Прежде чем рисовать экраны или выбирать базу данных, чётко поймите, для чего приложение, кто будет им пользоваться и что считается «хорошо». Приложения для оценки поставщиков чаще всего проваливаются, когда пытаются удовлетворить всех сразу — или не могут ответить на простые вопросы вроде «Какого именно поставщика мы на самом деле оцениваем?»
Цели, пользователи и охват
Кто использует (и что им нужно)
Начните с перечисления основных групп пользователей и их повседневных решений:
- Закупки: нужна консистентная скор‑карта поставщика, виды для сравнения и защищённый аудиторский след для решений по снабжению.
- Финансы: интересуют отклонения по стоимости, соблюдение условий оплаты и сигналы риска, влияющие на прогнозы.
- Операции: хотят быстрое решение проблем — отслеживание инцидентов, документирование корректирующих действий и понимание, улучшается ли производительность.
- Поставщики (опционально, портал): хотят видеть обратную связь, иметь возможность ответить и понимать, как считаются оценки.
Полезный приём: выберите одного «основного пользователя» (часто закупки) и спроектируйте первый релиз вокруг его рабочего процесса. Добавляйте следующие группы только когда можете объяснить, какую новую возможность это откроет.
Ключевые результаты, к которым вы стремитесь
Пишите результаты как измеримые изменения, а не как функции. Распространённые исходы:
- Лучшие решения по поставщикам (например, список предпочтительных поставщиков на основе доказательств, а не анекдотов)
- Более быстрое решение проблем (чёткая ответственность, сроки и последующие действия)
- Более последовательная оценка (меньше вариаций между рецензентами или площадками)
Эти результаты позже определят, какие KPI и отчёты вам нужны.
Определите, что в вашей системе значит «поставщик»
«Поставщик» может означать разное в зависимости от структуры организации и контрактов. Решите заранее, является ли поставщик:
- юридическим лицом (материнская компания)
- площадкой/локацией (полезно, когда качество разнится по заводам/регионам)
- линейкой услуг (например, логистика и упаковка от одного и того же поставщика)
Выбор влияет на всё: свёртки оценок, права доступа и на то, будет ли одна проблемная площадка портить общие отношения.
Выберите подход к оценке
Три распространённых шаблона:
- Взвешенные KPI: числовые входы (процент своевременных поставок, уровень дефектов) умножаются на веса. Отлично для прозрачности и автоматизации.
- Рубрики: рецензенты выбирают уровни (например, «Отлично/Хорошо/Удовлетворительно/Плохо») с пояснительным текстом. Хорошо, когда данные качественные.
- Гибрид: KPI для измеряемых областей + рубрика для сотрудничества, отзывчивости или стратегического соответствия.
Сделайте метод оценки достаточно понятным, чтобы и поставщик, и внутренний аудитор могли проследить, как получился результат.
Определите метрики успеха для приложения
Наконец, выберите несколько глобальных метрик, чтобы подтвердить принятие и полезность:
- Внедрение: % активных поставщиков с хотя бы одним отзывом за квартал
- Полнота отзывов: заполнены ли обязательные поля, прикреплены ли доказательства, указаны ли KPI
- Время цикла: время от открытия отзыва → утверждение → отправка поставщику (если применимо)
С целями и пользователями определёнными, у вас будет стабильный фундамент для модели оценивания и проектирования рабочих процессов.
Модель оценки и дизайн KPI
Приложение для оценки поставщиков «живет» или «умирает» в зависимости от того, насколько оценка соответствует реальному опыту людей. Прежде чем строить экраны, зафиксируйте точные KPI, шкалы и правила, чтобы закупки, операции и финансы одинаково интерпретировали результаты.
Выберите небольшой, обоснованный набор KPI
Начните с ядра, которое большинство команд признают:
- Своевременная доставка (например, % отправок в согласованные окна)
- Качество (уровень дефектов, возвратов или % прохождения инспекций)
- Соблюдение SLA (тикеты, решённые в целевое время; аптайм если релевантно)
- Отклонение по стоимости (счёт vs PO, незапланированные сборы)
- Отзывчивость (время до первого ответа, время до решения для эскалаций)
Держите определения измеримыми и привязывайте каждый KPI к источнику данных или вопросу в форме обзора.
