10 авг. 2025 г.·8 мин
Как LLM справляются с бизнес‑правилами и логикой рабочих процессов
Узнайте, как LLM интерпретируют бизнес‑правила, отслеживают состояние рабочих процессов и проверяют решения с помощью подсказок, инструментов, тестов и участия людей — а не только кода.
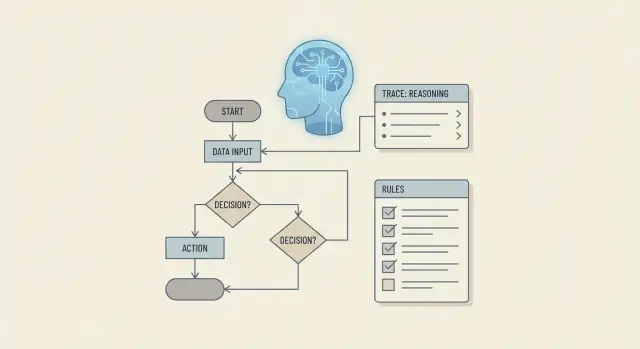
Почему рассуждение о бизнес‑правилах — это больше, чем генерация кода
Когда спрашивают, может ли LLM «размышлять о бизнес‑правилах», обычно имеют в виду нечто более требовательное, чем «может ли оно написать if/else». Рассуждение о правилах — это способность последовательно применять политики, объяснять решения, обрабатывать исключения и оставаться в соответствии с текущим шагом рабочего процесса — особенно когда входные данные неполные, грязные или меняются.
Рассуждение vs. генерация кода
Генерация кода в основном про создание корректного синтаксиса в целевом языке. Рассуждение о правилах — про сохранение намерения.
Модель может сгенерировать совершенно корректный код, который всё равно приведёт к неверному бизнес‑результату, потому что:
- Текст политики неоднозначен ("недавний клиент", "высокий риск", "одобренные документы").
- Правила конфликтуют, и приоритет неясен.
- Краевые случаи не описаны (частичные возвраты, дубли, выходные/праздники).
- Состояние рабочего процесса меняет то, что должно происходить дальше (приём → проверка → окончательное утверждение).
Иными словами, корректность — это не «собирается ли код?», а «соответствует ли это тому, что компания бы решила, всегда, и можем ли мы это доказать?».
Что ожидать от LLM
LLM помогают переводить политики в структурированные правила, предлагать варианты принятия решений и готовить объяснения для людей. Но они не знают автоматически, какое правило имеет приоритет, какой источник данных доверенный или на каком шаге находится дело. Без ограничений они могут уверенно выбрать правдоподобный вариант вместо управляемого.
Поэтому цель — не «позволить модели решать», а дать ей структуру и проверки, чтобы она могла надёжно помогать.
Что будет дальше в этом посте
Практический подход выглядит как конвейер:
- Преобразовать текст политики в пригодные для использования представления правил.
- Отслеживать состояние рабочего процесса, чтобы решения оставались согласованными между шагами.
- Использовать шаблоны подсказок для принудительного соблюдения приоритетов, исключений и объяснений.
- Подкреплять решения инструментами и вытаскиванием данных (только из утверждённых источников).
- Ограничивать выводы схемами, чтобы снизить неоднозначность.
- Валидировать, тестировать и мониторить, чтобы ошибки ловились до релиза.
Вот разница между умной строкой кода и системой, которая поддерживает реальные бизнес‑решения.
Бизнес‑правила и рабочие процессы: краткое объяснение простым языком
Прежде чем говорить о том, как LLM «размышляют», полезно разделить то, что команды часто смешивают: бизнес‑правила и рабочие процессы.
Что такое бизнес‑правила?
Бизнес‑правила — это утверждения о принятии решений, которые организация хочет обеспечивать последовательно. Они появляются в виде политик и логики, например:
- Право на участие: кто имеет право на льготу, тариф или функцию?
- Ценообразование: какая скидка применяется и когда?
- Утверждения: когда требуется проверка менеджера?
