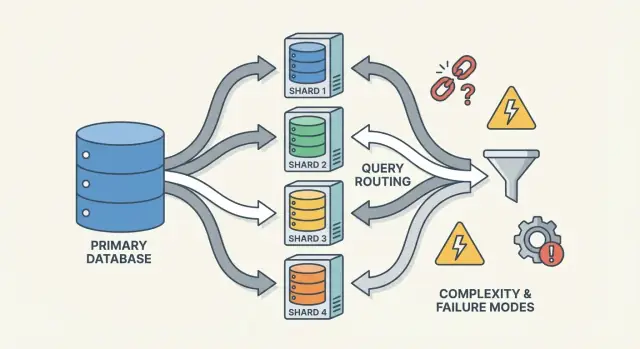
Что такое шардинг (и что это не решает)
Шардинг (также называемый горизонтальным разбиением) означает, что то, что для приложения выглядит как одна база данных, на деле разнесено по нескольким машинам, называемым шардами. Каждый шард хранит только подмножество строк, но вместе они представляют полный набор данных.
Одна логическая таблица — много физических мест
Полезная мысленная модель — разница между логической структурой и физическим размещением.
- Логически: у вас всё ещё одна таблица «Users» (те же колонки, тот же смысл).
- Физически: строки этой таблицы хранятся в разных местах — например, пользователи с ID 1–1 000 000 на шарде A, а следующие миллион на шарде B.
С точки зрения приложения вы хотите выполнять запросы, как будто это одна таблица. Под капотом система должна решить, к какому(им) шарду(ам) обращаться.
Это не репликация и не просто «купить большой сервер»
Шардинг отличается от репликации. Репликация создаёт копии одних и тех же данных на нескольких узлах, главным образом для доступности и масштабирования чтений. Шардинг разделяет данные так, что каждый узел хранит разные записи.
Он также отличается от вертикального масштабирования, когда вы оставляете одну БД, но переносите её на более мощную машину (больше CPU/RAM/быстрые диски). Вертикальное масштабирование может быть проще, но имеет практические пределы и быстро дорожает.
Что шардинг не исправляет автоматически
Шардинг увеличивает ёмкость, но не делает автоматически вашу БД «простее» или каждый запрос — быстрее.
- JOIN’ы могут стать дорогими, если связанные строки живут на разных шардах.
- Транзакции через шарды сложнее; согласованные «всё или ничего» обновления требуют координации.
- Операционная сложность возрастает: маршрутизация, ребалансировка, отладка и обработка отказов становятся частью системы.
Шардинг лучше понимать как способ масштабировать хранилище и пропускную способность — а не как бесплатное улучшение всех аспектов поведения базы данных.
Почему команды шардят: проблемы, которые это решает
Шардинг редко становится первым выбором. Команды обычно приходят к нему после того, как успешная система достигает физических лимитов или эксплуатационная боль становится слишком частой. Мотивация чаще не «мы хотим шардинг», а «нам нужно расти, не делая одну базу единым точкой отказа и затрат».
Болевые точки, толкающие к шардингу
Один узел базы данных может исчерпать свои ресурсы разными способами:
- Ограничения по хранилищу: таблицы и индексы растут, дисков становится мало, бэкапы замедляются, операции обслуживания рискуют.
- Ограничения пропускной способности записи: CPU, WAL/redo или конкуренция блокировок ограничивают количество записей в секунду.
- Ограничения по чтению: даже с кэшем и репликами некоторые нагрузки перегружают primary (или реплики дорого масштабировать).
- Шумные соседи: один клиент или шаблон нагрузки монополизирует ресурсы и ухудшает опыт у всех.
Когда эти проблемы возникают регулярно, часто причина не в одном «плохом» запросе — а в том, что одна машина несёт слишком много ответственности.
Цели: scale out, изоляция и контроль затрат
Шардинг распределяет данные и трафик по нескольким узлам, чтобы ёмкость росла при добавлении машин вместо вертикального апгрейда одного. При правильной реализации это также изолирует рабочие нагрузки (чтобы всплеск у одного клиента не портил задержки для других) и контролирует затраты, избегая всё более дорогих премиум-инстансов.
