Почему команды упираются в стену при традиционных интеграциях
Большинство продуктов начинают с простых точечных интеграций: Система A вызывает Систему B, или небольшой скрипт копирует данные из одного места в другое. Это работает, пока продукт не растёт, команды не разделяются, и количество соединений не умножается. Вскоре каждое изменение требует координации между несколькими сервисами, потому что одно маленькое поле или обновление статуса может распространиться по цепочке зависимостей.
Скорость обычно ломается первой. Добавление новой функции означает обновление нескольких интеграций, повторный деплой нескольких сервисов и надежду, что никто не зависел от старого поведения.
Дальше отладка становится болезненной. Когда в UI что-то выглядит неправильно, трудно ответить на простые вопросы: что произошло, в каком порядке и какая система записала то значение, которое вы видите?
Часто не хватает трейла аудита. Если данные пушатся напрямую из одной базы в другую (или преобразуются по пути), вы теряете историю. Видно только финальное состояние, но не последовательность событий, к которой оно привело. Постинцидентные разбирательства и служба поддержки страдают, потому что вы не можете воспроизвести прошлое, чтобы подтвердить, что и почему изменилось.
Здесь же начинается спор «кто владеет истиной». Одна команда говорит: «Сервис биллинга — источник правды». Другая отвечает: «Сервис заказов — источник правды». На самом деле каждая система видит частичную картину, и точечные интеграции превращают это расхождение в ежедневное трение.
Простой пример: заказ создан, затем оплачен, затем возвращён. Если три системы обновляют друг друга напрямую, каждая может получить разную историю при ретраях, таймаутах или ручных исправлениях.
Это приводит к основному вопросу проектирования, стоящему за Kafka event streaming: нужно ли вам просто перемещать работу из одного места в другое (очередь), или вам нужен общий, долговечный журнал того, что произошло, который многие системы могут читать, перематывать и которому можно доверять (журнал)? Ответ меняет способ построения, отладки и эволюции системы.
Jay Kreps, Kafka и идея журнала
Jay Kreps помог сформировать Kafka и, что важнее, то, как многие команды думают о перемещении данных. Полезный сдвиг — в мышлении: перестать рассматривать сообщения как разовые доставки и начать рассматривать активность системы как запись.
Суть проста. Моделируйте важные изменения как поток неизменяемых фактов:
- Заказ был создан.
- Платёж был авторизован.
- Пользователь сменил email.
Каждое событие — факт, который не следует редактировать задним числом. Если что-то изменилось позже, вы добавляете новое событие, которое фиксирует новую истину. Со временем эти факты формируют журнал: добавляемую-only историю вашей системы.
Здесь Kafka event streaming отличается от многих простых систем обмена сообщениями. Многие очереди устроены по принципу «отправь, обработай, удали». Это нормально, когда работа — просто передача. Видение журнала говорит: «сохраняйте историю, чтобы многие потребители могли её использовать сейчас и позже».
Возможность повторного проигрывания истории — практическая суперсила.
Если отчёт неверен, вы можете прогнать ту же историю событий через исправленную аналитическую задачу и увидеть, где поменялись цифры. Если баг вызвал неправильные письма, вы можете воспроизвести события в тестовой среде и воссоздать точную последовательность. Если новой функции нужны старые данные, можно сделать нового потребителя, который начнёт с самого начала и догонит в своём темпе.
Вот конкретный пример. Представьте, что вы добавляете проверки на мошенничество после того, как уже обработали месяцы платежей. С журналом платежей и событий аккаунта вы можете воспроизвести прошлое, обучить или откалибровать правила на реальных последовательностях, вычислить оценки риска для старых транзакций и добавить события «fraud_review_requested», не переписывая базу данных.
Заметьте, что это заставляет вас делать. Подход на основе журнала подталкивает к чёткой номенклатуре событий, их стабильности и принятию того, что несколько команд и сервисов будут зависеть от них. Он также вызывает полезные вопросы: что является источником правды? Что это событие значит в долгосрочной перспективе? Что делать, если мы ошиблись?
Ценность не в личности. Она в осознании, что общий журнал может стать памятью вашей системы, а память позволяет системам расти, не ломаясь при добавлении нового потребителя.