Определите шкалы, которые люди смогут объяснить
Выберите либо 1–5 (удобно для людей), либо 0–100 (более тонкая градация), затем опишите, что значит каждый уровень. Например: «Своевременная доставка: 5 = ≥ 98%, 3 = 92–95%, 1 = < 85%.» Чёткие пороги уменьшают споры и делают оценки сопоставимыми между командами.
Веса, пропущенные данные и правила справедливости
Назначьте веса категорий (например, Доставка 30%, Качество 30%, SLA 20%, Стоимость 10%, Отзывчивость 10%) и задокументируйте, когда веса меняются (разные типы контрактов могут приоритизировать разные показатели).
Решите, как обрабатывать пропущенные данные:
- исключать KPI из знаменателя за период, или
- применять нейтральное значение по умолчанию, или
- помечать оценку как «недостаточно данных» и блокировать ранжирование.
Что бы вы ни выбрали, применяйте последовательно и отображайте это в подробных видах, чтобы команды не принимали «пропуск» за «хорошо».
Несколько скор‑карт для одного поставщика
Поддерживайте более одной скор‑карты на поставщика, чтобы команды могли сравнивать производительность по контракту, региону или периоду. Это предотвращает усреднение проблем, относящихся к конкретному сайту или проекту.
Споры и исправления
Задокументируйте, как споры влияют на оценки: можно ли метрику исправлять ретроспективно, помечает ли спор оценку временно, и какая версия считается «официальной». Даже простое правило типа «оценки перерассчитываются после утверждения корректировки с заметкой о причине» предотвращает путаницу позже.
Модель данных и базовая схема
Чистая модель данных поддерживает справедливость оценок, отслеживаемость отзывов и доверие к отчётам. Вы должны уметь ответить на простые вопросы надёжно — «Почему у поставщика 72 в этом месяце?» и «Что изменилось с прошлого квартала?» — без ручной магии в таблицах.
Ключевые сущности (что хранить)
Минимум, что нужно определить:
- Vendor: профиль поставщика (название, статус, категория, контакты)
- Contract: детали коммерческих соглашений и окна действия
- Order/Invoice (или объединённая Transaction): операционные факты, которые питают KPI
- KPI Metric: определения типа своевременная доставка %, уровень дефектов, время ответа
- Score: рассчитанный результат для поставщика за период (в целом и/или по метрике)
- Review: качественная обратная связь, рейтинги и доказательства в виде текста
- Attachment: файлы, связанные с отзывами или спорами (письма, фото, PDF)
Этот набор поддерживает и «жёсткую» измеряемую производительность, и «мягкую» обратную связь, для которых обычно нужны разные рабочие процессы.
Отношения (как данные связаны)
Моделируйте связи явно:
- Vendor → Contracts: один поставщик может иметь несколько контрактов с течением времени.
- Vendor → Orders/Invoices: транзакций обычно много к одному поставщику.
- Score → Metric: оценки должны быть прослеживаемы до определения метрики и версии расчёта.
- Review → Period: отзывы нуждаются в привязке ко временному бакету (месяц/квартал), чтобы не «плавать» без контекста.
Обычная реализация:
scorecard_period (например, 2025-10)vendor_period_score (общая)vendor_period_metric_score (по каждой метрике, включает числитель/знаменатель если применимо)
Поля, которые пригодятся позже
Добавьте согласованные поля во многие таблицы:
- Временные метки:
created_at, updated_at, и для утверждений submitted_at, approved_at
- Автор и актор:
created_by_user_id, плюс approved_by_user_id там, где это релевантно
- Система источника:
source_system и внешние идентификаторы вроде erp_vendor_id, crm_account_id, erp_invoice_id
- Достоверность/качество:
confidence или data_quality_flag для пометки неполных фидов или оценок
Они дают возможность для аудита, обработки споров и надёжной аналитики закупок.
