Что такое страница статуса SaaS (и почему это важно)
Страница статуса SaaS — это публичный (или доступный только клиентам) сайт, который показывает, работает ли ваш продукт прямо сейчас — и что вы делаете, если нет. Она становится единственным источником правды во время инцидентов, отдельно от соцсетей, тикетов поддержки и слухов.
Она помогает гораздо большему числу людей, чем вы можете ожидать:
- Клиенты быстро проверяют «У меня одного?» и решают ждать, повторить попытку или использовать обходной путь.
- Команды поддержки могут ссылаться на одно каноническое обновление вместо многократных объяснений в десятках тикетов.
- Отдел продаж и Customer Success могут проактивно управлять продлениями и ключевыми аккаунтами, опираясь на точные, помеченные временем данные.
Реальное состояние vs. история инцидентов vs. постмортемы
Хорошая страница статуса обычно содержит три связанные (но разные) пласты:
- Реальное состояние: что сейчас работает, не работает или деградирует по компонентам (API, панель, биллинг и т.д.).
- Страница истории инцидентов: хронология прошлых инцидентов и техобслуживаний, чтобы клиенты видели паттерны и понимали, что вопросы решались.
- Послеморты: подробные отчёты с объяснением корневой причины, исправлений и шагов по предотвращению. Их можно публиковать или делиться приватно с пострадавшими клиентами.
Цель — ясность: реальное состояние отвечает «Могу ли я пользоваться продуктом?», история отвечает «Как часто это случается?», а постмортемы отвечают «Почему это произошло и что изменилось?».
Управление ожиданиями: прозрачность, скорость и ясность
Страница статуса работает, когда обновления быстрые, на понятном языке и честно отражают масштаб воздействия. Вам не нужен идеальный диагноз, чтобы сообщать о проблеме. Нужны метки времени, зона влияния (кто пострадал) и время следующего обновления.
Типичные случаи использования
Ею пользуются при проставах, сниженной производительности (медленные логины, задержки webhook) и плановом техобслуживании, которое может вызвать кратковременные нарушения.
Если относиться к странице статуса как к продуктовой поверхности (а не одноразовой операционной странице), остальная настройка становится проще: можно определить ответственных, шаблоны и подключить мониторинг, не придумывая процесс заново в каждом инциденте.
Определите цели, аудиторию и владение
Прежде чем выбирать инструмент или макет, решите, что ваша страница статуса должна делать. Ясная цель и явный владелец — то, что сохраняет полезность страницы во время инцидента, когда все заняты и информация фрагментирована.
Определите цель (что значит «успех»)
Большинство SaaS-команд создают страницу статуса ради трёх практических результатов:
- Сократить тикеты поддержки, ответив на «Упало ли у всех?» в одном месте
- Построить доверие через своевременные обновления на понятном языке
- Ускорить коммуникацию между поддержкой, инженерами, продажами и Customer Success
Запишите 2–3 измеримых сигнала, которые можно отслеживать после запуска: меньше повторяющихся тикетов при сбоях, более быстрое время до первого обновления или рост числа подписчиков.
Определите аудиторию и уровень чтения
Основной читатель — обычно некогда технический клиент, который хочет знать:
- Работает ли продукт прямо сейчас?
- Что затронуто (вход, API, биллинг и т.д.)?
- Что мне делать дальше?
- Когда всё будет исправлено?
Это означает минимум жаргона. Предпочитайте «Некоторые клиенты не могут войти» вместо «Увеличение 5xx ошибок на auth». Если нужны технические детали, добавляйте их кратко как вторую строку.
Выберите тон, правила и владельца
Выберите тон, который сможете поддерживать под давлением: спокойный, фактический и прозрачный. Решите заранее:
- Кто может публиковать обновления (одна роль или ротация on-call)
- Кто утверждает обновления (если кто-то нужен) и сколько может занять согласование
- Минимальная частота обновлений при активном инциденте (например, каждые 30 минут)
Сделайте владение явным: страница статуса не должна быть «чужой обязанностью», иначе она станет ничьей.
