13 нояб. 2025 г.·8 мин
Как появились NoSQL — чтобы решить задачи масштабирования и гибкости
Узнайте, почему возникли NoSQL: требования веб‑масштаба, гибкость данных и ограничения реляционных систем — а также ключевые модели и компромиссы.
Узнайте, почему возникли NoSQL: требования веб‑масштаба, гибкость данных и ограничения реляционных систем — а также ключевые модели и компромиссы.
NoSQL возник тогда, когда у многих команд возник разрыв между потребностями приложений и тем, для чего оптимизированы традиционные реляционные базы данных (SQL). SQL не «провалился» — но при веб‑масштабе некоторые команды начали ставить другие приоритеты.
Во‑первых, масштаб. Популярные потребительские приложения стали испытывать всплески трафика, постоянные записи и огромные объёмы пользовательских данных. Для таких нагрузок «купить более мощный сервер» оказалось дорого, медленно в реализации и в конечном счёте ограничивалось самым большим управляемым узлом.
Во‑вторых, изменчивость. Функции продукта быстро эволюционировали, и данные за ними не всегда укладывались в фиксированный набор таблиц. Добавление новых атрибутов в профиль пользователя, хранение разных типов событий или приём полуструктурированного JSON из разных источников часто требовало повторяющихся миграций схем и координации между командами.
Реляционные базы отлично справляются с обеспечением структуры и сложными запросами по нормализованным таблицам. Но для некоторых высокомасштабных нагрузок эти преимущества было труднее реализовать:
Результат: некоторые команды искали системы, которые жертвовали некоторыми гарантиями и возможностями ради более простого масштабирования и быстрой итерации.
NoSQL — не одна СУБД и не единая архитектура. Это зонтичный термин для систем, которые делают упор на сочетание:
NoSQL никогда не замещал SQL повсеместно. Это набор компромиссов: можно получить масштаб и гибкость схемы, но принять более слабые гарантии согласованности, меньше возможностей для ad‑hoc запросов или большую ответственность за моделирование данных в приложении.
Долгое время стандартный ответ на медленную базу был прост: купить более мощный сервер. Добавить CPU, RAM, быстрые диски и сохранить ту же схему и модель эксплуатации. Этот подход «масштабировать вверх» работал — пока не перестал быть практичным.
Топовые машины быстро становятся дорогими, и кривая цена/производительность теряет привлекательность. Апгрейды часто требуют больших бюджетных одобрений и окон обслуживания для перемещения данных и переключения. Даже если можно позволить себе более мощный хост, один сервер имеет потолок: одна шина памяти, одна подсистема хранения и один первичный узел, принимающий нагрузку записей.
По мере роста продуктов базы испытывали постоянную нагрузку чтений/записей, а не редкие пики. Трафик стал круглосуточным, и отдельные функции породили неравномерные шаблоны доступа. Небольшое число часто запрашиваемых строк или партиций могло доминировать, создавая «горячие» таблицы (или ключи), которые замедляли всё остальное.
Операционные узкие места стали обычным явлением:
Многим приложениям также требовалось быть доступными по регионам, а не только быстрыми в одном дата‑центре. Одна «главная» база в одном месте увеличивает задержки для удалённых пользователей и делает простои катастрофическими. Вопрос перестал быть «как купить больше железа?» и стал «как запустить базу по множеству машин и локаций?»
Реляционные БД хороши, когда форма данных стабильна. Но многие современные продукты не стоят на месте. Схема таблицы намеренно строгая: каждая строка следует одинаковому набору колонок, типов и ограничений. Эта предсказуемость ценна — пока вы активно не итератируете.
На практике частые изменения схемы могут быть дорогими. Казалось бы небольшое обновление может потребовать миграций, бэфиллов, обновлений индексов, скоординированных деплоев и планирования совместимости, чтобы старый код не ломался. На больших таблицах даже добавление колонки или изменение типа может стать длительной операцией с реальным операционным риском.
Это трение заставляет команды откладывать изменения, накапливать костыли или хранить неструктурированные блобы в текстовых полях — что плохо для быстрой итерации.