Ретеншн, версионирование и «что изменилось?»
Оценки меняются из‑за поздних данных, эволюции формул или исправлений. Вместо перезаписи истории храните версии:
- держите версию расчёта (или
calculation_run_id) в каждой строке оценки
- записывайте коды причины для перерасчёта (поздний счёт, обновление определения KPI, ручная коррекция)
- рассмотрите append‑only аудитный журнал для ключевых таблиц (scores, reviews, approvals), чтобы можно было показать, кто что и когда изменял
По ретеншену определите, как долго храните сырые транзакции vs. производные оценки. Часто производные оценки хранят дольше (меньше объём, высокая ценность для отчётов), а сырые ERP‑выгрузки — по более короткой политике.
Стратегия идентификаторов для сопоставления с ERP/CRM
Обращайтесь с внешними ID как с полями первого класса, а не заметками:
- храните и внешний ID, и название системы источника (ERP_A vs ERP_B)
- обеспечьте уникальность по паре (например,
unique(source_system, external_id))
- добавьте лёгкие таблицы соответствий при слияниях/разделениях поставщиков, чтобы исторические оценки оставались корректными
Такая прокладка делает интеграции, отслеживание KPI, модерацию и аудит проще реализовать и объяснить.
Загрузка данных и интеграции
Приложение для оценки поставщиков ценно ровно настолько, насколько качественны входные данные. Планируйте несколько путей загрузки с первого дня, даже если начнёте с одного. Большинство команд в итоге нуждаются в смеси ручного ввода для исключений, массовых загрузок для истории и API‑синхрона для актуальных обновлений.
Распространённые источники данных
Ручной ввод полезен для мелких поставщиков, единичных инцидентов или когда нужно быстро зафиксировать отзыв.
Загрузка CSV помогает загрузить прошлую производительность, счета, тикеты или записи о доставках. Делайте шаблоны предсказуемыми: публикуйте версионированный шаблон, чтобы изменения не ломали импорты молча.
API‑синхрон обычно подключается к ERP/инструментам закупок (PO, приемки, счета) и сервисным системам вроде helpdesk (тикеты, нарушения SLA). Предпочитайте инкрементальный синхрон (с курсором «since last»), чтобы не тянуть всё каждый раз.
Валидация, которая предотвращает «мусор»
Настройте правила валидации на этапе импорта:
- обязательные поля (vendor ID, дата, имя/значение метрики)
- числовые диапазоны (например, 0–100 для score, неотрицательные количества)
- обнаружение дубликатов (тот же поставщик + метрика + период + ID исходной записи)
Сохраняйте неверные строки с сообщениями об ошибках, чтобы админы могли исправить и перезагрузить, не теряя контекст.
Исправления, бэкфиллы и логи перерасчётов
Импорты иногда будут неверны. Поддерживайте повторные прогонки (идемпотентные по исходным ID), бэкфиллы (исторические периоды) и логи перерасчётов, фиксирующие, что изменилось, когда и почему. Это критично для доверия, когда оценка поставщика сдвигается.
Расписание и прозрачность
Большинству команд хватает ежедневных/еженедельных импортов для финансовых и доставочных метрик и почти реального времени для критических инцидентов.
Откройте админскую страницу импорта (например, /admin/imports) с указанием статуса, количества строк, предупреждений и точных ошибок — чтобы проблемы были видны и исправлялись без помощи разработчиков.
Роли, права и рабочий процесс утверждения
Чёткие роли и предсказуемый путь утверждения предотвращают «хаос в скор‑картах»: конфликтные правки, неожиданные изменения оценок и неясность, что видит поставщик. Определите правила доступа заранее и применяйте их в UI и API.
Типы ролей (и зачем они нужны)
Практичный стартовый набор ролей:
- Admin: управляет настройками организации, назначениями ролей, шаблонами оценок и правилами модерации.
- Internal Reviewer: создаёт отзывы, прикладывает доказательства и черновые обновления оценок.
- Approver: проверяет чувствительные действия (публикация отзывов, блокировка периодов, утверждение изменений оценок).
