13 июл. 2025 г.·8 мин
Как бэкенд‑фреймворки формируют организацию кода и привычки команды
Узнайте, как бэкенд‑фреймворки влияют на структуру папок, границы ответственности, тестирование и рабочие процессы команды — чтобы команды могли выпускать фичи быстрее с единообразным и поддерживаемым кодом.
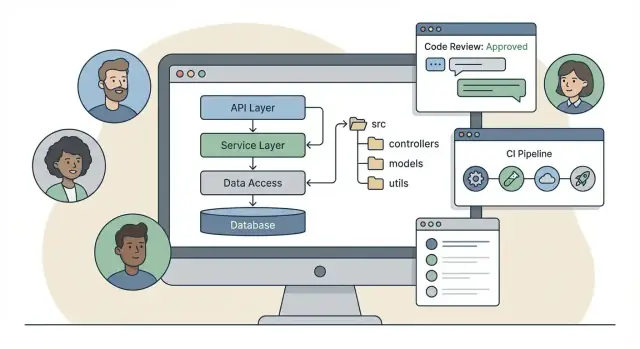
Почему бэкенд‑фреймворки важны не только как «выбор стека»
Бэкенд‑фреймворк — это не просто набор библиотек. Библиотеки помогают решить конкретные задачи (маршрутизация, валидация, ORM, логирование). Фреймворк добавляет опинионированный «способ работы»: стандартную структуру проекта, общие паттерны, встроенные инструменты и правила того, как части связаны между собой.
Фреймворки формируют повседневные решения
Когда фреймворк принят, он подсказывает сотни мелких решений:
- Куда помещать новый код (фичи, модули, сервисы)
- Как заявки проходят через приложение (контроллеры, middleware, хендлеры)
- Как вы решаете сквозные задачи: авторизация, валидация, обработка ошибок
- Как команды называют сущности, пишут тесты и проверяют pull‑request’ы
Именно поэтому две команды, которые строят «тот же API», могут получить очень разные кодовые базы — даже если у них одинаковый язык и база данных. Конвенции фреймворка становятся стандартным ответом на вопрос «как мы тут это делаем?».
Скорость и согласованность против гибкости
Фреймворки часто жертвуют гибкостью ради предсказуемой структуры. Плюсы: быстрее онбординг, меньше споров, повторное использование паттернов, снижающее случайную сложность. Минусы: конвенции фреймворка могут выглядеть ограничивающими, когда продукт требует нетипичных рабочих процессов, тонкой настройки производительности или нестандартной архитектуры.
Хорошее решение — не «фреймворк или нет», а вопрос «сколько конвенции нам нужно» и готовы ли вы платить цену кастомизации с течением времени.
Кому это важно
- Инженерам: меньше пересоздания паттернов, больше времени на фичи
- Тех‑лидам: понятные стандарты для архитектуры, тестирования и ревью
- Продуктовым командам: более предсказуемые сроки и меньше регрессий по мере роста кода
Дефолты фреймворка, которые определяют структуру проекта
Большинство команд не начинают с пустой папки — они стартуют с «рекомендуемой» раскладки фреймворка. Эти дефолты решают, куда люди кладут код, как они называют вещи и что считается «нормой» в ревью.
Два распространённых подхода по умолчанию
Некоторые фреймворки ориентированы на классическую слоистую структуру: controllers / services / models. Это просто для понимания и хорошо отображает обработку запросов:
/src
/controllers
/services
/models
/repositories
Другие фреймворки склоняются к feature‑модулям: группируют всё, что нужно для одной фичи (HTTP‑хендлеры, доменные правила, персистентность). Это облегчает локальное мышление — работая с «Billing», вы открываете одну папку:
/src
/modules
/billing
/http
/domain
/data
Ни один из подходов не является автоматически лучшим, но каждый формирует привычки. Слоистая структура облегчает централизацию сквозных стандартов (логирование, валидация, обработка ошибок). Модульный подход уменьшает "горизонтальную" навигацию по мере роста кода.
Скаффолдинги создают долговременные паттерны
CLI‑генераторы «липнут» к командам. Если генератор создаёт пару controller + service для каждого эндпойнта, люди будут продолжать так делать — даже когда проще обойтись функцией. Если он генерирует модуль с понятными границами, команда с большей вероятностью будет их соблюдать под давлением сроков.
