Джо Армстронг и Erlang: «Let It Crash» для надёжных платформ
Как идеи Джо Армстронга сформировали подход Erlang к конкурентности, надёжности и концепции «let it crash» — принципы, которые до сих пор помогают строить отказоустойчивые real‑time сервисы.
О чём этот пост (и почему это всё ещё важно)
Джо Армстронг не только помог создать Erlang — он стал его самым ясным и убедительным объяснителем. Через доклады, статьи и прагматичное мировоззрение он популяризировал простую мысль: если вы хотите, чтобы ПО держалось в работе, вы проектируете его для отказа, а не притворяетесь, что отказов не будет.
Этот материал — экскурсия по мышлению Erlang и объяснение, почему оно важно при построении надёжных real-time платформ: чат-систем, маршрутизации звонков, живых уведомлений, координации мультиплеера и инфраструктуры, которая должна реагировать быстро и предсказуемо, даже когда части её ведут себя плохо.
«Реальное время» простыми словами
Реальное время не всегда значит «микросекунды» или «жёсткие дедлайны». Во многих продуктах это означает:
- быстрые ответы, которые чувствует пользователь (никаких загадочных пауз)
- предсказуемое поведение под нагрузкой (может замедлиться, но не уйти в спираль)
- продолжение обслуживания при частичных отказах (плохой компонент не должен валить всё)
Erlang создавался для телеком-систем, где такие ожидания не обсуждаются — и это давление сформировало его ключевые идеи.
Три столпа, на которых мы сосредоточимся
Вместо погружения в синтаксис, мы остановимся на концепциях, из-за которых Erlang стал известен и которые продолжают появляться в современном дизайне систем:
- Конкурентность по умолчанию: стройте ПО из множества маленьких, изолированных воркеров, а не из нескольких громадных модулей.
- Отказоустойчивость как цель проектирования: предполагаете баги, таймауты и падения — и планируете, что происходит дальше.
- «Let it crash»: не защищайте каждую строку кода до смерти; лучше падать быстро и восстанавливаться чисто через структуру (а не через геройство).
По пути мы свяжем эти идеи с акторной моделью и передачей сообщений, объясним деревья надзора и OTP простыми словами и покажем, почему BEAM VM делает весь подход практичным.
Даже если вы не используете Erlang (и никогда не будете), суть остаётся: формулировка Армстронга даёт мощный чек-лист для построения систем, которые остаются отзывчивыми и доступными, когда реальность начинает портить планы.
Мотивация Джо Армстронга: строить системы, которые не падают
Телеком-коммутаторы и платформы маршрутизации звонков не могут «пойти на техобслуживание» так, как многие сайты. От них ожидают круглосуточной обработки звонков, биллинга и сигнального трафика — часто с жёсткими требованиями по доступности и предсказуемому времени отклика.
Erlang появился в Ericsson в конце 1980‑х как попытка решать эти задачи программным путём, а не только специализированным железом. Джо Армстронг и коллеги не гнались за элегантностью ради элегантности; они пытались построить системы, которым операторы могли бы доверять при постоянной нагрузке, частичных отказах и в грязных реальных условиях.
Что на практике значит «надёжный»
Ключевой сдвиг в мышлении — надёжность не равна «никогда не падать». В больших долгоживущих системах что‑то обязательно сломается: процесс получит неожиданный ввод, узел перезагрузится, сетевой линк начнёт флапать или зависимость застопорится.
Тогда цель выглядит так:
- продолжать обслуживать пользователей, даже когда части ведут себя плохо
- быстро обнаруживать отказы
- автоматически восстанавливаться с минимальным вмешательством человека
- изолировать сбои, чтобы одна ошибка не валивала всё
Именно это мышление позже делает понятия вроде деревьев надзора и «let it crash» разумными: вы проектируете отказ как нормальное событие, а не как катастрофу.
Меньше мифов, больше решения задач
Удобно рассказывать историю как прорыв одного визионера. Полезнее понять проще: ограничения телекомов диктовали другие компромиссы. Erlang сделал ставку на конкурентность, изоляцию и восстановление, потому что это были практические инструменты для поддержания сервисов в постоянно меняющемся мире.