- Vendor User: видит свою скор‑карту, отвечает на отзывы и добавляет пояснения (если разрешено).
- Read-only: может просматривать дашборды и профили поставщиков, но не редактировать.
Разрешения, привязанные к реальным действиям
Избегайте расплывчатых прав вроде «может управлять поставщиками». Контролируйте конкретные возможности:
- Просмотр: кто видит отзывы, имена рецензентов, вложения и исторические оценки.
- Редактирование: кто может создавать/редактировать черновики, менять значения KPI или веса.
- Публикация: кто переводит содержимое из черновика в видимое.
- Экспорт: кто может скачивать отчёты (CSV/PDF) и в каком объёме (отдельный поставщик vs все поставщики).
Рассмотрите разделение «экспорт» на «экспорт своих поставщиков» vs «экспорт всех» — это часто важно для аналитики закупок.
Правила видимости для поставщиков
Пользователи‑поставщики обычно видят только свои данные: свои оценки, опубликованные отзывы и статус открытых пунктов. По умолчанию ограничьте показ личности рецензента (показывайте отдел или роль вместо полного имени), чтобы снизить межличностные трения. Если допускаете ответы поставщиков, храните их в треде и явно помечайте как вклад от поставщика.
Потоки утверждения для доверия и согласованности
Обращайтесь с отзывами и изменениями оценок как с предложениями до утверждения:
- Internal Reviewer отправляет черновой отзыв/обновление оценки.
- Approver изучает доказательства, проверяет политику и либо утверждает, либо просит правки, либо отклоняет.
- Только утверждённые элементы влияют на «текущую» оценку и становятся видимыми для поставщика.
Ограничьте сроки: например, изменения оценок могут требовать утверждения только в момент месяичной/квартальной закрывающей стадии.
Требования к аудиту
Для соответствия и подотчётности логируйте каждое значимое событие: кто что сделал, когда, откуда и что именно изменилось (значения до/после). Аудитный журнал должен покрывать изменения прав, правки отзывов, утверждения, публикации, экспорты и удаления. Сделайте журнал поисковым, экспортируемым для ревизий и защищённым от подмены (append‑only или неизменяемые логи).
UX и базовые экраны
Вносите изменения без риска
Тестируйте изменения в оценках безопасно с помощью снимков и отката при изменении весов или KPI.
Приложение для оценки поставщиков выигрывает, если занятые пользователи быстро находят нужного поставщика, понимают оценку с первого взгляда и без трения оставляют доказательства. Начните с небольшого набора «опорных» экранов и делайте каждое число объясняемым.
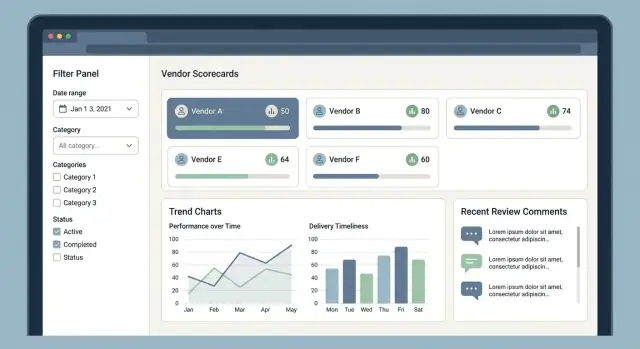
1) Список поставщиков (командный центр)
Отсюда обычно начинается сессия. Держите макет простым: имя поставщика, категория, регион, текущая банд‑оценка, статус и последняя активность.
Фильтрация и поиск должны быть мгновенными и предсказуемыми:
- категория, регион, статус (active/on hold/blocked)
- диапазон дат (последний отзыв, последний инцидент доставки)
- банда оценки (A/B/C или диапазоны 0–100)
Сохраняйте общие представления (например, «Критичные поставщики в EMEA ниже 70»), чтобы команды не воссоздавали фильтры каждый день.
2) Профиль поставщика (всё на одной странице)
Профиль должен суммировать «кто они» и «как идут дела», не загоняя пользователя в табы слишком рано. Разместите контакты и метаданные контрактов рядом с ясной сводкой оценки.