Такая же динамика проявляется и в workflow с «vibe‑coding»: если дефолты платформы дают предсказуемую раскладку и чёткие швы модулей, команда обычно сохраняет когерентность кода по мере роста. Например, Koder.ai генерирует full‑stack приложения по чат‑промптам: помимо скорости, практический плюс в том, что команда может стандартизовать структуры и паттерны на раннем этапе — а затем итеративно их дорабатывать, как любой другой код (включая экспорт исходников при желании полного контроля).
Как избежать «толстых контроллеров»
Фреймворки, делающие контроллеры центральными, искушают складывать бизнес‑правила прямо в хендлеры. Полезное эмпирическое правило: контроллеры переводят HTTP → вызов приложения и больше ничего. Помещайте бизнес‑логику в слой сервисов/юзкейсов (или доменный слой модуля), чтобы её можно было тестировать без HTTP и переиспользовать в фоновых задачах или CLI.
Быстрая проверка структуры
Если вы не можете ответить на вопрос «Где хранится логика ценообразования?» одним предложением, дефолты фреймворка могут противоречить вашему домену. Исправьте это рано — папки легко менять; привычки — нет.
Поток запроса: маршрутизация, контроллеры и конвенции middleware
Бэкенд‑фреймворк определяет, как запрос должен проходить через код. Когда все следуют одному пути запроса, фичи доставляются быстрее, а ревью меньше зависят от стиля и больше от корректности.
Маршрутизация: публичная карта вашей системы
Маршруты должны читаться как оглавление API. Хорошие фреймворки побуждают к маршрутам, которые:
- Декларативны (можно просканировать и понять, что доступно)
- Согласованы (одинаковые шаблоны URL и HTTP‑глаголы по всему проекту)
- Близки к краю (в конфигурации маршрутов не должно быть бизнес‑правил)
Практическая конвенция: держать файлы маршрутов сфокусированными на маппинге: GET /orders/:id -> OrdersController.getById, а не «если пользователь VIP — сделай X».
Контроллеры/хендлеры: тонкие переводчики запросов
Контроллеры работают лучше всего как переводчики между HTTP и основной логикой:
- Читают входы (params, headers, body)
- Вызывают сервис/юзкейс
- Возвращают ответ
Когда фреймворк предоставляет хелперы для парсинга, валидации и форматирования ответов, командам хочется нагромождать логику в контроллерах. Здоровая модель — «тонкие контроллеры, толстые сервисы»: держите HTTP‑аспекты в контроллерах, а бизнес‑решения в отдельном слое, не знающем про HTTP.
Middleware/фильтры: одно место для сквозных задач
Middleware (или фильтры/перехватчики) определяет, куда размещать повторяющееся поведение: аутентификация, логирование, rate limiting, request IDs. Главное правило: middleware должно обогащать или защищать запрос, а не реализовывать продуктовые правила.
Например, auth‑middleware может прикреплять req.user, а контроллеры передавать эту идентичность в ядро логики. Логирующее middleware стандартизирует, что попадает в логи без того, чтобы каждый контроллер изобретал своё решение.
Именования, снижающие трение в ревью
Согласуйте предсказуемые имена:
OrdersController,OrdersService,CreateOrder(use‑case)authMiddleware,requestIdMiddlewarevalidateCreateOrder(схема/валидатор)
Когда имена кодируют намерение, ревью сосредотачиваются на поведении, а не на вопросе «куда это положить».
Слои и границы: где живёт бизнес‑логика
Фреймворк не только помогает доставлять эндпойнты — он толкает команду к определённой «форме» кода. Если вы не определите границы рано, дефолтная гравитация часто такова: контроллеры напрямую дергают ORM, ORM читает базу, а бизнес‑правила разбрасываются по коду.
Практичная слоистая архитектура
Простой и устойчивый разрез выглядит так:
- Presentation layer: HTTP‑аспекты (маршрутизация, контроллеры, auth middleware). Преобразует запросы в команды приложения и возвращает ответы.
- Application layer: Use‑cases (например,
CreateInvoice,CancelSubscription). Оркестрирует работу и транзакции, но минимально зависит от фреймворка. - Domain layer: Основные бизнес‑правила и концепции (сущности, политики, domain services). Должен читаться как бизнес, а не как SQL.
- Data layer: Репозитории, ORM‑модели/мапперы, запросы, миграции.