- Соответствие: что должно быть залогировано, скрыто или заблокировано?
Правила обычно формулируются как «ЕСЛИ X, ТО Y» (иногда с исключениями) и должны давать очевидный исход: одобрить/отказать, цена A/цена B, запросить доп. информацию и т. п.
Что такое рабочие процессы?
Рабочий процесс — это процесс, который перемещает задачу от начала до конца. Он меньше про решение что разрешено, и больше про что происходит дальше. Рабочие процессы часто включают:
- Состояния: отправлено → на проверке → одобрено/отклонено → завершено
- Шаги и передачи: служба поддержки → финансы → клиент
- События по времени: напоминания, SLA, авто‑отмена через 14 дней
- Артефакты: формы, вложения, коды причин, аудиторские заметки
Небольшой пример: запросы на возврат
Представьте запрос на возврат.
Фрагмент правила: "Возвраты разрешены в течение 30 дней с покупки. Исключение: цифровые загрузки не подлежат возврату после доступа. Исключение: chargeback’и должны эскалироваться."
Фрагмент рабочего процесса:
- Клиент отправляет запрос (состояние: submitted).
- Система проверяет дату покупки и тип товара (состояние: under review).
- Если право есть — выполнить возврат и уведомить клиента (состояние: completed).
- Если chargeback — направить в финансы для расследования (состояние: escalated).
Почему правила сложнее, чем кажутся
Правила усложняются, когда они конфликтуют ("VIP‑клиенты всегда получают возврат" vs. "цифровые загрузки никогда"), зависят от недостающего контекста (была ли загрузка открыта?), или скрывают краевые случаи (пакеты, частичные возвраты, региональные законы). Рабочие процессы добавляют ещё один уровень: решения должны быть согласованы с текущим состоянием, предыдущими действиями и дедлайнами.
Как LLM «размышляют»: сопоставление шаблонов с полезной структурой
LLM не «понимают» бизнес‑правила так, как человек. Они генерируют следующие наиболее вероятные слова на основе паттернов, выученных из большого объёма текста. Поэтому LLM может звучать убедительно даже когда угадывает — или тихо подставляет недостающие детали.
Это ограничение важно для рабочих процессов и логики принятия решений. Модель может применить правило, которое звучит правильно ("сотрудникам всегда нужна подпись менеджера"), хотя настоящая политика имеет исключения ("только свыше $500" или "только для подрядчиков"). Это распространённая ошибка: уверенное, но неверное применение правила.
Почему они всё ещё полезны для бизнес‑правил
Даже без истинного «понимания» LLM полезны, если рассматривать их как структурированного помощника:
- Резюмировать длинные политики в понятную форму для ревью
- Картографировать неструктурированный текст в согласованные поля (кто, что, порог, исключение, дата вступления)
- Проверять предложенное решение по заявленным правилам ("какой пункт это поддерживает?")
Ключ — поставить модель в положение, где ей сложно уйти в импровизацию.
Ограничьте модель, чтобы она не сбилась с пути
Практический способ снизить неоднозначность — ограниченный вывод: требовать ответа в фиксированной схеме или шаблоне (например, JSON с определёнными полями или таблицу с обязательными колонками). Когда модель должна заполнить rule_id, conditions, exceptions и decision, становится проще заметить пробелы и автоматически валидировать результат.
Ограниченные форматы также помогают увидеть, когда модель чего‑то не знает. Если обязательное поле пусто, можно вызвать уточняющий вопрос вместо того, чтобы принимать ненадёжный ответ.
Вывод: «рассуждение» LLM лучше рассматривать как генерацию по шаблонам, управляемую структурой — полезно для организации и сверки правил, рискованно воспринимать модель как безошибочный источник решений.
Преобразование неструктурированного текста политики в пригодные представления правил
Документы политики написаны для людей: они смешивают цели, исключения и «здравый смысл» в одном абзаце. LLM может суммировать этот текст, но ему надежнее следовать правилам, если политику превратить в явные, тестируемые входы.
