09 авг. 2025 г.·8 мин
Как абстракции фреймворков «протекают» при масштабировании систем
Узнайте, почему высокоуровневые фреймворки начинают «протекать» при масштабе: типичные паттерны утечек, симптомы, диагностика и практические исправления для дизайна и эксплуатации.
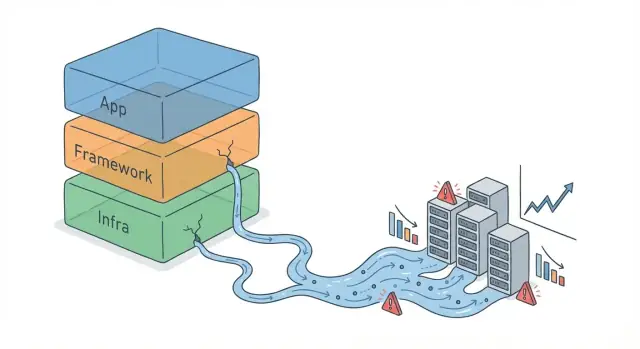
Что значит «утечки абстракций» при масштабе
Абстракция — это уровень упрощения: API фреймворка, ORM, клиент очереди сообщений или даже «однострочный» помощник кеша. Она позволяет мыслить в более высокоуровневых терминах («сохранить объект», «отправить событие»), не управляя постоянно низкоуровневыми деталями.
«Утечка абстракции» происходит, когда эти скрытые детали всё равно начинают влиять на реальные результаты — и вам приходится понимать и управлять тем, что абстракция пыталась скрыть. Код продолжает «работать», но упрощённая модель перестаёт предсказывать поведение.
Почему утечки остаются незаметными на старте
Ранний рост прощает многое. При низком трафике и небольших объёмах данных неэффективности прячутся за избыточным CPU, тёплыми кешами и быстрыми запросами. Пики задержек редки, повторы не накапливаются, и немного лишнего логирования не имеет значения.
Когда объём увеличивается, те же упрощения усиливаются:
- Больше запросов превращает мелкую накладную в постоянное узкое место.
- Большие таблицы делают «удобные» запросы дорогими.
- Больше сервисов повышает вероятность того, что таймауты, повторы и частичные отказы сложатся цепочкой.
Утечки — это не только про скорость
Утекающие абстракции проявляются обычно в трёх областях:
- Производительность: медленные запросы, исчерпание потоков, чрезмерная сериализация, неожиданные N+1 вызовы.
- Надёжность: штормы повторов, накопление в очередях, таймауты, запускающие каскадные отказы.
- Стоимость: растущие облачные счета из‑за многословных сервисов, избыточного логирования, неэффективного кеширования и лишнего трафика/хранения.
Чего ожидать в этом руководстве
Дальше мы сосредоточимся на практических сигналах утечки абстракции, как диагностировать первопричину (не только симптомы) и на вариантах смягчения — от конфигурационных правок до сознательного «опускания уровня», когда абстракция больше не соответствует вашему масштабу.
Почему при масштабе меняются правила
Многое ПО проходит одинаковую траекторию: прототип доказывает идею, продукт выпускается, затем использование растёт быстрее, чем исходная архитектура. Сначала фреймворки кажутся волшебными: их дефолты позволяют быстро двигаться — роутинг, доступ к БД, логирование, повторы и фоновые задачи «бесплатны».
При масштабе вы всё ещё хотите этих выгод — но дефолты и удобные API начинают вести себя как допущения.
Дефолты настроены под «обычную» нагрузку
Дефолты фреймворков обычно предполагают:
- умеренный размер данных
- стабильный трафик
- ограниченную конкуренцию
- предсказуемое время выполнения
Эти допущения работают вначале, поэтому абстракция кажется чистой. Но масштаб меняет понятие «обычно». Запрос, годный при 10 000 строк, становится медленным при 100 миллионах. Синхронный обработчик, казавшийся простым, начинает таймаутиться при всплесках трафика. Политика повторов, которая сглаживала редкие ошибки, может усилить сбои, когда тысячи клиентов повторяют одновременно.
Объём, всплески и конкуренция обнажают скрытые издержки
Масштаб — это не просто «больше пользователей». Это больший объём данных, бурстовый трафик и больше одновременной работы. Они давят на части, которые абстракции скрывают: пулы соединений, планирование потоков, глубина очередей, давление памяти, ограничения I/O и лимиты от внешних зависимостей.