Где её размещать
Есть два популярных варианта:
- Отдельный сайт (например, status.yourcompany.com): даёт ясное разделение и часто более устойчива к сбоям
- Подпуть (например, /status): проще с точки зрения брендинга и аналитики
Если основное приложение может упасть, обычно безопаснее отдельное доменное имя для страницы статуса. При этом можно ссылаться на неё из приложения и центра помощи (например, /help).
Составьте карту сервисов и модель статусов компонентов
Страница статуса полезна ровно настолько, насколько полезна «карта», стоящая за ней. Прежде чем выбирать цвета или писать текст, решите, о чём вы действительно сообщаете. Цель — отражать то, как клиенты ощущают продукт, а не структуру вашей организации.
Начните с инвентаризации компонентов
Перечислите части, которые клиент мог бы назвать при описании поломки. Для многих SaaS практичным стартовым набором будет:
- API
- Веб-приложение
- Панель / админка
- Аутентификация (вход, SSO)
- Платежи
- Интеграции (Slack, Salesforce, вебхуки и т.д.)
Если вы предлагаете несколько регионов или тарифов — зафиксируйте это тоже (например, «API – US» и «API – EU»). Делайте имена понятными клиентам: «Вход» яснее, чем «IdP Gateway».
Решите, как группировать компоненты
Выбирайте группировку, соответствующую тому, как клиенты думают о сервисе:
- По продукту: удобно, если у вас разные предложения (Продукт A vs Продукт B)
- По регионам: если доступность существенно отличается по географии
- По фиче/рабочему потоку: если клиенты зависят от конкретных задач (Отчёты, Импорты, Уведомления)
Старайтесь избегать бесконечных списков. Если интеграций десятки, рассмотрите один родительский компонент («Интеграции») плюс несколько ключевых дочерних («Salesforce», «Webhooks»).
Определите уровни статуса (и их смысл)
Простая и последовательная модель предотвращает путаницу во время инцидентов. Часто используют:
- Operational: работает как ожидалось
- Degraded Performance: медленнее обычного или периодические ошибки
- Partial Outage: значимая часть пользователей/фич недоступна
- Major Outage: сервис в целом недоступен
Задокументируйте внутренние критерии для каждого уровня (даже если не публикуете их). Например, «Partial Outage = один регион недоступен» или «Degraded = p95 latency выше X в течение Y минут». Последовательность укрепляет доверие.
Зафиксируйте зависимости — и решите, что показывать
Большинство сбоев вовлекают сторонние сервисы: облачный хостинг, доставку почты, платежных провайдеров или удостоверяющие сервисы. Задокументируйте эти зависимости, чтобы обновления были точными.
Публиковать их публично или нет — зависит от аудитории. Если клиенты напрямую затрагиваются (например, платежи), показывать зависимость полезно. Если это добавляет шум или провоцирует обвинения, храните зависимости внутренне, но упоминайте их в обновлениях при релевантности (например, «Мы расследуем повышенное число ошибок у нашего платежного провайдера").
Как только появится модель компонентов, остальная настройка страницы статуса станет проще: каждый инцидент получает понятный «где» (компонент) и «насколько серьёзно» (статус) с самого начала.
Дизайн простой и понятной страницы статуса
Страница статуса полезна, когда отвечает на вопросы клиента за секунды. Люди приходят в стрессовом состоянии и хотят ясности — не навигации по сайту.
Сначала то, что нужно клиенту
Приоритизируйте вверху страницы:
- Текущее состояние: работает/деградирует/падает
- Воздействие: что затронуто (кто/какие регионы/фичи) и что пользователь может заметить
- ETA (если есть): аккуратно — делитесь только теми оценками, которые можно подтвердить
- Время следующего обновления: конкретное обещание вроде «Следующее обновление к 14:30 UTC» уменьшает количество повторных тикетов
Пишите простым языком. «Повышенные ошибки API» понятнее, чем «Partial outage in upstream dependency». Если нужно техническое объяснение, добавьте короткий перевод («Некоторые запросы могут завершаться ошибкой или таймаутом»).