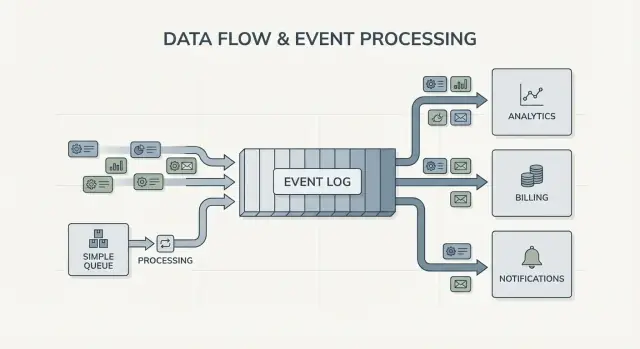
Очередь vs журнал: простая мысленная модель
Очередь сообщений — как очередь задач для вашего софта. Производители кладут работу в линию, потребители берут следующий элемент, выполняют работу, и элемент исчезает. Система в основном про то, чтобы задача была выполнена один раз как можно быстрее.
Журнал другой. Это упорядоченная запись фактов, которые произошли, хранимая в прочной последовательности. Потребители не «забирают» события. Они читают журнал в своём темпе и могут читать его снова позже. В Kafka event streaming журнал — это основная идея.
Практический способ запомнить разницу:
- Очередь = работа, которую нужно выполнить. Как только работник подтверждает, запись исчезает.
- Журнал = история того, что произошло. События хранятся в течение периода ретеншна.
Ретеншн меняет дизайн. С очередью, если позже понадобилась новая функция, зависящая от старых сообщений (аналитика, проверки мошенничества, воспроизведение после бага), часто приходится добавлять отдельную базу или начинать копировать сообщения куда‑то ещё. С журналом воспроизведение — нормальность: вы можете восстановить вывод, прочитав с начала (или с известной точки).
Фан-аут — ещё одно большое отличие. Представьте, что сервис оформления заказа эмитирует OrderPlaced. С очередью обычно выбирают одну группу воркеров для обработки или дублируют работу по нескольким очередям. С журналом billing, email, inventory, поисковое индексирование и аналитика могут все читать один и тот же поток независимо. Каждая команда движется в собственном темпе, и добавление нового потребителя позже не требует изменений со стороны производителя.
Итак, модель проста: используйте очередь, когда вы перемещаете задачи; используйте журнал, когда вы записываете события, которые многие части компании захотят читать сейчас или позже.
Что меняет потоковая передача событий в дизайне системы
Event streaming переворачивает исходный вопрос. Вместо «кому я должен отправить это сообщение?» вы начинаете с записи: «что только что произошло?» Звучит мелко, но меняет модель системы.
Вы публикуете факты, такие как OrderPlaced или PaymentFailed, а другие части системы решают, реагировать ли им, когда и как.
С Kafka event streaming производители перестают нуждаться в списке прямых интеграций. Сервис оформления заказа может опубликовать одно событие и не знать, будут ли его использовать аналитика, email, проверки мошенничества или будущая рекомендательная сервис. Новые потребители могут появляться позже, старые — ставиться на паузу, а поведение производителя не меняется.
Это также меняет восстановление после ошибок. В мире только сообщений, если потребитель пропустил что‑то или в нём был баг, данные часто «теряются», если вы не сделали кастомные бэкапы. С журналом можно исправить код и воспроизвести историю, чтобы восстановить корректное состояние. Это часто лучше, чем ручные правки баз данных или одноразовые скрипты, которым никто не доверяет.
На практике сдвиг проявляется в нескольких надёжных способах: вы относитесь к событиям как к долговременной записи, добавляете функции подпиской вместо изменения производителей, можете перестроить представления (поиск, дашборды) с нуля и получаете более ясные хронологии происходившего между сервисами.
Наблюдаемость улучшается, потому что журнал событий становится общим ориентиром. Когда что‑то идёт не так, вы можете следовать бизнес‑последовательности: заказ создан, резервирование инвентаря, повторная попытка оплаты, планирование отгрузки. Эта временная шкала часто проще для понимания, чем разбросанные логи приложений, потому что она сфокусирована на бизнес‑фактах.