Множество данных приложения по своей природе полуструктурированы: вложенные объекты, опциональные поля, атрибуты, которые меняются со временем.
Например, «профиль пользователя» мог начинаться с имени и почты, затем расшириться на предпочтения, связанные аккаунты, адреса доставки, настройки уведомлений и флаги экспериментa. Не у каждого пользователя есть все поля, и новые поля появляются постепенно. Документные модели позволяют хранить вложенные и неоднородные формы напрямую, не заставляя каждую запись соответствовать одному жёсткому шаблону.
Гибкость также сокращает потребность в сложных джоинах для некоторых форм данных. Когда один экран нуждается в собранном объекте (заказ с позициями, информацией о доставке и историей статусов), реляционный дизайн может требовать нескольких таблиц и джоинoв — плюс ORM, который пытается скрыть сложность, но часто добавляет трение.
NoSQL‑варианты упростили моделирование данных ближе к тому, как приложение читает и записывает их, помогая командам быстрее выпускать изменения.
Веб‑приложения не просто выросли — они изменили форму. Вместо предсказуемого числа внутренних пользователей в рабочее время продукты стали обслуживать миллионы глобальных пользователей круглосуточно, с резкими всплесками из‑за запусков, новостей или вирусного расшаривания.
Ожидание «всегда доступно» подняло планку: простой простоя стал новостью, а не неудобством. При этом команды должны были выпускать фичи быстрее — зачастую ещё до того, как была понятна «финальная» модель данных.
Чтобы успевать, масштабирование одного сервера перестало быть достаточным. Чем больше трафика, тем больше хотели добавить ёмкости постепенно — добавляя узлы, распределяя нагрузку и изолируя отказы.
Это сместило архитектуру в сторону кластеров машин вместо одного «главного» узла и изменило ожидания от БД: не только корректность, но предсказуемая производительность при высокой конкуренции и грациозное поведение при деградации частей системы.
До того как NoSQL стал массовым, многие команды уже тянули системы в сторону веб‑масштаба:
Эти техники работали, но переносили сложность в код приложения: инвалидация кэша, поддержание консистентности дублей и создание пайплайнов для «готовых к выдаче» записей.
По мере того как эти шаблоны стали стандартом, базам данных пришлось поддерживать распределение данных по узлам, терпеть частичные отказы, обрабатывать большие объёмы записей и чисто представлять эволюционирующие данные. NoSQL‑базы появились частично чтобы сделать обычные практики веб‑масштабирования первоклассными, а не постоянными костылями.
Когда данные живут на одной машине, правила кажутся простыми: есть единый источник правды, и каждое чтение или запись можно проверить сразу. Когда вы распределяете данные по серверам (часто по регионам), появляется новая реальность: сообщения могут задерживаться, узлы падать, и части системы временно перестают общаться.
Распределённой базе нужно решить, что делать, когда она не может безопасно скоординироваться. Продолжать ли обслуживать запросы, чтобы приложение оставалось «вверх», даже если результаты могут быть немного устаревшими? Или отказывать в операциях до тех пор, пока реплики не подтвердят согласие, что выглядит как простой для пользователей?
Такие ситуации возникают при отказах маршрутизаторов, перегрузках сети, роллинговых деплойментах, ошибках в настройках фаервола и задержках кросс‑региональной репликации.
Теорема CAP — краткая формула трёх свойств, которые хотелось бы иметь одновременно:
Ключевая мысль не в том, чтобы «всегда выбирать два». Это: когда происходит сетевой разрыв, нужно выбирать между согласованностью и доступностью. В веб‑масштабных системах разрывы считаются неизбежными — особенно в мульти‑региональных конфигурациях.
Представьте, что приложение работает в двух регионах для устойчивости. Перебой в маршрутизации мешает синхронизации.
Разные NoSQL‑системы (и разные настройки одной и той же системы) делают различные компромиссы, в зависимости от того, что важнее: пользовательский опыт при сбоях, гарантии корректности, простота эксплуатации или поведение при восстановлении.
