10 нояб. 2025 г.·8 мин
Изменения схемы и миграции в системах, созданных ИИ: руководство
Узнайте, как безопасно управлять изменениями схем в системах, созданных ИИ: версионирование, обратная совместимость, миграции данных, тестирование, наблюдаемость и стратегии отката.
Что означает «схема» в системах, созданных ИИ
«Схема» — это просто общее соглашение о формате данных и значении каждого поля. В системах, созданных с участием ИИ, такое соглашение проявляется не только в таблицах базы данных — и менять его приходится чаще, чем команды ожидают.
Схема — это не только база данных
Схемы встречаются как минимум на четырёх уровнях:
- Базы данных: имена таблиц/столбцов, типы данных, ограничения, индексы и связи.
- API: структура JSON запросов/ответов, обязательные и опциональные поля, перечисления, форматы ошибок, соглашения пагинации.
- События и сообщения: полезные нагрузки в потоках, очередях и вебхуках (часто неявно версионируются через потребителей).
- Конфигурации и контракты: feature-флаги, переменные окружения, YAML/JSON-конфиги и «скрытые контракты» вроде форматов файлов и соглашений по именованию.
Если две части системы обмениваются данными — там есть схема, даже если никто её не задокументировал.
Почему в системах с ИИ схема меняется чаще
Код, сгенерированный ИИ, сильно ускоряет разработку, но и увеличивает текучесть:
- Сгенерированный код отражает текущий prompt и контекст, поэтому мелкие правки promptа могут поменять имена полей, вложенность, значения по умолчанию или валидации.
- Требования эволюционируют быстрее, когда дешёво внедрять новый endpoint или шаг пайплайна.
- Несогласованные конвенции (snake_case vs. camelCase,
idvs.userId) появляются, когда генерации и рефакторы выполняются разными процессами или командами.
В результате чаще возникает «дрейф контрактов» между продьюсерами и консюмерами.
Если вы используете рабочий процесс vibe-кодинга (например, генерация хэндлеров, слоёв доступа к БД и интеграций через чат), стоит заложить дисциплину по работе со схемами с самого начала. Платформы вроде Koder.ai помогают командам быстро генерировать React/Go/PostgreSQL и Flutter-приложения из чата — но чем быстрее вы шипите, тем важнее версионировать интерфейсы, валидировать полезные нагрузки и аккуратно выкатывать изменения.
Цель этого руководства
В этой статье — практические способы сохранять продакшн в стабильном состоянии, продолжая быстро итерации: поддерживать обратную совместимость, безопасно выкатывать изменения и проводить миграции данных без сюрпризов.
Что здесь не рассматривается
Мы не будем углубляться в теорию моделирования, формальные методы или фичи конкретных вендоров. Упор на паттерны, применимые в разных стеках — будь ваша система ручной разработки, с поддержкой ИИ или в основном сгенерированная ИИ.
Почему изменения схем встречаются чаще при генерации кода ИИ
Код, сгенерированный ИИ, делает изменения схемы «нормой» — не потому что команды неаккуратны, а потому что входные данные в систему меняются чаще. Когда поведение приложения частично определяется promptами, версиями моделей и сгенерированным glue-кодом, форма данных имеет больше шансов дрейфовать со временем.
Частые триггеры реальных изменений
Некоторые паттерны регулярно вызывают текучесть схем:
- Новые продуктовые фичи: добавление поля (например,
risk_score,explanation,source_url) или разделение одного понятия на несколько (например,address→street,city,postal_code). - Изменения вывода модели: новая модель может выдавать более детализированные структуры, другие значения перечислений или немного отличающиеся имена ("confidence" vs. "score").
- Обновления promptа: правки promptа, направленные на улучшение качества, могут непреднамеренно изменить форматирование, обязательность полей или вложенность.
Рисковые паттерны, делающие системы с ИИ хрупкими
Код, сгенерированный ИИ, часто «работает» быстро, но может закодировать хрупкие допущения:
- Неявные допущения: код тихо предполагает, что поле всегда присутствует, всегда числовое или всегда в заданном диапазоне.