Такой ориентированный на проблему подход и объясняет, почему уроки Erlang остаются применимы сегодня — везде, где важнее время безотказной работы и быстрое восстановление, чем идеальная предотвращаемость ошибок.
Конкурентность по умолчанию: много маленьких воркеров
Основная идея в Erlang — «делать много вещей одновременно» не как опция, а как нормальная структура системы.
Лёгкие процессы, простыми словами
В Erlang работа разбита на множество крошечных «процессов». Думайте о них как о маленьких воркерах, каждый из которых отвечает за одну задачу: обработка звонка, поддержка сессии чата, мониторинг устройства, ретрай платежа или наблюдение за очередью.
Они лёгкие — это значит, что их можно запускать очень много без огромных затрат на железо. Вместо одного тяжёлого воркера, который пытается справиться со всем, вы получаете толпу сфокусированных воркеров, которые быстро стартуют, быстро останавливаются и легко заменяются.
Почему «одна большая программа» ломается иначе
Многие системы спроектированы как единый большой процесс с множеством тесно связанных частей. Когда такая система сталкивается с серьёзным багом, проблемой памяти или блокирующей операцией, отказ может распространиться — как выбивание одного автомата и обесточивание всего здания.
Erlang идёт в обратную сторону: изолируйте обязанности. Если один мелкий воркер ведёт себя плохо, вы можете убрать и заменить именно его, не роняя всё остальное.
Передача сообщений как «передача записок»
Как воркеры координируются? Они не лезут в внутреннее состояние друг друга. Они шлют сообщения — скорее как передача записок, а не совместное рисование на одной доске.
Один воркер может сказать: «Новый запрос», «Пользователь отключился» или «Попробуй через 5 секунд». Получатель читает записку и решает, что с ней делать.
Главный плюс — сдерживание распространения ошибок: так как воркеры изолированы и общаются через сообщения, сбои реже расползаются по всей системе.
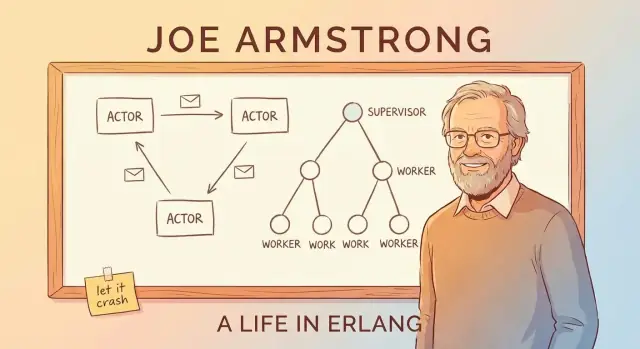
Передача сообщений и акторная модель (без жаргона)
Проще всего понять акторную модель как систему из множества маленьких независимых воркеров.
Акторы: маленькие воркеры, которые общаются только сообщениями
Актор — это самостоятельная единица с приватным состоянием и почтовым ящиком. Он делает три базовые вещи:
- получает сообщения (по одному за раз) из своего ящика
- обновляет своё внутреннее состояние
- отправляет сообщения другим акторам
И всё. Никаких скрытых общих переменных, никаких «взглянуть в память другого воркера». Если один актор нуждается в чём‑то у другого, он просит через сообщение.
Почему отсутствие общего состояния убирает целые классы багов
Когда несколько потоков шарят одни и те же данные, появляются условия гонки: два действия почти одновременно меняют одно значение, и результат зависит от тайминга. Тогда баги становятся редкими и трудно воспроизводимыми.
При передаче сообщений каждое состояние принадлежит актору. Другие акторы не могут напрямую его менять. Это не устраняет все ошибки, но сильно уменьшает проблемы, связанные с одновременным доступом к одним и тем же данным.
