Уточните цели, пользователей и метрики успеха
Прежде чем эскизировать экраны или выбирать базу данных, согласуйте, что именно ваша команда подразумевает под веб-приложением для отслеживания инцидентов — и что должно давать «управление постмортемами». Команды часто используют одни и те же слова по-разному: для одной группы инцидент — любое сообщение от клиента; для другой — только Sev-1 с эскалацией на дежурного.
Определите «отслеживание инцидентов» для вашей команды
Напишите короткое определение, отвечающее на вопросы:
- Что считается инцидентом (влияние на клиентов, только внутренние случаи, события безопасности, пропущенные SLA)?
- Когда инцидент «начинается» и «заканчивается» (первое оповещение vs первое человеческое подтверждение; полностью исправлено vs под наблюдением)?
- Какие данные обязательны (затронутый сервис, уровень серьёзности, владелец, временные метки, обновления статуса)?
Это определение управляет вашим рабочим процессом реагирования на инциденты и предотвращает превращение приложения в слишком строгий (никто им не пользуется) или слишком свободный (данные несогласованы) инструмент.
Определите «управление постмортемами» (и зачем это нужно)
Решите, что такое постмортем в вашей организации: лёгкое резюме для каждого инцидента или полноценный RCA только для инцидентов высокой серьёзности. Уточните, что главное: обучение, соответствие требованиям, снижение повторных инцидентов или всё вместе.
Полезное правило: если вы ожидаете, что постмортем приведёт к изменениям, то инструмент должен поддерживать трекинг action items, а не просто хранение документов.
Перечислите решаемые вами проблемы
Большинство команд строят такое приложение, чтобы решить небольшой набор повторяющихся болевых точек:
- Видимость: «Что происходит прямо сейчас?», «Как часто ломается этот сервис?»
- Координация: ясная ответственность, передача дел и общий таймлайн инцидента
- Обучение: согласованные шаблоны RCA и процесс ревью, который действительно выполняется
- Доведение до конца: action items не исчезают после встречи
Держите этот список компактным. Каждая добавляемая функция должна решать хотя бы одну из этих проблем.
Выберите метрики успеха, соответствующие поведению
Выберите несколько метрик, которые можно автоматически измерить по модели данных приложения:
- Время обнаружения, подтверждения, смягчения и разрешения (ваш таймлайн инцидента должен это фиксировать)
- Частота по уровням серьёзности, сервисам и категориям причин
- Процент закрытых action items и медиана времени до закрытия
- Сигналы качества: процент инцидентов с постмортемом в пределах N дней; процент с ясным владельцем и обновлениями статуса
Они станут вашими операционными метриками и «определением готовности» для первого релиза.
Уточните ваших пользователей (и что каждому нужно)
Одно и то же приложение обслуживает разные роли в on-call операциях:
- Дежурный инженер: быстрое создание записи, минимум полей, простые обновления статуса
- Incident commander: вид координации, текущее состояние, владельцы, контрольные точки
- Менеджеры: тренды, повторяющиеся проблемы, выполнение action items
- Заинтересованные стороны: понятные обновления статуса без внутреннего шума
Если вы будете проектировать для всех сразу, UI получится перегруженным. Лучше выбрать основного пользователя для v1 и затем обеспечить остальные роли через индивидуальные представления, дашборды и права доступа.
Проектируйте рабочий процесс инцидента и роли
Ясный рабочий процесс предотвращает две распространённые ошибки: инциденты, которые «застевают», потому что никто не знает «что дальше», и инциденты, которые выглядят «закрытыми», но не дают уроков. Начните с картирования жизненного цикла от начала до конца и затем привяжите роли и права к каждому шагу.
Карта жизненного цикла инцидента
Большинство команд следуют простой цепочке: обнаружение → триаж → смягчение → разрешение → обучение. Ваше приложение должно отражать это небольшим набором предсказуемых шагов, а не бесконечным меню опций.
Определите, что такое «готово» для каждой стадии. Например, «смягчение» может означать, что влияние на клиента остановлено, даже если корневая причина ещё неизвестна.
Определите роли и ответственности
Сделайте роли явными, чтобы люди могли действовать без ожидания встреч:
- Reporter: создаёт инцидент, добавляет начальный контекст, прикрепляет ссылки/логи.