Масштабирование наружу (horizontal scaling) значит увеличивать ёмкость добавлением более машин, а не покупкой единого более мощного сервера. Для многих команд это был финансовый и операционный сдвиг: можно постепенно добавлять узлы, ожидать отказы и расти без рискованных «big box» миграций.
Чтобы сделать множество узлов полезными, NoSQL‑системы опирались на шардинг (партиционирование). Вместо одной базы, обрабатывающей всё, данные разбиваются на партиции и распределяются по узлам.
Простой пример — партиционирование по ключу (user_id):
Чтения и записи распределяются, уменьшая «горячие точки» и позволяя пропускной способности расти с добавлением узлов. Партиционный ключ становится важным решением проектирования: если выбрать ключ, не соответствующий шаблонам запросов, можно случайно сосредоточить трафик в одном шарде.
Репликация означает хранение нескольких копий одних и тех же данных на разных узлах. Это улучшает:
Репликация также позволяет размещать данные по стойкам или регионам, чтобы пережить локальные отказы.
Шардинг и репликация вводят постоянную операционную работу. По мере роста данных или смены узлов система должна ребалансироваться — перемещать партиции в онлайне. Если это сделано плохо, ребалансировка может вызвать всплески задержек, неравномерную нагрузку или временный дефицит ёмкости.
Это ключевой компромисс: дешевле масштабироваться через множество узлов, но сложнее распределение, мониторинг и обработка отказов.
Когда данные распределены, база должна определить, что означает «корректно» при одновременных обновлениях, медленной сети или недоступности узлов.
При сильной согласованности, как только запись подтверждена, каждый читатель должен увидеть её немедленно. Это соответствует опыту «единого источника истины», который многие ассоциируют с реляционными базами.
Проблема — координация: строгие гарантии требуют множества сообщений, ожидания ответов и обработки сбоев в полёте. Чем дальше и загруженнее узлы, тем большую задержку можно добавить — иногда на каждую запись.
Конечная согласованность ослабляет это требование: после записи разные узлы могут кратко отдавать разные ответы, но со временем система сходится.
Примеры:
Для многих пользовательских сценариев такая временная рассинхронизация приемлема, если система остаётся быстрой и доступной.
Если две реплики принимают обновления почти одновременно, база должна применить правило слияния.
Распространённые подходы:
Сильная согласованность обычно оправдана для денежных операций, лимитов запасов, уникальных имён пользователей, разрешений и любых рабочих процессов, где «две истины на мгновение» приводят к реальному ущербу.
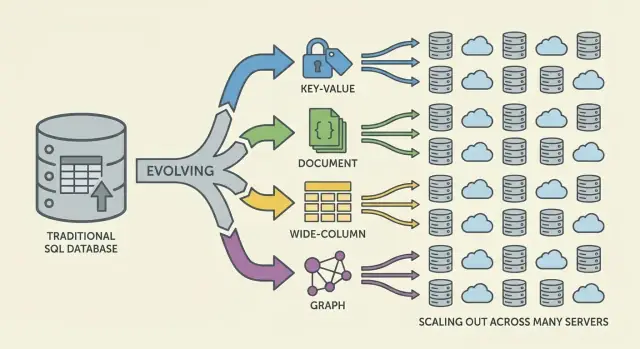
NoSQL — набор моделей, которые по‑разному жертвуют ради масштаба, задержки и формы данных. Понимание «семейства» помогает предсказать, что будет быстрым, а что болезненным.
Key‑value базы хранят значение по уникальному ключу, как огромный распределённый hashmap. Поскольку шаблон доступа обычно «get по ключу» / «set по ключу», такие системы очень быстрые и горизонтально масштабируемые.
Отлично подходят, когда ключ для поиска уже известен (сессии, кеши, feature‑flags), но ограничены для ad‑hoc запросов: фильтрация по нескольким полям часто не предполагается.
Документные базы хранят JSON‑подобные документы (обычно в коллекциях). Каждый документ может иметь чуть другую структуру, что поддерживает гибкость схемы по мере развития продукта.
Они оптимизированы для чтения/записи целых документов и запросов по полям внутри них — без принуждения к жёстким таблицам. Компромисс: моделирование связей может усложняться, и джоины (если есть) обычно менее мощные, чем в реляционных системах.
