От идеи до приложения: что на самом деле значит «перевод»
Идея продукта, выраженная простыми словами, обычно начинается как смесь намерения и надежды: для кого это, какую проблему решает и что считать успехом. Это может быть пара предложений («приложение для назначения выгулов собак»), примерный сценарий («клиент запрашивает → выгульщик принимает → оплата») и пара обязательных функций («push‑уведомления, рейтинги»). Этого достаточно, чтобы обсудить идею — но недостаточно, чтобы последовательно построить продукт.
Когда говорят, что LLM может «перевести» идею в приложение, полезный смысл таков: превратить размытые цели в конкретные, проверяемые решения. «Перевод» — это не просто перефразирование, это добавление структуры, чтобы вы могли просмотреть, поставить под сомнение и внедрить результаты.
Что модель может сгенерировать (быстро)
LLM хорошо справляются с созданием первого черновика основных блоков:
- Роли пользователей и ключевые сценарии (напр., клиент, исполнитель, админ)
- Списки функций и критерии приёма («пользователь может сбросить пароль по e‑mail»)
- Инвентарь экранов и UI‑потоки для web и mobile
- Рекомендуемая архитектура (фронтенды, бэкенд‑сервисы, интеграции)
- Модели данных (таблицы/коллекции, связи)
- Наброски API (эндпоинты, формы запрос/ответ)
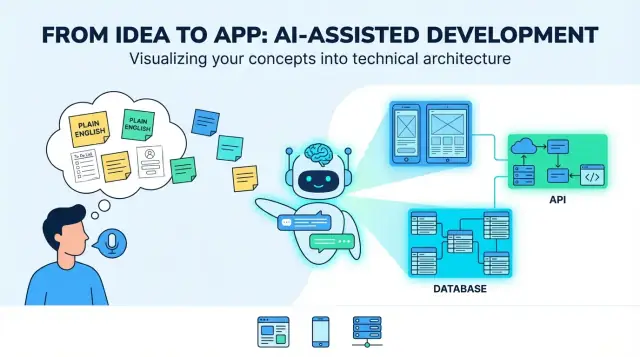
Типичный «конечный результат» выглядит как чертёж полноценного продукта: веб‑интерфейс (часто для админов), мобильный интерфейс (для пользователей в пути), бэкенд‑сервисы (аутентификация, бизнес‑логика, уведомления) и хранилище данных (БД и файловое хранилище).
Какие решения всё ещё за людьми
LLM не всегда может надёжно выбирать компромиссы, потому что правильные ответы зависят от контекста, который вы, возможно, не указали:
- Что считать «успехом» и какие метрики важны?\n- Какие ограничения существуют (бюджет, сроки, соответствие, уже используемые инструменты)?\n- Какие крайние случаи вам важны (а какие можно отложить)?\n- Какой самый простой вариант, который всё ещё понравится пользователям?
Рассматривайте модель как систему, предлагающую варианты и значения по‑умолчанию, а не как окончательную истину.
Ключевые риски
Наиболее распространённые ошибки предсказуемы:
- Неоднозначность: «быстро», «безопасно», «удобно» нельзя реализовать без чётких определений.\n- Пропущенные крайние случаи: отмены, повторы, оффлайн‑режим, возвраты, дубликаты, злоупотребления.\n- Чрезмерная уверенность: выводы могут звучать уверенно, даже если предположения шатки.
Настоящая цель «перевода» — сделать предположения видимыми, чтобы вы могли подтвердить, пересмотреть или отвергнуть их до того, как они закрепятся в коде.
Шаг 1: Уточните бриф продукта
Прежде чем LLM сможет превратить «Сделай приложение для X» в экраны, API и модели данных, нужен продуктовый бриф, достаточный для проектирования. Этот шаг — о превращении расплывчатого намерения в общую цель.
Начните с проблемы и того, как измерять успех
Запишите формулировку проблемы в одно‑два предложения: кто испытывает трудности, с чем именно и почему это важно. Затем добавьте метрики успеха, которые можно наблюдать.