Фреймворки часто выбирают безопасные, общие настройки (размеры пулов, таймауты, поведение батчинга). Под нагрузкой эти настройки могут превратиться в конкуренцию за ресурсы, длиннохвостовую латентность и каскадные отказы — проблемы, которые не были видны, когда всё помещалось в запас прочности.
Продакшн — это не staging с дополнительным трафиком
Staging редко зеркалит продакшн: меньшие наборы данных, меньше сервисов, другое поведение кешей и менее «грязная» пользовательская активность. В продакшне есть реальная сетевaя вариативность, шумные соседи, rolling deploy’ы и частичные отказы. Поэтому абстракции, казавшиеся идеальными в тестах, могут начать протекать под давлением реальных условий.
Типичные сигналы, что абстракция протекает
Когда абстракция фреймворка протекает, симптомы редко приходят в виде аккуратного сообщения об ошибке. Скорее вы видите паттерны: поведение, которое было нормальным при низком трафике, становится непредсказуемым или дорогим при большем объёме.
Типичные симптомы по производительности
Часто утечку выдаёт видимая пользователю латентность:
- Эндпоинты, которые замедляются нелинейно (p95/p99 взрываются, в то время как средние выглядят «нормально»)
- Таймауты, которые появляются только при пиковых нагрузках
- Накопление в очередях (фоновые задачи, потребители сообщений, пулы потоков), когда работы приходит больше, чем обрабатывается
- Внезапные потолки пропускной способности: вы добавляете инстансы, но RPS едва растёт
Это классические признаки того, что абстракция скрывает узкое место, которое не решить иначе, чем «опустившись на уровень ниже» (например, посмотрев реальные запросы, использование соединений или поведение I/O).
Симптомы по стоимости, похожие на «таинственные счета»
Некоторые утечки проявляются сначала в счётах, а не на дашбордах:
- Всплески CPU в БД или рост IOPS без очевидного релиза
- Трясение кеша: метрики попаданий/промахов скачут, увеличиваются вытеснения или доминируют горячие ключи
- Скачки egress‑трафика из‑за посредников/маршрутов, вызывающих межзонный/межрегиональный трафик
- Нужна больше нодов, чтобы держать ту же нагрузку, потому что накладные расходы растут с объёмом (сериализация, логирование, повторы)
Если масштабирование инфраструктуры не восстанавливает производительность пропорционально, часто дело не в сырой мощности, а в накладных расходах, о которых вы не догадывались.
Симптомы надёжности (самые опасные)
Утечки становятся проблемой надёжности, когда они взаимодействуют с повторами и цепочками зависимостей:
- Каскадные отказы: одна медленная зависимость вызывает таймауты выше по цепочке, что даёт нагрузку на другие части
- Повторы усиливают нагрузку: таймаут вызывает повторы, удваивая или утраивая давление на слабое звено
- Circuit breaker’ы и rate limit’ы «случайно» срабатывают из‑за роста вариативности латентности
- Инциденты, которые начинались как «чуть медленнее», заканчиваются частичным простоем
Быстрая проверка: утечка или недопредоставленность?
Используйте это, прежде чем покупать дополнительную ёмкость:
- Производительность улучшается линейно, когда вы удваиваете ресурсы? Если нет — подозревайте утечку.
- Растут ли p95/p99 и ошибки, в то время как CPU на апп‑серверах умеренный? Часто это узкое место внешней зависимости.
- Наблюдается ли несоразмерный рост БД/кеша/сети относительно объёма запросов? Вероятно, абстракция генерирует лишнюю работу.
- Коррелируют ли повторы/очереди с пиками? Это обычно утечка, взаимодействующая с обработкой ошибок.
Если симптомы сосредоточены в одной зависимой системе и не реагируют предсказуемо на «ещё серверов», это сильный индикатор, что нужно заглянуть под абстракцию.
Абстракции базы данных: ORM, запросы и скрытые издержки
ORM удобны для удаления болевого кода, но они заставляют забывать, что каждый объект в конечном счёте превращается в SQL. На малых объёмах этот компромисс незаметен. На больших данных БД часто становится первым местом, где «чистая» абстракция начинает взимать плату.
Внезапное появление N+1 запросов
N+1 происходит, когда вы загружаете список родительских записей (1 запрос), а затем в цикле загружаете связанные записи для каждого родителя (ещё N запросов). В локальных тестах это выглядит нормально — возможно, N = 20. В продакшне N превращается в 2000, и приложение тихо превращает один запрос в тысячи round‑trip’ов.
Сложность в том, что ничего «не ломается» сразу: латентность ползёт вверх, пулы соединений заполняются, повторы умножают нагрузку.