Ранние признаки, что вы близки к потолку
Повторяющиеся паттерны: постоянный рост p95/p99 в пике, увеличение отставания репликации, бэкапы/восстановления, превышающие допустимый интервал, и «маленькие» изменения схемы, превращающиеся в крупные события.
Почему шардинг обычно — крайний шаг
Перед тем как принять решение, команды обычно исчерпывают более простые варианты: индексация и исправление запросов, кэширование, read replicas, партиционирование в одной БД, архивирование старых данных и апгрейды железа. Шардинг решает проблему масштабирования, но добавляет координацию, операционную сложность и новые режимы отказа — поэтому порог для его включения должен быть высоким.
Основные части: шарды, маршрутизаторы и метаданные
Шардированная БД — это не одна вещь, а система взаимодействующих частей. Причина, по которой шардинг кажется «трудным для рассуждения», в том, что корректность и производительность зависят от взаимодействия этих частей, а не только от движка БД.
Шарды: независимые партиции (со своими индексами)
Шард — это подмножество данных, обычно хранящееся на собственном сервере или кластере. У каждого шарда обычно есть:
- хранилище (файлы данных)
- индексы (чтобы запросы были быстрыми внутри шарда)
- локальные лимиты (CPU, память, диск, соединения)
С точки зрения приложения, шарди́рованная система часто пытается выглядеть как одна логическая БД. Но под капотом запрос, который был бы «одним индексным поиском» в одноузловой БД, может стать: «найти нужный шард, затем выполнить поиск».
Маршрутизаторы/координаторы: как запросы попадают в нужный шард
Маршрутизатор (иногда координатор, query router или прокси) — это регулировщик трафика. Он отвечает на практический вопрос: какому шарду должен обработать этот запрос?
Два распространённых паттерна:
- Клиентская маршрутизация: библиотека в приложении знает карту шардов и подключается прямо к нужному шарду.
- Прокси-маршрутизация: приложение подключается к сервису-маршрутизатору, который форвардит запрос.
Маршрутизаторы снижают сложность в приложении, но сами могут стать бутылочным горлышком или новой точкой отказа, если они спроектированы плохо.
Метаданные/сервис конфигурации: карта шардов, владение и здоровье
Шардинг опирается на метаданные — источник истины, описывающий:
- карту шардов (какой шард владеет какой областью/бакетом/ID)
- владение (особенно во время миграций, когда владение может временно перекрываться)
- здоровье и членство (какие узлы в сети, роли primary/replica, статус дренажа)
Эта информация обычно живёт в сервисе конфигурации (или небольших «control plane» БД). Если метаданные устарели или несогласованы, маршрутизаторы могут посылать трафик не туда — даже если сами шарды полностью здоровы.
Фоновые задачи: балансировка, миграции и бэкапы
Наконец, шардинг зависит от фоновых процессов, которые поддерживают систему в рабочем состоянии:
- ребалансировка данных, когда один шард растёт быстрее других
- миграции при переносе владения между шардами
- бэкап/восстановление, работающие через много шардов и соответствующие целям восстановления
Эти задачи просто игнорировать тяжело — именно они часто вызывают сюрпризы в продакшне, потому что меняют форму системы, пока она ещё обслуживает трафик.
Выбор ключа шарда: первый большой компромисс
Ключ шарда — это поле (или комбинация полей), которое система использует, чтобы решить, на каком шарде хранить строку/документ. Этот единичный выбор тихо определяет производительность, затраты и даже то, какие функции будут «простыми» позже — потому что он контролирует, можно ли маршрутизовать запрос к одному шардy или придётся рассылать его по многим.
Что делает ключ хорошим
Хороший ключ обычно имеет:
- Высокую кардинальность: много возможных значений (например,
user_id лучше, чем страна).
- Равномерное распределение: значения равномерно распределяют записи и запросы по шардy вместо концентрации в одном.