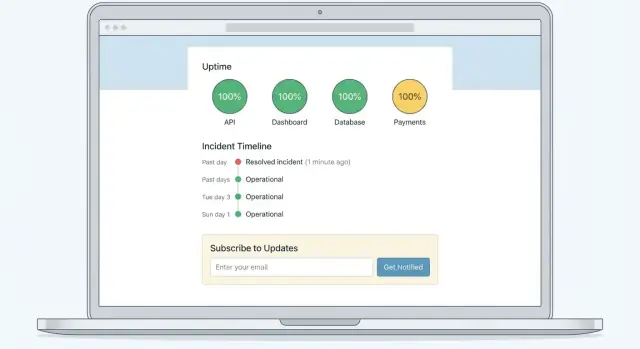
Простой, сканируемый макет
Надёжный шаблон:
- Верхний баннер с общим статусом (All Systems Operational / Degraded Performance / Major Outage)
- Список компонентов с понятными статусами (Веб, API, Платежи, Интеграции и т.д.)
- Активные инциденты и плановые работы под списком, отсортированные по времени последнего обновления
Для списка компонентов используйте клиентские ярлыки. Если внутренний сервис называется «k8s-cluster-2», клиентам нужен «API» или «Background Jobs».
Доступность и мобильность
Сделайте страницу читаемой в стрессовой ситуации:
- Контраст цветов и текстовые метки (не полагайтесь только на цвет)
- Чёткие и понятные иконки (зелёный = OK, жёлтый = деградация, красный = аврал)
- Мобильная адаптация и удобные зоны нажатия; многие проверяют статус с телефона
Быстрые ссылки там, где ожидают
Разместите небольшой набор ссылок вверху (в хедере или под баннером):
- Подписаться (email/SMS/webhook)
- История инцидентов
- Связаться с поддержкой по адресу /support
Цель — уверенность: клиент должен сразу понимать, что происходит, что затронуто и когда ждать следующего обновления.
Создайте шаблоны обновлений для инцидентов и техобслуживания
Когда случается инцидент, команда одновременно диагностирует, устраняет и отвечает на вопросы клиентов. Шаблоны убирают догадки, помогая обновлениям оставаться последовательными и быстрыми — особенно когда разные люди публикуют сообщения.
Какие поля всегда публиковать в инциденте
Хорошее обновление начинается с одних и тех же фактов. Минимум стандартизируйте эти поля, чтобы клиенты быстро понимали ситуацию:
- Время начала инцидента (с часовым поясом)
- Затронутые компоненты/сервисы (по вашей модели статусов)
- Влияние на клиентов (кого и как коснулось)
- Текущее состояние (Investigating, Identified, Monitoring, Resolved)
- Лог обновлений (записи с отметками времени)
- Время завершения (когда восстановлено по норме)
Если вы публикуете историю инцидентов, единообразие этих полей облегчает сканирование и сравнение прошлых событий.
Простой повторяемый шаблон обновления
Короткие обновления, отвечающие на одни и те же вопросы — лучше всего. Практический шаблон, который можно вставить в инструмент статуса:
Title: Краткое конкретное резюме (например, «Ошибки API в регионе EU»)
Start time: YYYY-MM-DD HH:MM (TZ)
Affected components: API, Dashboard, Payments
Impact: Что видят пользователи (ошибки, таймауты, снижение производительности) и кто затронут
What we know: Одно предложение о причине если подтверждена (избегайте спекуляций)
What we’re doing: Конкретные действия (откат, масштабирование, эскалация к вендору)
Next update: Время следующего сообщения
Updates:
- HH:MM (TZ) — Investigating: …
- HH:MM (TZ) — Identified: …
- HH:MM (TZ) — Monitoring: …
- HH:MM (TZ) — Resolved: …
Правила частоты обновлений
Клиенты хотят предсказуемости.
- Для крупных инцидентов — обновления каждые 30–60 минут, даже если это «Мы всё ещё расследуем; ETA нет; следующее обновление в X».
- Для незначительных проблем — реже, но всегда с обещанным временем следующего обновления.