Перегрузка данных, отсутствующие индексы и дорогие join’ы
Абстракции часто по умолчанию предлагают доставать полные объекты, даже если нужны только два поля. Это увеличивает I/O, память и сетевой трафик.
В то же время ORM может сгенерировать запрос, который обходит индекс, который вы ожидали (или который вообще не существует). Один отсутствующий индекс может превратить селективный поиск в скан таблицы.
Join’ы — ещё одна скрытая цена: «включить связь» может вырасти в много‑join‑ную операцию с большими промежуточными результатами.
Пулы соединений и конкурентная борьба в транзакциях
Под нагрузкой соединения — дефицитный ресурс. Если каждый запрос раскрывается в несколько запросов к БД, пул быстро достигает лимита и приложение начинает ждать.
Длинные транзакции (иногда случайные) также вызывают конкуренцию: блокировки держатся дольше, и конкуренция коллапсирует.
Митигиры, которые лучше масштабируются
- Используйте жадную загрузку для известных связей, но делайте это осознанно: доставляйте только то, что нужно.
- Формируйте запросы: выбирайте конкретные колонки, добавляйте пагинацию и избегайте «загрузить всё».
- Батчьте операции, где возможно (bulk insert/update) — это снижает накладные расходы на строку.
- Для систем с преобладанием чтений вводите реплики чтения и направляйте безопасные запросы туда.
- Валидируйте SQL, генерируемый ORM, через
EXPLAIN, и рассматривайте индексы как часть дизайна приложения, а не как заботу DBA в последнюю очередь.
Модели конкуренции и обратное давление
Конкуренция — это место, где абстракции кажутся «безопасными» в разработке, а затем громко проваливаются под нагрузкой. Дефолтная модель фреймворка часто скрывает реальное ограничение: вы не просто обслуживаете запросы — вы управляете конкуренцией за CPU, потоки, сокеты и downstream‑возможности.
Thread‑per‑request vs async: разные формы отказа
Thread‑per‑request (распространено в классических веб‑стэках) простая модель: каждый запрос получает рабочий поток. Она ломается, когда медленный I/O (БД, API) заставляет потоки накапливаться. Как только пул потоков исчерпан, новые запросы становятся в очередь, латентность взлетает, и в конце концов вы получаете таймауты — при том, что сервер «занят» просто ожиданием.
Async/event‑loop модели обслуживают много одновременных запросов с меньшим числом потоков, поэтому они хорошо работают при высокой конкуренции. Они ломаются иначе: один блокирующий вызов (синхронная библиотека, медленный парсер JSON, тяжёлое логирование) может заблокировать цикл событий, превратив «один медленный запрос» в «всё медленно». Async также облегчает создание слишком большой конкуренции, переполняя зависимость быстрее, чем ограничения потоков.
Обратное давление: недостающий контракт
Backpressure — это механизм, позволяющий компоненту сказать вызывающим сторонам: «замедлитесь; я не могу безопасно принять больше». Без него медленная зависимость не просто замедляет ответы — она увеличивает число текущих запросов, использование памяти и длину очередей. Эта дополнительная работа делает зависимость ещё медленнее, создавая петлю обратной связи.
Таймауты и штормы повторов
Таймауты должны быть явными и многослойными: клиент, сервис и зависимость. Если таймауты слишком длинные, очереди растут и восстановление длится дольше. Если повторы автоматические и агрессивные, они могут порождать шторм повторов: зависимость тормозит, вызовы таймаутятся, клиенты повторяют, нагрузка умножается, и зависимость коллапсирует.
Митигиры, которые масштабируются
- Используйте bulkheads для изоляции ресурсов (отдельные пулы потоков/соединений на зависимость), чтобы одна медленная часть не съела всё.
- Добавьте circuit breaker для прекращения вызовов к падающей зависимости и дачи ей времени на восстановление.
- Реализуйте request shedding (быстрое отклонение с понятной ошибкой) при переполненных очередях — лучше отбросить часть трафика, чем сделать весь трафик непредсказуемо медленным.
Сеть и накладные расходы middleware
Экспериментируйте без риска
Пробуйте сырой SQL или изменения конфигурации безопасно с помощью снимков и быстрого отката.
Фреймворки делают сетевые вызовы похожими на «просто вызов эндпоинта». Под нагрузкой эта абстракция часто протекает через невидимую работу middleware‑слоёв, сериализации и обработки полезной нагрузки.
