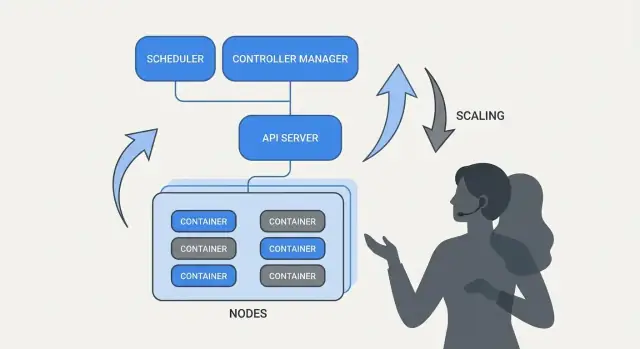
Почему Kubernetes изменил повседневную эксплуатацию
Kubernetes — это не просто новый инструмент: он изменил представление о том, как выглядят «повседневные операции», когда вы управляете десятками (или сотнями) сервисов. Раньше команды часто склеивали вместе скрипты, ручные runbook’и и племенные знания, чтобы отвечать на повторяющиеся вопросы: где должен работать этот сервис? как безопасно развернуть изменение? что происходит, если узел умирает в 2 утра?
Что на самом деле решает «оркестрация»
В своей основе оркестрация — это слой координации между вашим намерением («запустить этот сервис так») и грязной реальностью машин, которые падают, трафиком, который меняется, и непрерывными развёртываниями. Вместо того чтобы считать каждый сервер уникальным «снежинкой», оркестрация рассматривает вычисления как пул, а рабочие нагрузки — как единицы, которые можно планировать и перемещать.
Kubernetes популяризовал модель, где команды описывают, чего они хотят, а система постоянно работает, чтобы привести реальность в соответствие с этим описанием. Этот сдвиг важен, потому что он делает операционную деятельность менее героической и более повторяемой.
Три результата, которые команды почувствовали сразу
Kubernetes стандартизировал операционные результаты, которые нужны большинству команд сервисов:
- Развёртывание: единообразный способ декларировать, что должно работать, обновлять это и проверять здоровье.
- Масштабирование: практический путь от одного экземпляра к многим, без переработки сервиса или ручного provision’а машин.
- Операции сервисов: стабильные механизмы для того, чтобы сервисы находили друг друга, маршрутизировали трафик и продолжали работать по мере изменения экземпляров.
Примечание о масштабе и источниках
Эта статья фокусируется на идеях и шаблонах, связанных с Kubernetes (и лидерами вроде Brendan Burns), а не на личной биографии. Когда мы говорим «как всё началось» или «почему это было спроектировано именно так», эти утверждения должны опираться на публичные источники — доклады на конференциях, дизайн‑доки и официальную документацию — чтобы история оставалась проверяемой, а не мифом.
Brendan Burns в истории происхождения Kubernetes (вкратце)
Brendan Burns широко признан одним из трёх первоначальных сооснователей Kubernetes вместе с Joe Beda и Craig McLuckie. В ранней работе над Kubernetes в Google Burns помог сформировать как техническое направление, так и способ, которым проект объяснялся пользователям — особенно вокруг вопросов «как вы эксплуатируете ПО», а не только «как вы запускаете контейнеры». (Источники: Kubernetes: Up & Running, O’Reilly; список AUTHORS/maintainers в репозитории Kubernetes)
Открытое сотрудничество формировало дизайн
Kubernetes не был просто «выпущен» как завершённая внутренняя система; он строился публично с растущим числом контрибьюторов, кейсов использования и ограничений. Эта открытость подтолкнула проект к интерфейсам, которые могли выжить в разных средах:
- понятные, версионируемые API вместо скрытых деталей реализации
- переносимое поведение между облачными провайдерами и on‑prem
- точки расширения, чтобы ядро оставалось относительно малым, но поддерживало много потребностей
Это совместное давление важно, потому что оно влияло на то, для чего Kubernetes оптимизировали: общие примитивы и повторяемые паттерны, с которыми могли согласиться многие команды, даже если они расходились во мнениях о инструментах.
Что здесь означает «стандартизировал»
Когда говорят, что Kubernetes «стандартизировал» развертывание и эксплуатацию, обычно не имеют в виду, что он сделал все системы одинаковыми. Речь о том, что он дал общий словарь и набор рабочих процессов, которые можно повторять:
- общие термины: «Deployment», «Service», «Ingress», «Job», «Namespace»
- единая модель для декларации желаемого состояния и позволения системе работать в его направлении
- предсказуемые способы выкатывать изменения, масштабировать и восстанавливаться после сбоев
Эта общая модель упростила перенос документации, инструментов и практик между компаниями.