Какими должны быть «пригодные» правила
Хорошие представления правил имеют два свойства: они недвусмысленны и их можно проверить.
Пишите правила как утверждения, которые вы могли бы протестировать:
- IF/THEN для решений (право, маршрутизация, утверждения)
- MUST / MUST NOT для жёстких ограничений
- MAY для допустимых опций (требует дополнительного критерия разрыва равенства)
Правила можно передавать модели в разных формах:
- Пулевые пункты на простом языке (быстрее, всё ещё структурировано)
- Таблица (удобно для правил, основанных на порогах)
- YAML/JSON (лучше всего, когда нужны ограниченные выходы и автоматическая валидация)
Работа с конфликтами и приоритетами
Реальные политики конфликтуют. Когда два правила противоречат, модели нужна чёткая схема приоритета. Распространённые подходы:
- Конкретное побеждает общее (исключение отменяет дефолт)
- Высший авторитет побеждает (юридический/комплаенс выше командного пожелания)
- Новый документ побеждает старый (последняя версия имеет приоритет)
- Явные числовые приоритеты (самый надёжный способ)
Укажите правило разрешения конфликта явно или закодируйте его (например, priority: 100). Иначе LLM может «усреднить» правила.
Пример: преобразование абзаца в список правил
Исходный текст политики:
“Refunds are available within 30 days for annual plans. Monthly plans are non-refundable after 7 days. If the account shows fraud or excessive chargebacks, do not issue a refund. Enterprise customers need Finance approval for refunds over $5,000.”
Structured rules (YAML):
rules:
- id: R1
statement: \"IF plan_type = annual AND days_since_purchase \u003c= 30 THEN refund MAY be issued\"
priority: 10
- id: R2
statement: \"IF plan_type = monthly AND days_since_purchase \u003e 7 THEN refund MUST NOT be issued\"
priority: 20
- id: R3
statement: \"IF fraud_flag = true OR chargeback_rate = excessive THEN refund MUST NOT be issued\"
priority: 100
- id: R4
statement: \"IF customer_tier = enterprise AND refund_amount \u003e 5000 THEN finance_approval MUST be obtained\"
priority: 50
conflict_resolution: \"Higher priority wins; MUST NOT overrides MAY\"
Теперь модель не предполагает, что важно — она применяет набор правил, который вы можете просмотреть, протестировать и версионировать.
Отслеживание состояния рабочего процесса, чтобы модель оставалась последовательной
Рабочий процесс — это не только набор правил; это последовательность событий, где ранние шаги меняют то, что должно происходить дальше. Эта «память» — состояние: текущие факты по делу (кто что отправил, что уже утверждено, что ожидается и какие дедлайны действуют). Если состояние не отслеживать явно, рабочие процессы ломаются предсказуемо — дублируются согласования, пропускаются проверки, принимаются противоположные решения или применяется не та политика, потому что модель не может надёжно вывести, что уже сделано.
Что значит «состояние» простыми словами
Думайте о состоянии как о табло рабочего процесса. Оно отвечает: Где мы сейчас? Что сделано? Что разрешено дальше? Для LLM краткое резюме состояния предотвращает пересмотр пройденных шагов или угадывание.
Как передавать состояние модели
При вызове модели включайте компактный payload состояния вместе с запросом пользователя. Полезные поля:
- Название шага и статус (например,
manager_review: approved,finance_review: pending) - Уникальные ID (request ID, employee ID), чтобы модель не путала дела
- Метки времени (submitted_at, last_updated), чтобы разрешать ситуации «последняя версия побеждает»
- Флаги (исключения политики, недостающие документы, требуемая эскалация)
Избегайте вбрасывать всю историю сообщений. Вместо этого давайте текущее состояние плюс короткий аудиторский след ключевых переходов.
Держите единый источник правды
Рассматривайте движок рабочего процесса (БД, система тикетов или оркестратор) как единственный источник правды. LLM должен читать состояние из этой системы и предлагать следующий шаг, а система — авторитетно фиксировать переходы. Это уменьшает «дрейф состояния», когда повествование модели расходится с реальностью.