Фреймворки, которые генерируют «controller + service + repository», могут быть полезны — если относиться к этому как к направлению потока, а не как к требованию, что у каждой фичи должны быть все слои.
Как ORM и репозитории влияют на границы
ORM соблазняет передавать модели БД повсюду, потому что они удобны и частично валидированы. Репозитории помогают давать узкий интерфейс ("получить клиента по id", "сохранить счёт"), чтобы приложение и домен не зависели от деталей ORM.
Чтобы избежать дизайна «всё зависит от базы данных»:
- Не возвращайте ORM‑сущности напрямую из контроллеров.
- Держите форму запросов в data‑слое; правила — в домене.
- Предпочитайте доменно‑дружественные входы/выходы для юзкейсов.
Когда вводить слой сервисов (и когда нет)
Добавляйте слой application/service, когда логика переиспользуется между эндпойнтами, требует транзакций или должна последовательно применяться. Пропустите его для простого CRUD, где нет бизнес‑поведения — лишние слои создают церемонию без ясности.
Внедрение зависимостей и привычки модульного дизайна
DI — это дефолт фреймворка, который обучает всю команду. Когда он встроен, вы перестаёте создавать сервисы прямым new в случайных местах и начинаете рассматривать зависимости как вещи, которые объявляют, связывают и заменяют осознанно.
Что DI поощряет (и что может осложнять)
DI склоняет команду к малым, фокусированным компонентам: контроллер зависит от сервиса, сервис — от репозитория, и у каждой части есть понятная роль. Это улучшает тестируемость и упрощает замену реализаций (реальный платёжный шлюз vs мок).
Минус: DI может скрывать сложность. Если у каждого класса по пять зависимостей, становится трудно понять, что реально выполняется при обработке запроса. Неправильная конфигурация контейнера может дать ошибку далеко от кода, который вы меняли.
Инъекция через конструктор и интерфейсно‑ориентированный дизайн
Большинство фреймворков продвигает конструкторную инъекцию, потому что это делает зависимости явными и предотвращает anti‑pattern «service locator».
Полезная практика — сочетать конструкторную инъекцию с интерфейсами: код зависит от стабильного контракта (например, EmailSender), а не от конкретной реализации. Это локализует изменения при смене поставщика или рефакторинге.
Когерентные модули без циклических зависимостей
DI работает лучше, когда модули когерентны: модуль владеет одной функциональной областью (orders, billing, auth) и экспортирует небольшую публичную поверхность.
Циклические зависимости — частая проблема; они часто указывают на нечёткие границы: два модуля разделяют концепции, которые заслуживают выделения в отдельный модуль, либо один модуль делает слишком много.
Согласование места wiring‑а
Команде нужно договориться о том, где регистрируются зависимости: единый composition root (startup/bootstrap) плюс модульное связывание для внутренних вещей модуля.
Централизованное связывание упрощает ревью: проверяющий может увидеть новые зависимости, понять их обоснованность и избежать «разрастания контейнера», когда DI превращается из инструмента в загадку.
API‑контракты: валидация, ошибки и формы данных
Рефакторьте без страха
Экспериментируйте со структурой безопасно, используя снимки и откат при итерациях.
Бэкенд‑фреймворк влияет на представление «хорошего API» в вашей команде. Если валидация — первоклассная фичa (декораторы, схемы, пайпы, guards), люди проектируют эндпойнты вокруг четких входов и предсказуемых выходов — потому что сделать «правильно» проще, чем пропустить это.
Валидация формирует вид эндпойнтов
Когда валидация живёт на границе (до бизнес‑логики), команды начинают воспринимать полезность payload как контракт, а не как «что там клиент пришлёт». Это обычно ведёт к:
- Явному разграничению обязательных и опциональных полей
- Чётким правилам форматов (даты, ID, enum) и ограничениям (min/max, длина)
- Раннему отклонению некорректных запросов, чтобы сервисный код фокусировался на бизнес‑правилах
Также фреймворки поощряют общие конвенции: где определена валидация, как формируются ошибки, и разрешать ли неизвестные поля.
Централизованные ошибки дают предсказуемость клиентам
Фреймворки, поддерживающие глобальные фильтры/обработчики исключений, упрощают достижение согласованности. Вместо того чтобы каждый контроллер выдумывал ответы, можно стандартизировать:
- Форма ошибки (например,
code,message,details,traceId) - Соответствие HTTP‑статусов (валидация → 400, auth → 401/403, not found → 404)
- Логирование и корреляционные id, чтобы быстро отлаживать проблемные запросы
Единая форма ошибок снижает ветвление логики на фронтенде и делает документацию API более надёжной.