Проект Kubernetes vs. экосистема
Полезно отделять Kubernetes (открытый проект) от экосистемы Kubernetes.
Проект — это ядро API и компоненты control plane, которые реализуют платформу. Экосистема — это всё, что выросло вокруг: дистрибутивы, управляемые сервисы, адд‑оны и смежные проекты CNCF. Многие реальные «фичи Kubernetes», на которые опираются люди (стэки наблюдаемости, движки политики, GitOps‑инструменты), находятся в этой экосистеме, а не в самом ядре.
Основная идея: декларативное желаемое состояние
Декларативная конфигурация — простое изменение способа описания систем: вместо перечисления шагов вы заявляете, чего хотите в итоге.
В терминах Kubernetes вы не говорите «запусти контейнер, открой порт, перезапусти при падении». Вы декларируете: «должно быть три копии этого приложения, доступные на этом порту, использующие этот образ контейнера». Kubernetes берёт на себя ответственность привести реальность в соответствие с этим описанием.
Желаемое состояние vs императивные скрипты
Императивные операции похожи на runbook: последовательность команд, которая работала в прошлый раз, выполняется снова при изменении. Желаемое состояние ближе к контракту. Вы фиксируете ожидаемый результат в конфиге, и система непрерывно стремится к нему. Если происходит дрейф — процесс падает, узел исчезает или вносятся ручные изменения — платформа обнаруживает несоответствие и исправляет его.
До/после: команды в runbook vs YAML
Раньше (императивное мышление runbook):
- SSH на сервер
- забрать новый образ контейнера
- остановить старый процесс
- запустить новый процесс
- обновить правило балансировщика нагрузки
- при всплеске трафика повторить на других серверах
Это работает, но легко привести к «снежинкам» среди серверов и длинному чек‑листу, которому доверяют лишь несколько человек.
После (декларативное желаемое состояние):
apiVersion: apps/v1
kind: Deployment
metadata:
name: checkout
spec:
replicas: 3
selector:
matchLabels:
app: checkout
template:
metadata:
labels:
app: checkout
spec:
containers:
- name: app
image: example/checkout:1.2.3
ports:
- containerPort: 8080
Вы изменяете файл (например, обновляете image или replicas), применяете его, и контроллеры Kubernetes работают над тем, чтобы то, что запущено, соответствовало декларации.
Почему это снижает рутину и дрейф
Декларативное желаемое состояние снижает операционный труд, превращая «выполни эти 17 шагов» в «держи так». Оно также уменьшает конфигурационный дрейф, потому что источник правды явный и поддаётся ревью — часто в системе контроля версий — и сюрпризы легче заметить, проверить и последовательно откатить.
Контроллеры и реконсиляция: механизм поддержания правды
Kubernetes кажется «самоуправляемым», потому что он построен вокруг простого паттерна: вы описываете, чего хотите, а система постоянно работает, чтобы привести реальность в соответствие с этим описанием. Движком этого паттерна является контроллер.
Что такое контроллер (простыми словами)
Контроллер — это цикл, который смотрит на текущее состояние кластера и сравнивает его с желаемым состоянием, которое вы объявили в YAML (или через API). Когда он обнаруживает разницу, он предпринимает действия, чтобы её уменьшить.
Это не разовый скрипт и не ожидание клика человека. Он запускается постоянно — наблюдать, решить, действовать — поэтому может реагировать на изменения в любой момент.
Реконсиляция: как Kubernetes «поддерживает правду»
Эта повторяющаяся поведение «сравнивай‑и‑исправляй» называется реконсиляцией. Это механизм, лежащий в основе обещания «самовосстановления». Система не предотвращает сбои волшебным образом; она замечает дрейф и исправляет его.
Дрейф может происходить по простым причинам:
- процесс упал
- узел исчез
- кто‑то масштабировал что‑то вручную
- обновление развёртывания
Реконсиляция означает, что Kubernetes воспринимает эти события как сигналы пересмотреть намерение и восстановить его.
Результаты, которые действительно важны для людей
Контроллеры дают знакомые операционные результаты:
- замена упавших Pod’ов: если Pod умирает, контроллер видит, что вы всё ещё хотите его и планирует новый
- поддержание числа реплик: если вы запросили 5 реплик, а работает 4, Kubernetes создаст недостающую
- контроль прогресса развёртывания: во время обновлений контроллеры двигают систему к новой версии, сохраняя требуемую доступность
Ключ в том, что вы не гоняетесь вручную за симптомами. Вы задаёте цель, а управляющие петли выполняют непрерывную работу по её поддержанию.