3) Скор‑карта с развёрнутыми объяснениями «почему»
Показывайте общую оценку и разбиение по KPI (качество, доставка, стоимость, соответствие). Для каждого KPI должно быть видно источник: отзывы, инциденты или метрики, которые на него повлияли.
Хорошая схема:
- KPI → формула/вес → составляющие элементы → доказательства (комментарии, вложения, временные метки)
4) Отзывы и инциденты (быстрый ввод, сильный контекст)
Сделайте ввод отзывов удобным для мобильных: крупные элементы управления, короткие поля и быстрый комментирование. Всегда привязывайте отзыв к времени и (если релевантно) к заказу, площадке или проекту, чтобы обратная связь оставалась действующей.
5) Отчёты (готовые к принятию решений)
Отчёты должны отвечать на распространённые вопросы: «Какие поставщики в тренде вниз?» и «Что поменялось в этом месяце?» Используйте читаемые графики, понятные подписи и клавиатурную навигацию для доступности.
Отзывы, комментарии и модерация
Отзывы — это то место, где приложение становится действительно полезным: они фиксируют контекст, доказательства и «почему» за числами. Чтобы они были последовательными и защищаемыми, рассматривайте отзывы сначала как структурированные записи, а свободный текст — вторичным.
Типы отзывов, которые стоит поддерживать
Разные ситуации требуют разных шаблонов. Набор для старта:
- Периодические (месяц/квартал): регулярная сводка производительности и трендов
- Инцидентные: привязаны к поздней доставке, дефекту или нарушению соответствия
- Проектные/закрывающие: итог при завершении взаимодействия с уроками
Типы могут разделять общие поля, но позволять специфические вопросы, чтобы не втискивать инцидент в квартальную форму.
Структурированные поля: делайте отзывы индексируемыми
Помимо текста, включайте структурированные поля для фильтрации и отчётов:
- Теги и категории (например, Logistics, Quality, Communication)
- Сильные стороны и проблемные места (раздельные поля)
- Action items с ответственным, сроком и статусом
Такая структура превращает «обратную связь» в отслеживаемую работу, а не просто текстовое поле.
Работа с доказательствами (без лишней боли)
Позвольте рецензентам прикреплять доказательства в том же месте, где они пишут отзыв:
- файлы (фото, PDF)
- ссылки на общие документы
- ссылки на тикеты / PO / заказы (желательно — выбираемые из списка)
Храните метаданные (кто загрузил, когда, к чему относится), чтобы аудит не превращался в поиски по кусочкам.
Модерация и история правок
Даже внутренние инструменты нуждаются в модерации. Добавьте:
- базовую проверку на нецензурную лексику/спам
- правила эскалации для серьёзных утверждений (безопасность, мошенничество)
- историю правок, фиксирующую, что и кем менялось (включая редактирования и вырезки)
Избегайте молчаливых правок — прозрачность защищает и рецензентов, и поставщиков.
Уведомления, напоминания и SLA ответов
Определите правила уведомлений заранее:
- уведомлять поставщиков при публикации отзыва (или когда требуется ответ)
- отправлять внутренние напоминания по просроченным задачам
- установить SLA на ответы (например, 5 рабочих дней) с эскалацией при несоблюдении
При правильной настройке отзывы становятся замкнутым циклом обратной связи, а не однократной жалобой.
Архитектура и выбор стека технологий
Запустите пилот быстрее
Быстро разверните приложение оценки поставщиков, чтобы заинтересованные лица могли протестировать его как можно раньше.
Первая архитектурная дилемма — это не «последняя модная технология», а то, как быстро вы сможете выпустить надёжную платформу оценок и отзывов без долгов по сопровождению.