- Responder: расследует, добавляет обновления, выполняет смягчающие действия.
- Incident Commander: отвечает за координацию, назначает responders, утверждает уровень серьёзности, контролирует обновления для заинтересованных сторон.
- Reviewer: ведёт постинцидентный обзор, обеспечивает качество постмортема.
В UI должно быть видно «текущего владельца», а рабочий процесс — поддерживать делегирование (переназначение, добавление ответчиков, ротация командира).
Состояния и переходы
Выберите обязательные состояния и разрешённые переходы, например Investigating → Mitigated → Resolved. Добавьте защитные механизмы:
- Требуйте уровня серьёзности перед переходом после triage
- Требуйте итогового резюме перед пометкой Resolved
- Запрещайте «Resolved → Investigating», если не указана причина переоткрытия
План коммуникаций
Отделяйте внутренние обновления (быстрые, тактические, могут быть небрежными) от обновлений для заинтересованных сторон (ясные, с временными метками, кураторские). Постройте два потока обновлений с разными шаблонами, видимостью и правилами утверждения — чаще всего командир единственный, кто публикует обновления для внешних заинтересованных.
Моделируйте данные: сущности, связи и история
Хороший инструмент для инцидентов кажется «простым» в UI, потому что модель данных под ним последовательна. Перед созданием экранов решите, какие объекты существуют, как они связаны и что должно быть исторически корректно.
Основные сущности (объекты, которые вы храните)
Начните с небольшого набора первичных объектов:
- Incident: контейнер для всего, что произошло.
- Service: то, чем вы оперируете (API, база данных, мобильное приложение), используется для оценки влияния и отчётности.
- Update: человеко-читаемые обновления статуса (внутренние заметки и внешние статусы).
- Timeline Event: точные события с временной меткой («сработал алерт», «произвел откат», «применено смягчение»).
- Action Item: последующие задачи с владельцами и сроками.
- Postmortem: структурированная запись (влияние, анализ корневой причины, уроки, ссылки).
Связи и идентификаторы
Большинство связей — один-ко-многим:
- Один Incident → много Updates / Timeline Events / Action Items
- Один Incident → один (или ноль) Postmortem
- Один Incident ↔ много Services (обычно many-to-many через связь «affected_services»)
Используйте стабильные идентификаторы (UUID) для инцидентов и событий. Людям всё ещё нужен удобный ключ вроде INC-2025-0042, который можно генерировать из последовательности.
Метаданные, которые понадобятся позже
Спроектируйте их заранее, чтобы можно было фильтровать, искать и строить отчёты:
- Уровень серьёзности, статус (open/mitigated/resolved), теги
- Время начала, время окончания, время обнаружения
- Incident commander, команда-ответчик, дежурная ротация (опционально)
- Затронутые сервисы, краткое описание влияния на клиентов
История, хранение и аудируемость
Данные инцидентов чувствительны и часто просматриваются позже. Обращайтесь с правками как с данными, а не как с перезаписью:
- Храните created_at/created_by для каждой записи.
- Для правок ведите audit log (изменение полей + актор + временная метка) или версионируйте важные документы (постмортем, обновления).
- Решите политику хранения заранее (например, хранить инциденты навсегда, очищать стенограммы чатов через N дней).
Такая структура упростит последующую реализацию поиска, метрик и прав доступа без переделки.
Реализуйте приём инцидента, обновления и таймлайн
Когда что-то ломается, задача приложения — уменьшить количество ввода и повысить ясность. Этот раздел покрывает «путь записи»: как люди создают инцидент, поддерживают его обновления и восстанавливают картину позже.
Приём инцидента: минимум полей, умные значения по умолчанию
Сделайте форму создания короткой, чтобы её можно было заполнить во время отладки. Хороший набор обязательных полей:
- Title (простыми словами: «Ошибки в чекауте на мобильном»)
- Service/System (выбирать из списка, чтобы избежать вариантов написания)
- Severity (по умолчанию на основе сервиса или времени, но редактируемое)
- Reporter (автозаполнение текущим пользователем)
Всё остальное делайте опциональным при создании (влияние, ссылки на тикеты клиентов, предполагаемая причина). Используйте умные значения по умолчанию: ставьте start time = «сейчас», предварительно выбирайте on-call команду пользователя и предлагайте однонажатийный «Create & open incident room».