Почему это масштабируется за пределы одной фичи
Этот подход не ограничен одним типом ресурса. Kubernetes использует ту же идею контроллера и реконсиляции для многих объектов — Deployment, ReplicaSet, Job, Node, Endpoints и т.д. Эта последовательность значительно облегчила превращение Kubernetes в платформу: поняв шаблон, вы можете предсказать поведение системы при добавлении новых возможностей (включая собственные ресурсы, следующие тому же циклу).
Планирование как продуктовая фича, а не ручная задача
Владейте кодовой базой
Забирайте исходники и применяйте ваши Kubernetes‑паттерны в собственном пайплайне.
Если бы Kubernetes только «запускал контейнеры», командам всё равно пришлось бы решать самое сложное: где запускать нагрузку. Планировщик — это встроенная система, которая автоматически размещает Pod’ы на подходящих узлах, исходя из требований ресурсов и правил, которые вы определяете.
Это важно, потому что решения о размещении напрямую влияют на доступность и стоимость. Веб‑API, застрявший на перегруженном узле, может замедлиться или упасть. Batch‑задача, помещённая рядом с latency‑чувствительными сервисами, может создать эффект «шумного соседа». Kubernetes превращает это в повторяемую продуктовую возможность вместо рутины в spreadsheet + SSH.
Что оптимизирует планировщик
В базовом виде планировщик ищет узлы, которые удовлетворяют запросы вашего Pod’а.
- Запросы CPU/памяти: запрос резервирует ёмкость для решения о размещении. Если вы просите 500m CPU и 1Gi памяти, Kubernetes будет рассматривать только узлы с достаточной доступной ёмкостью.
Эта одна привычка — задавать реалистичные requests — часто снижает «рандомную» нестабильность, потому что критические сервисы перестают конкурировать со всем остальным.
Распространённые ограничения, которые команды используют на практике
Кроме ресурсов, большинство продакшен‑кластеров опираются на несколько практичных правил:
- Affinity / anti‑affinity: «размещать вместе» (для локальности кеша) или «держать раздельно» (чтобы один отказ узла не вывел все реплики).
- Taints и tolerations: пометить узлы как специальные (GPU, системные, соответствия) и разрешить попадать на них только утверждённым нагрузкам.
Как это уменьшает простои
Фичи планирования помогают командам зафиксировать операционные намерения:
- распределять реплики по узлам, чтобы пережить отказ узла
- изолировать «всплесковые» задачи от клиентских сервисов
- не допускать потребления дорогих узлов (GPU) не теми нагрузками
Практический вывод: относитесь к правилам планирования как к требованиям продукта — задокументируйте их, ревьюйте и применяйте последовательно — чтобы надёжность не зависела от того, кто «помнит правильный узел в 2 утра».
Масштабирование: от одного экземпляра до тысяч без переписывания кода
Одна из самых практичных идей Kubernetes — масштабирование не должно требовать изменения кода приложения или изобретения нового подхода развертывания. Если приложение может работать как один контейнер, то с той же дефиниции нагрузки обычно можно вырасти до сотен или тысяч копий.
Масштабирование имеет два уровня
Kubernetes разделяет масштабирование на два связанных решения:
- Сколько Pod’ов запустить (больше копий приложения для большей пропускной способности или отказоустойчивости).
- Сколько у вас ёмкости в кластере (достаточно ли узлов и подходящего размера, чтобы разместить эти Pod’ы).
Это разделение важно: вы можете запросить 200 Pod’ов, но если в кластере места только для 50, «масштабирование» превратится в очередь Pending.
Концептуально об автомасштабировании (HPA, VPA, Cluster Autoscaler)
В Kubernetes обычно используют три автомасшкалера, каждый действует на своём рычаге:
- Horizontal Pod Autoscaler (HPA): меняет число Pod’ов по сигналам вроде CPU, памяти или кастомных метрик приложения.
- Vertical Pod Autoscaler (VPA): корректирует requests/limits Pod’а, чтобы каждому Pod’у досталось больше или меньше CPU/памяти.
- Cluster Autoscaler: добавляет или удаляет узлы, чтобы у планировщика было достаточно места для Pod’ов, которые вы запросили.