Если хотите двигаться быстро, рассмотрите прототипирование рабочего процесса (поставщики → скор‑карты → отзывы → утверждения → отчёты) на платформе, которая умеет генерировать рабочее приложение из чёткого спецификации. Например, Koder.ai — платформа в стиле vibe‑coding, где можно создать веб‑, бэкенд‑ и мобильные приложения через чат‑интерфейс, а затем экспортировать исходный код, когда будете готовы доводить решение до промышленного уровня. Это практичный способ проверить модель оценки и роли/права до больших инвестиций в кастомный UI и интеграции.
Монолит vs модульные сервисы (держите просто)
Для большинства команд оптимальна модульная монолитная архитектура: одно деплойное приложение, организованное по модулям (Vendors, Scorecards, Reviews, Reporting, Admin). Это простая разработка и отладка, а также более простая безопасность и деплойменты.
Переходите к отдельным сервисам только при явной необходимости — высокая нагрузка отчётов, несколько продуктовых команд или строгая изоляция. Частый путь эволюции: монолит сейчас, вынести «imports/reporting» позже при необходимости.
Дизайн API (REST, который отражает работу)
REST API обычно проще всего понимать и интегрировать с системами закупок. Стремитесь к предсказуемым ресурсам и нескольким «task» endpoint'ам, где система выполняет реальную работу.
Примеры:
/api/vendors (создать/обновить поставщика, статус)/api/vendors/{id}/scores (текущая оценка, историческое разбиение)/api/vendors/{id}/reviews (список/создать отзывы)/api/reviews/{id} (обновление, модерация)/api/exports (запрос экспорта; возвращает job id)
Держите тяжёлые операции (экспорты, массовые перерасчёты) асинхронными, чтобы UI оставался отзывчивым.
Фоновые задания (импорты, перерасчёты, уведомления)
Используйте очередь задач для:
- импорта данных поставщиков (CSV/SFTP/API)
- перерасчёта оценок при изменении KPI, весов или отзывов
- отправки уведомлений (запрос отзыва, смена оценки, требуется утверждение)
Это также помогает автоматически повторять неудачные операции без ручных вмешательств.
Кеширование для дашбордов и тяжёлых отчётов
Дашборды могут быть дорогими. Кешируйте агрегированные метрики (по периоду, категории, подразделению) и инвалидируйте кеш при значимых изменениях или обновляйте по расписанию. Это сохраняет «открытый дашборд» быстрым и при этом сохраняет возможность разворачивать детали.
Документация (для разработчиков и админов)
Пишите API‑доки (OpenAPI/Swagger подойдёт) и поддерживайте внутреннее руководство в формате /blog — например, «Как работает оценивание», «Как обрабатывать спорные отзывы», «Как запускать экспорты» — и ссылку на него из приложения по адресу /blog.
Безопасность, приватность и надёжность
Данные об оценках поставщиков влияют на контракты и репутацию, поэтому нужны предсказуемые, аудитируемые и простые правила безопасности.
Аутентификация и контроль доступа
Начните с подходящих опций входа:
- Email/password для небольших команд (используйте строгие правила паролей и MFA)
- SSO для корпоративных клиентов через SAML или OIDC, чтобы доступ управлялся централизованно и мог быть отозван быстро
Сопровождайте аутентификацию RBAC: админы закупок, рецензенты, утверждающие и только для чтения. Делайте права детализированными (например, «view scores» vs «view review text»). Храните аудиторский след для изменений оценок и утверждений.
Защита конфиденциальных данных
Шифруйте данные в транзите (TLS) и в состоянии покоя (БД и бекапы). Относитесь к секретам как к первым классам:
- храните их в управляемом хранилище секретов
- регулярно ротируйте
- никогда не коммитьте в репозиторий
Защита от злоупотреблений и безопасные эндпоинты
Даже если приложение «внутреннее», публичные точки (сброс пароля, инвайт‑ссылки, формы отправки отзывов) могут быть атакованы. Добавьте rate limiting и защиту от ботов (CAPTCHA или риск‑скоринг) там, где это нужно, и ограничьте API скоуп‑токенами.
Приватность по дизайну
Отзывы часто содержат имена, email и детали инцидентов. Минимизируйте персональные данные по умолчанию (структурированные поля вместо свободного текста), задайте правила хранения и предоставьте инструменты для редактирования или удаления контента по запросу.