- Скрытая связность: один сервис полагается на внутренние имена полей или порядок другого сервиса вместо явно определённого интерфейса.
- Недокументированные поля: модель начинает выдавать новое свойство, и downstream-код начинает на него опираться без явного согласования контракта.
Почему ИИ усиливает частоту изменений
Генерация кода поощряет быструю итерацию: вы регенерируете хэндлеры, парсеры и слои доступа к БД по мере эволюции требований. Эта скорость полезна, но и упрощает многократную отправку мелких изменений интерфейса — иногда незаметно.
Более безопасный подход — считать каждую схему контрактом: таблицы базы, API-пэйлоуды, события и даже структурированные ответы LLM. Если на это полагается потребитель — версионируйте, валидируйте и меняйте сознательно.
Типы изменений схем: добавочные vs. ломающие
Изменения схемы разные. Самый полезный первый вопрос: будут ли существующие потребители работать без изменений? Если да — обычно это добавочное изменение. Если нет — это ломающая смена, требующая скоординированного плана выката.
Добавочные изменения (обычно безопасны)
Добавочные изменения расширяют существующее не меняя его смысла.
Примеры для БД:
- Добавить столбец с дефолтом или разрешить NULL (например,
preferred_language). - Добавить новую таблицу или индекс.
- Добавить опциональное поле в JSON-blob, хранимый в столбце.
Небазовые примеры:
- Добавить новое свойство в ответ API (клиенты, игнорирующие неизвестные поля, будут работать).
- Добавить новое поле в событие в потоке/очереди.
- Добавить новое значение флага фичи, сохранив старое поведение по умолчанию.
Добавочное безопасно только если старые потребители терпимы: они должны игнорировать неизвестные поля и не требовать новых.
Ломающие изменения (рискованные)
Ломающие изменения меняют или удаляют то, от чего уже зависят потребители.
Типичные БД-примеры:
- Изменить тип столбца (string → integer, изменение точности таймштампа).
- Переименовать поле/столбец (всё, что читает старое имя — сломается).
- Удалить столбец/таблицу, которая ещё запрашивается.
Небазовые ломающие изменения:
- Переименовать/удалить JSON-поля в запросах/ответах.
- Изменить семантику поля в событии (то же имя — другое значение).
- Изменить структуру вебхука без bump-версии.
Всегда записывайте влияние на потребителей
Перед мерджем задокументируйте:
- Кто потребляет (сервисы, дашборды, data pipelines, партнёры).
- Совместимость (обратная/прямая, на какой срок).
- Режим отказа (ошибки парсинга, тихая порча данных, неверная бизнес-логика).
Эта короткая «записка о влиянии» заставляет прояснить намерения — особенно когда ИИ-сгенерированный код неявно вводит изменения в схему.
Стратегии версионирования для схем и интерфейсов
Версионирование сообщает другим системам (и будущему вам): «это изменилось, и вот насколько это рискованно». Цель не в бумажке — а в предотвращении тихих поломок, когда клиенты, сервисы или пайплайны обновляются с разной скоростью.
Мысленный подход семантического версионирования
Думайте в терминах major / minor / patch, даже если вы не публикуете 1.2.3:
- Major: ломающие изменения. Старые потребители могут падать или работать неправильно без изменений.
- Minor: безопасное расширение. Старые потребители работают, новые используют новые возможности.
- Patch: багфикс или уточнение, не меняющее смысла.
Простое правило, которое спасает команды: никогда не меняйте смысл существующего поля незаметно. Если status="active" раньше означал «платящий клиент», не переопределяйте его как «учётная запись существует». Добавьте новое поле или новую версию.
Версионированные эндпоинты vs. версионированные поля
Есть две практичные опции:
- Версионированные эндпоинты (например,
/api/v1/ordersи/api/v2/orders):
Хорошо, когда изменения ломающие или широкомасштабные. Явно, но может привести к дублированию и долгому поддержанию нескольких версий.