Например: «Сократить время, которое требуется клинике для назначения повторного приёма». Метрики: среднее время на назначение, процент неявок, доля пациентов, записавшихся самостоятельно.
Определите целевых пользователей и основные сценарии
Перечислите основные типы пользователей (не всех, кто может касаться системы). Для каждого укажите основную задачу и короткий сценарий.
Полезный шаблон подсказки: «Как [роль], я хочу [сделать что‑то], чтобы [получить выгоду]». Стремитесь к 3–7 ключевым сценариям, описывающим MVP.
Раннее фиксирование ограничений (они формируют всё)
Ограничения — это разница между чистым прототипом и продуктом, готовым к релизу. Укажите:
- Платформы: web, iOS, Android (и оффлайн‑требования)\n- Таймлайн и бюджет: какие компромиссы допустимы\n- Соответствие/конфиденциальность: HIPAA, GDPR, хранение данных, журналы аудита\n- Интеграции: платежи, календари, SSO, CRM, почта/SMS‑провайдеры
Определите «готово»: MVP vs позже
Будьте конкретны, что входит в первый релиз, а что откладывается. Простое правило: функции MVP должны поддерживать основные сценарии end‑to‑end без ручных обходных путей.
Если хотите, оформите это как одностраничный бриф и держите его как «источник правды» для следующих шагов (требования, UI‑потоки и архитектура).
Шаг 2: Преобразуйте простую речь в требования
Идея на простом языке обычно содержит цели («помочь людям записываться на занятия»), предположения («пользователи будут входить в систему») и расплывчатую область («сделать просто»). LLM полезен тем, что может превратить такой ввод в требования, которые вы проверите, исправите и утвердите.
Превратите утверждения в пользовательские истории
Перепишите каждое предложение как user story. Это вынуждает уточнить, кто хочет что и почему:
- Как новый пользователь, я хочу зарегистрироваться по e‑mail или через Google, чтобы начать быстро.\n- Как вернувшийся пользователь, я хочу видеть мои предстоящие брони, чтобы планировать неделю.
Если история не указывает роль или выгоду, она, вероятно, всё ещё слишком расплывчата.
Сформируйте список функций и приоритеты
Сгруппируйте истории по функциям и отметьте каждую как must‑have или nice‑to‑have. Это помогает избежать расширения объёма работ до начала дизайна и разработки.
Например: «push‑уведомления» могут быть nice‑to‑have, а «отменить бронь» обычно — must‑have.
Напишите критерии приёма, которые модель сможет проверить
Добавьте простые, проверяемые правила под каждой историей. Хорошие критерии приёма конкретны и наблюдаемы:
- При вводе неверного e‑mail, при отправке формы появляется inline‑ошибка и аккаунт не создаётся.\n- Если я отменяю в пределах 24 часов, при подтверждении отмены моё место освобождается и приходит подтверждение.
Ранний список крайних случаев
LLM часто по‑умолчанию выдаёт «happy path», поэтому явно запросите крайние случаи, такие как:
- Оффлайн или плохая сеть (очередование действий, повторные попытки)\n- Неверные вводы (пустые поля, неподдерживаемые типы файлов)\n- Отмены и двойные отправки (идемпотентность, подтверждения)
Этот набор требований становится «источником правды», по которому вы будете оценивать дальнейшие выводы (UI‑потоки, API и тесты).
Шаг 3: Проектируйте UI‑потоки для веба и мобильных
Идея становится пригодной к реализации, когда она превращается в пользовательские сценарии и экраны, соединённые понятной навигацией. На этом этапе не выбирают цвета — определяют, что пользователи могут делать, в каком порядке и что считать успехом.