Конкретный пример: если баг в скидках неправильно оценил заказы в течение двух часов, вы можете выпустить фикc и воспроизвести затронутые события, чтобы пересчитать итоги, обновить счета и освежить аналитику. Вы исправляете результаты, перепроизводя их, а не выясняя, какие таблицы править вручную.
Когда простая очередь достаточна
Простая очередь — правильный инструмент, когда вы перемещаете работу, а не строите долговременную запись. Цель — передать задачу воркеру, выполнить её и забыть. Если никому не нужно воспроизводить прошлое, смотреть старые события или позже добавлять потребителей, очередь упрощает систему.
Очереди хороши для фоновых заданий: отправка письма при регистрации, изменение размера изображений после загрузки, генерация ночного отчёта или вызов внешнего API, который может работать медленно. В этих случаях сообщение — просто билет на работу. Как только воркер завершил задачу, билет выполнил свою роль.
Очередь также соответствует обычной модели ответственности: одна группа потребителей отвечает за выполнение работы, и не ожидается, что другие сервисы будут независимо читать то же сообщение.
Очередь обычно достаточна, когда большинство из следующих условий верны:
- Данные имеют краткосрочную ценность.
- Одной команде или одному сервису принадлежит задача от начала до конца.
- Воспроизведение и длительное хранение не требуются.
- Отладка не зависит от повторного проигрывания истории.
Пример: продукт загружает фотографии пользователей. Приложение пишет задачу "изменить размер изображения" в очередь. Воркер A забирает её, создаёт миниатюры, сохраняет и помечает задачу как выполненную. Если задача запустится дважды, результат тот же (идемпотентно), поэтому at‑least‑once доставка допустима. Другие сервисы не должны читать эту задачу позже.
Если ваши потребности начинают склоняться к общим фактам (много потребителей), воспроизведению, аудиту или вопросу «что система считала на прошлой неделе?», тогда Kafka event streaming и подход на основе журнала начинают окупаться.
Когда подход на основе журнала оправдан
Подход на основе журнала окупается, когда события перестают быть разовыми сообщениями и становятся общей историей. Вместо «отправь и забудь» вы храните упорядоченную запись, которую многие команды могут читать сейчас или позже в своём темпе.
Самый ясный сигнал — множественные потребители. Одно событие, например OrderPlaced, может питать billing, email, проверки мошенничества, поисковое индексирование и аналитику. С журналом каждый потребитель читает один и тот же поток независимо. Вам не нужно строить кастомный фан‑аут или координировать, кто получит сообщение первым.
Ещё одно преимущество — возможность ответить на вопрос «что мы тогда знали?». Если клиент оспаривает списание или рекомендация сработала неправильно, добавочный журнал делает возможным воспроизведение фактов в том виде, как они приходили. Трейл аудита сложно прикрутить к простой очереди задним числом.
Вы также получаете практический способ добавлять новые функции без переписывания старых. Если спустя месяцы вы добавляете страницу статуса доставки, новый сервис может подписаться и заполнить состояние из существующей истории вместо запроса экспортов у всех upstream‑сервисов.
Подход на основе журнала обычно стоит применять, когда вы видите одно или несколько из этих требований:
- Те же события должны питать несколько систем (analytics, search, billing, support tools).
- Нужны воспроизведение, аудит или расследования на основе прошлых фактов.
- Новые сервисы должны иметь возможность бэфилла из истории без одноразовых задач.
- Порядок важен на уровне сущности (по заказу, по пользователю).
- Форматы событий будут эволюционировать, и нужен контролируемый способ версионирования.
Типичный сценарий: продукт начинается с заказов и писем. Позже финансы хотят отчёты по доходам, продукт — воронки, ops — живую панель. Если каждая новая потребность заставляет копировать данные через новую трубопроводную линию, расходы быстро растут. Общий журнал событий позволяет командам строить поверх единого источника правды, даже если система растёт и форма событий меняется.
Как выбрать, шаг за шагом
Выбор между очередью и подходом на основе журнала проще, если рассматривать его как продуктное решение. Начинайте с того, что вам нужно, чтобы было верно через год, а не только то, что работает на этой неделе.