Быстрые обновления: статус, влияние, следующие шаги
UI для обновлений должен быть оптимизирован для частых небольших правок. Предоставьте компактную панель обновлений с:
- Status (Investigating / Identified / Mitigated / Resolved)
- Краткое описание влияния (1–2 предложения)
- Ключевые заметки (что изменилось с момента последнего обновления)
- Следующие шаги (что делается далее, кем)
Делайте обновления апенд-ориентированными: каждое становится временной записью, а не перезаписывает предыдущий текст.
Таймлайн: автоматические события + ручные записи
Соберите в таймлайне смешение:
- Авто-захваченные события: изменения полей (серьёзность, статус), назначение ответственных, добавление ссылок, время разрешения
- Ручные события: «Деплой hotfix», «Откат», «Запуск резервирования БД»
Это создаёт надёжный нарратив, не заставляя людей помнить о логировании каждого клика.
UX для мобильных
Во время инцидента многие обновления приходят с телефона. Приоритет — быстрый, малотяжёлый экран: крупные элементы управления, одна прокручиваемая страница, оффлайн-драфты и однонажатийные действия вроде «Опубликовать обновление» и «Скопировать ссылку на инцидент».
Добавьте уровни серьёзности, чек-листы и контекст
Серьёзность — это «скоростной диск» реагирования: она говорит, как срочно действовать, как широко коммуницировать и какие компромиссы допустимы.
Определите уровни серьёзности (и что они подразумевают)
Избегайте расплывчатых меток вроде «высокий/средний/низкий». Сделайте так, чтобы каждый уровень соответствовал явным операционным ожиданиям — в особенности времени реакции и частоте коммуникаций.
Например:
- SEV1 (Критический): пользовательский outage или риск безопасности. Пейджить немедленно, открыть мост/чат инцидента, обновлять заинтересованных каждые 15–30 минут, рассмотреть публичный статус-апдейт.
- SEV2 (Серьёзный): частичная недоступность или сильное деградирование. Реагировать быстро, координироваться в чате, обновлять заинтересованных каждые 30–60 минут.
- SEV3 (Незначительный): ограниченное влияние, доступен обходной путь. Обрабатывать в рабочие часы при необходимости, обновлять по ключевым вехам.
- SEV4 (Информ): нет немедленного влияния; отслеживать как операционный вопрос.
Делайте эти правила видимыми в UI там, где выбирают уровень, чтобы респонденты не искали документацию во время инцидента.
Чек-листы для ответчиков, соответствующие вашему рабочему процессу
Чек-листы уменьшают когнитивную нагрузку в стрессовой ситуации. Делайте их короткими, действенными и привязанными к ролям.
Полезный шаблон — несколько секций:
- Triage: подтвердить влияние на клиента, оценить радиус поражения, установить уровень, назначить лидера инцидента.
- Mitigation: проверить откат/feature flag, подтвердить сигналы восстановления, мониторить регрессии.
- Comms: уведомить поддержку, опубликовать внутреннее обновление, решить о /status-обновлении, подготовить сообщение для клиентов.
Отмечайте время и автора выполнения пунктов, чтобы они стали частью записи инцидента.
Ссылки на вспомогательные артефакты
Инциденты редко живут в одном инструменте. Позвольте ответчикам прикреплять ссылки на:
- Дашборды и конкретные графики
- Запросы в логах
- Тикеты/задачи
- Чат-ветки или war-room каналы
- Руководства и плейбуки
Предпочитайте «типизированные» ссылки (например, Runbook, Ticket), чтобы их можно было фильтровать позже.
Захват влияния на SLA/SLO при необходимости
Если в организации отслеживают цели надёжности, добавьте лёгкие поля вроде SLO затронут (да/нет), оценка прожигания error budget, и риск SLA для клиента. Делайте их опциональными, но простыми для заполнения во время или сразу после инцидента, когда детали ещё свежи.
Создайте шаблоны постмортемов и поток ревью
Начните с малого, масштабируйтесь позже
Начните на бесплатном тарифе и переходите на платный только при необходимости.
Хороший постмортем — лёгкий для начала, трудно забываемый и согласованный между командами. Проще всего достичь этого, предоставив шаблон по умолчанию (с минимальным набором обязательных полей) и автозаполнением из записи инцидента, чтобы люди думали, а не перепечатывали.