Смапьте ключевые пользовательские пути
Начните с путей, которые имеют наибольшее значение. Для многих продуктов структура выглядит так:
- Онбординг: создание аккаунта, подтверждение e‑mail/телефона, первичная настройка\n- Основная задача: главная работа приложения (создать, искать, бронировать, отслеживать, делиться)\n- Платежи: просмотр тарифов, оформление, квитанции, управление подпиской\n- Поддержка: FAQ, форма обратной связи, сообщение о проблеме\n- Настройки: профиль, уведомления, приватность, выход, удаление аккаунта
Модель может набросать эти потоки пошагово. Ваша задача — подтвердить, что обязательно, что опционально и где пользователь может безопасно выйти и вернуться.
Сгенерируйте список экранов (web + mobile) с навигацией
Попросите два артефакта: инвентарь экранов и карту навигации.
- Web обычно предпочитает левое сайдбар/верхнюю навигацию с большим количеством видимых опций.\n- Mobile чаще использует вкладки и стек экранов с меньшим количеством опций на экране.
Хороший результат даёт согласованность в наименованиях экранов (например, «Order Details» vs «Order Detail»), определяет точки входа и содержит состояния пустых списков (нет результатов, нет сохранённых элементов).
Формы и правила валидации
Преобразуйте требования в поля форм с правилами: обязателен/опционален, форматы, лимиты и дружелюбные сообщения об ошибках. Пример: правила для пароля, формат адреса оплаты или «дата должна быть в будущем». Убедитесь, что валидация есть и inline (по мере ввода), и при отправке.
Базовые требования доступности
Включите читаемые размеры текста, достаточный контраст, полную поддержку клавиатуры на вебе и сообщения об ошибках, которые объясняют, как исправить проблему (а не просто «Неверный ввод»). У каждого поля должна быть метка, а порядок фокуса — логичный.
Шаг 4: Предложите архитектуру приложения
Архитектура — это план приложения: какие части существуют, за что каждая отвечает и как они общаются. Когда LLM предлагает архитектуру, ваша задача — убедиться, что она достаточно проста для реализации сейчас и достаточно ясна для развития в будущем.
Начните с дефолтного варианта: монолит или модульный?
Для большинства новых продуктов правильный старт — единый бэкенд (монолит): один код‑репозиторий, один деплой, одна БД. Быстрее строить, проще отлаживать и дешевле эксплуатировать.
Часто оптимальным является модульный монолит: всё ещё один деплой, но код организован по модулям (Auth, Billing, Projects и т.д.) с чёткими границами. Разделение на сервисы откладывают до реальной нагрузки: большая посещаемость, команда, требующая независимых деплоев, или часть системы с иным масштабированием.
Если модель предлагает «микросервисы», попросите её аргументировать этот выбор конкретными потребностями, а не гипотетическими причинами.
Назовите основные компоненты (и держите их простыми)
Хороший план архитектуры перечисляет базовые элементы:
- Auth & user management: регистрация/вход, роли, сессии/токены.\n- Слой бизнес‑логики: правила продукта (ценообразование, утверждения, лимиты).\n- Доступ к данным: чтение/запись в БД.\n- Фоновые задачи: долгие задачи (импорты, отчёты, планировщик).\n- Уведомления: e‑mail/push/in‑app, шаблоны и предпочтения.
Модель также должна указать, где живёт каждая часть (бэкенд vs мобильный/веб) и как клиенты взаимодействуют с бэкендом (обычно REST или GraphQL).
Явно обозначьте предположения по стеку технологий
Архитектура остаётся неясной, если не зафиксировать базовые вещи: фреймворк бэкенда, БД, хостинг и подход к мобильной части (нативная или кросс‑платформа). Попросите модель оформить это как «Предположения», чтобы все понимали, против чего проектируются решения.
Планируйте масштаб без overengineering
Вместо больших переработок предпочитайте небольшие «аварийные выходы»: кэширование, очередь для фоновых задач и статeless‑серверы, чтобы можно было добавить инстансы. Лучшие архитектурные предложения объясняют эти опции, сохраняя v1 простым.
Шаг 5: Смоделируйте данные
Идея продукта полна существительных: «пользователи», «проекты», «задачи», «платежи», «сообщения». Моделирование данных — это шаг, где LLM превращает эти сущности в общее представление того, что нужно хранить и как всё связано.