Пример: снимок состояния для потока утверждений
{
"request_id": "TRV-10482",
"workflow": "travel_reimbursement_v3",
"current_step": "finance_review",
"step_status": {
"submission": "complete",
"manager_review": "approved",
"finance_review": "pending",
"payment": "not_started"
},
"actors": {
"employee_id": "E-2291",
"manager_id": "M-104",
"finance_queue": "FIN-AP"
},
"amount": 842.15,
"currency": "USD",
"submitted_at": "2025-12-12T14:03:22Z",
"last_state_update": "2025-12-13T09:18:05Z",
"flags": {
"receipt_missing": false,
"policy_exception_requested": true,
"needs_escalation": false
}
}
С таким снимком модель остаётся последовательной: она не попросит менеджера подтвердить снова, сосредоточится на проверках финансов и сможет объяснить решение с опорой на текущие флаги и шаг.
Шаблоны подсказок, которые улучшают соблюдение правил и принятие решений
Откатывайтесь с уверенностью
Защищайте релизы снимками и откатывайтесь при изменениях правил или подсказок.
Хорошая подсказка не просто просит ответ — она задаёт ожидания, как модель должна применять правила и как сообщить результат. Цель — повторяемые решения, а не красноречие.
1) Ролевые подсказки: назначьте задачу, а не атмосферу
Дайте модели конкретную роль, привязанную к вашему процессу. Три роли хорошо работают вместе:
- Аналитик политики: интерпретирует текст правил и сопоставляет их с текущим делом.
- Валидатор: проверяет решение на соответствие требованиям и отмечает недостающие входы.
- Агент: выполняет следующий шаг рабочего процесса (создать тикет, составить письмо, сменить статус).
Можно запускать их по очереди ("аналитик → валидатор → агент") или требовать все три результата в одном структурированном ответе.
2) Пошаговые инструкции (без просьбы о скрытом рассуждении)
Вместо запроса «chain‑of‑thought», задайте видимые шаги и артефакты:
- Выделите релевантные правила.
- Извлеките нужные входы из дела.
- Примените правила в порядке приоритета.
- Сформулируйте решение и следующий шаг.
Это организует модель и фокусирует на финальном результате: какие правила использованы и какой исход следует.
3) Попросите структурированную мотивацию: ID правил + доказательства
Свободные объяснения уходят в сторону. Требуйте компактную мотивацию, указывающую источники:
- ID правил (например, R‑12, R‑18)
- Доказательства (цитаты из политики и конкретные поля дела)
- Предположения (только если вход недоступен)
Это ускоряет ревью и помогает отлаживать расхождения.
4) Шаблон чек‑листа: входы, решение, исключения, следующий шаг
Используйте фиксированный шаблон всегда:
- Входы получены: …
- Входов не хватает: …
- Решение: approve/deny/needs_review
- Ссылки на правила: [R‑…]
- Рассмотренные исключения: …
- Следующий шаг в workflow: обновить статус / запросить инфо / эскалировать
Шаблон снижает неоднозначность и заставляет модель обнаруживать пробелы до принятия окончательного действия.
Использование инструментов и retrieval для привязки решений к реальным данным
LLM может написать убедительный ответ, даже если не хватает фактов. Это полезно для набросков, но рискованно для бизнес‑решений. Если модель должна угадывать статус аккаунта, уровень клиента, региональную ставку налога или достигнут ли лимит — вы получите уверенно выглядящие ошибки.
Инструменты решают это, превращая «рассуждение» в двухэтапный процесс: сначала получить доказательства, потом решать.
Частые инструменты, которые удерживают модель от ошибок
В системах с правилами и рабочими процессами несколько простых инструментов делают основную работу:
- Запрос в БД (профиль клиента, статус аккаунта, права, использованные ресурсы)
- Хранилище политик/правил (утверждённый текст правил, версионированные процедуры, списки исключений)
- Калькулятор (сборы, пропорции, налоги, временные окна, пороги)
- API тикетов/воркфлоу (открытые дела, таймеры SLA, утверждения, завершение шагов)
Суть в том, что модель не «придумывает» операционные факты — она их запрашивает.