DTO и view‑модели защищают внутренности
Многие фреймворки подталкивают к использованию DTO (вход) и view‑моделей (выход). Это полезно: предотвращает случайную утечку внутренних полей, избегает привязки клиентов к схеме БД и делает рефакторинг безопаснее. Практическое правило: контроллеры говорят на DTO; сервисы — на доменных моделях.
Версионирование и основы обратной совместимости
Даже маленькие API эволюционируют. Конвенции маршрутизации часто определяют, будет ли версионирование в URL (/v1/...) или в заголовках. Какой бы метод вы ни выбрали, задайте базовые правила рано: не удаляйте поля без окна депрекации, добавляйте поля обратно‑совместимо и документируйте изменения в одном месте (например, /docs или /changelog).
Стратегия тестирования под влиянием инструментов фреймворка
Фреймворк диктует не только то, как вы доставляете фичи, но и как вы их тестируете. Встроенный раннер тестов, утилиты для бутстрапа и контейнер DI часто определяют, что легко — а значит, что команда действительно делает.
Хелперы фреймворка: unit vs integration vs end‑to‑end
Многие фреймворки дают «тестовый апп»‑бутстраппер, который поднимает контейнер, регистрирует маршруты и позволяет выполнять запросы в памяти. Это склоняет команды к integration‑тестам — они всего на пару строк длиннее unit‑теста.
Практический разрез:
- Unit‑тесты для чистой бизнес‑логики (без фреймворка и БД).
- Integration‑тесты для модулей/сервисов, связанных через контейнер DI.
- End‑to‑end для реального HTTP‑поведения (маршрутизация, middleware, auth, маппинг ошибок).
Тестовая пирамида для бэкенд‑сервисов
Для большинства сервисов важнее скорость, чем идеальная «пирамидная» структура. Практическое правило: много быстрых unit‑тестов, фокусированные integration‑тесты вокруг границ (БД, очереди) и тонкий E2E‑слой, который подтверждает контракт.
Если фреймворк делает симуляцию запросов дешёвой, можно чуть больше полагаться на integration‑тесты, но при этом изолируйте доменную логику, чтобы unit‑тесты оставались стабильными.
Мокинг в духе DI и рантайма
Стратегия мокирования должна соответствовать тому, как фреймворк резолвит зависимости:
- Предпочитайте переопределение DI‑биндингов (подменить реальный email‑клиент на фейк), а не monkey‑patch импортов.
- Используйте in‑memory адаптеры где возможно (например, in‑memory репозитории), чтобы избежать хрупких заглушек.
- Моке́йте на границах модулей, а не внутри бизнес‑логики, чтобы рефакторинг не ломал тесты.
Быстрые и надёжные тесты для CI
Время поднятия фреймворка может доминировать в CI. Держите тесты быстрыми: кешируйте дорогостоящую настройку, выполняйте миграции один раз за тест‑сьют и используйте параллелизацию там, где гарантирована изоляция. Для удобства диагностики — детерминированные сиды, строгие хуки очистки и фиксированные часы лучше, чем «повторить при ошибке».
Масштабирование кодовой базы: модули, пакеты и общий код
Сделайте API предсказуемыми
Генерируйте эндпоинты с единообразной валидацией и обработкой ошибок, затем настраивайте контракт.
Фреймворки формируют не только первый API — они влияют на то, как код растёт, когда «один сервис» превращается в десятки фич, команд и интеграций. Механики модулей и пакетов, которые фреймворк делает простыми, обычно становятся вашей долгосрочной архитектурой.
Паттерны модульности, которые поощряют фреймворки
Большинство фреймворков подталкивают к модульности: приложения, плагины, blueprints, модули фич, пакеты. Когда это дефолт, команды склонны добавлять возможности как «ещё один модуль», а не разбрасывать файлы по проекту.
Практическое правило: относитесь к каждому модулю как к мини‑продукту с собственной публичной поверхностью (маршруты/хендлеры, интерфейсы сервисов), приватными внутренностями и тестами. Если фреймворк поддерживает авто‑обнаружение (module scanning), используйте это осторожно — явные импорты часто делают зависимости проще для понимания.