Надёжные операции без утечки данных
Логируйте достаточно для отладки (request IDs, latency, error codes), но избегайте записи конфиденциального текста отзывов или вложений в логи. Настройте мониторинг и алерты на сбои импортов, ошибки задач перерасчётов и необычную активность без превращения логов в «вторую БД» с чувствительным содержанием.
Отчёты, дашборды и объяснимость
Приложение полезно ровно настолько, насколько помогает принимать решения. Отчёты должны быстро отвечать на три вопроса: Кто хорошо выступает, по сравнению с чем и почему?
Дашборды для занятых стейкхолдеров
Начните с исполнительной панели, которая суммирует общую оценку, изменения во времени и разбиение по категориям (качество, доставка, соответствие, стоимость, сервис). Тренд‑линии критичны: поставщик с чуть меньшей оценкой, но с устойчивым ростом, может быть лучше, чем высокий, но падающий.
Дайте возможность фильтровать по периоду, подразделению/площадке, категории поставщиков и контракту. Используйте консистентные дефолты (например, «последние 90 дней»), чтобы разные люди видели сопоставимые данные.
Бенчмаркинг с контролем доступа
Бенчмаркинг мощный, но чувствительный. Позвольте сравнивать поставщиков в одной категории (например, "поставщики упаковки"), соблюдая права:
- лидеры закупок видят именованные сравнения
- менеджеры площадок видят только свои поставщики
- общие заинтересованные лица видят анонимизированные ранжирования или квартилы
Так вы избегаете случайных разглашений, но поддерживаете выбор поставщиков.
Отчёты с углублением: от оценки к источнику
Дашборды должны вести к деталям, объясняющим движение оценок:
- По периоду: месячные/квартальные сводки с дельтами по KPI
- По площадке: выделение проблем на конкретных локациях
- По контракту: соответствие SLA и коммерческим условиям
Хороший drill‑down заканчивается доказательствами: связанные отзывы, инциденты, тикеты или записи отгрузок.
Экспорт для внутреннего обмена
Поддерживайте CSV для анализа и PDF для пересылки. Экспорты должны отражать текущие фильтры, содержать отметку времени и при желании ставить «внутренний» водяной знак (и идентифицировать просмотревшего), чтобы снизить риск распространения за пределами организации.
Объяснимость: показывайте, как строится оценка
Избегайте «чёрных ящиков». Для каждой оценки поставщика показывайте:
- вклад KPI (веса, сырые значения, нормализация)
- применённые штрафы/бонусы (например, критический вопрос соответствия)
- заметки о расчётах и версию формулы
Когда пользователи видят детали расчёта, споры решаются быстрее, а планы по улучшению легче согласовать.
Тестирование и проверки качества
MVP для оценки поставщиков
Прототипируйте процесс оценки поставщиков в Koder.ai до полной разработки.
Тестирование платформы оценки поставщиков — это не только поиск багов, но и защита доверия. Команды закупок должны быть уверены, что оценка корректна, а поставщики — что отзывы и утверждения обрабатываются согласованно.
Создавайте тестовые данные, отражающие реальную неидеальность
Сформируйте небольшие, переиспользуемые наборы тестовых данных с крайними случаями: пропущенные KPI, поздние отправки, конфликтующие значения в импортах и споры (например, поставщик оспаривает результат SLA). Включите случаи отсутствия активности и ситуации, когда KPI есть, но должны исключаться из‑за дат.
Проверяйте логику расчётов модульными тестами
Математика расчётов — сердце продукта, тестируйте её как финансовые формулы:
- правила взвешивания (включая суммарные веса ≠ 100% и как это обрабатывается)
- поведение округления и ничьи в ранжировании
- пороги (когда KPI переходит из «хорошо» в «требует внимания")
- регрессионные тесты при изменении определений KPI
Юнит‑тесты должны проверять не только итоговые оценки, но и промежуточные компоненты (оценки по KPI, нормализация, штрафы/бонусы), чтобы упростить отладку.