Back-pressure, объяснённый как очередь в кофейне
Сообщения не приходят «бесплатно». Если актор получает сообщения быстрее, чем обрабатывает, его почтовый ящик растёт. Это и есть back-pressure: система косвенно говорит «эта часть перегружена».
На практике вы мониторите размеры почтовых ящиков и вводите лимиты: отбрасывание нагрузки, батчинг, сэмплирование или перераспределение работы по дополнительным воркерам, вместо того чтобы позволять очередям расти бесконечно.
Конкретный пример: уведомления чата
Представьте чат‑приложение. Для каждого пользователя может быть актор, отвечающий за доставку уведомлений. Когда пользователь офлайн, сообщения продолжают приходить — почтовый ящик растёт. Хорошо спроектированная система ограничит очередь, сбросит некритичные уведомления или переключится на дайджест‑режим, а не позволит одному медленному пользователю ухудшить работу всего сервиса.
«Let It Crash»: падать быстро, восстанавливаться быстрее
«Let it crash» — это не лозунг для халтурной инженерии. Это стратегия надёжности: когда компонент попадает в плохое или неожиданное состояние, он должен остановиться быстро и заметно, а не пытаться медленно тащиться дальше.
Что это значит на деле
Вместо написания кода, который пытается обработать каждую возможную тупиковую ситуацию внутри одного процесса, Erlang поощряет держать воркеры маленькими и сфокусированными. Если воркер сталкивается с тем, что он не может корректно обработать (повреждённое состояние, нарушенные допущения, неожиданный ввод), он выходит. Другая часть системы отвечает за его восстановление.
Это смещает главный вопрос с «как предотвратить отказ?» на «как чисто восстановиться после отказа?».
Компромисс: меньше защитного кода, чище логика
Защитное программирование повсюду может превратить простые потоки в лабиринт условных операторов, ретраев и частичных состояний. «Let it crash» меняет часть этой внутренней сложности на:
- более понятные, читаемые потоки выполнения
- более быструю детекцию сломанных допущений
- восстановление, которое предсказуемо (потому что централизовано)
Главная идея — восстановление должно быть предсказуемым и повторяемым, а не импровизацией внутри каждой функции.
Где подходит — а где нет
Этот подход лучше всего работает, когда отказы восстановимы и изолированы: временные сетевые проблемы, плохой запрос, зависший воркер, таймаут у стороннего сервиса.
Он плохо подходит, когда падение может привести к необратимому вреду, например:
- потеря данных без долговременного источника истины
- операции, критичные с точки зрения безопасности, где «попробуй ещё раз» неприемлемо
Быстрые перезапуски и известное хорошее состояние
Падение помогает только если восстановление быстрое и безопасное. На практике это значит перезапуск воркеров в известное хорошее состояние — часто через перезагрузку конфигурации, восстановление in‑memory кэшей из долговременного хранилища и продолжение работы без притворства, что сломавшееся состояние никогда не существовало.
Деревья надзора: проектирование отказов преднамеренно
Идея «let it crash» работает только потому, что падения не остаются на совести случая. Ключевой паттерн — дерево надзора: иерархия, где супервайзеры как менеджеры и воркеры делают реальную работу (обработка звонков, сессий, потребление очередей и т.д.). Когда воркер ведёт себя плохо, менеджер это замечает и рестартует его.
Менеджеры, которые перезапускают воркеров
Супервайзер не пытается «починить» упавший воркер на месте. Он применяет простое и последовательное правило: если воркер умер — запусти нового. Это делает путь восстановления предсказуемым и снижает необходимость в импровизированной обработке ошибок по всему коду.
Не менее важно, что супервайзеры решают и когда не перезапускать — если что‑то падает слишком часто, это может указывать на глубинную проблему, и бесконечные перезапуски только усугубят ситуацию.
Стратегии перезапуска (в общих чертах)
Супервайзия не универсальна. Популярные стратегии:
- One‑for‑one: перезапускается только упавший воркер. Подходит для независимых задач.
- Group restarts: при падении одного перезапускается связанный набор. Подходит для тесно связанных компонентов, которые должны оставаться синхронизированными.