Используемые вместе, эти механизмы превращают масштабирование в политику: «держать латентность в пределах» или «поддерживать CPU около X%», а не в ручную тревогу по вызову.
От чего зависит «хорошее» масштабирование
Масштабирование работает только при корректных входных данных:
- Метрики: CPU просто получить, но он не всегда релевантен; частота запросов, глубина очереди и латентность часто лучше отражают реальную нагрузку.
- Requests/limits: они говорят планировщику, что нужно Pod’у. Без них размещение и предсказание работы автомасшкалеров превращаются в гадание.
- Паттерны нагрузки: всплески, медленный прогрев и тяжёлые фоновые задачи меняют скорость реакции масштабирования.
Частые подводные камни
Две ошибки встречаются часто: масштабирование по неверной метрике (CPU низкий, а запросы таймаутятся) и отсутствие requests (автомасшкалы не могут предсказать ёмкость, Pod’ы набиваются на узлы и производительность нестабильна).
Безопасные развёртывания: rollouts, проверки здоровья и откаты
Большой сдвиг, который популяризовал Kubernetes — рассматривать «развёртывание» как управляемую задачу, а не как одноразовый скрипт, запускаемый в пятницу в 17:00. Rollout’ы и откаты — первоклассные поведения: вы декларируете желаемую версию, и Kubernetes ведёт систему к ней, постоянно проверяя, безопасно ли изменение.
Rollout как контролируемый переход
С Deployment’ом rollout — это постепенная замена старых Pod’ов на новые. Вместо остановки всего и перезапуска Kubernetes обновляет по шагам — поддерживая доступность, пока новая версия доказывает свою работоспособность.
Если новая версия начинает падать, откат — это не аварийная процедура. Это нормальная операция: вы можете вернуться к предыдущему ReplicaSet (последней известной рабочей версии) и позволить контроллеру восстановить старое состояние.
Пробы: предотвращение «плохо, но запущено» релизов
Проверки здоровья превращают rollout’ы из «надеюсь, что всё ок» в измеримые процессы.
- Readiness probes определяют, должен ли Pod получать трафик. Контейнер может быть запущен, но ещё не готов (прогревается кеш, ждёт зависимостей). Readiness предотвращает отправку трафика на экземпляры, которые ещё не могут корректно отвечать.
- Liveness probes обнаруживают зависший или некорректный контейнер и перезапускают его. Это избегает медленного режима отказа, когда процесс жив, но не работает.
Использованные грамотно, пробы снижают ложные успехи — когда развёртывание «выглядит» успешным, потому что Pod стартовал, но на самом деле отказывает в обработке запросов.
Стратегии развёртывания: rolling, blue/green, canary
Kubernetes поддерживает rolling update «из коробки», но команды часто накладывают дополнительные паттерны:
- Blue/green: две полные среды; переключение трафика со старой (blue) на новую (green) после верификации.
- Canary: направить небольшой процент трафика на новую версию, наблюдать метрики и затем расширять.
Измеримая (и автоматизируемая) безопасность
Безопасные развёртывания зависят от сигналов: уровень ошибок, латентность, насыщение и влияние на пользователей. Многие команды связывают решения по продвижению релиза с SLO и error budget — если канарейка «сжигает» слишком много бюджета, продвижение останавливается.
Цель — автоматические триггеры отката на основе реальных индикаторов (провал readiness, рост 5xx, всплески латентности), чтобы «откат» стал предсказуемым ответом системы, а не ночной героической операцией.
Операции сервисов: обнаружение, маршрутизация и стабильная сеть
Шаблон приложения за минуты
Опишите сервис в чате — сгенерируйте основу на React, Go и PostgreSQL.
Платформа для контейнеров кажется «автоматической» только если остальные части системы тоже могут найти ваш сервис после его перемещений. В продакшен‑кластерах Pod’ы постоянно создаются, удаляются, реседьюлятся и масштабируются. Если каждое изменение требовало бы правки IP‑адресов в конфигурациях, эксплуатация превратилась бы в постоянную рутину, а простои стали бы обычным делом.
Почему важно обнаружение сервисов
Обнаружение сервисов — это практика предоставления клиентам надёжного способа добраться до меняющегося набора бэкендов. В Kubernetes ключевая идея — вы перестаёте целиться в отдельные экземпляры («позвоните 10.2.3.4») и начинаете целиться в именованный сервис («вызовите checkout»). Платформа сама управляет тем, какие Pod’ы сейчас обслуживают это имя.