Налог на каждый хоп из‑за «простого» middleware
Каждый слой — API‑gateway, auth‑middleware, rate limiting, валидация запросов, хуки наблюдаемости, повторные попытки — добавляет немного времени. Дополнительная миллисекунда редко важна в разработке; при масштабе несколько middleware могут превратить 20 ms в 60–100 ms, особенно когда формируются очереди.
Ключ в том, что латентность не просто суммируется — она усиливается. Малые задержки увеличивают конкуренцию (больше одновременных запросов), что увеличивает конкуренцию за ресурсы, что снова увеличивает задержки.
Стоимость сериализации и сюрпризы с размером полезной нагрузки
JSON удобен, но кодирование/декодирование больших payload’ов может доминировать в CPU. Утечка проявляется как «сетевая» медлительность, которая на самом деле является потреблением CPU приложения, плюс дополнительная нагрузка на память из‑за буферов.
Большие payload’ы замедляют всё вокруг:
- больше времени в пути и больше копирования между буферами
- больше давления на GC в управляемых рантаймах
- более длинные tail‑латентности, когда несколько больших ответов блокируют общие ресурсы
Заголовки, сжатие и стриминг vs буферизация
Заголовки могут незаметно раздуть запросы (куки, токены аутентификации, заголовки трассировки). Это умножается по каждому хопу и каждому вызову.
Сжатие — компромисс. Оно экономит пропускную способность, но стоит CPU и может добавить задержку — особенно если сжатие делается для маленьких сообщений или несколько раз через прокси.
Наконец, стриминг vs буферизация важны. Многие фреймворки по умолчанию буферизуют тело запроса/ответа целиком (чтобы поддержать повторы, логирование или вычисление content‑length). Это удобно, но при высокой нагрузке увеличивает использование памяти и создаёт head‑of‑line блокинг. Стриминг помогает держать память предсказуемой и уменьшает time‑to‑first‑byte, но требует аккуратной обработки ошибок.
Практические mitigations
Рассматривайте размер полезной нагрузки и глубину middleware как бюджет, а не как после‑думье:
- Установите лимиты на payload и заголовки; принуждайте их через ограничения и варнинги.
- Предпочитайте пагинацию и частичные ответы вместо «вернуть всё».
- Стримьте большие загрузки/скачивания; избегайте логирования полных тел.
- Используйте бинарные форматы (например, Protobuf) там, где критичны латентность/CPU.
- Сжимайте выборочно (по порогам размера, в одном месте цепочки).
Когда масштаб обнажает сетевые накладные расходы, исправление часто меньше про «оптимизировать сеть» и больше про «перестать делать скрытую работу на каждом запросе».
Кеширование: когда «простое» решение порождает новые режимы отказа
Кеширование часто воспринимают как простой переключатель: добавить Redis (или CDN), ждать снижения латентности и двигаться дальше. При реальной нагрузке кеш — это абстракция, которая может сильно протечь — потому что она меняет где работа выполняется, когда она выполняется и как распространяются отказы.
Кеш — не бесплатный ускоритель
Кеш добавляет дополнительные сетевые хопы, сериализацию и операционную сложность. Он также вводит вторую «истину», которая может быть устаревшей, частично заполненной или недоступной. Когда что‑то идёт не так, система не просто медленнее — она может вести себя иначе (отдавать старые данные, усиливать повторы или перегружать БД).
Частые режимы отказа: stampede, ключи и инвалидизация
Cache stampede происходит, когда много запросов одновременно промахиваются и все рвутся воссоздать одно значение (часто после истечения TTL). При масштабе это превращает небольшой процент промахов в всплеск в БД.
Плохой дизайн ключей — ещё одна тихая проблема. Если ключи слишком широкие (например, user:feed без параметров), вы отдаёте неправильные данные. Если ключи слишком узкие (включают timestamp, случайные ID, неупорядоченные query params), у вас нулевая hit‑rate и вы платите за кеш без выгоды.
Инвалидизация — классическая ловушка: обновить БД легко; обеспечить, чтобы все связанные представления в кеше обновились — нет. Частичная инвалидизация ведёт к «у меня исправлено» багам и непоследовательному чтению.
Горячие ключи и неравномерный трафик
Реальный трафик неравномерен. Профиль знаменитости, популярный товар или общий endpoint конфигурации может стать горячим ключом, концентрирующим нагрузку на одной записи кеша и на её бэкенд‑сервисе. Даже если средняя производительность в порядке, tail‑латентность и нагрузка на ноду могут взорваться.