Core‑domain vs инфраструктурные модули
По мере роста смешивать бизнес‑правила с адаптерами становится дорого. Полезное разделение:
- Core domain modules: бизнес‑правила, политики, domain services и модели (то, что должно пережить смену БД)
- Infrastructure modules: клиенты БД, ORM‑модели, брокеры сообщений, HTTP‑клиенты, кэши, провайдеры аутентификации
Конвенции фреймворка влияют на это: если фреймворк поощряет «service‑классы», помещайте domain‑сервисы в core‑модули, а framework‑специфную привязку (контроллеры, middleware, провайдеры) — по краям.
Shared libs vs копипаст: правила принятия решения
Команды часто рано начинают делиться кодом. Предпочитайте копирование маленького кода, пока он не стабилен, и выносите в общую библиотеку, когда:
- две или более команды поддерживают одинаковую логику
- баг фикс нужно вносить во многих местах
- вы можете определить чёткий API и версионировать его
При выносе публикуйте внутренние пакеты (или workspace‑библиотеки) с ясной ответственностью и дисциплиной changelog'ов.
Подготовка к переходу от модульного монолита к микросервисам
Модульный монолит часто — лучший «средний масштаб». Если у модулей чёткие границы и минимум перекрёстных импортов, позже вы сможете выделить модуль в сервис с меньшим количеством изменений. Дизайн модулей вокруг бизнес‑способностей, а не технических слоёв. Для глубокой стратегии см. /blog/modular-monolith.
Конфигурация, окружения и готовность к эксплуатации
Модель конфигурации фреймворка определяет, насколько последовательны ваши деплои. Если конфиг разбросан по ad‑hoc файлам, случайным env‑переменным и «вот в этой константе», команды будут дебажить различия вместо того, чтобы разворачивать фичи.
Стиль конфигурации = согласованность
Большинство фреймворков подталкивают к единому источнику истины: файлы конфигурации, переменные окружения или кодовая конфигурация (модули/плагины). Какой бы путь вы ни выбрали, стандартизируйте его рано:
- Файлы удобны для локальной разработки и явных дефолтов (
config/default.yml). - Environment variables удобны для отличий в момент деплоя и контейнерных платформ.
- Кодовая конфигурация мощная, но легко спрятать важные настройки за логикой.
Хорошая конвенция: дефолты хранятся в versioned config‑файлах, env‑переменные переопределяют их для окружений, и код читает из одного типизированного config‑объекта. Так во время инцидента ясно, где менять значение.
Секреты: отдельная категория
Фреймворки часто предоставляют помощники для чтения env, интеграции со secret‑store или валидации конфига на старте. Используйте эти инструменты, чтобы усложнить обращение с секретами:
- Никогда не коммитьте секреты в репозиторий (включая «временные» ключи)
- Не выводите секреты в логи и страницы ошибок
- Предпочитайте runtime‑внедрение (CI/CD, оркестратор контейнеров, secret manager) вместо локальных
.env
Операционная привычка: разработчики запускают локально с безопасными заглушками, а реальные креды́ншелы живут только в окружении, где они нужны.
Паритет окружений: dev, staging, production
Дефолты фреймворка могут либо поощрять паритет (один и тот же процесс старта везде), либо создают спец‑кейсы («в продакшене другой entrypoint»). Стремитесь к одному стартовому команде и единой схеме конфигурации во всех окружениях, меняя только значения.
Staging — это репетиция: те же feature‑флаги, тот же путь миграций, те же фоновые задачи — только в меньшем масштабе.
Документируйте конфиг как API
Если конфигурация не документирована, коллеги будут выдумывать значения — и догадки превратятся в инциденты. Держите краткое, поддерживаемое руководство в репозитории (например, /docs/configuration) с перечислением:
- каждого ключа конфигурации и что он контролирует
- ожидаемого типа/формата (string, URL, integer)
- дефолтного значения и безопасных примеров
- окружений, где он должен быть задан
Многие фреймворки умеют валидировать конфиг на старте. Сочетайте это с документацией — и «работает у меня» перестанет быть частым оправданием.
Стандарты наблюдаемости, заданные фреймворком
Фреймворк задаёт базу того, как вы понимаете систему в продакшне. Когда наблюдаемость встроена (или сильно поощряется), команды перестают относиться к логам и метрикам как к «потом» и начинают проектировать их как часть API.