Практичный шаблон постмортема (что включить)
Встроенный шаблон должен сочетать структуру и гибкость:
- Краткое резюме: что произошло простыми словами (2–5 предложений).
- Влияние: кто/что пострадало, как долго, видимые у клиентов симптомы и бизнес-эффект (задержка заказов, рост ошибки, нарушение SLA).
- Root cause: первопричина (техническая/процессная). Факты, без обвинений.
- Сопутствующие факторы: вторичные проблемы (пробелы в мониторинге, неясность ответственности, рискованный тайминг изменения).
- Что прошло хорошо / что пошло не так / повезло ли нам: подсказки для честного, действенного анализа.
Сделайте «Root cause» опциональной на ранних стадиях для более быстрой публикации, но требуйте её перед финальным утверждением.
Автосвязь постмортема с таймлайном инцидента
Постмортем не должен быть отдельным документом в вакууме. При создании постмортема автоматически прикрепляйте:
- Таймлайн инцидента (ключевые обновления, изменения статуса, шаги по смягчению)
- Участников (командир, ответчики, коммуникации)
- Артефакты (связанные тикеты, дашборды, ссылки на логи — хранятся как ссылки)
Используйте эти данные для предварительного заполнения разделов постмортема. Например, блок «Влияние» может начинаться с времён старта/окончания и текущей серьёзности, а «Что мы делали» — подтягиваться из записей таймлайна.
Поток ревью и утверждения, поддерживающий обучение
Добавьте лёгкий рабочий поток, чтобы постмортемы не зависали:
- Черновик (создаётся автоматически при закрытии инцидента или вручную)
- На проверке (назначенные рецензенты — чаще IC + владелец сервиса)
- Одобрено (фиксируется финальное резюме + примечания о решении)
- Опубликовано (поделиться внутри организации; опционально связать с публичным уведомлением)
На каждом шаге фиксируйте решения: что изменено, почему и кто одобрил. Это предотвращает «молчащие правки» и упрощает будущие аудиты и обзоры.
Если хотите упростить UI, относитесь к ревью как к комментариям с явным исходом (Approve / Request changes) и храните финальное одобрение как неизменяемую запись.
Для команд, которым это нужно, свяжите «Опубликовано» с workflow статуса (см. /blog/integrations-status-updates) без ручного копирования содержимого.
Трекьте action items до завершения
Постмортемы уменьшают вероятность повторных инцидентов только если последующая работа действительно выполняется. Обращайтесь с action items как с первоклассными объектами в приложении — не как с абзацем в документе.
Определите action items как структурированные записи
У каждой задачи должны быть стандартизированные поля для трекинга и измерения:
- Owner (один ответственный, даже если исполнение совместное)
- Due date (и опционально «start not before»)
- Priority (P0–P3 или Высокий/Средний/Низкий)
- Status (Open, In progress, Blocked, Done, Won’t do)
- Критерии верификации (как подтвердить, что фикса сработала)
Добавьте полезную метаинформацию: теги (например, «мониторинг», «документы»), компонент/сервис и «создано из» (ID инцидента и ID постмортема).
Сделайте задачи доступными по всему приложению
Не привязывайте action items только к странице постмортема. Предоставьте:
- Глобальный поиск по владельцу, сервису, тегу и статусу
- Фильтры вроде «просроченные», «срок на этой неделе», «заблокированные», «высокий приоритет»
- Простые отчёты: количество по командам/сервисам, коэффициент завершения, среднее время до закрытия
Это превращает последующую работу в операционную очередь, а не в разрозненные заметки.
Повторяющиеся задачи и внешние ссылки (опционально)
Некоторые задачи повторяются (ежеквартальные game days, ревью плейбуков). Поддержите повторяющиеся шаблоны, которые создают новые элементы по расписанию, сохраняя каждое событие отдельным для трекинга.
Если команды уже используют другой трекер, позвольте action item ссылаться на внешний ID и ссылку, оставаясь источником правды для связи с инцидентом и верификации.
Напоминания и правила эскалации
Реализуйте лёгкие напоминания: уведомляйте владельцев по мере приближения сроков, помечайте просроченные элементы для лидов команды, показывайте хронические просрочки в отчётах. Делайте правила настраиваемыми, чтобы команды могли подстроиться под реалии on-call нагрузки.