- Версионирование на уровне полей / добавочная эволюция (например, добавить
new_field, оставитьold_field):
Хорошо, когда можно вносить изменения добавочно. Старые клиенты игнорируют непонятные поля; новые читают новое поле. Со временем депрекейтьте и удалите старое поле с явным планом.
Схемы для событий и реестры
Для стримов, очередей и вебхуков потребители часто вне вашего контроля. Реестр схем (или централизованный каталог схем с проверками совместимости) помогает применять правила типа «разрешены только добавочные изменения» и показывает, какие продьюсеры и потребители завязаны на какие версии.
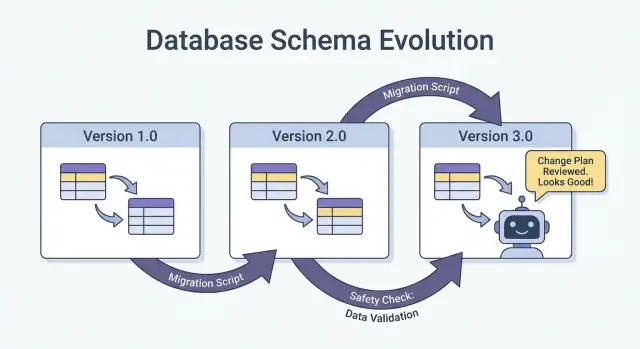
Безопасные выкаты: Expand/Contract (самый надёжный паттерн)
Самый безопасный способ внедрить изменения схемы — особенно когда у вас много сервисов, джобов и ИИ-сгенерированных компонентов — это паттерн expand → backfill → switch → contract. Он минимизирует даунтайм и избегает «всё или ничего» развертываний, когда отстающий потребитель ломает продакшн.
Четыре шага (и почему они работают)
1) Expand: Введите новую схему обратносовместимым способом. Существующие читатели и писатели должны продолжать работать без изменений.
2) Backfill: Заполните новые поля для исторических данных (или переработайте сообщения), чтобы система стала консистентной.
3) Switch: Обновите писателей и читателей на использование нового поля/формата. Можно делать постепенно (canary, процентный rollout), потому что схема поддерживает оба формата.
4) Contract: Удалите старое поле/формат только после того, как убедитесь, что никто на него не опирается.
Двухфазный (expand → switch) и трёхфазный (expand → backfill → switch) rollouts уменьшают даунтайм, так как избегают жёсткой связки: писатели могут поменяться первыми, читатели позже, и наоборот.
Пример: добавить столбец, сделать backfill, затем сделать обязательным
Предположим, вы хотите добавить customer_tier.
- Expand: Добавьте
customer_tierкак nullable с дефолтомNULL. - Backfill: Запустите джоб, который рассчитает tier для существующих строк.
- Switch: Обновите приложение и пайплайны, чтобы всегда писать
customer_tier, и обновите ридеры, чтобы предпочитать его. - Contract: После мониторинга сделайте поле NOT NULL (и опционально удалите legacy-логику).
Координация: писатели и читатели должны согласовываться
Рассматривайте каждую схему как контракт между продьюсерами (writers) и консюмерами (readers). В системах с ИИ это легко пропустить, потому что быстро появляются новые код-пути. Делайте выкаты явными: документируйте, какая версия что пишет, какие сервисы могут читать оба формата и точную «дату контракта», когда старые поля можно удалить.
Миграции базы данных: как менять данные без поломки продакшна
Внедряйте изменения безопасно
Разверните и хостьте приложение, когда читатели и писатели согласованы с новой схемой.
Миграции БД — это «инструкция», как аккуратно перевести продакшн-структуру и данные в новое состояние. В системах с ИИ они особенно важны: сгенерированный код может ошибочно предполагать существование столбца, переименовать поля по-разному или поменять ограничения без учёта существующих строк.
Файлы миграций vs. авто-миграции
Файлы миграций (в source control) — явные шаги вроде «add column X», «create index Y», «copy data from A to B». Они ревьюируемы, аудируемы и можно воспроизвести в staging/prod.