Покрывайте импорты, права и рабочие процессы интеграционными тестами
Интеграционные тесты должны симулировать end‑to‑end сценарии: загрузку скор‑карты, применение прав, и проверку, что только нужные роли могут смотреть, комментировать, утверждать или эскалировать спор. Включите тесты для записей аудита и заблокированных действий (например, поставщик пытается изменить утверждённый отзыв).
Валидируйте через UAT и нагрузочные проверки
Проводите пользовательские приёмочные тесты с командами закупок и пилотной группой поставщиков. Фиксируйте моменты непонимания и обновляйте UI‑тексты, валидацию и подсказки.
Наконец, запускайте тесты производительности для пиковых периодов (концы месяца/квартала): время загрузки дашбордов, массовые экспорты и параллельные задачи перерасчёта.
План запуска и дорожная карта итераций
Приложение выигрывает, когда им реально пользуются. Обычно это означает выпуск по фазам, аккуратную замену таблиц и явные ожидания, что и когда изменится.
Поэтапный запуск, который строит доверие
Начните с минимальной версии, которая всё ещё даёт полезные скор‑карты.
Фаза 1: Только внутренние скор‑карты. Дайте закупкам и стейкхолдерам место для записи значений KPI, формирования скор‑карты и оставления внутренних комментариев. Упростите рабочий процесс и сфокусируйтесь на согласованности.
Фаза 2: Доступ поставщиков. Когда внутренняя оценка стабильна, приглашайте поставщиков смотреть свои скор‑карты, отвечать и добавлять контекст (например, «задержка из‑за закрытия порта»). Здесь важны права и аудиторский след.
Фаза 3: Автоматизация. Добавьте интеграции и плановые перерасчёты, когда вы доверяете модели оценивания. Ранний переход к автоматизации может усилить проблемы плохих данных или неясных определений.
Если нужно ускорить пилот, платформы вроде Koder.ai могут помочь: быстро поднять ядро (роли, утверждения, экспорты), итеративно проверять с закупками в «режиме планирования» и экспортировать кодовую базу, когда будете готовы усиливать интеграции и соответствие.
План миграции (безопасный выход из таблиц)
Если вы заменяете таблицы, планируйте переход по шагам, а не «большой взрыв».
Предоставьте шаблоны импорта, которые соответствуют существующим колонкам (имя поставщика, период, значения KPI, рецензент, заметки). Добавьте помощники импорта: ошибки валидации («неизвестный поставщик»), предпросмотр и dry‑run режим.
Решите, мигрируете ли вы всю историю или только недавние периоды. Часто достаточно последних 4–8 кварталов, чтобы получить тренды без превращения миграции в археологию данных.
Учебные материалы, которые действительно читают
Держите обучение коротким и по ролям:
- одностраничные быстрые инструкции для рецензентов, утверждающих и админов
- подсказки в приложении при первом использовании (как оценивать, где оставлять контекст, что значит «отправить")
- чек‑лист админа: создать категории, задать определения KPI, настроить циклы обзора и проверить права
Текущая поддержка и итерации
Относитесь к определениям оценивания как к продукту. KPI меняются, категории расширяются, веса эволюционируют.
Установите политику перерасчётов: что происходит, если меняется определение KPI? Пересчитываете ли вы историю или сохраняете оригинал для аудита? Многие команды хранят исторические результаты и пересчитывают только с эффективной даты.
Следующие шаги: ценообразование и пакеты
Когда вы переходите дальше пилота, решите, что входит в каждый уровень (число поставщиков, циклы обзора, интеграции, продвинутые отчёты, доступ портала поставщиков). Если формализуете коммерческий план, опишите пакеты и ссылку на /pricing для деталей.
Если оцениваете «строить vs покупать vs ускорять», учитывайте «насколько быстро мы можем выпустить надёжный MVP?» как фактор упаковки. Платформы вроде Koder.ai (с тарифами от бесплатного до enterprise) могут быть мостом: быстро строить и итеративно развивать, хостить и при этом сохранять опцию экспортировать полный исходный код, когда программа оценки поставщиков зрелая.