Retrieval: приносите только релевантные правила
Даже если у вас все политики в одном хранилище, редко стоит вставлять их целиком в подсказку. Retrieval помогает выбирать только те фрагменты, что важны для текущего случая, например:
- Политика отмены для тарифного плана клиента
- Региональная оговорка соответствия в зависимости от страны/штата
- Правило‑исключение при наличии chargeback
Это уменьшает противоречия и не даёт модели следовать устаревшему правилу просто потому, что оно встретилось раньше в контексте.
Превращение результатов инструментов в доказательства решения
Надёжный паттерн — считать результаты инструментов доказательствами, на которые модель должна ссылаться при решении. Например:
- Tool:
get_account(account_id)→status="past_due",plan="Business",usage_this_month=12000 - Tool:
retrieve_policies(query="overage fee Business plan")→ returns rule: “Overage fee applies above 10,000 units at $0.02/unit.” - Tool:
calculate_overage(usage=12000, threshold=10000, rate=0.02)→$40.00
Теперь решение не угадывание: это вывод, привязанный к конкретным входам ("past_due", "12000 units", "$0.02/unit"). Если позже потребуется аудит, видно, какие факты и какая версия правила использовались — и можно исправить именно ту часть, которая изменилась.
Ограниченные (constrained) выходы: схемы, которые снижают неоднозначность
Быстро запустите полный стек
Сгенерируйте приложение на React с бэкендом на Go и PostgreSQL из одного разговора.
Свободный текст гибок, но он же самый простой путь для поломки рабочего процесса. Модель может дать «разумный» ответ, который нельзя автоматизировать ("всё в порядке") или быть непоследовательной между шагами ("approve" vs "approved"). Ограниченные выходы решают это, заставляя каждое решение входить в предсказуемую форму.
Возвращайте решения в виде JSON
Практичный паттерн — требовать от модели единый JSON‑объект, который ваша система может распарсить и маршрутизировать:
{
"decision": "needs_review",
"reasons": [
"Applicant provided proof of income, but the document is expired"
],
"next_action": "request_updated_document",
"missing_info": [
"Income statement dated within the last 90 days"
],
"assumptions": [
"Applicant name matches across documents"
]
}
Такая структура полезна даже когда модель не может принять окончательное решение. missing_info и assumptions превращают неопределённость в понятные действия, а не в скрытые догадки.
Используйте перечисления, чтобы ограничить результаты
Чтобы снизить вариативность, определите допустимые значения (enums) для ключевых полей. Например:
decision:approved|denied|needs_reviewnext_action:approve_case|deny_case|request_more_info|escalate_to_human
С перечислениями downstream‑системам не нужно интерпретировать синонимы или тон — они просто ветвят по известным значениям.
Почему схемы делают рабочие процессы безопаснее
Схемы — это как ограждения. Они:
- Предотвращают «частичные ответы», требуя обязательные поля.
- Упрощают аудит:
reasonsпоказывает, почему принято решение. - Позволяют надёжную автоматизацию: очереди, уведомления и создание задач могут срабатывать напрямую по
decisionиnext_action. - Поддерживают валидацию: можно отклонять выводы, не соответствующие схеме, и просить модель повторить.
Результат — меньше неоднозначности, меньше сбоев на краях и последовательные решения в workflow.
Стратегии валидации: ловим ошибки до релиза
Даже хорошо подсказанная модель может «звучать верно», нарушая правило, пропуская обязательный шаг или выдумывая значение. Валидация — это сетка безопасности, которая превращает правдоподобный ответ в надёжное решение.
Предварительные проверки: валидируйте входы до рассуждения
Начните с проверки минимального набора данных, нужного для применения правил. Предпроверки должны выполняться до того, как модель примет решение.