- Если вы не можете соблюдать обещанную частоту, опубликуйте короткое сообщение о задержке и обновите ожидания.
Шаблоны для планового техобслуживания
Плановые работы должны выглядеть спокойно и структурированно. Стандартизируйте посты о техобслуживании с полями:
- Окно обслуживания: время начала/окончания (с часовым поясом)
- Ожидаемое влияние: none / degraded / intermittent / downtime
- Затронутые компоненты
- Действия со стороны клиентов (если есть): «Действий не требуется» или чёткие шаги
- Напоминание: короткое сообщение при начале и при завершении работ
Держите язык точным (что меняется, что клиенты заметят) и не давайте неоправданных обещаний — клиенты ценят точность больше, чем чрезмерный оптимизм.
Постройте историю инцидентов, которая легко читается
Страница истории инцидентов — больше, чем журнал. Это способ быстро понять, как часто происходят проблемы, какие типы инцидентов повторяются и как вы отвечаете.
Зачем нужна история инцидентов
Чистая история укрепляет доверие за счёт прозрачности. Она также показывает тренды: если вы видите повторяющиеся инциденты «Задержки API» каждые несколько недель, это сигнал вложиться в производительность и процесс послемортемов. Со временем последовательная отчётность сокращает тикеты, потому что клиенты сами находят ответы.
Выберите период хранения
Подберите окно хранения, подходящее для ожиданий клиентов и зрелости продукта:
- 90 дней: распространённый выбор для ранних стартапов, держит страницу лёгкой
- 6–12 месяцев: лучше для корпоративных клиентов, оценивающих надёжность
- Дольше: можно экспортировать старые записи в отдельный архив, если временная шкала становится шумной
Чётко указывайте период хранения (например, «История инцидентов хранится 12 месяцев").
Сделайте каждую запись понятной сразу
Последовательность упрощает сканирование. Используйте предсказуемый формат:
YYYY-MM-DD — Краткий заголовок (например, «2025-10-14 — Задержка доставки писем»)
Для каждого инцидента показывайте минимум:
- затронутые компоненты
- время начала/окончания (с часовым поясом)
- уровень влияния (minor/major)
- короткая заметка о решении
Ссылки на подробности
Если публикуете постмортемы, ставьте ссылку из карточки инцидента (например: «Читайте постмортем» со ссылкой на /blog/postmortems/2025-10-14-email-delays). Это сохраняет хронологию чистой и даёт детали тем, кто хочет их увидеть.
Добавьте подписки и уведомления
Страница статуса полезна, когда клиенты о ней не забывают. Подписки превращают реактивный просмотр в проактивные уведомления: клиенты получают обновления автоматически.
Предлагайте каналы, которые уже используются
Обычно достаточно пары вариантов:
- Email (по умолчанию для многих)
- SMS (для срочных высокосигнальных оповещений)
- Slack или Microsoft Teams (для корпоративных клиентов и ops-команд)
- RSS/Atom (для технических пользователей и внутреннего тулкита)
Если поддерживаете несколько каналов, упростите процесс подписки, чтобы клиенты не чувствовали, что подписываются четырьмя разными способами.
Сделайте подтверждение и настройки понятными
Подписки всегда должны быть по желанию. Ясно объясните, что люди получат — особенно для SMS.
Дайте подписчикам контроль над:
- Областью подписки: все обновления или выбор отдельных компонентов (например, «API», но не «Маркетинг сайт»)
- Типом: только инциденты, только техобслуживание или оба
- Серьёзностью (опционально): только «Major outage» или «все обновления»
Эти настройки уменьшают усталость от уведомлений и сохраняют доверие к оповещениям. Если нет подписки по компонентам, начните с «Все обновления» и добавляйте фильтры позже.
Не допускайте отказа уведомлений в момент, когда они нужны
Во время инцидента объём сообщений растёт, и провайдеры могут троттлить трафик. Проверьте:
- Доставляемость: SPF/DKIM/DMARC для email; верифицированные домены отправителей; знакомые адреса в поле From
- Ограничения скорости: лимиты провайдера email/SMS, лимиты вебхуков Slack/Teams и поведение ретраев
- Запасные варианты: если Slack-публикации падают, отсылаете ли вы email? Если SMS задерживаются, показываете ли вы баннер на странице статуса?
Стоит запускать тесты подписок хотя бы ежеквартально, чтобы убедиться, что всё работает как положено.
Поставьте «Подписаться» там, где его не пропустят
Разместите заметный блок подписки вверху страницы статуса — лучше «above the fold», чтобы клиенты могли подписаться до следующего инцидента. Сделайте видимым на мобильных устройствах и разместите ссылку на странице помощи или в футере приложения.
Выберите способ реализации: хостинг или DIY
Выбор способа сборки страницы статуса зависит от того, что вы хотите оптимизировать: скорость запуска, доступность в момент сбоя и усилия по поддержке.
Вариант 1: Использовать hosted-инструмент
Hosted-инструмент — самый быстрый путь. Вы получаете готовую страницу, подписки, хронологию инцидентов и часто интеграции с мониторингом.
На что обратить внимание в hosted-инструменте:
- Надёжность и независимость: страница должна быть доступна, даже если ваше приложение упало
- API и автоматизация: создание инцидентов, обновление компонентов и публикация прогресса через API/webhooks
- Контроль доступа: роли публикующих и черновики; SSO — бонус
- Брендинг и кастомный домен: логотип/цвета и домен вроде status.yourcompany.com
- Аналитика: число подписчиков, просмотры обновлений и метрики доставки email
- Соответствие требованиям: журналы аудита и политики хранения, если вы в регулированной среде
Вариант 2: Сделать своими силами (DIY)
DIY подходит, если вам нужен полный контроль над дизайном, данными и представлением истории. Компромисс — вы сами отвечаете за надёжность.
Практичная DIY-архитектура:
- Статический сайт (быстрый, кэшируемый) для UI и страниц истории
- API-слой или лёгкая CMS для хранения инцидентов, компонентов и обновлений
- Агрессивное кэширование + CDN, чтобы страница оставалась быстрой при пиковых нагрузках
Если хостите сами, продумайте варианты отказа: что, если база данных недоступна или пайплайн деплоя сломается? Многие команды держат страницу статуса на отдельной инфраструктуре (или даже у другого провайдера), отличной от основного продукта.
Если хотите контроля DIY, но не хотите всё строить с нуля, платформа для кодинга вроде Koder.ai может помочь быстро поднять кастомный статус-сайт (веб-UI плюс небольшой инцидентный API) по чат-спеку. Это удобно для команд, которые хотят кастомную модель компонентов, UX истории инцидентов или внутренние админ-потоки — и при этом иметь возможность экспортировать код и быстро деплоить.
Планирование затрат
Hosted-инструменты обычно имеют предсказуемую месячную стоимость; DIY требует времени инженеров, хостинга/CDN и поддержки. Сравнивайте ожидаемые ежемесячные расходы и внутреннее время, а затем сверяйте их с бюджетом (см. /pricing).
Подключите мониторинг и рабочий процесс инцидентов
Страница статуса полезна, если быстро отражает реальность. Проще всего добиться этого, если связать системы, которые обнаруживают проблемы (мониторинг), и те, что координируют ответ (инцидент-менеджмент), чтобы обновления были согласованными и своевременными.
Откуда должны поступать обновления
Обычно команды комбинируют три источника данных:
- Сигналы мониторинга (health checks, синтетические тесты, уровни ошибок, задержки, глубина очереди). Они хороши для детекции, но не всегда описывают влияние на клиентов.
- Ручные обновления от on-call или команды поддержки. Люди добавляют контекст: кто затронут, какой обходной путь и что поменялось.
- Инструменты управления инцидентами (PagerDuty, Opsgenie, Jira Service Management и т.д.). Они дают таймлайн, роли и заметки по разрешению, которые страница статуса может суммировать.
Практическое правило: мониторинг обнаруживает; инцидентный рабочий процесс координирует; страница статуса коммуницирует.
Автоматизация, которая помогает (но не обещает лишнего)
Автоматизация экономит минуты в критический момент:
- Создавайте инцидент по сигналу высокой серьёзности (например, «ошибка API > 5% за 5 минут»). Предзаполняйте заголовок, компоненты и начальную серьёзность.
- Обновляйте статусы компонентов по health checks для объективных сигналов (например, «Web app: Degraded Performance», когда превышены пороги latency).
- Синхронизируйте смену статуса в канале инцидента (Slack/Teams), чтобы ответственные видели то же, что и клиенты.
Первое публичное сообщение держите консервативным. «Исследуем повышенные ошибки» безопаснее, чем «Авария подтверждена», пока идёт верификация.
Не делайте всё автоматом без проверки человеком
Полностью автоматические сообщения могут навредить:
- Шумный алерт может создать ложный инцидент.
- Частичная деградация может выглядеть как «down» для одного монитора, но не влиять на клиентов.
- Авто‑резолв может закрыть инцидент, пока пользователи ещё испытывают проблемы.
Используйте автоматизацию для черновиков и предложений, но требуйте человека для утверждения клиент-ориентированной формулировки — особенно при переходе в состояния Identified, Mitigated, Resolved.
Ведите аудит изменений
Относитесь к странице статуса как к публичному журналу. Убедитесь, что вы можете ответить:
- Кто изменил статус инцидента?
- Что именно было изменено (текст, компоненты, метки времени)?
- Когда это произошло?
Аудит помогает в послемортемах, облегчает передачу обязанностей и повышает доверие, когда клиенты просят подробности.
Сделайте страницу надёжной: хостинг, DNS и защита от падений
Страница статуса помогает только если доступна в момент падения продукта. Частая ошибка — разместить страницу статуса на той же инфраструктуре, что и приложение: когда приложение падает, исчезает и статус-страница, оставляя клиентов без источника правды.
Изолируйте её от основного стека
По возможности размещайте страницу статуса у другого провайдера, чем продукт (или хотя бы в другой учётной записи/регионе). Цель — разделение радиуса поражения: сбой платформы приложения не должен лишать вас коммуникации.
Также продумайте отдельный DNS. Если основной DNS управляется там же, где edge/CDN приложения, проблема с DNS или сертификатом может заблокировать и то, и другое. Многие команды используют отдельный поддомен (например, status.yourcompany.com) с независимым хостингом DNS.
Сделайте страницу быстрой и устойчивой
Минимизируйте зависимости: минимум JavaScript, сжатые CSS и отсутствие вызовов в API приложения для базовой отрисовки. Поставьте CDN и включите кэширование статики, чтобы страница загружалась даже при пиковом трафике.
Практический запасной вариант — статический fallback режим:
- предрендерьте последний известный статус и баннер инцидента
- храните его в object storage или статическом хостинге
- обновляйте динамически, когда системы здоровы, но при деградации отдавайте предрендерённую страницу
Публично по умолчанию, с безопасным админ-доступом
Клиентам не нужно логиниться, чтобы увидеть состояние сервиса. Держите страницу публичной, а админ‑инструменты — за аутентификацией (SSO при наличии), с сильным контролем доступа и логированием.
Наконец, тестируйте сценарии отказа: временно блокируйте origin приложения в staging и проверьте, что страница статуса по-прежнему резолвится, быстро загружается и её можно обновлять в критический момент.
Операционный процесс: кто обновляет и когда
Страница статуса сохраняет доверие только если её регулярно обновляют в реальных инцидентах. Это не происходит случайно — нужны чёткое владение, простые правила и предсказуемый ритм.
Определите роли заранее
Держите маленькую и явную команду:
- Incident Commander (IC): управляет ответом, решает приоритеты и подтверждает стабильность
- Communications Lead: публикует обновления и делает их понятными для клиентов
- Инженеры на дежурстве: расследуют, устраняют и донесут подтверждённые факты до IC
В маленьких командах один человек может совмещать роли — просто решите это заранее. Задокументируйте передачу обязанностей и пути эскалации в on-call handbook (см. /docs/on-call).
Простой чеклист для обновлений
Когда алерт превращается в инцидент с влиянием на клиентов, следуйте повторяемому потоку:
- Подтвердить: быстро опубликовать «Investigating» (даже если деталей мало)
- Оценить влияние: подтвердить, какие компоненты/регионы/сегменты клиентов затронуты
- Опубликовать обновление: что замечает пользователь, обходные пути (если есть) и когда будет следующее обновление
- Восстановить: подтвердить восстановление и что вы мониторите
- Резюмировать: добавить краткое резюме и ссылку на полный разбор, когда он будет готов
Практическое правило: опубликовать первое обновление в течение 10–15 минут, затем каждые 30–60 минут, пока есть влияние — даже если сообщение «Без изменений, всё ещё расследуем».
После разрешения: обзор и улучшения
В течение 1–3 рабочих дней проведите лёгкий post-incident review:
- Таймлайн: ключевые события от детекции до восстановления
- Корневая причина (наилучшее известное объяснение): простым языком
- Действия: конкретные исправления, ответственные и сроки
Затем обновите запись инцидента финальным резюме, чтобы история была полезной, а не просто журналом «resolved» сообщений.
Чеклист запуска и постоянного улучшения
Страница статуса полезна, если её легко найти, ей доверяют и её регулярно обновляют. Перед анонсом выполните «production-ready» проверку — затем настройте лёгкий цикл улучшений.
Чеклист запуска (практичный)
Текст и структура
- Проверьте, что имена компонентов понятны клиентам (например, «Панель», а не внутренние имена).
- Добавьте краткое «Что показывает эта страница» и ссылку на поддержку (/support) для аккаунт-специфичных вопросов.
- Убедитесь, что обновления объясняют влияние на клиента (например, «платежи не проходят») и дают следующие шаги (например, «повторите попытку через 10 минут»).
Брендинг и доверие
- Добавьте логотип, favicon и простую цветовую схему для статусов (избегайте слишком тонких оттенков).
- Включите понятный формат меток времени и часовой пояс.
Доступ и права
- Проверьте, кто может публиковать инциденты, плановые работы и менять настройки.
- Настройте резерв on-call, чтобы публикации не блокировались одним человеком.
Протестируйте рабочий процесс
- Проведите тестовый инцидент (пометьте его как тест и закройте).
- Подпишитесь через email/SMS и убедитесь, что уведомления приходят с корректными ссылками.
Анонс
- Добавьте ссылку на страницу статуса в футер приложения, центр помощи и автоответы поддержки.
- Отправьте короткое сообщение клиентам с объяснением, чего ожидать и как подписаться.
Если строите свой сайт статуса, выполните тот же чеклист в staging. Инструменты вроде Koder.ai помогут ускорить цикл: сгенерировать UI, админ-панели и бэкенд из одной спецификации, а затем экспортировать код и быстро деплоить.
Измеряйте улучшения
Отслеживайте несколько простых метрик и пересматривайте их ежемесячно:
- Снижение тикетов: сравните объём тикетов по инцидентам до и после запуска
- Быстрее первое обновление: время от детекции до первого публичного сообщения
- Рост подписчиков: число подписчиков по каналам и компоненты, за которыми они следят
Учитесь на паттернах инцидентов
Ведите простую таксономию, чтобы история была действенной:
- Тегируйте инциденты по категории (производительность, частичный сбой, сторонний сервис, техобслуживание, безопасность)
- Фиксируйте повторяющиеся компоненты и «частых виновников»
- Используйте это для приоритетизации исправлений и улучшения процесса послемортемов
SEO-основы (чтобы клиенты находили нужную страницу)
- Используйте понятные заголовки типа «Service Status» и «Incident History».
- Держите структуру заголовков (H2/H3) для удобного сканирования.
- Предпочитайте индексируемые страницы истории инцидентов (если нет соображений безопасности/конфиденциальности) и обеспечьте доступные ссылки между главной страницей статуса и деталями инцидентов.
Со временем небольшие улучшения — понятнее формулировки, более частые обновления, лучшая категоризация — аккумулируются в меньшее число прерываний, меньше тикетов и больше доверия клиентов.