Services, selectors и endpoints (простыми словами)
Service — это стабильная фронт‑дверь для группы Pod’ов. У него есть постоянное имя и виртуальный адрес внутри кластера, даже когда подлежащие Pod’ы меняются.
Selector решает, какие Pod’ы находятся «за» этой дверью. Обычно это соответствие меткам, например app=checkout.
Endpoints (или EndpointSlices) — живой список фактических IP Pod’ов, которые сейчас соответствуют селектору. Когда Pod’ы масштабируются, откатываются или пересаживаются, этот список обновляется автоматически — клиенты продолжают обращаться к одному и тому же Service‑имени.
Стабильные адреса, балансировка и маршрутизация трафика
Операционно это даёт:
- Стабильные адреса: приложения обращаются к DNS‑имени Сервиса вместо того, чтобы гоняться за IP Pod’ов.
- Балансировку нагрузки: трафик распределяется по здоровым Pod’ам за Service.
- Предсказуемую маршрутизацию: вы отделяете «кто должен получать трафик» (labels/selectors) от «где сейчас запущены Pod’ы».
Для north–south трафика (из вне кластера) Kubernetes обычно использует Ingress или более новый подход Gateway. Оба дают контролируемую точку входа с маршрутизацией по хосту или пути и часто централизуют такие вещи, как TLS‑терминация. Идея та же: держать внешний доступ стабильным, пока бекэнды меняются под капотом.
Самовосстановление: что это реально значит в продакшене
«Самовосстановление» в Kubernetes не магия. Это набор автоматических реакций на сбой: перезапуск, пересадка и замена. Платформа следит за тем, что вы заявили (желаемое состояние), и постоянно подталкивает реальность обратно к нему.
Перезапуск: когда контейнер падает
Если процесс выходит или контейнер становится нездоровым, Kubernetes может перезапустить его на том же узле. Обычно это управляется:
- Liveness probes: «функционирует ли контейнер?» Если нет — перезапустить.
- Политиками перезапуска: правила, когда следует перезапускать.
Обычная схемаг: контейнер упал → Kubernetes перезапустил его → Service маршрутизирует только к здоровым Pod’ам.
Пересадка и замена: когда узел умирает
Если весь узел умирает (аппаратный сбой, kernel panic, потеря сети), Kubernetes помечает узел как Unavailable и начинает переносить работу в другое место:
- узел помечается как Unready/нездоровый
- Pod’ы, что были на нём, считаются потерянными
- контроллеры создают заменяющие Pod’ы на других здоровых узлах, чтобы восстановить желаемое число реплик
Это «самовосстановление» на уровне кластера: система восстанавливает ёмкость вместо ожидания человека с SSH.
Наблюдаемость: как понять, что всё лечится
Самовосстановление имеет смысл, если вы можете это проверить. Команды обычно смотрят:
- логи (логи приложения и события платформы), чтобы увидеть, что перезапустилось и почему
- метрики: счётчики перезапусков, провалы проб, состояние узлов
- алерты: когда лечение не срабатывает (CrashLoopBackOff, нехватка реплик, много эвикций)
Некорректные настройки, разрушающие самовосстановление
Даже с Kubernetes «лечилка» может не сработать, если неправильно настроены защитные ограждения:
- плохие или отсутствующие liveness/readiness probes (ложные срабатывания или Pod никогда не становится Ready)
- отсутствие requests/limits, что ведёт к непредсказуемому планированию или OOM‑убийствам
- слишком мало реплик (один Pod не даёт непрерывности)
- чрезмерно агрессивные тайминги проб, вызывающие рестарт‑штормы
- нагрузки, полагающиеся на локальное состояние узла без стратегии долговременного хранения
При корректной настройке самовосстановление сокращает время и масштаб простоя — и, что важнее, делает их измеримыми.
Стандартные API и расширяемость: как Kubernetes стал платформой
Выберите подходящий план
Перейдите от индивидуального прототипа к командной работе с тарифом, который вам подходит.
Kubernetes выиграл не только потому, что запускал контейнеры. Он выиграл потому, что предложил стандартные API для наиболее распространённых операционных задач — развёртывание, масштабирование, сеть и наблюдаемость. Когда команды соглашаются на одинаковую «форму» объектов (Deployment, Service, Job), инструменты можно переиспользовать по организациям, обучение проще, а передача ответственности между девами и опсами перестаёт быть ремесленным знанием.
Почему стандартные API меняют рабочие процессы команд
Единый API значит: пайплайн развёртывания не должен знать причуды каждого приложения. Он может выполнять одинаковые действия — create, update, rollback, check health — через одни и те же концепции Kubernetes.