Права доступа, контроль и аудит
Держите полный контроль над кодом
Владейте кодовой базой, чтобы команда могла укреплять, расширять и проверять всё.
Инциденты и постмортемы часто содержат чувствительные детали — идентификаторы клиентов, внутренние IP, находки по безопасности или проблемы с вендорами. Ясные правила доступа делают инструмент совместным, не превращая его в точку утечки данных.
Определите уровни доступа
Начните с небольшого понятного набора ролей:
- View-only (stakeholders): могут читать резюме инцидентов, таймлайны и финальные постмортемы, но не редактировать. Подходит для руководства, поддержки и партнёров.
- Editors (responders): могут создавать инциденты, добавлять обновления, управлять таймлайном и готовить постмортемы.
- Admins (owners): управляют ролями, конфигурируют шаблоны, подключают интеграции и решают споры по доступу.
Если у вас много команд, рассмотрите область применения ролей по сервису/команде (например, «Payments Editors») вместо глобального доступа.
Решите, что приватно, а что можно шарить
Классифицируйте содержимое заранее, до того как люди выработают привычки:
- Только для внутреннего пользования: PII клиентов, заметки расследований по безопасности, сырые логи, стенограммы чатов.
- Доступно для шаринга: высокоуровневое влияние, времена начала/окончания, смягчающие меры, публичные статусные апдейты.
Практичный паттерн — помечать разделы как Internal или Shareable и применять ограничения при экспорте и на статусной странице. Инциденты по безопасности могут иметь отдельный тип с более жёсткими настройками по умолчанию.
Доверенные аудит-логи
Для каждого изменения инцидента и постмортема записывайте: кто сделал изменение, что изменилось и когда. Включайте правки серьёзности, временных меток, влияния и финальных утверждений. Делайте аудит-логи поисковыми и неизменяемыми.
Аутентификация и безопасность сессий
Поддерживайте надёжную аутентификацию: email + MFA или magic link, и добавляйте SSO (SAML/OIDC), если пользователи этого ожидают. Используйте короткоживущие сессии, защищённые куки, CSRF-защиту и автоматическую отзыв сессий при изменении ролей. Для нюансов раскатки смотрите /blog/testing-rollout-continuous-improvement.
UX: дашборды, поиск и навигация
Во время активного инцидента люди сканируют информацию, а не читают подробно. UX должен показывать текущее состояние за секунды и при этом позволять ответчикам углубиться в детали, не теряясь.
Основные экраны для проектирования в первую очередь
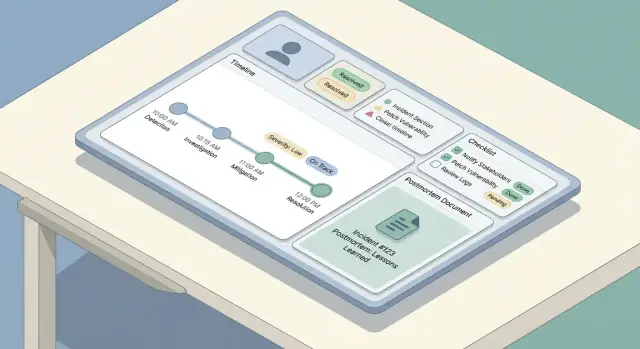
Начните с трёх экранов, покрывающих большинство рабочих потоков:
- Список инцидентов (дашборд): таблица или список карточек с бейджиком статуса, уровнем серьёзности, заголовком, затронутыми сервисами, владельцем/командиром, временем последнего обновления и длительностью.
- Деталь инцидента: «дом» для всего по одному инциденту — резюме, текущий статус, ключевые ссылки, участники и панель действий.
- Таймлайн: хронологическая лента обновлений и событий с крупными читаемыми временными метками.
Простое правило: страница детали инцидента должна отвечать «Что происходит прямо сейчас?» вверху и «Как мы сюда пришли?» ниже.
Фильтрация и поиск, которые действительно используют ответчики
Инциденты быстро накапливаются, поэтому сделайте обнаружение быстрым и нетребовательным:
- Быстрые фильтры: сервис, серьёзность, статус (open/mitigating/resolved/postmortem due), тег, диапазон дат, владелец.