Практики, которые реально работают
- Используйте TTL с джиттером, чтобы истечения не сходились во времени.
- Добавьте single‑flight/request coalescing, чтобы только один запрос перестраивал значение, пока остальные ждут.
- Рассмотрите многоуровневые кеши (в‑процесс LRU + общий кеш), чтобы снизить сетевые накладные и защитить Redis.
- Применяйте rate limits и circuit breaker’ы вокруг путей при промахах кеша, чтобы инцидент кеша не стал инцидентом БД.
Память, GC и утечки ресурсов
Делайте это версионируемым
Сохраняйте артефакт диагностики как реальный код, экспортируя полный исходный код.
Фреймворки часто делают память «управляемой», что успокаивает — пока трафик не вырастет и латентность не начнёт скакать в несоответствии с графиками CPU. Многие дефолты настроены для удобства разработчика, а не для длительных процессов под sustained‑нагрузкой.
Как дефолты скрывают рост памяти и паузы GC
Фреймворки обычно аллоцируют короткоживущие объекты на запрос: обёртки request/response, контекст middleware, деревья JSON, временные строки и т. п. По‑одиночке они малы. На масштабе они создают постоянный поток аллокаций, заставляющий рантайм чаще запускать сборку мусора (GC).
Паузы GC могут проявляться как краткие, но частые всплески латентности. По мере роста кучи паузы часто становятся длиннее — не обязательно потому, что есть утечка, а потому что рантайму нужно больше времени на сканирование/компактацию памяти.
Паттерны аллокаций, большие кучи и фрагментация
Под нагрузкой объект может «пережить» несколько циклов GC (например, ожидая в очередях, буферах, пулах соединений или в полёте), что приводит к продвижению в старшую генерацию и раздутой куче.
Фрагментация — ещё одна скрытая цена: память может быть свободна, но неподходящего размера для новых аллокаций, и процесс просит ОС ещё памяти.
Утечка vs высокая, но стабильная память
Истинная утечка — это неограниченный рост: память растёт и не возвращается, в конце концов вызывая OOM‑киллы или экстремальный GC. Высокая, но стабильная — это когда память поднимается до плато после прогрева и держится примерно стабильно.
Митигиры, которые не вредят системе
Начинайте с профайлинга (heap snapshots, allocation flame graphs) чтобы найти горячие пути аллокаций и удерживаемые объекты.
Будьте осторожны с пуллингом: он может снизить аллокации, но плохо подобранный пул зафиксирует память и ухудшит фрагментацию. Сначала уменьшайте аллокации (стриминг вместо буферизации, избегать лишнего создания объектов, лимитировать per‑request кеши), затем добавляйте пулы там, где метрики явно показывают выигрыш.
Протекаемость наблюдаемости: логи, метрики и трейсы при высоком трафике
Инструменты наблюдаемости часто кажутся «бесплатными», потому что фреймворк даёт удобные дефолты: логи запросов, автоинструментированные метрики и одно‑строчный трейсинг. При реальном трафике эти дефолты становятся частью нагрузки, которую вы пытаетесь наблюдать.
Когда наблюдаемость становится узким местом
Логирование на запрос — классический пример. Одна строка на запрос кажется безвредной — пока не станет тысячи запросов в секунду. Тогда вы платите за форматирование строк, JSON‑кодирование, дисковые или сетевые записи и downstream‑ингест. Утечка проявляется как рост tail‑латентности, всплески CPU, отставание лог‑пайплайнов и иногда таймауты из‑за синхронной записи логов.
Метрики могут перегрузить систему более тихо. Счётчики и гистограммы дешёвы, пока у вас мало временных рядов. Но фреймворки часто поощряют добавлять теги/лейблы вроде user_id, email, path, order_id. Это ведёт к взрыву кардинальности: вместо одной метрики вы создаёте миллионы уникальных серий. Результат: раздутый клиент и бекенд, медленные запросы в дашбордах, потерянные сэмплы и неожиданные расходы.
Трейсинг: видимость с ценником
Распределённый трейсинг добавляет хранение и вычислительную нагрузку, растущую с трафиком и числом спанов на запрос. Если вы трассируете всё по‑умолчанию, вы платите дважды: в накладных приложении (создание спанов, пропагация контекста) и в бекенде трейсинга (ингест, индекс, хранение).
Сэмплинг — способ вернуть контроль, но его легко сделать неправильно. Чрезмерный сэмплинг скрывает редкие ошибки; слишком маленький — делает трейсинг дорогим. Практичный подход: больше сэмплов для ошибок и медленных запросов, меньше для быстрых успешных путей.