Зависимости: над чем надо подумать
Хороший дизайн дерева надзора начинается с карты зависимостей: какие компоненты от чего зависят и что значит «чистый старт» для них.
Если обработчик сессии зависит от кэша, перезапускать только обработчик может оставить его в подвешенном состоянии. Группировка под правильным супервайзером (или перезапуск вместе) превращает хаотичные режимы отказов в согласованное и предсказуемое восстановление.
OTP: готовые блоки для надёжных сервисов
Если Erlang — язык, то OTP (Open Telecom Platform) — набор компонентов, который превращает «let it crash» в то, что можно эксплуатировать годами.
OTP как набор проверенных шаблонов
OTP — не просто библиотека; это набор конвенций и готовых компонентов (behaviours), которые решают скучные, но критичные части построения сервисов:
gen_serverдля долго живущих воркеров с состоянием и последовательной обработкой запросовsupervisorдля автоматического перезапуска упавших воркеров по понятным правиламapplicationдля определения порядка старта/остановки сервиса и его места в релизе
Это не магия, а шаблоны с явными колбэками, так что ваш код вписывается в знакомую форму вместо того, чтобы каждый проект изобретал свою.
Почему стандартные паттерны лучше кастомных фреймворков
Команды часто пишут ad‑hoc фоновые воркеры, самодельные хуки мониторинга и одноразовую логику перезапуска. Это работает — пока не перестаёт. OTP снижает риск, направляя всех к одному языку и жизненному циклу. Новый инженер не должен сначала изучать ваш самописный фреймворк; он опирается на общепринятые паттерны в Erlang‑экосистеме.
Как OTP задаёт архитектуру в повседневной работе
OTP подталкивает думать про роли процессов и ответственности: кто воркер, кто координатор, кто за что перезапускает и что никогда не должно перезапускаться автоматически.
Он также поощряет хорошую дисциплину: явные имена, порядок старта, предсказуемое завершение и встроенные сигналы мониторинга. В результате получается софт, спроектированный для непрерывной работы — сервисы, которые могут восстановиться, эволюционировать и продолжать выполнять свою задачу без постоянного человеческого надзора.
BEAM VM: рантайм, который делает модель практичной
Большие идеи Erlang — крошечные процессы, обмен сообщениями и «let it crash» — были бы гораздо труднее применять в продакшене без BEAM виртуальной машины. BEAM — это рантайм, который делает эти паттерны естественными, а не хрупкими.
Планирование задач: справедливость важнее «одного большого потока»
BEAM создан для запуска огромного числа лёгких процессов. Вместо опоры на несколько потоков ОС и надежды, что приложение себя правильно поведёт, BEAM сам планирует Erlang‑процессы.
Практический эффект — отзывчивость под нагрузкой: работа режется на маленькие куски и по очереди исполняется, так что ни один занятый воркер не должен надолго доминировать систему. Это отлично подходит для сервисов из множества независимых задач — каждая делает немного работы, затем уступает.
Изоляция и сборка мусора на процесс
Каждый Erlang‑процесс имеет свой собственный хип и свою сборку мусора. Важная деталь: очистка памяти в одном процессе не требует паузы всего приложения.
Не менее важно, что процессы изолированы. Если один падает, он не портит память других, и VM остаётся живой. Эта изоляция — фундамент, который делает деревья надзора реалистичными: отказ локален, затем его обрабатывают перезапуском части, а не сваливанием системы.
Дистрибуция: несколько нод как одна система
BEAM также поддерживает дистрибуцию простыми средствами: вы можете запускать несколько Erlang‑нод и позволять им общаться сообщениями. Если вы поняли «процессы общаются сообщениями», дистрибуция — это просто продолжение той же идеи: часть процессов живёт на другой ноде.
BEAM не обещает абсолютной скорости. Он даёт удобство делать конкурентность, изоляцию отказов и восстановление привычной практикой, а не утопией.