Ширококолоночные СУБД (вдохновлённые Bigtable) организуют данные по ключам строк с множеством колонок, которые могут различаться для каждой строки. Они блистают при массовых записях и распределённом хранении, хорошо подходя для временных рядов, событий и логов.
Они вознаграждают тщательный дизайн с учётом шаблонов доступа: эффективно запросить по первичному ключу и кластерным правилам, а не по произвольным фильтрам.
Графовые БД делают связи первоклассными. Вместо многократных джоинов таблиц они обходят рёбра между узлами, делая естественными и быстрыми запросы типа «как эти объекты связаны?» (фрод‑сети, рекомендации, зависимости).
Реляционные базы поощряют нормализацию: разбивать данные на много таблиц и собирать их джоинами при запросе. Многие NoSQL‑системы заставляют проектировать вокруг ключевых шаблонов доступа — иногда ценой дублирования — чтобы сохранять предсказуемую задержку между узлами.
В распределённых базах джоин может требовать вытягивания данных из нескольких партиций или машин. Это добавляет сетевые хопы, координацию и непредсказуемую задержку. Денормализация (хранение связанных данных вместе) сокращает круги запросов и делает чтение чаще «локальным».
Практическое следствие: вы можете хранить то же имя клиента в записи orders, даже если оно также есть в customers, потому что «показать последние 20 заказов» — ключевой быстрый запрос.
Многие NoSQL‑базы поддерживают ограниченные джоины (или вообще нет), поэтому приложение берёт на себя больше ответственности:
Поэтому моделирование в NoSQL часто начинается с вопросов: «Какие экраны нужно загрузить?» и «Какие топ‑запросы должны быть быстрыми?»
Вторичные индексы открывают новые запросы («найти пользователей по email»), но не бесплатны. В распределённых системах каждая запись может обновлять несколько индексных структур, что приводит к:
order, чтобы прочитать заказ одним запросомuser_profile_summary, чтобы отдавать страницу профиля без сканирования постов, лайков и подписокNoSQL приняли не потому, что он «лучше во всём». Его приняли, потому что команды были готовы пожертвовать удобствами реляционных БД ради скорости, масштаба и гибкости при веб‑нагрузках.
Горизонтальное масштабирование по дизайну. Многие NoSQL‑системы сделали практичным добавление машин вместо постоянного апгрейда одного сервера. Шардинг и репликация стали базовыми возможностями, а не дополнительными.
Гибкие схемы. Документные и key‑value системы позволяли приложениям эволюционировать без прохождения каждого изменения через жёсткое определение таблицы, уменьшая трение при частых изменениях.
Шаблоны высокой доступности. Репликация по узлам и регионам упрощала поддержку сервиса в период аппаратных сбоев или обслуживания.
Дублирование данных и денормализация. Избегание джоинов часто ведёт к дублированию. Это улучшает скорость чтения, но увеличивает объёмы хранения и вводит задачу «обнови везде».
Сюрпризы связанной с согласованностью. Конечная согласованность может быть приемлемой — пока вдруг не становится неприемлемой. Пользователи могут видеть устаревшие данные или странные краевые случаи, если приложение не спроектировано для терпимости или разрешения конфликтов.
Сложности с аналитикой (иногда). Некоторые NoSQL‑хранилища хороши для операционных чтений/записей, но усложняют ad‑hoc запросы, отчётность и сложные агрегаты по сравнению с SQL‑системами.
Раннее принятие NoSQL часто переносило усилия из возможностей базы в инженерную дисциплину: мониторинг репликации, управление партициями, запуск компакций, планирование бэкапов/восстановлений и нагрузочное тестирование сценариев отказа. Команды с высокой операционной зрелостью выигрывали больше.
Выбирайте, исходя из реальностей рабочей нагрузки: ожидаемой задержки, пиковой пропускной способности, доминирующих шаблонов запросов, терпимости к устаревшим чтениям и требований к восстановлению (RPO/RTO). "Правильный" NoSQL‑выбор — тот, что соответствует тому, как ваше приложение падает, масштабируется и запрашивается, а не просто впечатляющий список возможностей.