- Поиск по: заголовку, ID инцидента, затронутым компонентам и тегам.
Предлагайте сохранённые представления типа Мои открытые инциденты или Sev-1 за эту неделю, чтобы дежурные не собирали фильтры каждый раз.
Бейджики статуса и согласованность «текущего состояния»
Используйте согласованные, цветобезопасные бейджи по всему приложению (избегайте тонких оттенков, которые плохи в стрессовой ситуации). Держите одинаковую терминологию в списке, заголовке детали и событиях таймлайна.
С первого взгляда ответчики должны видеть:
- Текущий статус + уровень серьёзности
- Время последнего обновления (и кто его опубликовал)
- Следующая контрольная точка (например, «Следующее обновление через 8 мин», если поддерживается частота апдейтов)
Читаемость под давлением
Отдавайте приоритет сканируемости:
- Крупные временные метки и явные заголовки секций
- Прилипающий заголовок инцидента при прокрутке
- Свертываемые секции для шумных данных (сырые алерты, длинные логи)
- Навигация с клавиатуры (/, n/p для следующего/предыдущего инцидента)
Проектируйте для худшего момента: если кто-то полусонный просматривает с телефона, UI всё равно должен быстро вести к нужному действию.
Интеграции: алерты, чат, тикет-система и статус-страницы
Интеграции превращают трекер инцидентов из «места для заметок» в систему, в которой команда действительно управляет инцидентами. Начните со списка систем, которые нужно подключить: мониторинг/наблюдаемость (PagerDuty/Opsgenie, Datadog, CloudWatch), чат (Slack/Teams), email, тикетинг (Jira/ServiceNow) и статусная страница.
Выберите стиль интеграции
Большинство команд используют смесь:
- Inbound webhooks для алертов и команд в чате (быстро, почти в реальном времени, невысокая операционная стоимость).
- Polling когда инструмент не может пушить события, но держите интервалы умеренными и кэшируйте результаты.
- Ручное связывание как запасной вариант (вставить URL алерта, прикрепить ключ тикета) — полезно, когда API недоступны.
Предотвращайте дублирование инцидентов (идемпотентность)
Алерты шумные, ретраются и часто приходят не по порядку. Определите стабильный idempotency key для события провайдера (например: provider + alert_id + occurrence_id) и храните его с уникальным ограничением. Для дедупликации решите правила вроде «тот же сервис + та же сигнатура в пределах 15 минут» — добавлять в существующий инцидент, а не создавать новый.
Границы ответственности и режимы отказа
Будьте явными, что ваше приложение владеет, а что остаётся в исходном инструменте:
- Ваше приложение может владеть записью инцидента, таймлайном, ролями и постмортемом.
- Система тикетов может владеть выполнением работы и утверждениями.
Когда интеграция падает, деградируйте мягко: ставьте retries в очередь, показывайте предупреждение в инциденте («публикация в Slack задерживается») и всегда позволяйте операторам продолжать вручную.
Статусные обновления без лишней работы
Относитесь к статусным обновлениям как к первоклассному действию: структурированное «Обновление» в UI должно уметь публиковать в чат, дописывать таймлайн инцидента и опционально синхронизироваться со статусной страницей — без необходимости писать одно и то же сообщение трижды.
Архитектура и выбор стека технологий
Выпустите первую версию
Создайте приём, обновления, таймлайн и постмортемы без недель настройки.
Ваш инструмент для инцидентов — это система «во время простоя», поэтому отдавайте предпочтение простоте и надёжности. Лучший стек — тот, который ваша команда может развернуть, отладить и поддерживать в 2:00 ночи с уверенностью.
Выберите стек, которым команда владеет
Начните с того, что ваши инженеры уже умеют деплоить в проде. Популярные веб-фреймворки (Rails, Django, Laravel, Spring, Express/Nest, ASP.NET) обычно безопаснее, чем новый фреймворк, который понимает только один человек.
Для хранения данных реляционная БД (PostgreSQL/MySQL) хорошо подходит для инцидент-ориентированных записей: инциденты, обновления, участники, action items и постмортемы выигрывают от транзакций и явных связей. Используйте Redis только при реальной потребности (кеш, очередь, блокировки).