Превратите имена сущностей в объекты и связи
Начните с перечисления ключевых сущностей и задайте вопрос: что чему принадлежит?
Например:
- User создаёт много Projects\n- Project содержит много Tasks\n- Task может иметь много Comments
Затем определите связи и ограничения: может ли задача существовать без проекта, можно ли редактировать комментарии, можно ли архивировать проекты и что происходит с задачами при удалении проекта.
Набросайте таблицы/коллекции и поля, которые важны
Далее модель предлагает первичный скелет схемы (SQL‑таблицы или NoSQL‑коллекции). Держите модель простой и сфокусированной на принятиях решений, влияющих на поведение.
Типичный пример:
- users: id, email, name, password_hash/identity_provider_id, created_at\n- projects: id, owner_user_id, name, status, created_at\n- project_members: project_id, user_id, role\n- tasks: id, project_id, title, description, status, due_date, assignee_user_id
Важно: фиксируйте поля статуса, временные метки и уникальные ограничения (например, уникальный e‑mail). Эти детали определяют фильтры UI, уведомления и отчётность.
Владение, разрешения и мульти‑тенантность
Реальные приложения нуждаются в ясных правилах доступа. LLM должен сделать владение явным (owner_user_id) и промоделировать доступ (членства/роли). Для мульти‑тенантных продуктов введите сущность tenant/organization и привяжите tenant_id к тем записям, которые нужно изолировать.
Также определите, как применяются права доступа: по ролям (admin/member/viewer), по владению или их комбинации.
Удаление, хранение и аудиторские логи
Наконец, решите, что нужно логировать и что удалять. Примеры:
- События аудита: «task created», «permission changed», «export performed»\n- Правила хранения: удалять персональные данные по запросу, хранить счета X лет\n- Soft delete vs hard delete: можно ли восстановить записи или удалить навсегда
Эти решения предотвращают неприятные сюрпризы при требованиях соответствия, поддержке или вопросах по биллингу.
Шаг 6: Сгенерируйте бэкенд‑API
API — это место, где обещания приложения становятся реальными действиями: «сохранить профиль», «показать мои заказы», «поиск объявлений». Хороший вывод начинается с действий пользователя и превращает их в небольшой набор понятных эндпоинтов.
Начинайте с действий пользователя → CRUD + поиск
Перечислите основные элементы взаимодействия (Projects, Tasks, Messages). Для каждого определите, что пользователь может делать:
- Create: добавить новый объект\n- Read: получить один объект или список\n- Update: изменить поля\n- Delete: удалить/деактивировать\n- Search/filter: найти по ключевым словам, статусу, дате и т.д.
Обычно это отражается в эндпоинтах вида:
POST /api/v1/tasks (create)\n- GET /api/v1/tasks?status=open&q=invoice (list/search)\n- GET /api/v1/tasks/{taskId} (read)\n- PATCH /api/v1/tasks/{taskId} (update)\n- DELETE /api/v1/tasks/{taskId} (delete)
Примеры запросов/ответов (plain language + JSON)
Создать задачу: пользователь отправляет title и due date.
POST /api/v1/tasks
{
"title": "Send invoice",
"dueDate": "2026-01-15"
}
Ответ возвращает сохранённую запись (включая поля, сгенерированные сервером):
201 Created
{
"id": "tsk_123",
"title": "Send invoice",
"dueDate": "2026-01-15",
"status": "open",
"createdAt": "2025-12-26T10:00:00Z"
}
(Обратите внимание: блоки кода выше не переводятся — это примеры запросов/ответов.)
Обработка ошибок, с которой мобильные приложения смогут жить
Попросите модель производить согласованные ошибки:
- 400 — ошибки валидации (с сообщениями по полям)\n- 401/403 — проблемы с аутентификацией/правами\n- 404 — не найдено\n- 409 — конфликт (дубликат, устаревшее обновление)\n- 429 — слишком много запросов (укажите, когда повторить)\n- 500 — непредвиденная ошибка (общая подсказка + request id)
Для повторных попыток используйте idempotency keys в POST и дайте ясные рекомендации вроде «retry after 5 seconds».