Типичные предварительные проверки: обязательные поля (тип клиента, сумма заказа, регион), базовый формат (даты, ID, валюта) и допустимые диапазоны (неотрицательные суммы, проценты до 100%). Если что‑то не проходит — возвращайте понятную ошибку ("Missing 'region'; cannot choose tax rule set") вместо того, чтобы позволять модели угадывать.
Постпроверки: валидируйте решение относительно правил
После того как модель выдала результат, проверьте, соответствует ли он набору правил.
Сфокусируйтесь на:
- Покрытие правил: ссылается ли решение на применимые правила или пропущена обязательная политика?
- Проверки на противоречия: не конфликтует ли вывод с входными данными (например, "approved" при действующей блокировке)?
- Краевые случаи: тесты для пороговых значений (ровно $10,000), пустых состояний ("нет прошлых нарушений") и «чуть больше» сценариев.
Двойная проверка: дополнительный шаг ревью
Добавьте «второй проход», который перепроверяет первый ответ. Это может быть ещё один вызов модели или тот же LLM с валидаторским промптом, который только проверяет соответствие, а не творит.
Простой паттерн: первый проход даёт решение + обоснование; второй возвращает valid или структурированный список ошибок (недостающие поля, нарушенные ограничения, неоднозначная интерпретация правил).
Логирование: делайте решения аудируемыми
Для каждого решения логируйте входные данные, версию правила/политики и результаты валидации (включая второй проход). Когда что‑то идёт не так, это позволяет воспроизвести точные условия, исправить сопоставление правил и убедиться в корректности — без попыток гадать, что модель «имела в виду».
Тестирование и мониторинг для надёжности правил и рабочих процессов
Тестирование LLM‑фич с правилами и рабочими процессами — это не столько «создала ли модель ответ?», сколько «сделает ли она то же решение, что и вдумчивый человек, по правильным причинам, всегда?». Хорошая новость: это можно тестировать дисциплинированно, как традиционную логику принятия решений.
Unit‑тесты для бизнес‑правил (малые, предсказуемые проверки)
Относитесь к каждому правилу как к функции: для заданных входов оно должно возвращать ожидаемый результат.
Например, для правила возврата: «возвраты разрешены в течение 30 дней для нераспечатанных товаров», напишите фокусные кейсы с ожидаемыми результатами:
- Age заказа = 10 дней, unopened = true → approve
- Age заказа = 10 дней, unopened = false → deny
- Age заказа = 45 дней, unopened = true → deny
- Краевые случаи: ровно 30 дней, отсутствует поле “unopened”, конфликтующие сигналы
Эти unit‑тесты ловят ошибки типа off‑by‑one, отсутствующие поля и «полезное» поведение модели, когда она пытается заполнять неизвестные значения.
Сценарные тесты для рабочих процессов (многошаговые, зависящие от времени пути)
Рабочие процессы ломаются, когда состояние рассогласовано между шагами. Сценарные тесты симулируют реальные путешествия:
- Тесты путей: подать претензию → запросить документы → документы получены → решение
- Временные края: "если нет ответа в течение 7 дней — напомнить", "если прошло 30 дней — закрыть дело"
- Ветвления: клиент эскалирует, запрошено исключение политики, обнаружен дубликат
Цель — проверить, что модель соблюдает текущее состояние и делает только разрешённые переходы.
Постройте «gold set» эталонных кейсов
Создайте кураторский набор реальных, анонимизированных примеров с согласованными исходами (и краткими обоснованиями). Ведите его под версионированием и пересматривайте при изменении политики. Небольшой gold set (даже 100–500 кейсов) мощен, потому что отражает реальную «грязь» — недостающие данные, странную формулировку, пограничные решения.
Мониторинг в продакшене (ловите дрейф до того, как почувствуют клиенты)
Отслеживайте распределение решений и сигналы качества во времени:
- Дрейф: показатели одобрений/отказов изменяются без обновления политики
- Всплески
needs_reviewили переводов на людей (часто — проблема подсказки, retrieval или upstream‑данных) - Кластеры ошибок по продукту, региону или категории политик
Сопровождайте мониторинг безопасной возможностью отката: храните предыдущую упаковку подсказок/правил, используйте feature‑флаги и быстро возвращайте версию при регрессе метрик. Для операционных плейбуков и gating‑релизов смотрите /blog/validation-strategies.