Выбор NoSQL не должен начинаться с брендов или хайпа — он должен начинаться с того, что ваше приложение должно делать, как оно будет расти и что значит «правильно» для ваших пользователей.
Перед выбором хранилища пропишите:
Если вы не можете ясно описать шаблоны доступа, любой выбор будет угадыванием — особенно с NoSQL, где моделирование часто формируется под способ чтения и записи.
Используйте это как фильтр:
Практический сигнал: если ваш «core truth» (заказы, платежи, инвентарь) должен быть корректен всегда — держите это в SQL или другом сильно согласованном хранилище. Если вы обслуживаете высоко объёмный контент, сессии, кеши, ленты или гибкие пользовательские данные — NoSQL может подойти.
Многие команды успешно используют несколько хранилищ: например, SQL для транзакций, документную базу для профилей/контента и key‑value для сессий. Цель — не сложность ради сложности, а подбор инструмента под каждую рабочую нагрузку.
Это также где важен рабочий процесс разработчика. Если вы итеративно экспериментируете с архитектурой (SQL vs NoSQL vs гибрид), возможность быстро поднять прототип — API, модель данных и UI — снижает риск. Платформы вроде Koder.ai помогают генерировать full‑stack приложения из чата, обычно с React фронтендом и Go + PostgreSQL бэкендом, позволяя экспортировать исходники. Даже если позже вы добавите NoSQL для отдельных частей, наличие сильной SQL «системы записи» плюс быстрые прототипы, снимки и откаты делает эксперименты безопаснее и быстрее.
Что бы вы ни выбрали — докажите это:
Если вы не можете протестировать эти сценарии, решение по базе остаётся теоретическим — и продакшен сделает тестирование за вас.
NoSQL решал сразу две частые проблемы:
Речь не о том, что SQL «плох», а о том, что разные рабочие нагрузки требуют других компромиссов.
Классический подход «scale up» сталкивался с практическими ограничениями:
NoSQL сделал ставку на масштабирование горизонтально — добавлять узлы вместо постоянной покупки более мощной машины.
Реляционная схема по замыслу строгая — это хорошо для предсказуемости, но болезненно при быстрой итерации. На больших таблицах даже «простые» изменения требуют:
Документные модели снижают этот трение, позволяя полям быть опциональными и эволюционировать постепенно.
Не обязательно. Многие SQL-системы умеют масштабироваться горизонтально, но это часто операционно сложно (шардинг, кросс-шардовые джоины, распределённые транзакции).
NoSQL-решения сделали распределение (партиционирование + репликация) «first-class», оптимизировав систему под предсказуемые шаблоны доступа при больших объёмах.
Денормализация хранит данные в том виде, в котором их читают, иногда дублируя поля, чтобы избежать дорогостоящих джоинов.
Пример: хранить имя клиента в записи orders, чтобы получить «последние 20 заказов» одним быстрым запросом.
Компромисс — сложность обновления: нужно поддерживать согласованность дублированных данных на уровне приложения или через пайплайны.
В распределённой системе при сетевой разрыве база должна выбирать поведение:
CAP напоминает, что в условиях разрыва сети нельзя иметь одновременно идеальную согласованность и полную доступность.
Сильная согласованность: после подтверждённой записи все читатели видят её сразу; часто требует координации между узлами.
Конечная (eventual) согласованность: реплики могут временно расходиться, но с течением времени сходятся. Подходит для лент, счётчиков и сценариев, где кратковременная рассинхронизация допустима.
Конфликт возникает, когда разные реплики принимают конкурентные обновления. Популярные стратегии:
Выбор зависит от того, допустимо ли потерять промежуточные обновления для данного типа данных.
Короткое руководство:
Выбирайте, исходя из доминирующего шаблона доступа, а не от популярности.
Начните с требований и подтвердите их тестами:
Во многих системах гибридный подход выигрывает: SQL для критичных данных (платежи, инвентарь), NoSQL для высоконагруженных или гибких данных (ленты, сессии, профили).