- Стабильные паттерны доступа: ключ соответствует тому, как вы чаще всего запрашиваете данные сейчас и в ближайшем будущем.
Обычный пример — шардинг по tenant_id в мульти-тенантном приложении: большинство чтений и записей по арендаторам остаются на одном шарде, а арендаторы в целом многочисленны, чтобы распределить нагрузку.
Что делает ключ плохим (и почему это больно)
Некоторые ключи почти гарантируют проблемы:
- Временные монотонные ключи (таймстемпы, автоинкрементные ID): новые данные скапливаются на «последнем» шарде, создавая хотспот.
- Поля с низкой кардинальностью (status, plan_tier, country): слишком мало различных значений → несколько шардов выполняют большую часть работы.
- Изменяемые идентификаторы (email, изменяемые username): если ключ меняется, перенос данных между шардy становится дорогостоящим и рискованным.
Даже если поле с низкой кардинальностью удобно для фильтрации, оно часто превращает обычные запросы в scatter-gather, потому что соответствующие строки могут быть везде.
Реальный компромисс: удобство запросов vs качество распределения
Лучший ключ для балансировки нагрузки не всегда лучший для удобства продуктовых запросов.
- Если выбрать ключ, соответствующий основному паттерну доступа (например,
user_id), некоторые «глобальные» запросы (например, админские отчёты) станут медленнее или потребуют отдельного пайплайна.
- Если выбрать ключ, удобный для отчётности (например,
region), вы рискуете хотспотами и неравномерной ёмкостью.
Большинство команд проектируют под этот компромисс: оптимизируют ключ для самых частых и чувствительных по латентности операций, а остальное решают индексами, денормализацией, репликами или отдельными аналитическими таблицами.
Распространённые стратегии шардинга (Range, Hash, Directory)
Нет единственно «лучшего» способа шардирования. Выбранная стратегия определяет, как легко маршрутизировать запросы, насколько равномерно распределяются данные и какие паттерны доступа будут болью.
Range шардирование
При range шардировании каждый шард владеет непрерывным отрезком ключевого пространства — например:
- Шард A: customer_id 1–1 000 000
- Шард B: customer_id 1 000 001–2 000 000
Маршрутизация проста: посмотрел ключ — выбрал шард.
Проблема — хотспоты. Если новые пользователи всегда получают возрастающие ID, «последний» шард станет бутылочным горлышком по записям. Range чувствителен и к неравномерному росту (один диапазон популярен, другой тих). Плюс: range-запросы («все заказы с 1 по 31 октября») могут быть эффективными, потому что данные физически сгруппированы.
Hash шардирование
Hash шардирование прогоняет ключ через хеш-функцию и использует результат, чтобы выбрать шард. Это обычно равномернее распределяет данные и помогает избежать «всё идёт в новый шард».
Компромисс: range-запросы становятся проблемными: запрос «ID между X и Y» больше не мэпится на небольшой набор шардов, а может затронуть многие.
Практический момент, который недооценивают: консистентный хеш. Вместо прямого мэппинга на количество шардов (что перемешивает всё при добавлении шарда), многие системы используют hash-ring с «виртуальными нодами», чтобы при добавлении мощности перешли только часть ключей.
Directory (lookup) шардирование
Directory шардирование хранит явную мапу (lookup table/сервис) от ключа → локация шарда. Это наиболее гибко: можно поместить отдельных арендаторов на выделенные шарды, переместить одного клиента, не трогая всех, и поддерживать неравномерные размеры шардов.
Минус — дополнительная зависимость. Если справочник медленный, устаревший или недоступен, маршрутизация страдает — даже если сами шарды здоровы.
Составные ключи и суб-шардирование
Реальные системы часто смешивают подходы. Составной ключ (например, tenant_id + user_id) изолирует арендаторов и одновременно распределяет нагрузку внутри арендатора. Суб-шардирование похоже: сначала маршрутизируйте по тенанту, затем делайте хеш внутри группы шардов этого тенанта, чтобы один большой клиент не доминировал на одном шарде.