Авто-миграции (сгенерированные ORM/фреймворком) удобны на ранних стадиях и прототипах, но могут породить рискованные операции (удаление колонок, перестроение таблиц) или изменить порядок шагов не так, как вы ожидали.
Практическое правило: используйте авто-миграции для драфта, затем переводите их в проверяемые migration-файлы для всего, что касается продакшна.
Идемпотентность и порядок
Сделайте миграции идемпотентными, где возможно: повторный запуск не должен портить данные или приводить к частичному выполнению. Предпочитайте «create if not exists», добавляйте новые столбцы сначала как nullable и защищайте трансформации проверками.
Также поддерживайте чёткий порядок. Везде — локально, CI, staging, prod — должна применяться одна и та же последовательность миграций. Не «чините» продакшн ручным SQL без фиксации этого шага в миграции.
Долгие миграции без блокировок таблицы
Некоторые изменения схемы могут блокировать записи (или чтение) при больших таблицах. Высокоуровневые способы снизить риск:
- Используйте онлайн/минимизирующие блокировки операции, поддерживаемые вашей СУБД (например, concurrent index builds).
- Разбейте изменения на шаги: сначала добавьте новые структуры, затем делайте backfill по партиям, потом переключайтесь в приложении.
- Планируйте тяжёлые операции в окна низкой нагрузки, с таймаутами и мониторингом.
Мульти-тенант и шарды
Для мульти-тенантных баз выполняйте миграции контролируемым циклом по каждому тенанту, с трекингом прогресса и безопасными повторными попытками. Для шардов относитесь к каждому шару как отдельному продакшну: выкатывайте миграции по шардам, проверяйте здоровье, затем продолжайте. Это ограничивает blast radius и делает откат выполнимым.
Backfills и повторная обработка: обновление существующих данных
Backfill — заполнение добавленных полей для существующих записей. Reprocessing — пропуск исторических данных через пайплайн снова (обычно из-за изменения бизнес-логики, фикса бага или обновления формата модели/вывода).
Оба процесса часты после изменений схем: просто начать писать новую форму для «новых данных» — недостаточно, потому что продакшн часто зависит от консистентности исторических данных.
Распространённые подходы
Online backfill (в продакшне, постепенно). Контролируемый джоб обновляет записи малыми батчами, система остаётся живой. Безопаснее для критичных сервисов: можно управлять нагрузкой, ставить на паузу и возобновлять.
Batch backfill (оффлайн или по расписанию). Обрабатывает большие куски в окна низкой нагрузки. Проще операционно, но может создать пики нагрузки и сложнее откатывать ошибки.
Lazy backfill при чтении. При чтении старой записи приложение вычисляет/заполняет отсутствующие поля и записывает обратно. Это распределяет стоимость с течением времени и избегает большого джоба, но делает первое чтение медленнее и может оставить часть данных не конвертированной долгое время.
На практике команды комбинируют подходы: lazy backfill для хвостовых записей и online job для наиболее часто запрашиваемых данных.
Как валидировать backfill
Валидация должна быть явной и измеримой:
- Счётчики: сколько строк/событий должно быть обновлено vs сколько обновлено.
- Контрольные суммы/агрегаты: сравнение сумм (например, сумма amounts, distinct IDs) до/после.
- Сэмплинг: выборочная проверка статистически значимой выборки, включая крайние кейсы.
Также валидируйте downstream-эффекты: дашборды, поисковые индексы, кеши и экспорты, зависящие от обновлённых полей.
Стоимость, время и критерии приёмки
Backfills жертвуют скоростью (закончить быстро) ради риска и стоимости (нагрузка, вычисления, операционные затраты). Задайте критерии приёмки заранее: что означает «готово», ожидаемое время выполнения, максимально допустимый процент ошибок и план действий при провале валидации (пауза, повтор, откат).
Эволюция схем событий и сообщений (стримы, очереди, вебхуки)
Создавайте и получайте вознаграждения
Делитесь тем, что вы создали, с Koder.ai или приглашайте коллег и зарабатывайте кредиты.