Практические 5 шагов для принятия решения
-
Замапьте издателей и читателей. Запишите, кто сейчас создаёт события и кто их читает, затем добавьте вероятных будущих потребителей (аналитика, индексирование поиска, проверки мошенничества, уведомления). Если вы ожидаете, что много команд будет независимо читать те же события, журнал начинает иметь смысл.
-
Спросите, потребуется ли вам перечитывать историю. Будьте конкретны: воспроизведение после бага, бэфиллы или потребители, читающие в разном темпе. Очереди хороши для однократной передачи работы. Журналы лучше, когда нужен запись, которую можно воспроизвести.
-
Определите, что значит «готово». Для некоторых рабочих потоков готовность означает «задача запущена» (отправить письмо, изменить изображение). Для других это значит «событие — долговечный факт» (заказ размещён, платёж авторизован). Долговечные факты тянут к журналу.
-
Выберите ожидания доставки и решите, как вы будете обрабатывать дубликаты. Часто используется at‑least‑once доставка, а это значит, что дубликаты возможны. Если дубликат может навредить (двойное списание), планируйте идемпотентность: храните ID обработанного события, используйте уникальные ограничения или делайте обновления безопасными при повторном применении.
-
Начните с одного тонкого среза. Выберите один поток событий, который легко объяснить, и растите от него. Если вы идёте с Kafka event streaming, держите первую тему сфокусированной, давайте понятные имена событиям и избегайте смешивания несвязанных типов событий.
Конкретный пример: если OrderPlaced впоследствии будет питать доставку, выставление счётов, саппорт и аналитику, журнал даёт каждой команде возможность читать в своём темпе и воспроизводить при ошибках. Если вам нужен только фоновой воркер для отправки квитанции, простая очередь обычно достаточна.
Пример: события заказа в растущем продукте
Представьте небольшой онлайн‑магазин. Сначала нужно только принимать заказы, списывать карту и создавать запрос на доставку. Самый простой вариант — одна фонова задача после оформления: «обработать заказ». Она обращается к платежному API, обновляет строку заказа в базе, затем вызывает доставку.
Этот стиль очереди работает, когда есть один ясный рабочий процесс, только один потребитель (воркер), и ретраи и dead letters покрывают большинство ошибок.
Проблемы появляются по мере роста магазина. Саппорт хочет автоматические обновления «где мой заказ?». Финансы хотят ежедневные отчёты о доходах. Команда продукта хочет e‑mail‑рассылки. Проверка мошенничества должна быть до отправки. С одной задачей «process order» вы всё время правите одного и того же воркера, добавляете ветки и рискуете новым багом в основном потоке.
С подходом на основе журнала оформление создаёт мелкие факты в виде событий, и каждая команда может строить поверх них. Типичные события выглядят так:
OrderPlacedPaymentConfirmedItemShippedRefundIssued
Ключевое изменение — владение. Сервис оформления отвечает за OrderPlaced. Платёжный сервис — за PaymentConfirmed. Доставка — за ItemShipped. Позже могут появиться новые потребители без изменения производителя: сервис мошенничества читает OrderPlaced и PaymentConfirmed для оценки риска, сервис писем отправляет чеки, аналитика строит воронки, инструменты поддержки показывают временную шкалу событий.
Именно тут Kafka event streaming окупается: журнал хранит историю, поэтому новые потребители могут перемотать и догнать с начала (или с известной точки), вместо того чтобы просить каждую upstream‑команду добавить ещё один webhook.
Журнал не заменяет вашу базу данных. База всё ещё нужна для текущего состояния: последний статус заказа, карточка клиента, остатки на складе и транзакционные правила (например, «не отправлять, пока платёж не подтверждён»). Думайте о журнале как о записи изменений, а о базе — как о месте, где вы запрашиваете «что верно прямо сейчас».
Распространённые ошибки и ловушки
Event streaming может сделать систему чище, но несколько распространённых ошибок быстро сведут на нет преимущества. Большинство из них связаны с тем, что журнал воспринимают как пульт дистанционного управления, а не как запись.