Как работают запросы: маршрутизация vs scatter-gather
Сравните стратегии шардинга
Быстро сравнивайте стратегии (range, hash, directory) в отдельных прототипах.
В шарди́рованной БД есть два принципиально разных пути выполнения запроса. Понять, по какому пути вы идёте, объясняет большинство сюрпризов в производительности и почему шардинг кажется непредсказуемым.
Запросы на один шард: быстрый путь
Идеальный результат — отправить запрос ровно на один шард. Если запрос содержит shard key (или что-то, что мэпится на него), систему можно отправить прямо в нужное место.
Поэтому команды стараются делать частые чтения «сознательными по shard key». Один шард означает меньше сетевых прыжков, проще исполнение, меньше блокировок и координации. Латентность в основном — это работа БД, а не «кластер спорит, кто обслужит».
Scatter-gather чтения: фан-аут и хвостовая латентность
Если запрос нельзя точно маршрутизировать (например, фильтр по полю, не являющемуся shard key), систему может распространить запрос по многим или всем шардaм. Каждый шард выполняет запрос локально, затем маршрутизатор (или координатор) объединяет результаты — сортирует, удаляет дубликаты, применяет лимиты и объединяет частичные агрегаты.
Такой фан-аут усиливает хвостовую латентность: даже если 9 шардов вернули быстро, один медленный держит весь запрос в заложниках. Это также умножает нагрузку: один пользовательский запрос превращается в N запросов к шардам.
Межшардовые JOIN’ы и агрегации
JOIN’ы между шардaми дороги, потому что данные, которые раньше пересекались «внутри» БД, теперь должны перемещаться между шардaми (или к координатору). Даже простые агрегации (COUNT, SUM, GROUP BY) могут потребовать двухфазного плана: частичные результаты на каждом шарде, затем объединение.
Ограничения индексации: локальные vs глобальные
Большинство систем по умолчанию используют локальные индексы: каждый шард индексирует только свои данные. Они дешевы в поддержке, но не помогают маршрутизации — поэтому запросы всё ещё могут рассылаться.
Глобальные индексы позволяют целевую маршрутизацию по полям, не являющимся shard key, но добавляют накладные записи на запись, дополнительную координацию и собственные проблемы масштабируемости и согласованности.
Записи и транзакции через шарды
Именно записи превращают шардинг из «просто масштабирования» в фактор, меняющий дизайн фич. Запись, касающаяся одного шарда, может быть быстрой и простой. Запись, затрагивающая несколько шардов, может быть медленной, подверженной ошибкам и неожиданно трудной для корректности.
Записи на один шард: счастливый путь
Если каждый запрос маршрутизируется на ровно один шард (обычно через shard key), БД использует обычную транзакционную механику. Вы получаете атомарность и изоляцию в пределах шарда, и большинство оперативных проблем похожи на знакомые одноузловые проблемы — только повторяются N раз.
Мультишардовые записи: где возникает сложность
Как только нужно обновить данные на двух шардах в одной «логической операции» (например, перевод денег, перемещение заказа между пользователями, обновление агрегата где-то ещё), вы попадаете в область распределённых транзакций.
Они сложны, потому что требуют координации между машинами, которые могут быть медленными, разделёнными сетью или перезапущены в любой момент. Протоколы вроде двухфазного коммита добавляют раунды обмена, могут блокироваться на таймаутах и делают ошибки неоднозначными: применил ли шард B изменение до смерти координатора? Если клиент повторяет запрос, не получится ли дублирование? Если не повторять — потеряете изменения?
Паттерны, уменьшающие мультишардовые записи
Несколько тактик сокращают необходимость в мультишардовых транзакциях:
- Локализация данных: колокализуйте связанные записи на одном шарде (например, всё, что связано с клиентом).
- Маршрутизация запросов: сделайте операцию «владением» одного шарда и относитесь к другим шардам как к входным (read-only).
- Денормализация: дублируйте небольшие куски данных, чтобы обновления не надо было рассылать.