Где Koder.ai вписывается в этот конвейер
Владейте исходным кодом
Сохраняйте контроль, экспортируя исходный код, когда прототип становится критичным для продакшена.
Если вы реализуете описанные паттерны, обычно вокруг модели выстроится небольшая система: хранение состояния, вызовы инструментов, retrieval, валидация схем и оркестрация workflow. Koder.ai — практичный способ прототипировать и выпускать такого рода ассистента быстрее: вы описываете рабочий процесс в чате, генерируете рабочее веб‑приложение (React) вместе с бэкендом (Go + PostgreSQL) и итеративно разворачиваете с возможностью снапшотов и отката.
Это важно для рассуждений о бизнес‑правилах, потому что «ограждения» часто живут в приложении, а не в подсказке:
- Planning mode помогает спроектировать поток (состояния, допустимые переходы, пути эскалации) до выполнения.
- Схемно‑ограниченные ответы можно жестко проверять на границе API, чтобы принимать только парсируемые решения.
- Хуки инструментов (чтение БД, retrieval политик, калькуляторы, обновления тикетов) реализуются как явные эндпойнты, делая «сначала получить доказательства, потом решить» шаблоном по умолчанию.
- Экспорт исходников позволяет избежать фиксации на прототипе, когда он становится критичным для продакшена.
Ограничения, безопасное использование и когда оставлять человека в цикле
LLM могут удивительно хорошо применять повседневные политики, но они не замена детерминированному движку правил. Рассматривайте их как помощника, которому нужны ограждения, а не как окончательную инстанцию принятия решений.
Где LLM обычно испытывают трудности
Три повторяющихся режима ошибок в рабочих процессах с правилами:
- Редкие исключения и краевые случаи: если исключение случается раз в год, оно может плохо представлено в обучающих данных и легко пропуститься, если явно не включено в подсказку или не извлечено из политик.
- Длинные контексты и «зарытые» ограничения: когда ключевые детали разбросаны по многим страницам или сообщениям, модель может переоценить последний или самый яркий текст и недооценить ранние ограничения.
- Числовая точность и строгие расчёты: итоги, пропорции, пороги и правила округления могут дрейфовать. Используйте инструменты для арифметики и требуйте, чтобы модель ссылалась на точные числа.
Когда требовать человеческий ревью
Добавьте обязательный ревью, когда:
- Исход высокого риска (движение денег, комплаенс, безопасность, юридические обязательства, кредит/право клиента).
- Модель сигнализирует низкую уверенность (просит угадать недостающие входы, не находит опору в политике или даёт противоречивую мотивацию).
- Дело новое (новый продукт, новый регион, политика недавно поменялась) или особенно чувствительное.
Пути эскалации, которые сохраняют движение процесса
Вместо того, чтобы модель «что‑то придумывала», определите чёткие следующие шаги:
- Задавайте уточняющие вопросы (недостающие даты, уровень клиента, юрисдикция, статус утверждения).
- Маршрутизируйте к агенту с извлечёнными фактами, предложенным решением и цитатами.
- Создавайте тикет, когда политика неоднозначна или конфликтует, чтобы это можно было исправить в источнике (и потом автоматически извлечь).
Простая рамка принятия решений для внедрения
Используйте LLM в рабочих процессах с правилами, когда можете ответить «да» на большинство из этих вопросов:
- Можем ли мы подвязать решения к утверждённому тексту политики или системным данным?
- Можем ли мы ограничить выводы (схема, допустимые действия, обязательные ссылки)?
- Можем ли мы проверять (проверки, пороги, unit‑тесты, выборочный контроль) перед исполнением?
- Есть ли у нас маршрут эскалации к человеку для рискованных или неопределённых случаев?
Если нет — держите LLM в роли чернового/ассистентского инструмента, пока такие контролы не появятся.