Схемы живут не только в БД. Где бы одна система ни отправляла данные другой — Kafka-топики, SQS/RabbitMQ, вебхуки, даже «события», записанные в object storage — там контракт. Продьюсеры и консюмеры обновляются независимо, поэтому эти контракты чаще ломаются, чем внутренняя таблица приложения.
Самый безопасный дефолт: эволюция событий назад-совместимым образом
Для event streams и вебхуков предпочитайте изменения, которые старые консюмеры могут игнорировать, а новые — принять.
Практическое правило: добавляйте поля, не удаляйте и не переименовывайте. Если нужно задепрекейтить — продолжайте отправлять старое поле некоторое время и задокументируйте депрекацию.
Пример: расширить OrderCreated событие, добавив опциональные поля.
{
"event_type": "OrderCreated",
"order_id": "o_123",
"created_at": "2025-12-01T10:00:00Z",
"currency": "USD",
"discount_code": "WELCOME10"
}
Старые консюмеры читают order_id и created_at, игнорируя остальное.
Контракты, управляемые потребителем (простыми словами)
Вместо того, чтобы продьюсер гадал, что может сломать других, потребители публикуют, от чего они зависят (поля, типы, обязательность/опциональность). Продьюсер затем валидирует изменения относительно этих ожиданий перед выпуском. Это особенно полезно в кодовой базе, сгенерированной ИИ, где модель может «полезно» переименовать поле или изменить тип.
Безопасная обработка «неизвестных полей»
Сделайте парсеры терпимыми:
- Игнорируйте неизвестные поля по умолчанию (не падать из-за нового ключа).
- Рассматривайте новые поля как опциональные, пока они действительно не понадобятся.
- Логируйте неожиданные поля на низком уровне, чтобы заметить их использование без алармов.
Когда нужен ломающий изменения — используйте новый тип события или версионированное имя (например, OrderCreated.v2) и запускайте оба варианта параллельно, пока все консюмеры не мигрируют.
Выходы ИИ как схема: promptы, модели и структурированные ответы
Когда вы добавляете LLM в систему, её выводы быстро становятся де-факто схемой — даже если никто не написал формальный спецификат. Downstream-код начинает предполагать «будет поле summary», «первая строка — заголовок» или «пули разделяются дефисами». Эти допущения закрепляются, и небольшое изменение поведения модели может сломать их, как переименование колонки в БД.
Предпочитайте явную структуру (и валидируйте её)
Вместо парсинга «красивого текста» просите структурированный вывод (обычно JSON) и валидируйте его перед попаданием в систему. Это переход от «best effort» к контракту.
Практический подход:
- Опишите JSON-схему (или типизированный интерфейс) для ответа модели.
- Отклоняйте или помещайте в карантин некорректные ответы (не молча коэрсируйте).
- Логируйте ошибки валидации, чтобы видеть, что меняется.
Это особенно важно, когда ответы LLM попадают в data pipelines, автоматизацию или пользовательский контент.
Планируйте дрейф модели
Даже при одинаковом prompt выводы могут со временем смещаться: поля могут опускаться, появляться лишние ключи, типы могут меняться ("42" vs 42, массивы vs строки). Рассматривайте это как события эволюции схемы.
Эффективные смягчающие меры:
- Делайте поля опциональными, где разумно, и задавайте явные дефолты.
- Разрешайте неизвестные ключи, но безопасно их игнорируйте (если вы не в строгих требованиях соответствия).
- Добавляйте guardrails-проверки (обязательные поля, max-length, enum-значения).
Считайте изменения promptа как изменения API
Prompt — это интерфейс. Если вы его правите, версионируйте. Держите prompt_v1, prompt_v2 и выкатывайте постепенно (feature-флаги, canary, переключение по тенантам). Тестируйте на фиксированном evaluation-наборе перед промоушеном и держите старые версии пока downstream не адаптируется. Для подробностей по механике безопасного выката свяжите подход с /blog/safe-rollouts-expand-contract.