Обновления без остановки системы (Hot Code, аккуратно)
Один из самых обсуждаемых трюков Erlang — горячая замена кода: обновление частей работающей системы с минимальным простоем (при поддержке рантайма и инструментов). Практическое обещание не в «никогда ничего не перезапускать», а в том, чтобы правки можно было выпустить, не превращая мелкий баг в долгое падение.
Что на самом деле значит «hot code»
В Erlang/OTP рантайм может держать одновременно две версии модуля. Существующие процессы могут закончить работу на старой версии, а новые вызовы — идти на новую. Это даёт пространство для патчей, релизов и правок без массовых перезапусков.
При аккуратном использовании это поддерживает цели надёжности напрямую: меньше перезапусков, короче окна обслуживания и быстрее восстановление при ошибке.
Ограничения, которые нельзя игнорировать
Не каждое изменение безопасно для живой подмены. Примеры изменений, требующих осторожности или перезапуска:
- изменение формы состояния (новый код ожидает другие данные)
- изменения протоколов или формата сообщений, требующие совместимости между сервисами
- миграции схем, которые занимают время или требуют координации
Erlang предоставляет механизмы для контролируемого перехода, но вам всё равно нужно проектировать путь обновления.
Мышление: апгрейды и откаты — нормальное дело
Горячие обновления работают лучше, когда апгрейды и откаты рассматриваются как рутинные операции, а не редкие чрезвычайные события. Это значит планирование версионирования, совместимости и явного пути «отката» с самого начала. На практике команды комбинируют live‑upgrade техники со staged rollouts, health checks и восстановлением через супервайзеры.
Даже если вы никогда не будете использовать Erlang, урок переносится: проектируйте систему так, чтобы безопасно менять её было важным требованием, а не опцией.
Где идеи Erlang особенно полезны в real‑time платформах
Real‑time платформы скорее про то, чтобы оставаться отзывчивыми, когда всё идёт не так: сети шатаются, зависимости тормозят, трафик взлетает. Дизайн Erlang — популяризированный Джо Армстронгом — подходит под эту реальность, потому что предполагает сбои и делает конкурентность нормой.
Частые кейсы «реального времени»
Erlang‑подход проявляет себя там, где много независимых активностей:
- Messaging и чат: миллионы небольших разговоров, у каждого своё состояние и ретраи.
- Реальное общение: сигнальная логика для голоса/видео, обновления присутствия, координация сессий.
- IoT: парки устройств, которые непредсказуемо подключаются и отключаются.
- Платёжные workflow: многошаговые процессы, где некоторые шаги медленные, недоступные или требуют компенсирующих действий.
Что обычно значит «soft real‑time»
Большинству продуктов не нужны жёсткие гарантии «каждое действие за 10 мс». Им нужно soft real‑time: стабильно низкая задержка для обычных запросов, быстрое восстановление при сбоях и высокая доступность, чтобы пользователи редко замечали инциденты.
Отказ — это нормальность: проектируйте для этого
Реальные системы сталкиваются с:
- сбрисами соединений (мобильные сети, переключения Wi‑Fi)
- таймаутами у медленных зависимостей
- частичными отказами в регионе или у внешней зависимости
Модель Erlang поощряет изолировать каждую активность (сессия пользователя, устройство, попытка оплаты), чтобы отказ не растёкся. Вместо одного гигантского компонента команды разбивают логику на маленькие воркеры: каждый делает своё, общается сообщений и, если ломается — его чисто перезапускают.
Именно этот сдвиг — от «предотвратить каждый отказ» к «сдержать и быстро восстановиться» — часто делает real‑time платформы стабильными под давлением.
Распространённые заблуждения и реальные ограничения
Репутация Erlang иногда воспринимается как обещание: системы, которые никогда не падают, потому что просто перезапускаются. Реальность практичнее. «Let it crash» — инструмент для надёжности, а не оправдание игнорирования сложных проблем.
Перезапуски — не пластырь
Обычная ошибка — считать, что супервизия скрывает глубокие баги. Если процесс падает сразу после старта, супервайзер может постоянно его перезапускать в crash loop — при этом жрёт CPU, засоряет логи и создаёт ещё большую проблему.