Если нужен базовый набор того, что собирать (и чего избегать), см. /blog/observability-basics.
Что делать, когда наблюдаемость протекает
Относитесь к наблюдаемости как к продакшн‑трафику: задавайте бюджеты (объём логов, число серий метрик, инжест трейсинга), ревьюйте теги на риск кардинальности и нагрузочно тестируйте с включённой инструментированностью. Цель — не «меньше наблюдаемости», а наблюдаемость, которая работает под давлением системы.
Распределённые системы: где «просто вызвать» превращается в связанность
Фреймворки часто делают вызов другого сервиса похожим на локальную функцию: userService.getUser(id) возвращает быстро, ошибки — «просто исключения», а повторные попытки кажутся безобидными. На малом масштабе эта иллюзия держит. На большом — абстракция протекает, потому что каждый «простой» вызов несёт скрытую связанность: латентность, лимиты по мощности, частичные отказы и рассинхронизацию версий.
Скрытая связанность между сервисами
Удалённый вызов связывает циклы релизов, модели данных и время доступности двух команд. Если Сервис A предполагает, что Сервис B всегда доступен и быстрый, поведение A уже определяется не его кодом, а худшим днём B. Так системы становятся жёстко связанными, даже если код выглядит модульным.
Транзакции, согласованность и идемпотентность
Распределённые транзакции — частая ловушка: то, что выглядело как «сохранить пользователя, затем списать оплату», становится многошаговым рабочим процессом между БД и сервисами. Two‑phase commit редко остаётся простым в продакшне, поэтому многие системы переходят к eventual consistency (например, «оплата будет подтверждена вскоре»). Это заставляет проектировать обработку повторов, дубликатов и событий вне порядка.
Идемпотентность становится критичной: если запрос повторяется из‑за таймаута, он не должен провести вторую оплату или вторую отправку. Помощники фреймворка для повторов могут усилить проблему, если конечные точки не безопасны для повторения.
Распространение сбоев
Одна медленная зависимость может исчерпать пулы потоков, пузыри соединений или очереди, создавая эффект домино: таймауты вызывают повторы, повторы повышают нагрузку, и скоро деградируют несвязанные эндпоинты. «Добавить инстансы» иногда усугубляет шторм, если все повторяют одновременно.
Смягчения, делающие связанность явной
Определяйте чёткие контракты (схемы, коды ошибок, версионирование), задавайте таймауты и бюджеты на вызов и реализуйте fallback’ы (кешированные чтения, деградированные ответы) там, где это уместно.
Наконец, ставьте SLO по зависимостям и соблюдайте их: если Сервис B не укладывается в своё SLO, Сервис A должен быстро падать или деградировать, а не тихо тянуть всю систему вниз.
Как диагностировать утечки без гаданий
Тестируйте сценарии отказа заранее
Прототипируйте изменения кэша, таймаутов и повторных попыток в виде изолированных веток для сравнения.
Когда абстракция протекает на масштабе, она часто проявляется как расплывчатый симптом (таймауты, всплески CPU, медленные запросы), который искушает команды преждевременно переписывать архитектуру. Лучший путь — превратить догадку в доказательство.
Практический пошаговый рабочий процесс
1) Воспроизведите (заставьте ломаться на запрос).
Зафиксируйте минимальный сценарий, который вызывает проблему: эндпоинт, фоновая задача или пользовательский поток. Воспроизведите локально или в staging с продакшн‑конфигурацией (флаги фич, таймауты, размеры пулов).
2) Измерьте (выберите 2–3 сигнала).
Выберите пару метрик, говорящих куда уходят время и ресурсы: p95/p99, ошибка, CPU, память, время GC, время запросов к БД, глубина очереди. Избегайте добавления десятков графиков прямо в инцидент.
3) Изолируйте (сузьте круг подозреваемых).
Используйте инструменты для разделения «накладные расходы фреймворка» и «ваш код»:
- Профайлеры (CPU, память, аллокации) чтобы найти горячие пути и хвосты аллокаций
- Трейсинг (OpenTelemetry, APM) чтобы увидеть время по хопам и глубину вызовов
- Планировщик запросов / EXPLAIN чтобы проверить SQL от ORM и использование индексов
- Нагрузочные тесты (k6, Gatling, Locust) чтобы воспроизвести под контролем
4) Подтвердите (докажите причинно‑следственную связь).