Частая ловушка — записывать события как команды, типа «SendWelcomeEmail» или «ChargeCardNow». Это сильно связывает потребителей с вашим намерением. События лучше записывать как факты: «UserSignedUp» или «PaymentAuthorized». Факты лучше стареют. Новые команды могут переиспользовать их без догадок о значении.
Дубликаты и ретраи — следующий большой источник боли. В реальных системах производители ретраят и потребители перерабатывают. Если вы не спроектировали это, получите двойные платежи, двойные письма и недовольных пользователей. Исправление не экзотическое, но должно быть продуманным: идемпотентные обработчики, стабильные ID событий и бизнес‑правила, которые обнаруживают «уже применено».
Распространённые ошибки:
- Использование командного стиля событий, которые говорят сервисам, что делать, вместо фиксации фактов.
- Потребители, которые ломаются при повторном появлении того же события.
- Раннее дробление потоков, когда один бизнес‑поток раз散ан по слишком многим темам.
- Игнорирование правил схемы, пока мелкое изменение не сломает старых потребителей.
- Восприятие стриминга как замены хорошего проектирования базы данных.
Схемам и версионированию нужно уделять особое внимание. Даже если вы начинаете с JSON, нужен ясный контракт: какие поля обязательны, какие опциональны и как разворачиваются изменения. Маленькое изменение, например переименование поля, может тихо сломать аналитику, биллинг или мобильные клиенты, которые обновляются медленнее.
Ещё одна ловушка — чрезмерное дробление. Команды иногда создают новый поток для каждой фичи. Через месяц никто не сможет ответить «какое текущее состояние заказа?», потому что история разбросана по множеству мест.
Event streaming не отменяет необходимость в чётких моделях данных. База данных всё ещё нужна для представления текущей правды. Журнал — это история, а не всё ваше приложение.
Быстрый чеклист и дальнейшие шаги
Если вы в раздумьях между очередью и Kafka event streaming, начните с нескольких быстрых проверок. Они подскажут, нужен ли вам простой перенос задач между воркерами или журнал, которым будут пользоваться годами.
Быстрые проверки
- Нужны ли вам воспроизведения (для бэфиллов, фиксирования багов или новых фич), и насколько глубоко?
- Понадобится ли более чем одному потребителю те же события сейчас или скоро (аналитика, поиск, письма, мошенничество, биллинг)?
- Нужен ли ретеншн, чтобы команды могли перечитывать историю без просьб к производителю переслать данные?
- Насколько важен порядок и на каком уровне: по сущности (по заказу, по пользователю) или глобально?
- Могут ли потребители быть идемпотентными (безопасно ли повторно применять одно и то же событие без двойного списания, двойной почты или двойного обновления)?
Если вы ответили «нет» на воспроизведение, «один потребитель» и «короткоживущие сообщения», базовой очереди обычно хватает. Если вы ответили «да» на воспроизведение, несколько потребителей или длительный ретеншн, подход на основе журнала окупается, потому что превращает поток фактов в общий источник, на который можно опираться.
Следующие шаги
Преобразуйте ответы в небольшой тестируемый план.
- Составьте список из 5–10 ключевых событий простым языком (пример:
OrderPlaced, PaymentAuthorized, OrderShipped) и отметьте, кто публикует и кто потребляет каждое.
- Решите ключ упорядочивания (чаще по сущности, например
orderId) и документируйте, что значит «правильный порядок».
- Определите правило идемпотентности для каждого потребителя (например: хранить последний обработанный ID события на заказ).
- Выберите цель ретеншна, соответствующую вашим потребностям (дни для рабочих задач, недели/месяцы, когда важны воспроизведения).
- Прогоните один сквозной срез в песочнице, прежде чем фиксировать систему полностью.
Если вы прототипируете быстро, можно наметить поток событий в режиме планирования Koder.ai и итеративно дорабатывать дизайн до того, как закрепите имена событий и правила ретраев. Так как Koder.ai поддерживает экспорт исходников, снимки и откат, это практичный способ протестировать один producer‑consumer срез и подправить форму событий, не превращая ранние эксперименты в долгосрочный долг.