Хорошие системы вводят бэк‑офф, лимиты интенсивности рестартов и поведение «сдаться и эскалировать». Перезапуски должны восстанавливать корректную работу, а не маскировать сломанные инварианты.
С состоянием сложнее
Перезапустить процесс обычно просто; восстановить корректное состояние — нет. Если состояние живёт только в памяти, нужно решить, что значит «правильно» после падения:
- восстанавливать из долговременного хранилища?
- можно ли воспроизвести события безопасно (идемпотентность)?
- что с in‑flight работой или частично применёнными обновлениями?
Отказоустойчивость не заменяет тщательный дизайн данных — она заставляет делать его явным.
Нужна наблюдаемость
Падения полезны только если их видно и понимают. Это значит вкладываться в логирование, метрики и трейсинг — не просто «он перезапустился, значит всё ок». Нужно замечать рост числа рестартов, раздувающиеся очереди и медленные зависимости до того, как пользователи это почувствуют.
Реальные операционные ограничения существуют
Даже с сильными сторонами BEAM система может падать по обычным причинам:
- рост памяти из‑за утечек, больших хипов или кэшей
- накопление сообщений в почтовиках, когда производители быстрее потребителей
- отказы зависимостей (БД, сторонние API, DNS), где перезапуск кода не решит корень проблемы
Модель Erlang помогает изолировать и восстанавливаться, но не может убрать сами сбои.
Как применить уроки сегодня (даже если вы не на Erlang)
Главный подарок Erlang — не синтаксис, а набор привычек для построения сервисов, которые держатся в работе, когда части неизбежно ломаются. Эти привычки можно перенести в любой стек.
Перевод идей в конкретные действия
Начните с явного определения границ отказа. Разбейте систему на компоненты, которые могут падать независимо, и пропишите для каждого контракт (входы, выходы и что значит «плохо»).
Затем автоматизируйте восстановление вместо попыток предотвратить каждую ошибку:
- изолируйте компоненты: запускайте рискованную работу в отдельных процессах/контейнерах/сервисах
- определяйте границы: таймауты, ретраи с backoff, circuit breakers и bulkheads
- сделайте восстановление рутинным: health checks, авто‑рестарт и безопасные дефолты
Один практичный путь внедрения — вшить эти привычки в инструменты и жизненный цикл, а не только в код. Например, когда команды пользуются Koder.ai для vibe‑кодинга веба, бэкенда или мобильных приложений через чат, рабочий процесс поощряет явное планирование (Planning Mode), повторяемые деплои и безопасную итерацию со снимками и откатом — концепции, созвучные мышлению Erlang: предполагать изменение и отказ и делать восстановление банальным.
Отправные точки вне Erlang
Можно приблизить паттерны «супервизии» с помощью привычных инструментов:
- Супервизоры: systemd, Kubernetes Deployments или менеджер процессов (restart‑on‑failure, readiness probes).
- Изоляция процессов: отдельные сервисы для тяжёлых или ненадёжных задач.
- Передача сообщений: очереди/стримы (RabbitMQ, SQS, Kafka) для развязки и смягчения всплесков.
Короткий чек‑лист для решений
Перед тем как копировать паттерны, решите, что вам действительно нужно:
- Ожидаемые сценарии отказа: перегрузка, частичные отказы, медленные зависимости, некорректные входы, утечки памяти.
- Требования по латентности: нужен ли отклик в реальном времени или допустима отложенная обработка?
- Цель восстановления: быстрый рестарт, грациозная деградация или ручное вмешательство?
- Командные навыки и инструменты: кто в он‑колле, кто отвечает за наблюдаемость и инциденты?
Если хотите практические следующие шаги, смотрите гайды в /blog, реализационные детали в /docs и планы в /pricing, если оцениваете инструменты.
FAQ
Почему подход Джо Армстронга с Erlang всё ещё релевантен сегодня?
Erlang популяризировал практичный подход к надёжности: предполагать, что части системы будут падать, и заранее планировать, что с этим делать.