Версионирование и обратная совместимость
Мобильные клиенты обновляются медленно. Используйте версионированный базовый путь (/api/v1/...) и избегайте ломающих изменений:
- Добавляйте новые поля опционально, вместо переименования/удаления\n- Держите старые поля в течение окна депрекации\n- Документируйте изменения в коротком changelog‑эндпоинте (например,
GET /api/version)
Шаг 7: Безопасность и приватность по‑умолчанию
Безопасность — не задача «потом». Когда LLM превращает идею в спецификации, вы хотите, чтобы безопасные настройки были явными — чтобы первая версия не оказалась случайно уязвимой.
Аутентификация: как пользователи доказывают личность
Попросите модель рекомендовать основной метод входа и резервный, а также что происходит при проблемах доступа (потеря доступа, подозрительная активность). Распространённые варианты:
- E‑mail + пароль (универсально, но нужно обрабатывать сброс пароля, требования к надёжности и утечки)\n- Магические ссылки / коды одноразовые (меньше риска с паролями, но нужна надёжная доставка почты и короткий срок действия токена)\n- Социальный вход (быстрая регистрация, но зависимость от сторон и правила связывания аккаунтов)
Уточните политику сессий (короткоживущие access‑токены, refresh‑токены, выход на всех устройствах) и поддерживается ли MFA.
Авторизация: что пользователям можно делать
Аутентификация идентифицирует пользователя; авторизация ограничивает доступ. Побуждайте модель выбрать один понятный подход:
- Роли (Admin, Member, Viewer) — для простых приложений\n- Права (напр.,
project:edit, invoice:export) — для гибкости\n- Доступ на уровне объектов (критично): пользователи видят/меняют только то, что им принадлежит или чем с ними поделились
Хороший вывод включает примерные правила: «Только владелец проекта может удалить проект; соучастники могут редактировать; зрители — комментировать».
Контрольные меры по безопасности, которые важны в плане
Пусть модель перечислит конкретные меры, а не общие обещания:
- Валидация и санитизация входа на каждом эндпоинте (не доверяйте клиенту)\n- Ограничение скорости для логина, OTP/магических ссылок и тяжёлых эндпоинтов\n- Хранение секретов: не держите API‑ключи в коде, вращайте креденшалы, не логируйте токены
Также запросите чек‑лист угроз: CSRF/XSS, безопасные cookie, безопасная обработка загрузок файлов.
Приватность: собирать меньше, объяснять больше
По умолчанию собирайте минимально необходимый объём данных: только то, что реально нужно, и только на нужный срок.
Попросите LLM набросать текст простым языком для:
- Какие данные вы собираете и зачем\n- Как долго вы их храните\n- Как пользователь может удалить или экспортировать данные
Если вы добавляете аналитику — обеспечьте отказ от трекинга (opt‑out) или явное согласие, где требуется, и задокументируйте это в настройках и политике конфиденциальности.
Шаг 8: Стратегия тестирования, которую модель может сгенерировать
Хорошая LLM может превратить ваши требования в план тестирования, который окажется полезным — если вы привяжете всё к критериям приёма, а не к общим «должно работать».
Сопоставьте тесты с критериями приёма
Начните с передачи модели списка функций и критериев приёма, затем попросите её сгенерировать тесты по каждому критерию. Солидный вывод включает:
- Unit‑тесты для бизнес‑правил (например, расчёт цен, валидация, проверки прав)\n- Интеграционные тесты для поведения API + БД (например, создание заказа сохраняет нужные строки)\n- E2E‑тесты для критических пользовательских сценариев (регистрация → онбординг → выполнение первой задачи)
Если тест не ссылается на конкретный критерий — скорее всего, это лишнее.