Это также улучшает выравнивание: команды безопасности могут задавать guardrails как политики; SRE могут стандартизировать runbook’ы вокруг общих сигналов здоровья; разработчики получают общий язык для обсуждения релизов.
Расширение Kubernetes: CRD и Operators
Сдвиг в платформенность становится очевиден с Custom Resource Definitions (CRD). CRD позволяют добавить новый тип объекта в кластер (например, Database, Cache, Queue) и управлять им через те же API‑паттерны, что и встроенными ресурсами.
Operator сочетает эти кастомные объекты с контроллером, который постоянно реконсилирует реальность с желаемым состоянием — автоматизируя задачи, которые раньше выполнялись вручную: бэкапы, failover, апгрейды. Главное преимущество не в «волшебной автоматизации», а в повторном использовании того же control loop‑подхода, который Kubernetes применяет ко всему остальному.
Встраивание в GitOps, CI/CD и проверки политик
Поскольку Kubernetes управляется через API, он органично интегрируется с современными workflow’ами:
- GitOps: желаемое состояние живёт в Git; изменения ревьюятся как код.
- CI/CD: пайплайны применяют манифесты, ждут Ready и продвигают версии.
- Проверки политик: admission‑контроллеры могут блокировать рискованные конфигурации до попадания в прод.
Если хотите больше практических гайдов по развёртыванию и опс‑процедурам, основанных на этих идеях, смотрите /blog.
Что команды могут применить уже сегодня (даже вне Kubernetes)
Главные идеи Kubernetes — многие из которых связаны с ранним видением Brendan Burns — хорошо переносятся, даже если вы запускаете VMs, serverless или более простую контейнерную среду.
Паттерны, улучшающие повседневные операции
Задокументируйте «желаемое состояние» и дайте автоматизации поддерживать его. Будь то Terraform, Ansible или CI‑пайплайн, обращайтесь с конфигурацией как с источником правды. Результат — меньше ручных шагов и меньше «работало у меня на машине» сюрпризов.
Используйте реконсиляцию, а не одноразовые скрипты. Вместо скриптов, которые выполняются один раз и надеются на лучшее, стройте петли, которые постоянно проверяют ключевые свойства (версия, конфиг, число инстансов, здоровье). Так вы получаете повторяемые опсы и предсказуемое восстановление.
Сделайте планирование и масштабирование явными фичами продукта. Определите, когда и почему вы добавляете ёмкость (CPU, глубина очереди, SLO по латентности). Даже без Kubernetes автомасштабирования команды могут стандартизировать правила масштабирования, чтобы рост не требовал переписывания приложения или ночных вызовов.
Стандартизируйте rollouts. Поэтапные обновления, проверки здоровья и быстрые откаты снижают риск изменений. Это можно реализовать с помощью балансировщиков, feature‑флагов и пайплайнов, которые ставят gates на основе реальных сигналов.
Чек‑лист для безопасного принятия подхода
- Опишите желаемое состояние сервиса: версия, конфиг, зависимости и минимальное число инстансов
- Добавьте health‑эндпоинты (аналогичные liveness и readiness) и интегрируйте их с балансировщиком или пайплайном развёртывания
- Автоматизируйте шаги релиза: deploy, verify, shift traffic, rollback on failure
- Сделайте небольшой «реконсайлер»: периодические проверки, исправляющие дрейф (неправильный конфиг, недостающие инстансы)
- Добавьте триггеры масштабирования с понятными лимитами (max instances, cooldown, правила одобрения)
Что это само по себе не решит
Эти паттерны не исправят плохой дизайн приложения, опасные миграции данных или управление затратами. Всё ещё нужны версионированные API, планы миграции, бюджетирование/лимиты и наблюдаемость, связывающая деплои с влиянием на клиентов.
Следующие шаги
Выберите один customer‑facing сервис и реализуйте чек‑лист end‑to‑end, затем расширяйте.
Если вы хотите быстрее получить «что‑то развертываемое», Koder.ai может помочь сгенерировать полный веб/бэкенд/мобильный проект из чат‑спецификации — обычно React на фронтенде, Go с PostgreSQL на бэкенде и Flutter для мобильных — а затем экспортировать исходники, чтобы вы могли применить те же Kubernetes‑паттерны, обсуждённые здесь (декларативные конфиги, повторяемые rollout’ы и безопасные откаты). Для анализа затрат и управления смотрите /pricing.