Идемпотентность и безопасность повторов
В шарди́рованных системах ретраи неизбежны. Делайте записи идемпотентными, используя стабильные ID операций (например, ключ идемпотентности) и храня в базе маркеры «уже применено». Тогда при таймауте и повторной попытке вторая попытка становится no-op вместо двойного списания, дубликатного заказа или неконсистентного счётчика.
Согласованность и репликация: как сохранить данные корректными
Проверьте в среде, приближенной к продакшену
Разверните прототип и посмотрите, как маршрутизация и хвостовая задержка ведут себя при реальном трафике.
Шардинг разбивает данные по машинам, но не отменяет необходимость избыточности. Репликация — это то, что делает шард доступным при падении узла — и то, что усложняет ответ на вопрос «что истинно прямо сейчас?».
Репликация внутри каждого шарда
Большинство систем реплицируют внутри шарда: один primary (leader) принимает записи, и одна или несколько реплик копируют эти изменения. Если primary падает, систему продвигает реплику (failover). Реплики также могут обслуживать чтения, чтобы снизить нагрузку.
Компромисс — во времени. Реплика может отставать на миллисекунды или секунды. Этот разрыв нормален, но важен, если пользователь ожидает «я только что обновил — я должен это видеть».
Модели согласованности простыми словами
- Сильная согласованность: после успешной записи чтения будут её отражать (обычно чтение у лидера или ожидание подтверждения реплик).
- Eventual consistency (схождения): система со временем сходится, но чтение может временно возвращать устаревшие данные.
В шарди́рованных установках часто получается сильная согласованность внутри шарда и слабее гарантии между шардами, особенно при мультишардовых операциях.
«Единый источник правды», когда данные разделены
С шардингом «единый источник правды» обычно значит: для каждого кусочка данных есть одно авторитетное место записи (обычно лидер шарда). Но глобально нет одной машины, которая мгновенно подтвердит актуальность всего. У вас много локальных истин, которые нужно держать в согласии через репликацию.
Глобальные ограничения: уникальность, внешние ключи, счётчики
Ограничения сложнее, когда проверяемые данные живут на разных шардах:
- Уникальность (например, username): обеспечение «без дубликатов по всем шардам» может требовать централизованного индекса, выделенного шарда для ограничений или работы на уровне приложения (бронь/резервирование).
- Внешние ключи: если parent и child в разных шардах, БД не сможет легко обеспечить ссылочную целостность без межшардовой координации.
- Счётчики (глобальные итоги, последовательные ID): наивный подход создаст бутылочное горлышко. Распространённые решения: диапазоны по шардам, батчинг или принятие приближённых значений.
Эти решения — не детали реализации, они определяют, что для вашего продукта значит «корректно».
Ребалансировка и перешардинг без даунтайма
Ребалансировка — это то, что делает шарди́рованную БД управляемой по мере изменения реальности. Данные растут неравномерно, «сбалансированный» ключ уходит в сдвиг, вы добавляете узлы или списываете железо. Любое из этого может превратить один шард в бутылочное горлышко — даже если изначальный дизайн был идеальным.
Почему это сложно
В отличие от одноузловой БД, шардинг вплавляет локацию данных в логику маршрутизации. Когда вы перемещаете данные, вы меняете не только байты — вы меняете то, куда должны идти запросы. Ребалансировка — это не только про хранение, но и про метаданные и поведение клиентов.
Паттерн онлайн-миграции (copy → overlap → cutover)
Большинство команд стремятся к онлайн-воркфлоу без большого окна «остановки мира»:
- Копирование: фоновая подкачка данных на целевые шарды, пока система жива.
- Двойная запись (иногда двойное чтение): во время перехода новые изменения записываются и в старое, и в новое место. Чтения могут смотреть оба (или использовать правило «новое побеждает») до уверенности.
- Cutover: обновление карты шардов, чтобы маршрутизаторы/клиенты отправляли трафик в новое место.
- Очистка: остановка двойных записей, удаление старой копии, компактирование и освобождение пространства.