Тестирование и валидация изменений схем
Изменения схем обычно фейлятся скучными, но дорогими способами: новый столбец отсутствует в одном окружении, потребитель всё ещё ждёт старое поле, или миграция проходит на пустых данных, но таймаутит в продакшне. Тестирование превращает эти «сюрпризы» в предсказуемые исправления.
Три уровня тестов (и что они ловят)
Unit tests защищают локальную логику: маппинги, сериализаторы/десериализаторы, валидаторы и генераторы запросов. При переименовании поля или изменении типа unit-тесты должны падать рядом с проблемным кодом.
Integration tests проверяют приложение с реальными зависимостями: настоящая СУБД, реальный инструмент миграций и реальные форматы сообщений. Здесь ловятся проблемы вроде «модель ORM изменилась, но миграция — нет» или «новое имя индекса конфликтует».
End-to-end tests симулируют пользовательские сценарии и кросс-сервисные рабочие процессы: создайте данные, мигрируйте их, прочитайте через API и проверьте, что downstream-потребители ведут себя корректно.
Контрактные тесты для продьюсеров и консюмеров
Эволюция схем часто ломается на границах: сервис‑to‑сервис API, стримы, очереди и вебхуки. Добавьте контрактные тесты по обе стороны:
- Продьюсеры доказывают, что могут эмитить события/ответы согласно контракту.
- Консюмеры доказывают, что могут парсить и старую, и новую версии во время выката.
Тестирование миграций: применение и откат в чистых окружениях
Тестируйте миграции так, как вы их деплоите:
- Начните с чистого снепшота базы.
- Примените все миграции по порядку.
- Проверьте, что приложение читает/пишет.
- Выполните rollback (если поддерживается) или down-migration и убедитесь, что система возвращается в рабочее состояние.
Фикстуры для старых и новых версий схем
Храните небольшой набор фикстур, представляющих:
- Данные, записанные по предыдущей схеме (legacy rows/events).
- Данные, записанные по новой схеме.
Эти фикстуры делают регрессии очевидными, особенно когда ИИ-сгенерированный код тонко меняет имена полей, опциональность или форматирование.
Наблюдаемость: раннее обнаружение поломок
Сохраняйте полное владение кодом
Экспортируйте исходники, чтобы просматривать миграции, валидации и изменения контрактов в вашем репозитории.
Изменения схем редко ломаются громко в момент деплоя. Чаще поломки проявляются как постепенный рост ошибок парсинга, подозрительные «unknown field» ворнинги, пропажа данных или отставание фоновых джобов. Хорошая наблюдаемость превращает эти слабые сигналы в действующие тревоги, пока вы ещё можете поставить выкаты на паузу.
Что мониторить во время выката
Начните с базового (здоровье приложения), затем добавьте схемо-специфичные метрики:
- Ошибки: всплески 4xx/5xx, но также "мягкие" ошибки — JSON parsing failures, failed deserialization и retries.
- Задержки: p95/p99 latencies и время обработки очередей. Изменения схем могут добавить джоины, большие пейлоады или дополнительную валидацию.
- Сигналы качества данных: рост доли NULL в ключевых колонках, резкое падение объёма событий, новые «дефолтные» значения, или рассогласование между старым и новым представлением.
- Отставание пайплайна: lag потребителей в стримах/очередях, бэклог по доставке вебхуков и пропускная способность джобов миграции.
Ключ — сравнение до и после и срезы по версии клиента, версии схемы и сегменту трафика (canary vs stable).
Дашборды, которые действительно помогают
Создайте два представления дашборда:
-
Дашборд поведения приложения
- Request rate, error rate, latency (RED)
- Топ исключений (группировать по сообщению)
- Количество/доля ошибок валидации/десериализации
- Распределение размеров пейлоада (чтобы ловить неожиданные большие сообщения)
-
Дашборд миграций и фоновых джобов
- Прогресс миграции (% complete), rows processed/sec, ETA
- Частота ошибок и количество ретраев
- Глубина очереди / потребительский lag
- Объём в dead-letter очереди (если есть)
Если вы применяете expand/contract, добавьте панель, показывающую чтения/записи по старой vs новой схеме, чтобы видеть, когда можно переходить к следующей фазе.