Меняйте по одному параметру: обойдите ORM для одного запроса, отключите middleware, уменьшите объём логов, ограничьте конкурентность или измените размеры пулов. Если симптом ведёт себя предсказуемо — вы нашли утечку.
Нагрузочное тестирование как в продакшн, а не как демо
Используйте реалистичные размеры данных (число строк, размеры payload’ов) и реалистичную конкуренцию (всплески, длинные хвосты, медленные клиенты). Многие утечки проявляются только когда кеши холодные, таблицы большие или повторы усиливают нагрузку.
Чек‑лист «до переписывания»
- Можете ли вы воспроизвести проблему нагрузочным тестом и собрать трейс?
- Есть ли снимок профайлера с топ‑потребителями?
- Проверяли ли вы худшие запросы планировщиком запросов?
- Проводили ли вы небольшое обратимое изменение, чтобы изолировать слой?
- Можете ли вы количественно измерить улучшение (p95/p99, затраты, ошибка) после фикса?
Стратегии смягчения и когда опускаться на уровень ниже
Утечки абстракций — не моральная ошибка фреймворка; это сигнал, что потребности системы переросли «дефолтный путь». Цель — не отказаться от фреймворков, а осознанно решать, когда их настраивать, а когда обходить.
Сначала настройте фреймворк (когда он всё ещё решает правильную задачу)
Оставайтесь в рамках фреймворка, когда проблема — конфигурация или использование, а не фундаментальное несоответствие. Хорошие кандидаты:
- медленный эндпоинт, который улучшается индексами, формированием запроса и настройкой пулов
- избыточное логирование, корректируемое сэмплингом и уровнями логов
- голодание потоков/воркеров, исправляющееся лимитами конкурентности и таймаутами
Если можно исправить настройками и guardrails — вы оставляете лёгкость обновлений и уменьшаете «специальные случаи».
Используйте escape‑hatches (когда нужна точность)
Большинство зрелых фреймворков дают способ выйти за абстракцию без переписывания всего. Распространённые паттерны:
- Escape hatches: сырой SQL для одного горячего запроса, прямые настройки HTTP‑клиента, кастомная сериализация для одного payload’а
- Тонкие адаптеры: небольшой слой вокруг компонента фреймворка, чтобы можно было потом подменить реализацию
- Граничные слои: держите фреймворк на периферии (роутинг, аутентификация), а ядро бизнес‑логики — за чётким интерфейсом
Так вы сохраняете фреймворк как инструмент, а не как фактор, диктующий архитектуру.
Операционные практики, чтобы «фиксы» не стали риском
Митигирование — это не только код:
- Планирование ёмкости: задавайте бюджеты (p95‑латентность, CPU, время БД) и отслеживайте их по релизам
- Канарейки и безопасные выкаты: выкатывайте на маленький срез, сравнивайте ошибки/латентность, затем расширяйте
- Нагрузочное тестирование, приближённое к реальности: включайте пики, повторы и замедления downstream
Для смежных практик выката см. /blog/canary-releases.
Простая рамка для решения
Опускайтесь на уровень ниже, когда (1) проблема посягает на критический путь, (2) вы можете измерить выигрыш, и (3) изменение не создаст долговременный налог поддержки, который команда не потянет. Если обход понимает только один человек, это не «фикс», а хрупкость.
Где вписывается Koder.ai (без добавления новых невидимых абстракций)
Когда вы охотитесь за утечками, важна скорость — но также и обратимость изменений. Команды часто используют Koder.ai, чтобы быстро поднимать маленькие, изолированные воспроизведения продакшн‑проблем (минимальный React UI, сервис на Go, схема PostgreSQL и хоре тестирования нагрузки) без дней на каркас.
Его режим планирования помогает документировать, что вы меняете и зачем, а снэпшоты и откат делают безопасным эксперимент «опуститься на уровень ниже» (например, заменить один ORM‑запрос сырым SQL) и затем вернуться, если данные не подтвердили выигрыш.
Если вы делаете эту работу с окружениями, встроенные деплой/хостинг и экспортируемый исходник Koder.ai помогают хранить артефакты диагностики (бенчмарки, repro‑приложения, внутренняя телеметрия) как реальное ПО — версионное, делимое и не зависящее от локальной машины.
FAQ
Что такое «утечка абстракции» на практике?
Утечка абстракции — это слой, который пытается скрыть сложность (ORM, помощники повторных попыток, обёртки кеша, middleware), но под нагрузкой скрытые детали начинают влиять на поведение системы.
На практике это значит, что ваша «простая ментальная модель» перестаёт предсказывать реальное поведение, и вам приходится разбираться в планах запросов, пулах соединений, глубине очередей, сборке мусора, таймаутах и повторных попытках.