Хостинг может быть простым — управляемая платформа (Render/Fly/Heroku-подобные) или существующая облачная среда (AWS/GCP/Azure). Предпочитайте управляемые БД и бэкапы, если возможно.
Реалтайм: websockets vs периодическое обновление
Активные инциденты ощущаются лучше с реальным временем, но на старте вам не всегда нужны вебсокеты.
- Периодический опрос (polling) проще реализовать и эксплуатировать. Для многих команд обновление таймлайна каждые 10–30 секунд «достаточно хорошо».
- Websockets/SSE становятся ценными при большом числе одновременно просматривающих, быстрых обновлениях или желании чатовоподобного взаимодействия.
Практичный подход: проектировать API/события так, чтобы можно было начать с polling и позже добавить websockets без переписывания UI.
Наблюдаемость самого инструмента
Если это приложение падает во время инцидента, оно становится частью инцидента. Добавьте:
- Структурированные логи (кто что поменял и контекст запроса)
- Метрики (латентность, rate ошибок, глубина очередей, число websocket-подключений)
- Трекинг ошибок (необработанные исключения, краши фронтенда)
Бэкапы, миграции и план восстановления
Обращайтесь с этим как с продакшен-системой:
- Автоматические ежедневные бэкапы (и регулярные тесты восстановления)
- Безопасные миграции схем (паттерны expand/contract, CI-проверки миграций)
- Минимальный DR-план: как поднять систему в новом регионе/аккаунте и как получить доступ к данным, если основная среда упала
Быстрый прототип без риска неверного решения
Если хотите проверить workflow и экраны до серьёзных вложений, подойдёт прототипирование: используйте инструмент, который быстро генерирует прототип (frontend + backend) по спецификации, и итеративно проверяйте с ответчиками. Так вы получите рабочую версию для учений, которую можно принять или доработать.
Тестирование, раскатка и непрерывное улучшение
Выпуск трекера инцидентов без репетиций — это риск. Лучшие команды относятся к инструменту как к любому другому операционному сервису: тестируйте критические пути, проводите реалистичные учения, раскатывайте поэтапно и постоянно улучшайте.
Тестируйте критические пути end-to-end
Сконцентрируйтесь на потоках, которые люди будут использовать в стрессовой ситуации:
- Создать инцидент, назначить уровень серьёзности и уведомить ответчиков
- Публиковать обновления (включая изменения статуса), проверять порядок в таймлайне и видимость правок
- Закрыть инцидент и сгенерировать постмортем из финального состояния
- Проверять, что ссылки и ссылки на артефакты (сервисы, владельцы, тикеты, чат) сохраняются
Добавьте регрессионные тесты для вещей, которые нельзя ломать: временные метки, часовые пояса и порядок событий. Инциденты — это повествования; если таймлайн неверен, доверие уходит.
Проверяйте права доступа и аудит
Баги в правах — это операционный и безопасностный риск. Добавьте тесты, которые гарантируют:
- Только авторизованные роли могут менять серьёзность, редактировать ключевые поля или закрывать инциденты
- View-only пользователи не видят приватных инцидентов
- Каждое чувствительное действие оставляет аудит-запись (кто, что, когда) и аудит нельзя изменить
Тестируйте сценарии «почти промахов», как потеря доступа у пользователя в разгар инцидента или реорганизация команды.
Проводите tabletop-упражнения с реальными ответчиками
Перед масштабным запуском прогоните сценарии с приложением как источником истины. Выбирайте узнаваемые сценарии (частичный outage, задержки данных, сбой третьей стороны). Наблюдайте за трениями: сбивчивые поля, недостающий контекст, слишком много кликов, неясная ответственность.
Сразу собирайте фидбек и превращайте его в небольшие, быстрые улучшения.
Роллаут через пилот и цикл обратной связи
Начните с одной пилотной команды и нескольких готовых шаблонов (типы инцидентов, чек-листы, форматы постмортемов). Проведите короткое обучение и дайте одностраничное «как мы проводим инциденты», прикреплённое из приложения (например, /docs/incident-process).
Отслеживайте метрики использования и улучшайте узкие места: время создания, % инцидентов с обновлениями, долю завершённых постмортемов и время закрытия action items. Рассматривайте их как продуктовые метрики, а не только комплаенс-метрики, и постоянно улучшайте релизы.