Карты шардов и поведение клиентов
Изменение карты шардов — событие, которое ломает кэшированные маршруты на клиентах. Хорошие системы относятся к метаданным маршрутизации как к конфигурации: версионность, частое обновление и чёткое поведение при обращении к перемещённому ключу (редирект, ретрай или прокси).
Операционные риски, которые нужно учитывать
Ребалансировка часто вызывает временное падение производительности (дополнительные записи, жаргон кэша, фоновые копии). Частичные переходы обычны — некоторые диапазоны мигрируют раньше других — поэтому нужны наблюдаемость и план отката (например, вернуть карту и стянуть двойные записи) перед cutover.
Хотспоты и сдвиг: когда «равномерное» перестаёт работать
Шардинг предполагает, что работа распределится. Удивительный момент: кластер может выглядеть «равномерно» по числу строк на бумаге, но вести себя крайне неравномерно в продакшне.
Горячие партиции (hot keys)
Хотспот — это когда небольшая часть ключевого пространства получает большую часть трафика: аккаунт знаменитости, популярный товар, тенант с тяжёлой батч-работой или временной ключ, где «сегодня» привлекает все записи. Если такие ключи попадают на один шард, он становится бутылочным горлышком, даже если остальные шарды простаивают.
Сдвиг: размер данных vs трафик
«Сдвиг» — не одно явление:
- Сдвиг по данным: один шард хранит больше байт/строк (давление по хранению, длинные бэкапы, медленные сканы).
- Сдвиг по трафику: один шард обрабатывает больше QPS или тяжёлых запросов (CPU насыщение, очередь, рост латентности).
Они не всегда совпадают. Шард с меньшим объёмом данных может быть самым горячим, если у него самые востребованные ключи.
Как быстро обнаружить
Не нужны сложные трассировки, чтобы заметить сдвиг. Начните с дашбордов по шардам:
- p95 задержки по шару (если p95 одного шарда уходит вверх — тревога)
- QPS (в т.ч. запись) по шару
- Использованное хранилище / размер таблиц по шару
Если у одного шарда растёт латентность вместе с QPS, пока другие стабильны — вероятен хотспот.
Смягчения
Исправления обычно меняют простоту на баланс:
- выбирайте ключ, который распределяет трафик, а не только записи
- добавляйте bucketing/salting для горячих ключей (разбивать логический ключ на несколько физических бакетов)
- используйте кэширование для прочитываемых горячих объектов
- применяйте rate limits или квоты по тенантам, чтобы защитить кластер
- разделяйте горячие шарды или перемещайте горячие диапазоны, когда шард не охлаждается
Режимы отказов и отладка в шарди́рованной системе
Заберите код
Сохраняйте полный контроль, экспортируя исходный код, когда дизайн вас устроит.
Шардинг добавляет не просто больше серверов — он добавляет больше способов, как что-то может пойти не так, и больше мест, где это искать. Многие инциденты — не «БД целиком упала», а «один шард упал» или «система не может договориться, где лежат данные».
Распространённые режимы отказа
Повторяющиеся паттерны:
- Шард недоступен (краш, диск заполнен, долгие паузы GC) → частичные аутеджи: некоторые клиенты работают, некоторые нет.
- Маршрутизатор неправильно маршрутизирует после изменения конфигурации или деплоя. Чтения могут молча возвращать пустые результаты, если отправлены не туда.
- Устаревшие или несогласованные метаданные (карта шардов). Во время миграций разные компоненты могут по-разному маршрутизировать один и тот же ключ.
- Частичные сетевые проблемы: таймауты между маршрутизаторами и подмножеством шардов выглядят как «случайные» ошибки и вызывают повторы, которые усиливают нагрузку.
Как меняется отладка
В одном узле вы хватаете один лог и смотришь метрики. В шарди́рованной системе нужно проследить запрос по нескольким шардам.
Используйте correlation IDs в каждом запросе и протягивайте их от API через маршрутизаторы к каждому шарду. Сопоставьте это с распределённым трейсингом, чтобы scatter-gather показывал, какой шард был медленным или упал. Метрики должны быть разложены по шардам (латентность, глубина очереди, rate ошибок), иначе горячий шард спрячется за средними по флоту.