Почему утечки абстракций остаются незаметными вначале?
Ранние системы имеют запас ресурсов: небольшие таблицы, низкая конкуренция, тёплые кеши и мало взаимодействий при сбоях.
По мере роста объёма даже небольшие накладные расходы превращаются в постоянные узкие места, а редкие граничные случаи (таймауты, частичные отказы) становятся нормой. Тогда и проявляются скрытые издержки абстракций в продакшне.
Какие самые распространённые признаки утечки абстракции?
Ищите паттерны, которые не улучшаются предсказуемо при добавлении ресурсов:
- p95/p99 латентности растут нелинейно, несмотря на нормальные средние значения
- таймауты возникают только при пиковом/бурстровом трафике
- очереди/заделы растут (фоновые задачи, потребители сообщений, пул потоков)
- потолки пропускной способности (добавление инстансов почти не увеличивает RPS)
- «таинственные» скачки затрат на БД/кеш/сеть без очевидных фич
Как отличить «утечку абстракции» от простого недопредоставления ресурсов?
Недодостаточность обычно улучшается примерно линейно при увеличении мощности.
Утечка проявляет себя так:
- генерируется дополнительная работа (N+1 запросы, многословные вызовы, тяжёлая сериализация/логирование)
- лимит создаёт один зависимый компонент (БД, кеш, внешний API)
- доминирует длиннохвостная латентность и очередь, даже когда CPU на приложениях умеренный
Если удвоение ресурсов не даёт пропорционального эффекта — подозревайте утечку.
Почему ORM становятся проблемой при масштабе и что делать в первую очередь?
ORM скрывает, что каждая операция с объектом становится SQL‑запросом. Частые утечки:
- N+1 (один запрос превращается в сотни/тысячи round‑trip)
- избыточный fetch целых строк/связей, когда нужны только поля
- отсутствующие/неиспользуемые индексы, приводящие к полным сканированиям
- неожиданные дорогие join’ы от «include relation»
Сначала пробуйте:
Какую роль играют пулы соединений и длительность транзакций в утечках?
Пулы соединений ограничивают параллелизм, чтобы защитить БД, но скрытая генерация запросов быстро исчерпывает пул.
Когда пул заполнен, запросы начинают очередиться в приложении — растёт латентность и удерживаются ресурсы дольше. Долгие транзакции усугубляют ситуацию, задерживая блокировки и снижая эффективную конкуренцию.
Практические исправления:
- уменьшить количество запросов на запрос (устранить N+1, батчинг)
- укоротить транзакции и избегать случайно долгих транзакций
- намеренно настраивать размеры пулов и мониторить время ожидания, а не только размер пула
Чем отличаются проявления утечек в моделях «поток на запрос» и async?
Thread‑per‑request ломается при медленном I/O: потоки накапливаются и всё очередится.
Async/event‑loop модели ломаются иначе:
- один блокирующий вызов может остановить цикл событий и сделать всё медленным
- легко создать чрезмерную конкуренцию и переполнить зависимости
В любом случае «фреймворк управляет конкурентностью» превращается в необходимость явных лимитов, таймаутов и обратного давления.
Что такое backpressure и почему он важен для предотвращения каскадов?
Обратное давление — это сигнал «замедлитесь», когда компонент не может безопасно принять больше работы.
Без него медленные зависимости увеличивают число параллельных запросов, потребление памяти и длину очередей — что делает зависимость ещё медленнее (петля обратной связи).
Инструменты:
- лимиты конкурентности на зависимость
- ограниченные очереди
- быстрое отклонение (fail fast)
- bulkheads (изоляция ресурсов), чтобы одна зависимость не съела всё
Почему повторы вызывают «retry storms» и как их избежать?
Автоматические повторы превращают замедление в сбойный шторм:
- зависимость замедляется → таймауты
- клиенты повторяют запросы → нагрузка умножается
- зависимость падает → ещё больше таймаутов → ещё повторов
Как избежать:
Как логирование/метрики/трейсинг становятся утечкой абстракции при масштабе?
Инструментация — это реальная нагрузка при высоком трафике:
- Логирование: форматирование + кодирование + запись + инжест могут съесть CPU и увеличить латентность
- Метрики: теги высокой кардинальности (
user_id,email,order_id) взрывают число временных рядов и ресурсы бекенда - Трейсинг: спаны и их инжест растут с трафиком и числом спанов на запрос
Контрмеры: