Определите зону ответственности и потребности пользователей
Прежде чем проектировать экраны или выбирать парсер файлов, четко поймите, кто перемещает данные в ваш продукт и зачем. Веб‑приложение для импорта данных, рассчитанное на внутренних операторов, будет сильно отличаться от самообслуживаемого Excel‑импортера для клиентов.
Кто пользователи?
Начните с перечисления ролей, которые будут работать с импортами/экспортами:
- Администраторы: настраивают маппинги, правила и права
- Операторы: регулярно запускают импорты и обрабатывают исключения
- Клиенты: загружают собственные CSV/Excel и ожидают понятных подсказок
Для каждой роли опишите ожидаемый уровень навыков и допустимую сложность. Клиентам обычно нужно меньше опций и гораздо больше объяснений прямо в продукте.
Основные сценарии (и что значит «готово»)
Опишите ключевые сценарии и приоретизируйте их. Общие кейсы:
- Первичная массовая загрузка при онбординге (большие объёмы, грязные данные)
- Периодическая синхронизация (еженедельно/ежемесячно, важна согласованность)
- Единичные экспорты для отчётов, миграции или бэкапа
Определите метрики успеха: меньше неудачных импортов, более быстрое время на исправление ошибок, меньше тикетов «мой файл не загружается». Эти метрики помогут принимать решения (например, вкладываться в более понятные сообщения об ошибках vs. поддерживать больше форматов файлов).
Форматы, лимиты и соответствие
Будьте конкретны в том, что вы поддерживаете с первого дня:
- Форматы файлов: CSV, Excel (XLSX), JSON
- Максимальный размер файла и лимиты по строкам (и что происходит при превышении)
- Ожидания по кодировке (например UTF‑8) и правила по часовым поясам для дат
Раннее определение требований по соответствию: содержится ли PII в файлах, требования по хранению (как долго держите загрузки), требования по аудиту (кто, что и когда импортировал). Эти решения влияют на хранение, логирование и права доступа во всей системе.
Выбор архитектуры и стека технологий
Прежде чем думать о навороченном UI для сопоставления колонок или правилах валидации CSV, выберите архитектуру, которую команда сможет надежно поддерживать и развивать. Импорт/экспорт — это «скучная» инфраструктура: скорость итераций и простота отладки важнее новизны.
Начните со стека, который команда уже знает
Любой мейнстрим-стек подойдет. Выбирайте исходя из существующих навыков и возможностей найма:
- React + Node (TypeScript) — один язык по всему стеку и сильная экосистема для фоновых задач.
- Django — «батарейки включены», зрелый ORM и быстрая доставка.
- Rails — соглашения, быстрый CRUD и отлаженные паттерны фоновых заданий.
Главное — последовательность: стек должен позволять легко добавлять новые типы импортов, правила валидации и форматы экспорта без переписываний.
Если нужно ускорить прототипирование, платформы вроде Koder.ai могут помочь: опишите поток импорта (upload → preview → mapping → validation → background processing → history) в чате, сгенерируйте React UI с backend на Go + PostgreSQL и быстро итерационируйте с помощью планирования и снапшотов.
Хранение: разделяйте «сырой файл» и «нормализованные записи»
Используйте реляционную базу данных (Postgres/MySQL) для структурированных записей, upsert’ов и аудита изменений.
Исходные загрузки (CSV/Excel) храните в объектном хранилище (S3/GCS/Azure Blob). Сохранение сырого файла бесценно для поддержки: можно воспроизвести проблемы парсинга, перезапустить джобы и объяснить решения по обработке ошибок.
Решите, как будут запускаться импорты
Небольшие файлы можно обрабатывать синхронно (upload → validate → apply) для более отзывчивого UX. Для крупных файлов вынесите работу в фоновые задания:
- upload → enqueue job → показывать прогресс/историю → уведомлять по завершении
Это также позволяет реализовать ретраи и троттлинг записей.
Мультиарендность vs одноарендная модель
Если вы строите SaaS, решите заранее, как отделять данные арендаторов (скоуп на уровне строк, отдельные схемы или отдельные БД). Это влияет на API экспорта, права доступа и производительность.
Нефункциональные требования, которые стоит задокументировать сейчас
Опишите таргеты по аптайму, макс. размеру файла, ожидаемому числу строк на импорт, времени выполнения и лимитам по стоимости. Эти цифры влияют на выбор очередей, стратегию батчинга и индексирования — задолго до того, как вы начнёте полировать UI.
Постройте поток приёма импорта
Поток приёма задаёт тон для всего импорта. Если он предсказуем и снисходителен к ошибкам, пользователи будут пытаться снова, а количество обращений в поддержку упадёт.
Точки входа: загрузка в UI и API
Предложите зону drag-and-drop и классический файловый селектор в веб‑интерфейсе. Drag-and-drop быстрее для продвинутых пользователей, а селектор привычнее и доступнее.
Если клиенты импортируют из других систем, добавьте API‑эндпоинт. Он может принимать multipart‑загрузки (файл + метаданные) или использовать пред‑подписанные URL для крупных файлов.
Безопасный парсинг: заголовки, кодировки и сэмплинг
При загрузке делайте лёгкий парсинг для формирования «предпросмотра» без фиксации данных:
- Определяйте заголовки и показывайте выборку строк (например, первые 20–100)
- Обрабатывайте распространённые кодировки (UTF‑8, UTF‑16) и разделители (запятая, таб, точка с запятой)
- Нормализуйте переносы строк и убирайте очевидные форматные артефакты
Этот предпросмотр используется на шагах сопоставления колонок и валидации.
Храните оригинальный файл для повтора
Всегда сохраняйте оригинал в безопасном месте (обычно объектное хранилище). Держите его неизменяемым, чтобы:
- Повторно запускать импорт при изменении правил валидации
- Исследовать баги с точным входом
- Давать опцию «скачать оригинал» из истории импортов
Фиксируйте метаданные с первого дня
Относитесь к каждой загрузке как к полноценной сущности. Сохраняйте метаданные: загрузивший пользователь, временная метка, исходная система, имя файла и checksum (для детектирования дубликатов и проверки целостности). Это крайне полезно для аудита и отладки.
Быстрые предварительные проверки, чтобы не тратить время пользователя
Выполняйте быстрые pre‑checks и досрочно отклоняйте явно неверные файлы:
- Тип файла и ограничения по размеру
- Базовая читаемость (парсится ли файл?)
- Наличие обязательных колонок (для данного типа импорта)
Если pre‑check падает, возвращайте понятное сообщение и подсказки по исправлению. Цель — быстро блокировать действительно плохие файлы, не мешая валидным, но неидеальным данным, которые можно сопоставить или очистить позже.
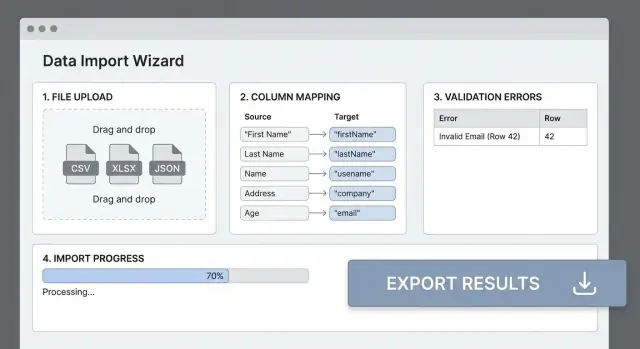
Добавьте сопоставление колонок и трансформации
Большинство ошибок импорта происходят потому, что заголовки файлов не совпадают с полями приложения. Ясный шаг сопоставления колонок превращает «грязный CSV» в предсказуемый ввод и спасает пользователей от метода тыка.
UI сопоставления, который понятен людям
Показывайте простую таблицу: Source column → Destination field. Автодетектируйте вероятные совпадения (с учётом регистра, синонимов вроде “E-mail” → email), но всегда давайте возможность изменить вручную.
Добавьте удобства:
- Помечайте обязательные поля и показывайте, сопоставлены ли они
- Позвольте «Ignore this column» для ненужных данных
- Подсвечивайте несопоставленные колонки, чтобы пользователи ничего не пропустили
Сохраняемые шаблоны сопоставлений (на клиента или набор данных)
Если клиенты регулярно импортируют одинаковый формат, сделайте это в один клик. Позвольте сохранять шаблоны для:
- аккаунта/клиента
- типа набора данных (например, Контакты vs. Счета)
- опционально, для конкретной интеграции или источника
При загрузке нового файла предлагайте шаблон на основе пересечения колонок. Поддерживайте версионирование, чтобы пользователи могли обновлять шаблон без поломки старых запусков.
Трансформации: делайте данные пригодными для схемы
Добавьте лёгкие трансформации для каждого сопоставленного поля:
- тримминг пробелов; пустые строки → null
- парсинг дат (MM/DD/YYYY vs. DD.MM.YYYY) с опциями таймзоны
- нормализация валют (например, “$1,200.00” → 1200.00 + валюта)
- enum‑нормализация (например, “Active”, “enabled”, “1” → ACTIVE)
- разделение/объединение полей (Full Name → First/Last или наоборот)
Делайте трансформации явными в UI ("Applied: Trim → Parse Date"), чтобы выход был объяснимым.
Предпросмотр перед подтверждением
Перед обработкой полного файла показывайте предпросмотр сопоставленных результатов для (например) 20 строк. Отображайте оригинальное значение, преобразованное значение и предупреждения (например, “Could not parse date”). Здесь пользователи ловят ошибки рано.
Обнаружение дубликатов и ключевых полей
Попросите пользователя выбрать ключевое поле (email, external_id, SKU) и объясните, что произойдёт при дубликатах. Даже если вы поддерживаете upsert позже, этот шаг задаёт ожидания: можно предупредить о дубликатах в файле и предложить правило «побеждает первая/последняя строка» или «ошибка».
Проектируйте систему валидации
Валидация — это то, что отличает простой «загрузчик файлов» от функционала импорта, которому доверяют. Цель не в излишней строгости, а в предотвращении распространения плохих данных и в предоставлении понятной, действенной обратной связи.
Разделите валидацию на уровни
Рассматривайте валидацию как три разных проверки, каждая с собственной целью:
- Схема (типы & обязательные поля): “email — строка?”, “amount — число?”, “customer_id — присутствует?” Быстрая проверка, которую можно выполнить сразу после парсинга.
- Бизнес‑правила: “Amount должен быть положительным”, “Status должен быть в списке Active/Paused”, “Start date не может быть в прошлом.” Эти правила отражают логику продукта.
- Кросс‑филд и реляционные правила: “Если
country=US, поле state обязательно”, “end_date должен быть после start_date”, “Название плана должно существовать в этой рабочей области.” Часто требуют контекста (другие колонки или проверки по БД).
Разделение делает систему расширяемой и проще для объяснения в UI.
Строгий vs лояльный режим (и почему это важно)
Решите заранее, должен ли импорт:
- Проваливать весь файл (строгий режим): подходит для финансовых данных или прав, где частичные обновления рискованны.
- Частично принимать валидные строки (лояльный режим): подходит для больших списков, где пользователи готовы исправлять только проблемные записи.
Можно поддержать оба: строгий по умолчанию и опция «Allow partial import» для админов.
Ошибки для людей (с ссылкой на строку/колонку)
Каждая ошибка должна отвечать: что случилось, где и как это исправить.
Пример: “Строка 42, колонка ‘Start Date’: должно быть корректной датой в формате YYYY‑MM‑DD.”
Различайте:
- Errors: блокируют обработку для строки (или для всего файла в строгом режиме)
- Warnings: допустимы, но подсвечены (например, “Неизвестный department; останется пустым”)
Обеспечьте цикл «исправил → перезагрузил»
Пользователи редко всё исправляют с первого раза. Сделайте повторную загрузку удобной: сохраняйте результаты валидации, позволяйте загружать скорректированный файл и предоставляйте скачиваемые отчёты об ошибках (см. ниже), чтобы исправлять массово.
Движок правил: настраиваемый там, где нужно, кодом там, где безопаснее
Практичный подход — гибрид:
- Настраиваемые правила для требований арендатора (например, “Employee ID должен быть уникален в рамках рабочего пространства”).
- Правила в коде для ключевых инвариантов продукта (например, границы прав доступа, обязательные связи), чтобы избежать неправильной конфигурации.
Это даёт гибкость без превращения системы в тяжёлую для отладки «паутину настроек».
Надёжная обработка и ретраи
Начните с рабочего шаблона
Создайте рабочее веб-приложение для импорта данных и затем шаг за шагом уточняйте сопоставления и преобразования.
Импорты обычно падают по скучным причинам: медленная база, пики загрузки или одна «плохая» строка, блокирующая весь батч. Надёжность — это вынос тяжёлой работы из синхронного пути и обеспечение безопасного повторного запуска.
Используйте фоновые задания для больших файлов
Парсинг, валидацию и запись выполняйте в фоновых работах (очереди/воркеры), чтобы загрузки не утыкались в таймауты веба. Это также позволяет масштабировать воркеров независимо по мере роста объёмов.
Практичный паттерн — разбивать работу на чанки (например, по 1 000 строк). «Родительская» джоба планирует чанковые задания, агрегирует результаты и обновляет прогресс.
Отслеживайте явные состояния и переходы
Моделируйте импорт как конечный автомат, чтобы UI и ops всегда понимали текущее состояние:
- queued → running → completed
- queued/running → failed (с причиной)
- queued/running → canceled (пользователь или система)
Храните временные метки и счётчик попыток по каждому переходу, чтобы отвечать на вопросы «когда началось?» и «сколько было попыток?» без лезания в логи.
Прогресс, которому можно доверять
Показывайте измеримый прогресс: обработано строк, осталось строк и найдено ошибок. Если можно оценить throughput, добавляйте грубое ETA — например, “~3 мин” вместо точного обратного отсчёта.
Сделайте обработку идемпотентной (безопасной для повторов)
Ретраи не должны создавать дубликаты или дублировать обновления. Распространённые техники:
- Используйте import_id + row_number (или хеш строки) как стабильный идемпотентный ключ.
- Upsert по натуральному ключу (external_id) вместо всегда insert.
- Пишите транзакционно по чанку, чтобы частичные ошибки не портили состояние.
Троттлинг для защиты всех пользователей
Ограничивайте одновременные импорты на рабочую область и троттлите тяжёлые записи (макс N строк/сек), чтобы не перегружать базу и не ухудшать опыт других пользователей.
Отчёты об ошибках и история импортов
Если люди не понимают, что пошло не так, они будут повторять загрузку до тех пор, пока не сдадутся. Относитесь к каждому импорту как к полноценному запуску с понятным следом и действенными ошибками.
Создайте запись «import run»
Начните с создания сущности import run в момент отправки файла. Она должна фиксировать:
- Кто инициировал (пользователь + организация)
- Что импортировалось (имя файла, размер, checksum, тип сущности)
- Когда (время начала/окончания)
- Как это интерпретировалось (конфигурация маппинга, версия трансформаций)
- Результат (success/failed/partial, обработано строк, отклонено строк)
Это и будет экраном истории импорта: список запусков с их статусом, счётчиками и страницей «просмотреть детали».
Храните ошибки на уровне строки (не только логи)
Логи хороши для инженеров, но пользователям нужны запросуемые ошибки. Храните структуру ошибок, привязанную к запуску импорта:
- Row-level: номер строки, первичный идентификатор (если найден), снимок raw‑значений
- Field-level: имя колонки, код ошибки (например, REQUIRED, INVALID_DATE), человеко‑читаемое сообщение, степень серьёзности
Такая структура даёт быстрые фильтры и агрегаты, например “Top 3 типа ошибок за неделю”.
Делайте ошибки удобными: UI + скачиваемый отчёт
На странице деталей запуска предоставьте фильтры по типу, колонке и серьёзности, а также поиск (например, “email”). Затем предложите скачиваемый CSV‑отчёт об ошибках, включающий оригинальную строку и дополнительные колонки вроде error_columns и error_message, с четкими рекомендациями: “Исправьте формат даты на YYYY‑MM‑DD.”
Добавьте режим dry run
«Dry run» валидирует всё с тем же маппингом и правилами, но не записывает данные. Отлично подходит для первых импортов и позволяет безопасно итерационировать перед фиксацией изменений.
Модель данных, upsert’ы и аудит
Сохраняйте владение исходниками
Когда будете готовы, экспортируйте исходный код и продолжайте в обычном рабочем процессе.
Импорты «готовы», когда строки попали в БД — но долгосрочные расходы часто связаны с обновлениями, дубликатами и неясной историей изменений. Здесь речь о проектировании модели так, чтобы импорты были предсказуемыми, откатываемыми и объяснимыми.
Решите: создавать, обновлять или и то, и другое
Для каждой сущности определите, как строка из импорта мапится на доменную модель и может ли импорт:
- Только создавать новые записи
- Только обновлять существующие
- Делать и то, и другое (частый кейс в SaaS)
Это должно быть явно указано в настройках импорта и сохранено вместе с джобом, чтобы поведение было воспроизводимо.
Выберите ключи для upsert и правила коллизий
Если вы поддерживаете «create or update», то нужны стабильные upsert‑ключи:
external_id (лучший вариант при интеграции с другой системой)- Email (подходит для пользователей/контактов, но может меняться)
- Составные ключи (например,
account_id + sku)
Опишите поведение при коллизиях: что, если две строки имеют один ключ или ключ соответствует нескольким записям? Хорошие дефолты — “ошибка для строки с понятным сообщением” или “побеждает последняя строка”, но решение должно быть осознанным.
Транзакции без блокировки всего мира
Используйте транзакции там, где они защищают консистентность (например, создание родителя и детей). Избегайте одной гигантской транзакции для файла в 200k строк — она может заблокировать таблицы и усложнить ретраи. Предпочитайте записывание чанками (500–2 000 строк) с идемпотентными upsert’ами.
Защищайте референциальную целостность
Импорты должны уважать связи: если строка ссылается на родителя (Company), либо требуйте его существование, либо создавайте контролируемым шагом. Досрочные ошибки «missing parent» предотвращают полусвязанные данные.
Аудитируйте всё, что меняют импорты
Добавьте логи аудита для изменений, вызванных импортом: кто запустил, когда, исходный файл и сводку изменений по записи (старое vs новое). Это упрощает поддержку, повышает доверие и облегчает откаты.
Стройте экспорты, которые масштабируются
Экспорт кажется простым, пока клиенты не попросят «всё» прямо перед дедлайном. Масштабируемая система экспорта должна обходиться без замедления приложения и без порчи файлов.
Предлагайте правильные типы экспорта
Начните с трёх опций:
- Полный экспорт: всё, к чему есть доступ.
- Фильтрованный экспорт: применяет те же фильтры, что и UI.
- Инкрементальный экспорт: «изменения с X» для синков и пайплайнов.
Инкрементальные экспорты полезны для интеграций и снижают нагрузку по сравнению с частыми полными дампами.
Выбирайте форматы по реальным сценариям
- CSV — дефолт для таблиц и анализа.
- JSON — для data export API и автоматизации.
- Excel — только когда нужно (несколько листов, богатое форматирование, нетехнические рабочие процессы).
Сохраняйте согласованные заголовки и стабильный порядок колонок, чтобы downstream‑процессы не ломались.
Стриминг и пагинация — чтобы избежать пиков по памяти
Большие экспорты не должны загружать все строки в память. Используйте стриминг/пагинацию, чтобы записывать строки по мере их извлечения. Это предотвращает таймауты и держит приложение отзывчивым.
Генерация больших экспортов асинхронно
Для крупных наборов данных формируйте экспорты в фоновой задаче и уведомляйте пользователя, когда файл готов. Частая схема:
- Пользователь запрашивает экспорт.
- Система ставит джоб в очередь.
- Джоб пишет файл в объектное хранилище.
- UI показывает ссылку на скачивание и сохраняет её в истории экспортов.
Это хорошо сочетается с фоновой обработкой импортов и тем же паттерном «история запусков + скачиваемый артефакт» для отчётов об ошибках.
Пропишите даты, часовые пояса и форматирование
Экспорты часто проходят аудит. Всегда включайте:
- Ясную политику часовых поясов (например, хранить в UTC, экспортировать в часовом поясе пользователя)
- Последовательное форматирование дат (ISO‑8601 для JSON; явные форматы для CSV/Excel)
- Штамп «generated at» и, для инкрементальных экспортов, чётко указанный cutoff
Эти детали уменьшают путаницу и облегчают сопоставления данных.
Безопасность, права и приватность данных
Импорты и экспорты мощные — они быстро перемещают много данных. Это же делает их источником частых уязвимостей: одна избыточная роль, устаревшая ссылка на файл или лог с персональными данными.
Аутентификация: выберите подходящую модель
Используйте ту же аутентификацию, что и в остальном приложении — не создавайте «особую» auth‑дорогу для импортов.
Для браузерных пользователей подходит сессионная аутентификация (и SSO/SAML). Для автоматизированных интеграций — API‑ключи или OAuth с чёткими правами и ротацией.
Практическое правило: UI импорта и API импорта должны применять одинаковые проверки прав, даже если используются разными аудиториями.
Ролевой доступ: определите, кто что может
Относитесь к операциям импорта/экспорта как к явным привилегиям. Частые роли:
- Can import (загружать файлы, запускать импорты)
- Can export (генерировать и скачивать экспорты)
- Can view history (видеть запуски, ошибки, счётчики)
- Can download files (оригинальные загрузки, отчёты об ошибках)
Сделайте «download files» отдельным разрешением — многие утечки происходят, когда у кого‑то есть доступ к просмотру запуска, но система автоматически даёт ссылку на скачивание оригинала.
Также учитывайте границы на уровне строк или арендатора: пользователь должен импортировать/экспортировать данные только для того аккаунта/рабочей области, к которой он принадлежит.
Защищайте конфиденциальные данные на всём пути
Для хранимых файлов используйте приватное объектное хранилище и короткоживущие ссылки на скачивание. Шифруйте на диске при необходимости по требованиям соответствия. Последовательность важна: исходный upload, промежуточные staging‑файлы и сгенерированные отчёты должны следовать одним правилам.
Будьте осторожны с логами: редактируйте чувствительные поля (email, телефоны, адреса) и не логируйте сырые строки по умолчанию. При необходимости включайте «подробное логирование строк» только для админов и делайте эти логи временными.
Валидируйте и сканируйте загрузки до обработки
Относитесь к каждой загрузке как недоверенному вводу:
- Проверяйте тип файла (не полагайтесь только на расширение)
- Устанавливайте лимиты размера, чтобы предотвратить DoS и случайно огромные загрузки
- Рассмотрите сканирование на вредоносное ПО, если профиль риска или отраслевые требования это требуют
Также валидируйте структуру рано: отклоняйте явно испорченные файлы до попадания в фоновые задания и давайте понятное сообщение пользователю.
Аудит для событий, связанных с безопасностью
Фиксируйте события, которые понадобятся при расследовании: кто загрузил файл, кто запустил импорт, кто скачал экспорт, изменения прав и неудачные попытки доступа.
Запись аудита должна включать актёра, временную метку, workspace/tenant и объект (import run ID, export ID), без хранения чувствительных строковых данных. Это хорошо сочетается с UI истории импортов и помогает быстро ответить на вопрос «кто что и когда сделал?».
Тестирование, мониторинг и операционная готовность
Создайте полный процесс загрузки
Сгенерируйте экраны загрузки, предварительного просмотра, сопоставления и проверки — и сразу приступайте к итерациям.
Если импорты/экспорты работают с данными клиентов, в итоге появятся крайние случаи: странные кодировки, объединённые ячейки, частично заполненные строки, дубликаты и «вчера работало». Операционная готовность — то, что не даёт этим случаям превращаться в поддержку.
Тесты, имитирующие реальные файлы
Начните с тестов для самых проблемных частей: парсинга, маппинга и валидации.
- Парсинг: набор фикстур CSV/XLSX (разные разделители, форматы дат, пустые колонки, большие числа, UTF‑8 vs Windows‑1252). Проверяйте количество строк и корректность парсинга ключевых полей.
- Маппинг и трансформации: при заданном наборе колонок проверяйте сопоставление в внутренние поля и применение трансформаций.
- Правила валидации: для каждого правила (required, unique, range, существование внешнего ключа) добавляйте «хорошие» и «плохие» строки и проверяйте точные коды/сообщения ошибок.
Добавьте хотя бы один end‑to‑end тест: upload → фон.обработка → генерация отчёта. Такие тесты ловят рассинхронизации контрактов между UI, API и воркерами.
Мониторинг, который отвечает на «что сломалось?»
Отслеживайте сигналы, влияющие на пользователей:
- Сбой джобов (количество и частота)
- Время обработки (p50/p95)
- Доля ошибок валидации (внезапные всплески часто означают изменения шаблона)
- Глубина очередей и throughput воркеров
Привяжите оповещения к симптомам (рост ошибок, нарастающая очередь), а не к каждой исключительной ситуации.
Админские инструменты и помощь пользователям
Дайте внутренним командам небольшой набор инструментов для повторного запуска джобов, отмены зависших импортов и исследования ошибок (метаданные input‑файла, использованный маппинг, сводка ошибок и ссылка на логи/трейсы).
Для пользователей снижайте предсказуемые ошибки подсказками в интерфейсе, скачиваемыми примерами шаблонов и понятными шагами на страницах ошибок. Держите централизованную страницу помощи и ссылку на неё из UI (например: /docs).
Деплой, выкатывание и дальнейшее развитие
Выпуск системы импорта/экспорта — это не просто «push в прод». Относитесь к нему как к продуктной фиче с безопасными настройками по умолчанию, понятными путями восстановления и возможностью эволюции.
Окружения: dev, staging, prod
Настройте отдельные dev/staging/prod окружения с изолированными базами и отдельными бакетами объектного хранилища (или префиксами) для загрузок и экспортов. Используйте разные ключи шифрования и креды, и убедитесь, что фоновые воркеры смотрят в правильные очереди.
Staging должен максимально повторять прод: те же concurrency джобов, таймауты и лимиты размеров файлов. Там вы проверяете производительность и права без риска для реальных данных.
Миграции и версионирование шаблонов
Импорты «живут вечно», потому что клиенты сохраняют старые таблички. Делайте миграции обычно, но версионируйте шаблоны импорта и сохраняйте template_version в каждом запуске, чтобы изменение схемы не сломало CSV прошлого квартала.
Практический подход — хранить template_version в импорте и держать совместимость для старых версий до момента депрекации.
Стратегия выкатывания с feature‑флагами
Используйте флаги, чтобы безопасно выпускать изменения:
- Новые правила валидации (сначала warn‑only, потом error)
- Новый формат экспорта (например, добавить JSON рядом с CSV)
- Новые опции маппинга (например, разделение «Full name")
Флаги позволяют тестировать на внутренних пользователях или небольшой когорте клиентов перед включением всем.
Поддержка и диагностика
Документируйте шаги для поддержки: как расследовать неудачный импорт через import history, ID джоба и логи. Простой чек‑лист: проверьте версию шаблона, первую фэйлящую строку, доступ к хранилищу, затем логи воркеров. Прикрепите это к внутреннему runbook и, где уместно, к админскому UI (/admin/imports).
Следующие шаги: интеграции
Когда основной поток стабилен, расширяйте его:
- API‑импорты для автоматизированных пайплайнов
- Вебхуки для «импорт завершён» или «экспорт готов»
- Коннекторы для популярных источников (Google Sheets, S3, Snowflake)
Эти расширения уменьшают ручную работу и делают ваш импортный функционал частью привычных процессов клиентов.
Если вы строите это как продуктную функцию и хотите сократить время до «первой рабочей версии», рассмотрите использование Koder.ai для прототипирования мастера импорта, страниц статуса джобов и истории запусков end‑to‑end, с последующим экспортом исходного кода в традиционный инженерный рабочий процесс. Такой подход особенно полезен, когда целью являются надёжность и скорость итераций (а не идеальная кастомная UI‑полировка в первый день).