Логирование, трассировка и метрики — что вы получаете «из коробки»
Многие фреймворки интегрируются с привычными инструментами структурированного логирования, распределённой трассировки и сбора метрик. Это формирует организацию кода: сквозные задачи централизуются (logging middleware, tracing interceptors, metrics collectors) вместо того, чтобы разработчики раскидывали print‑вызовы по контроллерам.
Хороший стандарт — определить небольшой набор обязательных полей для логов, связанных с запросом:
correlation_id(илиrequest_id) для связи логов между сервисамиrouteиmethodдля понимания задействованного эндпойнтаuser_idилиaccount_id(когда доступно) для расследованийduration_msиstatus_codeдля метрик производительности и надёжности
Конвенции фреймворка (контекст запроса или pipeline middleware) упрощают генерацию и передачу correlation IDs, чтобы разработчики не придумывали шаблоны для каждой фичи.
Health checks и readiness‑эндпоинты
Дефолты фреймворка часто определяют, являются ли health checks штатной частью приложения или отложенной задачей. Стандартные эндпоинты — /health (liveness) и /ready (readiness) — становятся частью "definition of done" и помогают держать операционные требования вне случайного кода фичи:
- liveness: «процесс жив?»
- readiness: «может ли сервис обслуживать трафик?» (напр., подключение к БД, применённые миграции)
Когда такие эндпоинты стандартизированы, операционные требования перестают протекать в произвольный код фич.
Используйте наблюдаемость, чтобы направлять рефакторинг
Данные наблюдаемости — инструмент принятия решений. Если трейс показывает, что один и тот же зависимый компонент занимает большую часть времени в эндпойнте — сигнал к выделению модуля, кешированию или переработке запроса. Если логи выявляют несогласованную форму ошибок — повод централизовать обработчик ошибок. Иными словами: hooks наблюдаемости фреймворка не только для дебага — они помогают перестраивать кодовую базу с уверенностью.
Командные рабочие процессы: конвенции, tooling и ревью кода
Создавайте и зарабатывайте кредиты
Получайте кредиты, делясь своими проектами на Koder.ai или приглашая других опробовать Koder.ai.
Фреймворк не только организует код — он задаёт «домашние правила» работы команды. Когда все следуют одним конвенциям (размещение файлов, именование, где и как связываются зависимости), ревью ускоряются, а онбординг упрощается.
Генерация кода и скаффолды: пользуйтесь, но не поклоняйтесь
Скаффолдинги стандартизируют каркасы эндпойнтов, модулей и тестов за минуты. Опасность — позволить генераторам диктовать модель домена.
Используйте скаффолды для согласованных оболочек, затем сразу редактируйте результат, чтобы он соответствовал архитектурным правилам. Политика: генераторы допустимы, но итоговый код должен выглядеть как продуманная реализация, а не дамп шаблона.
Если вы используете AI‑ассистированные рабочие потоки, сохраняйте ту же дисциплину: рассматривайте сгенерированный код как заготовку. На платформах вроде Koder.ai можно быстро итератировать через чат и при этом поддерживать командные конвенции (границы модулей, DI‑паттерны, формы ошибок) через ревью — потому что скорость полезна, только если структура остаётся предсказуемой.
Style guide в духе фреймворка
Фреймворки часто подразумевают идиоматичные практики: где живёт валидация, как поднимаются ошибки, как именуются сервисы. Зафиксируйте ожидаемое в коротком командном style guide:
- Naming‑конвенции, совпадающие с примитивами фреймворка (например, Controller, Service, Module)
- Границы папок (что разрешено в контроллере vs в домене/сервисе)
- Примеры «хорошего» эндпойнта
Держите руководство лёгким и практичным; добавьте ссылку на него в /contributing.
Линтеры, форматирование и pre‑commit хуки
Сделайте стандарты автоматическими. Настройте форматтеры и линтеры в соответствии с конвенциями фреймворка (импорты, декораторы/аннотации, async‑паттерны). Принудите их через pre‑commit хуки и CI, чтобы ревью фокусировались на дизайне, а не на пробелах и наименованиях.
PR‑шаблоны и чек‑листы, связанные с архитектурой
Чек‑лист, основанный на конвенциях фреймворка, предотвращает медленное дрейфование в сторону несогласованности. Добавьте в PR‑шаблон вопросы для ревьюеров:
- Новые эндпойнты соответствуют routing/controller конвенциям?
