты, устройства, заказы, продукты, локации — узлы. «Купил», «вошёл с», «работает с», «родитель» — рёбра.
Property graph vs RDF
Большинство продуктовых графовых БД используют property graph: и узлы, и рёбра могут иметь свойства (поля ключ–значение). Например, ребро PURCHASED может хранить date, amount, channel. Это естественно для моделирования «связей с деталями».
RDF выражает знания как триплеты: subject – predicate – object. Это хорошо для совместимых словарей и связывания данных между системами, но часто переносит «детали связи» в дополнительные узлы/триплеты. Практически RDF склоняет к стандартным онтологиям и SPARQL‑паттернам, тогда как property graph ближе к прикладному моделированию данных.
Языки запросов простыми словами
- Cypher (популярен в property graph) читается как искомый паттерн: “(Customer)-[PURCHASED]-\u003e(Product).”
- Gremlin похож на пошаговый traversal: начни здесь, пройди по рёбрам, фильтруй, затем агрегируй.
- SPARQL — язык RDF‑мира, сопоставляющий паттерны графа с триплетами и часто используя общие словари.
Не нужно сразу запоминать синтаксис — важно, что граф‑запросы обычно выражаются как пути и паттерны, а не как стыковка таблиц.
Что значит «схема» в графовых системах
Графы часто гибки по схеме: можно добавить новый label узла или свойство без тяжёлой миграции. Но гибкость требует дисциплины: определяйте соглашения по именам, обязательные свойства (например, id) и правила для типов связей.
Типы связей, направленность и свойства
Выбирайте типы связей, которые объясняют смысл («FRIEND_OF» vs «CONNECTED»). Используйте направление, чтобы уточнить семантику (например, FOLLOWS от подписчика к создателю), и добавляйте свойства ребрам, когда связь имеет свои факты (время, доверие, роль, вес).
Как понять, что проблема зависит от связей
Проблема «зависит от связей», когда сложность не в хранении записей, а в понимании того, как вещи связаны и как смысл меняется в зависимости от пути.
Начинайте с вопросов, а не с таблиц
Запишите 5–10 ключевых вопросов простым языком — те, что постоянно задают заинтересованные стороны и которые ваша текущая система отвечает медленно или непоследовательно. Хорошие кандидаты на граф обычно содержат фразы «связан с», «через», «похож на», «в пределах N шагов» или «кто ещё».
Примеры:
- «Какие клиенты связаны с этой мошеннической группой через общие устройства и адреса?»
- «Какие товары часто покупают вместе с теми, что посмотрели пользователи X?»
- «Какие поставщики опосредованно пострадают, если этот завод остановится?»
Переведите вопрос в сущности и взаимодействия
После вопросов сопоставьте существительные и глаголы:
- Ключевые сущности станут узлами (Customer, Account, Device, Product, Supplier).
- Взаимодействия станут связями (PAID_WITH, LOGGED_IN_FROM, BOUGHT, SUPPLIES).
Решите, что должно быть связью, а что узлом. Практическое правило: если объект требует собственных атрибутов и будет связывать нескольких участников, сделайте его узлом (например, Order или событие Login).
Сделайте фильтрацию и ранжирование простыми
Добавляйте свойства, которые помогут сузить результаты и отсортировать по релевантности без дополнительных JOIN или пост‑обработки. Типичные полезные свойства: время, сумма, статус, канал, оценка уверенности.
Если большинство ключевых вопросов требует многошаговых связей плюс фильтрации по таким свойствам, у вас, вероятно, проблема, где графы будут уместны.
Практичная архитектура: граф рядом с другими БД
Большинство команд не заменяют всё графом. Практичнее оставить «систему записи» там, где она хорошо работает (часто SQL), и использовать граф как специализированный движок для вопросов по связности.
Держите источник правды в SQL (или в основном хранилище)
Используйте реляционную БД для транзакций, ограничений и канонических сущностей. Затем проецируйте вид связей в графовую БД — только узлы и рёбра, нужные для связанных запросов.
Это упрощает аудит и управление данными и одновременно открывает быстрые запросы по траверсалам.
Стройте граф для одной фичи, а не для всей компании
Граф особенно силён, когда прикреплён к чётко очерченной функции, например:
- Рекомендации («те, кто купил X, также купили Y»)
- Скоринг рисков (мошеннические группы, общие устройства, повторяющиеся платёжные инструменты)
- Разрешение идентичности (связь профилей из разных систем)
Начните с одной фичи, одной команды и одного измеримого результата. Расширяйтесь, если это даёт ценность.
Если узкое место — скорость прототипирования, а не спор о модели, платформа для ускоренного кодинга вроде Koder.ai может помочь быстро поднять простое приложение с поддержкой графа: опишите фичу в чате, сгенерируйте React UI и Go/PostgreSQL бэкенд и итеративно валидируйте схему и запросы.