Тестовые данные и фикстуры, приближённые к реальным сценариям
LLM может также предложить фикстуры, отражающие реальные случаи: «грязные» имена, недостающие поля, часовые пояса, длинный текст, ненадёжные сети и «почти дубликаты».
Попросите:
- Набор seed‑данных (малый, средний) с крайними случаями\n- Переиспользуемые фабрики/фикстуры для пользователей, ролей и общих объектов\n- «Golden path» набор данных, используемый в E2E для согласованности
Мобильные проверки, которые часто забывают
Добавьте отдельный мобильный чек‑лист:
- Оффлайн‑режим (чтение vs очередь на запись, разрешение конфликтов)\n- Бэкграундинг/фронтграундинг (восстановление состояния, незаконченные запросы)\n- Диалоги разрешений (камера, локация, уведомления) и потоки отказа
Генерация тестов LLM и их проверка
LLM хороши в создании каркасов тестов, но проверьте:
- Утверждения: проверяют ли они результат, а не детали реализации?\n- Покрытие: включены ли негативные сценарии (401/403, 422, таймауты)?\n- Риски флаки: ожидания по времени, сетевые зависимости, нестабильные селекторы
Рассматривайте модель как быстрого автора тестов, но не как окончательное QA‑утверждение.
Шаг 9: Деплой, релизы и мониторинг
Модель может сгенерировать много кода, но пользователи получают выгоду только тогда, когда это безопасно запущено и вы видите, что происходит после релиза. Этот шаг — про повторяемые релизы: одни и те же шаги каждый раз, с минимальными сюрпризами.
Основы CI (что автоматизировать)
Настройте простой CI, который выполняется на каждом pull request и при слиянии в main:
- Linting/formatting чтобы ловить стиль и простые ошибки\n- Автотесты (unit + небольшой набор E2E «happy path»)\n- Шаги сборки для каждой поверхности:\n - Сборка веб‑приложения\n - Сборка мобильных приложений (Android/iOS)\n - Сборка/пакетирование бэкенда
Даже если код сгенерирован LLM, CI покажет, работает ли он после изменения.
Окружения: dev, staging, production
Используйте три окружения с разными целями:
- Dev: быстрая итерация, локальные базы, расширенный лог\n- Staging: среда, близкая к продакшену, для финальной верификации\n- Production: реальные пользователи, строгий доступ, минимум шумных логов
Конфигурация должна управляться через переменные окружения и секреты (не в коде). Правило: если изменение требует правки кода — это, вероятно, неправильная конфигурация.
План деплоя
Для типичного full‑stack приложения:
- Хостинг бэкенда: деплой контейнера или managed‑сервиса + проверка состояния\n- Миграции БД: версионные миграции, запуск во время деплоя и по возможности обратимые изменения\n- Релизы мобильных приложений: сначала внутренние сборки (TestFlight / internal testing), затем staged rollout в App Store/Play Store
Мониторинг и рабочий процесс для инцидентов
Планируйте три сигнала:
- Логи (что происходило), метрики (как часто) и алармы (что требует внимания)\n- Простое правило on‑call: алармы должны быть действенными, а не шумными\n- Путь для пользователей сообщить об ошибках (ссылка в приложении или /support), с триажем по severity, шагам воспроизведения и плану отката
Здесь AI‑помощь в разработке становится операционной: вы не просто генерируете код — вы запускаете продукт.
Где LLM ошибаются (и как это исправить)
LLM может превратить расплывчатую идею в нечто, что похоже на полноценный план — но отшлифованный текст может скрывать пробелы. Наиболее частые ошибки предсказуемы, и их можно предотвратить привычками.
Почему проваливаются подсказки
Слабые выводы обычно связаны с четырьмя проблемами:
- Отсутствие контекста: модель не знает ваших пользователей, ограничений (бюджет, сроки, навыки команды), требований соответствия или того, что уже есть.\n- Противоречивые требования: «сделать просто» и «поддерживать все крайние случаи» даёт расплывчатую спецификацию.\n- Скрытые предположения: модель может предполагать email/password, WebSockets для «реального времени» или что «админ» имеет полный доступ.\n- Неозначенные приоритеты: без trade‑offs (скорость vs стоимость vs качество) вы получите общие ответы, которые не подходят под вашу ситуацию.