- Валидация и ответы на ошибки соответствуют стандарту команды?
- Сохранены границы зависимостей (нет прямых вызовов БД из контроллеров)?
- Тесты следуют рекомендованным паттернам фреймворка?
Со временем эти мелкие «охранители рабочего процесса» сохраняют кодовую базу управляемой при росте команды.
Как выбирать и эволюционировать фреймворк без болезненных переписок
Выбор фреймворка часто закрепляет паттерны — раскладку директорий, стиль контроллеров, DI и даже то, как пишут тесты. Цель не в том, чтобы найти совершенный фреймворк, а выбрать тот, который соответствует тому, как ваша команда доставляет ПО, и при этом оставить возможность изменений, когда потребности меняются.
Оценка соответствия размеру и целям команды
Начните с ограничений доставки, а не списка фич. Малой команде обычно полезны жёсткие конвенции, «батарейки‑включены» и быстрый онбординг. Большим командам нужны ясные границы модулей, стабильные точки расширения и паттерны, препятствующие скрытой связности.
Задавайте практичные вопросы:
- Можете ли вы поддерживать согласованную структуру с минимальным вмешательством в ревью?
- Делает ли фреймворк простым правильное (валидация, обработка ошибок, логирование), или каждая команда придумывает своё?
- Прогнозируемы ли апгрейды (чёткие changelog‑и, пути депрекации), и зрел ли экосистема для ваших нужд?
Красные флаги, предвещающие переписывание
Перепись часто — результат игнорирования мелких болей. Следите за:
- Нечёткими границами: бизнес‑логика утекает в контроллеры, middleware или ORM‑модели
- Медленными тестами: integration‑тесты, которые занимают минуты, и команды их пропускают
- Хрупкими апгрейдами: частые breaking‑changes, зависимость от внутренних API или общепринятые обходные решения
Инкрементальные рефакторинг‑паттерны, которые не тормозят доставку
Вы можете эволюционировать, не останавливая фичи, вводя швы:
- Strangler: направляйте небольшой набор эндпойнтов в новый модуль, оставляя старую систему работающей
- Adapter‑слои: оборачивайте framework‑примитивы за своими интерфейсами (контекст запроса, логгер, репозитории)
- "Ports and adapters": выносите доменную логику в plain‑модули с минимальными импортами фреймворка, затем оборачивайте их по краю
Чек‑лист для принятия и следующие шаги
Перед окончательным решением (или перед крупным апгрейдом) проведите небольшой эксперимент:
- Постройте один реальный эндпойнт end‑to‑end: auth, валидация, ответы об ошибках и логирование.
- Напишите два теста: один быстрый unit для домена, один integration для HTTP‑слоя.
- Смоделируйте изменение: добавьте поле, версионируйте ответ и отрефакторьте модуль.
- Просмотрите заметки по последнему мажору — нанесло бы это вам вред?
Если нужно структурированное сравнение вариантов, подготовьте лёгкое RFC и положите его в репозиторий (например, /docs/decisions), чтобы будущие команды понимали, почему вы сделали выбор и как безопасно его менять.
Ещё одна перспектива: если команда экспериментирует с ускорением циклов сборки (включая чат‑управляемую разработку), проверьте, сохраняет ли рабочий процесс те же архитектурные артефакты — чёткие модули, исполняемые контракты и оперируемые дефолты. Лучшие ускорения (CLI‑фреймворка или платформ вроде Koder.ai) сокращают время цикла без размывания конвенций, которые делают бэкенд поддерживаемым.
FAQ
В чём практическая разница между бэкенд‑фреймворком и набором библиотек?
Бэкенд‑фреймворк задаёт опинионированный способ построения приложения: стандартную структуру проекта, конвенции для жизненного цикла запроса (маршрутизация → middleware → контроллеры/хендлеры), встроенные инструменты и «одобренные» паттерны. Библиотеки обычно решают отдельные задачи (маршрутизация, валидация, ORM), но не навязывают, как эти части должны интегрироваться в рамках команды.
Как фреймворки влияют на повседневные инженерные решения?
Конвенции фреймворка становятся стандартным ответом на повседневные вопросы: где размещать код, как проходит поток запроса, как формируются ошибки и как связываются зависимости. Такая согласованность ускоряет онбординг и уменьшает споры в ревью, но одновременно создаёт «лок‑ин» к определённым паттернам, которые потом бывает дорого менять.