Стратегии синхронизации: пакетно или близко к реальному времени
Насколько свежим должен быть граф?
- Пакетные обновления (каждый час/ночью) проще и часто достаточны для аналитики, discovery и многих рекомендательных движков.
- Почти в реальном времени (минуты/секунды) подходят для обнаружения мошенничества и оперативных решений.
Обычный паттерн: пишем транзакции в SQL → публикуем события об изменениях → обновляем граф.
Согласованные идентификаторы и явная ответственность
Графы портятся, когда ID рассинхронизируются.
Определите стабильные идентификаторы (например, customer_id, account_id), которые совпадают в разных системах, и документируйте, кто «владеет» каждым полем и связью. Если две системы могут создавать одно и то же ребро (например, «knows»), решите, кто имеет приоритет.
Если планируется пилот, см. /blog/getting-started-a-low-risk-pilot-plan для поэтапного подхода.
Начало: план низкорискованного пилота
Запустить пилот
Разместите пилот, чтобы заинтересованные лица могли выполнить реальные обходы и быстро оставить отзыв.
Пилот графа должен быть экспериментом, а не переписыванием всей архитектуры. Цель — доказать (или опровергнуть), что многошаговые запросы стали проще и быстрее — без крупных ставок на стек данных.
1) Выберите небольшой, ценный срез
Начните с узкого набора данных, который уже доставляет неудобства: слишком много JOIN, хрупкие SQL или медленные «кто с кем связан?» запросы. Ограничтесь одной рабочей областью (например: customer ↔ account ↔ device или user ↔ product ↔ interaction) и определите несколько ключевых запросов, которые хочется реализовать «от поля до результата».
2) Определите метрики успеха заранее
Измеряйте не только скорость:
- Сложность запроса: сколько строк, JOIN или промежуточных таблиц требуется сегодня против графа?
- Латентность: время ответа на реалистичных объёмах данных.
- Время разработчика: сколько времени занимает создание и изменение запросов при изменении требований?
Если вы не сможете назвать «до»‑числа, вы не поверите в «после».
3) Держите модель целенаправленной (избегайте граф‑сполза)
Соблазн смоделировать всё — велик. Сопротивляйтесь. Следите за «graph sprawl»: слишком много типов узлов/рёбер без ясного запроса, который они решают. Каждая новая метка или связь должна «заработать» своё место, решая реальную задачу.
4) Включите управление данными в пилот
Продумайте приватность, контроль доступа и хранение данных. Данные о связях могут раскрывать больше, чем отдельные записи (например, связи, которые намекают на поведение). Определите, кто может делать запросы, как аудитируются результаты и как удаляются данные по требованию.
5) Запустите параллельно с текущей БД
Используйте простую синхронизацию (пакетную или стримовую), чтобы питать граф, пока исходная система остаётся источником правды. Когда пилот докажет ценность, можно аккуратно расширять зону применения — шаг за шагом.
Быстрый чек‑лист решения: используйте граф для связей
При выборе БД начинайте не с технологии, а с вопросов. Графы полезны, когда ваши самые сложные задачи — про связи и пути, а не только про хранение записей.
Короткий тест «зависит ли задача от связей?»
Проверьте перед инвестициями:
- Глубина связей: вам часто нужно следовать связям 2+ шага (A→B→C→D)?
- Шаблоны запросов: ключевые вопросы про шаблоны (например, «люди, которые имеют общих работодателей и телефоны»), а не фильтры по одной таблице?
- Частота обновлений: связи часто меняются (новые, удалённые, смена ролей) и нужно ли это отражать быстро?
- Масштаб: достаточно ли данных, что объединение многих таблиц (или сбор в коде) становится медленным, дорогим или хрупким?
Если на большинство вопросов ответ «да», граф — сильный кандидат, особенно для многошагового шаблонного поиска вроде:
- «Найти кратчайший путь между двумя сущностями.»
- «Показать все аккаунты, связанные с этим устройством в пределах 3 шагов.»
- «Рекомендовать товары на основе общих соседей, а не только категорий.»
Когда оставаться на SQL/NoSQL
Если у вас в основном поиск по ID/email или агрегации («итоговые продажи по месяцам»), реляционная БД или key‑value/document хранилище обычно проще и дешевле.
Как снизить риск решения
Запишите топ‑10 бизнес‑вопросов простыми предложениями, затем протестируйте их на реальных данных в небольшом пилоте. Засеките время запросов, отметьте, что тяжело выразить, и ведите короткий журнал изменений модели. Если пилот в основном превращается в «больше JOIN» или «больше кэширования», это сигнал, что граф мало принесёт. Если же он даёт простые ответы на пути/шаблоны — граф может окупиться.