Вместо попыток предотвратить каждый сбой он делает акцент на изоляции отказов, быстрой детекции и автоматическом восстановлении, что хорошо подходит для реального времени — чат, маршрутизация звонков, уведомления и системы координации.
Что в посте понимается под «реальным временем»?
В этом контексте «реальное время» обычно означает soft real-time:
- ответы ощущаются быстрыми и согласованными
- поведение остаётся предсказуемым под нагрузкой
- система продолжает работать при частичных сбоях
Это не про микросекундные гарантии, а про избегание зависаний, лавинообразных проблем и каскадных отказов.
Что значит «конкурентность по умолчанию» в стиле Erlang?
«Конкурентность по умолчанию» означает строить систему из многих маленьких, изолированных рабочих вместо нескольких больших, тесно связанных компонентов.
Каждый воркер отвечает за узкую часть ответственности (сессия, устройство, попытка оплаты, цикл ретраев), что упрощает масштабирование и локализацию отказов.
Что такое «лёгкие процессы» в Erlang и зачем они нужны?
Лёгкие процессы — это небольшие независимые воркеры, которые можно создавать в большом количестве.
Практические плюсы:
- можно моделировать один процесс на «вещь» (пользователь/сессия/устройство)
- отказы остаются локальными для одного воркера
- перезапуск воркера дешевле, чем перезагрузка монолита
Почему Erlang предпочитает передачу сообщений вместо общего состояния?
Обмен сообщениями — это координация через отправку сообщений, а не через общий изменяемый стейт.
Это уменьшает целый класс ошибок конкурентности (например, гонки), потому что каждый воркер владеет своим состоянием; другие воркеры могут повлиять на него только косвенно, отправив сообщение.
Что такое back-pressure в акторной/сообщной системе и как с ним обращаться?
Бэк-прешер возникает, когда воркер получает сообщения быстрее, чем успевает их обрабатывать, и его почтовый ящик растёт.
Практические способы борьбы:
- мониторить размеры почтовых ящиков/очередей
- вводить лимиты (отбрасывать, сэмплировать, ограничивать)
- распределять нагрузку по большим пулу воркеров
- деградировать поведение (например, переключаться на дайджесты для некритичных уведомлений)
Что на самом деле означает «let it crash» (и чего это не значит)?
«Let it crash» значит: если воркер попадает в неверное или непредвиденное состояние, он должен быстро упасть, а не продолжать работать в некорректном режиме.
Восстановление берёт на себя структура (надзор), что даёт более простые и предсказуемые потоки выполнения — при условии, что перезапуски безопасны и быстры.
Что такое supervision trees и почему они важны для отказоустойчивости?
Дерево надзора — это иерархия, где супервайзеры наблюдают за воркерами и перезапускают их по заданным правилам.
Вместо рассыпанных по коду ad-hoc решений вы централизуете логику восстановления:
- решаете, что перезапускать при отказе
- предотвращаете бесконечные циклы падений через лимиты/бекофф
- перезапускаете связанные компоненты вместе, если им нужно оставаться согласованными
Что такое OTP и как оно помогает строить надёжные сервисы?
OTP — набор стандартных шаблонов (behaviours) и конвенций, которые делают «let it crash» пригодным для эксплуатации в продакшене.
Ключевые строительные блоки:
gen_serverдля долго живущих воркеров с состояниемsupervisorдля политик перезапускаapplicationдля описания старта/остановки и релизов
Преимущество — общая, понятная жизненная модель вместо множества самописных фреймворков.
Как применить уроки Erlang, если я не использую Erlang?
Принципы Erlang можно применить в любых стэках, выделяя отказные границы и автоматизируя восстановление:
- изолируйте рискованную работу в отдельные процессы/контейнеры/сервисы
- добавьте таймауты, ретраи с backoff, circuit breakers и bulkheads
- автоматизируйте восстановление (health checks + restart-on-failure)
- используйте очереди/стримы (RabbitMQ, SQS, Kafka) для развязывания продюсеров и консюмеров
Подробности и гайды — в /blog и /docs.