Инциденты корректности данных
Ошибка шардинга часто проявляется как баги корректности:
- Дубликаты после ретраев или неидемпотентных записей.
- Пропавшие строки при миграции данных, когда маршрутизация всё ещё указывает на старое место.
- Split-brain записи, если два представления метаданных принимают записи для одного и того же диапазона.
Резервное копирование, восстановление и DR
«Восстановить базу» превращается в «восстановить много частей в правильном порядке». Возможно, нужно восстановить сначала метаданные, затем каждый шард и проверить границы и правила маршрутизации, чтобы соответствовать точке восстановления. DR-планы должны включать прогоны, доказывающие, что вы можете собрать консистентный кластер, а не только восстановить отдельные машины.
Когда не шардить: практические альтернативы и чеклист принятия решения
Шардинг часто воспринимают как «переключатель масштабирования», но это постоянное увеличение сложности системы. Если вы можете удовлетворить цели по производительности и надёжности без разбиения данных по узлам, вы обычно получите более простую архитектуру, легче отлаживаемую и с меньшим количеством эксплуатационных краёв.
Практические альтернативы, которые часто дают много воздуха
Перед шардингом попробуйте варианты, сохраняющие одну логическую БД:
- Лучшее индексирование + тюнинг запросов: исправьте медленные пути — отсутствующие индексы, неограниченные запросы, тяжёлые JOIN’ы и N+1.
- Кэширование: положите часто читаемые стабильные ответы за кэш (кэш на уровне приложения, CDN для публичного контента или in-memory кэш для горячих ключей).
- Read replicas: переложите чтение на реплики, не меняя путь записи (с принятием отставания реплик там, где это допустимо).
- Партиционирование таблиц в одном узле: многие БД поддерживают партицирование, улучшающее обслуживание и запросы без маршрутизации между узлами.
Где инструменты помогают: прототипирование шард-осведомлённых сервисов
Практичный способ снизить риск — прототипировать инфраструктуру (границы маршрутизации, идемпотентность, рабочие процессы миграции и наблюдаемость) до того, как переводить продакшн.
Например, с Koder.ai можно быстро поднять реалистичный сервис из чата — обычно React UI + Go backend с PostgreSQL — и поэкспериментировать с shard-key-aware API, ключами идемпотентности и поведением cutover в безопасном песочнике. Поскольку Koder.ai поддерживает режим планирования, снимки/откат и экспорт кода, вы можете итеративно отработать решения по маршрутизации и метаданным, а затем перенести код и рукописи в основную стек, когда будете уверены.
Когда шардинг подходит (и когда нет)
Шардинг лучше, когда объём данных или пропускная способность по записям явно превышают лимиты одного узла и ваши паттерны запросов надёжно используют shard key (минимум cross-shard JOIN’ов и scatter-gather запросов).
Он плохо подходит, когда продукт требует много ad-hoc запросов, частых мультиизменяемых транзакций, глобальных уникальных ограничений или когда команда не готова поддерживать операционную нагрузку (ребалансировка, перешардинг, реагирование на инциденты).
Короткий чеклист для решения
Спросите себя:
- Нагрузка: В чём узкое место — CPU, I/O, память или конкуренция блокировок — и можно ли это исправить без шардинга?
- Паттерны запросов: Можно ли маршрутизовать 90%+ критичных запросов по shard key?
- Возможности команды: Кто отвечает за карту шардов, runbook’и on-call и поведение при мультишардовых транзакциях?
- SLO: Можно ли терпеть частичную деградацию (один шард упал) и более длинные хвостовые задержки?
Планируйте рост, а не только диаграмму
Даже если вы отложите шардинг, спроектируйте путь миграции: выбирайте идентификаторы, которые не помешают будущему shard key, не хардкодьте допущения одного узла и репетируйте, как вы будете перемещать данные с минимальным даунтаймом. Лучшее время планировать перешардинг — до того, как он понадобился.