Как организовать код: по слоям (controllers/services/models) или по feature‑модулям?
Выбирайте слоистую структуру, если нужна чёткая разделённость технических обязанностей и удобная централизация сквозных задач (аутентификация, валидация, логирование).
Выбирайте feature‑модули, если хотите, чтобы команды работали локально в рамках бизнес‑функции (например, Billing) без постоянного перехода по папкам.
Вне зависимости от выбора документируйте правила и контролируйте их в ревью, чтобы структура оставалась понятной по мере роста кодовой базы.
CLI‑генераторы/скелетоны полезны или вредны в долгосрочной перспективе?
Используйте генераторы, чтобы быстро создавать согласованные заготовки (маршруты/контроллеры, DTO, шаблоны тестов), но рассматривайте их как стартовую точку — а не как итоговую архитектуру.
Если scaffold всегда создаёт controller+service+repo для всего подряд, это может добавлять ненужную формальность. Периодически пересматривайте шаблоны и обновляйте их под реальные практики команды.
Как избежать «толстых контроллеров» в API на основе фреймворка?
Держите контроллеры сфокусированными на переводе HTTP:
- Парсинг входных данных (params/body/headers)
- Валидация на границе
- Вызов сервиса/юзкейса
- Формирование ответа
Переносите бизнес‑логику в слой приложений/домена, чтобы её можно было переиспользовать (в фоновых задачах, CLI) и тестировать без запуска веб‑стека.
Что принадлежит middleware/фильтрам, а что — сервисам/юзкэйсам?
Middleware должно обогащать или защищать запрос, но не реализовывать продуктовые правила.
Подходящие обязанности для middleware:
- Аутентификация/авторизация
- Установка requestId/correlationId
- Структурированное логирование
- Ограничение скорости (rate limiting)
- Парсинг/нормализация входных данных
Принятие бизнес‑решений (ценообразование, eligibility, ветвление рабочего процесса) оставляйте в сервисах/юзкейзах, где их проще тестировать и переиспользовать.
Как внедрение зависимостей (DI) меняет дизайн и сопровождение?
DI повышает тестируемость и упрощает замену реализаций (например, платёжный провайдер на заглушку) за счёт явного определения зависимостей.
Держите DI понятным:
- Используйте конструкторную инъекцию
- Регистрируйте зависимости в одном месте — composition root
- Избегайте чрезмерно глубоких графов зависимостей
Если появляются циклические зависимости, как правило, это сигнал о нечётких границах, а не «проблема DI».
Как лучше организовать валидацию, DTO и консистентные ответы об ошибках?
Относитесь к запросам/ответам как к контрактам:
- Валидируйте входные данные до запуска бизнес‑логики
- Стандартизируйте форму ошибок (например,
code,message,details,traceId) - Последовательно картируйте типичные ошибки на HTTP‑статусы (400/401/403/404)
Используйте DTO/вью‑модели, чтобы не случайно не выдать внутренние поля/ORM‑модели и чтобы клиенты не зависели напрямую от схемы БД.
Как наша стратегия тестирования должна адаптироваться под конвенции фреймворка?
Пусть инструменты фреймворка подсказывают, что просто поддерживать, но сохраняйте осознанный разрез:
- Unit‑тесты для доменной логики (без запуска фреймворка и БД)
- Integration‑тесты для модулей/DI и границ с персистентностью
- Небольшой слой E2E, чтобы проверить маршрутизацию/middleware/маппинг ошибок
Предпочитайте замену DI‑биндингов или in‑memory‑адаптеры вместо хрупкой monkey‑patching‑логики. Для CI оптимизируйте время поднимая окружение один раз на набор тестов и минимизируя дорогостоящие операции.
Какие признаки того, что выбор фреймворка приведёт к переписыванию, и как эволюционировать безопасно?
Сигналы риска переписывания:
- Бизнес‑логика расползается по контроллерам/моделям ORM
- Тесты медленные или нестабильные, команды начинают их пропускать
- Обновления фреймворка частые и ломают ожидания
Снижайте риск постепенно: оборачивайте примитивы фреймворка вашими интерфейсами (логгер, контекст запроса, репозитории), держите домен в «plain»‑модулях с минимумом импортов фреймворка, и выполняйте инкрементальные миграции (strangler, адаптеры) вместо «большого взрыва».