Как просить более точные выводы
Дайте модели конкретику:
- Примеры: «Как Calendly, но для выездных услуг» + 2–3 примерные user stories\n- Ограничения: «Должно использовать Postgres, деплой на AWS и поддерживать 10k MAU»\n- Требуйте явной аргументации: попросите перечислить предположения, открытые вопросы и альтернативы: «Покажи работу: решения + почему».
Добавьте «Definition of Done», чтобы снизить переработки
Попросите чек‑листы по результату. Например: требования считаются готовыми, если в них есть критерии приёма, состояния ошибок, роли/права и измеримые метрики успеха.
Держите единый источник правды
Выводы LLM рассыпаются, когда спецификации, заметки по API и идеи UI живут в разных местах. Поддерживайте один живой документ (простой markdown), где связаны:
- продуктовая спецификация,\n- контракт API (эндпоинты + схемы),\n- заметки по дизайну (ключевые потоки и крайние случаи).
При повторном промптинге вставляйте актуальный фрагмент и говорите: “Обнови только разделы X и Y; остальное не менять.”
Если вы внедряете по ходу, полезно использовать рабочий процесс с возможностью быстрого отката и снимков. Например, Koder.ai в режиме «planning mode» позволяет зафиксировать спецификацию (предположения, открытые вопросы, критерии приёма), сгенерировать каркасы web/mobile/backend из одной нити чата и полагаться на снапшоты/откат при регрессиях. Экспорт исходников полезен, чтобы архитектура и репозиторий оставались согласованными.
Практический пример и точки проверки человеком
Вот как может выглядеть «перевод» LLM от начала до конца — и где человек должен замедлиться и принять решения.
Короткий пример: идея → экраны, данные, API
Идея: «Маркетплейс сиделок для животных: владельцы публикуют запросы, сиделки откликаются, оплата удерживается до завершения работы.»
LLM может превратить это в черновик:
- Экраны: Регистрация/вход, Создать запрос, Детали запроса (с откликами), Откликнуться, Чат в приложении, Оформление, Завершение работы, Рейтинги/Отзывы, Админ (споры).\n- Модель данных: Users (role: owner/sitter), PetProfiles, Requests (даты, локация, статус), Applications, Messages, Payments, Reviews.\n- API:
POST /requests, GET /requests/{id}, POST /requests/{id}/apply, GET /requests/{id}/applications, POST /messages, POST /checkout/session, POST /jobs/{id}/complete, POST /reviews.
Это полезно — но ещё не «готово». Это структурированное предложение, требующее валидации.
Где люди проверяют (и почему это важно)
Продуктовые решения: что делает «валидным» отклик? Может ли владелец пригласить сиделку напрямую? Когда запрос считается «закрытым»? Эти правила влияют на экраны и API.
Безопасность и приватность: подтвердите RBAC (владельцы не читают чужие чаты), защиту платежей и правила хранения данных (удалить чат через X месяцев). Добавьте меры против злоупотреблений: rate limiting, спам‑фильтры, аудит‑логи.
Торговля производительностью: решите, что должно быть быстро (поиск/фильтр запросов, чат). Это влияет на кэш, пагинацию, индексы и фоновые задачи.
Итеративный цикл: обратная связь → требования → код
После пилота пользователи могут попросить «повторить запрос» или «отменить с частичным возвратом». Вносите это в обновлённые требования, регенерируйте или патчьте затронутые потоки, затем прогоняйте тесты и проверки безопасности.
Что документировать для поддержки в будущем
Фиксируйте «почему», а не только «что»: ключевые бизнес‑правила, матрицу прав, контракты API, коды ошибок, миграции БД и короткий runbook для релизов и инцидентов. Это поможет понять сгенерированный код через 6 месяцев.