Оповещения для ошибко‑специфичных проблем схемы
Пейджьте при проблемах, которые указывают на потерю или неверное чтение данных:
- Rate ошибок валидации схемы выше низкого порога (часто \u003c0.1% уже значимо).
- Парсинг/десериализация падает (особенно сконцентрировано в одном продьюсере/консюмере).
- Неожиданные / отсутствующие обязательные поля — тренд вверх.
- Миграция застопорилась (нет прогресса N минут) или lag растёт быстрее, чем пропускная способность.
Избегайте шумных алертов по сырым 500 без контекста; привязывайте сигналы к схеме-выкату через теги вроде версии схемы и endpoint.
Логируйте версию, чтобы быстро дебажить
Во время перехода включайте и логируйте:
- Версию схемы (например, заголовок
X-Schema-Versionили поле в метаданных сообщения) - Версию продюсера и потребителя приложения
- Версию модели / prompt когда структурированные данные формируются ИИ
Эта деталь делает вопрос «почему этот пейлоад упал?» разрешимым за минуты, а не дни — особенно когда одновременно живут разные версии сервисов и моделей.
Откат, восстановление и управление изменениями
Изменения схем ломаются двумя способами: само изменение неверно, или окружающая система ведёт себя иначе, чем ожидалось (особенно когда ИИ-сгенерированный код вносит тонкие допущения). В любом случае у каждой миграции до релиза должен быть план отката — даже если это явно «отката нет».
Выбор «без отката» может быть валиден, когда изменение необратимо (удаление колонок, перезапись идентификаторов, дедупликация). Но «без отката» — не отсутствие плана; это решение сдвигает стратегию в сторону фиксирования вперёд, восстановлений и локализации проблемы.
Практичные опции отката, которые реально работают
Feature-флаги / конфиги: Оборачивайте новых ридеров, райтеров и поля API флагами, чтобы можно было отключить новое поведение без redeploy. Особенно полезно, когда ИИ-сгенерированный код корректен синтаксически, но неверен семантически.
Отключение dual-write: Если вы пишете одновременно в старую и новую схемы во время expand/contract, держите kill-switch. Отключение нового пути записи остановит дальнейшее расхождение пока вы разбираетесь.
Ревертация ридеров (не только райтеров): Частые инциденты происходят потому, что потребители начинают читать новые поля/таблицы слишком рано. Сделайте простой механизм, чтобы сервисы могли вернуться к предыдущей версии схемы или игнорировать новые поля.
Знайте пределы обратимости
Некоторые миграции нельзя аккуратно отменить:
- Деструктивные трансформации (хеширование, lossy-normalization).
- Удаления/переименования без сохранённой копии.
- Backfills, перезаписывающие source-of-truth значения.
Для таких случаев планируйте восстановление из бэкапа, реплей из событий или пересчёт из raw inputs — и убедитесь, что эти входы ещё доступны.
Предварительный чеклист (перед релизом)
- Документировано решение по откату ("revert", "forward fix" или "no rollback + restore path").
- Наличие явной кнопки стоп: флаги и/или переключатель dual-write.
- Бэкапы/снэпшоты проверены; восстановление протестировано хотя бы один раз.
- Миграция идемпотентна; повторные запуски не портят данные.
- Мониторинг и алерты для error rate, валидации схем и lag.
- Ответственные: кто approves, кто выполняет, кто on-call во время выката.
Хорошее управление изменениями делает откаты редкими — и восстанавливает спокойный рутину, когда они всё же происходят.
Если ваша команда быстро итеративно работает с ИИ‑помощью, полезно сочетать эти практики с инструментами для безопасного эксперимента. Например, Koder.ai включает planning mode для проработки изменений заранее и snapshots/rollback для быстрого восстановления, когда сгенерированное изменение случайно смещает контракт. В связке быстрый кодогенератор и дисциплинированная эволюция схем позволяют двигаться быстрее, не обращая продакшн в тестовую среду.